希爾排序的簡單理解
詳細描述
希爾排序又稱為縮小增量排序,主要是對序列按下標的一定增量進行分組,對每組使用直接插入排序演算法排序;隨著增量逐漸減小,每組包含的關鍵字越來越多,當增量減至 1 時,整個文件恰被分成一組,演算法便終止。
希爾排序詳細的執行步驟如下:
- 選擇一個增量序列 t1, t2, …, tk,其中 ti > tj,tk = 1;
- 按增量序列個數 k 對序列進行 k 趟排序;
- 每趟排序,根據對應的增量 ti 將待排序序列分割成若干長度為 m 的子序列,分別對各子表進行直接插入排序;
- 僅增量因子為 1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
演算法圖解
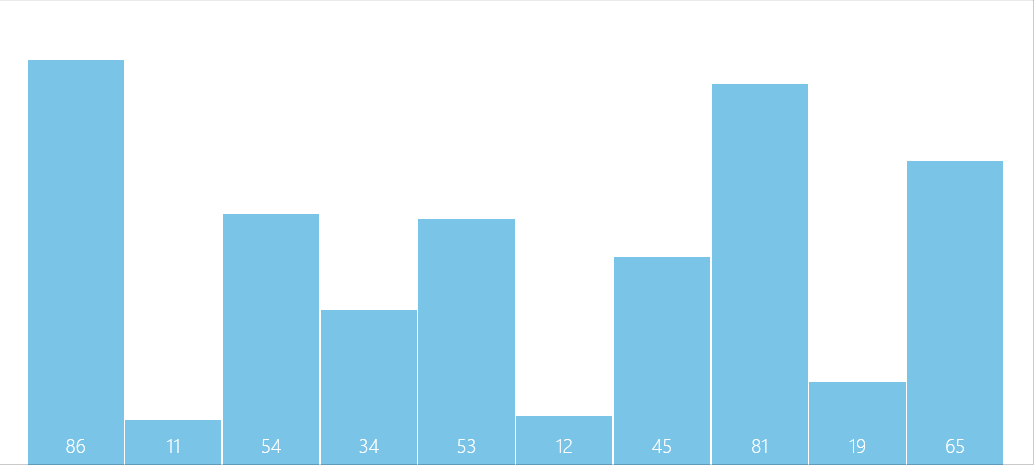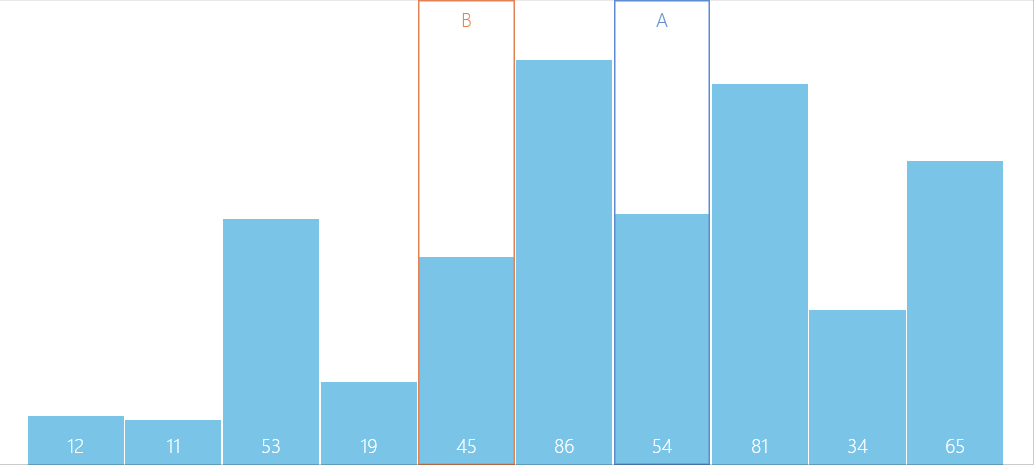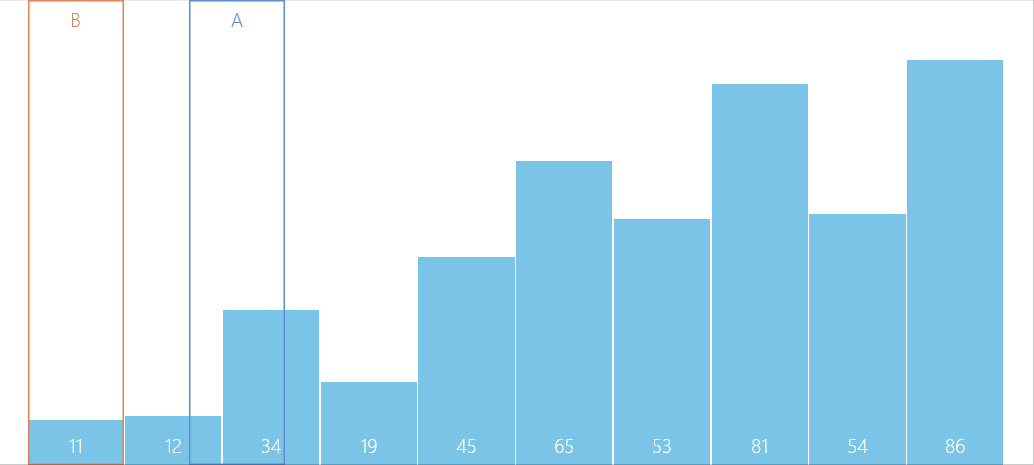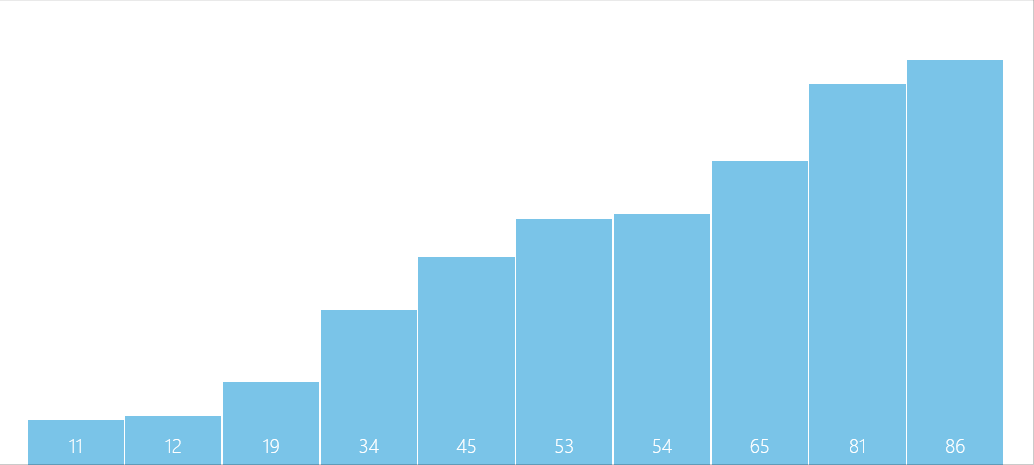
問題解疑
希爾排序是原地排序演算法嗎?
希爾排序是插入排序的一個優化版本,利用優化的策略使用插入排序,提高效率,沒有使用到額外的記憶體空間,因此希爾排序是原地排序演算法。
希爾排序是穩定的排序演算法嗎?
插入排序是穩定的排序演算法,但是,由於希爾排序使用了增量間隔進行插入排序,希爾排序並不能像插入排序保持穩定,排序過程中會出現相等的兩數前後順序不一致。
希爾排序的時間複雜度是多少?
最好情況時間複雜度為 \(O(n)\);最壞情況時間複雜度為 \(O(n^2)\);由於希爾排序花費的時間還由增量間隔決定,平均時間複雜度並不能明確得出,平均時間複雜度可看作為 \(O(n^{1.3 \sim 2})\)。
程式碼實現
package cn.fatedeity.algorithm.sort;
/**
* 希爾排序演算法
*/
public class ShellSort {
public static int[] sort(int[] numbers) {
int length = numbers.length;
// 通常增量序列進行二分對原序列拆分
for (int gap = length >> 1; gap > 0; gap = gap >> 1) {
for (int i = gap; i < length; i++) {
int j = i, current = numbers[i];
while (j >= gap && numbers[j - gap] > current) {
numbers[j] = numbers[j - gap];
j = j - gap;
}
numbers[j] = current;
}
}
return numbers;
}
}


