數據採集之:巧用布隆過濾器提取數據摘要
概覽
在telemetry採集中,由於數據量極大,一般採用分散式架構;使用消息隊列來進行各系統的解耦。有系統如下:
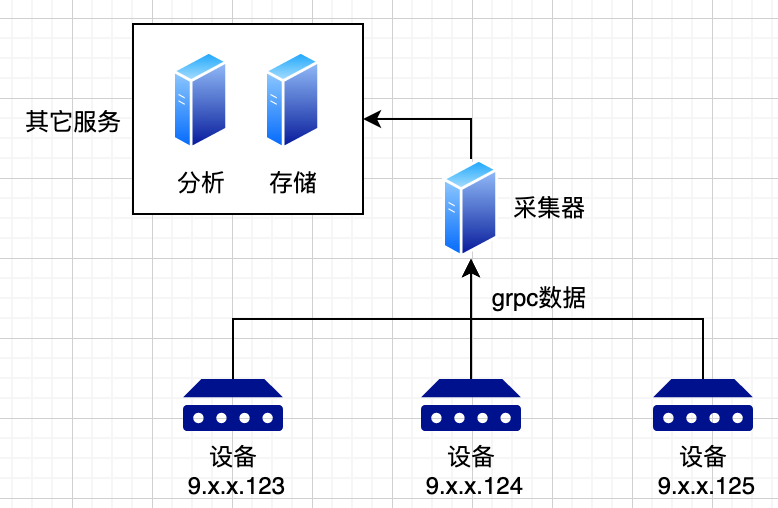
- 設備將各類數據上報給採集器,採集器充當格式轉換的角色。將各類不同的設備數據轉換為統一的格式。
- 採集器將數據寫入到消息隊列中,後端的其它服務,如「分析」,「告警」等服務從消息隊列中取數據,進行相關的實際業務。
採集器轉換後的的統一格式如下:
syntax = "proto3";
package talos.talosdata;
message Head {
uint64 time = 1;
string ip = 2; // 機器的IP
// .......
}
message TalosAttrData {
Head head = 1;
bytes data = 2;
}
其中,bytes data數據,可以再次解包為下列格式的數組:
message Data {
int32 attr_id = 1; // 申請的指標ID
string attr_name = 2; // 對應的指標名
float value = 3;
// ......
}
問題:後端分析系統資源浪費
因為是通用的採集系統,不方便感知具體的業務。所有類型的消息都會寫入到同一個消息隊列。
假設後端業務系統有告警服務,它只關注 attr_id = 10001的數據。它需要消費整個消息隊列中的數據並對每條數據進行判斷是否為目標數據。
偽程式碼如下:
kafkaMsg := kafka.Recv()
// 一次解包
baseData := new(TalosAttrData)
proto.Unmarshal(kafkaMsg.Bytes(), baseData)
// 二次解包
dataArr := make(DataArr, 0)
proto.Unmarshal(baseData.Data, &dataArr)
for _, data := range dataArr {
if data.AttrId == 10001{
// do sth
}
}
事實上,10001的消息,可能只佔整個消息數的1%,但用戶系統需要解出遍歷所有數據。這顯然不合理。
上述問題的產生,主要是兩個原因:
- 所有類型的數據不區別的放在同一個消息隊列topic中,這是主要矛盾。
- 關鍵資訊
attr_id必須解出最深層次的包體才能獲取。
解決第一個問題,實質上需要引入消息精細化分發的能力,也就是按需訂閱系統。因為在實作中考慮到擴展性和運維,幾乎不可能為每種類型的attr_id分配過於精細的消息隊列topic。這個地方的細節很多,但不是本文重點,暫時不表。
要解決第二個問題,假設在不解析bytes data = 2;就能判定這個數據中是否有目標的數據,則可以避免第二次解包。
解法:為每條消息新增摘要欄位
上文指出,每條消息還有一個head欄位,在第一次解包時,就可解出:
message Head {
uint64 time = 1;
string ip = 2; // 機器的IP
// .......
}
如需判定某內容是否存在於一個集合,很顯然應該使用布隆過濾器。
什麼是布隆過濾器
布隆過濾器非常的簡單,不了解的朋友需要先看看這篇文章://blog.csdn.net/zhanjia/article/details/109313475
假設使用8bit作為bloom filter的存儲,有兩個任意的hash函數(比如md5/sha256)
初始情況下,8位為0。
0000 0000
輸入為hello,假設對hello取第一次hash: hash1("hello") % 8 = 7,將存儲的第7位置1:
1000 0000
同樣對hello取第二次hash:hash2("hello") % 8 = 3,將存儲的第3位置為1:
1000 1000
如果要判定hello是否在bloom filter的存儲中,則只需要檢查第3/7位是否是1,因為hello的兩次hash的結果是已知的:
assert bloomData & b10001000 == b10001000
顯然:假設第3、7位都為1,則hello可能存在於bloom filter中,如果任意一位不為1,則hello一定不在bloom filter中。
bloom filter的優勢在於:
- 使用很少的存儲表示一個集合(在本例中是一個uint64)
- 判定(與bit位相比)較多的數據「一定不存在於」或「可能存在於」這個集合中。
提取摘要
一般布隆過濾器的用法是利用一個超大的集合來判定海量數據是否存在,比如爬蟲使用一個N長的布隆過濾器,來判定海量的url是否已經遍歷過。
但本文反其道而行之,為每條數據附加短小的消息摘要,然後在業務方判定摘要是否滿足條件。
-
在
head消息體中,新增filter欄位:message Head { uint64 time = 1; string ip = 2; // 機器的IP // ....... uint64 filter = 10; // bloom過濾欄位 } -
有函數如下,可以將任意消息提取摘要,並放置在uint64中。在這裡hash1是md5,hash2是sha256演算法。用其它的hash演算法也可。
// SetBloomUInt64 用一個uint64做bloom過濾器的存儲,給msg做摘要提取並設置到origin中,返回值為被設置後的值 func SetBloomUInt64(origin uint64, msg []byte) uint64 { origin = origin | 1<<(hash1(msg)%64) origin = origin | 1<<(hash2(msg)%64) return origin } func hash1(msg []byte) uint32 { hash := md5.New() hash.Write(msg) bts := hash.Sum(nil) return crc32.ChecksumIEEE(bts) } func hash2(msg []byte) uint32 { hash := sha256.New() hash.Write(msg) bts := hash.Sum(nil) return crc32.ChecksumIEEE(bts) } -
在採集器格式轉換的時候,將每條消息的
attr_id都提取摘要,循環放在head.filter欄位中。這個摘要可以在後續被所有的業務用上。// 提取bloom摘要 var filter uint64 for _, v := range data { bs := make([]byte, 4) binary.LittleEndian.PutUint32(bs, uint32(v.AttrId)) filter = bloom.SetBloomUInt64(filter, bs) // bloom過濾器演算法保證了設置重複的摘要不影響結果 } result.Head.Filter = filter -
關鍵步驟,後續的業務方可根據filter欄位,在解析出head後,就粗略判定這條消息是否包含目標數據,這樣就不需要進行二次的data解析和遍歷:
func blAttrID(attrID uint32) uint64 { bts := make([]byte, 4) binary.LittleEndian.PutUint32(bts, uint32(attrID)) return bloom.SetBloomUInt64(0, bts) } var bl10001 = blAttrID(10001) // 將10001轉換為origin為0的,經過bloom過濾器處理後的數據 // ... filter := talosData.Head.Filter if filter&bl10001 == bl10001{ //do sth }
為什麼能這樣
通過bloom過濾器,每條消息的head都包含了[]data的所有attr_id的摘要。這基於下面的假設:
- 同一個消息中包含的
attr_id的類型不能過多。根據文獻,假設使用uint64作為過濾器的長度,當hash函數的個數為2,attr_id的種類為10,則誤算率為0.08;如果種類為20,則誤算率為0.2。 - 誤算率指:判定數據包含在摘要中,但實際數據不存在。假設判定數據在摘要中不存在,則數據一定不存在。所以誤算率並不會造成邏輯錯誤,充其量會多一些冗餘的計算。
通過這一個小小的優化,在生產端增加一些計算,就可以為後續所有的業務提供服務。業務可以在一次uint64取或的時間內,判定整個數據是否符合要求。減輕業務系統的壓力。


