redis主從複製(九)
先來簡單了解下redis中提供的集群策略, 雖然redis有持久化功能能夠保障redis伺服器宕機也能恢復並且只有少量的數據損失,但是由於所有數據在一台伺服器上,如果這台伺服器出現硬碟故障,那就算是有備份也仍然不可避免數據丟失的問題。在實際生產環境中,我們不可能只使用一台redis伺服器作為我們的快取伺服器,必須要多台實現集群,避免出現單點故。
Redis雖然讀取寫入的速度都特別快,但是也會產生讀壓力特別大的情況。為了分擔讀壓力,Redis支援主從複製,Redis的主從結構可以採用一主多從或者級聯結構,Redis主從複製可以根據是否是全量分為全量同步和增量同步。
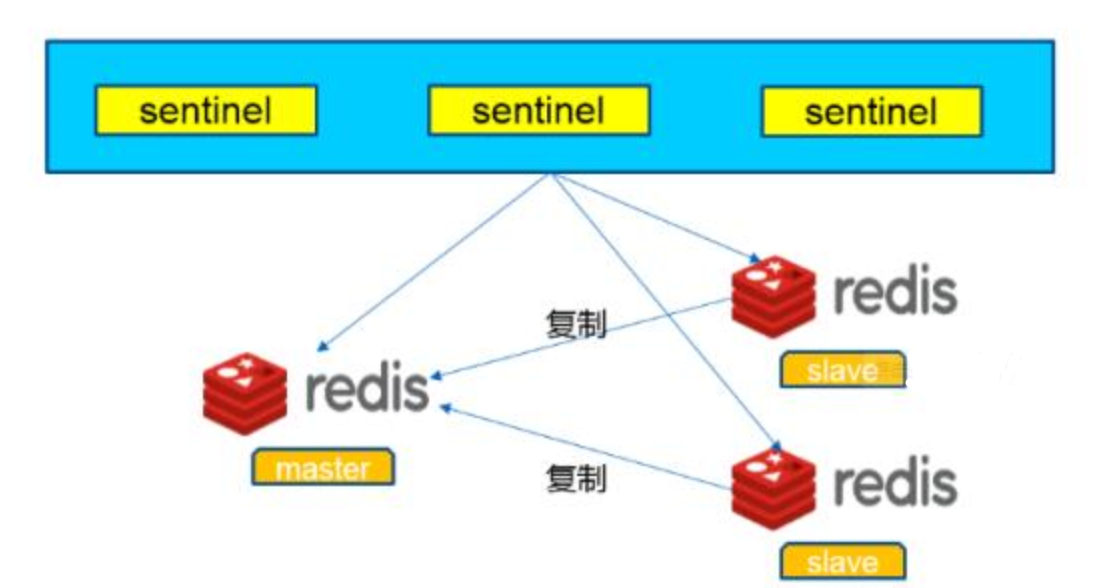
如上圖所示,我們可以將一台redis伺服器作為主庫,多台其他的伺服器作為從庫,主庫只負責寫數據,從庫負責讀數據,當主庫數據更新時,會同步到它所有的從庫。這就實現了主從複製,讀寫分離。既可以解決伺服器負載過大的問題,又能夠在一台伺服器發生故障時及時使用其他伺服器恢複數據。
下面演示一下redis中的主從複製,首先我們創建三份配置文件,分別對應埠號6379,6380,6381開啟三個redis服務:
可以看到目前下面3台服務的角色(role)是master,也就是目前沒有主從關係。

由於我們現在沒有配置主從庫,所以可以通過命令info replication看到,三台伺服器都分別是獨立的主庫。現在我們將埠號6379配置為主庫(master),將埠號6380和6381配置為6379的從庫,配置方法為在從庫中執行命令:SLAVEOF 主庫IP地址 主庫埠號,或者直接在從機的配置文件中配置 SLAVEOF 主庫IP地址 主庫埠號,然後重啟.新版本裡面是 replicaof ip port .

執行完SLAVEOF 命令以後我們再使用INFO REPLICATION 查看當前3台服務的關係,可以看到79服務為master ,其他兩台為slave,說明主從關係建立完成,這裡有個注意的點,就是在兩台從機的配置文件里需要配置 masterauth password 主機密碼,不然在建立主從關係的時候會提示認證失敗。

可以看到一開始3台服務的庫里都是空的,在主機上set 值以後,可以直接在從機上get,可以看到下圖,當在從機上set值的時候會報錯,這是為什麼呢?
默認情況下,從庫只能讀取數據,執行寫操作會報錯:可以修改配置文件中的以下參數來配置從機是只讀還是可寫,這裡推薦設置成yes 只讀。
1 全量同步
Redis全量複製一般發生在Slave初始化階段,這時Slave需要將Master上的所有數據都複製一份。具體步驟如下:
1)從伺服器連接主伺服器,發送SYNC命令;
2)主伺服器接收到SYNC命名後,開始執行BGSAVE命令生成RDB文件並使用緩衝區記錄此後執行的所有寫命令;
3)主伺服器BGSAVE執行完後,向所有從伺服器發送快照文件,並在發送期間繼續記錄被執行的寫命令;
4)從伺服器收到快照文件後丟棄所有舊數據,載入收到的快照;
5)主伺服器快照發送完畢後開始向從伺服器發送緩衝區中的寫命令;
6)從伺服器完成對快照的載入,開始接收命令請求,並執行來自主伺服器緩衝區的寫命令;

完成上面幾個步驟後就完成了slave伺服器數據初始化的所有操作,savle伺服器此時可以接收來自用戶的讀請求。master/slave 複製策略是採用樂觀複製,也就是說可以容忍在一定時間內master/slave數據的內容是不同的,但是兩者的數據會最終同步。具體來說,redis的主從同步過程本身是非同步的,意味著master執行完客戶端請求的命令後會立即返回結果給客戶端,然後非同步的方式把命令同步給slave。這一特徵保證啟用master/slave後 master的性能不會受到影響。
但是另一方面,如果在這個數據不一致的窗口期間,master/slave因為網路問題斷開連接,而這個時候,master是無法得知某個命令最終同步給了多少個slave資料庫。不過redis提供了一個配置項來限制只有數據至少同步給多少個slave的時候,master才是可寫的: min-slaves-to-write 3 表示只有當3個或以上的slave連接到master,master才是可寫的 ,min-slaves-max-lag 10 表示允許slave最長失去連接的時間,如果10秒還沒收到slave的響應,則master認為該slave以斷開.
2 增量同步
Redis增量複製是指Slave初始化後開始正常工作時主伺服器發生的寫操作同步到從伺服器的過程。增量複製的過程主要是主伺服器每執行一個寫命令就會向從伺服器發送相同的寫命令,從伺服器接收並執行收到的寫命令。
從redis 2.8開始,就支援主從複製的斷點續傳,如果主從複製過程中,網路連接斷掉了,那麼可以接著上次複製的地方,繼續複製下去,而不是從頭開始複製一份master node會在記憶體中創建一個backlog,master和slave都會保存一個replica offset還有一個master id,offset就是保存在backlog中的。如果master和slave網路連接斷掉了,slave會讓master從上次的replica offset開始繼續複製。但是如果沒有找到對應的offset,那麼就會執行一次全量同步 。
無硬碟複製:
前面我們說過,Redis複製的工作原理基於RDB方式的持久化實現的,也就是master在後台保存RDB快照,slave接收到rdb文件並載入,但是這種方式會存在一些問題
1. 當master禁用RDB時,如果執行了複製初始化操作,Redis依然會生成RDB快照,當master下次啟動時執行該RDB文件的恢復,但是因為複製發生的時間點不確定,所以恢復的數據可能是任何時間點的。就會造成數據出現問題
2. 當硬碟性能比較慢的情況下(網路硬碟),那初始化複製過程會對性能產生影響
因此2.8.18以後的版本,Redis引入了無硬碟複製選項,可以不需要通過RDB文件去同步,直接發送數據,通過以下配置來開啟該功能repl-diskless-sync yes 。master**在記憶體中直接創建rdb,然後發送給slave,不會在自己本地落地磁碟了。
3 Redis主從同步策略
主從剛剛連接的時候,進行全量同步;全同步結束後,進行增量同步。當然,如果有需要,slave 在任何時候都可以發起全量同步。redis 策略是,無論如何,首先會嘗試進行增量同步,如不成功,要求從機進行全量同步。
|
1
|
slave-read-only yes |

將從庫升級為獨立的主庫:
|
1
|
SLAVEOF NO ONE |
如果主庫宕機,從庫會「原地待命」,待主庫重新連接之後,會恢復和主庫的聯繫:
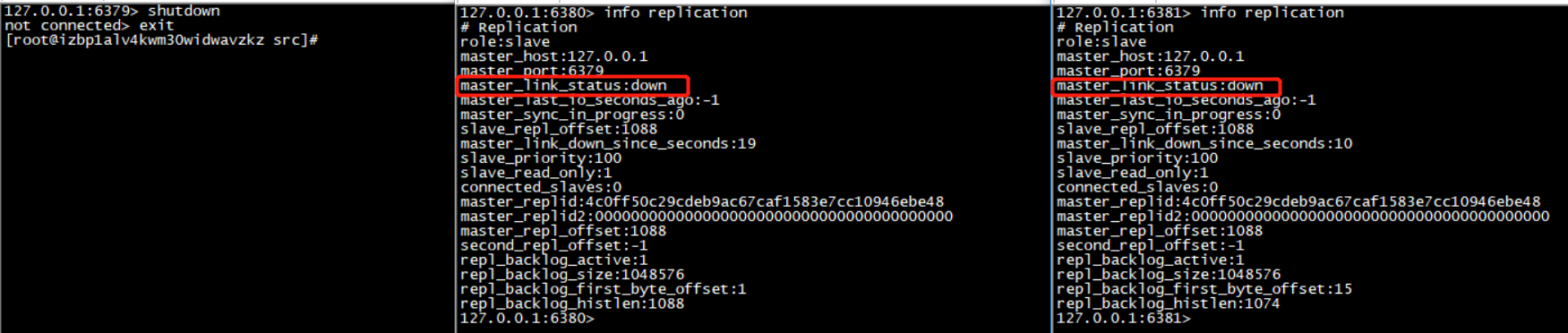
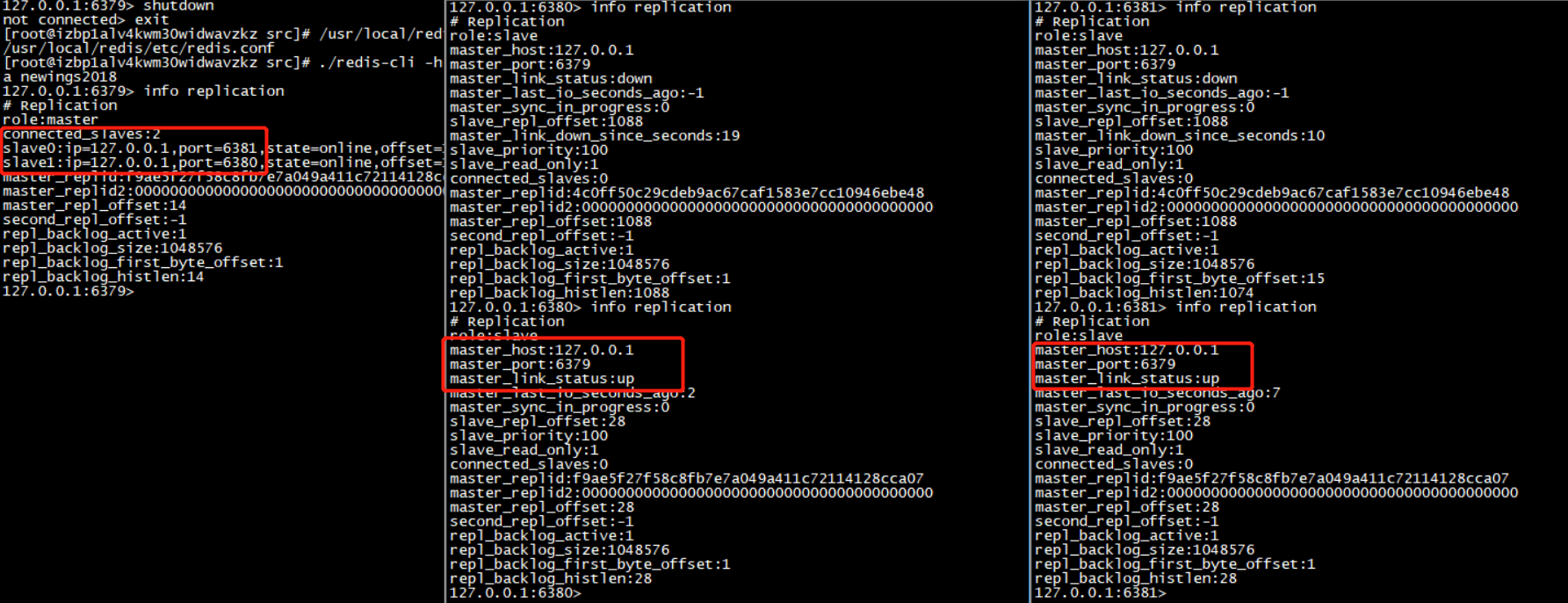
當主機重新啟動,他依然會回到自己原先的角色,而自己的從機也依然在苦苦等待他回來,一旦發現他回來了,從機依然會在他手下效勞,但是,如果從庫宕機,連接會斷開,當從庫重新連接後,需要重新建立與主庫的連接: 如下圖:
一個庫可以是一個庫的從庫,同時也可以是另一個庫的主庫,這樣可以有效減輕master的壓力,避免所有的從庫都從一個主庫中讀取數據:

主從複製的原理:
主庫master和從庫slave的複製分為全量複製和增量複製:
全量複製:全量複製一般發生在slave初始化階段,此時slave需要將master上的所有數據都複製一份,具體步驟如下:
- 從庫連接到主庫,並發送一條SYNC命令;
- 主庫接收到SYNC命令後,開始執行BGSAVE命令生成RDB快照文件,並使用緩衝區記錄此後執行的所有寫命令;
- 主庫執行完BGSAVE之後,將快照文件發送到所有從庫,在此期間,仍繼續將所有寫命令記錄到緩衝區;
- 從庫在接收到快照文件後,丟棄所有舊數據,載入快照文件中的新數據;
- 主庫繼續向從庫發送緩衝區中的寫命令;
- 從庫將快照文件中的數據載入完畢後,繼續接收主庫發送的緩衝區中的寫命令,並執行這些寫命令以更新數據。
完成上面的步驟之後,從庫可以開始接收來自用戶的讀數據請求。增量複製:增量複製是指,在slave初始化完成後的工作階段,主庫將新發生的寫命令同步到從庫的過程。主庫每執行一條寫命令,都會向從庫發送相同的寫命令,從庫會執行這些寫命令。
總結:主庫和從庫初次建立連接時,進行全量複製;全量複製結束後,進行增量複製。但是當增量複製不成功時,需要發起全量複製。
主從複製的不足:
主從模式解決了數據備份和性能(通過讀寫分離)的問題,但是還是存在一些不足:
- RDB 文件過大的情況下,同步非常耗時。
- 在一主一從或者一主多從的情況下,如果主伺服器掛了,對外提供的服務就不可用了,單點問題沒有得到解決。如果每次都是手動把之前的從伺服器切換成主伺服器,這個比較費時費力,還會造成一定時間的服務不可用。
哨兵模式:
哨兵模式是通過後台監控主庫是否故障,當主庫發生故障時,將根據投票數自動將某一從庫轉換為主庫。
sentinel monitor host6399 192.168.254.137 6399 1 --配置監控的master節點sentinel down-after-milliseconds host6399 5000 --表示如果5s內mymaster沒響應,就認為SDOWNprotected-mode no -- 禁止保護daemonize yes -- 後台運行logfile "/var/log/sentinel_log.log"sentinel failover-timeout host6399 15000 --表示如果15秒後,mysater仍沒活過來,則啟動failover,從剩下的slave中選一個升級為mastersentinel auth-pass host6399 123456-- 密碼然後通過 /usr/local/redis/bin/redis-sentinel /usr/local/redis/etc/sentinel.conf 啟動哨兵會出現以下資訊:
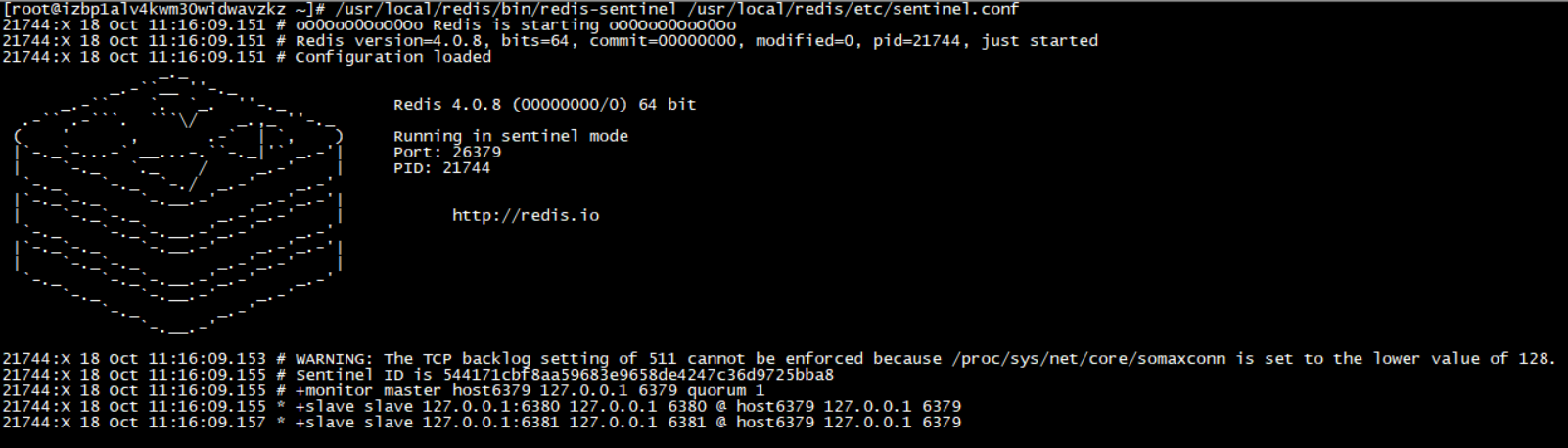
此刻說明哨兵已經啟動,接下去我讓主機 6379 宕機,來演示主機宕機以後從機的反客為主。
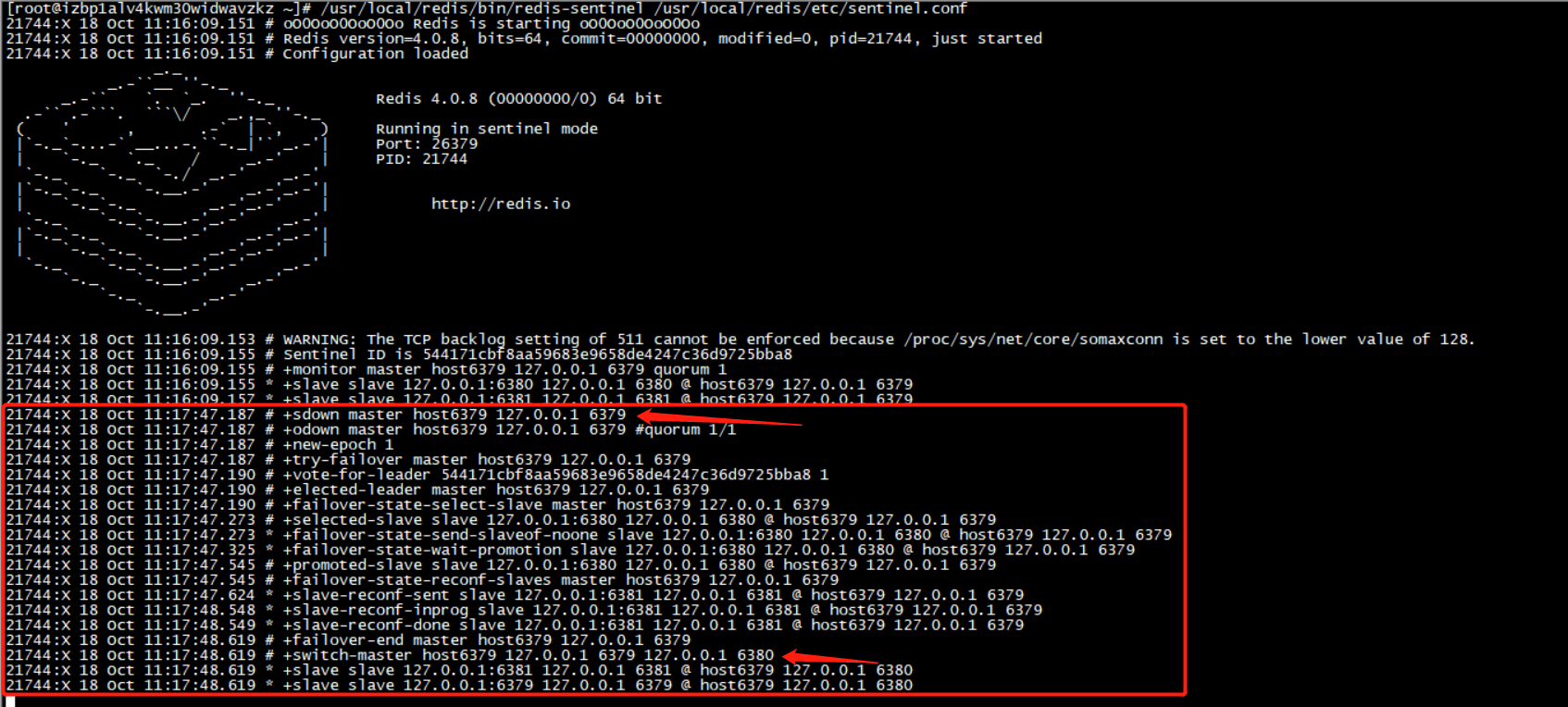
可以看到當主機宕機後,經過哨兵監控,發現主機宕機,會根據事先的配置文件里規則去選舉新的master。這裡選出來的是6380,如下圖: 
如果 master 被標記為下線,就會開始故障轉移流程。既然有這麼多的 Sentinel 節點,由誰來做故障轉移的事情呢?故障轉移流程的第一步就是在 Sentinel 集群選擇一個 Leader,由 Leader 完成故障轉移流程。Sentinle 通過 Raft 演算法,實現 Sentinel 選舉。
在分散式存儲系統中,通常通過維護多個副本來提高系統的可用性,那麼多個節點之間必須要面對數據一致性的問題。Raft 的目的就是通過複製的方式,使所有節點達成一致,但是這麼多節點,以哪個節點的數據為準呢?所以必須選出一個 Leader。大體上有兩個步驟:領導選舉,數據複製。Raft 是一個共識演算法(consensus algorithm)。比如比特幣之類的加密貨幣,就需要共識演算法。Spring Cloud 的註冊中心解決方案 Consul 也用到了 Raft 協議。
Raft 的核心思想:先到先得,少數服從多數。
Raft演算法動畫演示地址://thesecretlivesofdata.com/raft/
為了解決master選舉問題,又引出了一個單點問題,也就是哨兵的可用性如何解決,在一個一主多從的Redis系統中,可以使用多個哨兵進行監控任務以保證系統足夠穩定。此時哨兵不僅會監控master和slave,同時還會互相監控;這種方式稱為哨兵集群,哨兵集群需要解決故障發現、和master決策的協商機制問題.
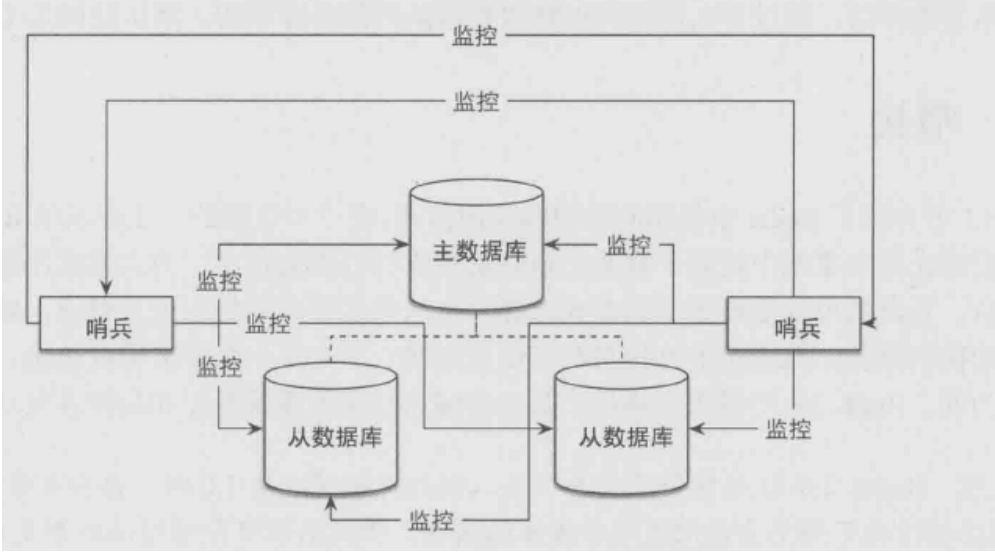
sentinel之間的相互感知:
sentinel節點之間會因為共同監視同一個master從而產生了關聯,一個新加入的sentinel節點需要和其他監視相同master節點的sentinel相互感知,首先
- 需要相互感知的sentinel都向他們共同監視的master節點訂閱channel:sentinel:hello
- 新加入的sentinel節點向這個channel發布一條消息,包含自己本身的資訊,這樣訂閱了這個channel的sentinel就可以發現這個新的sentinel
- 新加入得sentinel和其他sentinel節點建立長連接
實現原理:
每個Sentinel以每秒鐘一次的頻率向它所知的Master/Slave以及其他 Sentinel 實例發送一個 PING 命令
- 如果一個實例(instance)距離最後一次有效回復 PING 命令的時間超過 down-aftermilliseconds 選項所指定的值, 則這個實例會被 Sentinel 標記為主觀下線。
- 如果一個Master被標記為主觀下線,則正在監視這個Master的所有 Sentinel 要以每秒一次的頻率 確認Master的確進入了主觀下線狀態。
- 當有足夠數量的 Sentinel(大於等於配置文件指定的值:quorum)在指定的時間範圍內確認 Master的確進入了主觀下線狀態, 則Master會被標記為客觀下線 。
- 在一般情況下, 每個 Sentinel 會以每 10 秒一次的頻率向它已知的所有Master,Slave發送 INFO 命令
- 當Master被 Sentinel 標記為客觀下線時,Sentinel 向下線的 Master 的所有 Slave 發送 INFO 命令 的頻率會從 10 秒一次改為每秒一次 ,若沒有足夠數量的 Sentinel 同意 Master 已經下線, Master 的 客觀下線狀態就會被移除。
- 若 Master 重新向 Sentinel 的 PING 命令返回有效回復, Master 的主觀下線狀態就會被移除。
主觀下線:Subjectively Down,簡稱 SDOWN,指的是當前 Sentinel 實例對某個redis伺服器做出的下 線判斷。
客觀下線:Objectively Down, 簡稱 ODOWN,指的是多個 Sentinel 實例在對Master Server做出 SDOWN 判斷,並且通過 SENTINEL之間交流後得出Master下線的判斷。然後開啟failover
故障轉移過程:
- 怎麼讓一個原來的slave節點成為主節點? 選出Sentinel Leader之後,由Sentinel Leader向某個節點發送slaveof no one命令,讓它成為獨 立節點。
- 然後向其他節點發送replicaof x.x.x.x xxxx(本機服務),讓它們成為這個節點的子節點,故障轉 移完成。
如何選擇合適的slave節點成為master呢?有四個因素影響。
- 斷開連接時長,如果與哨兵連接斷開的比較久,超過了某個閾值,就直接失去了選舉權
- 優先順序排序,如果擁有選舉權,那就看誰的優先順序高,這個在配置文件里可以設置(replicapriority 100),數值越小優先順序越高
- 複製數量,如果優先順序相同,就看誰從master中複製的數據最多(複製偏移量最大)
- 進程id,如果複製數量也相同,就選擇進程id最小的那個
誰來完成故障轉移?
當redis中的master節點被判定為客觀下線之後,需要重新從slave節點選擇一個作為新的master節點, 那現在有三個sentinel節點,應該由誰來完成這個故障轉移過程呢?所以這三個sentinel節點必須要通 過某種機制達成一致,在Redis中採用了Raft演算法來實現這個功能。
每次master出現故障時,都會觸發raft演算法來選擇一個leader完成redis主從集群中的master選舉 功能。
常見的數據一致性演算法:
- paxos,paxos應該是最早也是最正統的數據一致性演算法,也是最複雜難懂的演算法。
- raft,raft演算法應該是最通俗易懂的一致性演算法,它在nacos、sentinel、consul等組件中都有使 用。
- zab協議,是zookeeper中基於paxos演算法上演變過來的一種一致性演算法 distro,
- Distro協議。Distro是阿里巴巴的私有協議,目前流行的Nacos服務管理框架就採用了 Distro協議。Distro 協議被定位為 臨時數據的一致性協議
哨兵機制的不足:
主從切換的過程中會丟失數據,因為只有一個 master。只能單點寫,沒有解決水平擴容的問題。如果數據量非常大,這個時候我們需要多個 master-slave 的 group,把數據分布到不同的 group 中。
Jedis的基本操作:

public class JedisSentinelTest {
private static JedisSentinelPool pool;
private static JedisSentinelPool createJedisPool() {
// master的名字是sentinel.conf配置文件裡面的名稱
String masterName = "redis-master";
Set<String> sentinels = new HashSet<String>();
sentinels.add("192.168.1.101:26379");
sentinels.add("192.168.1.102:26379");
sentinels.add("192.168.1.103:26379");
pool = new JedisSentinelPool(masterName, sentinels);
return pool;
}
public static void main(String[] args) {
JedisSentinelPool pool = createJedisPool();
pool.getResource().set("name", "qq"+System.currentTimeMillis());
System.out.println(pool.getResource().get("name"));
}
}


