Colab教程(超級詳細版)及Colab Pro/Colab Pro+使用評測
在下半年選修了機器學習的關鍵課程Machine learning and deep learning,但由於Macbook Pro顯示卡不支援cuda,因此無法使用GPU來訓練網路。教授推薦使用Google Colab作為訓練神經網路的平台。在高強度的使用了Colab一段時間後,我把自己的個人感受和使用心得與大家分享,同時也給想要嘗試的同學詳細介紹Colab具體的上手方法。
一、Colab介紹
在第一次使用Colab時,最大的困難無疑是對整個平台的陌生而導致無從下手,因此我首先介紹與Colab相關的基礎概念,以幫助大家更快地熟悉Colab平台。
Colab是什麼?
Colab = Colaboratory(即合作實驗室),是Google提供的一個在線工作平台,用戶可以直接通過瀏覽器執行python程式碼並與他人分享合作。Colab的主要功能當然不止於此,它還為我們提供免費的GPU。熟悉深度學習的同學們都知道:CPU計算力高但核數量少,善於處理線性序列,而GPU計算力低但核數量多,善於處理並行計算。在深度學習中使用GPU進行計算的速度要遠快於CPU,因此有高算力的GPU是深度學習的重要保證。由於不是所有GPU都支援深度計算(大部分的Macbook自帶的顯示卡都不支援),同時顯示卡配置的高低也決定了計算力的大小,因此Colab最大的優勢在於我們可以「借用」Google免費提供的GPU來進行深度學習。
綜上:Colab = “python版”Google doc + 免費GPU
Colab相關的概念
Jupyter Notebook:在Colab中,python程式碼的執行是基於.ipynb文件,也就是Jupyter Notebook格式的python文件。這種筆記型電腦文件與普通.py文件的區別是可以分塊執行程式碼並立刻得到輸出,同時也可以很方便地添加註釋,這種互動式操作十分適合一些輕量的任務。
具體關於Jupyter Notebook的資訊可以查看下面官網的鏈接://jupyter.org/
程式碼執行程式:程式碼執行程式就是Colab在雲端的”伺服器”。簡單來說,我們先在筆記型電腦寫好需要運行的程式碼,連接到程式碼執行程式,然後Colab會在雲端執行程式碼,最後把結果傳回瀏覽器。
實例空間:連接到程式碼執行程式後,Colab需要為其分配實例空間(Instance),可以簡單理解為運行筆記型電腦而創建的”虛擬機”,其中包含了執行ipynb文件時的默認配置、環境變數、自帶的庫等等。
二、Colab工作流程
介紹完了基本概念,下面我們來演示具體如何使用Colab
準備工作
首先我們需要創建一個Google賬戶,申請Google賬戶需要能接受簡訊的手機號碼。作者在寫這篇文章時親自進行了一次測試,發現目前不能通過中國手機來創建賬戶,但是帳號在創建後可以改綁中國手機。由於躍牆、如何申請Google賬戶不是本文的寫作目的,因此這裡就不作展開了,我個人猜測萬能的某寶之類應該有解決辦法。
Colab一般配合Google Drive使用(下文會提到這一點)。因此如有必要,我建議拓展Google雲端硬碟的儲存空間,個人認為性價比較高的是基本版或標準版。在購買完額外的空間後,頭像外部會出現一個四色光環,就像作者一樣。
有兩種方法可以新建一個筆記型電腦,第一種是在在雲端硬碟中右鍵創建。
第二種方法是直接在瀏覽器中輸入//colab.research.google.com,進入Colab的頁面後點擊新建筆記型電腦即可。使用這種方法新建的筆記型電腦時,會在雲端硬碟的根目錄自動創建一個叫Colab Notebook的文件夾,新創建的筆記型電腦就保存在這個文件夾中。
載入筆記型電腦
可以打開雲端硬碟中的已經存在的筆記型電腦,還可以從Github中導入筆記型電腦。如果關聯了Github賬戶,可以選擇一個賬戶中的Project,如果其中有ipynb文件就可以在Colab中打開。注意:關聯Github不是把Github中的項目文件夾載入到實例空間!
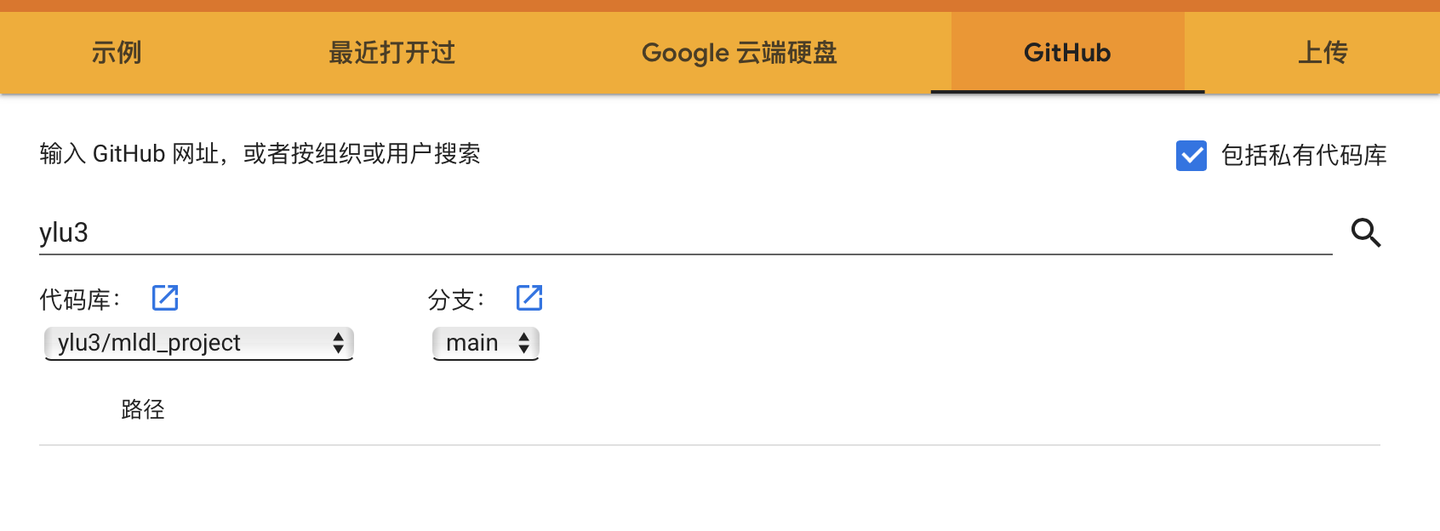
筆記型電腦介面
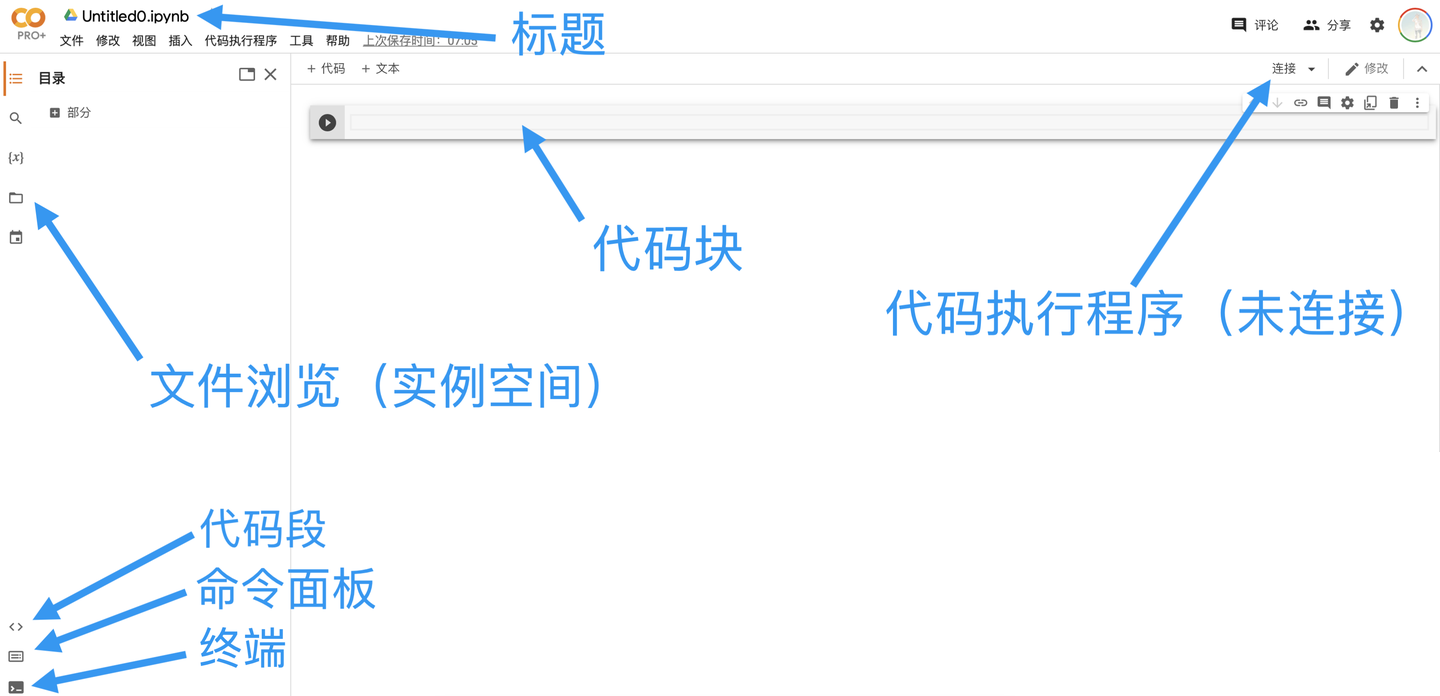
標題:筆記型電腦的名稱
程式碼塊:分塊執行的程式碼
文件瀏覽:Colab為筆記型電腦分配的實例空間
程式碼執行程式:用於執行筆記型電腦程式的伺服器
程式碼段:常用的程式碼段,比如裝載雲端硬碟
命令面板:常用的命令,比如查找/替換
終端:文件瀏覽下的終端(非常卡,不建議使用)
連接程式碼執行程式
點擊連接按鈕即可在5s左右的時間內連接到程式碼執行程式,此時可以看到消耗的RAM和磁碟
RAM:虛擬機運行記憶體,更大記憶體意味著更大的算力(之後會在Colab Pro中介紹)
磁碟:虛擬機文件的儲存空間,要注意的是購買更多雲端硬碟存儲空間不能增加可用磁碟空間
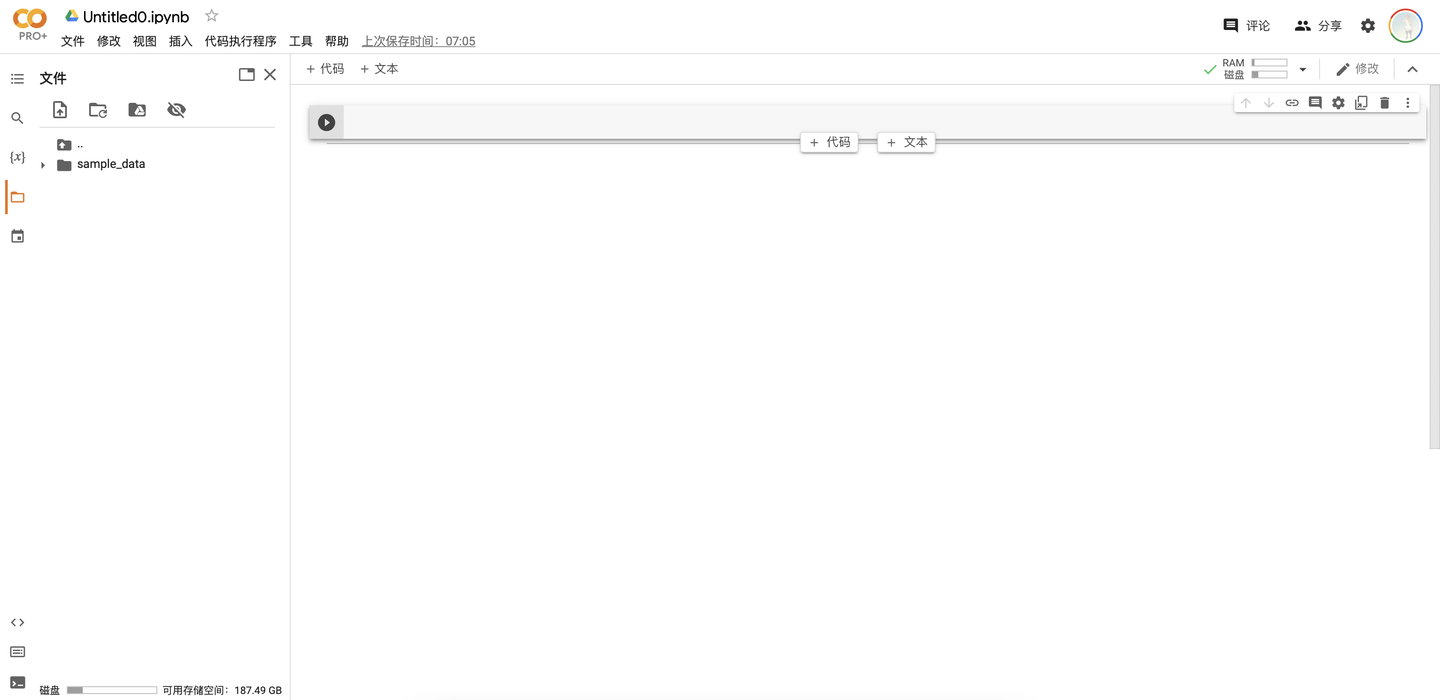
在打開筆記型電腦後,我們默認的文件路徑是“/content”,這個路徑也是執行筆記型電腦時的路徑,同時我們一般把用到的各種文件也保存在這個路徑下。在點擊“..”後即可返回查看根目錄“/”(如下圖),可以看到根目錄中保存的是一些虛擬機的環境變數和預裝的庫等等。不要隨意修改根目錄中的內容,以避免運行出錯,我們所有的操作都應在“/content”中進行。
執行程式碼塊
.ipynb文件通過的程式碼塊來執行程式碼,同時支援通過“!<command>”的方式來執行UNIX終端命令(比如“!ls”可以查看當前目錄下的文件)。Colab已經預裝了大多數常見的深度學習庫,比如pytorch,tensorflow等等,如果有需要額外安裝的庫可以通過“!pip3 install <package>”命令來安裝。下面是一些常見的命令。
# 載入雲端硬碟 from google.colab import drive drive.mount('/content/drive') # 查看分配到的GPU gpu_info = !nvidia-smi gpu_info = '\n'.join(gpu_info) if gpu_info.find('failed') >= 0: print('Not connected to a GPU') else: print(gpu_info) # 安裝python包 !pip3 install <package>
點擊「播放」按鈕執行程式碼塊。程式碼塊開始執行後,按鈕就會進入轉圈的狀態,表示「正在執行」,外部的圓圈是實線。如果在有程式碼塊執行的情況下繼續點擊其他程式碼塊的「播放」按鈕,則這些程式碼塊進入「等待執行」的狀態,按鈕也就會進入轉圈的狀態,但外部的圓圈是虛線。在當前程式碼塊結束後,會之前按照點擊的順序依次執行這些程式碼塊。
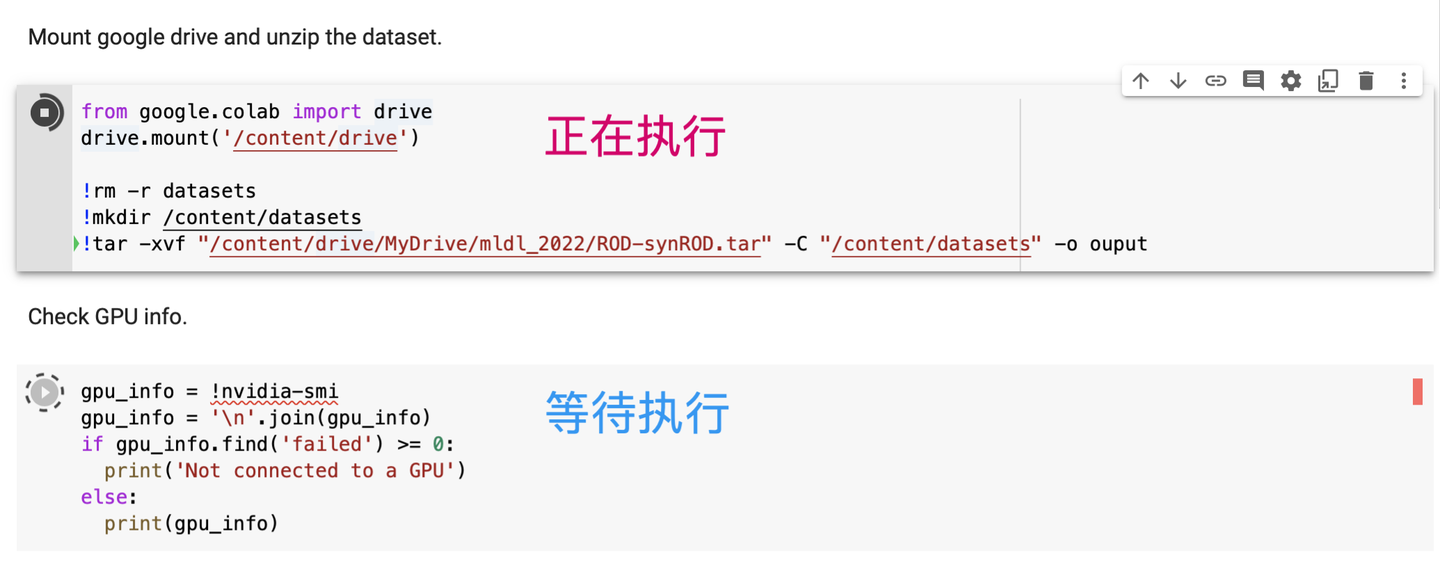
設置筆記型電腦的運行時類型
筆記型電腦在打開時的默認硬體加速器是None,運行規格是標準。在深度學習中,我們希望使用GPU來進行深度計算,同時如果購買了pro,我們希望使用高記憶體模式。點擊程式碼執行程式,然後點擊「更改運行時類型即可」。由於免費的用戶所能使用的GPU運行時有限,因此建議只在確實需要用到GPU時改變設置(模型搭建階段或其他非訓練階段使用None模式即可)。
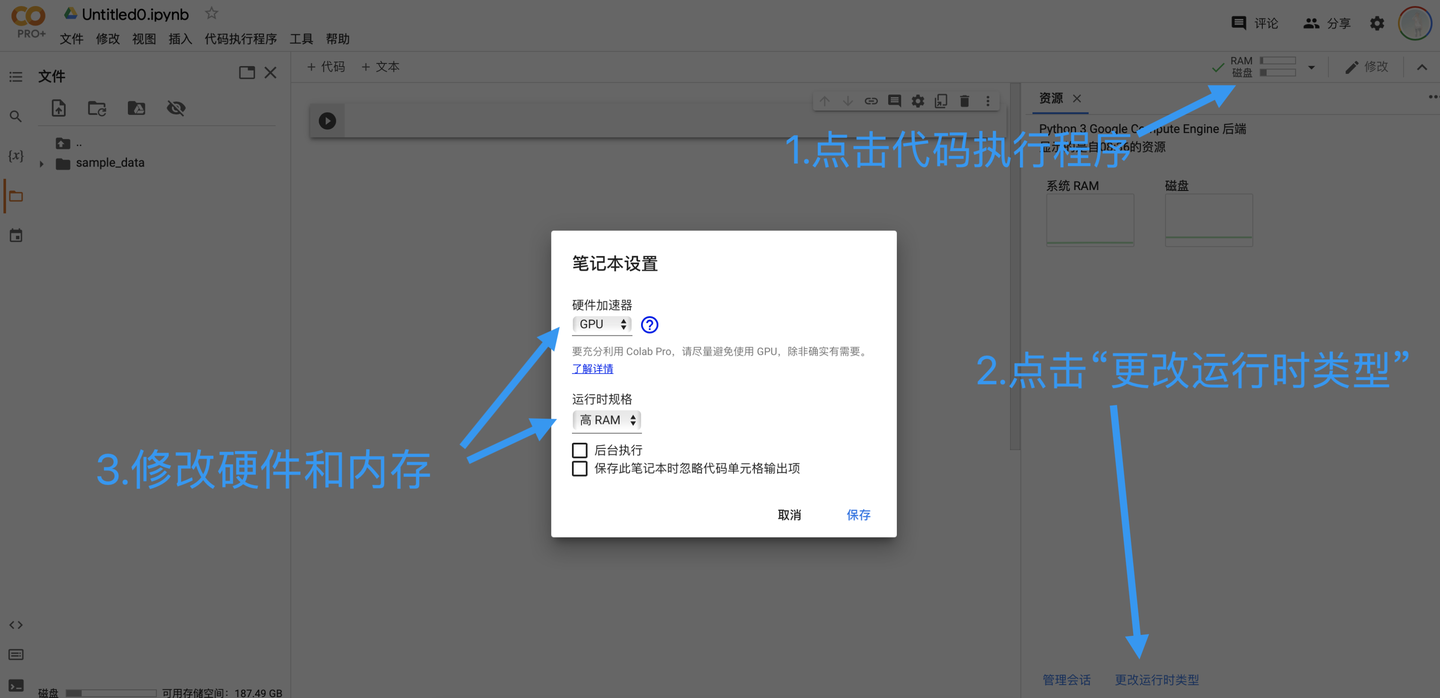
如果希望主動斷開程式碼執行程式,則點擊程式碼運行程式後選擇「斷開連接並刪除運行時」即可。
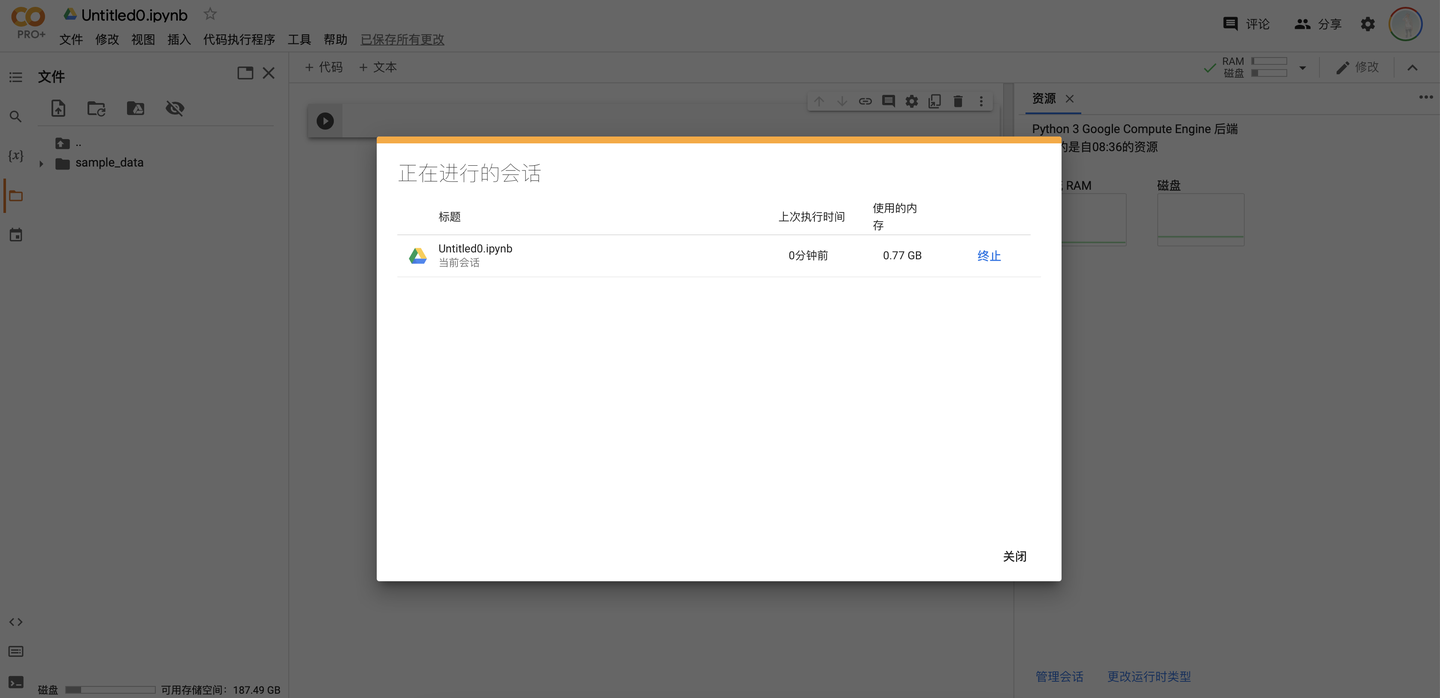
管理會話Session
會話就是當前連接到程式碼執行程式的筆記型電腦,通過點擊「管理會話」即可查看當前的所有會話,點擊「終止」即可斷開程式碼執行程式。用戶所能連接的會話數量是有限的,因此到達上限時再開啟新會話需要主動斷開之前的會話。
三、Colab重要特性
在這一部分,我希望強調一下Colab的一些重要特性和隨之帶來的相關影響
資源使用的限制
Google Colab為用戶提供免費的GPU,因此資源使用必然會受到限制(即使是Colab Pro+用戶也不例外),而這種限制無處不在。
有限的實例空間:實例空間的記憶體和磁碟都是有限制的,如果模型訓練的過程中超過了記憶體或磁碟的限制,那麼程式運行就會中斷並報錯。實例空間內的文件保存不是永久的,當程式碼執行程式被斷開時,實例空間內的所有資源都會被釋放(我們在“/content”目錄下上傳的文件也會全部消失)。


有限的連接時間:筆記型電腦連接到程式碼執行程式的時長是有限制的,這體現在三個方面:如果關閉瀏覽器,程式碼執行程式會在短時間內斷開而不是在後台繼續執行(這個「短時間」大概在幾分鐘左右,如果只是切換一下wifi之類是不會有影響的);如果空閑狀態過長(無互動操作或正在執行的程式碼塊),則會立即斷開連接;如果連接時長到達上限(免費用戶最長連接12小時),也會立刻斷開連接。

有限的GPU運行時:無論是免費用戶還是colab pro用戶,每天所能使用的GPU運行時間都是有限的。到達時間上限後,程式碼執行程式將被立刻斷開且用戶將被限制在當天繼續使用任何形式的GPU(無論是否為高RAM形式)。在這種情況下我們只能等待第二天重置。

頻繁的互動檢測:當一段時間沒有檢測到活動時,Colab就會進行互動檢測,如果長時間不點擊人機身份驗證,程式碼執行程式就會斷開。此外,如果頻繁地執行「斷開-連接」程式碼執行程式,也會出現人機身份驗證。
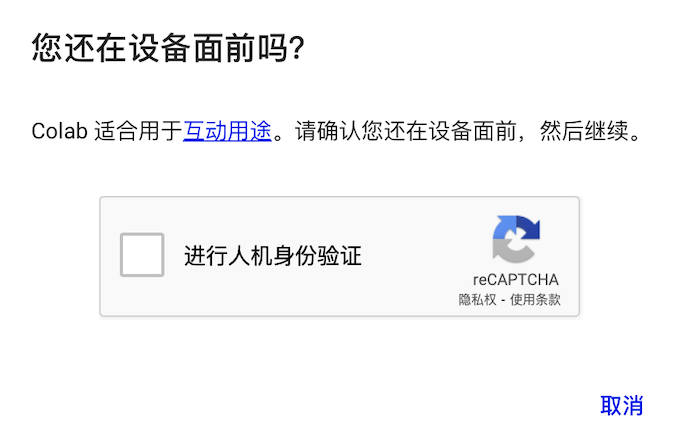
有限的會話數量:每個用戶所能開啟的會話數量都是有限的,免費用戶只能開啟1個會話,Pro用戶則可以開啟多個會話。不同的用戶可以在一個筆記型電腦上可以進行多個會話,但只能有一個程式碼塊開始執行。如果某個程式碼塊已經開始執行,另一個用戶連接到筆記型電腦的會話會顯示「忙碌狀態」,需要等待程式碼塊執行完後才能執行其他的程式碼塊。注意:掉線重連、切換網路、刷新頁面等操作也會使筆記型電腦進入「忙碌狀態」。
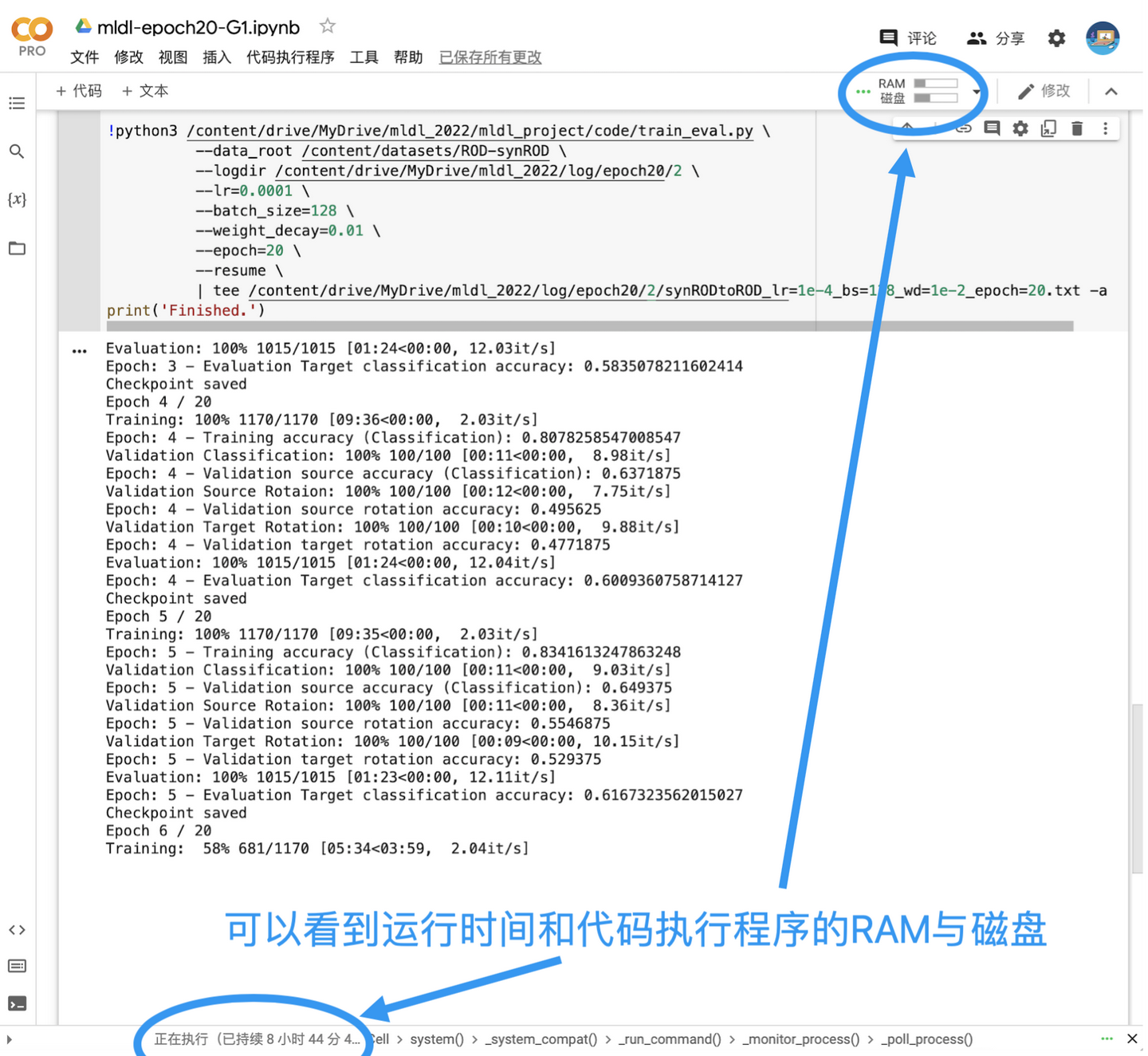
正常情況
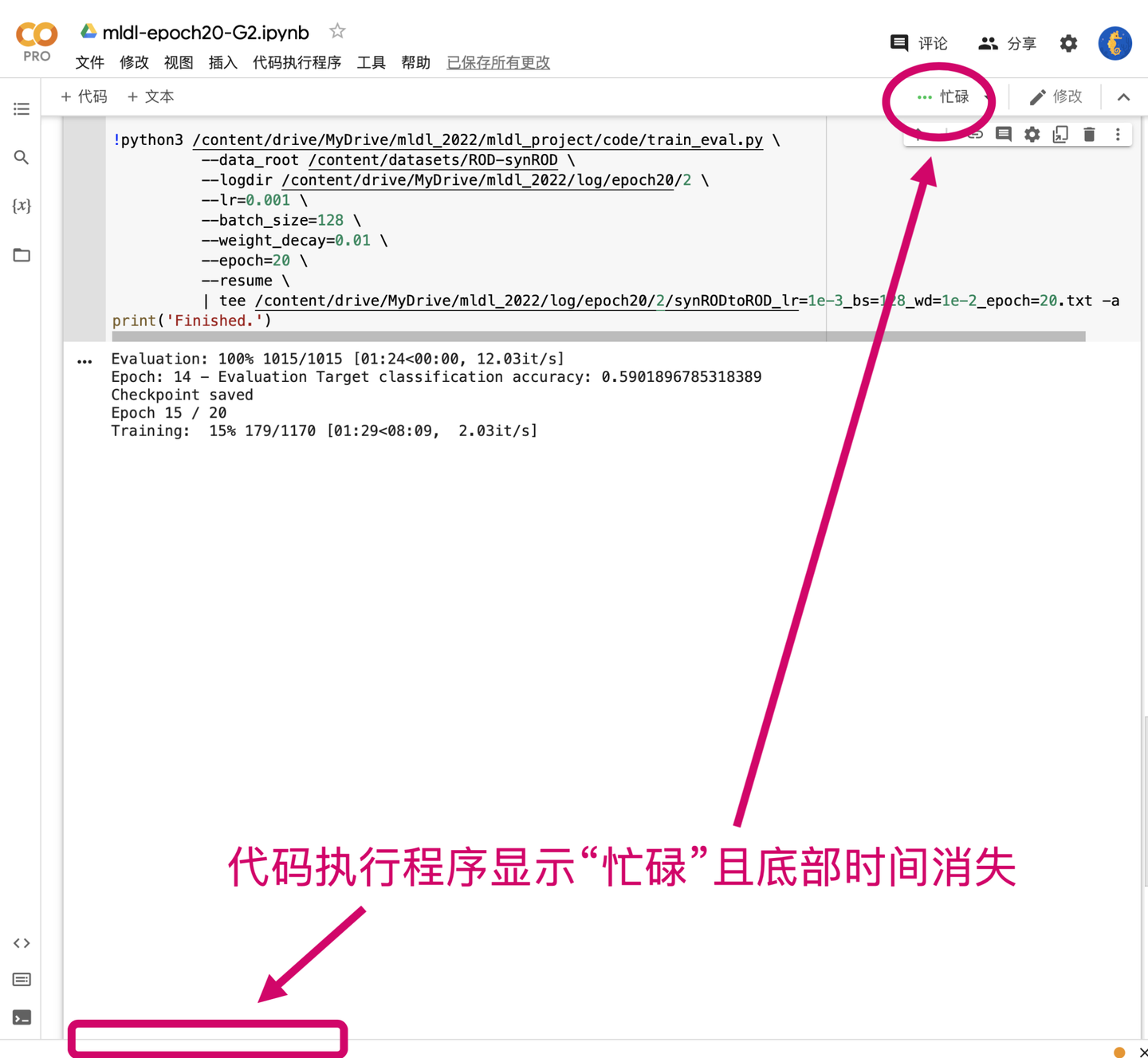
忙碌狀態
如何合理使用資源?
-
將訓練過後的模型日誌和其他重要的文件保存到Google雲盤,而不是本地的實例空間
-
運行的程式碼必須支援「斷點續傳」能力,簡單來說就是必須定義類似checkpoint功能的函數;假設我們一共需要訓練40個epochs,在第30個epoch掉線了之後模型能夠從第30個epoch開始訓練而不是從頭再來
-
僅在模型訓練時開啟GPU模式,在構建模型或其他非必要情況下使用None模式
-
在網路穩定的情況下開始訓練,每隔一段時間查看一下訓練的情況
-
註冊多個免費的Google帳號交替使用
四、Colab項目組織
在正式進入實例演示之前,最後簡單介紹一下在Colab上組織項目的方法
載入數據集
深度學習中,數據集一般由超大量的數據組成,如何在Colab上快速載入數據集?
1. 將整個數據集從本地上傳到實例空間
理論可行但實際不可取。經過作者實測,無論是上傳壓縮包還是文件夾,這種方法都是非常的慢,對於較大的數據集完全不具備可操作性。
2. 將整個數據集上傳到Google硬碟,掛載Google雲盤的之後直接讀取雲盤內的數據集
理論可行但風險較大。根據Google的說明,Colab讀取雲盤的I/O次數也是有限制的,太瑣碎的I/O會導致出現「配額限制」。如果數據集包含大量的子文件夾,也很容易出現掛載錯誤。
3. 將數據集以壓縮包形式上傳到Google雲盤,然後解壓到Colab實例空間
實測可行。掛載雲盤不消耗時間,解壓所需的時間遠遠小於上傳數據集的時間
此外,由於實例空間會定期釋放,因此模型訓練完成後的日誌也應該存放在Google雲盤上。綜上所述,Google雲盤是使用Colab必不可少的一環,由於免費的雲盤只有15個G,因此個人建議至少拓展到基本版。
運行Github項目
Colab的基本運行單位是Jupyter Notebook,如何在一個notebook上運行一個複雜的Github項目呢?
首先創建多個筆記型電腦來對應多個py模組是肯定不行的,因為不同的筆記型電腦會對應不同實例空間,而同一個項目的不同模組應放在同一個實例空間中。為解決這個問題,可以考慮以下幾種方法。
1. 克隆git倉庫到實例空間或雲盤,通過腳本的方式直接執行項目的主程式
# 克隆倉庫到/content/my-repo目錄下 !git clone //github.com/my-github-username/my-git-repo.git %cd my-git-repo !./train.py --logdir /my/log/path --data_root /my/data/root --resume
2. 克隆git倉庫到實例空間或雲盤,把主程式中的程式碼用函數封裝,然後在notebook中調用這些函數
from train import my_training_method my_training_method(arg1, arg2, ...)
由於筆記型電腦默認的路徑是”/content”,因此可能需要修改系統路徑後才能直接導入
import sys sys.path.append('/content/my-git-repo') # 把git倉庫的目錄添加到系統目錄
3. 克隆git倉庫到實例空間或雲盤,把原來的主程式模組直接複製到筆記型電腦中
類似於第二種方法,需要將git倉庫路徑添加到系統路徑,否則會找不到導入的模組
如何處理簡單項目?
如果只有幾個輕量的模組,也不打算使用git進行版本管理,則直接上傳到實例空間即可
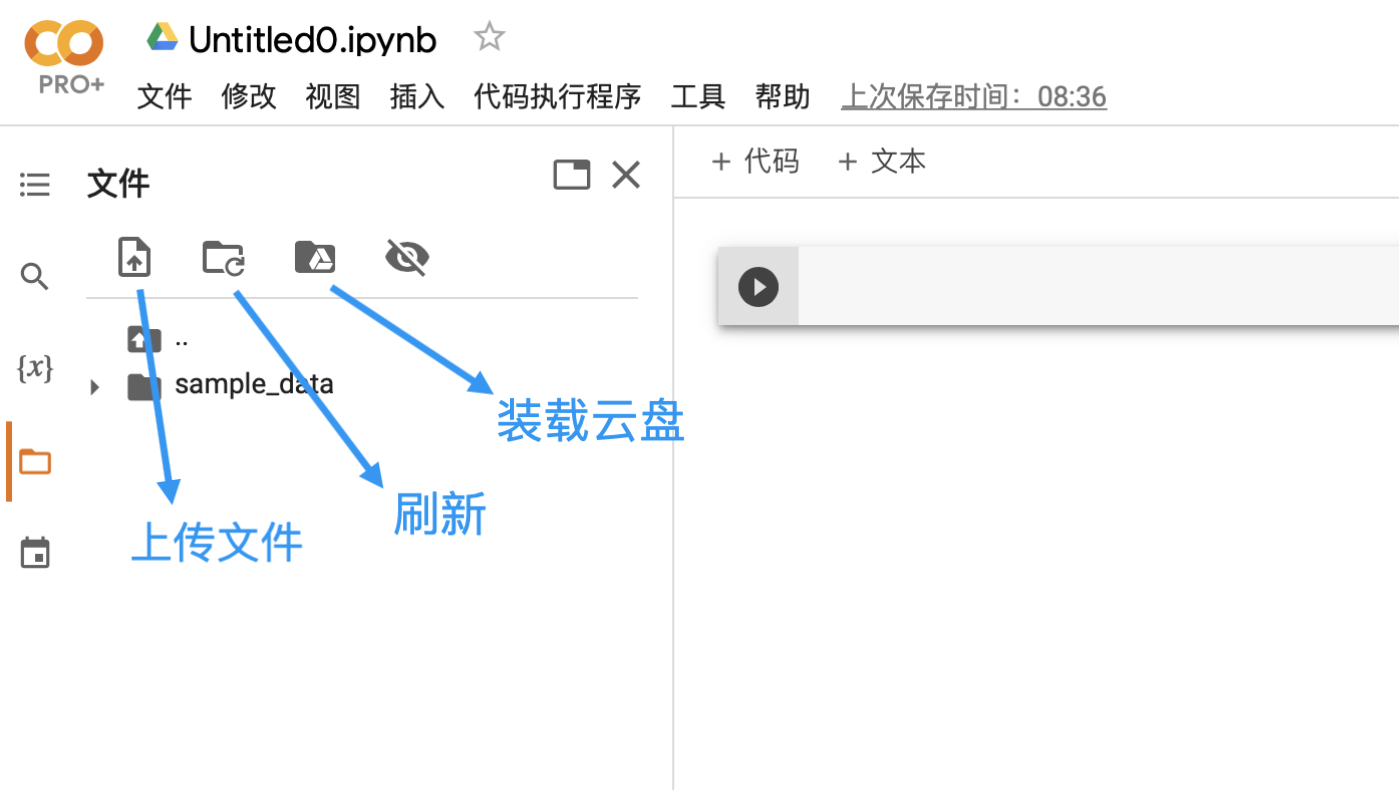
五、實例演示
下面以我在這個學期完成的項目為例,向大家完整展示Colab的使用過程。PS:真不是推銷自己的項目,而是我手上只有這一個項目(~ ̄▽ ̄)~
點擊以後就可以在Google雲盤的「與我共享」看到這個文件夾”zhihu_colab”,將這個文件夾的快捷方式添加到自己的雲盤即可(右鍵文件夾「將快捷方式添加到雲盤」,選擇「我的雲端硬碟」)
文件夾”zhihu_colab”中包含了數據集”ROD-synROD.tar”和程式碼”mldl_project”(以及這部分我寫的notebook)
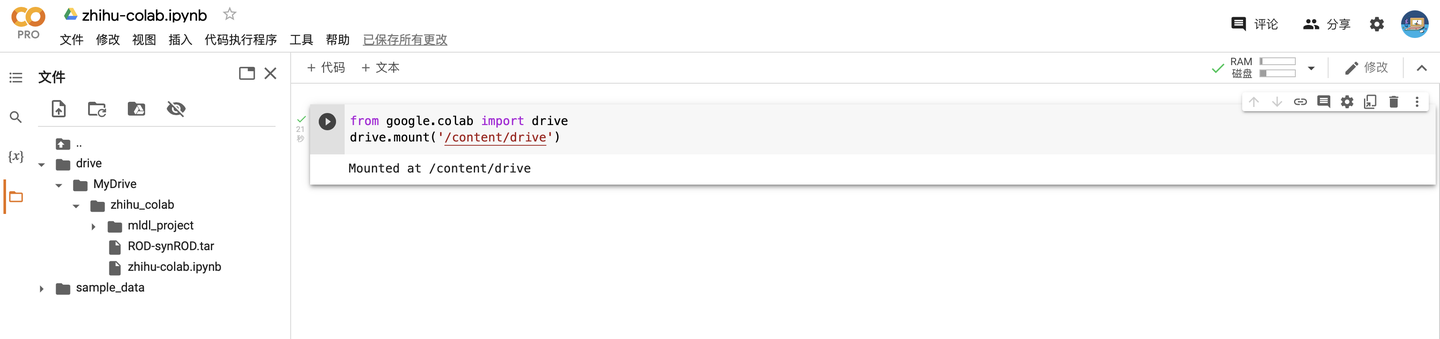
首先載入自己的Google雲盤
from google.colab import drive drive.mount('/content/drive')
載入成功以後(可以點一下刷新按鈕)就可以看到雲盤在實例空間中出現了
Google雲盤默認的載入路徑是“/content/drive/MyDrive”
在當前目錄下(“/content”)創建一個叫datasets的文件夾,並將”zhihu_colab”中的數據集解壓到這個文件夾
!mkdir /content/datasets !tar -xvf "/content/drive/MyDrive/zhihu_colab/ROD-synROD.tar" -C "/content/datasets"
查看一下自己分到的GPU是什麼,具體的資訊很長,只要看中間顯示卡部分就行了。
gpu_info = !nvidia-smi gpu_info = '\n'.join(gpu_info) if gpu_info.find('failed') >= 0: print('Not connected to a GPU') else: print(gpu_info)
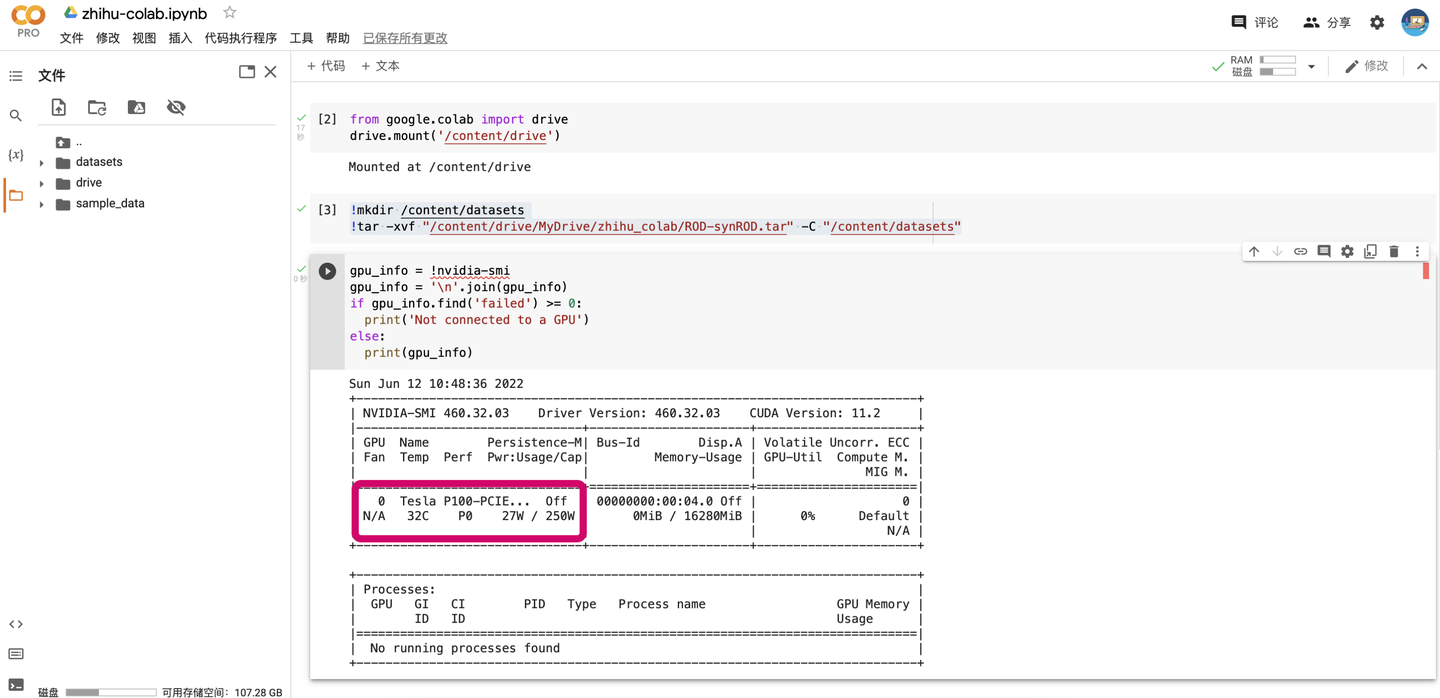
哇哦,我們作為高貴的Pro用戶果然分到了最好的P100🤣。去網上一查這個顯示卡買7000多歐,摺合人民幣好幾萬。
查看一下幫助文檔(主程式是train.py)
!python3 /content/drive/MyDrive/zhihu_colab/mldl_project/code/train_eval.py -h
最後就是訓練模型了(大家不需要理解這個項目在幹什麼,只是給大家做個示範)
!python3 /content/drive/MyDrive/zhihu_colab/mldl_project/code/train_eval.py \ --data_root /content/datasets/ROD-synROD \ --logdir /content/drive/MyDrive/ \ -- resume \ | tee /content/drive/MyDrive/synRODtoROD.txt -a
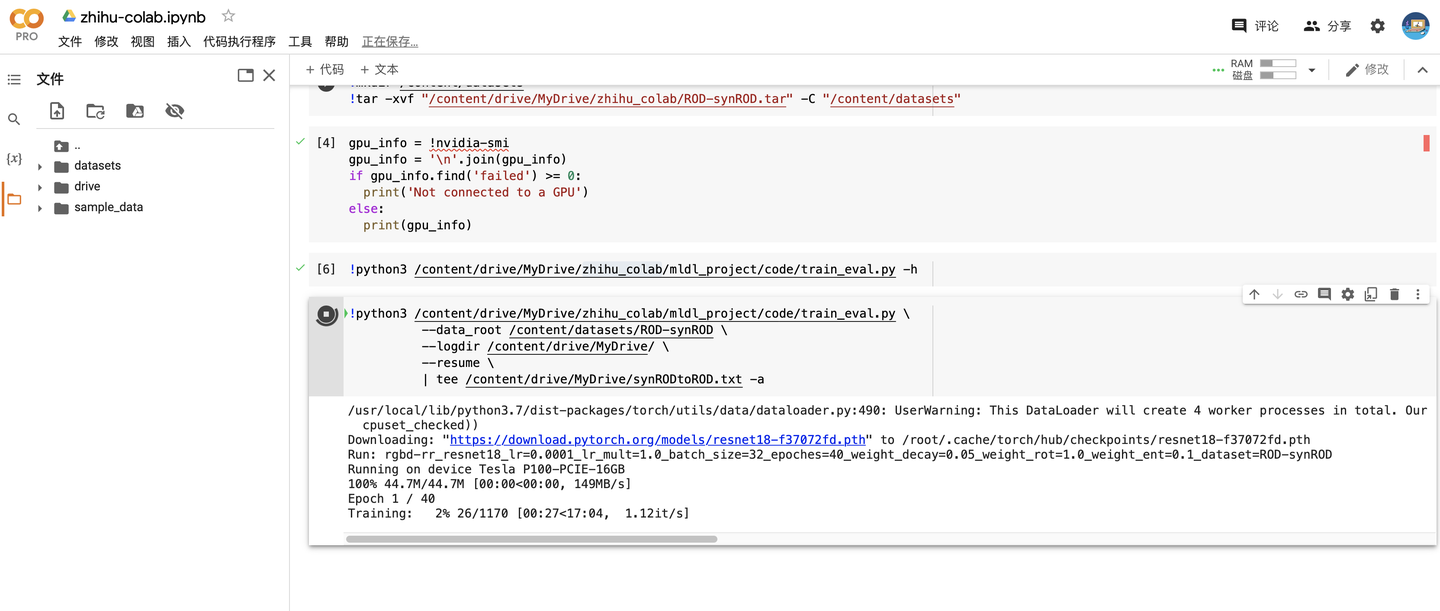
–data_root 用於指定數據集的根目錄
–logdir 用於指定保持模型日誌(checkpoint + tensorboard)的路徑,注意一定要保存到雲盤裡
–resume 表示如果有checkpoint就載入checkpoint
| 是表示流式輸入輸出(前一個命令的輸出作為後一個命令的輸入)
tee 命令用於將輸出保存到文件同時也輸出到螢幕,-a表示add模式(如果文件已存在會添加而不是覆蓋)
可以看到訓練一個epoch大概是17分鐘左右(顯示訓練進度是因為程式碼里用了tqdm模組),如果是高RAM模式的話大概只要一半的時間左右。
這就是在Colab上模型訓練的所有過程了,總的來說還是非常的簡單的,不需要進行任何額外的配置。
六、Colab Pro / Pro+
因為擔心項目完不成,我買了好幾個Colab Pro和Colab Pro+的帳號,在經過了一周的高強度使用後,和大家分享一下使用感受以及聊聊這兩種會員是否值得。
由於Google只給出了不同會員的大致功能區別而沒有給出詳細的區別,我先把我個人測試的結果放在下方供大家參考(三種配置下的標準RAM沒有區別,都是12GB)。
RAM-磁碟
壞了,把所有帳號都升級成PRO以後,現在反而不知道免費版的磁碟大小是多少了🤣
GPU模式下會話數量
高RAM會話的計算速度大致是標準RAM會話的兩倍
使用Pro/Pro+的個人感受
免費版沒有高RAM,且需要頻繁地互動否則會掉線,我用了一會兒就升Pro了,因此個人的體驗不是很多
Pro增加了一個高RAM會話和標準會話,與免費版相當於算力翻了4倍,效率有了飛躍式提升,而且最大連接時長到了24小時,最大閑置時長也增加了不少。
Pro+進一步增了兩個高RAM會話和1個標準會話,與免費版相比算力翻了9倍,與Pro比也翻了2.5倍,此外還多了後台運行功能。但是我有三點需要說明,首先後功能開啟時只能運行兩個筆記型電腦,其次我在後台運行時並沒有持續24小時(我只用過2次後台,因此這一點待測試,也可能只是我網路不好的原因),最後就是25GB的高RAM和52GB的高RAM沒有太大的區別(10分鐘的epoch能快個1-2分鐘)。
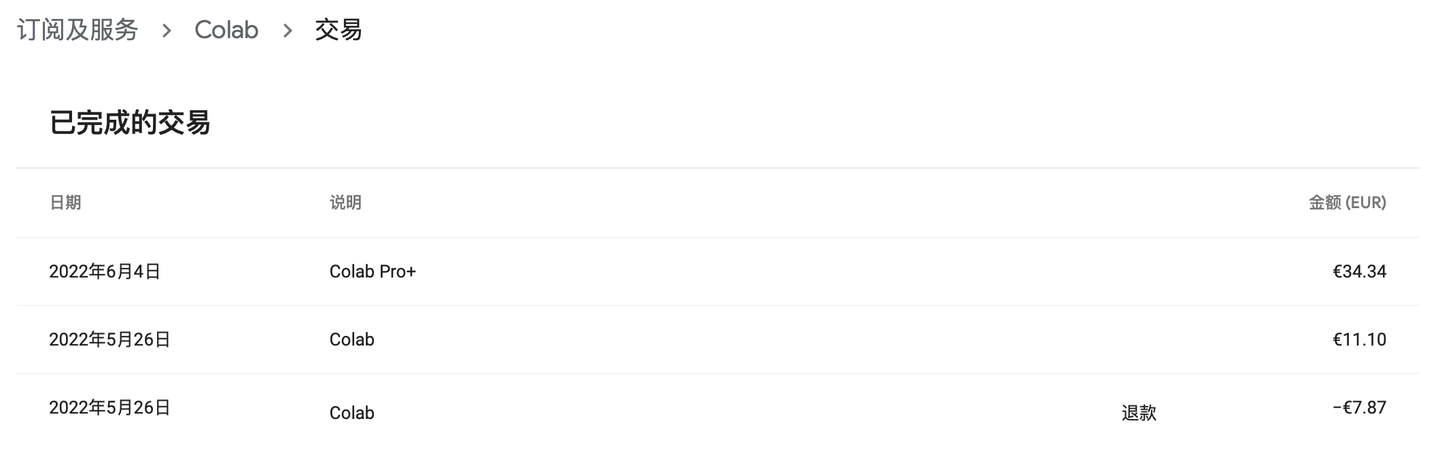
我們把不同套餐的價格也貼出來。

可以看到Pro+比起Pro貴了4倍但是算力卻只提升了2.5倍左右,也就是說如果不怕麻煩,也不依賴後台功能的話多買幾個Pro性價比是高於Pro+的。如果不想在多個帳號間來回切換或者比較喜歡能夠在關閉瀏覽器情況下後台運行的話,Pro+也可以考慮。
最後說幾個支付相關的細節,首先付款的話只要在Google賬戶綁定銀行卡就行,留學生肯定有外國銀行卡比如MasterCard等等就不說了,如果是中國卡的話必須要有Visa才能支付。其次就是如果買了Pro之後再買Pro+,中間的差價會退給你,不用擔心重複購買的問題。
綜上,我個人認為性價比較高的組合是:每月2歐的Google雲盤 + 每月9歐的ColabPro。
七、補充內容
如何讓程式碼有「斷點續傳」的能力?
雖然這個話題超出了本文的範圍,但是由於在Colab訓練模型時程式碼必須要有可恢復性(resumption),因此這裡也簡單提一下。我把教授寫的兩個分別實現保存和載入checkpoint的函數貼在下方,給大家作參考。
def save_checkpoint(path: Text, epoch: int, modules: Union[nn.Module, Sequence[nn.Module]], optimizers: Union[opt.Optimizer, Sequence[opt.Optimizer]], safe_replacement: bool = True): """ Save a checkpoint of the current state of the training, so it can be resumed. This checkpointing function assumes that there are no learning rate schedulers or gradient scalers for automatic mixed precision. :param path: Path for your checkpoint file :param epoch: Current (completed) epoch :param modules: nn.Module containing the model or a list of nn.Module objects :param optimizers: Optimizer or list of optimizers :param safe_replacement: Keep old checkpoint until the new one has been completed :return: """ # This function can be called both as # save_checkpoint('/my/checkpoint/path.pth', my_epoch, my_module, my_opt) # or # save_checkpoint('/my/checkpoint/path.pth', my_epoch, [my_module1, my_module2], [my_opt1, my_opt2]) if isinstance(modules, nn.Module): modules = [modules] if isinstance(optimizers, opt.Optimizer): optimizers = [optimizers] # Data dictionary to be saved data = { 'epoch': epoch, # Current time (UNIX timestamp) 'time': time.time(), # State dict for all the modules 'modules': [m.state_dict() for m in modules], # State dict for all the optimizers 'optimizers': [o.state_dict() for o in optimizers] } # Safe replacement of old checkpoint temp_file = None if os.path.exists(path) and safe_replacement: # There's an old checkpoint. Rename it! temp_file = path + '.old' os.rename(path, temp_file) # Save the new checkpoint with open(path, 'wb') as fp: torch.save(data, fp) # Flush and sync the FS fp.flush() os.fsync(fp.fileno()) # Remove the old checkpoint if temp_file is not None: os.unlink(path + '.old') def load_checkpoint(path: Text, default_epoch: int, modules: Union[nn.Module, Sequence[nn.Module]], optimizers: Union[opt.Optimizer, Sequence[opt.Optimizer]], verbose: bool = True): """ Try to load a checkpoint to resume the training. :param path: Path for your checkpoint file :param default_epoch: Initial value for "epoch" (in case there are not snapshots) :param modules: nn.Module containing the model or a list of nn.Module objects. They are assumed to stay on the same device :param optimizers: Optimizer or list of optimizers :param verbose: Verbose mode :return: Next epoch """ if isinstance(modules, nn.Module): modules = [modules] if isinstance(optimizers, opt.Optimizer): optimizers = [optimizers] # If there's a checkpoint if os.path.exists(path): # Load data data = torch.load(path, map_location=next(modules[0].parameters()).device) # Inform the user that we are loading the checkpoint if verbose: print(f"Loaded checkpoint saved at {datetime.fromtimestamp(data['time']).strftime('%Y-%m-%d %H:%M:%S')}. " f"Resuming from epoch {data['epoch']}") # Load state for all the modules for i, m in enumerate(modules): modules[i].load_state_dict(data['modules'][i]) # Load state for all the optimizers for i, o in enumerate(optimizers): optimizers[i].load_state_dict(data['optimizers'][i]) # Next epoch return data['epoch'] + 1 else: return default_epoch
在主程式train.py正式開始訓練前,添加下面的語句:
if args.resume: # args.resume是命令行輸入的參數,用於指示要不要載入上次訓練的結果 first_epoch = load_checkpoint(checkpoint_path, first_epoch, net_list, optims_list)
在每個epoch訓練結束後,保存checkpoint:
# Save checkpoint save_checkpoint(checkpoint_path, epoch, net_list, optims_list)
net_list是需要保存的網路列表,optims_list是需要保存的優化器列表(這裡沒有記錄scheduler的列表,如果你的程式碼里用到了scheduler那也要保存scheduler的列表)
如果分到了Tesla T4怎麼辦?
開啟了Pro/Pro+會員,大概率會分到最好的顯示卡P100,如果不幸分到了Tesla T4且馬上要進行大量的訓練,那隻能選擇反覆地刷顯示卡。具體方法為斷開運行時然後再連接,反覆直到刷出P100為止。玄學方案是先切到標準RAM刷幾次,刷出P100後切回高RAM。
這個過程可能很無聊,但確是必須的,因為Tesla T4和P100的訓練速度差了1倍多,多花三十分鐘刷一個P100出來可能會節省之後的十幾個小時(實際上要不了三十分鐘,一般五六分鐘就刷出來了)。


