深度學習與CV教程(14) | 影像分割 (FCN,SegNet,U-Net,PSPNet,DeepLab,RefineNet)

- 作者:韓信子@ShowMeAI
- 教程地址://www.showmeai.tech/tutorials/37
- 本文地址://www.showmeai.tech/article-detail/273
- 聲明:版權所有,轉載請聯繫平台與作者並註明出處
- 收藏ShowMeAI查看更多精彩內容

本系列為 斯坦福CS231n 《深度學習與電腦視覺(Deep Learning for Computer Vision)》的全套學習筆記,對應的課程影片可以在 這裡 查看。更多資料獲取方式見文末。
1.影像語義分割定義
影像語義分割是電腦視覺中十分重要的領域,它是指像素級地識別影像,即標註出影像中每個像素所屬的對象類別。下圖為語義分割的一個實例,它清晰地把圖中的騎行人員、自行車和背景對應的像素標註出來了。

影像分割有語義分割和實例分割的差別。語義分割不分離同一類的實例,我們只關心每個像素的類別,如果輸入對象中有兩個相同類別的對象,語義分割不將他們區分為單獨的對象。實例分割是需要對對象個體進行區分的。
2.語義分割常見應用
2.1 自動駕駛汽車
語義分割常見的應用場景之一是自動駕駛領域,我們希望自動駕駛汽車有「環境感知」的能力,以便其可以安全行駛;下圖為自動駕駛過程中實時分割道路場景:

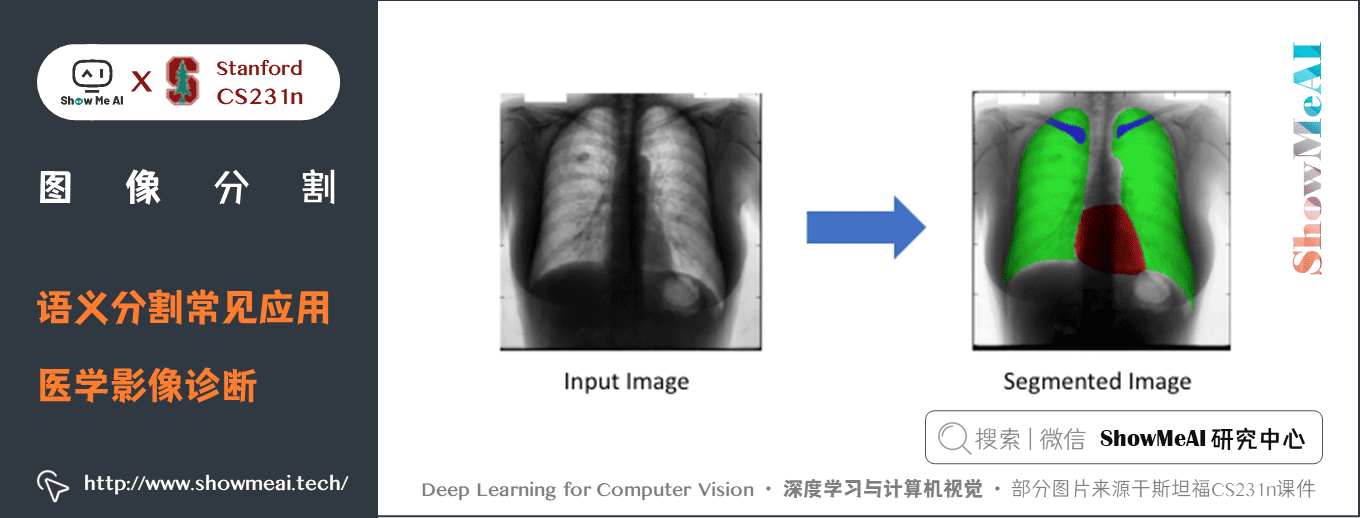
2.2 醫學影像診斷
語義分割的另外一個大應用場景是醫療影像診斷,機器可以智慧地對醫療影像進行分析,降低醫生的工作負擔,大大減少了運行診斷測試所需的時間;下圖是胸部X光片的分割,心臟(紅色),肺部(綠色以及鎖骨(藍色):
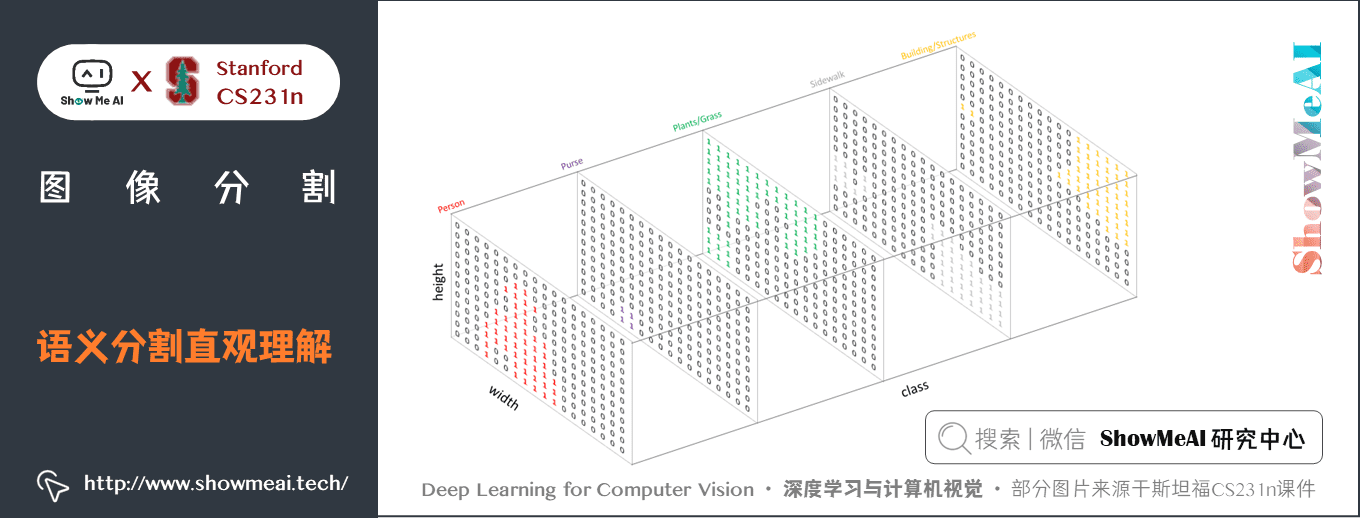
語義分割的目標是:將一張RGB影像(heightwidth3)或是灰度圖(heightwidth1)作為輸入,輸出的是分割圖,其中每一個像素包含了其類別的標籤(heightwidth1)。
下圖為典型示例,為了直觀易懂,示例顯示使用的低解析度的預測圖,但實際上分割圖的解析度應與原始輸入的解析度是一致的。

從上圖可以看到在語義分割任務中,像素級別的標籤設置,我們會使用one-hot編碼對類標籤進行處理。
關於one-hot 編碼的詳細知識也可以參考閱讀ShowMeAI的 機器學習實戰:手把手教你玩轉機器學習系列 中的文章 機器學習實戰 | 機器學習特徵工程最全解讀 里【獨熱向量編碼(one hot encoding) 】板塊內容。
最後,可以通過argmax將每個深度方向像素矢量摺疊成分割圖,將它覆蓋在原圖上,可以區分影像中存在不同類別的區域,方便觀測(也叫mask/掩碼)。

3.語義分割任務評估
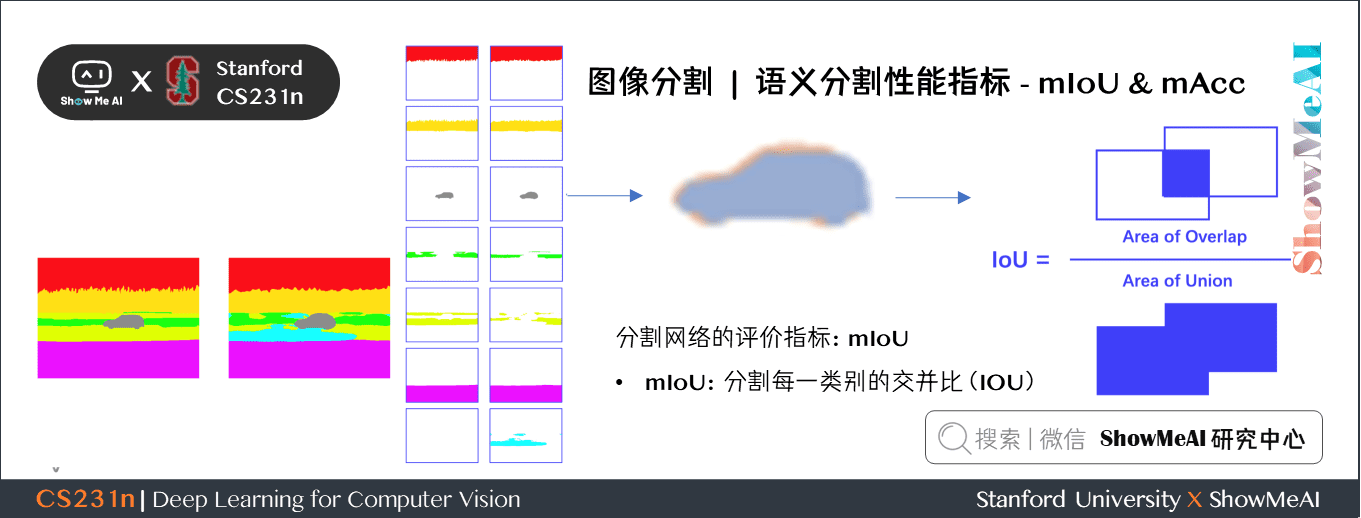
對於語義分割任務,我們會通過 mIoU(mean Intersection-Over-Union) 和 mAcc(mean Accuracy) 指標來進行效果評估。

3.1 mIoU
分割網路的評價指標:mIoU
- mloU:分割每一類別的交並比(IOU)
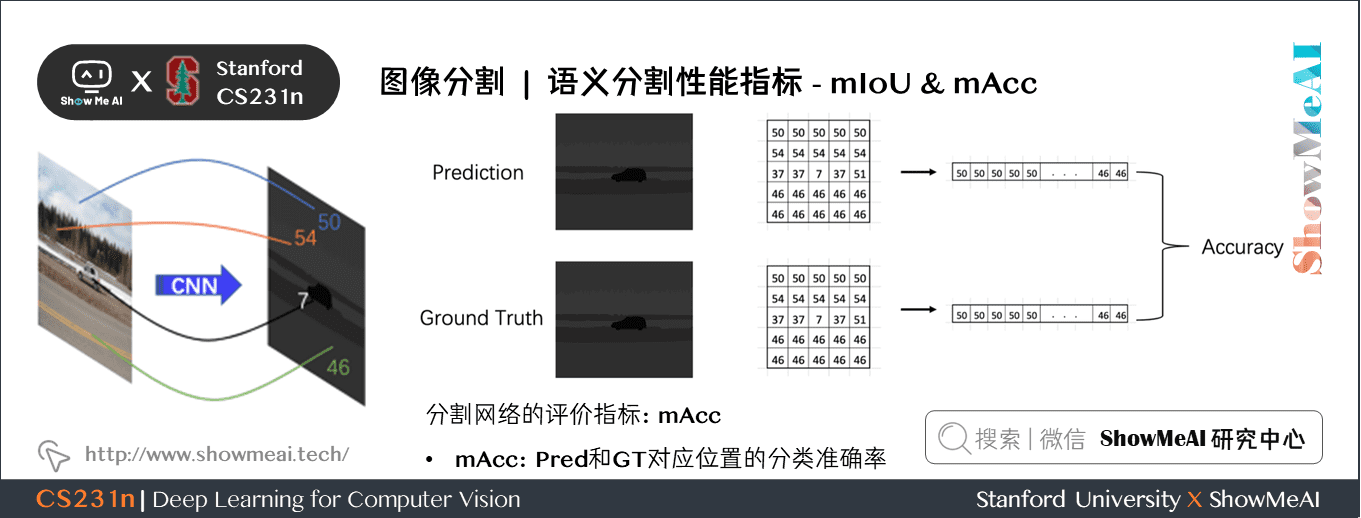
3.2 mAcc
分割網路的評價指標:mAcc
- mAcc:Pred和GT對應位置的分類準確率
4.語義分割方法綜述
早期的一些語義分割方法包括使用 TextonForest 和隨機森林分類器等。卷積神經網路(CNN)的引入不僅僅極大加速影像識別的進程,也對語義分割領域的發展起到巨大的促進作用。
語義分割任務最初流行的深度學習方法是影像塊分類(patch classification),即利用像素周圍的影像塊對每一個像素進行獨立的分類。使用影像塊分類的主要原因是分類網路中包含全連接層(fully connected layer),它需要固定尺寸的影像。
2014 年,加州大學伯克利分校的 Long等人提出全卷積網路(FCN),這使得卷積神經網路無需全連接層即可進行密集的像素預測。使用這種方法可生成任意大小的影像分割圖,且該方法比影像塊分類法要高效許多。之後,語義分割領域幾乎所有先進方法都採用了類似結構。
使用卷積神經網路進行語義分割存在的另一個大問題是池化層。池化層雖然擴大了感受野、聚合語境,但因此造成了位置資訊的丟失。但是,語義分割要求類別圖完全貼合,因此需要保留位置資訊。
有兩種不同結構來解決該問題。
- 第一個是編碼器解碼器結構。編碼器逐漸減少池化層的空間維度,解碼器逐步修復物體的細節和空間維度。編碼器和解碼器之間通常存在快捷連接,因此能幫助解碼器更好地修複目標的細節。U-Net是這種方法中最常用的結構。
- 第二種方法使用空洞/擴張卷積(dilated/atrous convolutions)結構,來去除池化層。
關於全連接層和池化層的詳細知識也可以參考ShowMeAI的文章
4.1 encoder-decoder 結構
針對語義分割任務構建神經網路架構的最簡單的方法是簡單地堆疊多個卷積層(使用same填充以維持維度)並輸出最終的分割圖。
這種結構通過特徵映射的連續變換,直接去學習從輸入影像到其對應分割的映射,缺點是在整個網路中保持全解析度的計算成本非常高。
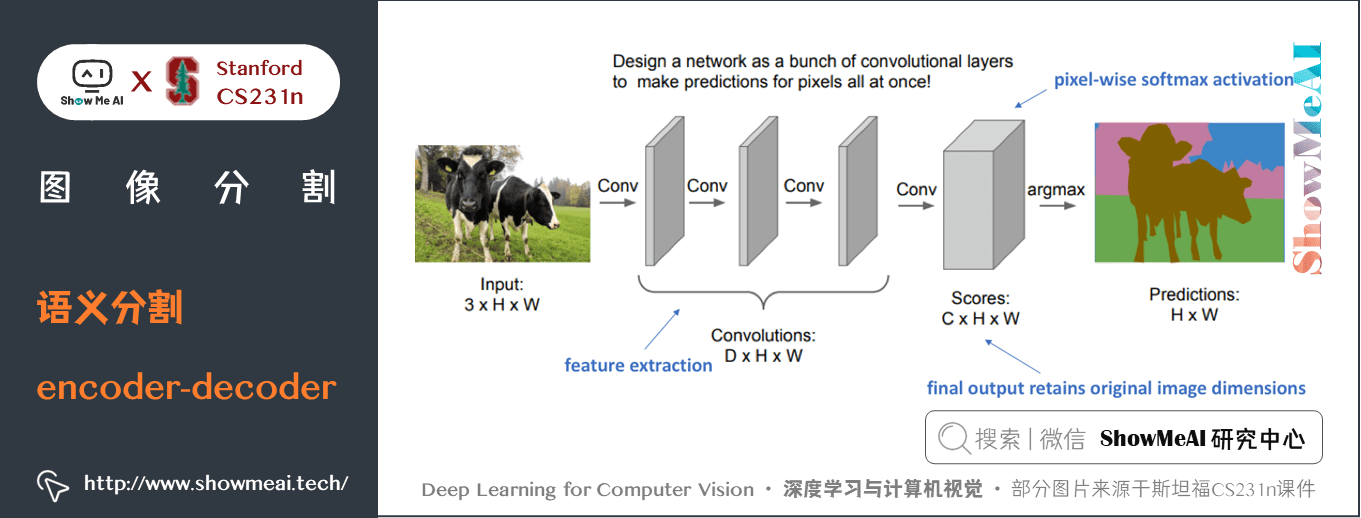
對於深度卷積網路,淺層主要學習低級的資訊,隨著網路越深,學習到更高級的特徵映射。為了保持表達能力,我們通常需要增加特徵圖 feature map 的數量(通道數),從而可以得到更深的網路。
在影像分類任務中,我們只關注影像是什麼(而不是位置在哪),因此CNN的結構中會對特徵圖降取樣(downsampling)或者應用帶步長的卷積(例如,壓縮空間解析度)。但對於影像分割任務而言,我們希望模型產生全解析度語義預測。
影像分割領域現在較為流行的是編碼器解碼器結構,其中我們對輸入的空間解析度進行下取樣,生成解析度較低的特徵映射,它能高效地進行分類,而後使用上取樣將特徵還原為全解析度分割圖。
4.2 上取樣方法
我們有許多方法可以對特徵圖進行上取樣。
「池化」操作通過對將小區域的值取成單一值(例如平均或最大池化)進行下取樣,對應的「上池化」操作就是將單一值分配到更高的解析度進行上取樣。
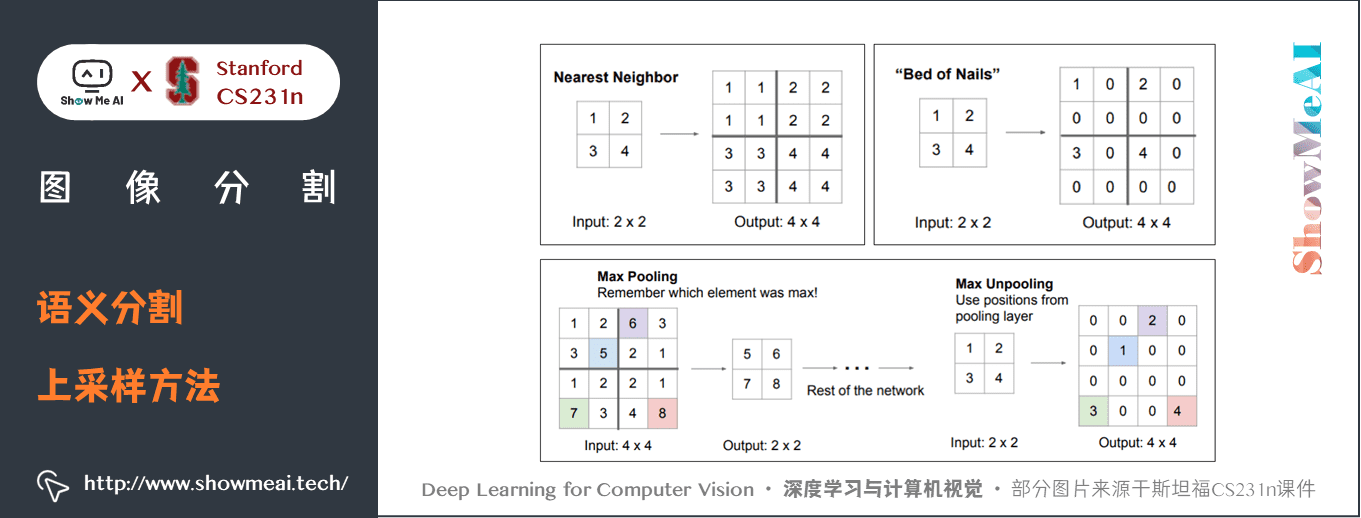
轉置卷積(Transpose Convolution,有時也翻譯為「反卷積」)是迄今為止最流行的上取樣方法,這種結構允許我們在上取樣的過程中進行參數學習。
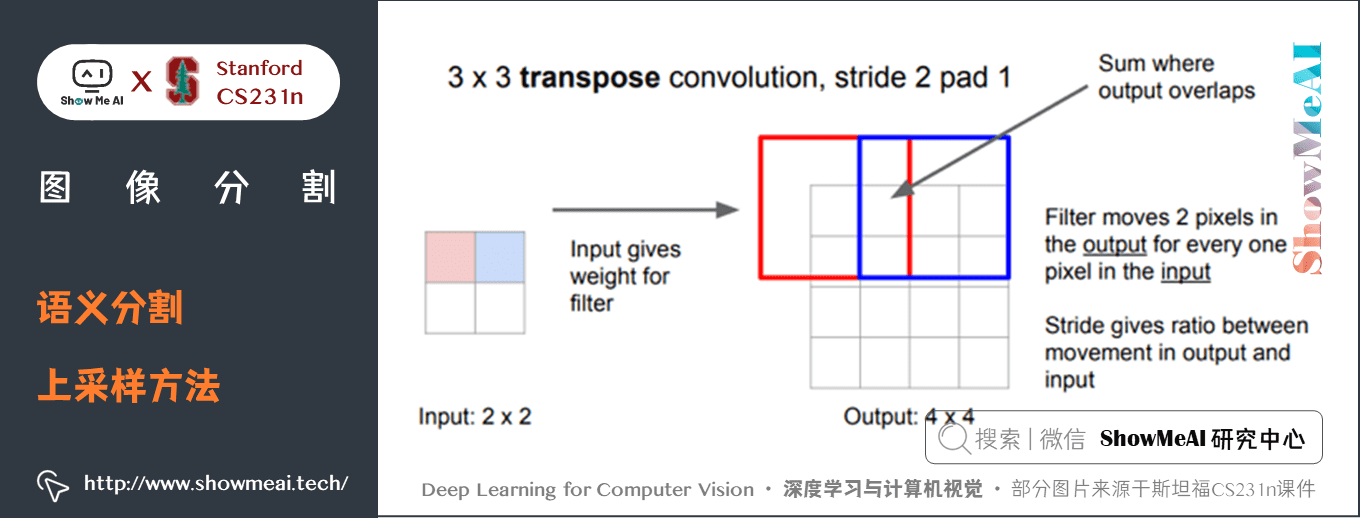
典型的「卷積」運算將採用濾波器視圖中當前值的點積並為相應的輸出位置產生單個值,而「轉置卷積」基本是相反的過程:我們從低解析度特徵圖中獲取單個值,並將濾波器中的所有權重乘以該值,將這些加權值投影到輸出要素圖中。
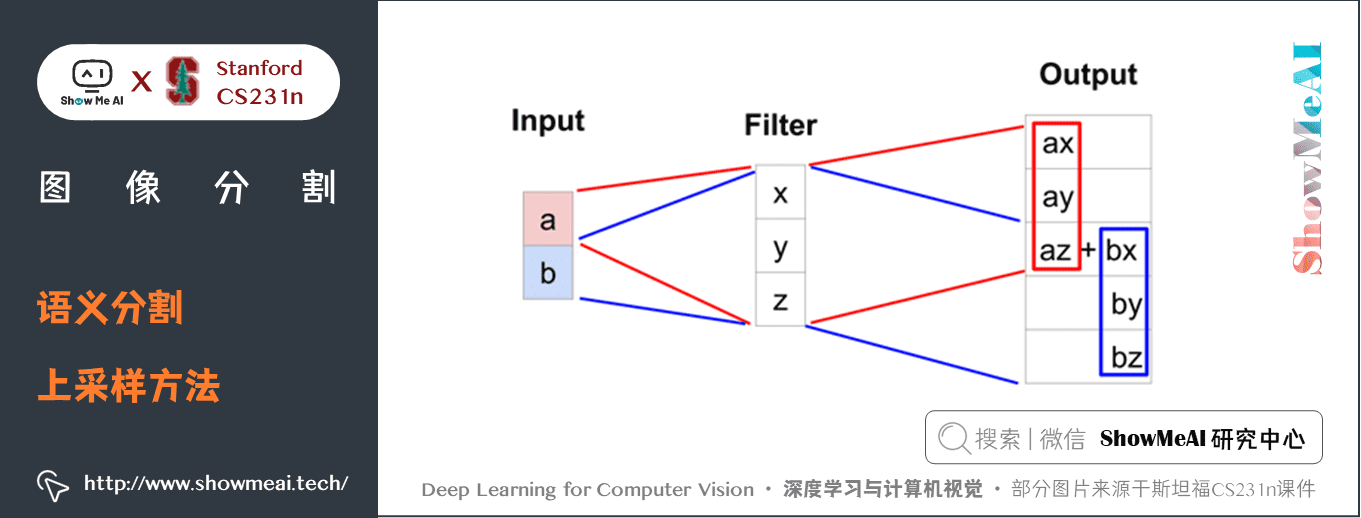
某些大小的濾波器會在輸出特徵映射中產生重疊(例如,具有步幅 \(2\) 的 \(3 \times 3\) 濾波器 – 如下面的示例所示),如果只是簡單將重疊值加起來,往往會在輸出中產生棋盤格子狀的偽影(artifact)。

這並不是我們需要的,因此最好確保您的濾波器大小不會產生重疊。
下面我們對主流的模型進行介紹,包括FCN、SegNet、U-Net、PSPNet、DeepLab V1~V3等。
5.典型語義分割演算法
5.1 FCN全卷積網路
全卷積網路FCN在會議CVPR 2015的論文 Fully Convolutional Networks for Semantic Segmentation 中提出。
它將CNN分類網路(AlexNet, VGG 和 GoogLeNet)修改為全卷積網路,通過對分割任務進行微調,將它們學習的表徵轉移到網路中。然後,定義了一種新的架構,它將深的、粗糙的網路層的語義資訊和淺的、精細的網路層的表層資訊結合起來,來生成精確和詳細的分割。
關於CNN的詳細結構,以及卷積層和全連接層的變換等基礎知識可以閱讀ShowMeAI文章
全卷積網路在 PASCAL VOC(2012年的數據,相對之前的方法提升了 \(20\%\) ,達到 \(62.2\%\) 的平均IoU),NYUDv2 和 SIFT Flow 上實現了最優的分割結果,對於一個典型的影像,推斷只需要 \(1/3\) 秒的時間。
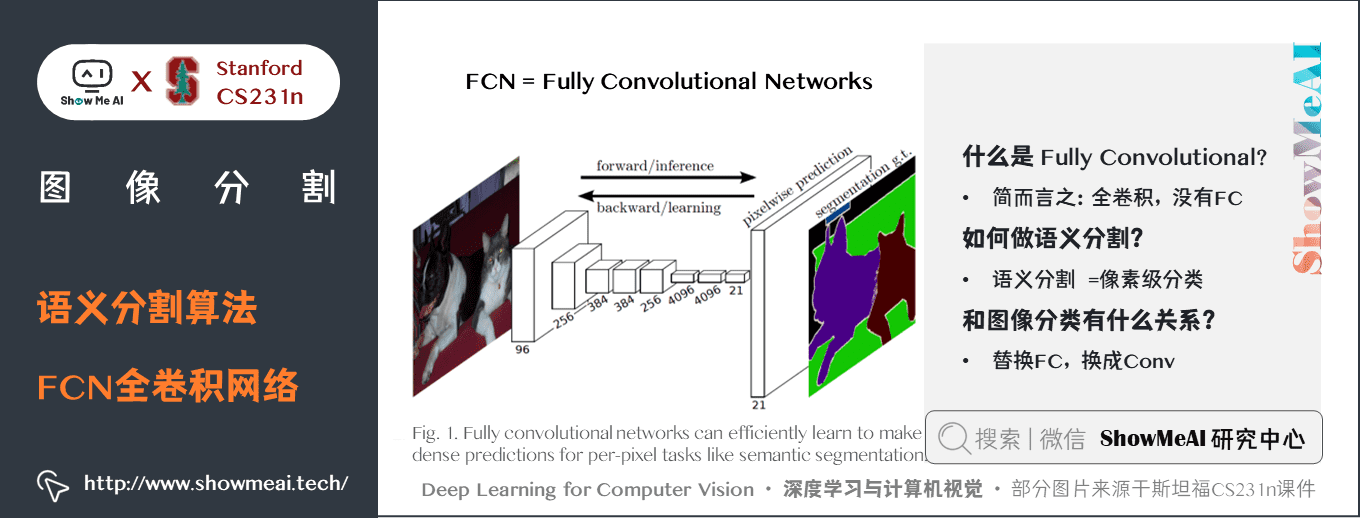
FCN的網路結構如下所示,典型的編碼器解碼器結構:
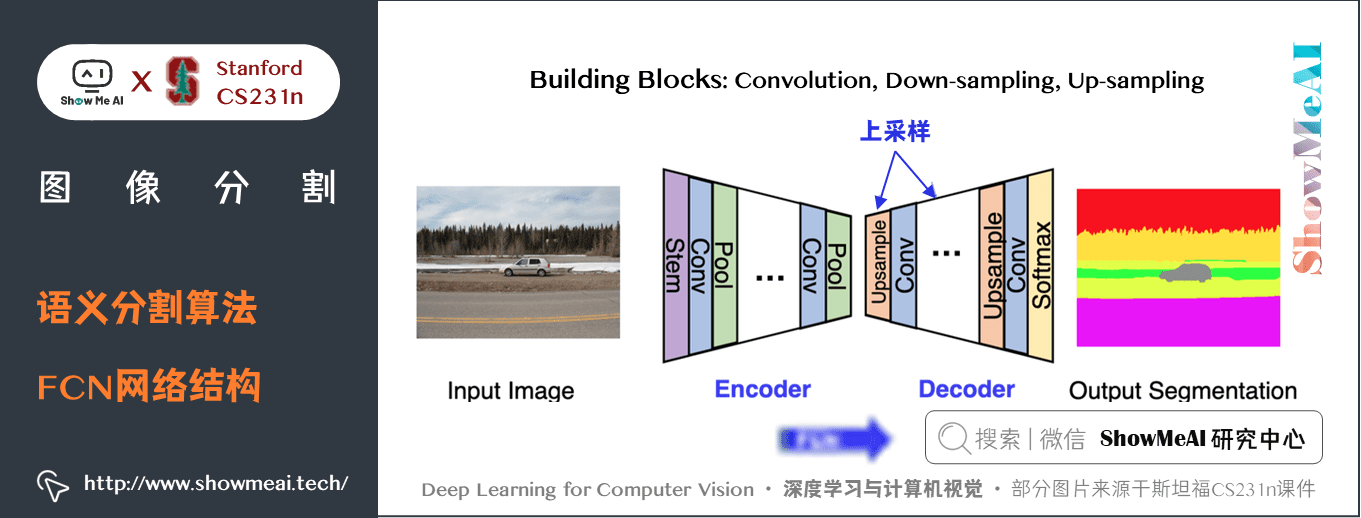
我們來看看FCN的中間層的一些數字,如下:

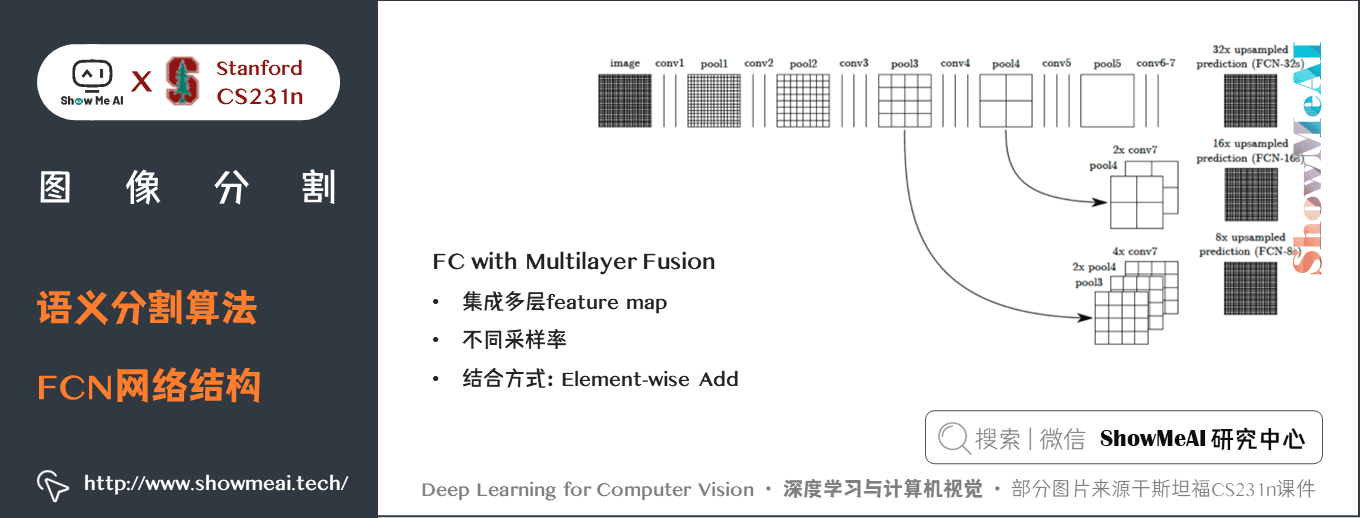
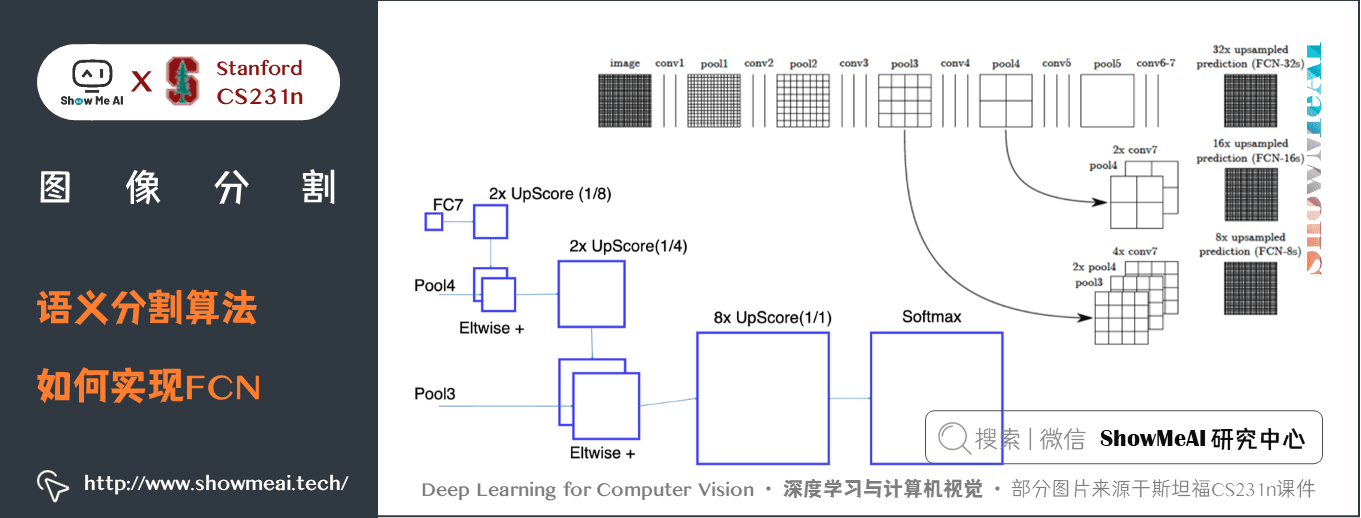
關鍵特點:
- FCN的特徵由編碼器中的不同階段合併而成的,它們在語義資訊的粗糙程度上有所不同。- 低解析度語義特徵圖的上取樣使用經雙線性插值濾波器初始化的「反卷積」操作完成。- 從 VGG16、Alexnet 等分類器網路進行知識遷移來實現語義細分。
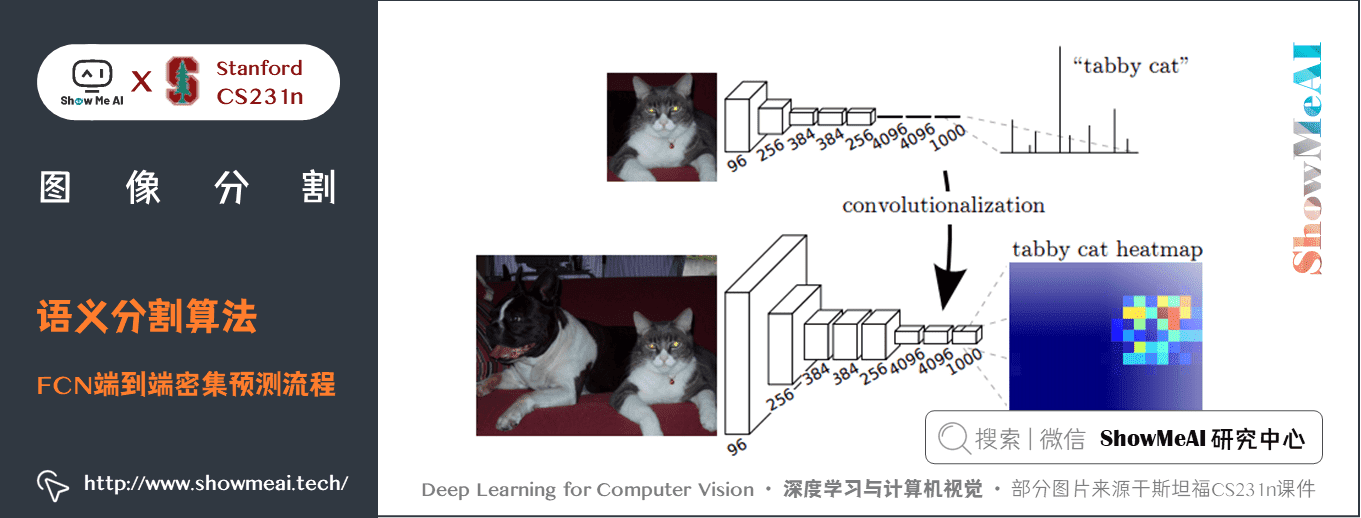
如上圖所示,預訓練模型 VGG16 的全連接層(fc6,fc7)被轉換為全卷積層,通過它生成了低解析度的類的熱圖,然後使用經雙線性插值初始化的反卷積,並在上取樣的每一個階段通過融合(簡單地相加) VGG16 中的低層(conv4和conv3)的更加粗糙但是解析度更高的特徵圖進一步細化特徵。
在傳統的分類 CNNs 中,池化操作用來增加視野,同時減少特徵圖的解析度。對分類任務來說非常有效,分類模型關注影像總體類別,而對其空間位置並不關心。所以才會有頻繁的卷積層之後接池化層的結構,保證能提取更多抽象、突出類的特徵。
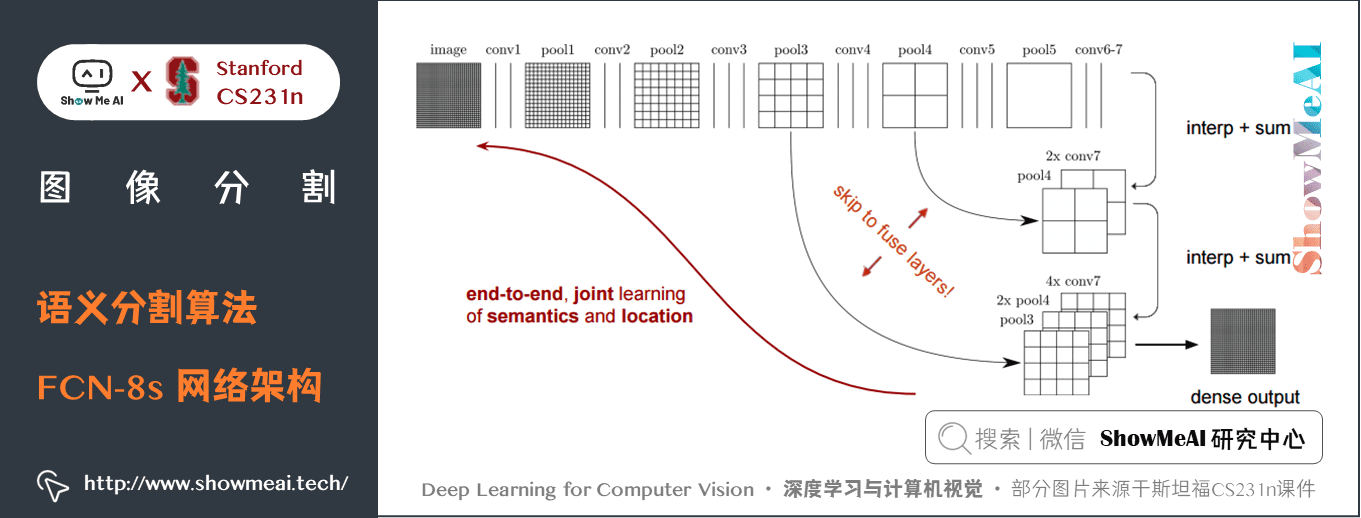
另一方面,池化和帶步長的卷積對語義分割是不利的,這些操作會帶來空間資訊的丟失。不同的語義分割模型在解碼器中使用了不同機制,但目的都在於恢復在編碼器中降低解析度時丟失的資訊。如上圖所示,FCN-8s 融合了不同粗糙度(conv3、conv4和fc7)的特徵,利用編碼器不同階段不同解析度的空間資訊來細化分割結果。
下圖為訓練 FCNs 時卷積層的梯度:
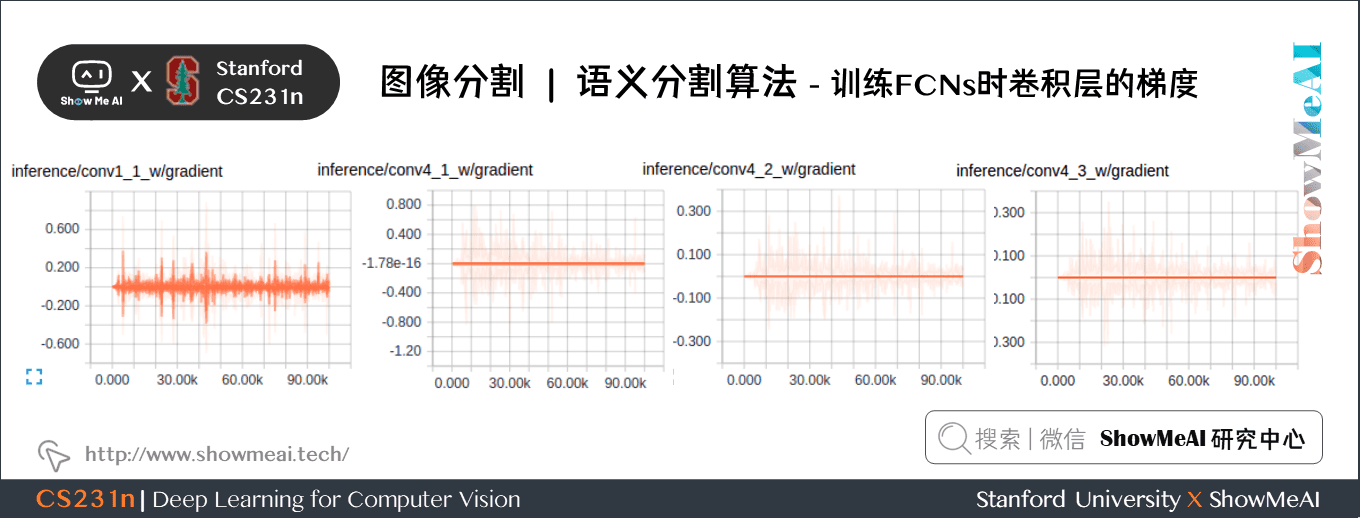
第1個卷積層捕捉低層次的幾何資訊,我們注意到梯度調整了第一層的權重,以便其能適應數據集。
VGG 中更深層的卷積層有非常小的梯度流,因為這裡捕獲的高層次的語義概念足夠用於分割。
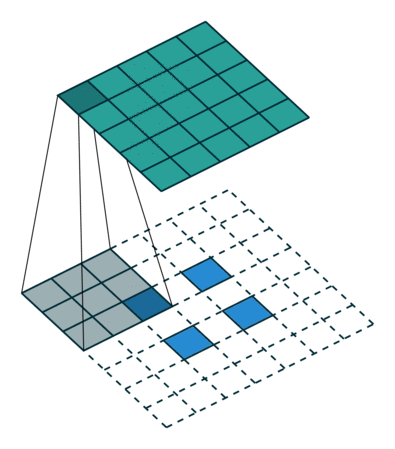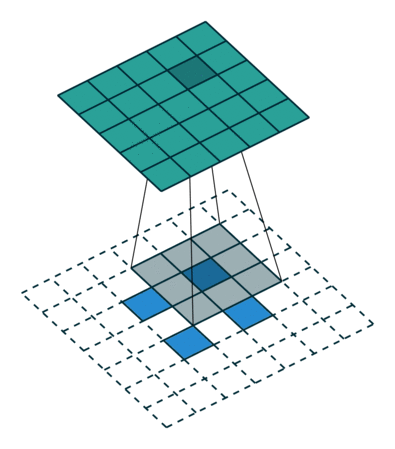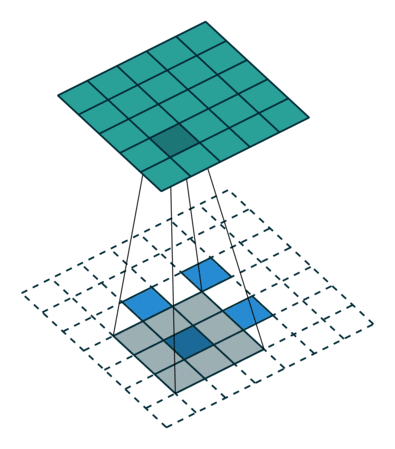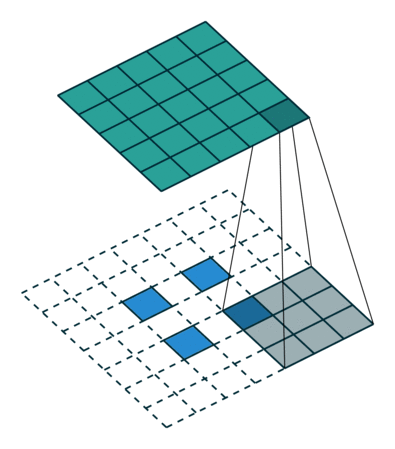
語義分割架構的另一個重要點是,對特徵圖使用「反卷積」(如上動圖所示),將低解析度分割圖上取樣至輸入影像解析度,或者花費大量計算成本,使用空洞卷積在編碼器上部分避免解析度下降。即使在現代 GPUs 上,空洞卷積的計算成本也很高。
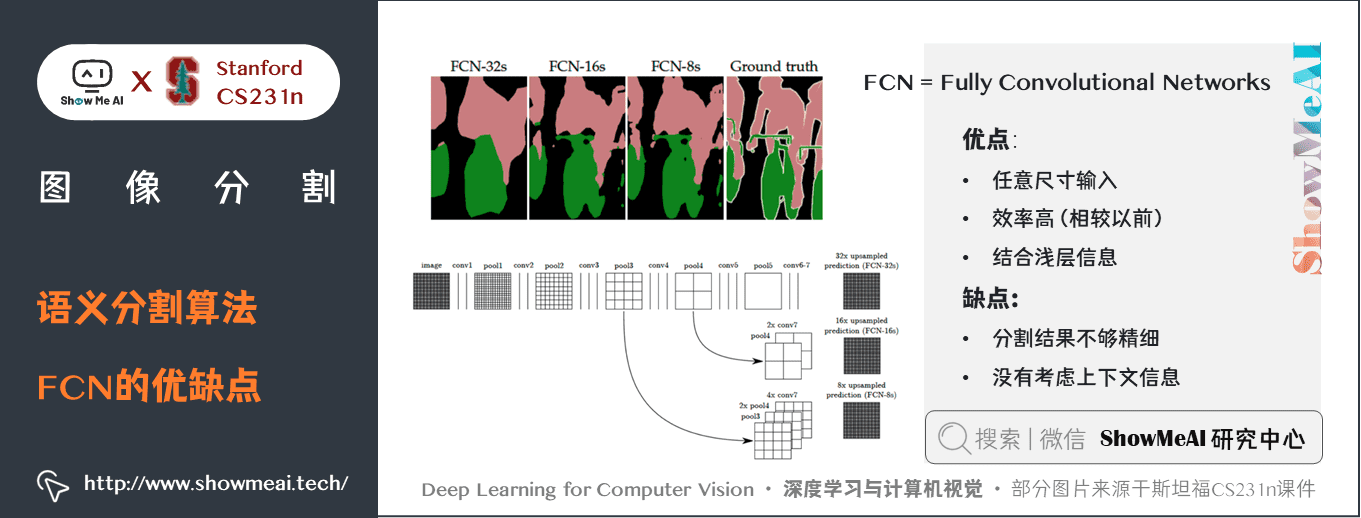
最後,我們來看看FCN的優缺點:
5.2 SegNet
SegNet在2015的論文 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation 中提出。
SegNet 的新穎之處在於解碼器對其較低解析度的輸入特徵圖進行上取樣的方式。
- 解碼器使用了在相應編碼器的最大池化步驟中計算的池化索引來執行非線性上取樣。
這種方法消除了學習上取樣的需要。經上取樣後的特徵圖是稀疏的,因此隨後使用可訓練的卷積核進行卷積操作,生成密集的特徵圖。
SegNet與FCN等語義分割網路比較,結果揭示了在實現良好的分割性能時所涉及的記憶體與精度之間的權衡。
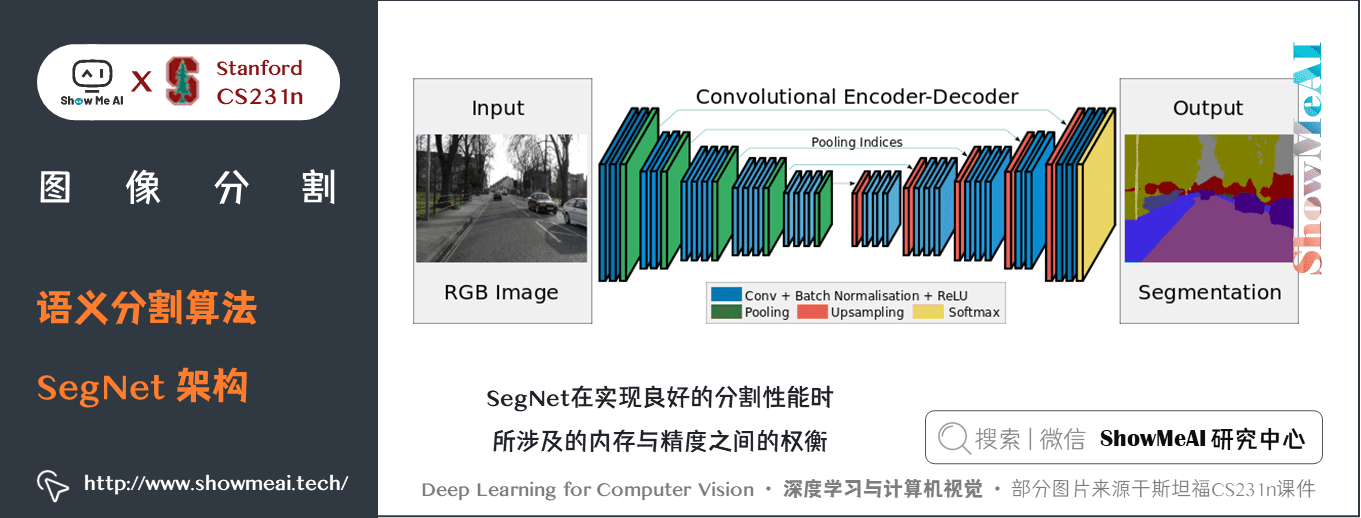
關鍵特點:
- SegNet 在解碼器中使用「反池化」對特徵圖進行上取樣,並在分割中保持高頻細節的完整性。- 編碼器捨棄掉了全連接層(和 FCN 一樣進行卷積),因此是擁有較少參數的輕量級網路。
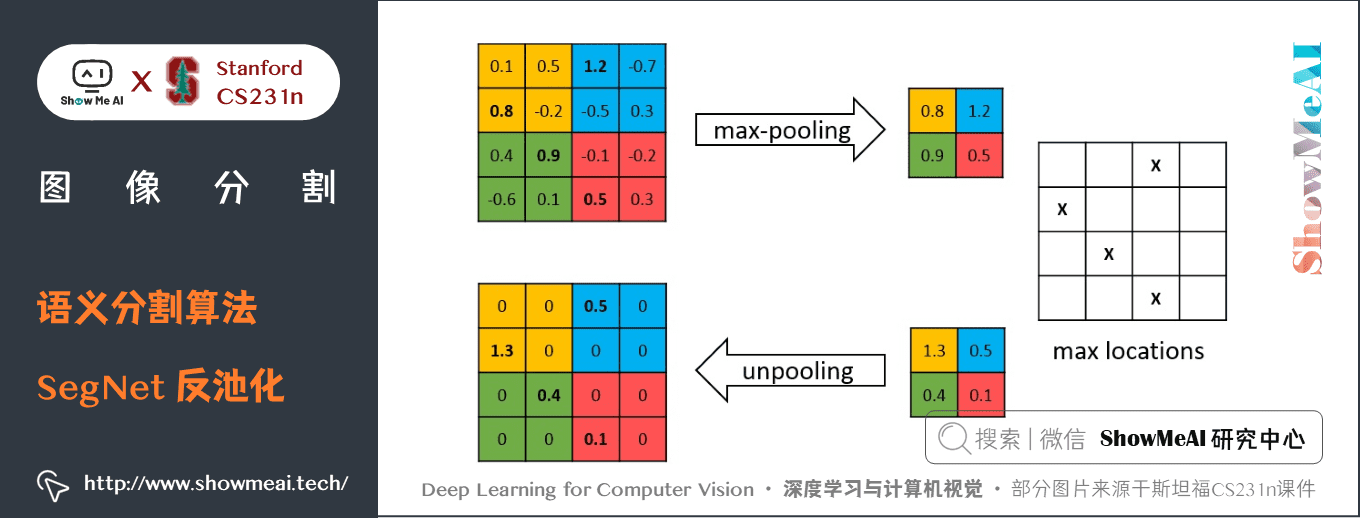
如上圖所示,編碼器中的每一個最大池化層的索引都被存儲起來,用於之後在解碼器中使用那些存儲的索引來對相應的特徵圖進行反池化操作。雖然這有助於保持高頻資訊的完整性,但當對低解析度的特徵圖進行反池化時,它也會忽略鄰近的資訊。
5.3 U-Net
SegNet在2015的論文 U-Net: Convolutional Networks for Biomedical Image Segmentation 中提出。
U-Net 架構包括一個「捕獲上下文資訊的收縮路徑」和一個「支援精確本地化的對稱擴展路徑」。這樣一個網路可以使用非常少的影像進行端到端的訓練,它在ISBI神經元結構分割挑戰賽中取得了比之前方法都更好的結果。
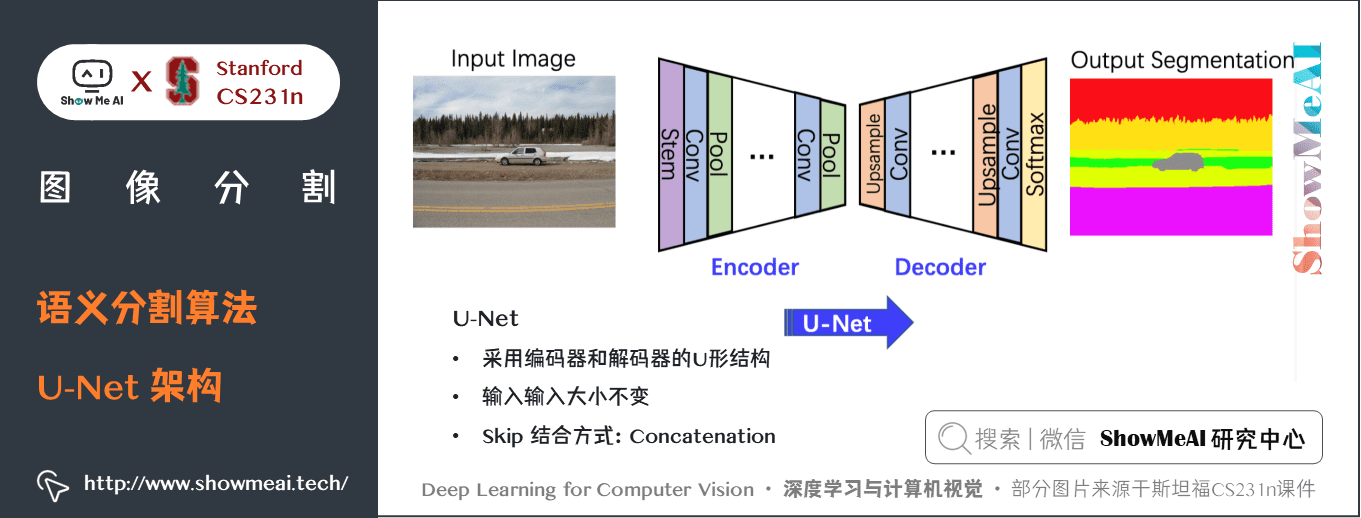
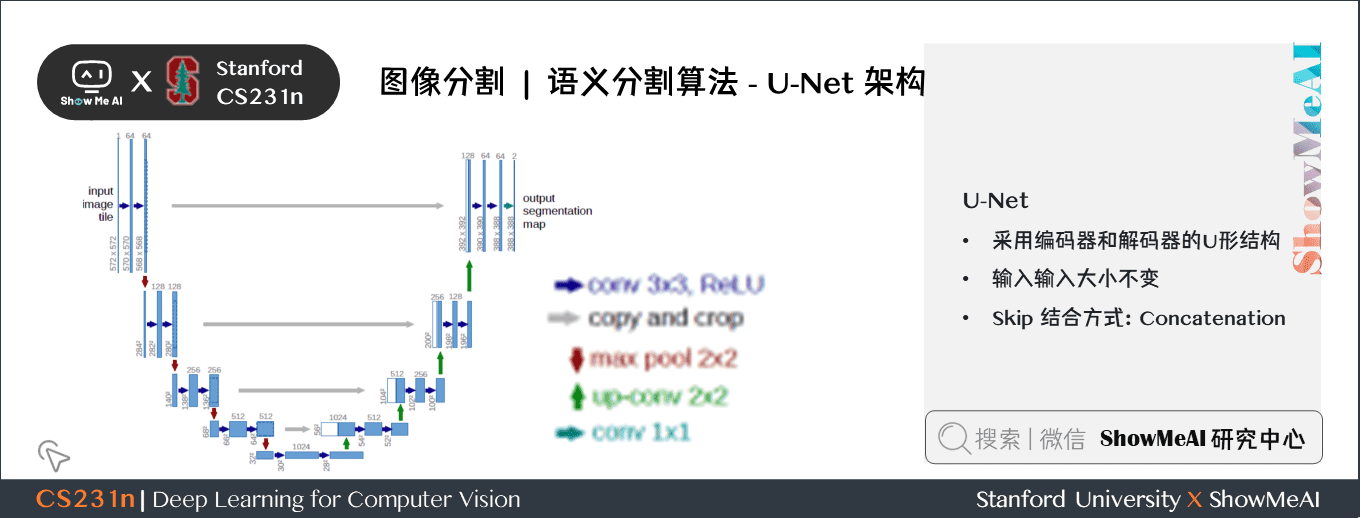
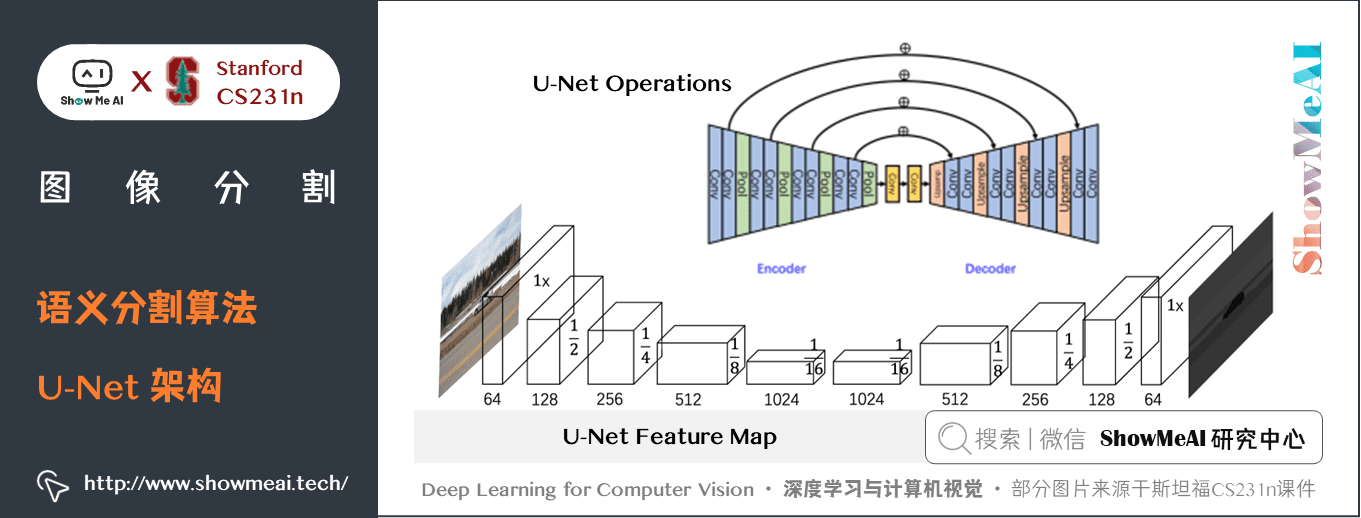
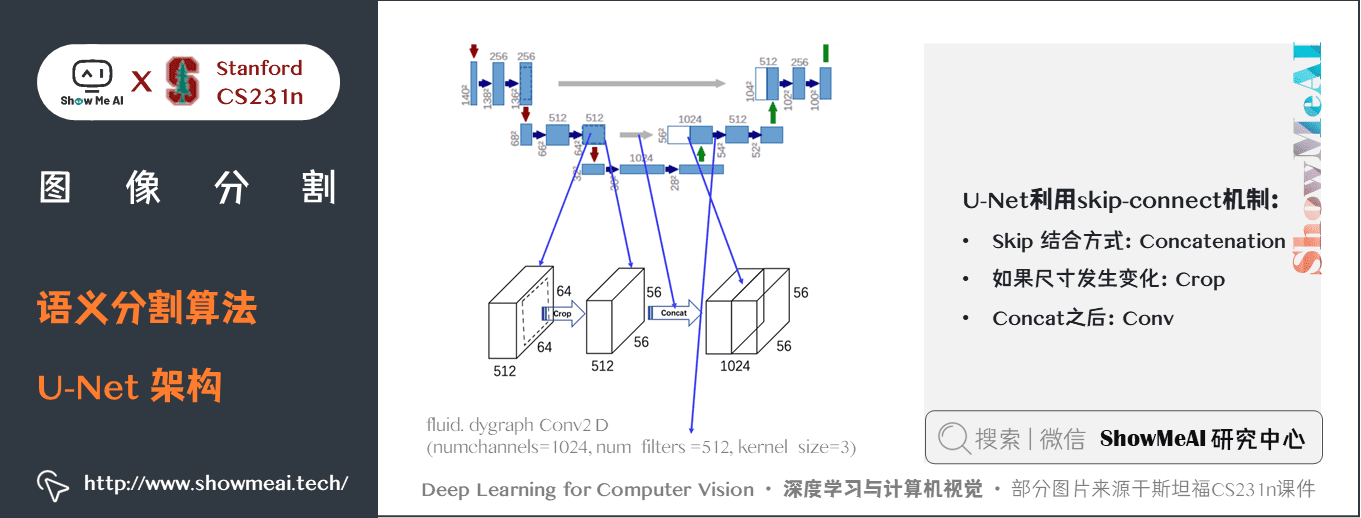
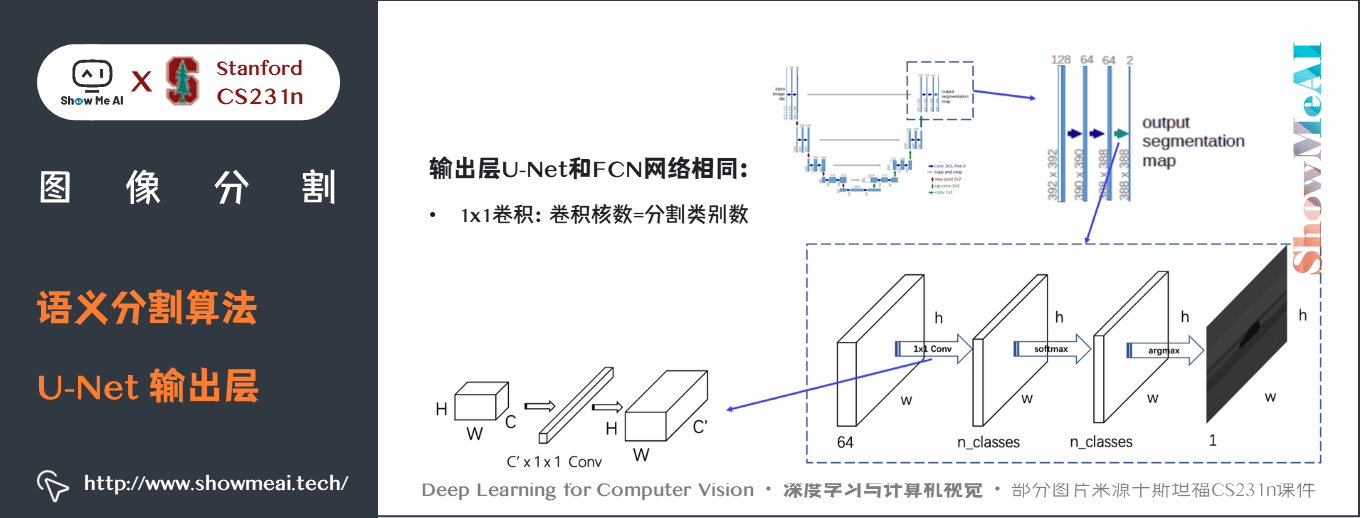
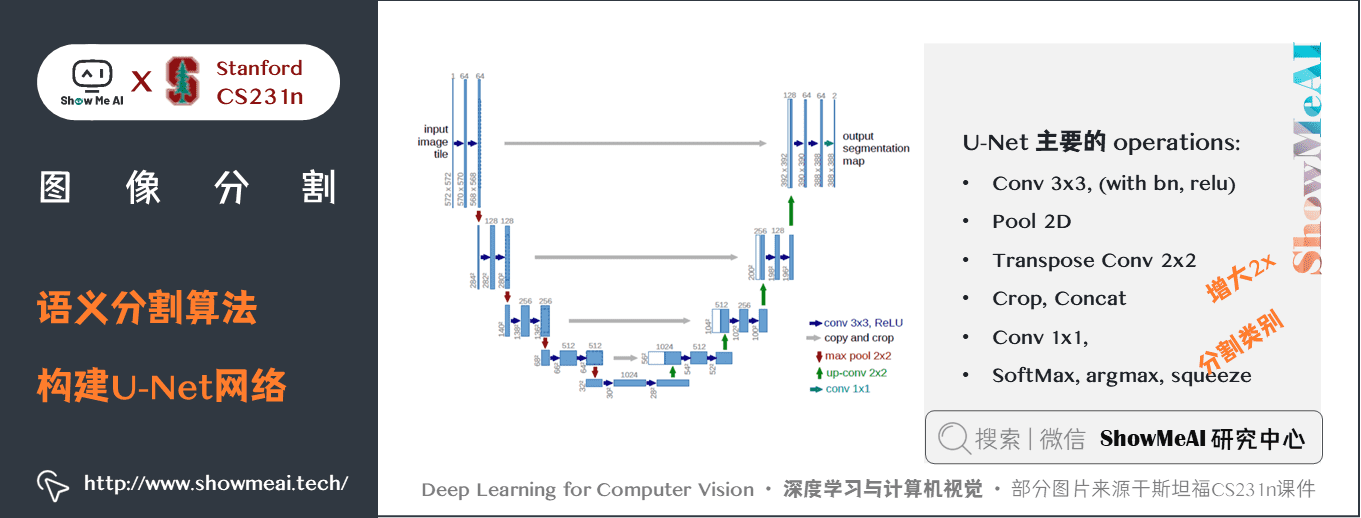
關鍵特點:
- U-Net 簡單地將編碼器的特徵圖拼接至每個階段解碼器的上取樣特徵圖,從而形成一個梯形結構。該網路非常類似於 Ladder Network 類型的架構。- 通過跳躍
拼接連接的架構,在每個階段都允許解碼器學習在編碼器池化中丟失的相關特徵。- 上取樣採用轉置卷積。
U-Net 在 EM 數據集上取得了最優異的結果,該數據集只有30個密集標註的醫學影像和其他醫學影像數據集,U-Net 後來擴展到3D版的 3D-U-Net。雖然 U-Net 最初的發表在於其在生物醫學領域的分割、網路的實用性以及從非常少的數據中學習的能力,但現在已經成功應用其他幾個領域,例如 衛星影像分割等。
5.4 DeepLab V1
DeepLab V1在2015的論文 Semantic Image Segmentation with deep convolutional nets and fully connected CRFs 中提出。
DeepLab V1結合 DCNN 和概率圖模型來解決語義分割問題。DCNN 最後一層的響應不足以精確定位目標邊界,這是 DCNN 的不變性導致的。DeepLab V1的解決方法是:在最後一層網路後結合全連接條件隨機場。DeepLab V1在 PASCAL VOC 2012 上達到了 71.6% 的 mIoU。

關鍵特點:
- 提出 空洞卷積(atrous convolution)(又稱擴張卷積(dilated convolution)) 。- 在最後兩個最大池化操作中不降低特徵圖的解析度,並在倒數第二個最大池化之後的卷積中使用空洞卷積。- 使用 CRF(條件隨機場) 作為後處理,恢復邊界細節,達到準確定位效果。- 附加輸入影像和前四個最大池化層的每個輸出到一個兩層卷積,然後拼接到主網路的最後一層,達到 多尺度預測 效果。
5.5 DeepLab V2
DeepLab V2 在2017的論文 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs 中提出。
DeepLab V2 提出了一種空洞空間金字塔池化(ASPP)的多尺度魯棒分割方法。
ASPP 使用多個取樣率的過濾器和有效的視野探測傳入的卷積特徵層,從而在多個尺度上捕獲目標和影像上下文。再結合 DCNNs 方法和概率圖形模型,改進了目標邊界的定位。
DCNNs 中常用的最大池化和下取樣的組合實現了不變性,但對定位精度有一定的影響。DeepLab V2通過將 DCNN 最後一層的響應與一個全連接條件隨機場(CRF)相結合來克服這個問題。DeepLab V2 在 PASCAL VOC 2012 上得到了 \(79.7\%\) 的 mIoU。
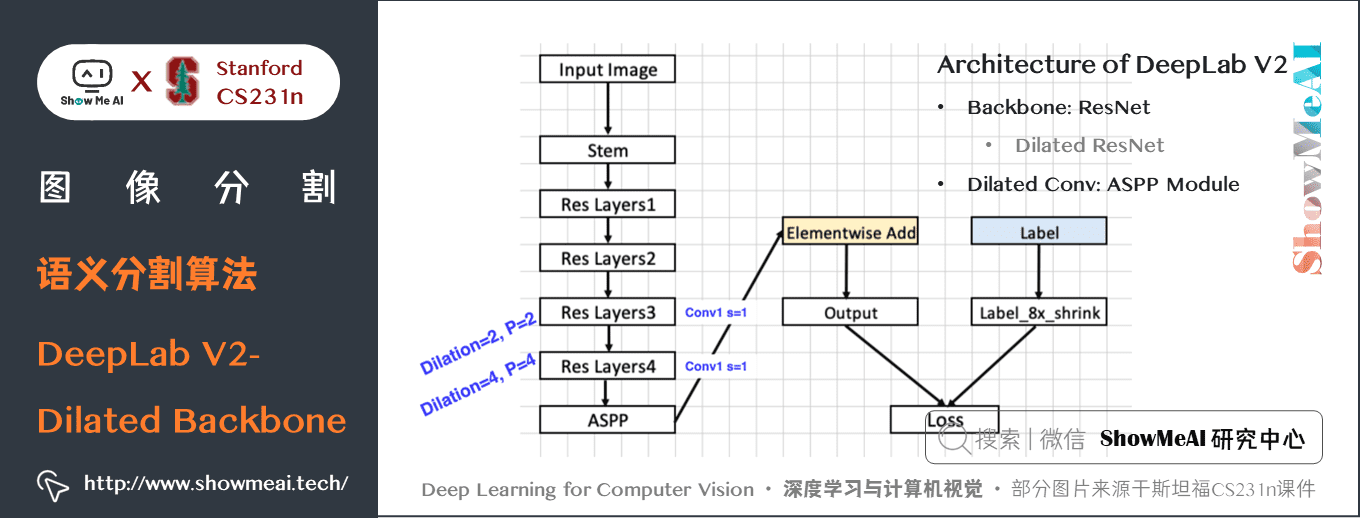
DeepLab V2的主幹網路是ResNet,整體網路如下圖所示,核心的一些結構包括 空洞卷積組建的ASPP模組、空洞空間金字塔池化。
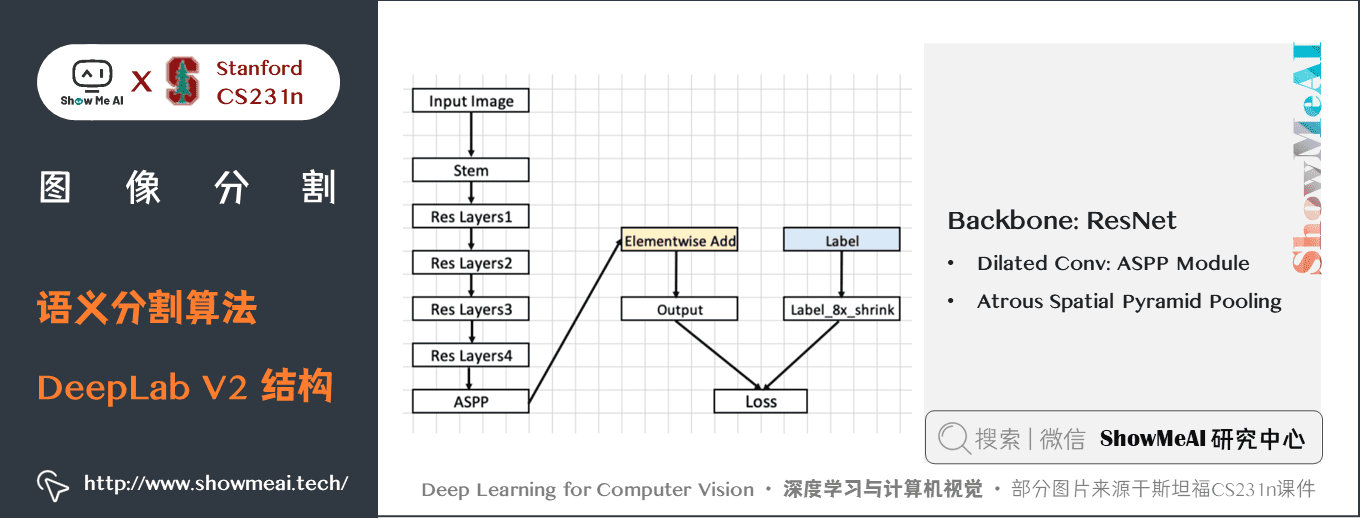
上圖中的 ASPP 模組具體展開如下方2個圖所示:
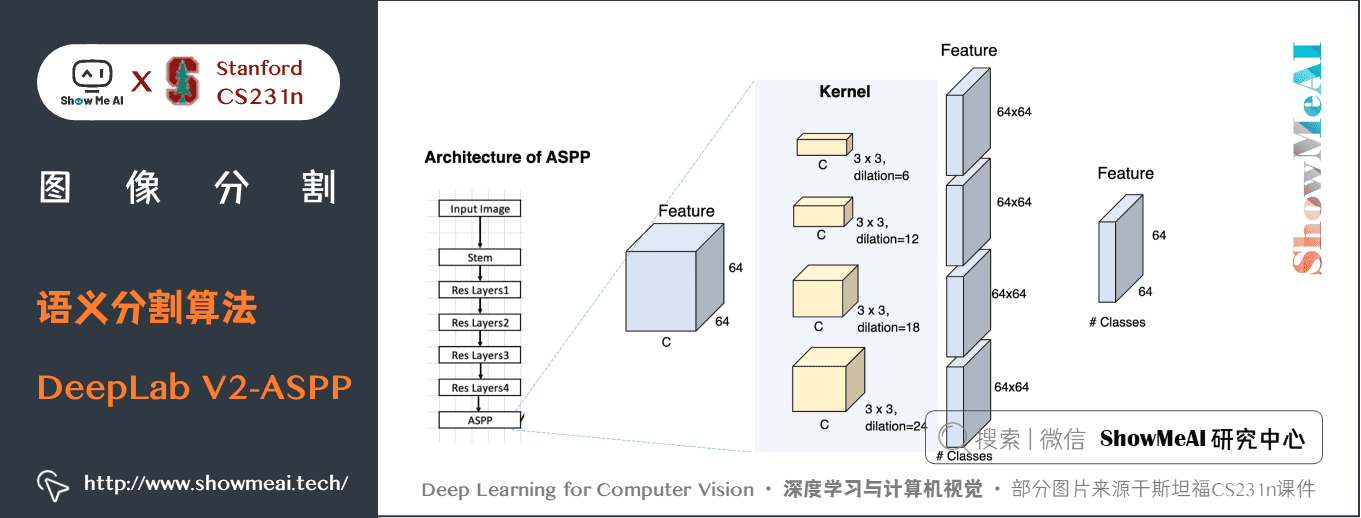
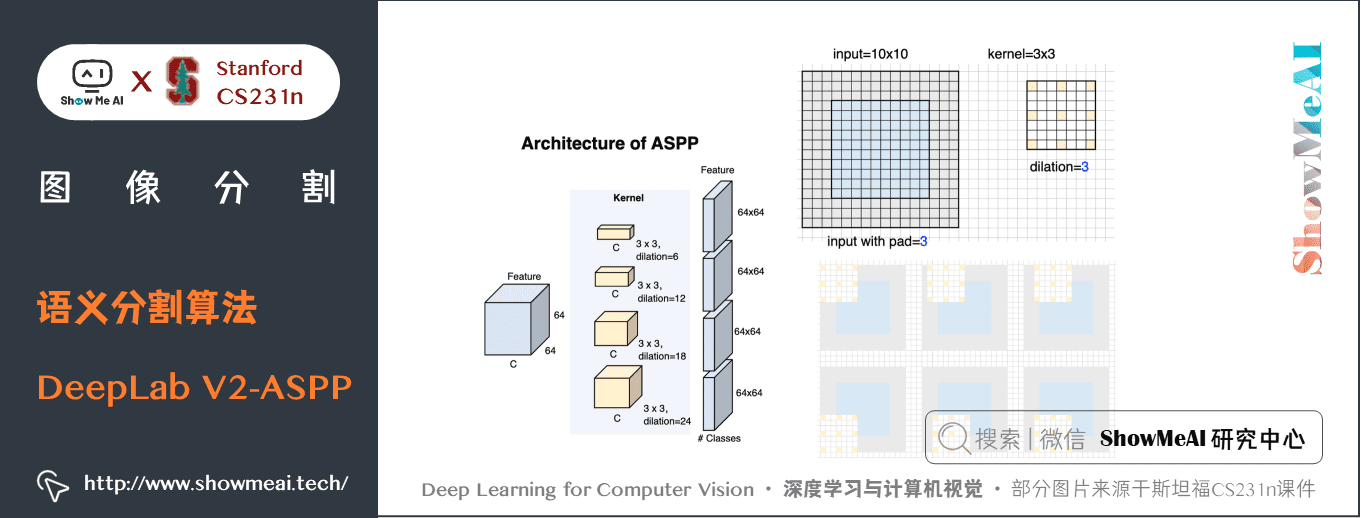
具體的,DeepLab V2 論文中提出了語義分割中的三個挑戰:
- ① 由於池化和卷積而減少的特徵解析度。
- ② 多尺度目標的存在。
- ③ 由於 DCNN 不變性而減少的定位準確率。
第①個挑戰解決方法:減少特徵圖下取樣的次數,但是會增加計算量。
第②個挑戰解決方法:使用影像金字塔、空間金字塔等多尺度方法獲取多尺度上下文資訊。
第③個挑戰解決方法:使用跳躍連接或者引入條件隨機場。
DeepLab V2 使用 VGG 和 ResNet 作為主幹網路分別進行了實驗。
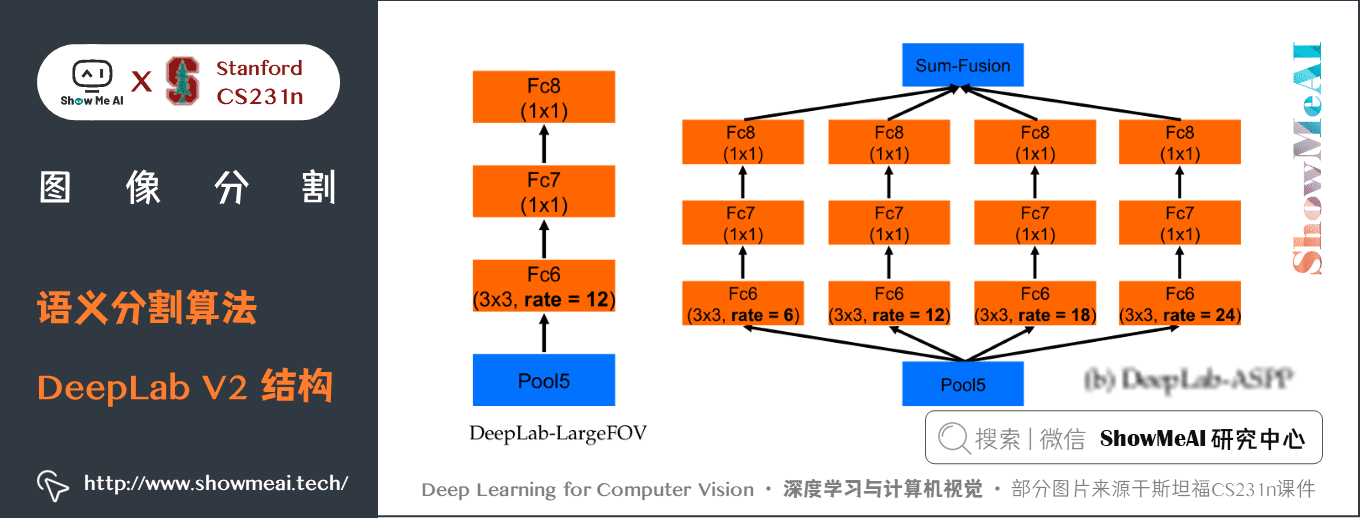
Deep LAB-ASPP employs multiple filters with different rates to capture objects and context at multiple scales.
關鍵特點:
- 提出了空洞空間金字塔池化(Atrous Spatial Pyramid Pooling) ,在不同的分支採用不同的空洞率以獲得多尺度影像表徵。
5.6 DeepLab V3
DeepLab V3在論文 Rethinking Atrous Convolution for Semantic Image Segmentation 中提出。
DeepLab V3 依舊使用了ResNet 作為主幹網路,也依舊應用空洞卷積結構。
為了解決多尺度目標的分割問題,DeepLab V3 串列/並行設計了能夠捕捉多尺度上下文的模組,模組中採用不同的空洞率。
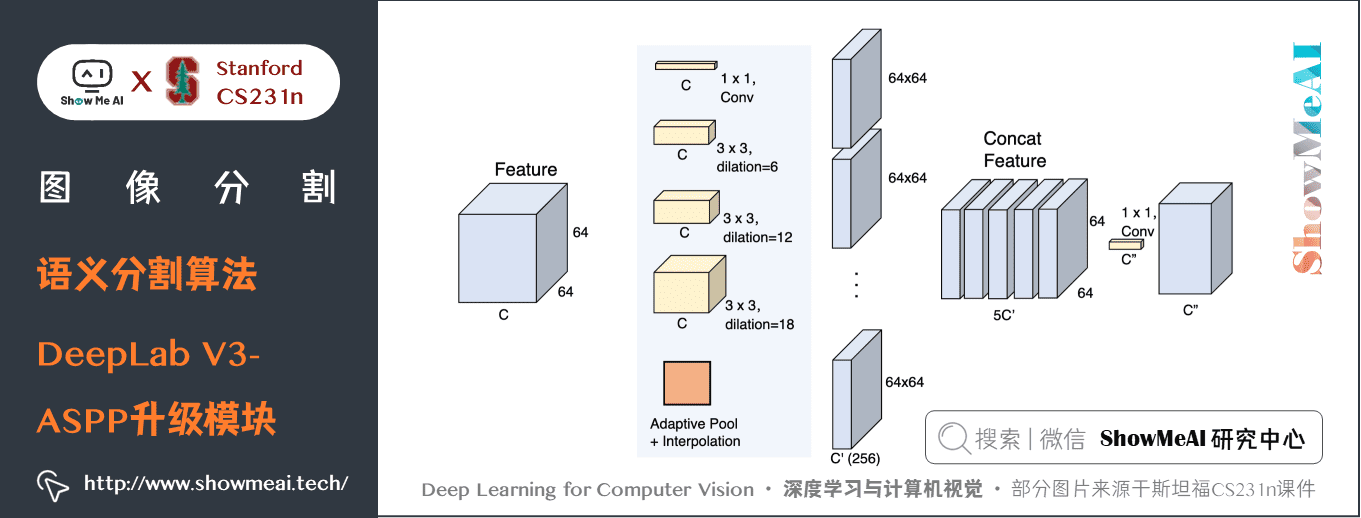
此外,DeepLab V3 增強了先前提出的空洞空間金字塔池化模組,增加了影像級特徵來編碼全局上下文,使得模組可以在多尺度下探測卷積特徵。
DeepLab V3 模型在沒有 CRF 作為後處理的情況下顯著提升了性能。
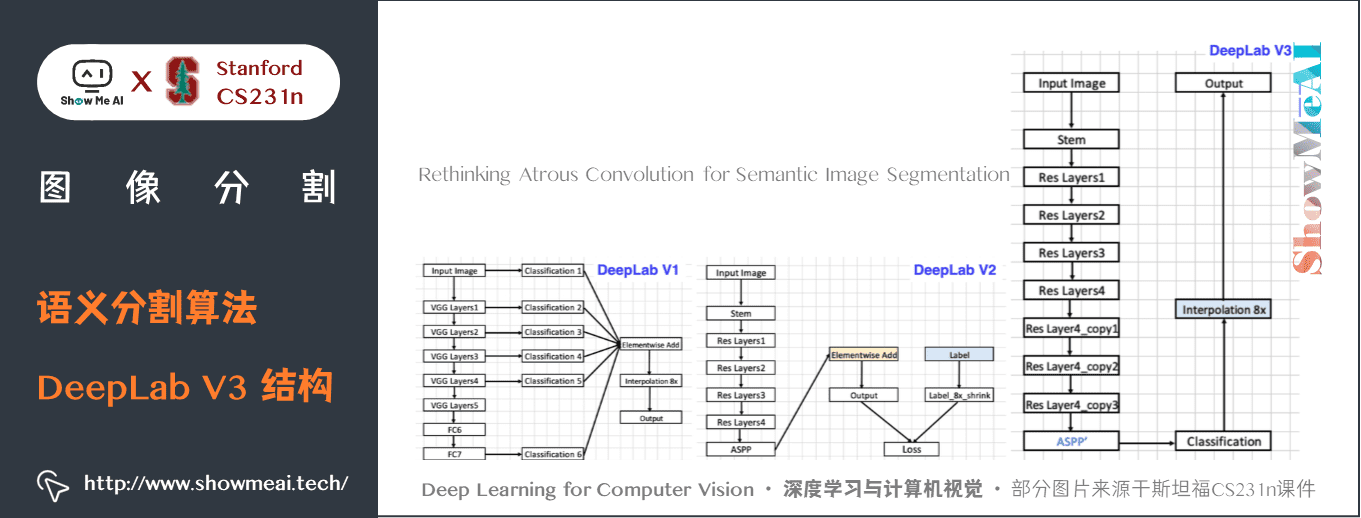
DeepLab V1-V3的結構對比如下所示:
DeepLab V3對ASPP模組進行了升級,升級後的結構細節如下圖所示:
DeepLab V3 的具體結構細節如下,包含多個殘差塊結構。
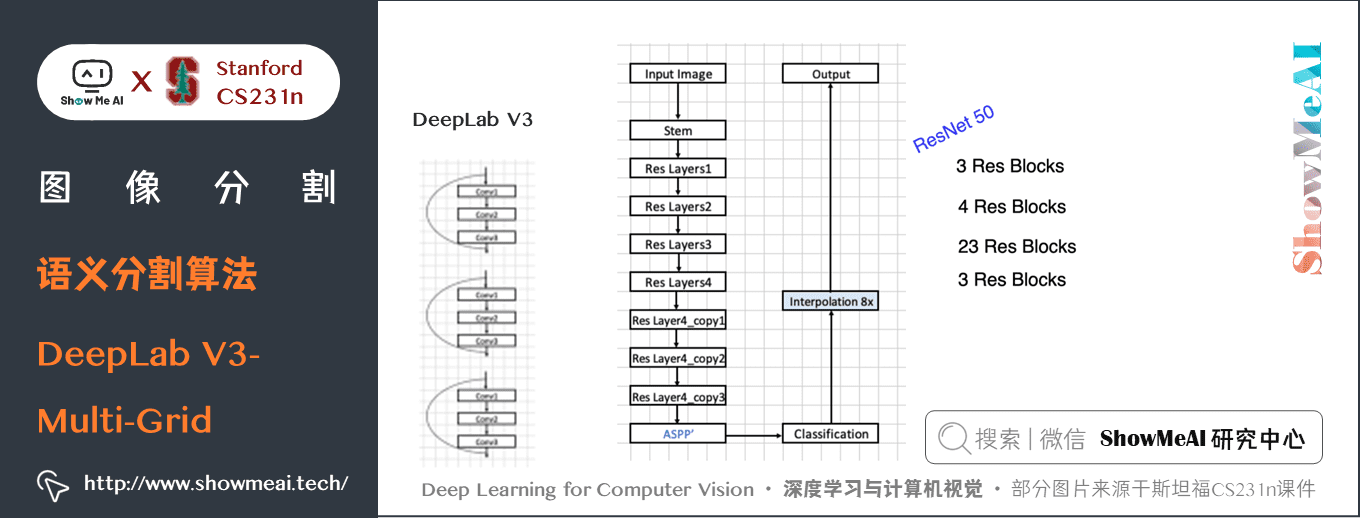
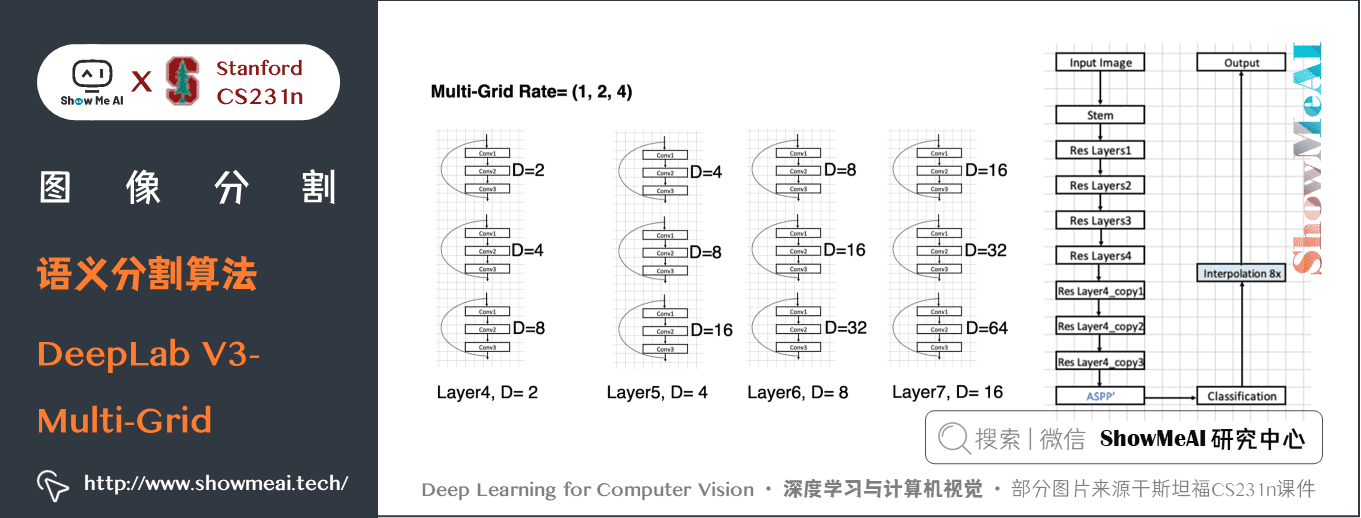
DeepLab V3中引入了Multi-grid,可以輸入大解析度圖片:
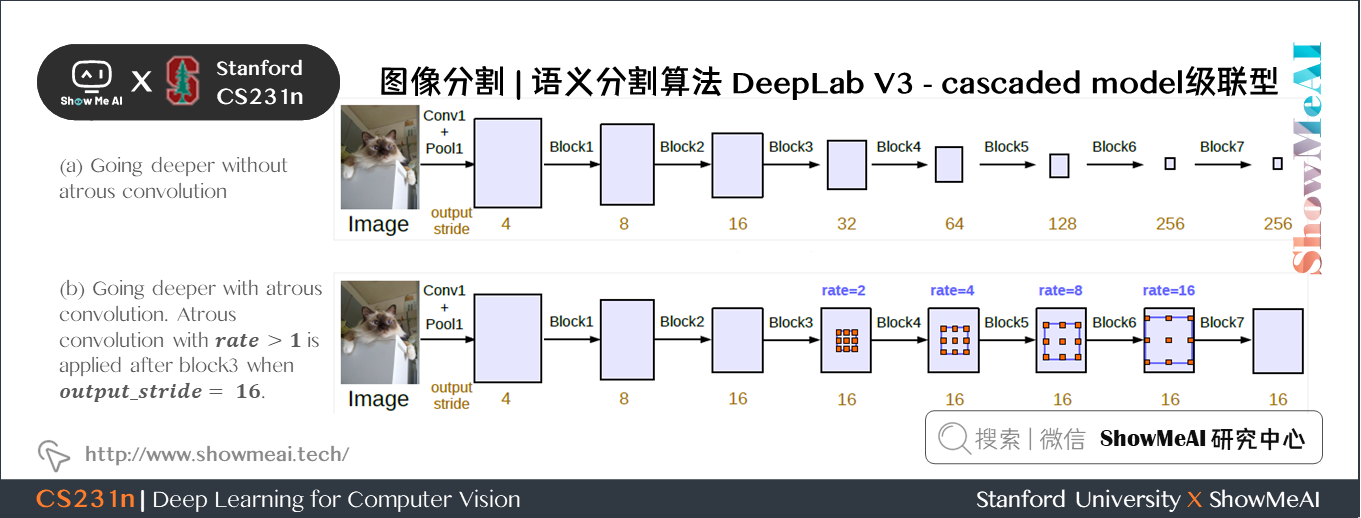
DeepLab V3包含2種實現結構:分別為 cascaded model 級聯型 和 ASPP model 金字塔池化型。
兩種模型分別如下的2幅圖所示。
- cascaded model 中 Block1,2,3,4 是 ResNet 網路的層結構(V3主幹網路採用 ResNet50 或 101),但 Block4 中將 \(3 \times 3\) 卷積和捷徑分支 \(1 \times 1\) 卷積步長 Stride 由 \(2\) 改為 \(1\),不進行下取樣,且將 \(3 \times 3\) 卷積換成膨脹卷積,後面的 Block5,6,7是對 Blockd 的 copy。(圖中 rate 不是真正的膨脹係數,真正的膨脹係數 \(=rate \ast Multi-grid\) 參數)
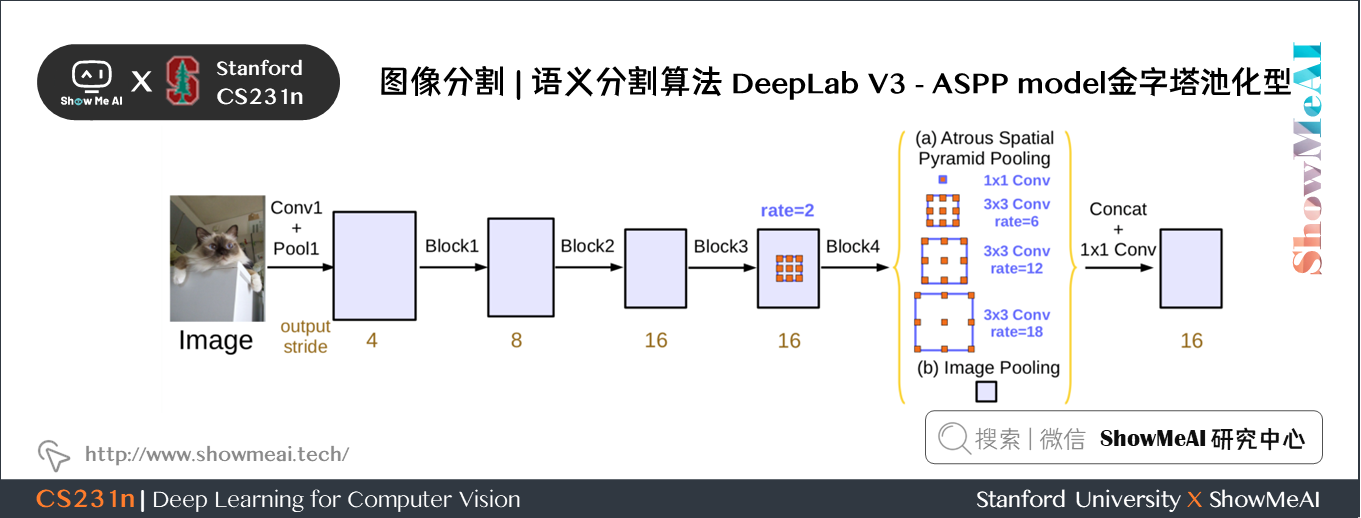
- ASPP模型的升級在前面介紹里提到了。
論文中使用較多的結構還是還是ASPP模型,兩者模型在效果上差距不大。
關鍵特點:
- 在殘差塊中使用多網格方法(MultiGrid),從而引入不同的空洞率。- 在空洞空間金字塔池化模組中加入影像級(Image-level)特徵,並且使用 BatchNormalization 技巧。
5.7 Mask R-CNN
Mask R-CNN在論文 Mask R-CNN 中被提出。
Mask R-CNN以Faster R-CNN 為基礎,在現有的邊界框識別分支基礎上添加一個並行的預測目標掩碼的分支。
Mask R-CNN很容易訓練,僅僅在 Faster R-CNN 上增加了一點小開銷,運行速度為 5fps。
此外,Mask R-CNN很容易泛化至其他任務,例如,可以使用相同的框架進行姿態估計。
Mask R-CNN在 COCO 所有的挑戰賽中都獲得了最優結果,包括實例分割,邊界框目標檢測,和人關鍵點檢測。在沒有使用任何技巧的情況下,Mask R-CNN 在每項任務上都優於所有現有的單模型網路,包括 COCO 2016 挑戰賽的獲勝者。
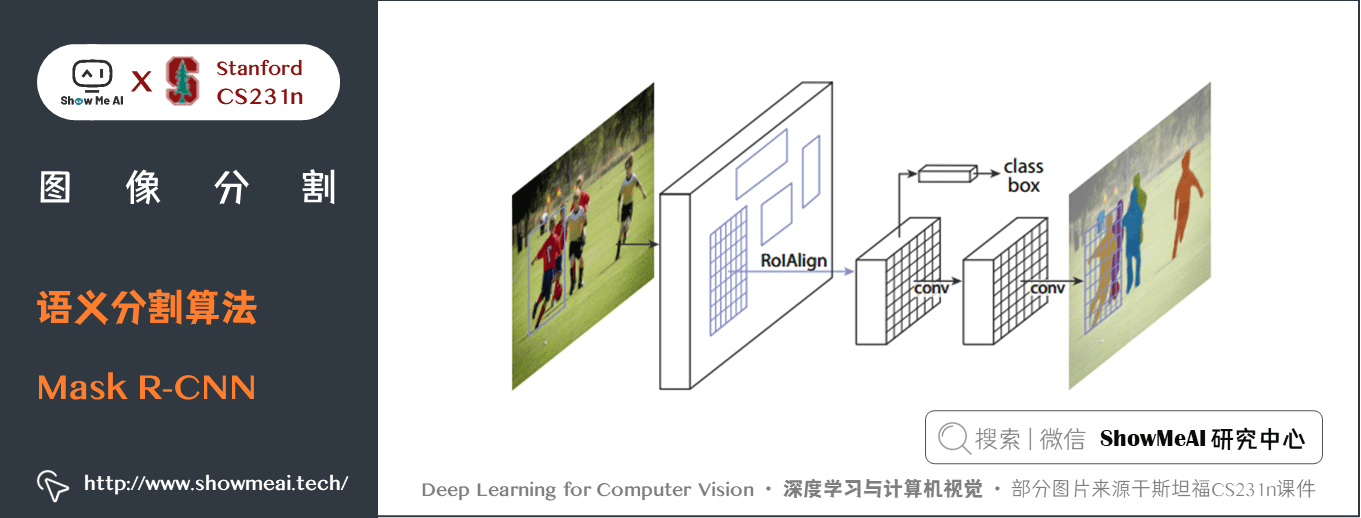
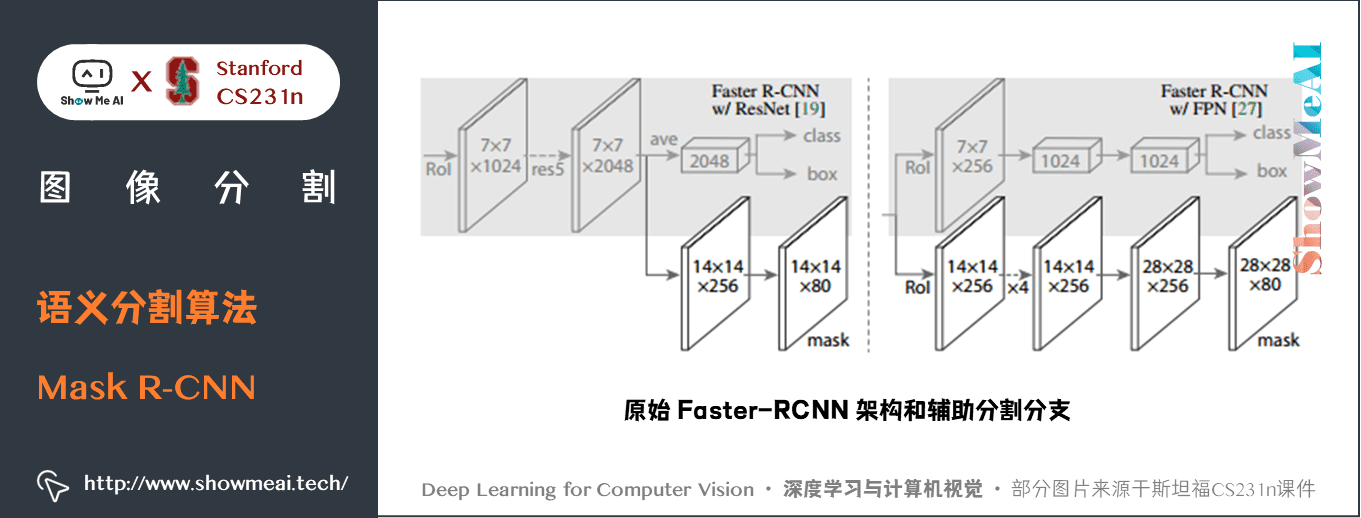
Mask R-CNN 是在流行的 Faster R-CNN 架構基礎上進行必要的修改,以執行語義分割。
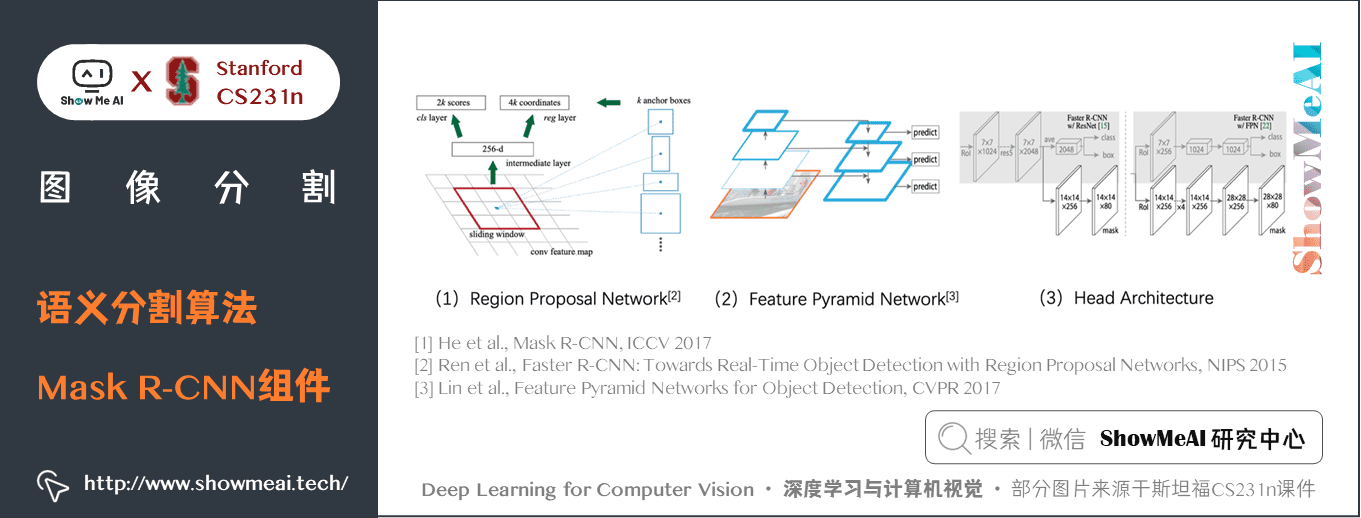
關鍵特點:
在Faster R-CNN 上添加輔助分支以執行語義分割- 對每個實例進行的 RoIPool 操作已經被修改為 RoIAlign ,它避免了特徵提取的空間量化,因為在最高解析度中保持空間特徵不變對於語義分割很重要。- Mask R-CNN 與 Feature Pyramid Networks(類似於PSPNet,它對特徵使用了金字塔池化)相結合,在 MS COCO 數據集上取得了最優結果。
5.8 PSPNet
PSPNet在論文 PSPNet: Pyramid Scene Parsing Network 中提出。
PSPNet利用基於不同區域的上下文資訊集合,通過我們的金字塔池化模組,使用提出的金字塔場景解析網路(PSPNet)來發揮全局上下文資訊的能力。
全局先驗表徵在場景解析任務中產生了良好的品質結果,而 PSPNet 為像素級的預測提供了一個更好的框架,該方法在不同的數據集上達到了最優性能。它首次在2016 ImageNet 場景解析挑戰賽,PASCAL VOC 2012 基準和 Cityscapes 基準中出現。
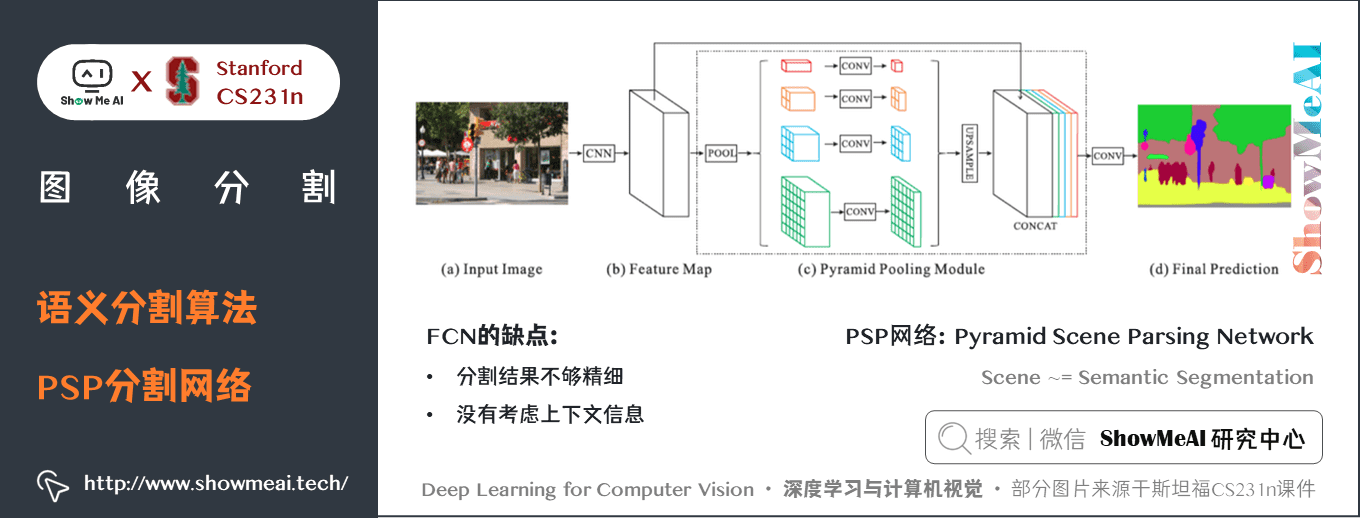
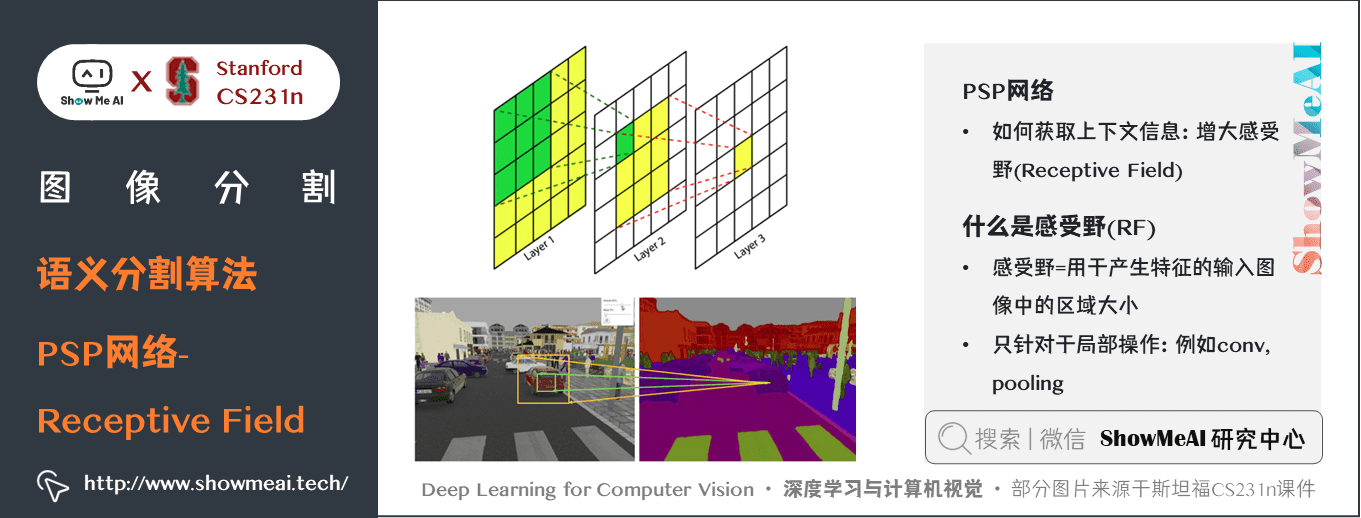
如上圖所示,PSP網路解決的主要問題是「缺少上下文資訊」帶來的不準確,其利用全局資訊獲取上下文,具體如下
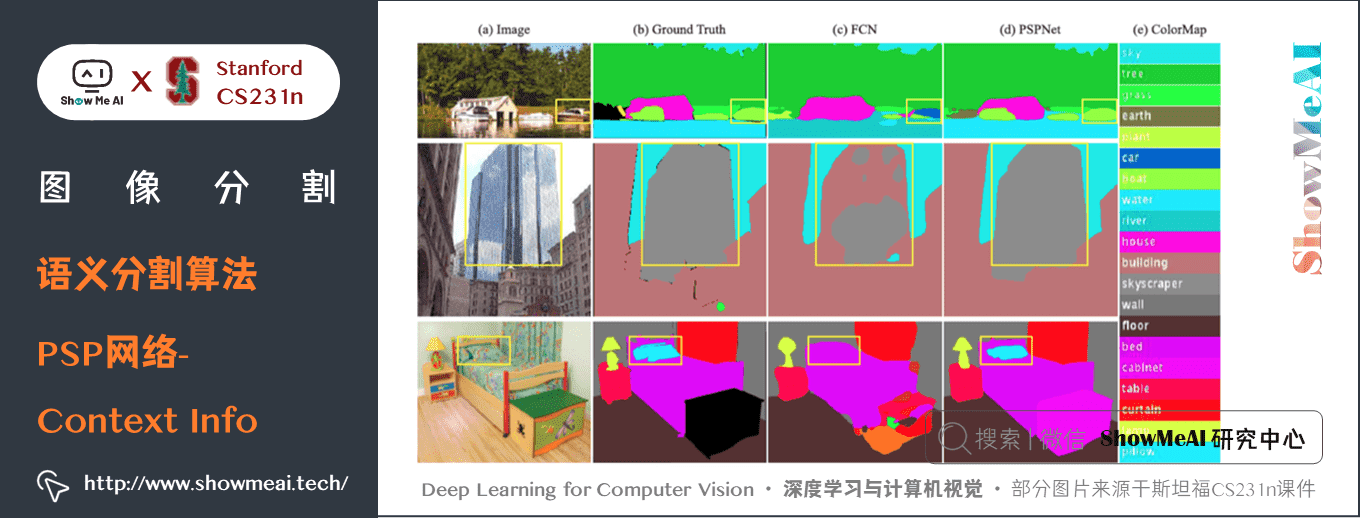
之前的問題: 缺少上下文資訊
如上圖所示
- 圖中的boat區域和類別”car」的appearance相似
- 模型只有local 資訊,Boat 容易被識別為”car”
- Confusion categories: Building and skyscraper
應用上下文資訊方法
- 利用全局資訊 (global information)
- 全局資訊 in CNN ~= feature/pyramid
PSP網路的一些細節如下幾幅圖中介紹:
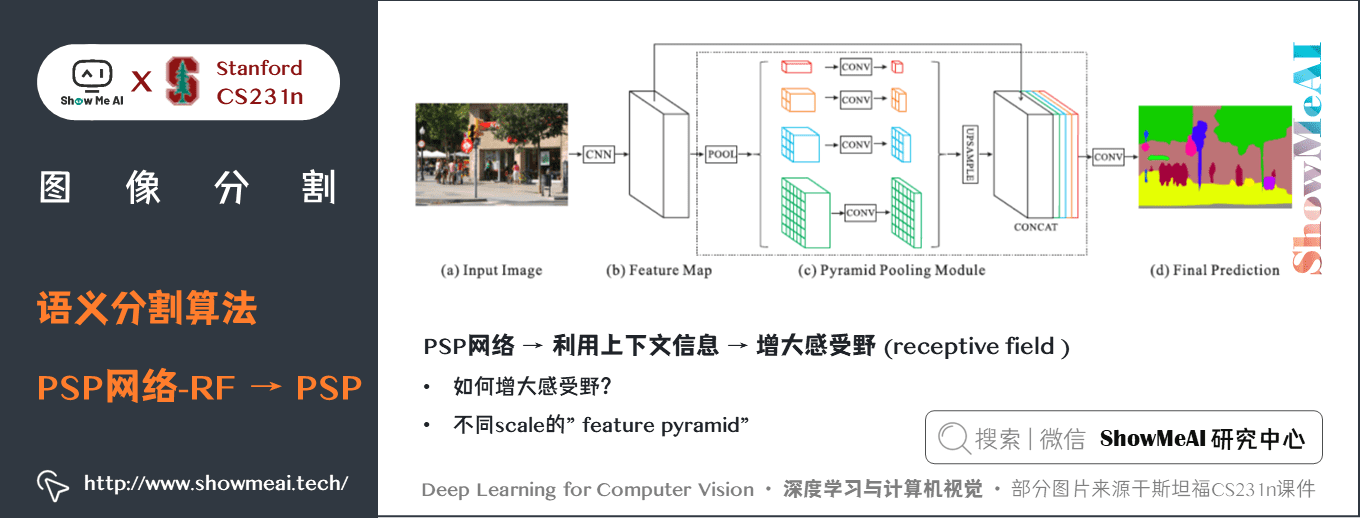
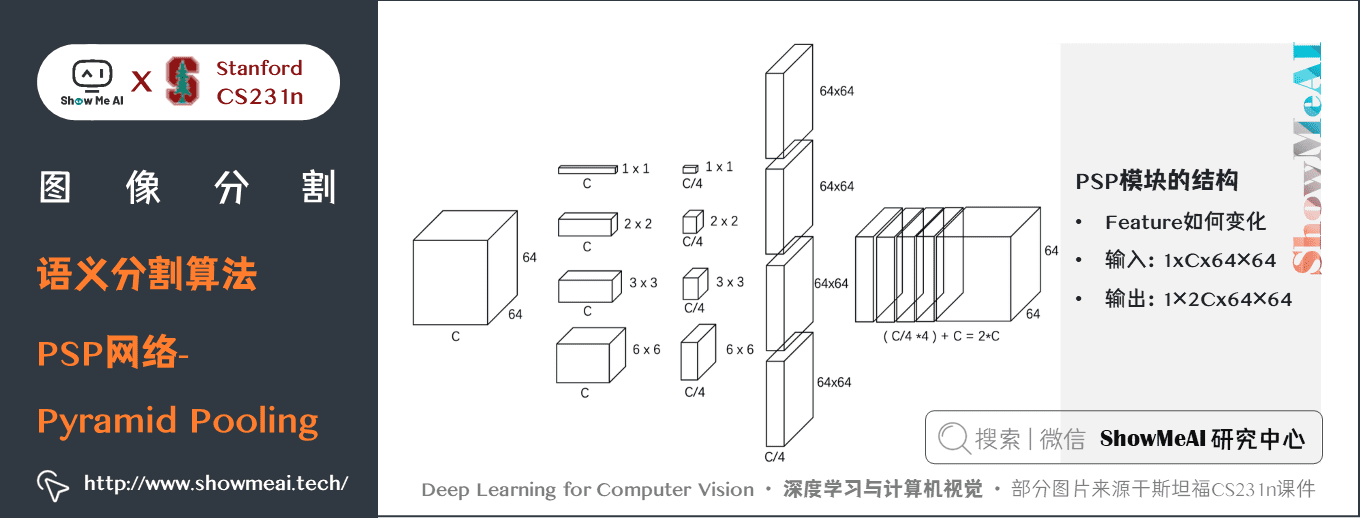
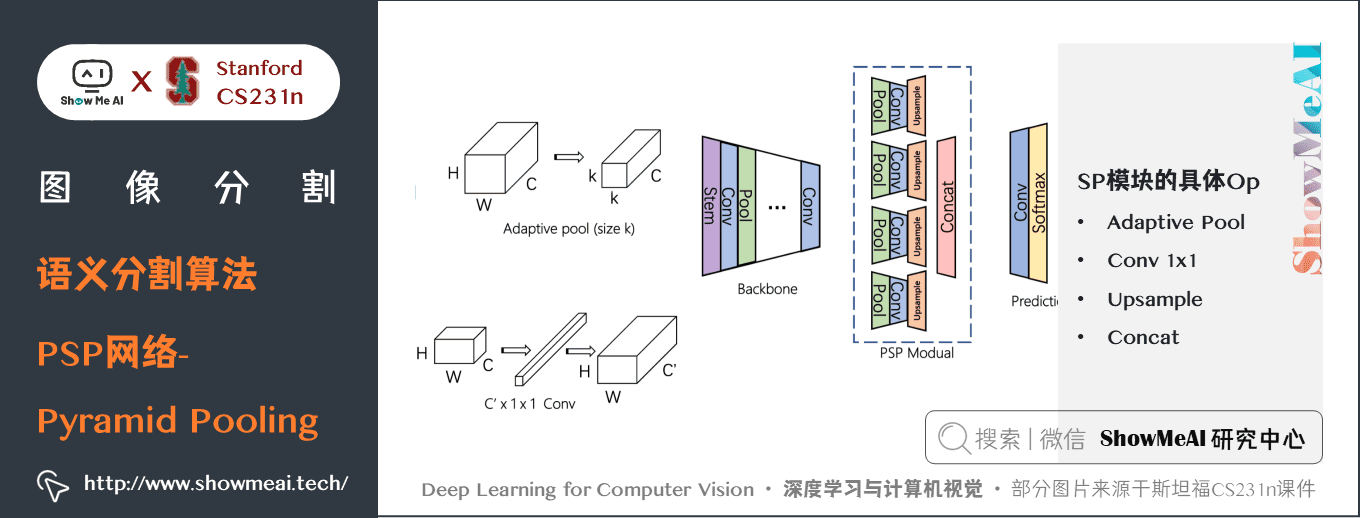
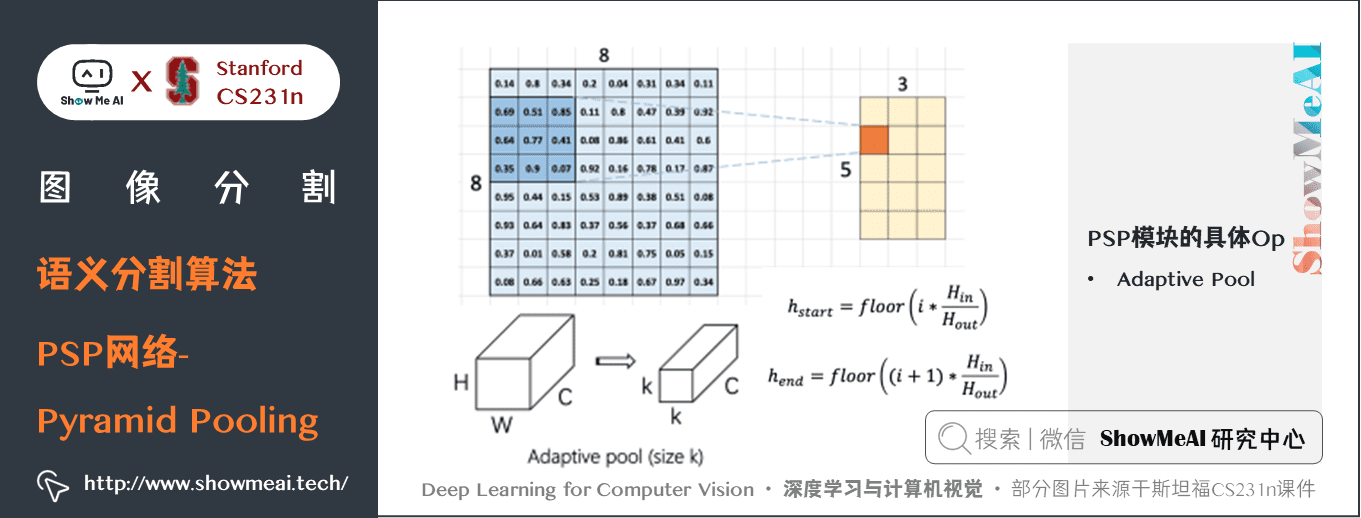
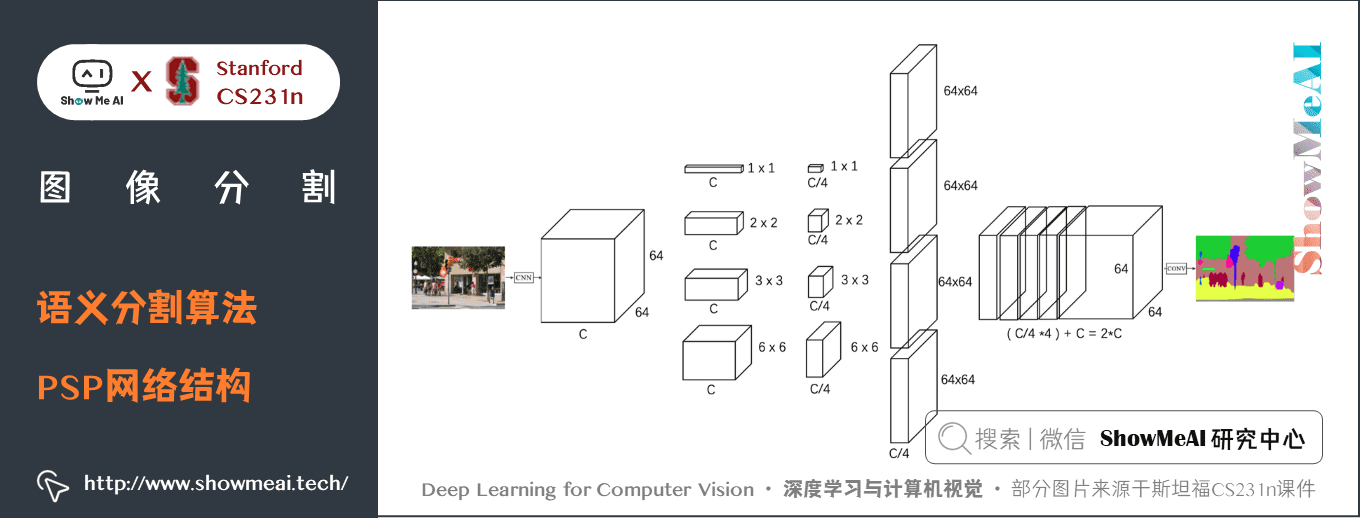
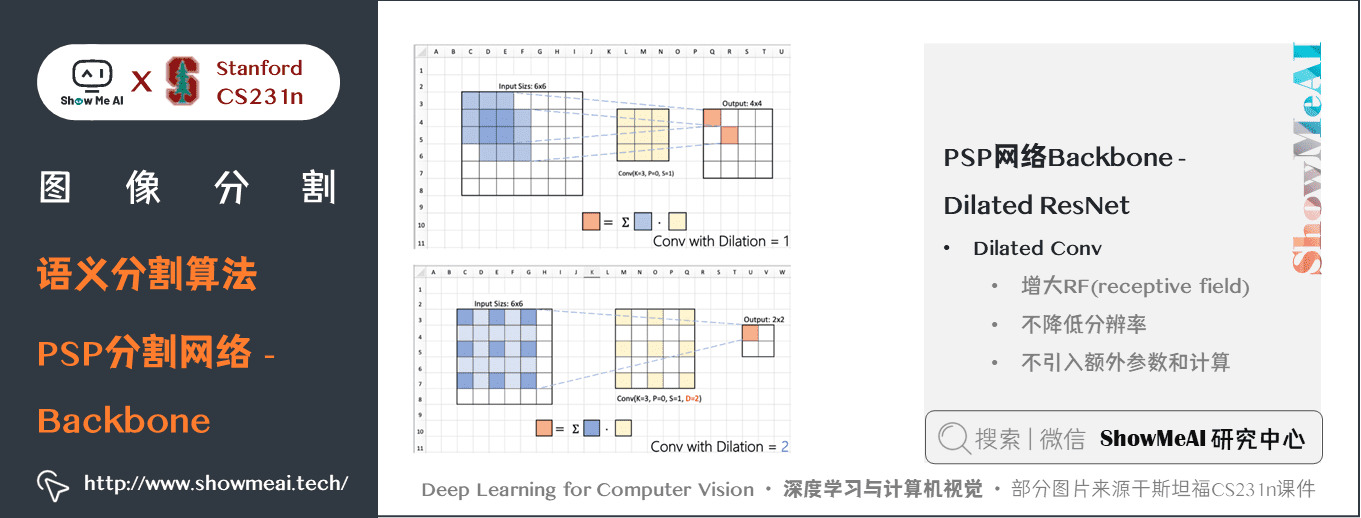
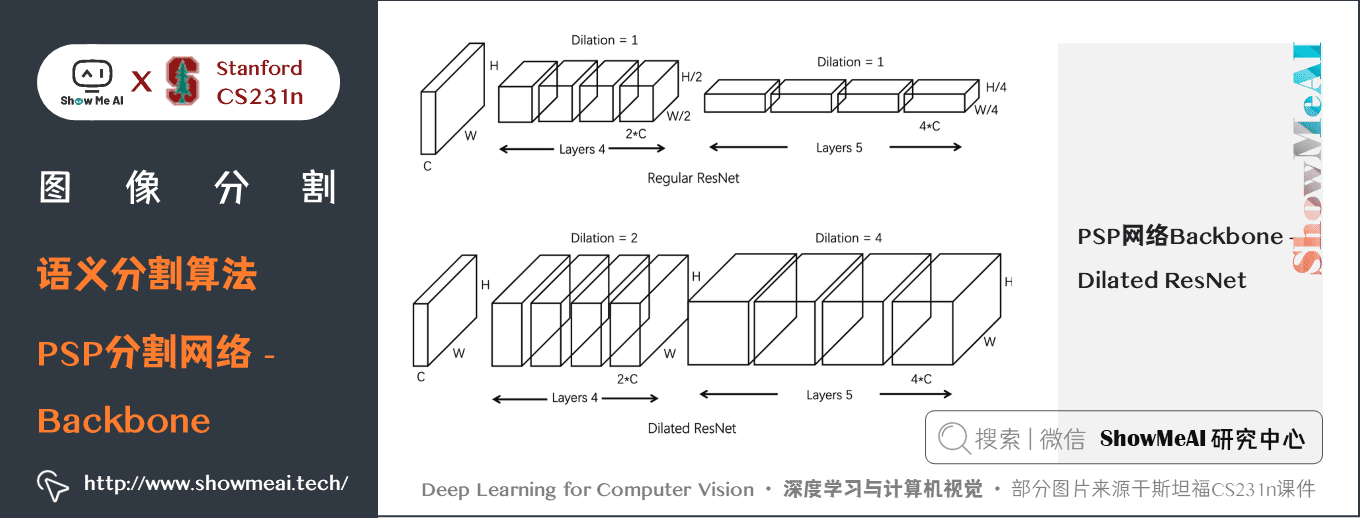
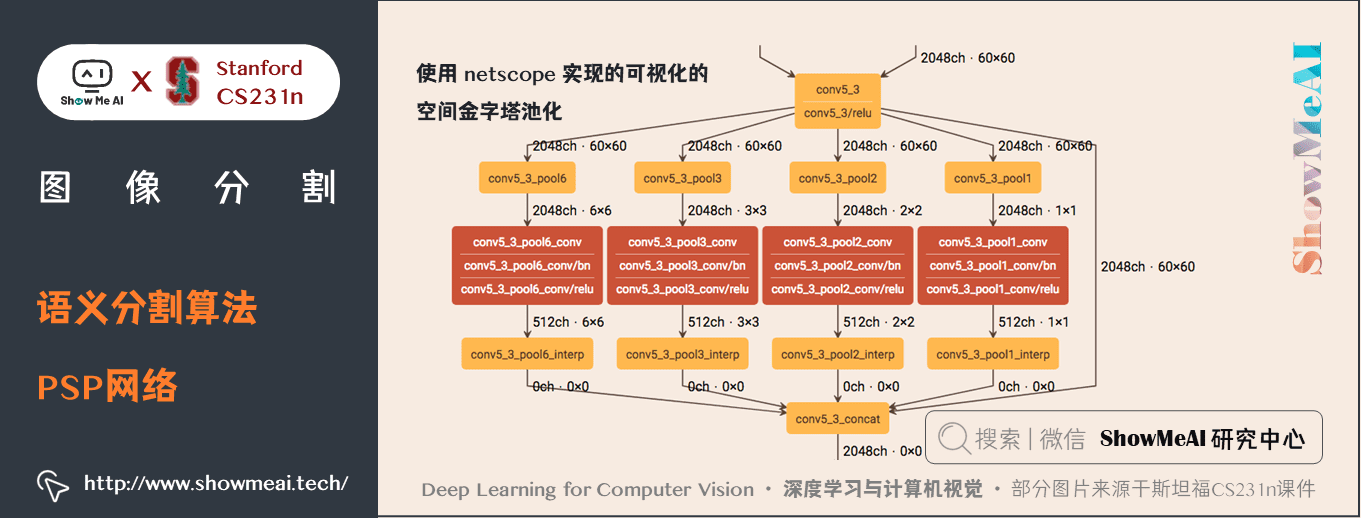
關鍵特點:
- PSPNet 通過引入空洞卷積來修改基礎的 ResNet 架構,特徵經過最初的池化,在整個編碼器網路中以相同的解析度進行處理(原始影像輸入的
1/4),直到它到達空間池化模組。- 在 ResNet 的中間層中引入輔助損失,以優化整體學習。- 在修改後的 ResNet 編碼器頂部的空間金字塔池化聚合全局上下文。
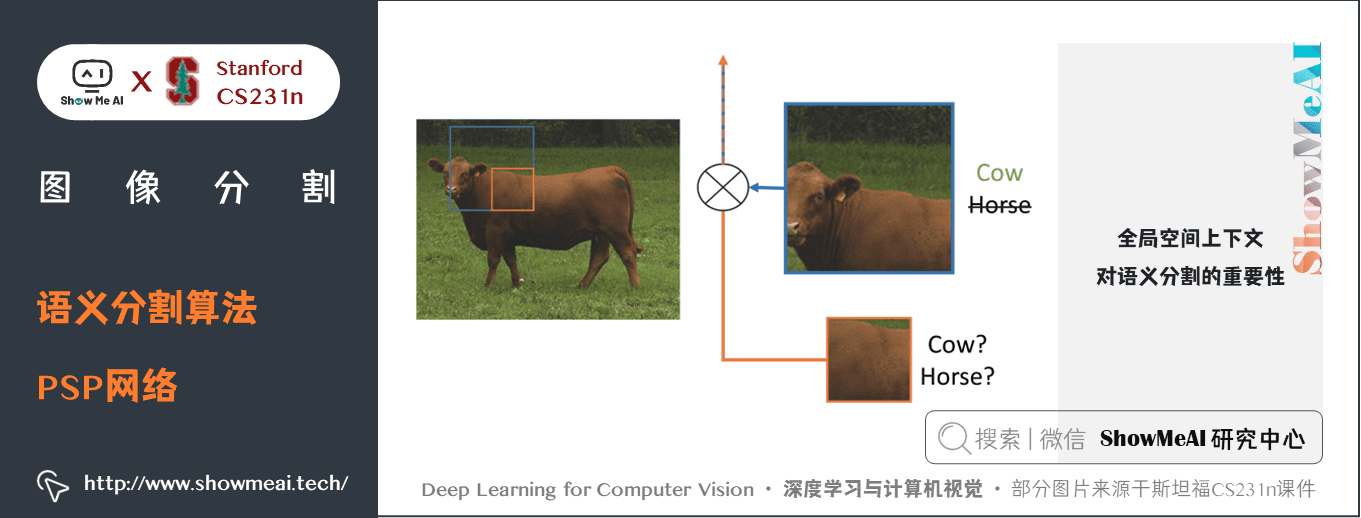
圖片展示了全局空間上下文對語義分割的重要性。它顯示了層之間感受野和大小的關係。在這個例子中,更大、更加可判別的感受野(藍)相比於前一層(橙)可能在細化表徵中更加重要,這有助於解決歧義
5.9 RefineNet
RefineNet在論文 RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation 中提出。
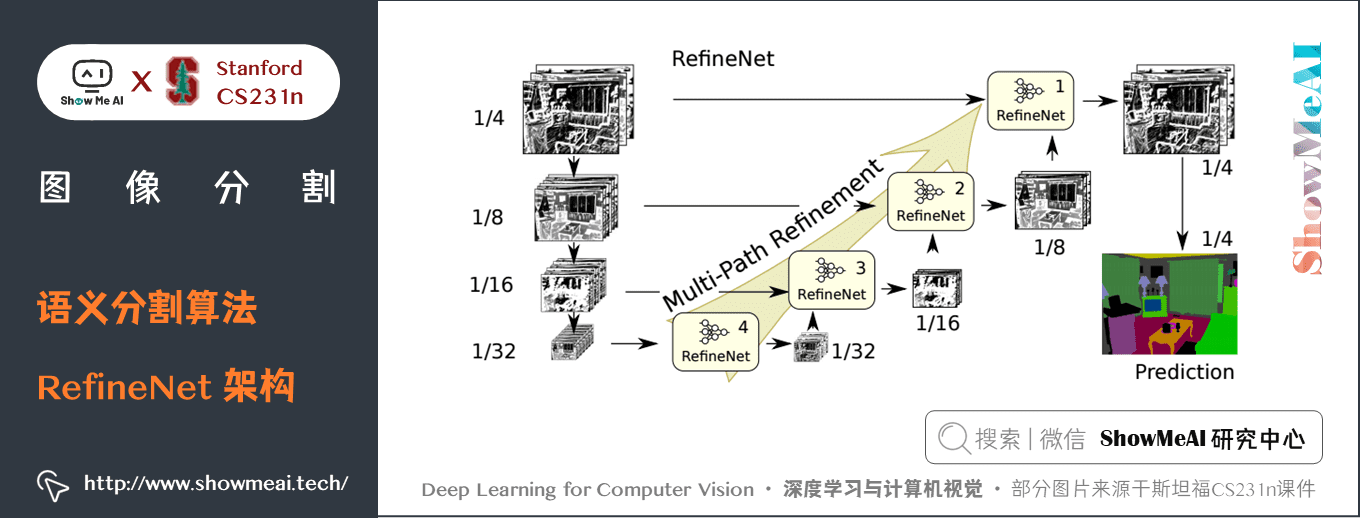
RefineNet是一個通用的多路徑優化網路,它明確利用了整個下取樣過程中可用的所有資訊,使用遠程殘差連接實現高解析度的預測。通過這種方式,可以使用早期卷積中的細粒度特徵來直接細化捕捉高級語義特徵的更深的網路層。RefineNet 的各個組件使用遵循恆等映射思想的殘差連接,這允許網路進行有效的端到端訓練。
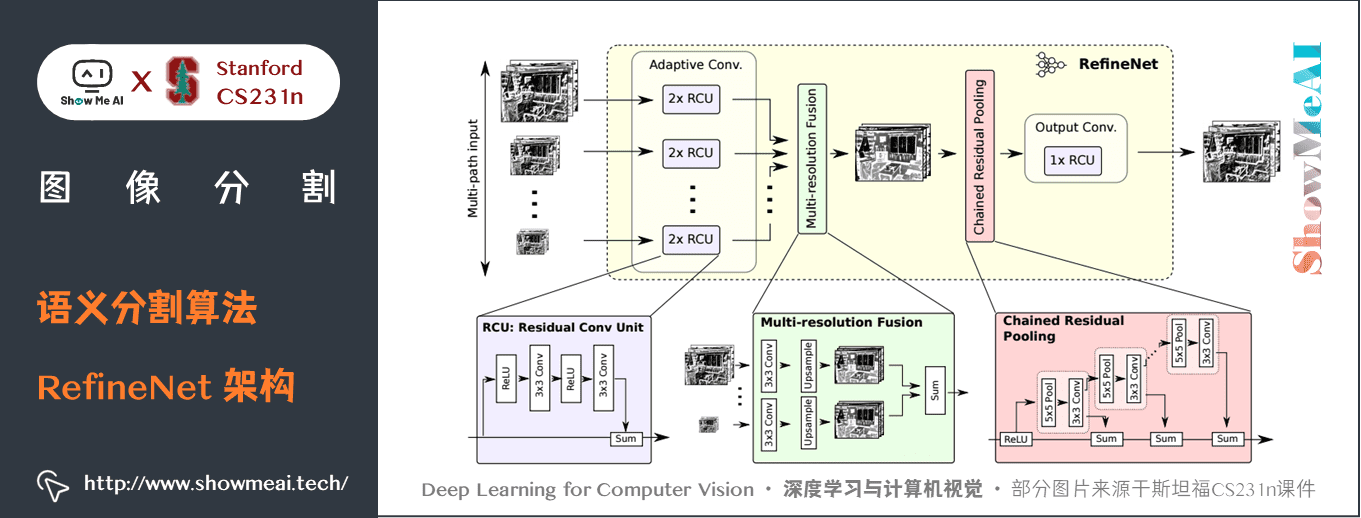
如上圖所示,是建立 RefineNet 的塊 – 殘差卷積單元,多解析度融合和鏈式殘差池化。
RefineNet 解決了傳統卷積網路中空間解析度減少的問題,與 PSPNet(使用計算成本高的空洞卷積)使用的方法非常不同。提出的架構迭代地池化特徵,利用特殊的 RefineNet 模組增加不同的解析度,並最終生成高解析度的分割圖。
關鍵特點:
- 使用多解析度作為輸入,將提取的特徵融合在一起,並將其傳遞到下一個階段。
- 引入鏈式殘差池化,可以從一個大的影像區域獲取背景資訊。它通過多窗口尺寸有效地池化特性,利用殘差連接和學習權重方式融合這些特徵。
- 所有的特徵融合都是使用
sum(ResNet 方式)來進行端到端訓練。 - 使用普通 ResNet 的殘差層,沒有計算成本高的空洞卷積。
6.拓展學習
可以點擊 B站 查看影片的【雙語字幕】版本
- 【課程學習指南】斯坦福CS231n | 深度學習與電腦視覺
- [【字幕+資料下載】斯坦福CS231n | 深度學習與電腦視覺 (2017·全16講)](<//www.bilibili.com/video/BV1g64y1B7m7)
- 【CS231n進階課】密歇根EECS498 | 深度學習與電腦視覺
- 【深度學習教程】吳恩達專項課程 · 全套筆記解讀
- 【Stanford官網】CS231n: Deep Learning for Computer Vision
7.參考資料
- An overview of semantic image segmentation
- A 2017 Guide to Semantic Segmentation with Deep Learning
- Semantic Segmentation using Fully Convolutional Networks over the years
斯坦福 CS231n 全套解讀
- 深度學習與CV教程(1) | CV引言與基礎
- 深度學習與CV教程(2) | 影像分類與機器學習基礎
- 深度學習與CV教程(3) | 損失函數與最優化
- 深度學習與CV教程(4) | 神經網路與反向傳播
- 深度學習與CV教程(5) | 卷積神經網路
- 深度學習與CV教程(6) | 神經網路訓練技巧 (上)
- 深度學習與CV教程(7) | 神經網路訓練技巧 (下)
- 深度學習與CV教程(8) | 常見深度學習框架介紹
- 深度學習與CV教程(9) | 典型CNN架構 (Alexnet, VGG, Googlenet, Restnet等)
- 深度學習與CV教程(10) | 輕量化CNN架構 (SqueezeNet, ShuffleNet, MobileNet等)
- 深度學習與CV教程(11) | 循環神經網路及視覺應用
- 深度學習與CV教程(12) | 目標檢測 (兩階段, R-CNN系列)
- 深度學習與CV教程(13) | 目標檢測 (SSD, YOLO系列)
- 深度學習與CV教程(14) | 影像分割 (FCN, SegNet, U-Net, PSPNet, DeepLab, RefineNet)
- 深度學習與CV教程(15) | 視覺模型可視化與可解釋性
- 深度學習與CV教程(16) | 生成模型 (PixelRNN, PixelCNN, VAE, GAN)
- 深度學習與CV教程(17) | 深度強化學習 (馬爾可夫決策過程, Q-Learning, DQN)
- 深度學習與CV教程(18) | 深度強化學習 (梯度策略, Actor-Critic, DDPG, A3C)
ShowMeAI 系列教程推薦
- 大廠技術實現:推薦與廣告計算解決方案
- 大廠技術實現:電腦視覺解決方案
- 大廠技術實現:自然語言處理行業解決方案
- 圖解Python編程:從入門到精通系列教程
- 圖解數據分析:從入門到精通系列教程
- 圖解AI數學基礎:從入門到精通系列教程
- 圖解大數據技術:從入門到精通系列教程
- 圖解機器學習演算法:從入門到精通系列教程
- 機器學習實戰:手把手教你玩轉機器學習系列
- 深度學習教程:吳恩達專項課程 · 全套筆記解讀
- 自然語言處理教程:斯坦福CS224n課程 · 課程帶學與全套筆記解讀
- 深度學習與電腦視覺教程:斯坦福CS231n · 全套筆記解讀



