【生成對抗網路學習 其一】經典GAN與其存在的問題和相關改進
參考資料:
1、//github.com/dragen1860/TensorFlow-2.x-Tutorials
2、《Generative Adversarial Net》
直接介紹GAN可能不太容易理解,所以本次會順著幾個具體的問題討論並介紹GAN(個人理解有限,有錯誤的希望各位大佬指出),本來想做程式碼介紹的,但是關於eriklindernoren的GAN系列實現已經有很多部落客介紹過了,所以就不寫了。
如果你對GAN的基本知識不太了解,建議先看看莫煩的介紹://mofanpy.com/tutorials/machine-learning/gan/
註:圖片刷不出來可能需要fq,最近jsdelivr代理好像掛了。
1、什麼是GAN
GAN是一種生成網路
區別於以往使用的RNN、CNN等網路,GAN不是將數據與結果根據某種關係聯繫起來,而是使用一堆隨機數去生成想要的結果
GAN中同時訓練著兩個模型:一個是生成器(Generator),另一個是判別器(Discriminator)。
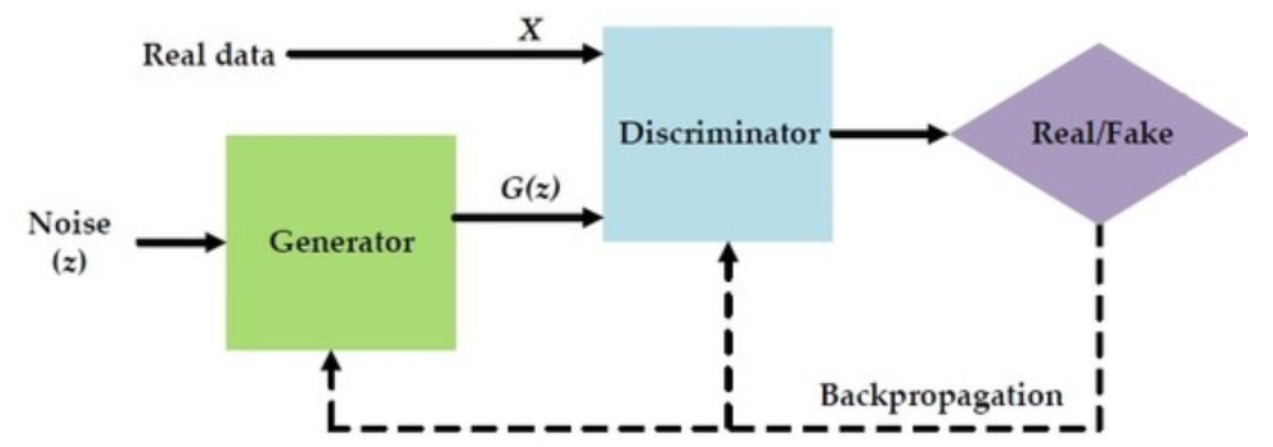
生成器通過隨機數來生成結果(有可能是圖片,也有可能是其他的),這裡我們把生成的結果稱為”生成數據“,我們的目標結果稱為”真實數據“。
之後,生成數據和真實數據會被同時送給判別器進行區分。
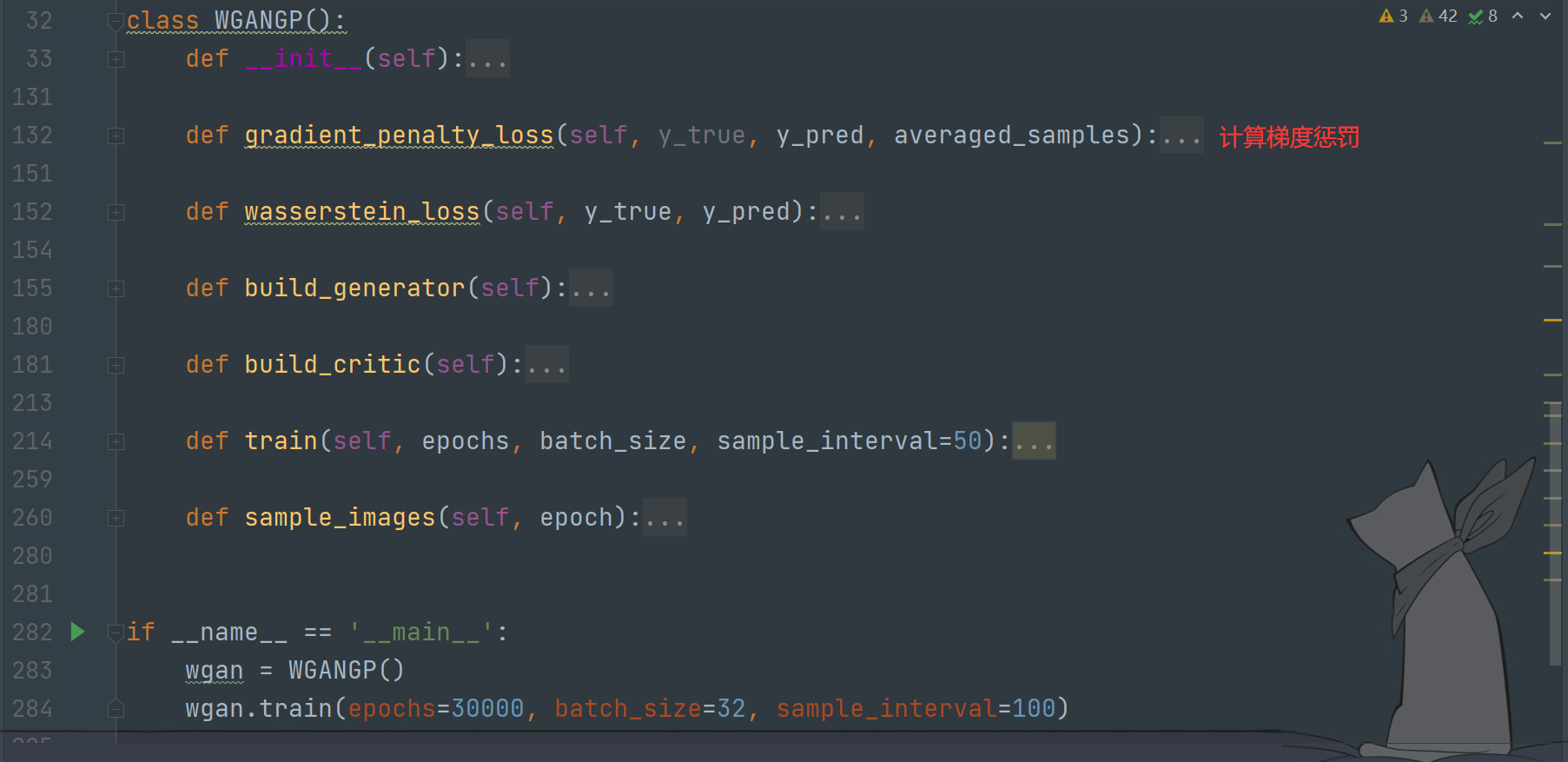
GAN的訓練
整體結構如下
2、GAN有什麼問題
研究數據的特點是解決問題的一個前提,數據分布會直接影響到我們演算法的結果
對於「通過訓練,從雜訊數據生成一副圖片」這個問題來說,裡面涉及到兩種數據:雜訊和真實圖片
這兩種數據在分布上來說是沒有重合部分的
例如,真實的圖片是「手寫數字1」,而還沒經過訓練的生成器用雜訊生成的圖片是類似老電視上的那種白色雪花噪點(我的理解,不知道恰不恰當)
顯然兩者不會有數據上的重合(overlapped),在這種情況下無論生成多少張圖片,我們人去看的時候總是能夠區分假圖片
具體來說就對應成下面的兩種分布:P、Q

省略KL與JS的推導過程直接看結論:
當θ≠0(數據分布沒有重合時),使用KL散度(相對熵)和JS散度不能夠很好地量化訓練結果
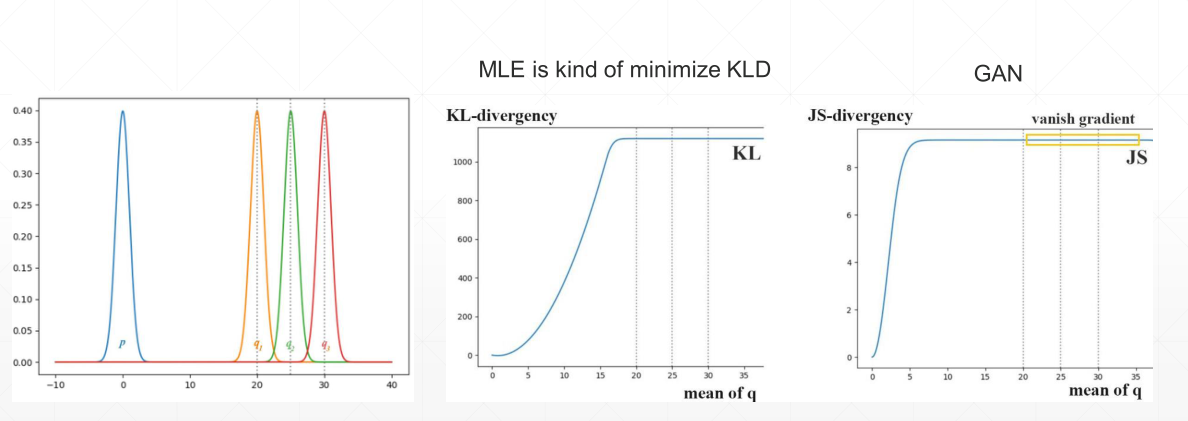
例如上圖,在均值達到某一大小時,兩者會變成固定常數(也就是不起作用,並且JS比KL出現時間更早),對應到現象就是出現梯度消失,沒辦法繼續更新梯度。
再換個角度看

藍色的是分布1,紅色的是真實數據分布,不管怎麼移動,只要兩者沒有重合,那麼JS永遠是log2(同一值)
也就是說,如果剛開始訓練時,數據分布處於一個不好的狀態,那麼訓練很難再進行下去
再舉個例子
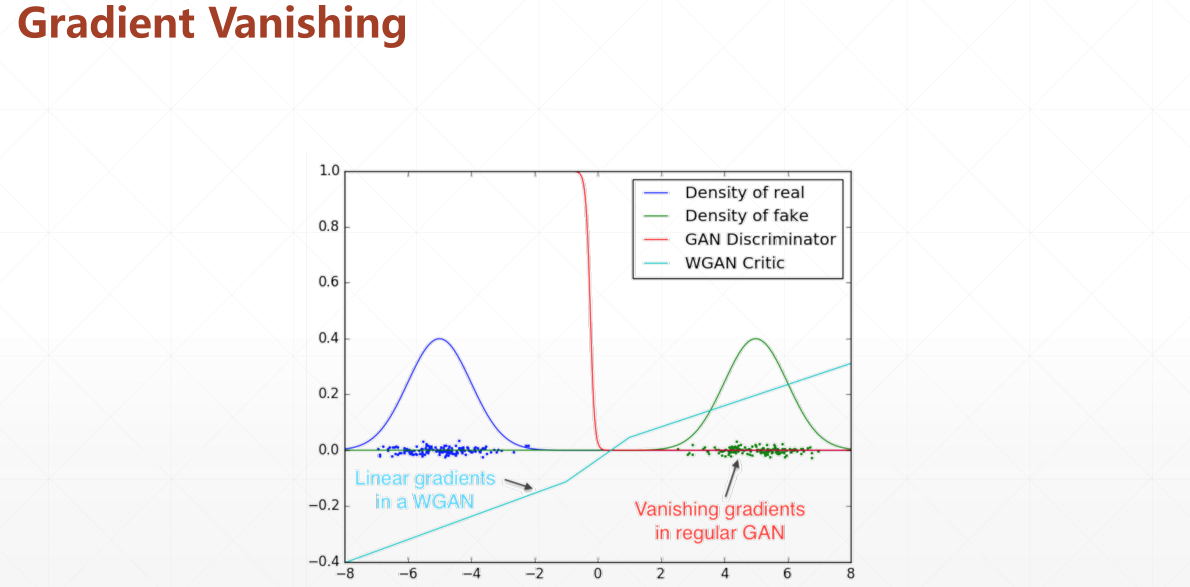
藍色是真實數據,綠色是生成數據的分布,它們中間部分是沒有重疊的
對於橙色線也就是判別器而言,他可以簡單的區分出是或者不是真實數據(0/1)
但是如果一開始我們的數據分布就處於綠色區域(不利位置),那麼是沒辦法進行判別的(無法更新)
而WGAN的評價標準(EM)可以解決這個問題,即使在不相交的位置,導數也可以起到引導作用
因此,使用EM距離來衡量訓練結果便是對GAN的一個重要改進
Wasserstein距離(Wasserstei Distance)(也叫EM距離,Earth-Mover Distance)可以用于衡量兩個分布之間的距離
對於沒有重疊的分布同樣適用,例如下面這種的
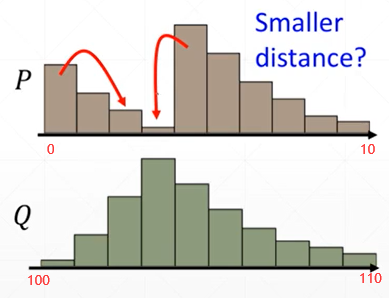
從橫軸可以看出,這兩個數據按照KL散度或者JS散度的標準,是完全沒有重疊的
現在將問題轉換一下,即使兩種分布沒有重疊,但是我們還可以讓他們形式儘可能保持一致嘛
那麼我們就可以通過”交換”上面的柱狀體來實現這個目標
可以通過「交換次數」來衡量這個行為的效率
於是問題轉換成了:「從P分布轉換到Q分布需要幾步?」
轉換需要的「步數」就是代價,可以用來衡量P分布與Q分布到底有多相似
所以,即便是完全不重疊的分布,無非就是轉換步驟很多而已,就說明他們非常不相關。
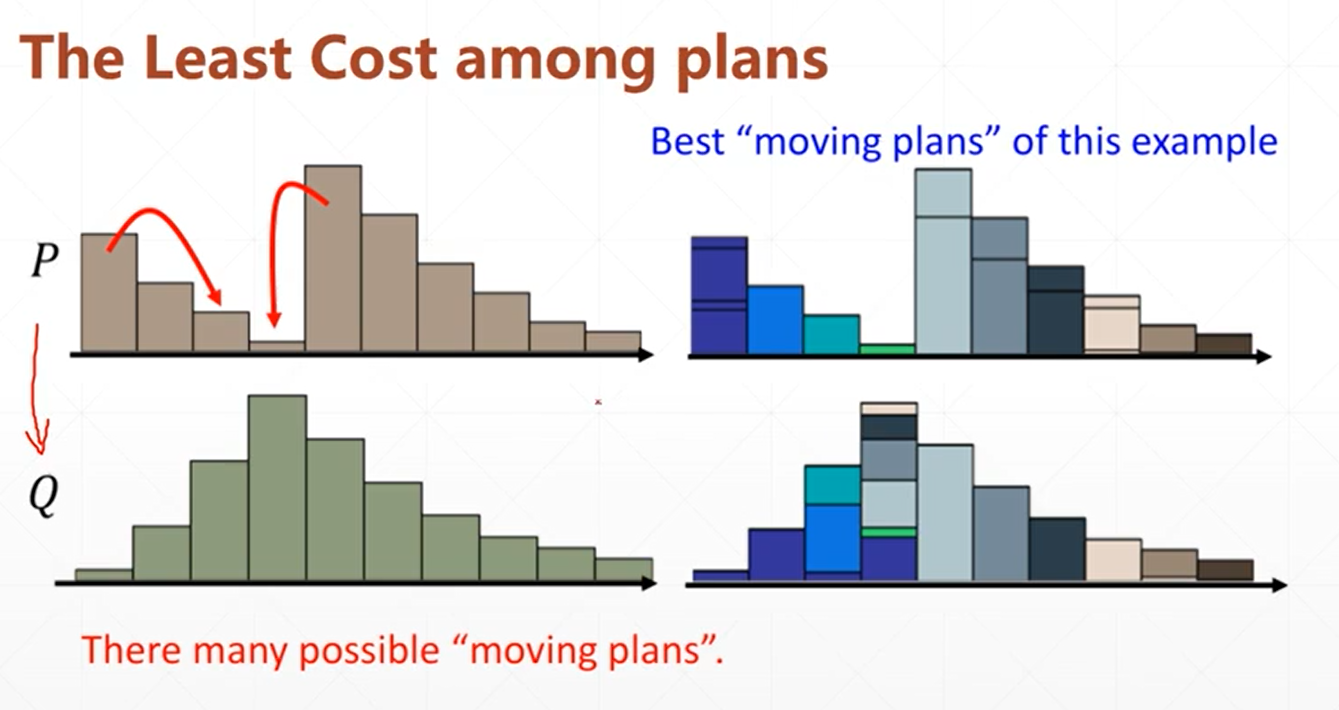
我們把柱形的移動轉換類比成「鏟土」,那麼同樣是鏟,笨方法就鏟的次數多,好方法步數少,於是我們會針對每個情況去計算最優的「鏟土方法」,用來衡量P與Q的相似度。
所以Wasserstein距離也叫「推土機距離」
計算式如下

可以看到,GAN中使用”D”來衡量分布的接近程度
這個”D”其實就是一個使用JS散度構建的神經網路層(判別器層)
而WGAN中則是使用”f”來衡量分布
“f”則是使用WD來構建的判別器層(因為WD原來是在離散情況下的,所以這裡在連續情況下使用相當於通過判別器來逼近理想的”f”,因此有約束條件)
但是有個約束條件:在f上取任意的兩個梯度x1、x2,他們的差必須小於1(圖中經過化簡了),即1-Lipschitz function
現在可以做個總結:
GAN與WGAN最主要的區別就是將JS散度換成Wasserstein距離(或者說EM距離),由此解決了GAN早期訓練時因為數據重合(overlapped)度低而出現的梯度消失問題。
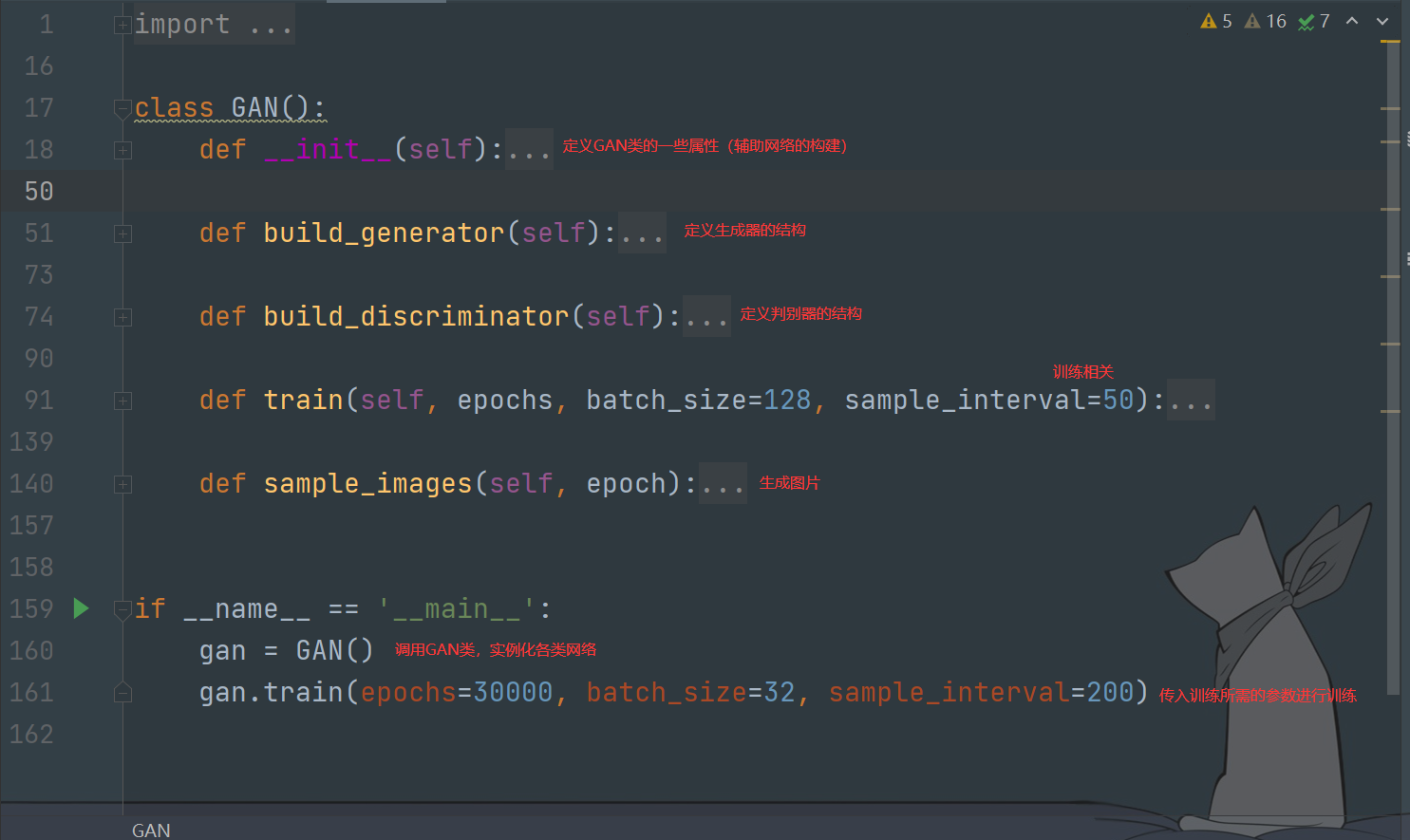
WGAN的訓練
整體結構如下
注意:經典GAN的生成器與編碼器均使用簡單的全連接層構建,而其他衍生種類GAN一般使用卷積層/反卷積層代替全連接層
3、WGAN有什麼問題
實現上面提到的設想的關鍵在於如何滿足1-Lipschitz約束
WGAN 為了實現這個約束,使用了 clip 截斷了判別器 weights
但這隻有在權重恰好合適時能夠實現(具體不推導了),並且這變相限制了這個網路的參數,進而約束了網路的表達能力。
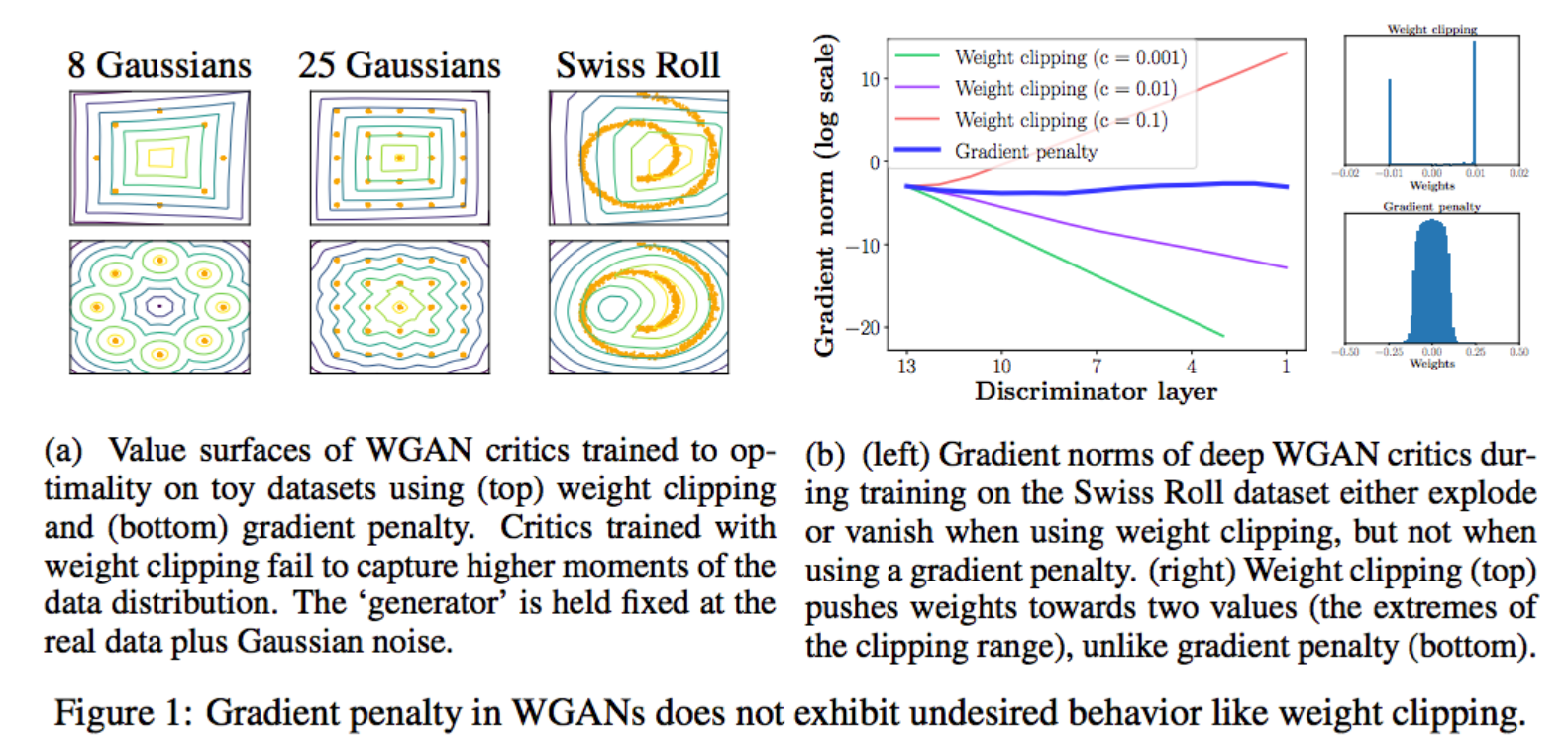
在WGAN-gp論文中,它提到了WGAN使用clip方式所引發的問題。
重點看看下面的右邊(b)這張圖,很多顏色線條那個是隨著判別器層數增加, Clip 方案中梯度傳導是有問題的,要麼爆炸要麼消失了,而 Gradient penalty 方案可以讓每一層的梯度都比較穩定。
再來看看最右邊的圖, Clip 方案網路中 weights 參數都跑到的極端的地方,要麼最大,要麼最小,而 Gradient penalty 方案可以讓 weights 比較均勻地分布。
WGAN-gp的訓練