【clickhouse專欄】clickhouse性能為何如此卓越
在《clickhouse專欄》上一篇文章中《資料庫、數據倉庫之間的區別與聯繫》,我們介紹了什麼是資料庫,什麼是數據倉庫,二者的區別聯繫。clickhouse的定位是「數據倉庫」,所以理解了上一篇的內容,其實就能夠知道clickhouse適用於什麼樣的應用場景,不適合什麼樣的應用場景。
下面本節我們就來繼續為大家介紹clickhouse的一些非常有意義的特性,來幫助大家更深入的理解ck的應用場景,以及它為什麼被稱為「性能怪獸」。
一、列式數據存儲
clickhouse的性能之所以彪悍,其列式存儲設計是非常重要的原因之一。給大家舉一個例子,假如我們現在有一張學生資訊表student
| id | name | age |
|---|---|---|
| 1 | 小紅 | 7 |
| 2 | 小明 | 8 |
| 3 | lucy | 7 |
如果這張表採用行式數據存儲,其在磁碟上的結構是下面這樣的:

如果這張表採用列式數據存儲,其在磁碟上的結構是下面這樣的:

對比上面的兩張圖我們可以看到,採用列式存儲的優點。
- 比如:我們查詢學生年齡的最大值,列式數據存儲只需要定位到年齡那一列的起始地址,然後順序讀取數據進行排序計算即可。而行式數據存儲的方式,因為年齡這一欄位的數據單元不是連續的,需要根據索引不斷的定址,或者全表掃描才能獲取到所有的年齡數據。所以在採用列式存儲時,我們需要針對某一列進行查詢過濾、統計計算性能就遠勝於行式數據存儲方式。
- 另外,因為資料庫的設計一列的數據通常是同一種數據類型,列式數據存儲有比行式存儲高達10倍以上的壓縮比,節省了大量的磁碟及記憶體空間,可以有效降低伺服器成本。
二、支援SQL並且性能卓越
目前開源世界裡的大部分的列式存儲資料庫是不支援SQL的,即使很多號稱支援SQL,其實支援SQL也是偽SQL,並且支援能力有限。
但是經過筆者的實驗,clikhouse對於標準SQL的支援已經可以與傳統的關係型資料庫媲美,雖然對於數據倉庫click house,我更建議大家使用寬表進行數據存儲,但是不代表ck不具備多表關聯查詢的能力。
可以訪問://clickhouse.com/benchmark/dbms/ ,獲取click house官方在線的針對各種數據統計型SQL的性能對比。
三、分散式分片存儲集群
clikhouse不僅支援單機模式,也支援分散式分片數據存儲的集群模式。數據以分片的行式,存儲在多台伺服器節點上面,因此ck可以利用集群伺服器的規模計算能力,快速的做出數據統計結果的響應。ck數據分片分散式存儲的機制,使得clickhouse具備了橫向擴展,海量數據分析處理的能力。
數據分片包括很多的方式,比如:數據隨機寫入不同伺服器分片存儲上、數據被發往指定的伺服器分片存儲之上、數據按照hash值進行分片、當然我們還可以自定義數據分片的方式。
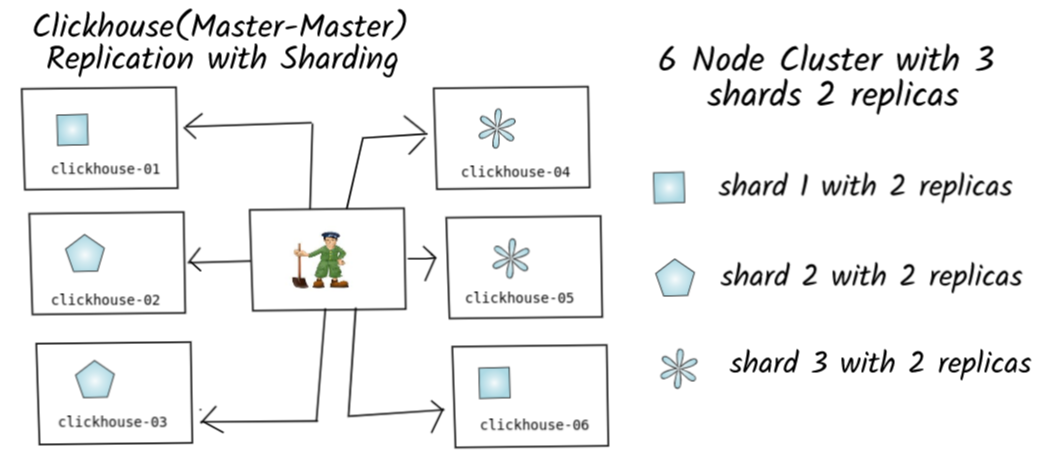
分散式數據存儲將數據分散到集群內的各個伺服器上(以分片(shard)的行式存在),為了保證數據的安全,每一個分片又有多個副本(replica),副本也是分散式存儲的,這樣即使部分伺服器宕機,仍然可以保障ck集群可用。
四、 支援按序存儲
與傳統的RMDB資料庫不同的是,clickhouse支援在建表的時候就通過sort by關鍵字指定排序欄位。這樣在數據入表的時候,實際是先進行了排序操作,按照排序欄位進行排序後的數據有序存放。
後續在進行數據查詢、過濾、統計的時候,就能夠有效的、快速的獲取連續的數據塊中的數據,提升查詢統計的性能。這種按序存儲的特性其實還是有非常廣泛的應用場景的,比如:股票K線圖都是按照交易日時間排序的,預設排序欄位、按序存儲有效的提升了統計性能。
五、支援數據TTL
在數據統計分析的資料庫中,通常我們需要數據TTL能力,也就是說:某些數據達到一定的存儲周期之後自動刪除。ck就提供了這種能力,降低了系統運維人員的工作難度。
ck支援以下幾種粒度的TTL
- 列級別TTL:為某一列設置TTL時間,當這一列中的部分數據過期之後,列值會被自動替換為默認值,全部數據過期之後會自動刪除該列。
- 行級別TTL:為某一行設置TTL時間,當某一行過期後,會直接刪除該行。
- 分區級別TTL:ck支援數據分區並設置TTL時間,當分區過期後,會直接刪除該分區。
推薦閱讀
限於博文篇幅,更多精彩內容我就不一一列舉了,推薦閱讀
《原創精品影片及配套文檔:springboot-已錄製97節(免費)》
等等等等


