Android Proguard混淆對抗之我見
關於何為Proguard,可以參考GuardSquare官網其優化業務及Wikipedia相關條目.
Proguard://www.guardsquare.com/proguard
Wikipedia://en.wikipedia.org/wiki/ProGuard
前言
本文旨在介紹兩種對抗Proguard混淆的方式.
其中一種為Richard Baumann於2017年提出的混淆還原方案,
另外一種即為本人所寫項目,此項目自然不能與前人之成果相比,
僅以之記錄我對Proguard混淆對抗之理解,
才疏學淺,獻此丑文.
局部敏感哈希與Proguard混淆對抗
2017年6月,Richard Baumann發表了標題為”Anti-ProGuard: Towards Automated Deobfuscation of Android Apps“(DOI:10.1145/3099012.3099020)的論文,其旨在利用SimHash演算法實現對Apk的自動化反混淆.關於何為SimHash,簡要來講可以理解為可用之計算兩個文本片段相似度的演算法,此處不再進行具體闡述,可以參考Google在2007年發表的論文”Detecting Near-Duplicates for Web Crawling“(DOI:10.1145/1242572.1242592).


論文第二部分中,其強調Proguard對Apk進行Obfuscating的過程是多個Transformation的集合,論文設欲混淆工程為P,而P可看作同時包含多個對象的對象集合,對象集合中包含的對象與未混淆之工程中的類,方法,成員一 一存在映射關係,作者統一稱這些對象為S.即P={S1,S2,S3…}
經過Proguard混淆後的工程設之為P’,而Proguard的混淆過程可看作一個能夠傳入任意量的Transformation函數T(x),即P’={T(S1),T(S2),T(S3)…}.可見論文強調整個混淆過程為對整個未混淆工程中各個元素進行轉換的總和(事實上也確實如此),而該思想在接下來的分析中也會多次得到體現.
而論文中的第三部分正式進入到自動化反混淆的實現部分,但由於論文中闡述的實現思路略去了很多細節,故下文不以論文進行分析,而Richard Baumann已經將自動化方案落地,在其Github賬戶ohaz下即可找到對應的POC項目(論文中並未給出其實現的項目地址,而該項目的首次commit時間最早為2016年,即早於論文發布時間).接下來以該項目具體分析自動化反混淆的實現思路.
//github.com/ohaz/antiproguard
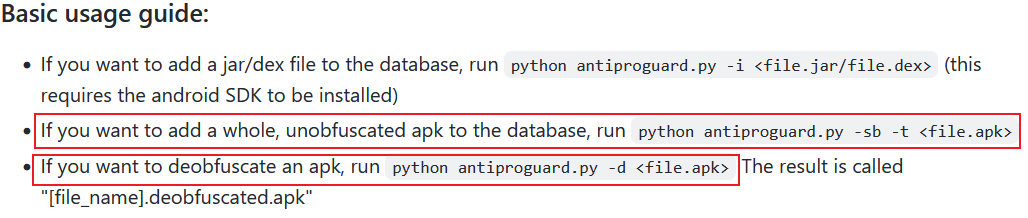

作者在其項目README文件上簡述了工具的基本使用,需要引起注意的是其工具的--sb -t參數與-d參數,其前者用於指定一個未被混淆的Apk,並將未混淆Apk之包,類,方法名及其對應的方法實體逐一抽離提取,存入資料庫,後者為反混淆的進行指定一個欲反混淆的Apk.
由於篇幅限制,下文僅對項目最核心的演算法部分進行分析,並在分析前假設一個前提:資料庫中已經填充了足夠多的未混淆Apk.
項目中antiproguard.py申明了一個關鍵方法compare,該方法用於將傳入的欲分析方法實體(被混淆)與資料庫中儲存的各個方法實體(未混淆)分別進行相似度對比,並依據相似度對比結果判斷是否生成一個hint,該生成的hint將作為輔助分析其他被混淆方法實體的依據.

可見在compare方法內,程式分別對被混淆方法實體分別生成了三個不同的SimHash值,而經過後續驗證,這三個SimHash的產生均與方法實體所對應的操作碼串有高度關聯,則此三個SimHash值的關係可以下圖進行表達.

由上圖不難得知這三個SimHash值與被混淆方法實體的關聯強度有關,並按照關聯強度以由大到小的順序排列.
接著該三值分別與資料庫中的未混淆方法實體對應產生的此三個SimHash值以論文中提到的如下方式分別進行一次計算:
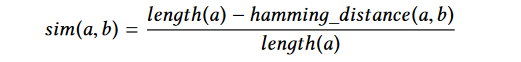
SimHash結合漢明距離,該計算方式得出的結果可抽象理解為兩個方法實體的相似程度,接著程式判斷計算出的相似程度是否大於90%,若超過該值,則判斷該被混淆方法實體與正在與之進行對比的未混淆方法實體高度相似,此時即可為下一次compare的調用產生一個hint,根據該hint以加快識別其他方法實體相似程度的速度,此處不再對hint更進一步分析.
而最終程式將對所有經過compare方法確定的與資料庫中未混淆的方法實體產生對應關係的被混淆的方法實體進行批量重命名,將其方法名’還原’為資料庫中對應的未混淆方法實體的對應方法名,簡而言之,compare方法負責確定被混淆方法與資料庫中的那個未混淆方法具有強相關的關係.
如果已經理解了compare方法,不難看出compare方法與反混淆之精細程度有著直接關係,同時也不難得出該反混淆方案的本質.既已分析過關鍵方法,剩下的分析流程我僅以一圖概之.




雖方案可行,但仍有局限之處,且看該論文的第四部分.

可見其選擇的被測試對象均為F-Droid上開放源程式碼的項目,且這些項目至少使用了一個或多個開源的第三方庫,這些開源第三方庫將在正式測試前被導入至資料庫中,以啟用Proguard優化的情況下編譯項目,以反混淆工具提供的方案處理之,雖然最終該反混淆方案正確還原的包超過了50%,但該方案依然在很大程度上無法勝任真正的逆向工程實戰.

- 其一,回顧上文對關鍵方法
compare的分析,不難發現一個需求與方案實現上的衝突,即逆向工程的本質是分析與剝離被分析對象最有價值的核心程式碼,而根據compare的實現可知其對方法實體的分析基於資料庫中數據量的多少,而能夠輸入資料庫的數據也僅限於第三方的開源支援庫(你總不能輸入一些能夠還原未開源程式碼的數據吧,這形成了悖論).

- 其二,論文第一部分明確指出,其所提出的基於相似性演算法的混淆程式碼還原方案基於資料庫中的已知程式碼,而如第一點所言,能輸入資料庫的程式碼主要來源於第三方的開源支援庫,故該論文提出的所謂通用性方案僅能對本就開源但被混淆的部分進行還原.


基於以上兩點假設一個理想情況,方案能夠還原所有被混淆的第三方開源庫程式碼,但需要明確的是,逆向工程的主要對象仍是針對軟體的業務程式碼,而市面上投放的軟體其業務程式碼量均十分龐大(想像一下如今用戶能夠從已知渠道下載的軟體,其臃腫程度導致的程式碼量可見一斑),即使能還原所有第三方開源庫程式碼,對逆向工程的幫助也是微乎其微.
DataFlow分析與Proguard混淆對抗
不論是嘗試’還原’被混淆為短位元組的方法名還是以其他方式處理被Proguard混淆的Apk工程,不難發現這些工作的本質都是嘗試輔助逆向工程人員’理解’被混淆方法實體,排除無意義短位元組的干擾,以減少逆向工程中抽離出有價值程式碼的時間成本.
基於該思想,我曾於21年4月份編寫並開源過一個項目,該項目的主旨是通過分析被混淆的成員與成員,方法,類之間的關係,讓逆向工程人員快速判斷被混淆成員是否具有被分析價值,但由於當時該項目不與任何現有工具聯動,且分析對象僅針對成員,職能單一,在逆向工程中發揮的作用不大,故在今年(22年)5月對部分程式碼重構,拓展了項目職能,目前可以與著名逆向工程工具JADX進行聯動,且分析對象由單一的成員拓展至方法,可通過分析欲分析方法中的參數在被標記為污點的情況下的向下傳播方向,即DataFlow分析.
//github.com/MG1937/AntiProguard-KRSFinder


而該項目的實現本質無疑是分析整個Apk工程的Dalvik操作碼,為操作碼分配相應的句柄以具體處理操作碼的操作對象,並依據處理結果進一步分析Apk內各個類的成員與方法,生成對應的分析報告用以聯動JADX.(關於Dalvik操作碼,可以參考Gabor Paller於2009年提供的Dalvik Opcodes).
像Dalvik虛擬機一樣思考
分析Apk無不分析其Dex,分析Dex無不Dump其IR,得其IR,何如?
正如前文所述,該項目旨在通過分析成員間關係與DataFlow以輔助逆向工程,然則不論如何分析,深入到Dex文件其操作碼總是必要的.雖從Dex中獲取Dalvik操作碼的方法有千百種,但論如何處理操作碼及其處理思想,固然是要引Google之鑒的.然則自Android5.0開始,Google就棄用Dalvik轉而以ART虛擬機處理Dex,但ART絕大情況下使用AOT技術,僅於技術需求而言,該項目對操作碼的處理思想必然要取JIT之鑒,故該部分將分析Dalvik虛擬機處理位元組碼的部分實現,進以指導項目實現.
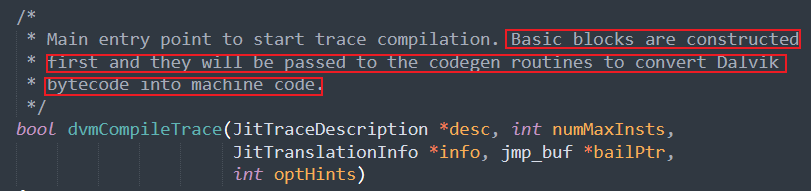
以Android-4.0.1_r1分支下的Dalvik虛擬機源碼為例,Dex實例將流入Frontend.cpp文件下dvmCompileTrace函數,該函數正是將Dalvik位元組碼轉換為機器碼的入口函數.
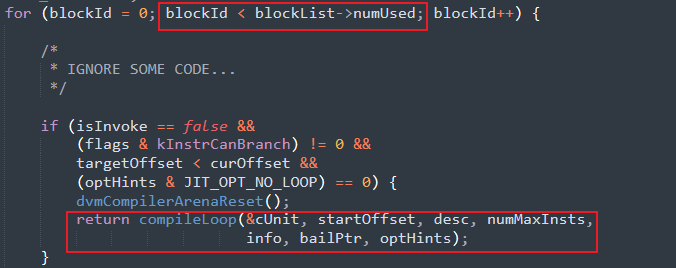
該函數不斷遍歷包含位元組碼的基本塊,最終將攜帶Dalvik位元組指令的cUnit成員引用傳入compileLoop函數下,而compileLoop函數最終將引用傳入CodegenDriver.cpp文件下的關鍵函數 dvmCompilerMIR2LIR,顧名思義,此函數將Dalvik位元組指令處理為LIR,最終由其他方法處理LIR為機器碼.
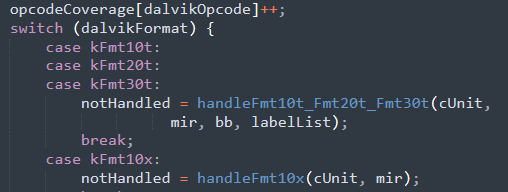
dvmCompilerMIR2LIR函數下cUnit成員引用中攜帶的Dalvik位元組碼被傳入dexGetFormatFromOpcode函數下處理為dalvikFormat成員,最終該成員被傳入一個巨大的switch-case塊中進行處理,該switch-case塊根據dalvikFormat成員為cUnit成員分配對應的處理句柄(handle)以具體處理其攜帶的Dalvik位元組碼即其操作對象(即暫存器).
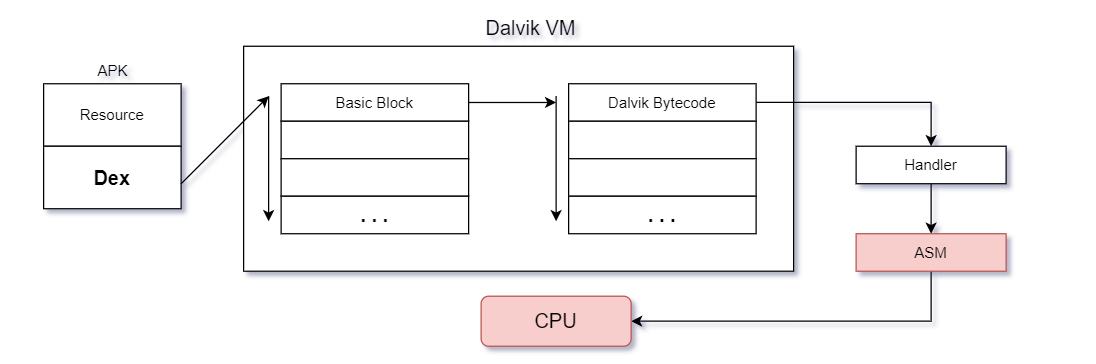
至此,Android4.0 Dalvik虛擬機處理位元組碼的大致流程已經分析完畢,如上圖流程圖所示,該流程及其Dalvik位元組碼處理思想將被運用到接下來的項目結構中.




項目實現
項目已經開源,可至AntiProguard-KRSFinder下查看項目具體程式碼.
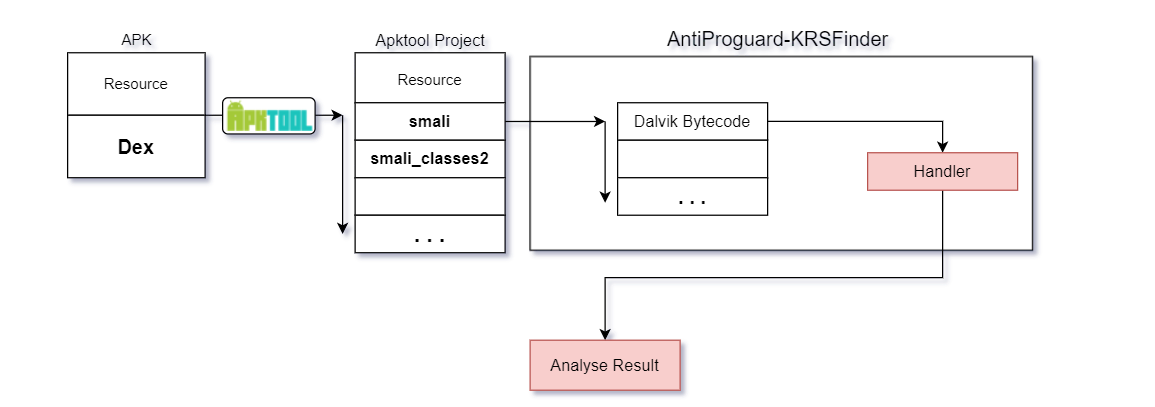
基於前文對Dalvik虛擬機處理位元組碼的流程分析,基於Dalvik思想繪製如上流程圖,該圖所示流程在項目正式開始前被作為理想流程框架用以指導項目進行,並且在已經完成的項目中其對位元組碼的大致處理流程也接近該理想流程框架.


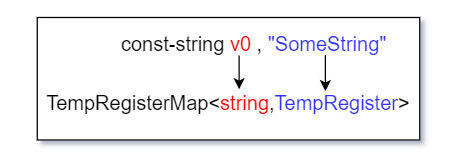
由Dalvik虛擬機源碼下docs文件夾中文檔的部分描述可知Dalvik虛擬機是基於暫存器的.故項目也需要一個組件用以儲存暫存器,該組件即為項目中TempRegisterMap.cs文件下的TempRegisterMap類.而該組件本質上是一個Dictionary對象,該組件其鍵為Dalvik操作碼具體操作的暫存器其名(即p0,v0…),其值為TempRegister對象,該對象即代表一個具體的暫存器,此暫存器目前僅需要儲存字元串與方法.下圖為該組件大致結構.


下面部分為項目對單個Dalvik位元組碼處理部分,該部分模仿了Dalvik虛擬機處理位元組碼的模式.
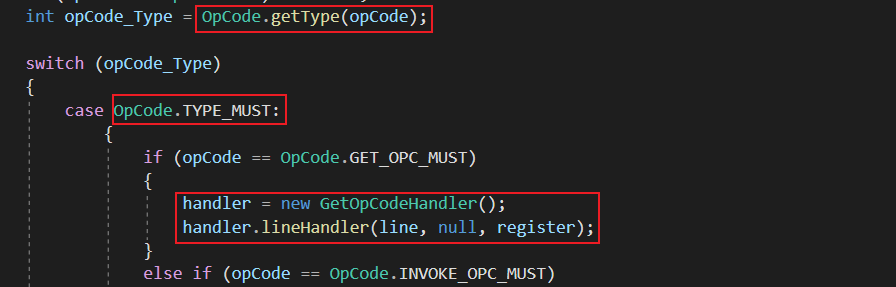
上圖為項目下MethodCodeAnalyseModule.cs文件中MethodCodeAnalyseModule類的methodAnalyse 函數,該函數為項目處理操作碼的正式入口,可以看到該部分我效仿Dalvik虛擬機處理單個位元組碼的流程模式,為即將處理的操作碼分類,並為之分配處理句柄以具體解析操作碼及其攜帶的暫存器,值得一提的是該函數的實現並不完全與Dalvik虛擬機處理操作碼的形式相同,在正式為操作碼分配處理句柄前,我將操作碼的處理優先順序以 MUST,CHECK,PASS 劃分,被賦予MUST優先順序的操作碼將被優先分配處理句柄,賦予CHECK優先順序的操作碼將在檢查其具體操作的暫存器是否有必要處理後再為操作碼分配處理句柄,賦予PASS優先順序的操作碼將不進行任何解析,以此略去部分不必要解析的操作碼,以加快整個流程的處理速度.

在正式進入下個部分前,有必要闡述清楚函數中方法區塊(以下稱為塊)的含義.
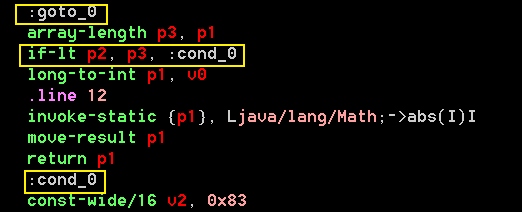
Dex中以MIR形式儲存的函數不僅以多個位元組碼組成的串形式保存,單個函數也可被分為多個塊,即以多個塊組成一個函數,欲簡單理解塊,可以ASM中的JMP指令為參考,JMP指令可以跳躍到記憶體中的任意地址,而在Dalvik中則以塊為跳躍對象,即在Dalvik中以塊為基本單位組成執行流程.以市面上常見的工具抽離Dex其操作碼串,輸出的結果中大多以高級語言中Label的形式表示函數中的塊,如下圖為帶有多個塊的函數片段.

下面部分為項目對單個函數的處理部分.
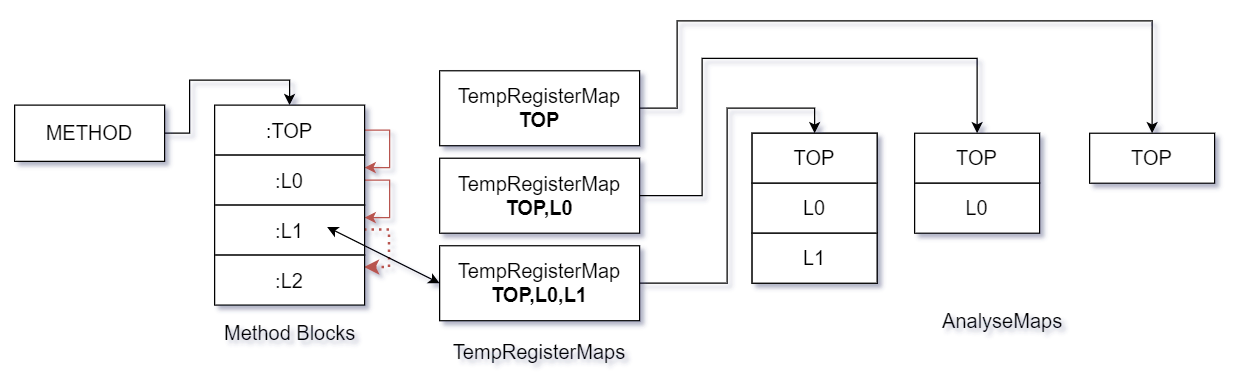
先假設項目即將對一個函數進行處理,且該函數被分為數量未知的多個塊,而上圖所示流程即為項目在該情況下的大致處理流程,假設一個理想情況,此時塊與塊之間沒有任何指令使得程式跨塊跳躍,即執行流程從塊頂部向下執行直到方法結束,那麼項目將在每個塊執行結束時,立刻截取當前塊的暫存器集(即TempRegisterMap組件)快照,並且記錄當前的執行路線,以暫存器集快照為引索保存每次執行路線,那麼在該執行流程下,暫存器集將以如下圖情況保存.
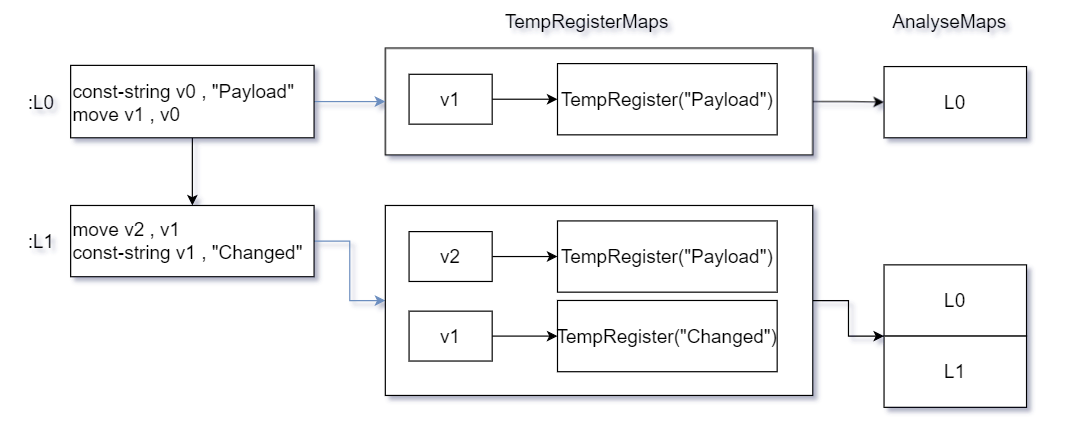
那麼此時假設塊與塊之間出現了一個或多個流程式控制制指令(如if,goto).


- 若流程式控制制指令為
goto指令,項目將標記其操作對象為強行跳轉目標,並繼續向下執行,但不具體解析非強行跳轉目標的塊,直到目標塊被找到才具體對塊中操作碼進行解析. - 若為
if類指令,項目將僅對其操作對象進行標記,而不令項目強行尋找目標塊,正常向下執行並解析塊.
以如上兩種流程式控制制方法儘可能覆蓋到大多數由流程式控制制指令導致的未知數量的解析路線.
假設塊與塊之間出現了數量未知的goto指令,此時處理流程將為下圖所示.
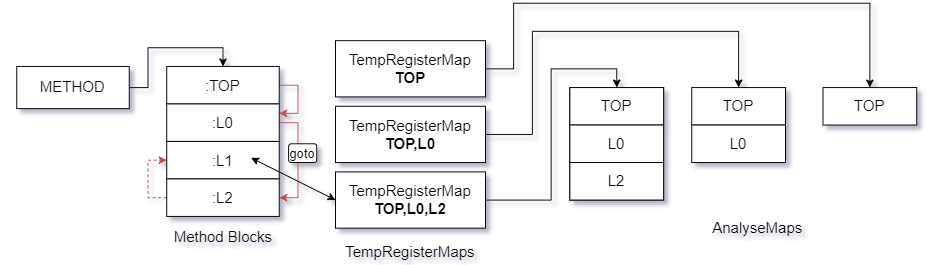
從流程上來看似乎處理過程沒有太大變化,但此時構造一個在Dalvik執行流程上能夠影響暫存器內容的函數片段,此時且看下圖處理結果.
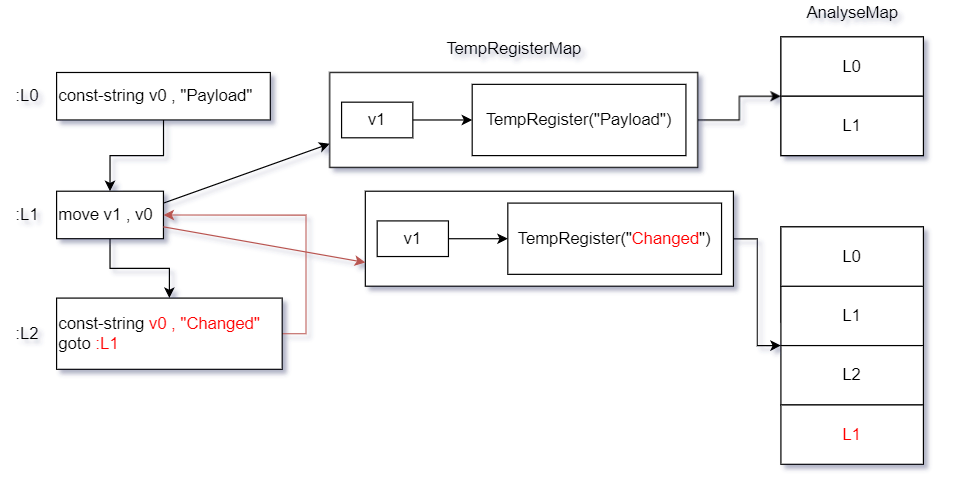
項目對流程的控制及暫存器集快照保存的作用就在此體現,從上圖給出的函數片段可知塊L1中的v1暫存器為執行流程所改變,若不保存暫存器集快照,就不能夠完全記錄暫存器的前後變化.
上文即為項目對單個函數的大致處理流程,該部分也是項目最核心的部分,不論是成員關係分析還是DataFlow分析,其結果的精確度都依賴於此,更多細節不再在此文寫出,至此,本文完結.





