李卓豪:網易數帆數據中台邏輯數據湖的實踐
- 2022 年 5 月 28 日
- 筆記
- DataFunTalk, 人工智慧, 大數據, 演算法

導讀: 本文將介紹過去15年中,網易大數據團隊在應對不斷湧現的新需求、新痛點的過程中,逐漸形成的一套邏輯數據湖落地方法。內容分為五部分:
- 關於網易數帆
- 為什麼做邏輯數據湖
- 怎麼做邏輯數據湖
- 未來規劃
- 精彩問答
—
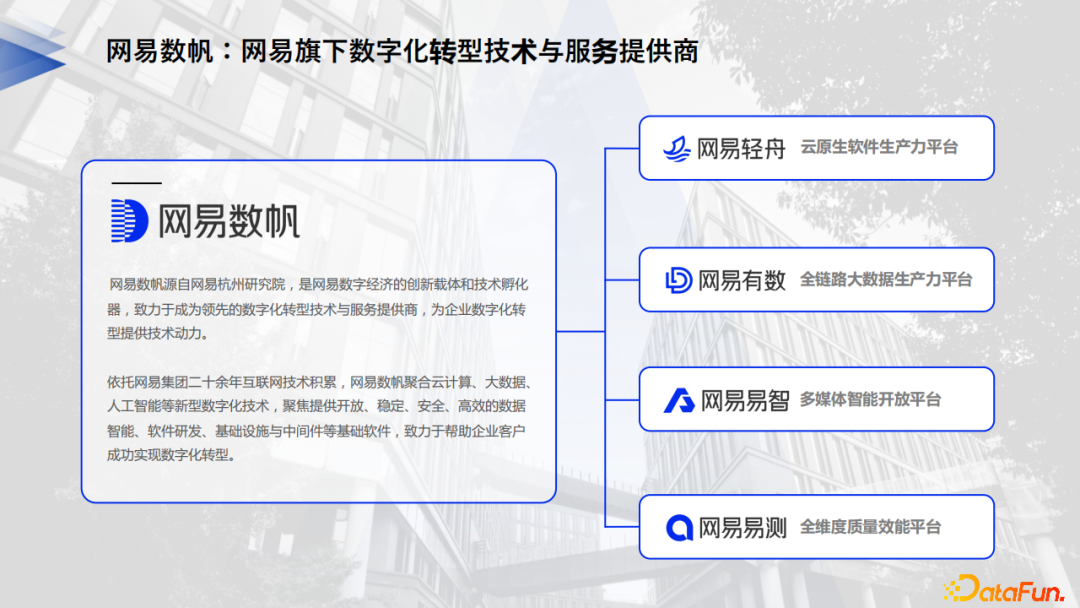
01 關於網易數帆
網易數帆是從網易杭州研究院孵化出來的。網易杭研的重要職責是公共技術的研究和產品孵化。下圖是網易數帆的整體產品架構。
1. 網易大數據發展歷史
網易是中國領先的互聯網技術公司,從2006年就開始對大數據相關技術進行探索。2009年為了支撐網易部落格等產品的海量數據,開始了分散式文件系統、分庫分表中間件(網易DDB)等技術的研發,並且於當年引入了Hadoop進行探索。2014年到2017年,網易對大數據平台的建設在內部取得了良好效果,同時發現業界存在普遍相似痛點,於是開始對外做商業化嘗試。2018年支援網易嚴選、考拉、音樂、新聞數據中台構建。通過在商業化過程對市場需求的摸索實踐,終於在2019年形成了「全鏈路數據中台」解決方案,致力於將「數據生產力」的理念能力落實到解決方案中。
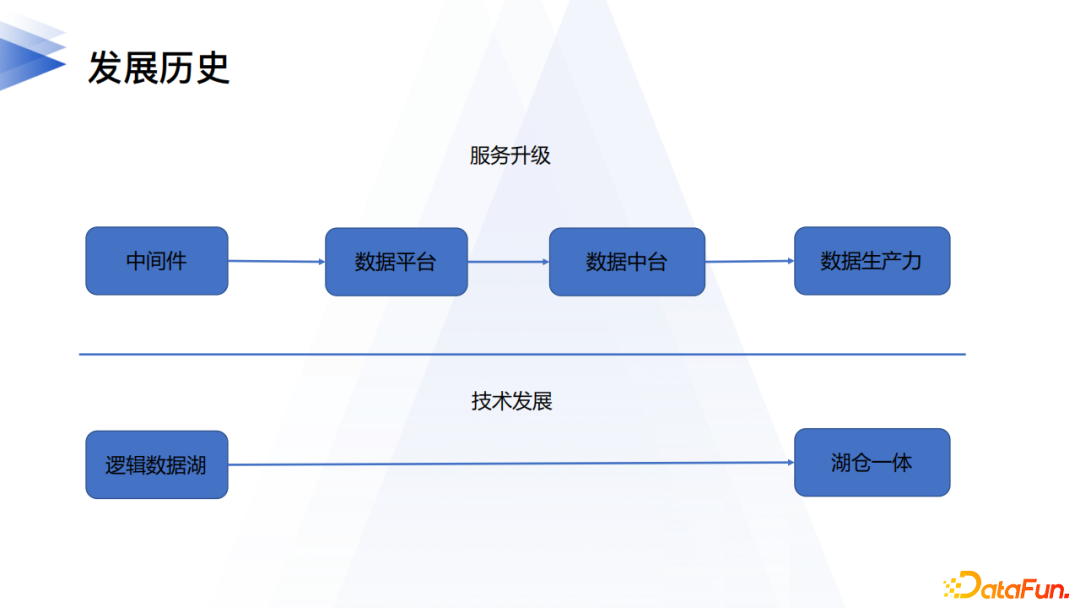
縱觀網易大數據的發展歷史,可以看到這個過程中貫穿了數據理念的變化。有數從公共數據平台逐漸轉變為具備有業務屬性的數據中台,最後逐步向「數據生產力」理念靠攏。在這個理念下,會要求我們要不斷貼近用戶、了解用戶實際情況,做到第一時間提供更好的服務。同時在服務用戶的過程中,為了給用戶提供更多價值交付,邏輯數據湖的產生是必然的。這個過程從技術發展角度看,也伴隨著湖倉一體的探索和落地。
2. 業務支撐情況介紹
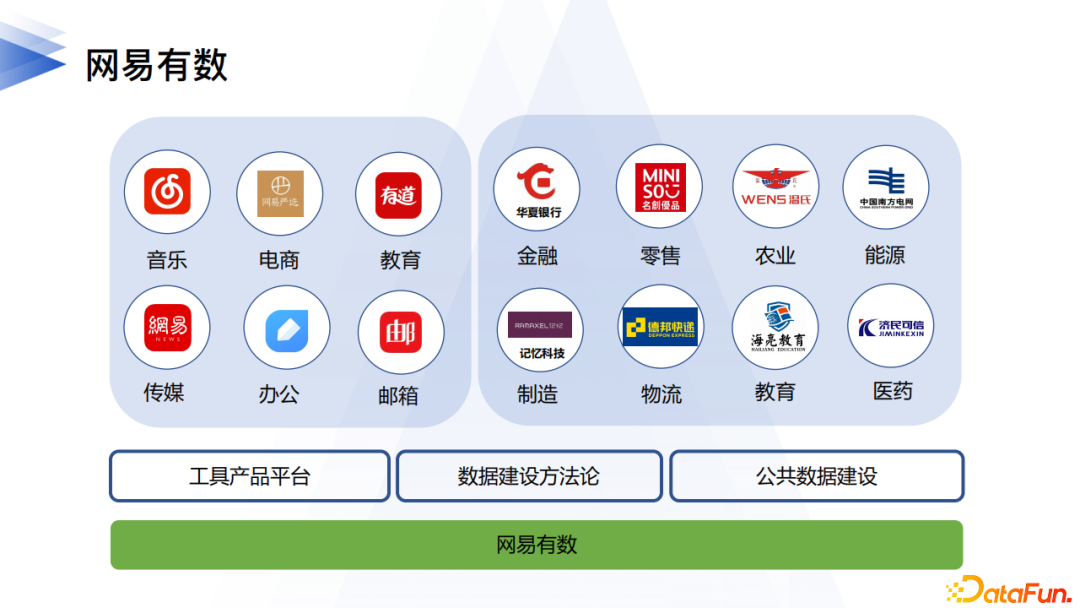
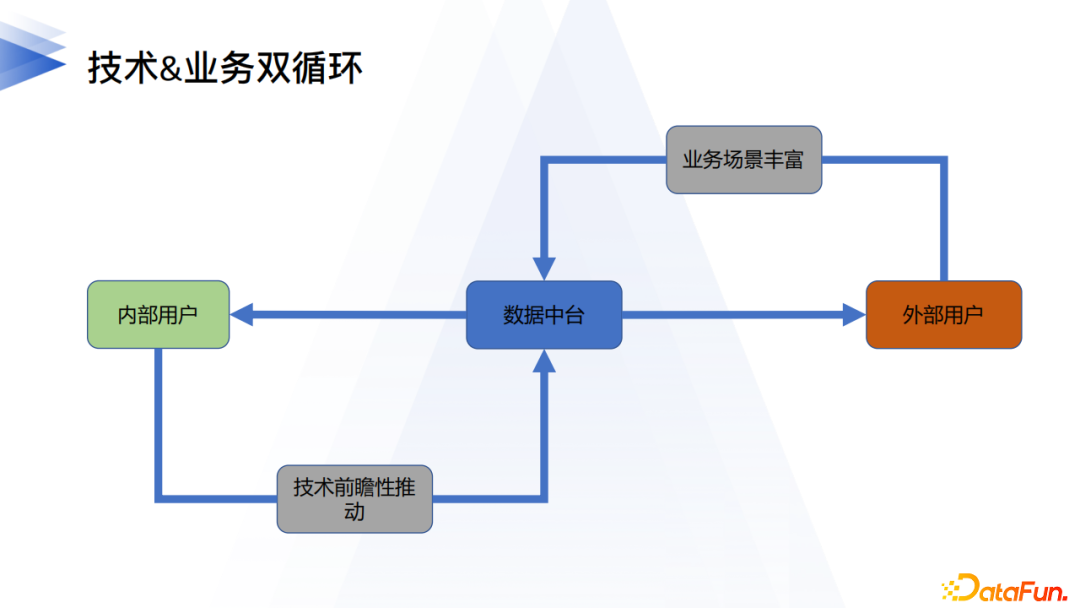
上圖最上層是網易有數對公司內外提供的業務支撐情況。網易有數的技術能力通過一套方法論、一個工具平台和公共數據建設三部分對上層輸出整體的價值。同時在落地過程中,形成了技術業務雙循環的模式。雙循環中涉及三個角色,兩種驅動力。三方分別是內部用戶、外部用戶、數據中台;業務場景、技術前瞻是推動雙循環的驅動力。這兩種驅動缺一不可:大數據技術和應用發展日新月異,數據中台的業務支撐能力特別依賴於底層的技術能力和前瞻性。
—
02 為什麼做邏輯數據湖
1. 數據生產力不足的問題
網易有數最早想要提升數據生產力是從建設數據開發平台開始的。在建設使用過程中暴露出各種問題導致了數據生產力不足:
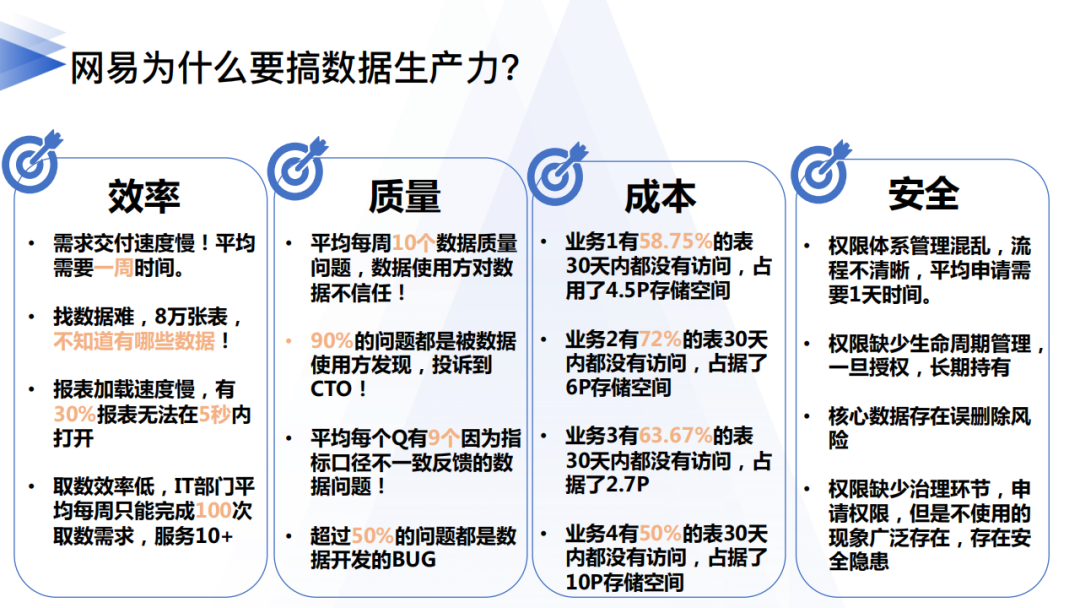
2. 數據生產力低下的原因
在梳理了數據開發平台碰到的問題之後,我們開始思考問題的根本原因是什麼。最終結論就是:這不僅是一個技術問題,更是產品體系問題。我們缺少一套貼近需求的數據產品力體系。這也是業內的數據平台在業務支撐中的普遍問題。
所以我們重新打造了我們的產品體系來保證整個數據應用的生產力落地,第三部分會展開來講我們如何通過構建邏輯數據湖來支撐這套產品力的落地。
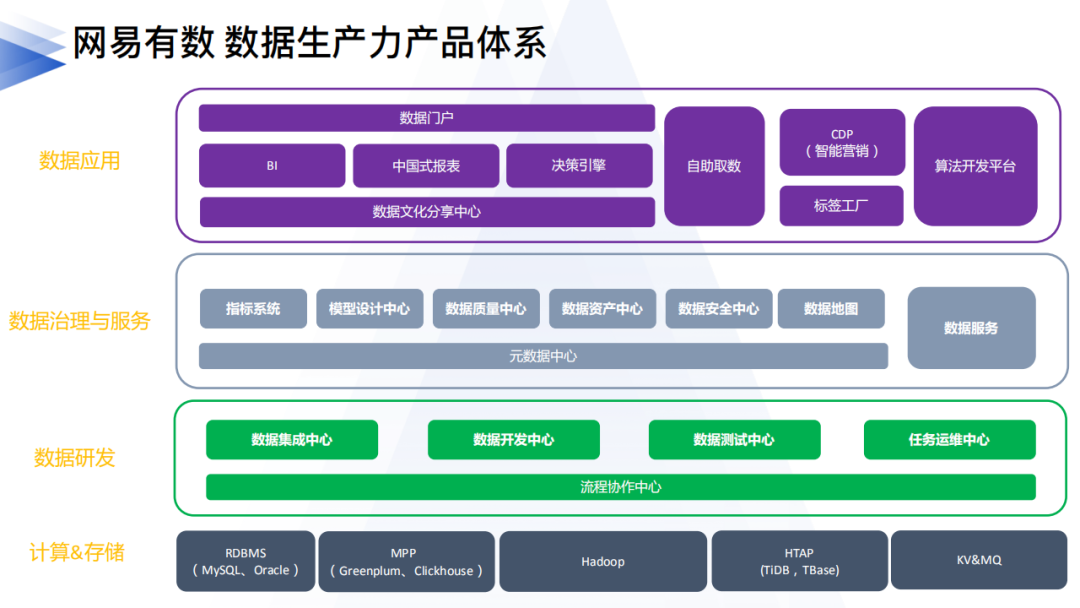
3. 數據生產力支撐——大數據底座

最近十幾年大數據相關技術的發展主要是基於開源的技術構建,我們團隊也以主動積極的態度看待開源,爭取回饋社區。我們積極培養技術專家,參與社區建設,輸出技術貢獻;這些幫助我們夯實了大數據的底座。
4. 數據生產力方法論
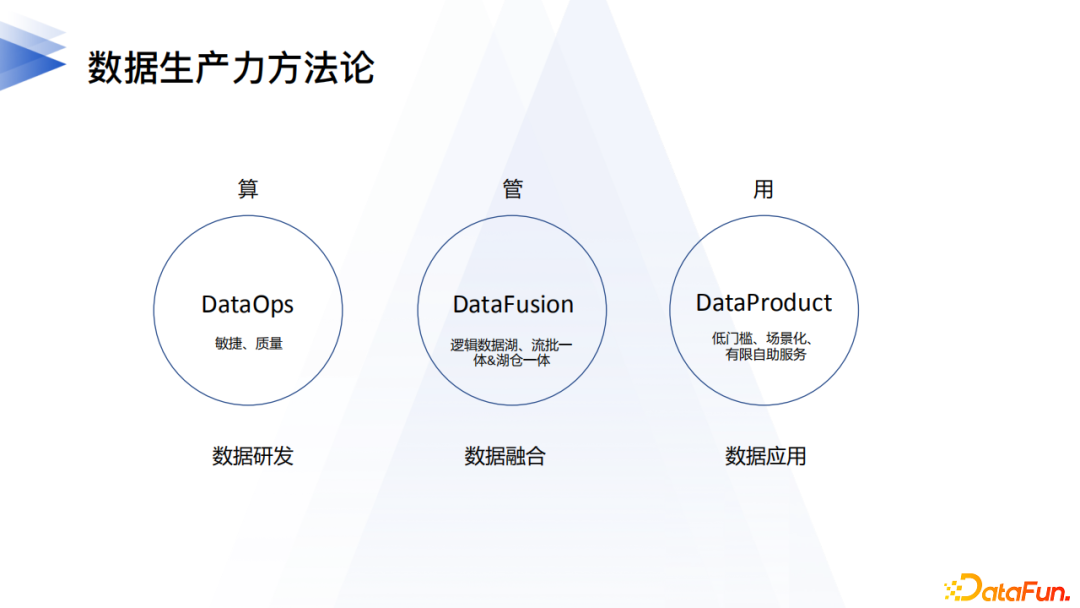
數據生產力建設的方法論,我們從上圖的三個維度來表達。首先是算,讓數據研發足夠敏捷保證工程效率和品質;其次是管,讓不同類型不同來源的數據融合,統一抽象對外表達;最後是用,做到低門檻,用戶不需要關心底層的情況,這很符合用戶的使用場景。
5. 數據生產力提升成果
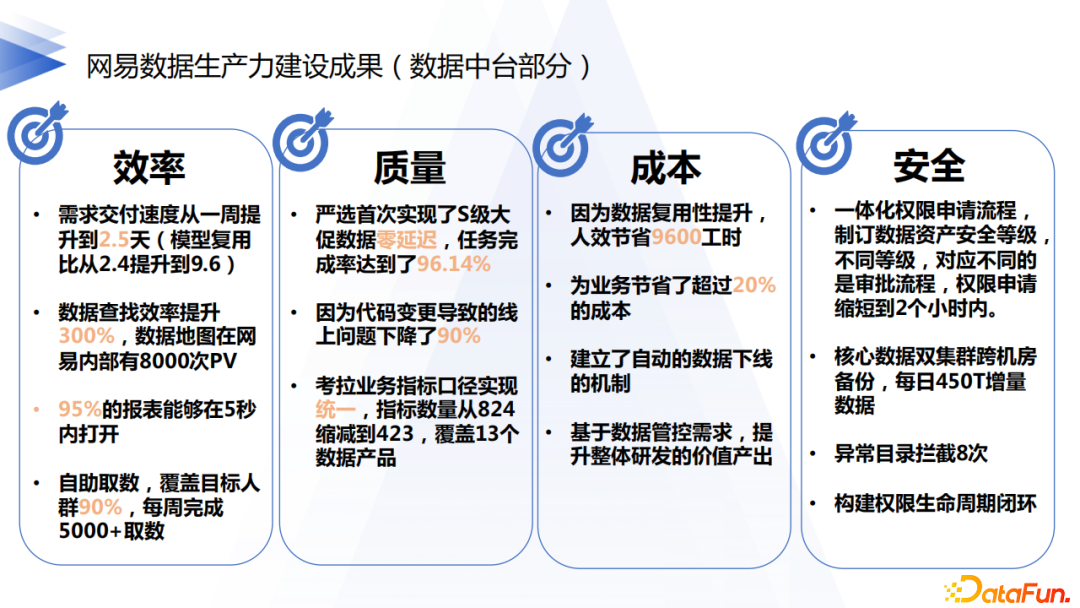
6. 數據產品建設成果

除了在技術指標層面的成果衡量,數據生產力建設在業務系統中也體現了巨大的價值。上圖是浙江衛視對我們在電商業務數據生產力提升的成果報道:切實提升了業務運轉效率並且產生了良好的社會和經濟價值。
7. 產品核心優勢
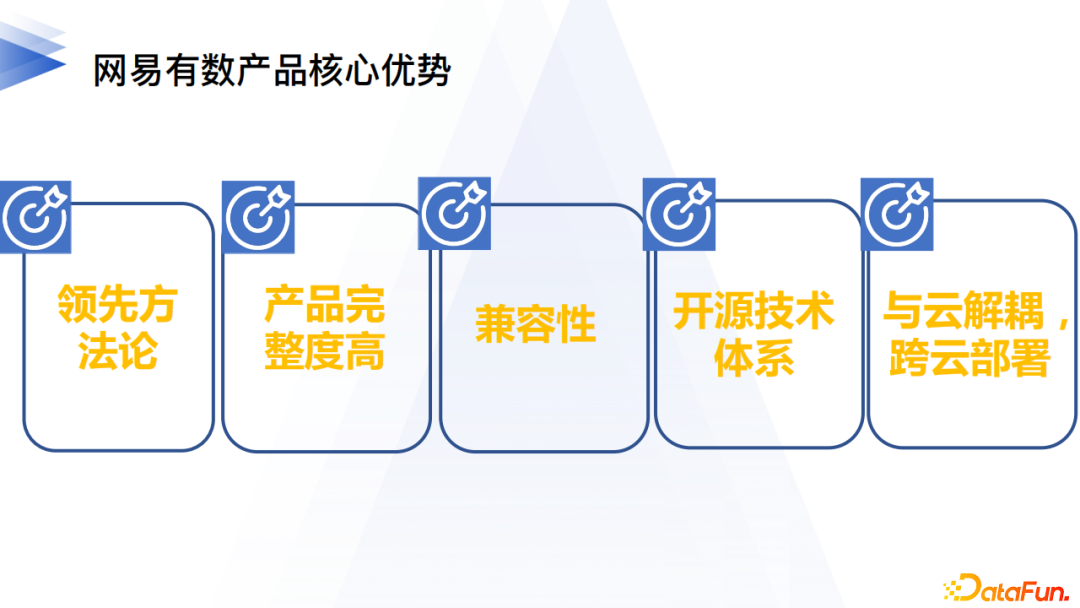
有數產品的核心優勢從方法論開始,對於複雜的產品系統建設,理論先行。基於生產力方法論我們建設了完整度很高的產品體系;產品同時具備良好的兼容性;基於開源技術體系做到了支援跨雲部署。
8. 企業用戶的靈魂拷問

開始商業化後,有數在調研外部用戶需求的過程中,經常會碰到上圖中的三個重要問題。
這個三個問題都非常實際,因為相比傳統的IT系統,大數據體系的技術架構還是要複雜一些的。
第一個問題是對業務的擔心,技術是對業務的支援,每個企業用戶的技術建設情況不同,業務複雜度也不一,很多傳統企業已有的IT系統已運行了很多年,只是無法再支援日益增長的數據需求,他們在大數據技術體系的經驗幾乎空白,當面對一個比如lambda架構的大數據解決方案時,往往會覺得過於複雜和難以掌握,對落地成效心存疑慮。還有部分用戶的業務在現有技術框架上(比如MPP)運行良好,出於對未來發展的前瞻性考慮,需要提前進行大數據的基礎技術建設,這部分用戶對於大數據未來的必要性是肯定的,但是會特別關心其適用的場景、業務覆蓋度以及如何平滑地進行業務的遷移。在我們與用戶的合作中,有很多行業標杆用戶,通過幫助標杆用戶建設數據平台過程,我們也逐漸積累了很多行業經驗,在和後續其他用戶的合作中通過組織培訓和實施的方式和客戶一起把方案落地,但是這個過程需要一定的成本,並且需要逐步給用戶信心。
第二個問題也是用戶非常關心的問題。再優秀的系統,也都是需要運維的,對於用戶而言他們非常關心數據平台能否自主運維(至少能參與基礎的運維),一方面這個是企業內部的硬性要求,一方面私有化部署模式下這也是一種良好的合作共建模式(特別是某些環境是閉網部署)。這個問題就涉及到:系統整體複雜度、運行狀態透明程度、以及運維團隊是否好組建等多個維度的考量。對於運維,網易內部有多年的經驗沉澱,總結了豐富的培訓教材,同時也開發了便捷的運維工具,通過分享和培訓,基本能夠讓用戶進行基礎的運維操作,但是總體而言用戶還是需要有一個學習的時間成本,很多情況下用戶已有的運維團隊對於老系統已經積累了很多經驗,技術架構一刀切的方式對原有團隊穩定性的衝擊也比較大。
第三個問題來自於這部分用戶:他們看中的是解決方案中的產品體系。有數的產品功能能夠解決他們在數據工具、數據管理和數據賦能上的痛點。但是並非一定需要Hadoop數據底座,產品功能和底層集群不需要強綁定。這也是我們做邏輯數據湖的重要出發點之一,滿足更多類型用戶的實際需要。
以上的這三個問題,都可以通過邏輯數據湖的技術方案來解決。
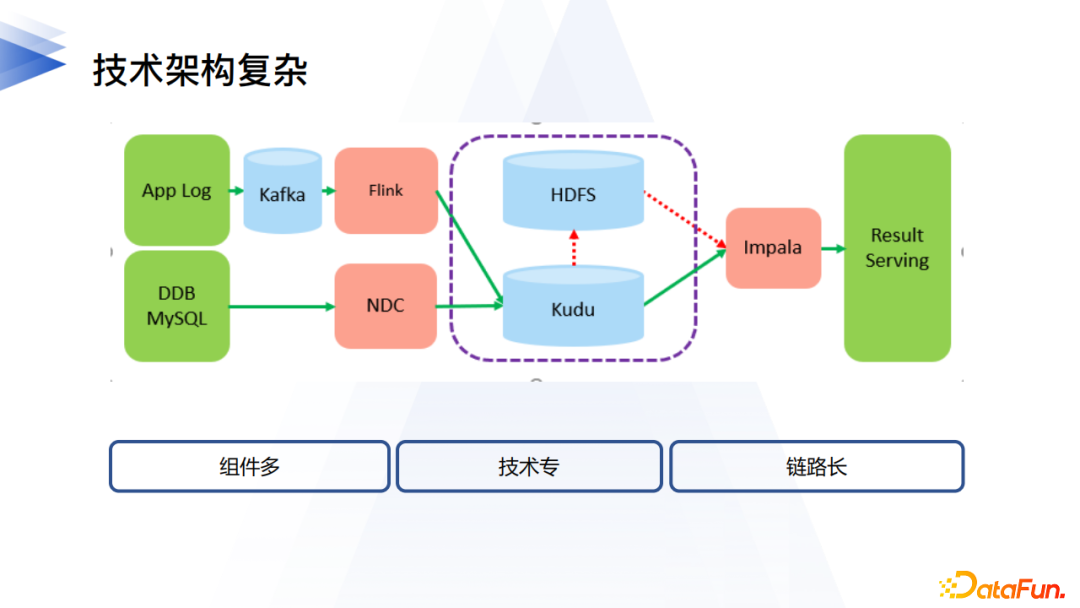
上圖是一個常見的實時數倉解決方案,在互聯網公司應該是非常常見的。這樣的架構明顯的特點就是:
組件多:多種數據源、CDC、消息隊列、實時計算框架、存儲系統、Adhoc查詢系統等等;
鏈路長:從數據源到最後數據結果產出,至少需要3-4個步驟;
技術專:每個組件都可以有專門的團隊來研究運維。
得益於大廠完善的基礎建設、業務量級以及人員儲備,這樣的模式還能相對順暢得運行,但是對於一般性的傳統企業而言,學習和運維壓力還是非常大的,哪怕是隨著湖倉一體技術的發展,整體的架構可以持續簡化,也難免心生敬畏,因此在必要的場景採用必要的技術,是對用戶的一種負責。
9. 為什麼要做邏輯數據湖
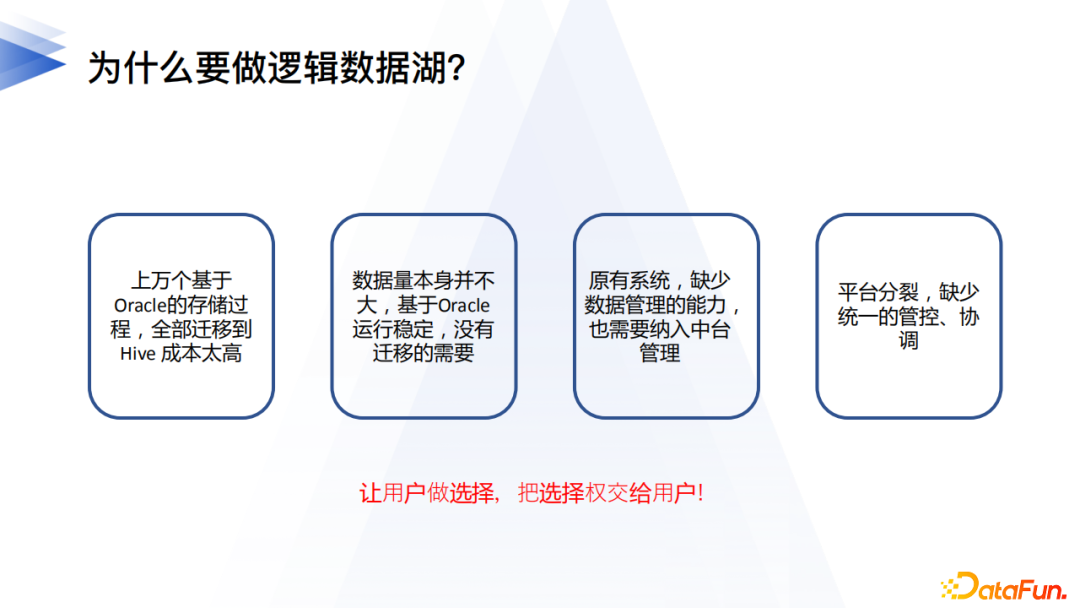
以上是我們在調研企業用戶數字化轉型中,對相當比例用戶痛點的總結。在實現數字化轉型的過程中,數據湖&Hadoop解決的是數據統一匯聚的問題,而統一元數據則是解決數據連接、資產、管理的問題,對於相當部分的用戶而言,當前最大的痛點不是海量數據的存儲,而是如何將散落到各個子數據系統的數據孤島統一管控起來。因此通過構建一個邏輯層面的數據湖,實現統一的元數據+分散的物理存儲,避免不必要的物理數據入倉(湖),從而將產品上層功能比如主題域構建、數據地圖等等及早給用戶使用才是解決問題的根本之道,邏輯數據湖方案,依然可以使用物理湖&Hadoop,同時提供通過虛擬表直連數據源的方案將其他類型的數據源也納入平台的管控中,用戶可以根據實際的需要選擇適合的存儲方案,把選擇權還給用戶。
10. 網易有數產品特色

以上是網易有數的十大產品特色能力,其中「流批一體&湖倉一體「對標的就是Lakehouse,而邏輯數據湖的目標是讓其他8個產品能力跑在不同的數據源上,實現中台數據治理能力和底層存儲架構的解耦,讓即使使用傳統數倉技術的用戶也能享受到數據生產力的福利。
—
03 怎麼做邏輯數據湖
1. 邏輯數據湖構建方法論
關於如何構建邏輯數據湖,我們的構建方法論主要分為如下三個大的層面:
數據源支援類型:除了Hadoop(Hive)體系,MPP、RDMS、HTAP、KV、MQ等都需要支援,並且一視同仁,都可以作為具體邏輯數據湖具體對象的物理存儲。
統一數據源 & 統一元數據:統一數據源要做的是規範每種數據源的登記註冊,包括數據源URL格式、數據源Owner、唯一性校驗、帳號映射、聯通性校驗、支援的版本、特定的參數等;統一元數據,則是將數據源的技術(物理)元資訊和業務元資訊進行關聯,提供統一的查詢修改介面。
統一數據開發、治理和查詢分析:這三個屬於構建在統一元數據&數據源基礎之上的應用層。統一的數據開發,包括不同物理數據源之間的交換、離線&實時開發、同源&跨源查詢;統一的數據治理,則包括數據主題建設、許可權管控、數據生命周期、資產地圖等;統一查詢分析,則是在完成數據主題建設、數據開發產出以後,提供同源&跨源的模型分析能力。
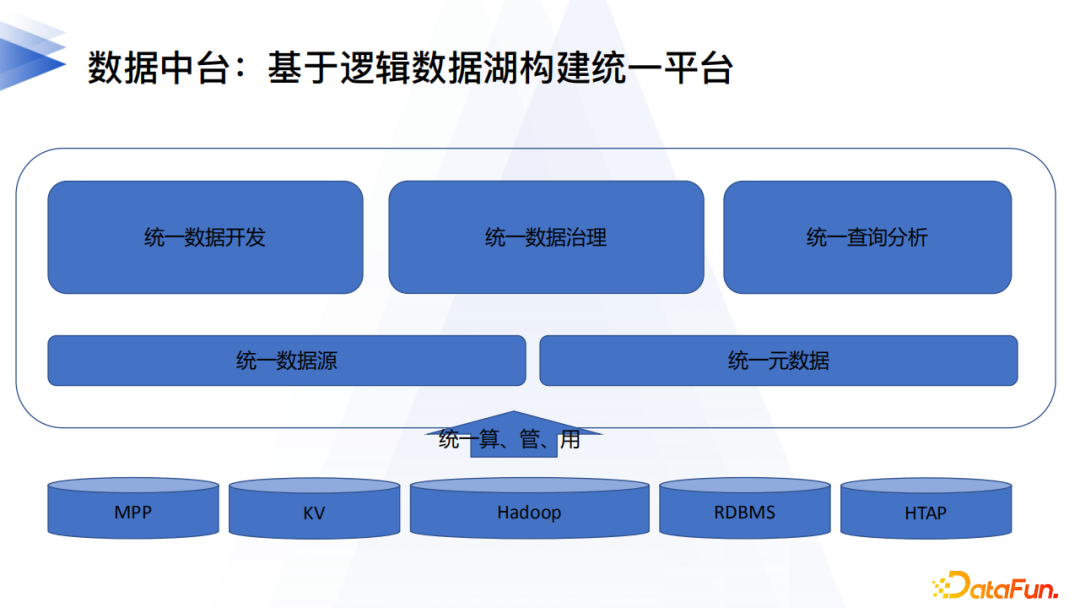
上圖中最底層就是各種類型的數據源,通過統一元數據和統一數據源層,完成上層應用和資源層的解耦。對上層提供統一的計算、管理、應用的功能。上述這些就是我們構建邏輯數據湖的方法論。
2. 統一元數據
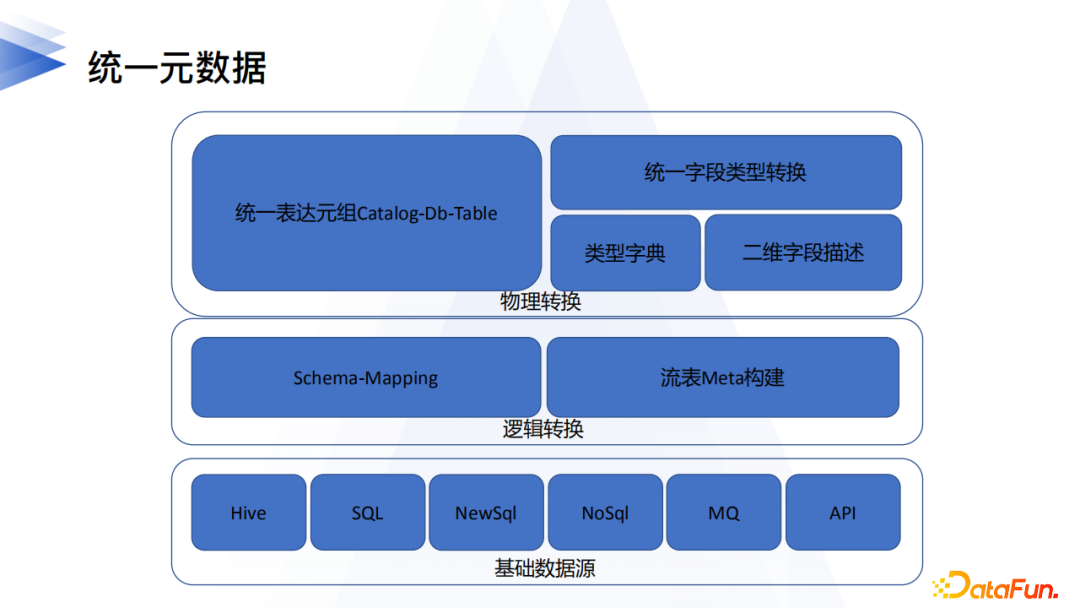
根據上一節講到的邏輯數據湖構建方法論,第一要務是構建統一元數據。統一元數據,也可以叫做元數據中心,其實無論是物理湖,還是邏輯湖,都需要這麼一個元數據中心的組件來統一管控湖中所有對象元資訊。他的功能有點類似HMS,但是在業務維度和數據規模上會比單一的HMS大很多,因此在存儲設計上可擴展性需要重點考慮。元數據中心組件主要有如下幾個核心功能:
(1) 數據源資訊的管理
負責存儲各類數據源的接入登記資訊,進行統一的合法性、連通性校驗,確保數據源的可用性。除了支援傳輸的數據源,還需要支援API網關等。
(2) 元模型的設計,主要有3點:
a) 抽象設計通用的數據對象描述meta-schema(比如catalog-db-table類似的三元組),meta-schema除了要考慮基礎的物理對象資訊以外,還需要考慮業務層面比如同catalog有多環境的場景;其次要將不同的類型的數據源schema擬合映射到meta-schema中,需要注意的是不同的數據源,即使是相同的名詞其邏輯概念會有很大不同,比如Database這個名詞,在MySql和Oracle的實際作用就完全不同(Oracle是通過User/Schema來劃分資料庫對象的邏輯歸屬),某些Newsql系統也有類似的問題,這些細節都需要處理好。
b) 流表的構建,主要針對一些schema free的數據源,比如MQ、KV系統等。這些數據源缺乏結構化的消息體描述,但是在實時計算等場景卻有重要的作用,我們在原有的數據對象(比如Topic)上創建流表,一方面可以讓數據開發一目了然地知道消息體的詳細格式,一方面也為數據開發SQL化奠定了基礎。對於流表除了schema以外,還需要提供許可權控制,避免數據污染。
c) 統一的欄位字典和轉換,不同的數據源系統支援的欄位類型集合各不相同,元數據中心定義了一套欄位類型字典以及各數據源欄位類型的轉換邏輯,對上層應用提供統一的類型轉換支援。比如在數據傳輸的場景下,傳輸工具根據推薦的轉換規則進行跨源的數據傳導。在後續實現物理湖數據統一匯聚的場景下,湖中數據需要做到原始高保真,統一的類型字典&轉換規則也是必須的。
(3) 元資訊的連接管理
a) 數據源技術(物理)元資訊的定期抽取。定期同步各個物理數據源的元資訊,用於做快照管理、地圖、IDE開發推薦等,可以做到多存儲系統,需要考慮海量數據的場景。
b) 業務元數據的關聯。在meta-schema的基礎上,增加標籤、主題、資產風險登記以及其他自定義的業務元資訊的關聯,並提供點、批量的修改查詢能力。
c) 動態元數據的變更管理。根據任務運行實例的SQL資訊等,及時調整血緣資訊,同時對於流表&Topic等同源的對象,在血緣影響分析層面自動進行合併關聯。
(4) 統一的介面調用
a) 元資訊的操作調用介面。
b) 元資訊變更消息訂閱等。
3. 統一數據源
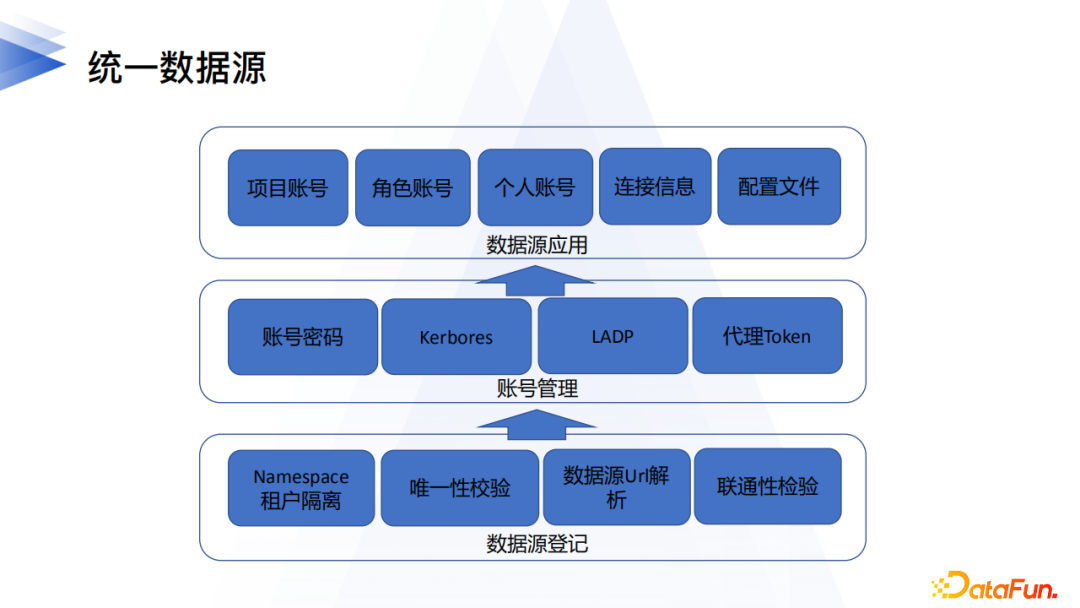
除了統一元數據,統一數據源也非常關鍵,某種程度上來說直接關係邏輯數據湖好不好用、能不能用,數據源的管理也是在元數據中心組件完成。關鍵功能如下:
(1) 確定數據源註冊登記的流程
針對每一種類型的數據源,首先要明確其註冊登記的URL資訊格式、帳號、認證token、version等資訊,以及必需項和可選項,在能正確解析數據源URL的同時,還需要確定數據源唯一性的元組,確保同一個數據源實例不會被重複登記。
其次是數據源在業務上有效空間的管理,Hive數據源是和單一集群綁定的,而非Hive的數據源可以做到跨集群的共享,同時一個數據源也可能做到跨租戶共享,因此對於統一個數據對象(比如db)需要確定好屬主、避免相互覆蓋。對於數據源,也需要確定好業務線歸屬,並且要有使用許可權管控,同一個租戶內不同業務線不能隨意使用。最後需要關注的就是數據源的可用性,元數據中心需要根據登記的數據源的資訊,進行連通性的檢查,除了檢查登記資訊的正確性以外,還需要儘可能確保需要訪問數據源的節點(比如傳輸任務運行的節點)都是正常的。
(2) 統一的帳號管理
主要是支援不同方式/場景的身份認證,不同的數據源認證的方式不同,常見方式有帳號密碼、代理token,對於安全性要求比較高的場景,可能會是Kerbores等。除了認證方式的不同,不同的用戶帳號管理模式也有不同,有的用戶為每個平台登錄帳號都創建對應的數據源帳號,好處是安全性高,但是許可權管理比較繁瑣。有些場景則是,所有場景使用一個登記的公共帳號,管理方便但是安全性不高。某些系統則可能給出一個具有代理許可權的帳號用來代理具體的身份,取一個折中,但是需要每個應用產品都支援其使用模式。
(3) 數據源應用
主要是根據介面調用,給出具體數據源的資訊以及運行模式(開發、線上)關聯的帳號資訊、配置文件等;拉取各個數據源的元資訊,需要關注的技術細節是不同的數據源元數據的獲取方式各不相同,需要逐一適配,同時對於同一類數據源不同版本的驅動,需要明確其支援覆蓋的數據源的版本範圍,當出現覆蓋不了的版本時,要能夠動態地加入新的驅動版本插件並更新驅動版本映射表。
總體來說數據源的統一管控,是邏輯數據湖的基礎,提供了最基礎的能力支援,除了關係到能否正確使用數據源以外,也對上層業務應用的展開規劃有基調性的影響。
4. 統一應用
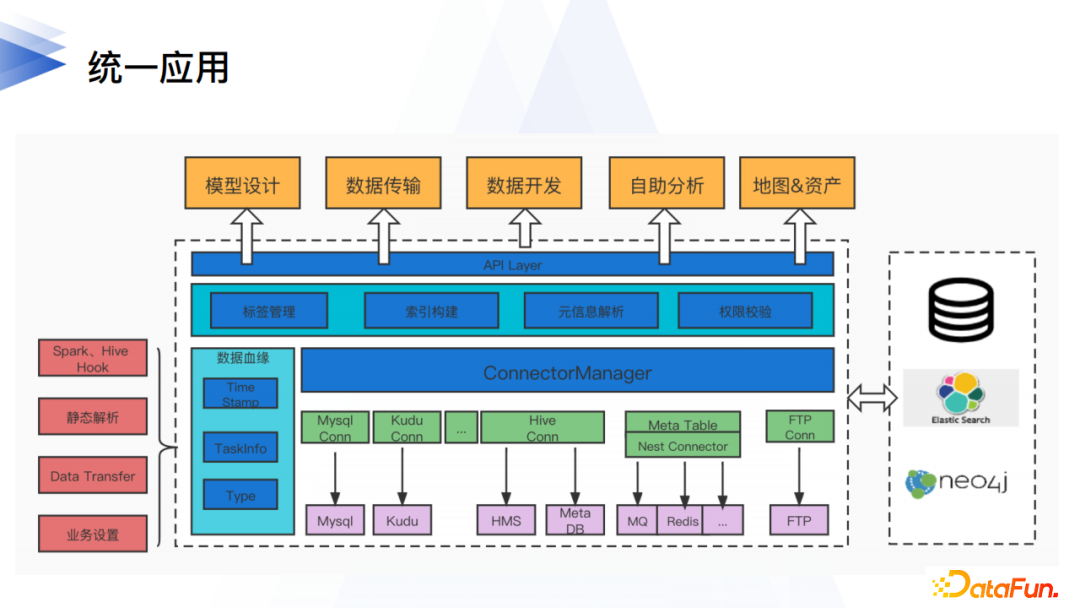
完成了統一的數據源&元數據層的構建以後,我們來看看如何在此之上構建統一的應用,從而實現各個數據源的統、算、管、用。從具體的產品維護劃分,就是模型設計、數據傳輸、數據開發、自助分區取數、資產地圖等都能在各個數據源上實現產品功能。
(1) 模型設計
基於元數據中心提供的業務元數據的介面能力,在具體數據源上數據主題域的構建和劃分,數據對象的打標等。同時支援在該數據源上進行規範的建表管理,實現手動、批量的表處理。
(2) 數據傳輸
實現不同邏輯數據源之間的數據傳導,同時也是後續數據入物理湖的基石。數據傳輸根據邏輯數據源的元資訊,給出最佳的傳輸方案。例如,對於Hive表,元數據中心解析其實際location,傳輸根據真實的存儲系統資訊進行對應jar包的選擇、傳輸任務參數設置,以及數據操作。
(3) 數據開發
一種是直接在源系統上進行開發,比如各類的SQL任務,用戶選擇對應的數據源,調度執行節點根據數據源相關的資訊、驅動配置等直接連上數據系統執行任務,支援用戶保留原有的開發習慣,也方便任務的遷移。對於跨源的SQL任務,主要依託Spark、Flink等計算框架的catalog-manger框架來實現。開發平台會根據任務執行的模式、運行環境,自動關聯同catalog下對應的數據源實例和執行帳號,動態註冊關聯的catalog-plugin和相關參數。同時數據稽查、數據探側等依託於開發框架也同樣支援相關數據源。
(4) 自助取數
自助取數和數據開發類似,在單源數據模型資訊的基礎上,根據登記的數據源資訊以及應用場景的關聯帳號,提供直連數據源的取數能力。值得說明的是,某些專門提供自助查的業務數據系統(比如用戶自研的脫敏平台)也可以作為邏輯數據源錄入平台,從而實現建模取數。
(5) 資產地圖
通過將各個來源的數據對象元資訊進行串聯和整合,給用戶提供快速數據查找的能力。以地圖表搜索為例子,通過解析邏輯數據源抽取並解析源系統的表元資訊,關聯主題、指標、標籤等資訊以後寫入ES等檢索系統,從而提供多個維度的庫表檢索能力,除了表詳情以外,還將關聯的產出任務、血緣資訊、變更ddl等一併展示。
除了通用的產品能力,為了更好地支援邏輯數據湖的應用,還需要很多其他基礎建設,比如許可權和血緣。許可權除了源系統自帶的許可權能力,元數據中心還需要提供邏輯數據源的使用許可權、meta表的許可權等。血緣則是實現高效數據資產的一個重要基礎資訊,基於此實現數據熱度、資源消耗、產出訂閱、依賴推薦等眾多高階管理能力。
5. 數據邏輯入湖
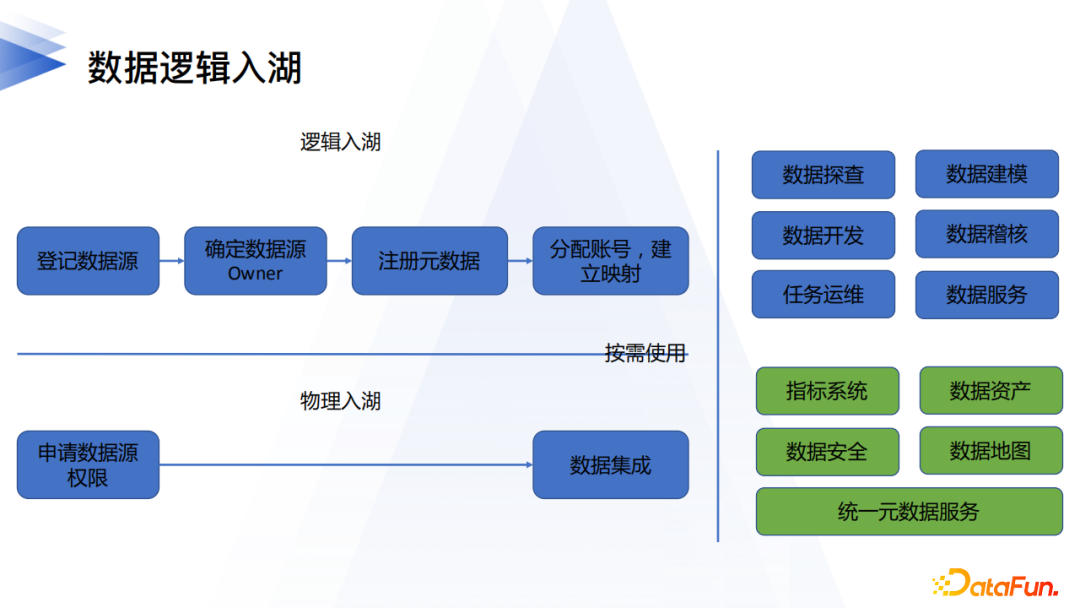
前文已經介紹完了邏輯數據湖的整體架構。我們來看看數據入湖的整體流程。有兩種模式,用戶可以根據實際的建設情況做選擇。
如果還沒有完成物理湖(湖倉一體)的建設,可以選擇邏輯入湖的方式,具體步驟是:登記數據源、確定數據源Owner、基礎技術元數據資訊註冊、以及帳號的映射設置。然後在數據管理類產品中持續完善業務元資訊,然後進行數倉建設、數據開發以及任務運維。
對於已經構建了物理湖的場景,用戶可以將物理湖也作為數據源登記到元數據中心,然後通過數據傳輸實現數據的物理入湖,物理入湖中需要關注數據變更發現的實時性、欄位映射等,確保入湖數據的保真性。入湖的方式不影響上層產品的使用。
6. 跨環境發布
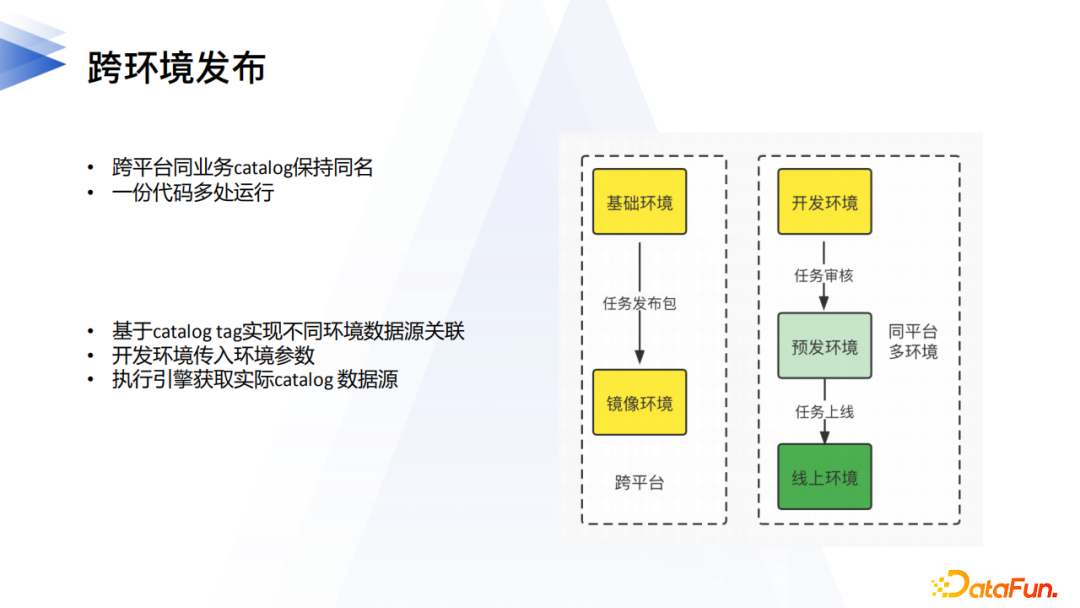
接下來我們看看邏輯數據在一些典型場景下的應用。
第一個是跨環境。這裡也有兩種情況,一種是各個環境之間網路隔離,比如金融機構的測試、生產環境往往是硬隔離的,這種模式下,不同環境需要部署各自的數據源和平台,只需要保證業務相同的數據源能以相同的名字註冊管理即可,平台提供任務發布包的導出和導入,實現測試環境到生產環境的一鍵發布。
還有一種情況是各個環境之間網路是可以打通的,比如開發、預發、線上,又或者業務全球化存在不同區域有獨立的集群,但是區域業務模式是相同的。這種模式下,可以一套平台對多個集群,不同集群鏡像的數據源登記為同一個catalog下的不同tag的源系統,這樣一份任務程式碼可以運行在不同的環境,自動根據環境資訊運行時訪問對應的數據源系統,實現一次開發多環境執行。
7. 邏輯數據湖的核心——血緣
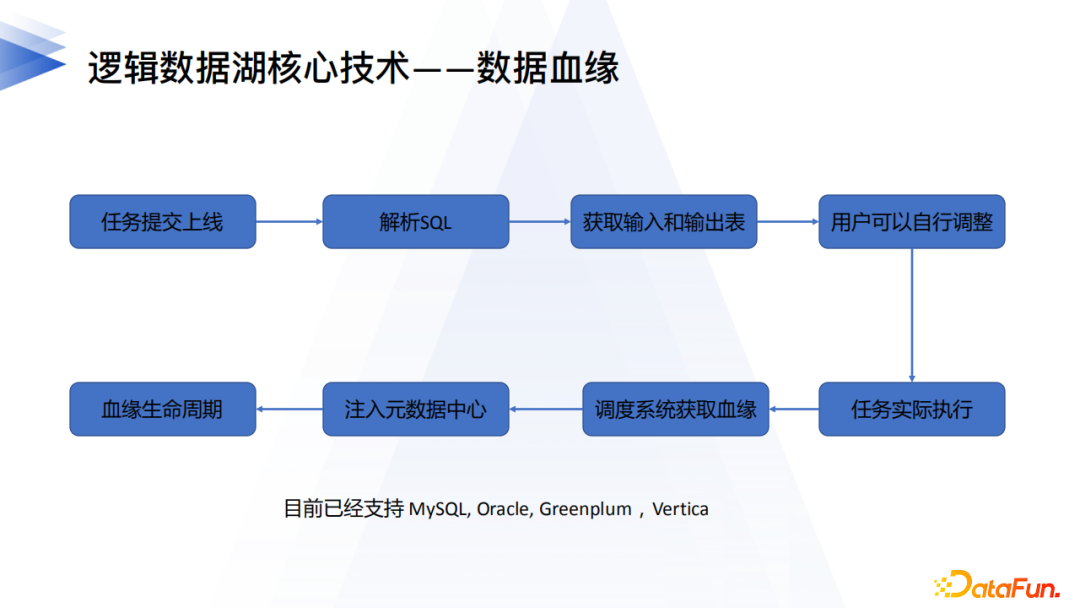
另一個核心場景是數據血緣。統一元數據提供了統一應用管理的基石,數據血緣則能夠將數據應用管理的多個場景串聯起來,相互協同發揮更大的作用。在任務提交階段,我們就會對SQL進行靜態解析,拿到輸入輸出表展示給用戶,方便用戶調試調整任務,在任務上線配置中根據歷史血緣資訊智慧地推薦出依賴的上游任務。另外在任務執行時,執行調度引擎服務會把運行時SQL,結合靜態的SQL形成的血緣表達式統一傳送給元數據中心,元數據中心生產最後的實際血緣資訊,並進行血緣生命周期的管理。
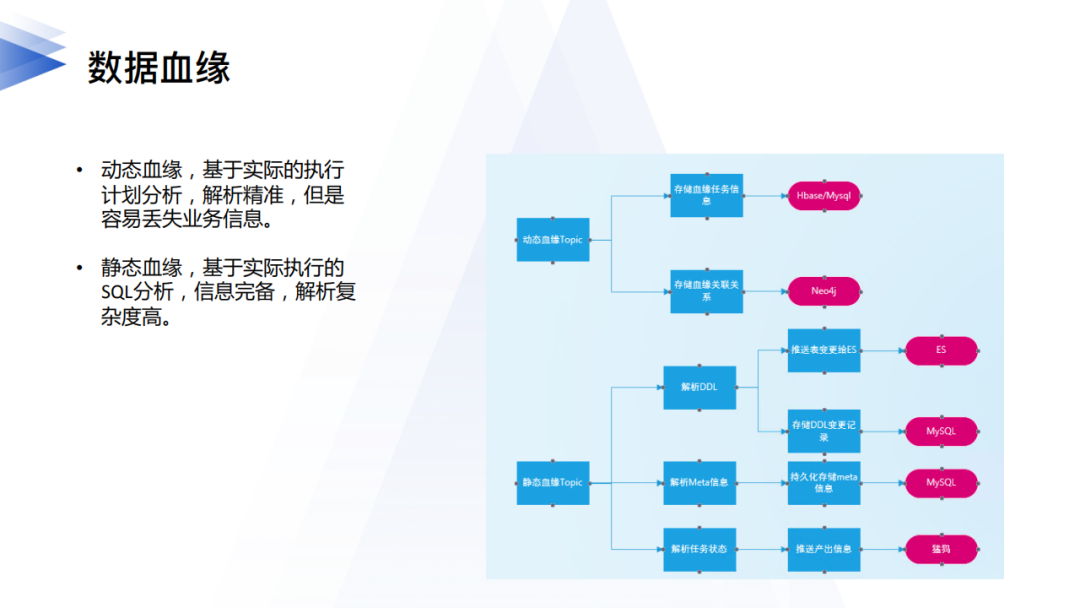
血緣包含兩類:靜態血緣和動態血緣。
動態血緣是從數據執行引擎獲取的,以Hive和Spark為例,我們通過hook拿到運行時的AST就可以知道實際的執行計劃,非常精準也很好解析。動態血緣的問題是AST是SQL經過執行引擎優化後的資訊,可能會丟失一些業務資訊。
靜態血緣主要通過解析調度系統實際任務執行時的SQL來做,通過靜動結合來保證最終的正確性。還有一些血緣需要通過數據傳輸、數據服務等上層產品的任務拿到。平台還可以對外提供開放介面能力,能讓業務系統自己的數據系統和平台對接,將外部的血緣告知平台。所有這些血緣最終都會在相關的產品上展現給用戶。
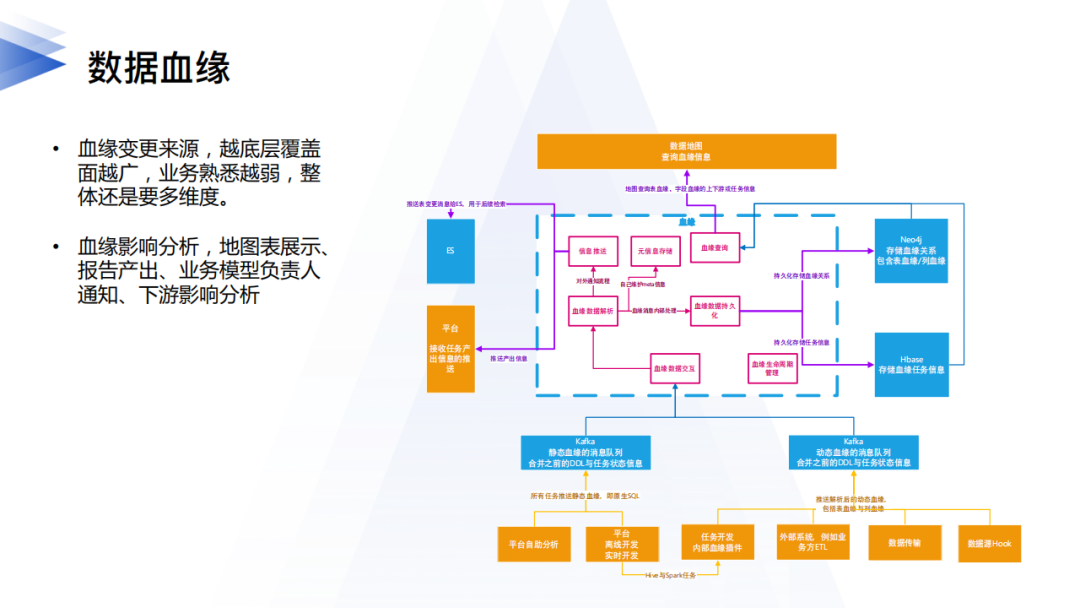
接下來我們來看下血緣資訊有什麼作用。
首先血緣資訊有多個分類維度:基礎資訊&業務資訊、離線&實時、邏輯&物理等。基礎資訊即根據SQL表達解析出來的純粹的表、欄位之間的輸入輸出關係,業務資訊則是產生該血緣的任務、平台等業務層面的資訊。離線&實時表示血緣來源的場景,不同場景生命周期管理不同,邏輯&物理則是邏輯湖表及其實際物理表的關係整理。我們通過多個層次的渠道收集先關資訊,然後在元數據中心進行統一匯總維護,保證血緣資訊完整有效。血緣的作用範圍,除了常見的數據地圖血緣展示,還包括:
- 任務依賴推薦,在設置任務調度依賴的時候一鍵式的智慧推薦&檢查上游依賴設置。
- 下游影響分析,當任務異常/變更的時候集合基準線快速定位影響的應用。
- 表變預警:重點核心表發生變化的時候,自動告警表Owner。
- 資產成本分析:基於血緣可以計算每個表成本,從而評估具體數據應用的價值。
- 表產出訂閱:訂閱重點&核心的表的產出,上層應用比如BI實現智慧快取刷新等。
8. 欄位血緣
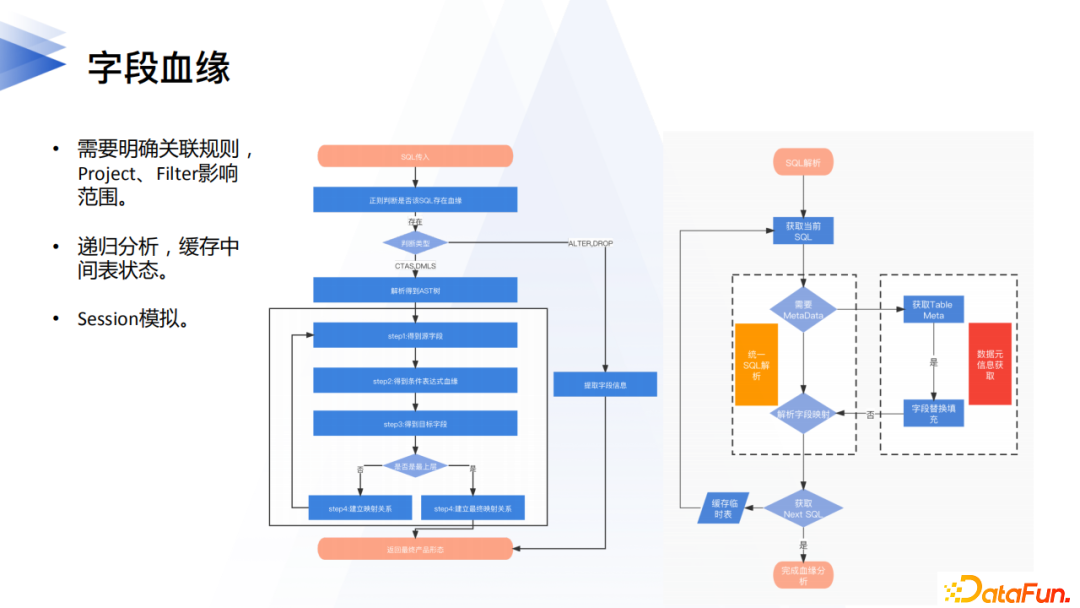
關於血緣,我們最後再看下欄位血緣。在大部分情況下表級別的血緣已經能夠滿足業務需求,但是在某些場景下表粒度還是太粗,最典型的就是大寬表的計算,需要迫切清楚欄位關聯的影響。
除了要能正確解析SQL以外,欄位血緣關鍵點在於確定映射規則和元資訊替換(靜態血緣),目前我們是基於投影(Project)和過濾(Filter)規則來分析欄位依賴關係,而元資訊的替換元數據中心可以通過表關聯的數據源直接獲取,確保實時性。通過遞歸分析各個子查詢過程,最終得到欄位級別的血緣。對於任務多SQL的場景,我們需要進行session化的模擬,一些中間臨時表的資訊要快取起來,對於create and drop的臨時表,需要正確地更新其快取資訊,確保下游SQL解析時有正確資訊輸入。
—
04 未來規劃

產品細節的打磨,主要是支援更多類型的數據源,提升血緣的覆蓋率和精準度。對於邏輯數據湖來說,資產安全和許可權落地也會更加複雜,同樣需要去覆蓋更多類型的數據源。
統一程式碼是我們在完成統一元數據和數據源之後,希望將離線實時程式碼做統一,同時實現跨源查詢和統一的數據脫敏。
最後,持續完善流批一體和湖倉一體技術方案,實現統一的存儲和高性能數倉。
—
05 精彩問答
Q:動態血緣和靜態血緣的使用場景分別是什麼?為什麼動態血緣不能完全替代靜態血緣?
A:首先動態血緣只有在某些提供hook的引擎能夠拿到,比如hive和spark;另外執行時的血緣經過了引擎優化的邏輯優化,可能會丟失原SQL中的一些表達資訊,從而造成血緣不準。而靜態血緣是用戶原始執行sql,基於既定的sql語法規則進行解析以後的血緣,雖然在準確性上會有風險,但是在業務資訊上是全面的。在構建血緣資訊方面,要二者相結合。靜態血緣在依賴推薦、稽查規則檢查等場景可以直接應用,動態血緣獲取更加底層,在任務開發比如腳本任務等場景可以有不錯的覆蓋率。
—
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號「DataFunTalk」。


