HDFS 細粒度鎖優化,FusionInsight MRS有妙招
摘要:華為雲FusionInsight MRS通過FGL對HDFS NameNode鎖機制進行優化,有效提升了NameNode的讀寫吞吐量,從而能夠支援更多數據,更多業務請求訪問,從而更好的支撐政企客戶高效用數,業務洞見更准,價值兌現更快。
本文分享自華為雲社區《FusionInsight MRS HDFS 細粒度鎖優化實踐》,作者:pippo。
背景
HDFS依賴NameNode作為其元數據服務。NameNode將整個命名空間資訊保存在記憶體中提供服務。讀取請求(getBlockLocations、listStatus、getFileInfo)等從記憶體中獲取資訊。寫請求(mkdir、create、addBlock)更新記憶體狀態,並將日誌事務寫入到日誌服務(QJM)。
HDFS NameNode的性能決定了整個Hadoop集群的可擴展性。命名空間性能的改進對於進一步擴展Hadoop集群至關重要。
Apache HDFS 整體架構如下:
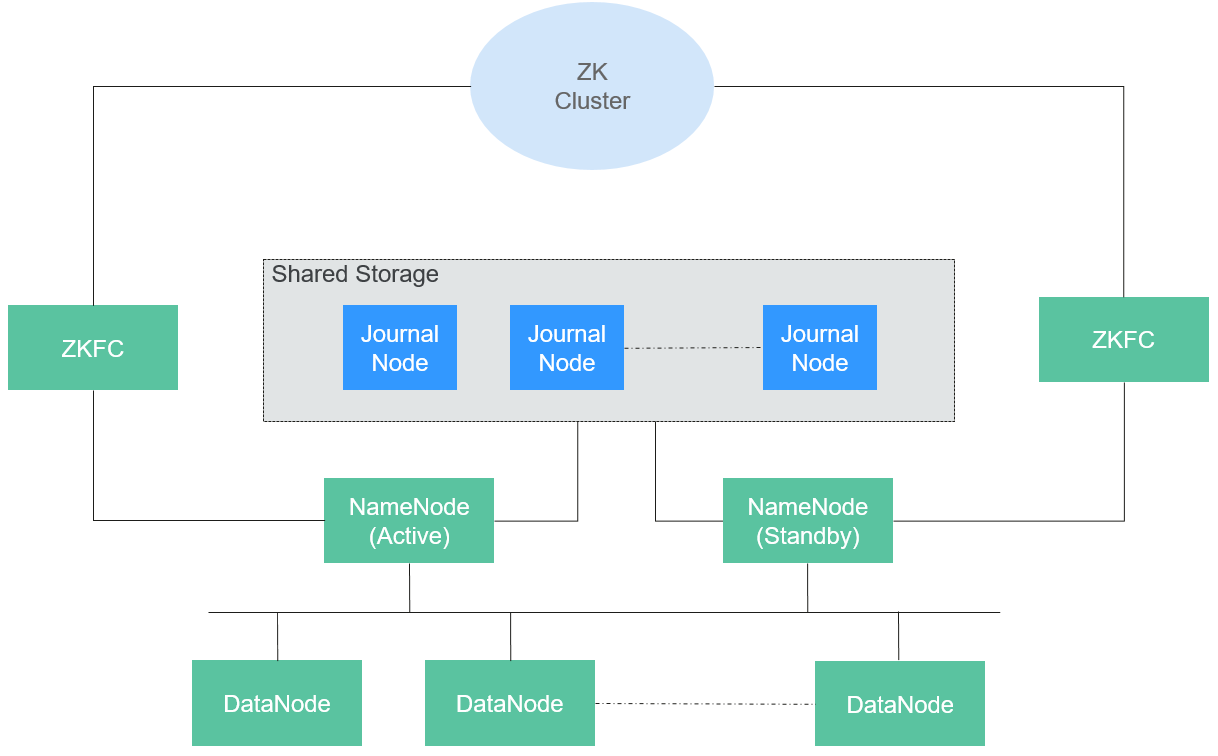
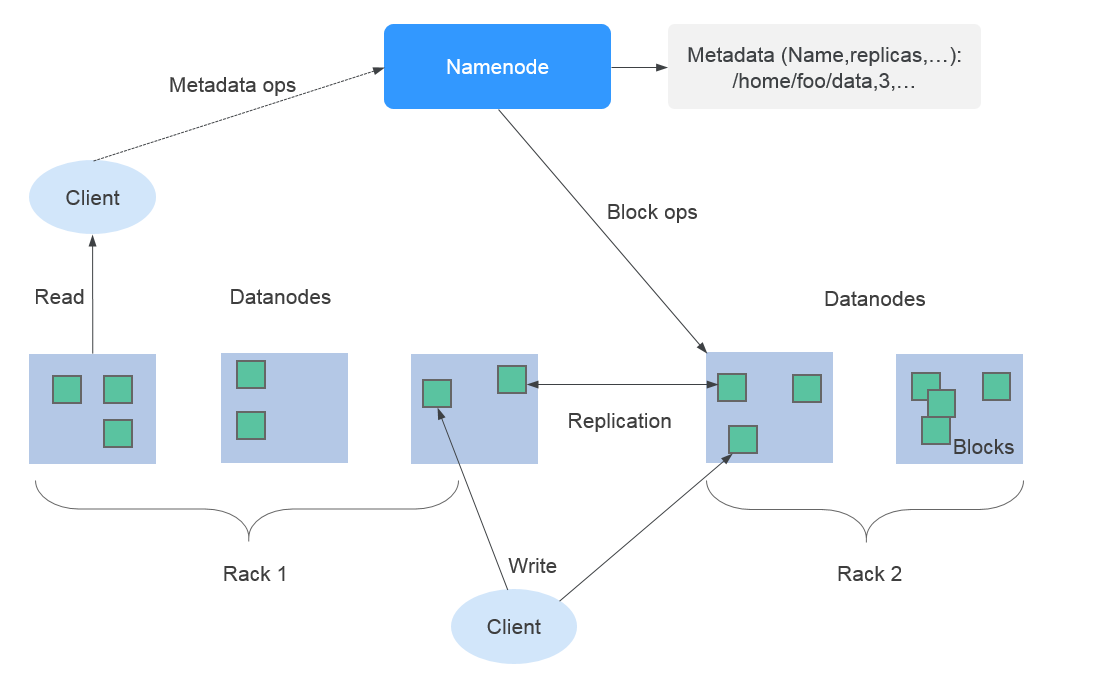
Apache HDFS 交互資訊如下:
痛點
HDFS NameNode的寫操作的性能受全局命名空間系統鎖的限制。每個寫操作都會獲取鎖並保留鎖,直到該操作執行完成。這樣可以防止寫入操作的並發執行,即使它們是完全獨立的,例如命名空間中的對象不相交部分。
什麼是Fine Grained Locking(FGL)
FGL【細粒度鎖】的主要目的是通過在獨立命名空間分區上用多個並發鎖替換全局鎖,允許寫入操作的並發。
當前狀態
HDFS設計思路為一次寫,多次讀。讀操作使用共享鎖,寫操作使用獨佔鎖。由於HDFS NameNode元數據被設計為單個記憶體空間中的命名空間樹,因此樹的任何級別的寫操作都會阻塞其它寫操作,直到當前寫操作完成。雖然寫是一次,但是當涉及大量並發讀/寫操作時,這就會影響整體性能。
在HDFS NameNode中,記憶體中的元數據有三種不同的數據結構:
- INodeMap: inodeid -> INode
- BlocksMap: blockid -> Blocks
- DataNodeMap: datanodeId -> DataNodeInfo
INodeMap結構中包含inodeid到INode的映射,在整個Namespace目錄樹種存在兩種不同類型的INode數據結構:INodeDirectory和INodeFile。其中INodeDirectory標識的是目錄樹中的目錄,INodeFile標識的是目錄樹中的文件。
BlocksMap結構中包含blockid到BlockInfo的映射。每一個INodeFile都會包含數量不同的Block,具體數量由文件大小以及每個Block大小來決定,這些Block按照所在文件的先後順序組成BlockInfo數組,BlockInfo維護的是Block的元數據;通過blockid可以快速定位Block。
DataNodeMap結果包含datanodeid到DataNodeInfo的映射。當集群啟動過程中,通過機架感知逐步建立起整個集群的機架拓撲結構,一般在NameNode的生命周期內不會發生大變化。
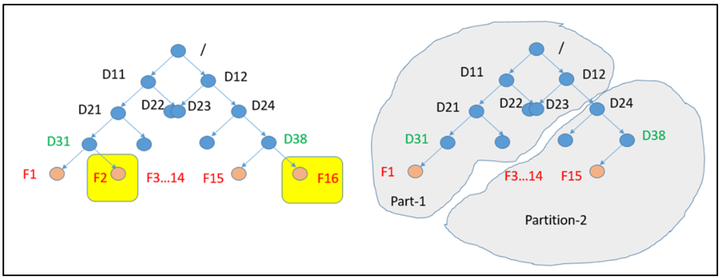
通過INodeMap和BlocksMap共同標識存儲在HDFS中的每個文件及其塊的資訊。隨著文件數量的增加,此數據結構大小也會隨之增加,並對單個全局鎖的性能產生很大影響。下面我們採用簡單的文件目錄樹結構來演示現有的單一全局鎖在文件系統的缺點。

HDFS NameNode 記憶體目錄樹結構
如上圖所示,/D11/D21/D31/F2 和 /D12/D24/D38/F16是不相交的文件,即有不同的父節點和祖父節點。可以看到F2和F16是兩個獨立的文件,對其中一個文件的任何操作都不應該影響另一個文件。
設計
如前所述,HDFS NameNode將文件資訊和元數據結構在記憶體中保存為一個目錄樹結構。當修改任意兩個獨立的文件時,第二次操作需要等到第一次操作完成並釋放鎖。釋放鎖以後,只有第二個操作獲取鎖後才能繼續修改文件系統。類似的,後續操作也會阻塞,直到第二次操作釋放鎖。
在下面的例子中,我們考慮2個文件並發寫入(創建、刪除、追加。。。)操作。F2和F16是文件系統下的2個獨立文件(具有不同的父節點和祖父節點)。在將內容追加到F2時,F16也可以同時進行修改。但是由於整個目錄樹全局對象鎖,對F16的操作必須等對F2的操作完成後才能執行。
代替全局鎖,可以將鎖分布在一組名為「分區」的文件中,每個分區都可以有自己的鎖。現在F2屬於分區-1,F16屬於分區-2。F2文件操作可以通過獲取分區-1的鎖來進行修改,F16文件操作可以通過獲取分區-2的鎖來進行修改。
和以前一樣,需要先獲取全局鎖,然後搜索每個文件屬於哪個分區。找到分區後,獲取分區鎖並釋放全局鎖。因此全局鎖並不會完全被刪除。相反,通過減少全局鎖時間跨度,一旦釋放全局鎖,則其它寫操作可以獲取全局鎖並繼續獲取分區鎖來進行文件操作。
分區的數量如何決定?如果有效的定義分區從而獲得更高的吞吐量?
默認情況下,分區大小為65K,溢出係數為1.8。一旦分區達到溢出條件,將會創建新分區並加入到分區列表中。理想情況下,可以擁有等於NameNode可用CPU核數的分區數,過多的分區數量將會使得CPU過載,而過少的分區數量無法充分利用CPU。
實現
引入新的數據結構-PartitionedGSet,它保存命名空間創建的所有分區資訊。PartitionEntry是一個分區的對象結構。LatchLock是新引入的鎖,用於控制兩級鎖–頂層鎖和子鎖。
PartitionedGSet
PartitionedGSet是一個兩級層次結構。第一層RangeMap定義了INode的範圍,並將它們映射到相應的分區中。分區構成了層次結構的第二級,每個分區存儲屬於指定範圍的INode資訊。為了根據鍵值查找INode,需要首先在RangeMap中找到對應鍵值的範圍,然後在對應的RangeSet,使用哈希值獲取到對應的INode。
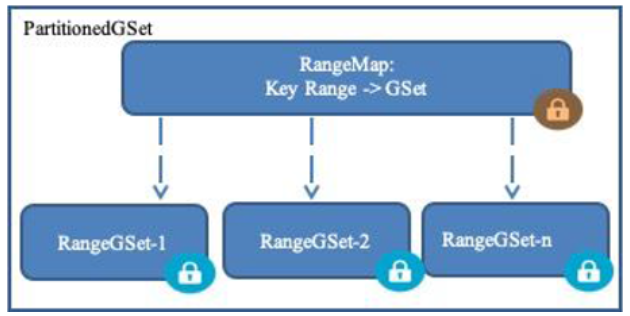
HDFS NameNode 兩級層次結構
RangeGSet的容量有一定的閾值。當達到閾值後,將創建新的RangeGSet。空的或者未充分利用的RangeGSet由後台RangeMonitor守護程式來進行垃圾回收。
HDFS NameNode啟動時,根據鏡像中的INode數量計算合理的初始分區數。同時還需要考慮CPU核數,因為將分區數量提高到遠超CPU核數並不會增加系統的並行性。
- 動態分區:分區的大小有限,可以像平衡樹一樣可以進行分裂和合併。
- 單個分區:只有一個分區,且只有一個與之相對應的鎖,並且應和全局鎖類似。這適用於小型集群或寫入負載比較輕的集群。
- 靜態分區:有一個固定的RangeMap,不添加或者合併現有分區。這適用於分區均勻增長的文件系統。而且這將消除鎖定RangeMap的要求,允許並行使用鎖。
Latch Lock
RangeMap與RangeGSet分別有單獨的鎖。Latch Lock是一種鎖模式,其中首先獲取RangeMap的鎖,以查找與給定INode鍵對應的範圍,然後獲取與分區對應的RangeGSet的鎖,同時釋放RangeMap鎖。這樣針對任何其它範圍的下一個操作都可以開始並發執行。
在RangeMap上持有鎖類似於全局鎖。目錄刪除、重命名、遞歸創建目錄等幾個操作可能需要鎖定多個RangeGSet。這要確保當前HDFS語義所要求的操作的原子性。例如,如果重命名將文件從一個目錄移動到另一個目錄,則必須鎖定包含文件、源和目標目錄的RangeMap,以便使重命名成為原子。此鎖定模式的一個理想優化是允許某些操作的Latch Lock與其他操作的全局鎖結合使用。
INode Keys
HDFS中的每個目錄和文件都有一個唯一的INode,即使文件被重命名或者移動到其它位置,該INode會保持不變。INode鍵是以文件INode本身結尾,前面包含父INode的固定長度序列。
Key Definition: key(f) = <ppId, pId, selfId>
selfId是文件的INodeId,pId是父目錄的INodeId,ppId是父目錄的父目錄的INodeId。INode鍵的這種表達不僅保證了同級,同時也保證了表親(相同祖父節點)在大多數情況下被分區到相同的範圍中。這些鍵基於INodeId而非文件名,允許簡單的文件和目錄進行重命名,稱為就地重命名,而無需重新進行分區。
效果
經過測試驗證使用和不使用FGL功能性能,在主要寫入操作情況下,吞吐量平均提高了25%左右。
詳細性能對比
使用Hadoop NN Benchmarking工具(NNThroughputBenchmark)來驗證NameNode的性能。每個寫入API驗證並觀察到平均25%的性能提升。有很少一部分輕微或者沒有提升的API,分析並發現這些API均是輕量級API,因此沒有太大的提升。
NNThroughputBenchmark是用於NameNode性能基準測試工具。該工具提供了非常基本的API調用,比如創建文件,創建目錄、刪除。在這個基礎上進行了增強,從而能夠支援所有寫入API,並能夠捕獲使用和不使用FGL的版本的性能數據。
用於測試的數據集:執行緒數 1000、文件數 1000000、每個目錄文件數 40。
寫入調用頻率高的API
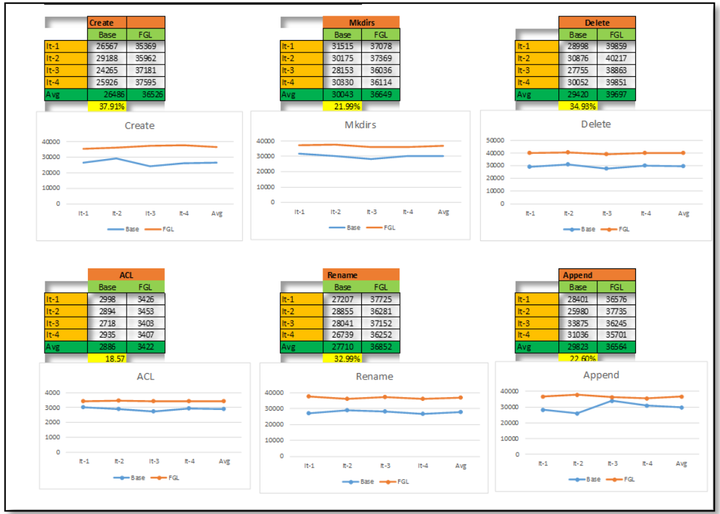
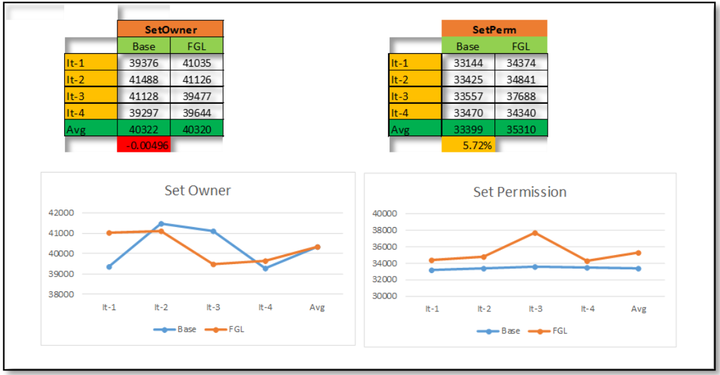
其它內部寫API
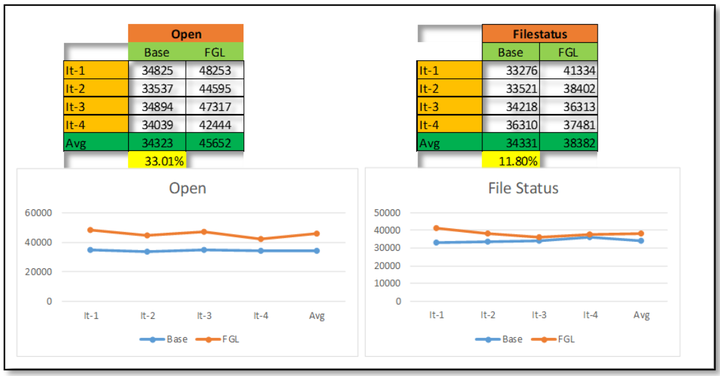
常用讀取API:
通過完整的FGL實現,讀取API也有很好的性能提升。
運行基準測試工具的命令:
./hadoop org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark -fs file:/// -op create -threads 200 -files 1000000 -filesPerDir 40 –close
./hadoop org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark -fs hdfs:x.x.x.x:dddd/hacluster -op create -threads 200 -files 1000000 -filesPerDir 40 -close
參考
與FGL相關的社區討論
Hadoop Meetup Jan 2019 — HDFS Scalability and Consistent Reads from Standby Node, which covers Three-Stage Scalability Plan. Slides 21–25
社區中跟蹤與NameNode可擴展性相關的其它Jira
HDFS-5453. Support fine grain locking in FSNamesystem
HDFS-5477. Block manager as a service
HDFS-8286. Scaling out the namespace using KV store
HDFS-14703. Namenode Fine Grained Locking (design inspired us to implement it fully)
總結
華為雲FusionInsight MRS雲原生數據湖為政企客戶提供湖倉一體、雲原生的數據湖解決方案,構建一個架構可持續演進的離線、實時、邏輯三種數據湖,支撐政企客戶全量數據的實時分析、離線分析、交互查詢、實時檢索、多模分析、數據倉庫、數據接入和治理等大數據應用場景。
華為雲FusionInsight MRS通過FGL對HDFS NameNode鎖機制進行優化,有效提升了NameNode的讀寫吞吐量,從而能夠支援更多數據,更多業務請求訪問,從而更好的支撐政企客戶高效用數,業務洞見更准,價值兌現更快。


