羅強:騰訊新聞如何處理海量商業化數據?
- 2022 年 5 月 22 日
- 筆記
- DataFunTalk, 人工智慧, 大數據, 演算法

導讀: 隨著資訊化時代的來臨,資訊呈現出爆炸式的增長。尤其是在移動互聯網的推動下,每天大量資訊湧入讓人們應接不暇,騰訊新聞客戶端的出現,就是以幫助用戶尋找有用資訊而出現。這時,面對海量的數據、繁多的業務,如何處理手中的數據,利用數據賦能是今天會議討論的重點。
今天的介紹會圍繞下面三部分展開:
- 背景介紹
- 海量日誌處理架構
- 數據應用舉例
—
01 背景介紹
首先介紹一下騰訊新聞的背景。
團隊目前承擔騰訊新聞客戶端,體育和新聞插件的創新業務的輸入,廣告和用戶行為的數據採集、處理、計算和分析的工作。最大的特點就是數據多、業務廣。數據龐大,業務應用多樣,例如數據會被用於報表展示、演算法模型的訓練、產品決策等場景。
—
02 海量日誌處理架構
1. 總體架構
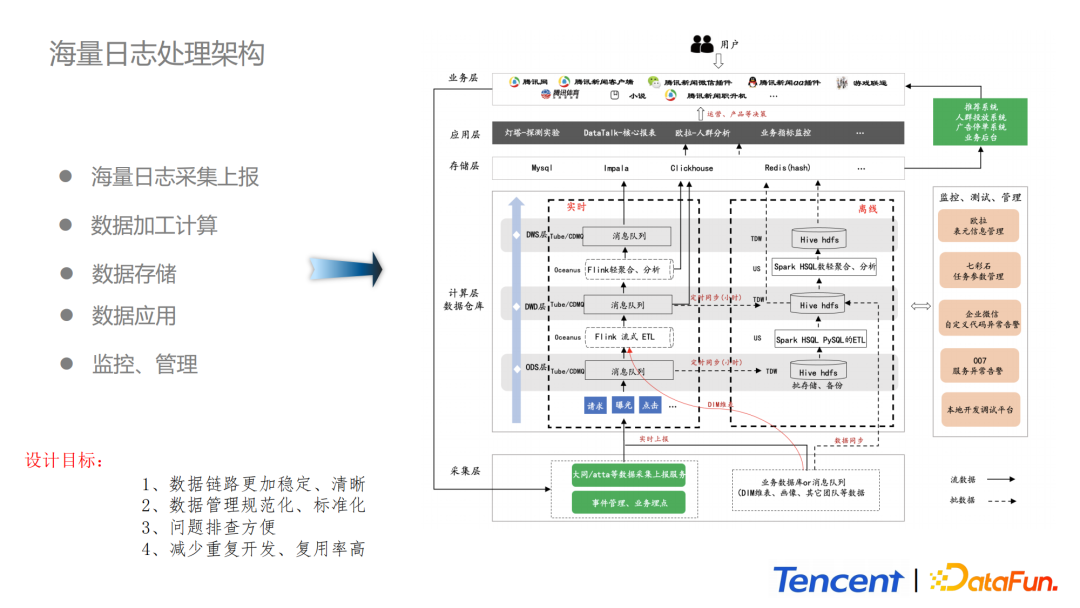
眾所周知,業務在實際開發過程中需要一套有效的數據管理、組織、處理方法,使得整個數據體系更加有序。上圖展示的是騰訊新聞整體的處理架構,包括:
-
採集層:依託於大同數據採集上報服務,大同是目前內部力推的數據治理的客戶端上報平台。
-
計算層:包括實時計算與離線計算。離線是基於TDW(hive表)和HDFS建立的各個業務請求、點擊、曝光等維度的數據表,同時利用歐拉平台的數據分層、數據分類、數據血緣等能力完成數據資產的管理。實時計算方面使用Oceanus平台和內部的Datahub完成整個數據的開發。這個設計解決了需求多變、程式碼複雜、系統高可用、海量數據低延時接入、數據高復用等問題。在ODS原始數據層、DWD數據明細層、DWS主題輕匯聚層,我們採用集團的Tube消息中間件,以及BG內部的CDMQ。Tube消息中間件解決海量數據及時接入的問題。數據各層由流式計算引擎進行業務的清洗與轉化,結果會迴流到下一個消息中間件,供下游使用。對於ODS層的實時數據我們會每隔一個小時同步到TDW,大概存儲周期為3天,這部分數據既能用於離線計算,又能作為數據的備份。比如一些鏈路發生異常,可以利用這部分數據進行問題排查和數據恢復。
-
數據存儲層:組件比較豐富,有Impala、ClickHouse、Mysql、Redis等。Impala主要應用在內部燈塔平台和Datatalk平台進行報表和數據探測的工作中。
2.數據上報
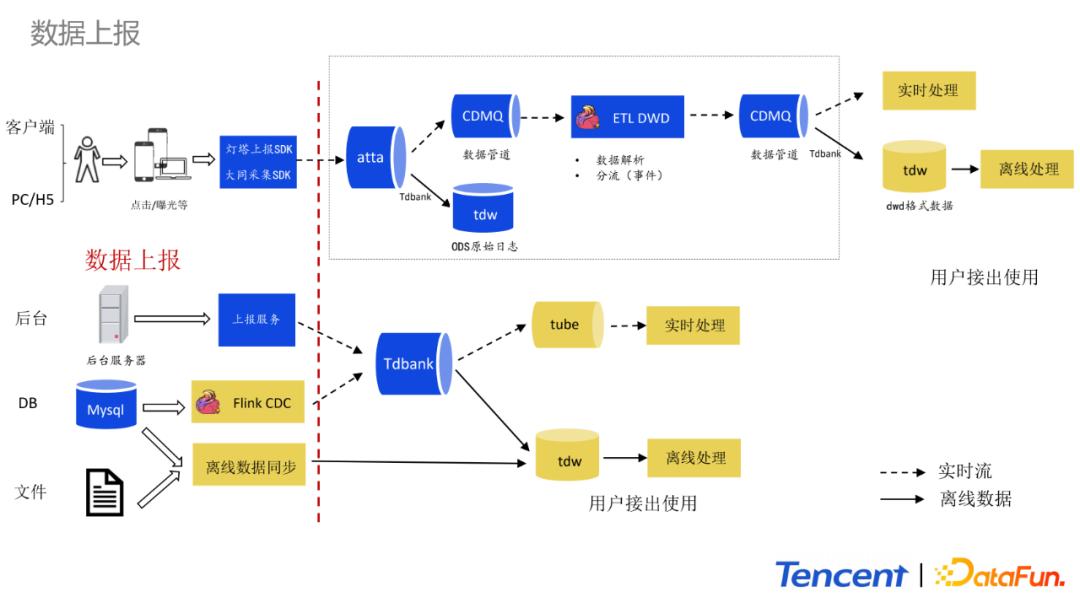
這部分詳細地講解整個數據上報體系。目前數據上報會根據數據源進行分類上報。數據源主要分為四大類:
-
客戶端:包括客戶端、PC、H5這類數據。採用燈塔SDK進行上報,使用大同SDK進行採集。同時會基於大同平台進行事件的管理,例如埋點的事件管理和統一參數的上報。大同平台有效地解決需求散亂、數據難校驗、上報不規範等問題。在整個實時鏈路中,這部分數據接著會通過atta分發到TDW(hive表)和CDMQ實時中間件供下游進行實時消費。
-
後台:主要包括後台伺服器日誌的上報。這部分數據會上報到Tdbank。Tdbank會同時將數據轉化為TDW(hive表),同時還會分發到Tube實時流中,供下游進行實時消費。
-
DB:跟後台數據上報類似。以前的方式是DB同步,例如按小時更新或者按天更新將Mysql更新數據放到Hive表中。目前,會通過Flink CDC監聽Mysql的binLog實時更新業務維表。
-
文件:例如業務配置和運營的配置文件,量不大,會通過手動的方式離線同步到TDW(hive表)中去。
3. 實時計算框架
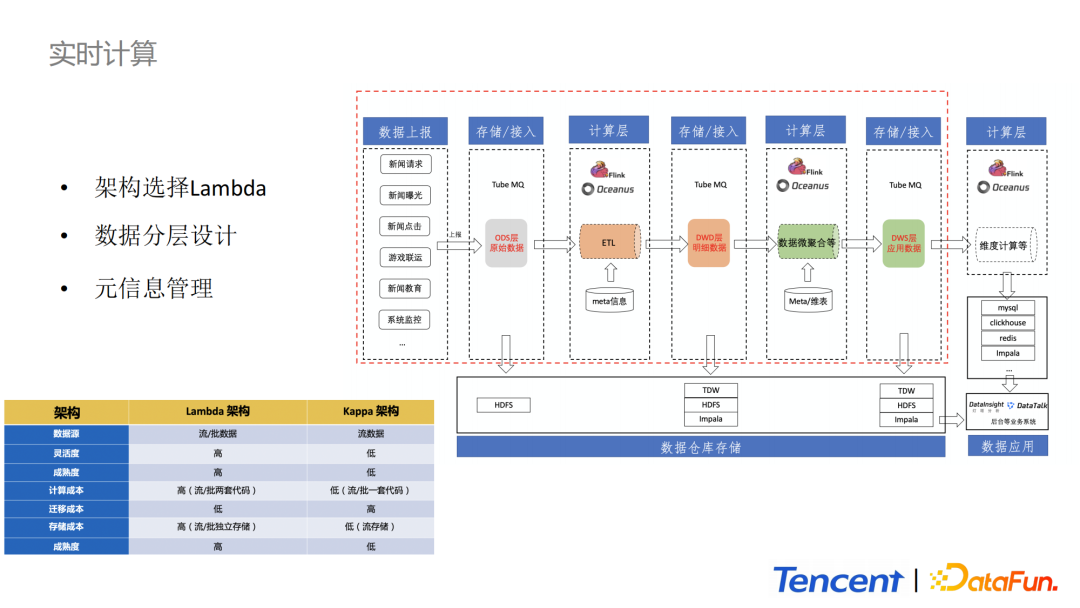
實時計算架構整體上選擇Lamda架構,ODS層到DWD層數據的處理,實時和離線部分是公用的,也體現了流批一體的概念。下面就分模組介紹實時計算部分的整體架構。
-
存儲/接入層:負責客戶端與後台的實時中間數據上報。數據被上報到消息中間件中,消息中間件一方面負責消息的存儲,另一方面承擔數據分發給離線和在線處理平台的功能,同時它是數據源和數據處理系統之間的橋樑。
-
DWD:DWD層的設計是為了減少下游頻繁對ODS層數據進行消費。對於新的需求開發我們只需要申請DWD層的Tube消費節點即可。這樣處理極大地節省了計算單元。
-
計算層:主要負責數據的ETL、維表關聯、特徵抽取等業務邏輯的計算。
-
數據倉庫存儲層:主要採用TDW(hive表)、HDFS和Impala作為存儲介質。ODS層的原始數據默認保存在HDFS上,保存周期默認為3天。
另外,DWD和DWS層數據支援寫入TDW和HDFS去做離線計算。同時也支援導入Impala進行存儲,以供燈塔平台和DataTalk平台等進行數據探測和報表展示。
4. 離線計算框架
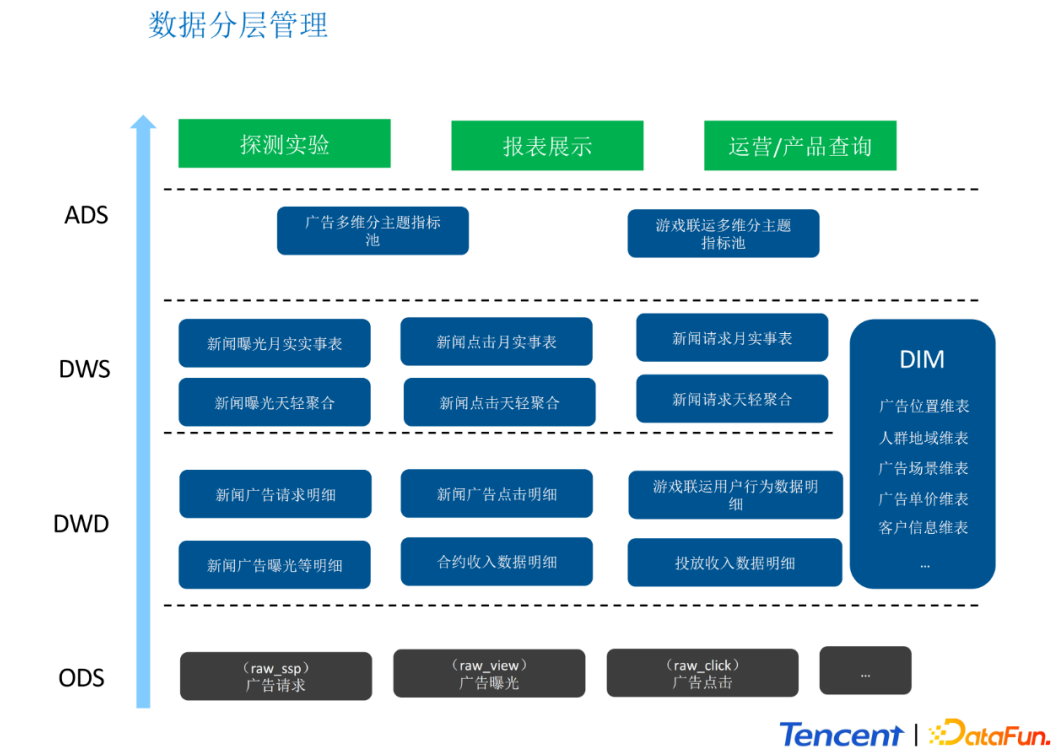
針對離線計算部分,我們對數據進行了分層管理,簡單概括為以下四層:
-
ODS:原始數據存儲層。存儲大同上報或後台上報的原始數據,例如廣告點擊曝光等數據。
-
DWD:數據明細存儲層。存儲經過清洗和標準化的數據。
-
DWS:數據輕度匯合層。基於單業務場景或者單用戶行為的匯總。
-
ADS:數據應用層。只要存儲最終的,呈現結果的數據。例如存儲報表和進入Impala之前的數據,或者 存儲需要進入Redis、ClickHouse等的數據。
我們對數據層的調用進行了約束:
-
DWD層必須存在。且所有的ETL邏輯都在DWD層上。
-
DWS層優先調用DWD層。ADS優先調用DWS層。
-
DWD層不做過多與DIM維表的關聯。
同時我們對於表的命名進行規範,該命名規範使得雜亂無章的數據表變得規範有序,使得內部業務合作變得便利。具體規範如下:

5. 數據品質及鏈路保障
關於數據品質以及鏈路保障,分為在線和離線兩部分進行講解。
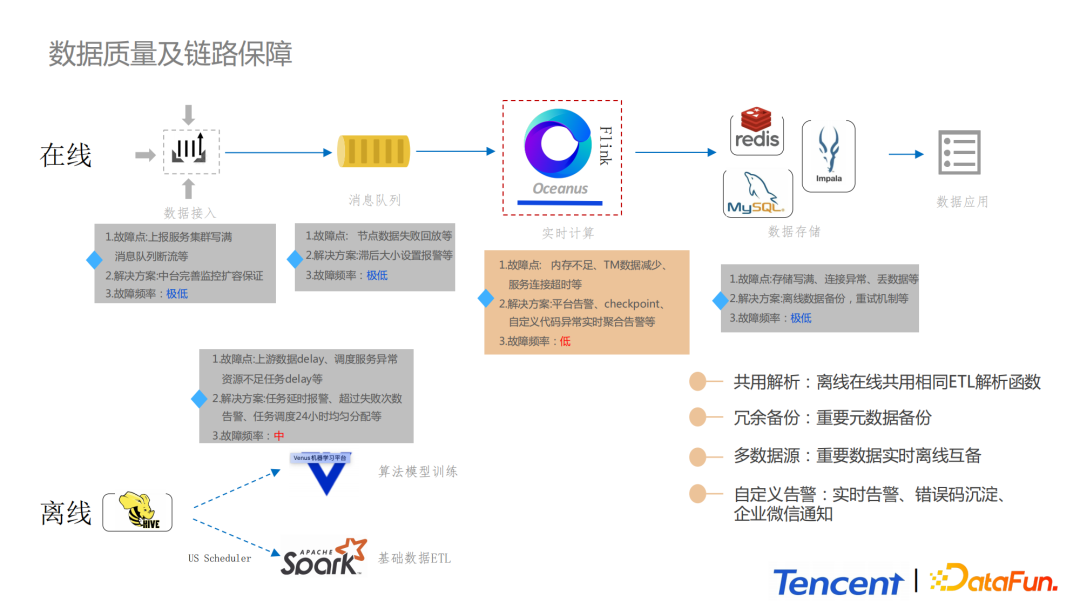
離線部分,一方面會依託平台提供指標監控告警以及SLA保障的能力;另一方面,在程式碼層面進行設計,通過異常捕獲、分級告警,出錯分層管理,重置機制等,提高整個系統的高可用和穩定性。
實時部分,最容易出錯的就是Flink實時計算部分,例如出現記憶體不足、TaskManager突然減少、網路抖動導致的服務連接超時等。我們會依託於Oceanus平台提供的告警能力。我們設計了一套程式碼層級的告警作為報警獨立模組。首先我們通過try catch捕捉Flink Task中的異常,同時這些報警資訊會被發送到消息中間件,然後報警資訊會在消息中間件中被聚合,為了預防報警疲勞,報警資訊會被分級,錯誤碼會被沉澱,然後報警會統一通過企業微信進行通知,正常情況問題可在5min內被解決。
6. 總結
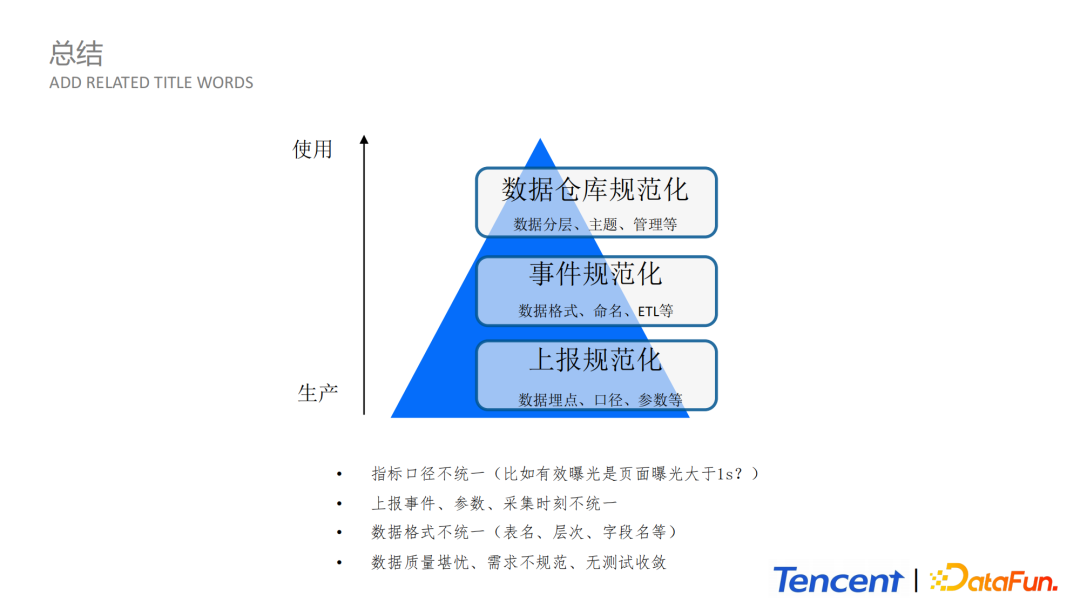
我們在實時和離線對海量日誌處理設計方案上的收益可以總結如下:
-
首先,通過大同平台上報,使得上報更加規範化;
-
第二是事件規範化,各個BG之間可以應用同一規範數據,有統一規範的數據格式和命名規則;
-
第三就是數據倉庫規範化,包括分層、主題、管理等,使得整體管理更加清晰。
03 數據應用舉例
1. Flink CDC(Change Data Capture)- DB數據同步技術
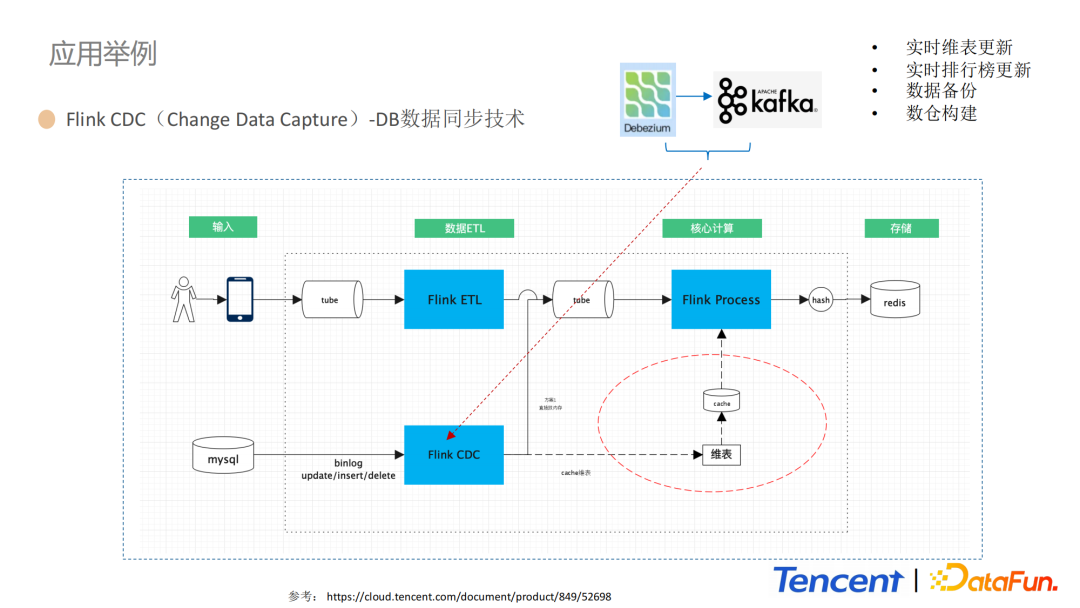
這部分,我們通過Flink CDC的DB數據同步技術,進一步舉例說明我們的海量數據處理流程。上圖是通過Flink CDC進行實時更新維表和實時排行榜更新的設計方案,整體主要包括輸入數據源、Flink實時ETL模組、Flink核心計算模組和數據存儲模組四部分。Flink內部繼承開源組件Debezium和Kafka,CDC技術可以實時捕捉Mysql的增刪改,然後將數據同步到下游,同步到多個數據源,然後通過抽取資料庫日誌的方式完成數據上報。
2. Flink CDC實現方法

Flink CDC實現方式主要有兩種:SQL模式和自定義反序列化模式。個人傾向於選擇第二種方式,可以更加靈活地實現業務需求。通過實現反序列化相關介面,資料庫的變更數據可以通過SourceRecord得到,解析之後的數據可以通過collect進行收集然後傳到下游進行消費。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號「DataFunTalk」。


