技術分享 | 雲原生多模型 NoSQL 概述
作者
朱建平,TEG/雲架構平台部/塊與表格存儲中心副總監。08年加入騰訊後,承擔過對象存儲、鍵值存儲,先後負責過KV存儲-TSSD、對象存儲-TFS等多個存儲平台。
NoSQL 技術和行業背景
NoSQL 是對不同於傳統關係型資料庫的一個統稱,提出 NoSQL 的初衷是針對某些場景簡化關係型資料庫的設計,更容易水平擴展存儲和計算,更側重於實現高並發、高可用和高伸縮性。
NoSQL vs 關係型資料庫
其實早幾年大家看兩者的區別是清晰的,關係型資料庫就是用 SQL 語句操作,具有行列結構和預定義 scheme 的二維表;NoSQL 是 Key-Value 存儲,它是一個分散式的 Hash Map 的存儲。但最近幾年卻有些不清晰了?主要是出現 NoSQL 的部分產品也開始增強在SQL的介面和事務等方面的能力,比如 Cassandra 支援 CQL,DynamoDB 支援 PartiQL,InfluxDB 也支援 InfuxQL 等。這裡我的看法是,NoSQL vs 關係型資料庫的關鍵差異:關係型資料庫具有強大的 ACID 事務、複雜 SQL 檢索、數據完整性約束等能力,這給它帶來很好的易用性,但同時也是它實現高並發、高可用和高伸縮性的束縛;NoSQL 在工程實現上做了個取捨平衡,弱化甚至捨棄了在跨分區事務、分散式JOIN等維度的能力,增強其在高並發、高可用和高伸縮性方面的能力。
多模型 NoSQL 的數據模型
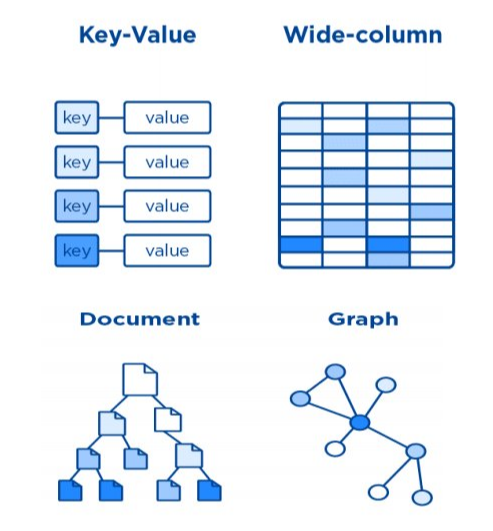
多模型 NoSQL 中的多模型是指這裡包括多個數據模型:鍵值模型 Key-Value、寬表模型 Wide-column、文檔模型 Document、時序模型 Time-series、圖模型 Graph 和記憶體模型 in-memory 等。我們可以簡單理解,Key-Value 是個哈希表,Wide-column 是個多維的哈希表即 Key-Key-Value 結構,文檔 Document 是類似於 Json 結構的一個嵌套樹結構,Graph 是以頂點和邊組成的複雜圖結構,Time-series 是按時間有序的一個檢索表。
數據模型使用和發展可以從受歡迎程度和增長速度兩個指標來看。受歡迎程度反映著應用推廣的累積效應,排名前三的依次為 文檔>鍵值>寬表;增長速度代表著未來需求的反應,排名前三依次 時序>鍵值>圖,其中時序和圖得益於物聯網LoT以及實時計算等方面需求目前增長較為迅速,國外 NoSQL 的一些創業公司,近期較多集中在時序和圖存儲相關領域。
NoSQL 存儲領域的業界玩家
主要分為三類:垂直領域的開源社區、多模型 NoSQL 公司 和公有雲廠商。
垂直領域的開源社區,包括鍵值存儲領域的 Redis,文檔存儲的 MongoDB,時序存儲領域的 InfluxDB、圖存儲的 Neo4j 等,這些公司都是從垂直開源社區多年的競爭中突圍出來的贏家,掌握了垂直領域的生態和介面的標準,基於公有雲開展支援多雲的企業服務。
多模型NoSQL公司,如YugabyteDB、Aerospike等,雖然也是開源,也是基於公有雲開展支援多雲的企業服務,但並不掌握垂直領域生態和介面標準,更多地兼容Redis、Cassandra、PG(PostgreSQL)等介面標準去融入已有的生態。
公有雲廠商,如微軟 Azure CosmosDB、亞馬遜 AWS DynamoDB 等,提供了雲原生的託管存儲服務,在介面上採用自定義或者直接兼容開源社區的 Redis 和 Cassandra 等垂直領域的介面。
而我們的 NoSQL 屬於這裡的第三類玩家。
據市場公開數據顯示,最近幾年這三類廠商都有比較好的市場增速,但也存在著垂直領域、開源社區和公有雲廠商的一些矛盾和競爭。

NoSQL 存儲的發展方向與趨勢
公司內部自研的 NoSQL,源於早些年結合業務場景的訂製開發。比如我們 oTeam 中的 CKV+、TSSD、PCG 的 BDB 、Grocery 等。但是面向雲原生的場景下、新的軟硬體基礎設施升級以及新場景的擴展支援也面臨著新的挑戰,以及無法同時兼顧內部自用與雲上外部客戶的一些訴求。
首先,雲原生場景下客戶對自研提出了更高的要求。例如要求解除雲廠商的綁定,就是採用業界 API 的介面標準,支援多可用區和地域的分布,彈性伸縮,按需付費容器化和分散式雲等方式部署。
其次,持續提升的基礎設施能力對底層存儲提出更高要求。過去幾年,公司機房、網路環境、微服務框架、系統、軟體等基礎設施方面的能力都得到極大的提升,如 SSD 單盤容量,以及單台存儲伺服器配置的磁碟數量都有了較顯著的增長,新 TRPC 框架、新網路和新的磁碟 IO 通道,如 RDMA/DPDK、SPDK/IO_URING 等能力的推出,均要求底層的存儲架構進行不斷地適配,以獲取更高的性價比。
最後,個性化內容推薦和物聯網監控等新生場景出現。相較於以往我們在社交網路中的鍵值存儲場景,近年來也出現了諸如個性化內容推薦中的特徵存儲、物聯網/監控中的時序存儲等新生場景,而它們在 API 介面、功能、存儲引擎等方面跟以往的鍵值存儲使用是有所差異,需要能復用平台的大部分能力,同時也需要能訂製部分組件。
為了應對新的機遇和挑戰,我們聯合了 PCG、CSIG、WXG 和 IEG 相關團隊,在2021年組建了多模型 NoSQL 的 Oteam,支援新的業務場景。經過 oTeam 各方的一起努力,從零研發出多模型 NoSQL 平台(X-Stor),目前已完成了平台技術能力和規模化運營能力的初步建設。
重新再造–多模型 NoSQL 系統架構
多模型 NoSQL 架構和目標
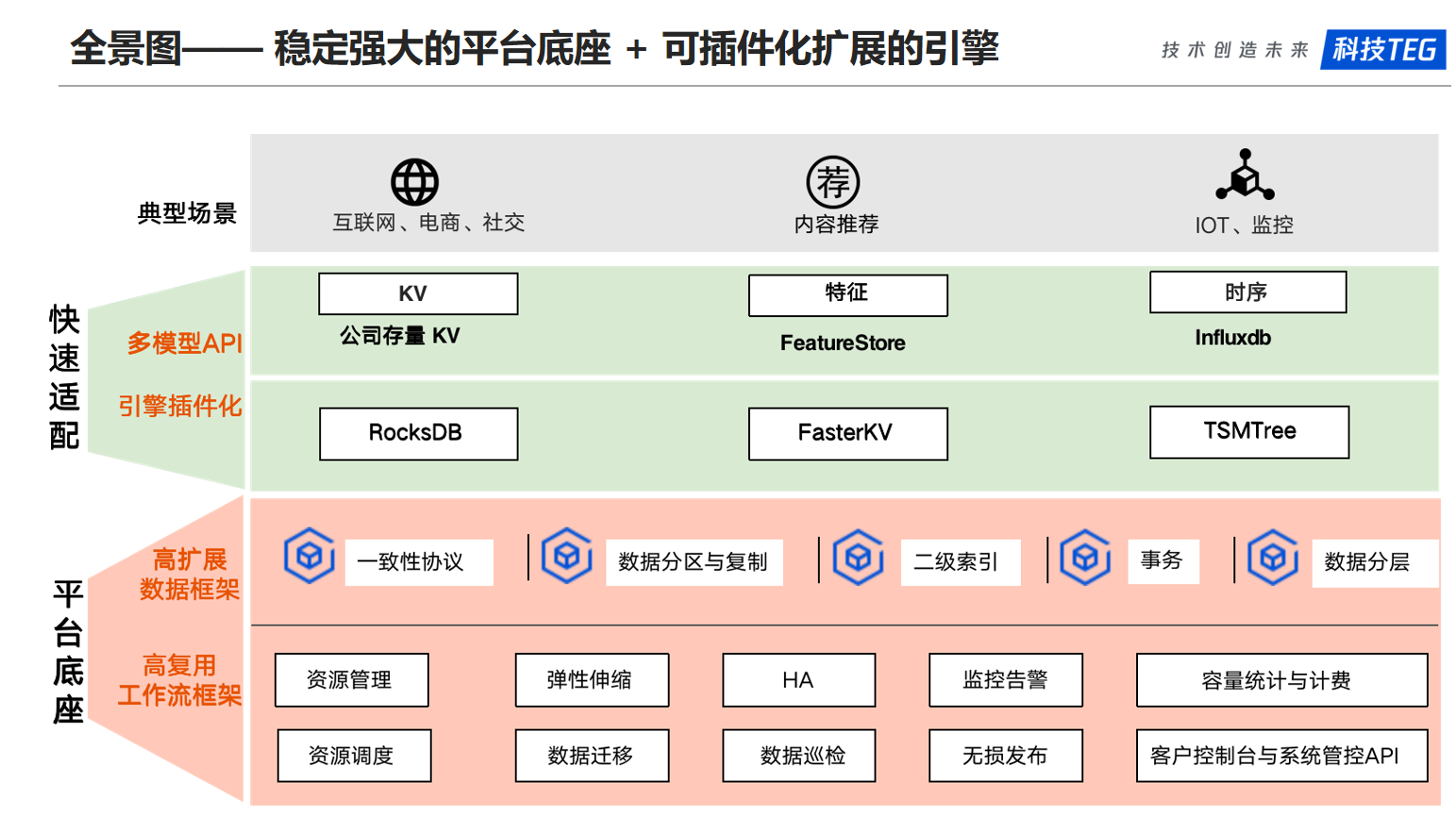
多模型 NoSQL 兩個核心目標:一是要提供穩定強大的平台底座,供不同的擴展實現復用;二是提供快速適配的能力,供業務訂製化開發或者是新的場景的擴展。
平台底座,包括在線訪問相關和管控相關。一 在線訪問相關部分,提供高度可擴展的數據處理框架,具體包括支援多種數據一致性,數據分區與多 AZ/Region 的數據副本複製、數據分層以及索引和事務等方面的能力。二 管控相關的部分,提供工作流引擎 WorkFlow,並基於這個工作流引擎實現了資源管理、數據遷移、數據備份和定點回檔、數據巡檢等運營管控能力。
快速適配,包括可擴展多模型API和存儲引擎框架。可擴展多模型 API,方便協同方根據業務場景需求訂製訪問協議。目前的 API 介面已支援TSSD/BDB/Grocery 等存量鍵值存儲平台的介面和功能,同時也支援了部分 Redis 的介面。存儲引擎的框架,方便根據業務場景訂製自己的存儲引擎,在記憶體佔用和磁碟 IO 資源方面進行取捨和平衡。目前已經支援的 LSM-Tree 的 RocksDB 存儲引擎,基於Hash的 FasterKV 引擎和基於 TSM-Tree 的時序 TSDB 存儲引擎。
多模型 NoSQL 資源概念

多模型 NoSQL 資源概念,我們分為用戶資源和物理資源。
用戶資源是用戶創建的邏輯資源,主要有 Account、Keyspace、Collection、Partition、Replica。這裡大家比較陌生的可能是 Account 這個概念。多模型 NoSQL 的 Account 主要不是為了計費設計的,它跟騰訊雲的賬戶或者公司內計費的 OBS 系統的賬戶不一樣,主要目的是方便客戶配置 Collection 的公共屬性,以及底層根據 Collection 的相關性做資源的共享,比如接入機關聯的北極星的入口,甚至同賬戶下的 Replica 副本將他們調度到一起,方便在資源層面進行多租戶隔離和復用。
物理資源是管理的伺服器資源,目前我們申請的存儲伺服器和接入/邏輯類的TKE容器。對於存儲伺服器進行容器化,比如對一個配置了12塊SSD 的存儲伺服器,我們創建了12個 TKE 的容器,讓每個容器關聯到一塊 SSD 盤,我們稱之為一個 Pod,相應地這台存儲伺服器我們稱之為一個 Node。根據硬體的物理分布,我們給每個 PoD 的關聯地域屬性 Region,集群屬性 Cluster,子集群的屬性Subcluster Group,我們稱為 SCG,子集群屬性Subcluster Region、Subcluster Group 和 Subcluster 之間是逐層包含的一個關係。SCG將指定數量的Node組成一個節點組,而 Subcluster 的是加 SCG 的部分盤組成的一個盤組。通過將一個Partition多個副本分布在這些Group的內部,方便有效地管理同時多個節點或者磁碟故障帶來的風險,同時也能控制我們在故障發生時的爆炸半徑,影響半徑。有興趣的同學可以在網上 google 下 CopySet 的論文,對其原理做進一步的了解。
多模型 NoSQL 模組結構

多模型 NoSQL 的模組架構中,我們分為數據面和控制面。數據面主要是指業務在線增/刪/改/查請求路徑上的模組;控制面是業務的控制台、運維繫統,或者內部的定時任務維護處理所涉及的模組。
數據面模組架構,為方便長尾延時的管控和成本的控制,採用兩層設計,服務一個請求後端最多經過兩跳,業務場景需求設計三類請求處理。
常規路徑(標①),請求到達接入層 gateway,其查詢本地快取的元資訊,並將請求轉發給底層的存儲模組cell,獨立gateway部署方便於收斂前端網路連接數,以及業務前端不支援訂製SDK的場景。
快取路徑(標②),請求到達接入層 cache,其查詢本地的記憶體快取,如果命中就直接返回,如果不命中,訪問底層存儲模組 cell 查詢獲取並通知 cache 主節點,由 cache 主節點根據預配置的快取策略更新快取並基於一致性協議同步更新給所有 cache 從節點。便於降低有明顯熱點效應的業務請求,降低訪問成本。
訂製路徑(標③),通過訂製的 sdk 允許客戶端直連存儲節點,實現一跳訪問,同時也可以將部分計算功能卸載到客戶端上執行,有利於降低訪問延時,減少計算成本。
控制面模組結構,控制面對外的訪問入口有兩個訪問網關和三個內部部分。訪問網關為 userAdmin 和 sysAdmin,userAdmin 是供客戶控制台API訪問的網關,sysAdmin 是供運維繫統訪問的網關。內部三個部分分別是元數據的存儲和分發、工作流 Workflow 和監控。
元數據存儲和分發,主要是資源管理服務,包含資源管理服務(RM)和資源管理快取服務(RMC)。元數據採用分散式的強一致存儲,目前是五副本存儲在 CMongo 中,未來會考慮閉環存儲於自身系統裡面。RMC是為了方便於元數據分發而設計的,數據面的 gateway 和 cache 服務啟動後會註冊到RMC,方便 RMC 做元數據的增量、推送、分發和一次性校驗,通過 userAdmin 和 sysAdmin 網關訪問 RM,實現元數據的更新,RMC 通過更新流感知到這個數據的變動,並推知元數據的更新給註冊到自己的 gateway 和 cache 容器。
工作流 Workflow,以往存儲管控的實踐中,通常是基於微服務架構設計數據遷移服務、數據巡檢服務、數據調度服務、容量採集服務、數據冷備服務、資源上下架服務等眾多的獨立模組上來實現存儲管控。雖然實現了較好的伸縮性,但模組多會增加開發、維護、運營、管理方面的成本。在 X-Stor 中,我們設計的是 Workflow 框架,搭積木的方式配置組裝處理流程,實現可重入的執行。通過 Workflow 框架,結合容器化部署,共用一個 Workflow 服務來實現上述的所有功能,同時自動伸縮和容錯,對所有的 Workflow 執行、日誌存檔和審計等能力也非常容易實現。
監控,通過在每個伺服器 Node 的上面本地部署 NodeAgent,實時彙集本 Node 上的各個容器的狀態資訊,並且推送給集群的 Monitor 服務。 Monitor 服務對接到 Prometheus 的存儲、集群調度服務、監控報警組件如 TEG 智研監控寶等,可以方便地按集群實現實時調度和基於 Grafana 訂製一個自己的可視化 Dashboard。
雲原生能力設計與思考
可擴展和雲原生是我們設計多模型 NoSQL 時考慮的兩個目標。前面介紹了實現擴展性的相關的架構內容,系統助於擴展性,支援多種數據訪問、API 和存儲引擎來實現多模型存儲。接下來我想分享下在雲原生上的設計思考。
雲原生這個詞是最近幾年大家經常聽到的概念,但當你百度這個概念時卻發現很難比較清晰的理解。我個人的理解,雲原生核心有兩個概念,雲原生產品和雲原生技術。雲原生產品是在公有雲普及的大背景下,站在客戶的視角,對雲端提供服務的產品提出的能力和要求,比如彈性伸縮、可觀測性等。雲原生技術是幫助實現雲原生產品的技術手段,如容器、服務網格、微服務、不可變的基礎設施和聲明式 api 等。多模型 NoSQL 從設計之初,我們就與相關的原生技術進行緊密結合,考慮了基於雲原生的能力。我們雲原生的特性重點體現在開放性、彈性伸縮、按需付費、多 AZ 和 Region 數據分布四個方面。
01 開放性

多模型 NoSQL 的開放性主要在下面三個維度進行體現。
首先,介面和功能的開放。客戶出於成本、容錯等方面的考慮提出了多雲的訴求,要求對雲端產品打破廠商綁定(Vendor Lockin),需要產品可以實現在不同的雲廠商間遷移。雲原生產品需要尊重這個考慮,我們放棄了鎖定自定義私有協議和介面,轉向全面兼容垂直社區軟體介面和功能,如 Redis、InfluxDB 等,未來還會在數據遷移 DTS 能力方面進一步補齊。
其次,支援擴展、開放互聯的連接器(Connector)。不斷豐富跟公有雲上的其他的雲原生產品實現互聯互通,如目前我們已經支援的數據鏡像、備份和更新流水存放於對象存儲產品 COS 或者其他兼容 S3 介面的產品,更新流可以導入到我們 Kafka 隊列中,未來可能會推出更多的連接器,能連接到相關的雲端產品。
最後,在資源層面,部署產品時不鎖定特定的硬體資源。我們率先在公司內實現了從接入到存儲完全架構在 K8S 的容器化化環境中,從能力上可以支援多雲和分散式雲的部署。
02 彈性伸縮
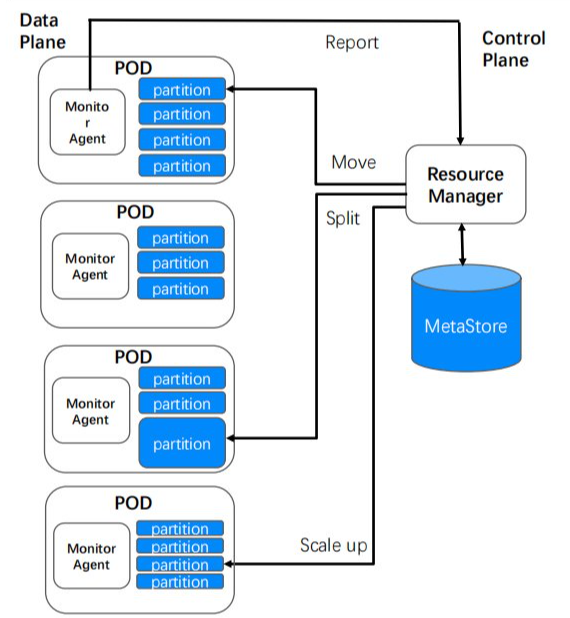
彈性伸縮,是雲原生產品非常重要的能力,解決以往自行開發在軟體架構層面或者在資源層面上面臨的一些瓶頸。多模型 NoSQL 從客戶資源、伺服器或者容器資源方面實現了彈性伸縮。
首先,通過分散式強一致存儲和分發的架構,提供強大的元數據存儲和訪問能力,支援用戶的庫表數量和單個庫表容量的伸縮能力;通過水平伸縮的架構和底層的調度能力,支援單個表在存儲和訪問容量上無限橫向伸縮。
其次,通過對資源的容器化和標準化,實現了從公司大的資源池中實時申請和釋放容器資源,便於我們快速地滿足業務在資源規格、資源數量和資源在機房分布等方面的要求。
最後,在伸縮的速度和效率方面,藉助前面提到的數據副本的分布策略和數據的實時採集調度,實現了極速地擴容和自動化伸縮,垂直伸縮小於10秒,4TB 水平伸縮小於5分鐘。
03 按需付費
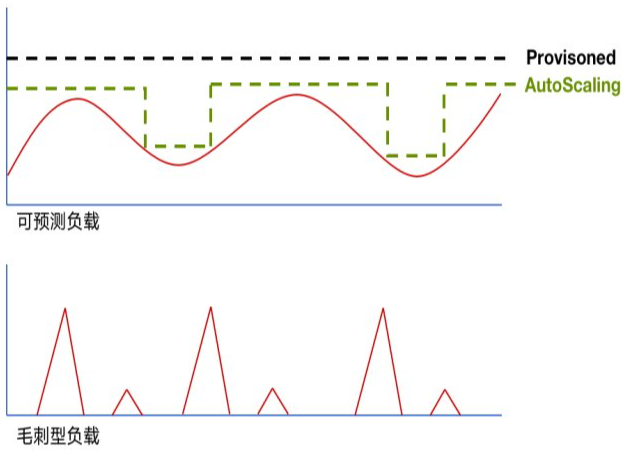
按需付費,是雲原生產品幫助客戶實現低成本運營的關鍵能力。在這方面我們主要實現了兩個方面的能力。
一是存儲和計算的分開計費。不需要客戶從幾個預定規格的容器中去做選擇,客戶僅需要關注於存儲容量和計算容量,底層通過集約化管理給各個庫表預留的 Buffer Pool,通過多租戶技術和裝箱調度,提升資源的整體利用率,通過我們的資源池管理和資源利用率提升達到幫助客戶去節省運營成本。
其次,靈活選擇。通過在客戶控制台/API 中方便靈活選擇,而不是剛性地捆綁/錨定,實現貼合業務場景需求來實現最高的性價比。如我們在於數據的一致性,數據的副本數,多 Region 的分布,數據生命周期,甚至存儲介質方面靈活地配置。在資源獨享方面,平衡成本和性能,在存儲機和接入機方面獨享和混用,可以獨立配置。
04 多 AZ 和 Region 分布
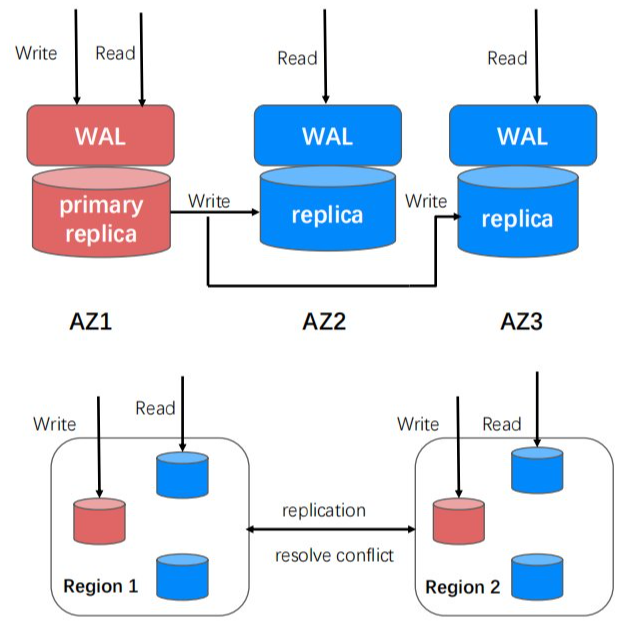
多 AZ 和 Region 分布,是雲原生產品實現高可用性、數據高可靠性方面的基礎要求。
公有雲中的 AZ 和 Region 跟我們常見的機房和城市的概念不完全一樣。如同 Region 下的多個 AZ 要求相距30到100千米,RTT 一般在0.5到2毫秒以內。不同 Region 間的物理距離一般在100千米以上。X-Stor 通過對資源構建 AZ 和 Region 的屬性,並結合集群調度、數據同步等方面的支援,實現了多 AZ 和 Region 數據分布的能力,可結合業務自身對於數據的一致性需求實現就近訪問;同時也計劃在多 Region 分布的基礎上,支援異地多活(Multi-Master)。對於多 Region 分布的 Collection,可以在任意的 Region 中就近寫入,內部我們對於 Region 間的數據進行複製,並解決並發衝突的問題,進一步優化寫延時的體驗。
關於我們
更多關於雲原生的案例和知識,可關注同名【騰訊雲原生】公眾號~
福利:
①公眾號後台回復【手冊】,可獲得《騰訊雲原生路線圖手冊》&《騰訊雲原生最佳實踐》~
②公眾號後台回復【系列】,可獲得《15個系列100+篇超實用雲原生原創乾貨合集》,包含Kubernetes 降本增效、K8s 性能優化實踐、最佳實踐等系列。
③公眾號後台回復【白皮書】,可獲得《騰訊雲容器安全白皮書》&《降本之源-雲原生成本管理白皮書v1.0》
④公眾號後台回復【光速入門】,可獲得騰訊雲專家5萬字精華教程,光速入門Prometheus和Grafana。
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多乾貨!!



