萬字長文詳解HBase讀寫性能優化
一、HBase 讀優化
1. HBase客戶端優化
和大多數系統一樣,客戶端作為業務讀寫的入口,姿勢使用不正確通常會導致本業務讀延遲較高實際上存在一些使用姿勢的推薦用法,這裡一般需要關注四個問題:
1) scan快取是否設置合理?
優化原理:在解釋這個問題之前,首先需要解釋什麼是scan快取,通常來講一次scan會返回大量數據,因此客戶端發起一次scan請求,實際並不會一次就將所有數據載入到本地,而是分成多次RPC請求進行載入,這樣設計一方面是因為大量數據請求可能會導致網路頻寬嚴重消耗進而影響其他業務,另一方面也有可能因為數據量太大導致本地客戶端發生OOM。在這樣的設計體系下用戶會首先載入一部分數據到本地,然後遍歷處理,再載入下一部分數據到本地處理,如此往複,直至所有數據都載入完成。數據載入到本地就存放在scan快取中,默認100條數據大小。
通常情況下,默認的scan快取設置就可以正常工作的。但是在一些大scan(一次scan可能需要查詢幾萬甚至幾十萬行數據)來說,每次請求100條數據意味著一次scan需要幾百甚至幾千次RPC請求,這種交互的代價無疑是很大的。因此可以考慮將scan快取設置增大,比如設為500或者1000就可能更加合適。筆者之前做過一次試驗,在一次scan掃描10w+條數據量的條件下,將scan快取從100增加到1000,可以有效降低scan請求的總體延遲,延遲基本降低了25%左右。
優化建議:大scan場景下將scan快取從100增大到500或者1000,用以減少RPC次數
2) get請求是否可以使用批量請求?
優化原理:HBase分別提供了單條get以及批量get的API介面,使用批量get介面可以減少客戶端到RegionServer之間的RPC連接數,提高讀取性能。另外需要注意的是,批量get請求要麼成功返回所有請求數據,要麼拋出異常。
優化建議:使用批量get進行讀取請求
3) 請求是否可以顯示指定列族或者列?
優化原理:HBase是典型的列族資料庫,意味著同一列族的數據存儲在一起,不同列族的數據分開存儲在不同的目錄下。如果一個表有多個列族,只是根據Rowkey而不指定列族進行檢索的話不同列族的數據需要獨立進行檢索,性能必然會比指定列族的查詢差很多,很多情況下甚至會有2倍~3倍的性能損失。
優化建議:可以指定列族或者列進行精確查找的盡量指定查找
4) 離線批量讀取請求是否設置禁止快取?
優化原理:通常離線批量讀取數據會進行一次性全表掃描,一方面數據量很大,另一方面請求只會執行一次。這種場景下如果使用scan默認設置,就會將數據從HDFS載入出來之後放到快取。可想而知,大量數據進入快取必將其他實時業務熱點數據擠出,其他業務不得不從HDFS載入,進而會造成明顯的讀延遲毛刺
優化建議:離線批量讀取請求設置禁用快取,scan.setBlockCache(false)
2. HBase伺服器端優化
一般服務端端問題一旦導致業務讀請求延遲較大的話,通常是集群級別的,即整個集群的業務都會反映讀延遲較大。可以從4個方面入手:
1) 讀請求是否均衡?
優化原理:極端情況下假如所有的讀請求都落在一台RegionServer的某幾個Region上,這一方面不能發揮整個集群的並發處理能力,另一方面勢必造成此台RegionServer資源嚴重消耗(比如IO耗盡、handler耗盡等),落在該台RegionServer上的其他業務會因此受到很大的波及。可見,讀請求不均衡不僅會造成本身業務性能很差,還會嚴重影響其他業務。當然,寫請求不均衡也會造成類似的問題,可見負載不均衡是HBase的大忌。
觀察確認:觀察所有RegionServer的讀請求QPS曲線,確認是否存在讀請求不均衡現象
優化建議:RowKey必須進行散列化處理(比如MD5散列),同時建表必須進行預分區處理
2) BlockCache是否設置合理?
優化原理:BlockCache作為讀快取,對於讀性能來說至關重要。默認情況下BlockCache和Memstore的配置相對比較均衡(各佔40%),可以根據集群業務進行修正,比如讀多寫少業務可以將BlockCache佔比調大。另一方面,BlockCache的策略選擇也很重要,不同策略對讀性能來說影響並不是很大,但是對GC的影響卻相當顯著,尤其BucketCache的offheap模式下GC表現很優越。另外,HBase 2.0對offheap的改造(HBASE-11425)將會使HBase的讀性能得到2~4倍的提升,同時GC表現會更好!
觀察確認:觀察所有RegionServer的快取未命中率、配置文件相關配置項一級GC日誌,確認BlockCache是否可以優化
優化建議:JVM記憶體配置量 < 20G,BlockCache策略選擇LRUBlockCache;否則選擇BucketCache策略的offheap模式;期待HBase 2.0的到來!
3) HFile文件是否太多?
優化原理:HBase讀取數據通常首先會到Memstore和BlockCache中檢索(讀取最近寫入數據&熱點數據),如果查找不到就會到文件中檢索。HBase的類LSM結構會導致每個store包含多數HFile文件,文件越多,檢索所需的IO次數必然越多,讀取延遲也就越高。文件數量通常取決於Compaction的執行策略,一般和兩個配置參數有關:
hbase.hstore.compactionThreshold
hbase.hstore.compaction.max.size
前者表示一個store中的文件數超過多少就應該進行合併,後者表示參數合併的文件大小最大是多少,超過此大小的文件不能參與合併。這兩個參數不能設置太』松』(前者不能設置太大,後者不能設置太小),導致Compaction合併文件的實際效果不明顯,進而很多文件得不到合併。這樣就會導致HFile文件數變多。
觀察確認:觀察RegionServer級別以及Region級別的storefile數,確認HFile文件是否過多
優化建議:hbase.hstore.compactionThreshold設置不能太大,默認是3個;設置需要根據Region大小確定,通常可以簡單的認為 hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
4) Compaction是否消耗系統資源過多?
優化原理:Compaction是將小文件合併為大文件,提高後續業務隨機讀性能,但是也會帶來IO放大以及頻寬消耗問題(數據遠程讀取以及三副本寫入都會消耗系統頻寬)。正常配置情況下Minor Compaction並不會帶來很大的系統資源消耗,除非因為配置不合理導致Minor Compaction太過頻繁,或者Region設置太大情況下發生Major Compaction。
觀察確認:觀察系統IO資源以及頻寬資源使用情況,再觀察Compaction隊列長度,確認是否由於Compaction導致系統資源消耗過多
優化建議:
-
Minor Compaction設置:hbase.hstore.compactionThreshold設置不能太小,又不能設置太大,因此建議設置為5~6;hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
-
Major Compaction設置:大Region讀延遲敏感業務( 100G以上)通常不建議開啟自動Major Compaction,手動低峰期觸發。小Region或者延遲不敏感業務可以開啟Major Compaction,但建議限制流量;
-
期待更多的優秀Compaction策略,類似於stripe-compaction儘早提供穩定服務
3. HBase列族設計優化
HBase列族設計對讀性能影響也至關重要,其特點是隻影響單個業務,並不會對整個集群產生太大影響。列族設計主要從以下方面檢查:
1) Bloomfilter是否設置?是否設置合理?
優化原理:Bloomfilter主要用來過濾不存在待檢索RowKey或者Row-Col的HFile文件,避免無用的IO操作。它會告訴你在這個HFile文件中是否可能存在待檢索的KV,如果不存在,就可以不用消耗IO打開文件進行seek。很顯然,通過設置Bloomfilter可以提升隨機讀寫的性能。
Bloomfilter取值有兩個,row以及rowcol,需要根據業務來確定具體使用哪種。如果業務大多數隨機查詢僅僅使用row作為查詢條件,Bloomfilter一定要設置為row,否則如果大多數隨機查詢使用row+cf作為查詢條件,Bloomfilter需要設置為rowcol。如果不確定業務查詢類型,設置為row。
優化建議:任何業務都應該設置Bloomfilter,通常設置為row就可以,除非確認業務隨機查詢類型為row+cf,可以設置為rowcol
4. HDFS相關優化
HDFS作為HBase最終數據存儲系統,通常會使用三副本策略存儲HBase數據文件以及日誌文件。從HDFS的角度望上層看,HBase即是它的客戶端,HBase通過調用它的客戶端進行數據讀寫操作,因此HDFS的相關優化也會影響HBase的讀寫性能。這裡主要關注如下三個方面:
1) Short-Circuit Local Read功能是否開啟?
優化原理:當前HDFS讀取數據都需要經過DataNode,客戶端會向DataNode發送讀取數據的請求,DataNode接受到請求之後從硬碟中將文件讀出來,再通過TPC發送給客戶端。Short Circuit策略允許客戶端繞過DataNode直接讀取本地數據。(具體原理參考此處)
優化建議:開啟Short Circuit Local Read功能,具體配置戳這裡
2) Hedged Read功能是否開啟?
優化原理:HBase數據在HDFS中一般都會存儲三份,而且優先會通過Short-Circuit Local Read功能嘗試本地讀。但是在某些特殊情況下,有可能會出現因為磁碟問題或者網路問題引起的短時間本地讀取失敗,為了應對這類問題,社區開發者提出了補償重試機制 – Hedged Read。該機制基本工作原理為:客戶端發起一個本地讀,一旦一段時間之後還沒有返回,客戶端將會向其他DataNode發送相同數據的請求。哪一個請求先返回,另一個就會被丟棄。
優化建議:開啟Hedged Read功能,具體配置參考這裡
3) 數據本地率是否太低?
數據本地率:HDFS數據通常存儲三份,假如當前RegionA處於Node1上,數據a寫入的時候三副本為(Node1,Node2,Node3),數據b寫入三副本是(Node1,Node4,Node5),數據c寫入三副本(Node1,Node3,Node5),可以看出來所有數據寫入本地Node1肯定會寫一份,數據都在本地可以讀到,因此數據本地率是100%。現在假設RegionA被遷移到了Node2上,只有數據a在該節點上,其他數據(b和c)讀取只能遠程跨節點讀,本地率就為33%(假設a,b和c的數據大小相同)。
優化原理:數據本地率太低很顯然會產生大量的跨網路IO請求,必然會導致讀請求延遲較高,因此提高數據本地率可以有效優化隨機讀性能。數據本地率低的原因一般是因為Region遷移(自動balance開啟、RegionServer宕機遷移、手動遷移等),因此一方面可以通過避免Region無故遷移來保持數據本地率,另一方面如果數據本地率很低,也可以通過執行major_compact提升數據本地率到100%。
優化建議:避免Region無故遷移,比如關閉自動balance、RS宕機及時拉起並遷回飄走的Region等;在業務低峰期執行major_compact提升數據本地率
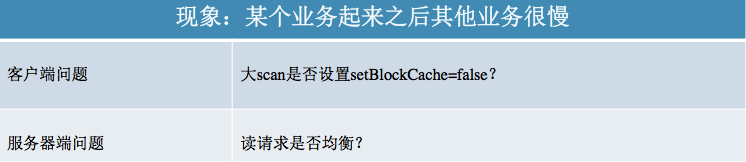
5. HBase讀性能優化歸納
在本文開始的時候提到讀延遲較大無非三種常見的表象,單個業務慢、集群隨機讀慢以及某個業務隨機讀之後其他業務受到影響導致隨機讀延遲很大。了解完常見的可能導致讀延遲較大的一些問題之後,我們將這些問題進行如下歸類,讀者可以在看到現象之後在對應的問題列表中進行具體定位:


二、HBase 寫優化
和讀相比,HBase寫數據流程倒是顯得很簡單:數據先順序寫入HLog,再寫入對應的快取Memstore,當Memstore中數據大小達到一定閾值(128M)之後,系統會非同步將Memstore中數據flush到HDFS形成小文件。
HBase數據寫入通常會遇到兩類問題,一類是寫性能較差,另一類是數據根本寫不進去。這兩類問題的切入點也不盡相同,如下圖所示:
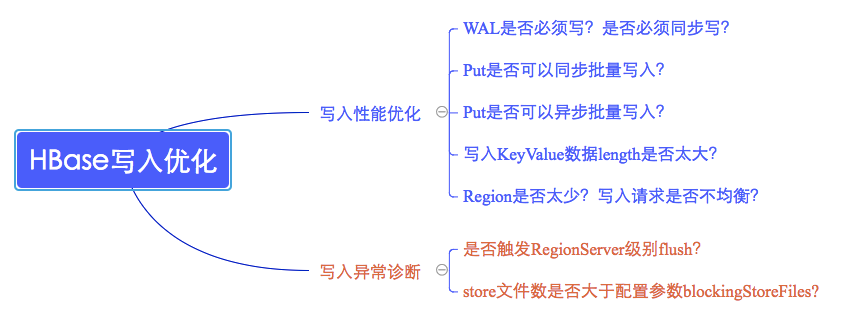
1. 寫性能優化切入點
1) 是否需要寫WAL?WAL是否需要同步寫入?
優化原理:數據寫入流程可以理解為一次順序寫WAL+一次寫快取,通常情況下寫快取延遲很低,因此提升寫性能就只能從WAL入手。WAL機制一方面是為了確保數據即使寫入快取丟失也可以恢復,另一方面是為了集群之間非同步複製。默認WAL機制開啟且使用同步機制寫入WAL。首先考慮業務是否需要寫WAL,通常情況下大多數業務都會開啟WAL機制(默認),但是對於部分業務可能並不特別關心異常情況下部分數據的丟失,而更關心數據寫入吞吐量,比如某些推薦業務,這類業務即使丟失一部分用戶行為數據可能對推薦結果並不構成很大影響,但是對於寫入吞吐量要求很高,不能造成數據隊列阻塞。這種場景下可以考慮關閉WAL寫入,寫入吞吐量可以提升2x~3x。退而求其次,有些業務不能接受不寫WAL,但可以接受WAL非同步寫入,也是可以考慮優化的,通常也會帶來1x~2x的性能提升。
優化推薦:根據業務關注點在WAL機制與寫入吞吐量之間做出選擇
其他注意點:對於使用Increment操作的業務,WAL可以設置關閉,也可以設置非同步寫入,方法同Put類似。相信大多數Increment操作業務對WAL可能都不是那麼敏感~
2) Put是否可以同步批量提交?
優化原理:HBase分別提供了單條put以及批量put的API介面,使用批量put介面可以減少客戶端到RegionServer之間的RPC連接數,提高寫入性能。另外需要注意的是,批量put請求要麼全部成功返回,要麼拋出異常。
優化建議:使用批量put進行寫入請求
3) Put是否可以非同步批量提交?
優化原理:業務如果可以接受異常情況下少量數據丟失的話,還可以使用非同步批量提交的方式提交請求。提交分為兩階段執行:用戶提交寫請求之後,數據會寫入客戶端快取,並返回用戶寫入成功;當客戶端快取達到閾值(默認2M)之後批量提交給RegionServer。需要注意的是,在某些情況下客戶端異常的情況下快取數據有可能丟失。
優化建議:在業務可以接受的情況下開啟非同步批量提交
使用方式:setAutoFlush(false)
4) Region是否太少?
優化原理:當前集群中表的Region個數如果小於RegionServer個數,即Num(Region of Table) < Num(RegionServer),可以考慮切分Region並儘可能分布到不同RegionServer來提高系統請求並發度,如果Num(Region of Table) > Num(RegionServer),再增加Region個數效果並不明顯。
優化建議:在Num(Region of Table) < Num(RegionServer)的場景下切分部分請求負載高的Region並遷移到其他RegionServer;
5) 寫入請求是否不均衡?
優化原理:另一個需要考慮的問題是寫入請求是否均衡,如果不均衡,一方面會導致系統並發度較低,另一方面也有可能造成部分節點負載很高,進而影響其他業務。分散式系統中特別害怕一個節點負載很高的情況,一個節點負載很高可能會拖慢整個集群,這是因為很多業務會使用Mutli批量提交讀寫請求,一旦其中一部分請求落到該節點無法得到及時響應,就會導致整個批量請求超時。因此不怕節點宕掉,就怕節點奄奄一息!
優化建議:檢查RowKey設計以及預分區策略,保證寫入請求均衡。
6) 寫入KeyValue數據是否太大?
KeyValue大小對寫入性能的影響巨大,一旦遇到寫入性能比較差的情況,需要考慮是否由於寫入KeyValue數據太大導致。KeyValue大小對寫入性能影響曲線圖如下:

圖中橫坐標是寫入的一行數據(每行數據10列)大小,左縱坐標是寫入吞吐量,右坐標是寫入平均延遲(ms)。可以看出隨著單行數據大小不斷變大,寫入吞吐量急劇下降,寫入延遲在100K之後急劇增大。
說到這裡,有必要和大家分享兩起在生產線環境因為業務KeyValue較大導致的嚴重問題,一起是因為大欄位業務寫入導致其他業務吞吐量急劇下降,另一起是因為大欄位業務scan導致RegionServer宕機。
案件一:大欄位寫入導致其他業務吞吐量急劇下降
部分業務回饋集群寫入忽然變慢、數據開始堆積的情況,查看集群表級別的數據讀寫QPS監控,發現問題的第一個關鍵點:業務A開始寫入之後整個集群其他部分業務寫入QPS都幾乎斷崖式下跌,初步懷疑黑手就是業務A。
下圖是當時業務A的寫入QPS(事後發現腦殘忘了截取其他表QPS斷崖式下跌的慘象),但是第一感覺是QPS並不高啊,憑什麼去影響別人!
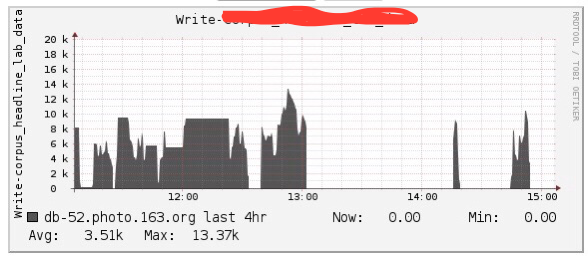
於是就繼續查看其他監控資訊,首先確認系統資源(主要是IO)並沒有到達瓶頸,其次確認了寫入的均衡性,直至看到下圖,才追蹤到影響其他業務寫入的第二個關鍵點:RegionServer的handler(配置150)被殘暴耗盡:
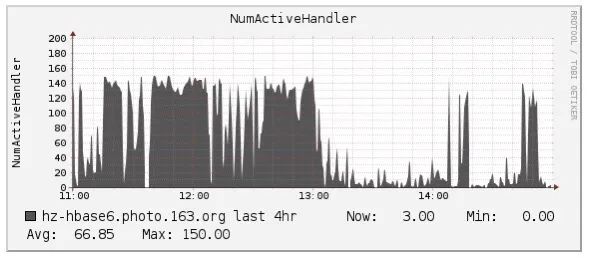
對比上面兩張圖,是不是發現出奇的一致,那就可以基本確認是由於該業務寫入導致這台RegionServer的handler被耗盡,進而其他業務拿不到handler,自然寫不進去。那問題來了,為什麼會這樣?正常情況下handler在處理完客戶端請求之後會立馬釋放,唯一的解釋是這些請求的延遲實在太大。
試想,我們去漢堡店排隊買漢堡,有150個窗口服務,正常情況下大家買一個很快,這樣150個窗口可能只需要50個服務。假設忽然來了一批大漢,要訂製超大漢堡,好了,所有的窗口都工作起來,而且因為大漢堡不好製作導致服務很慢,這樣必然會導致其他排隊的用戶長時間等待,直至超時。
可回頭一想這可是寫請求啊,怎麼會有這麼大的請求延遲!和業務方溝通之後確認該表主要存儲語料庫文檔資訊,都是平均100K左右的數據,是不是已經猜到了結果,沒錯,就是因為這個業務KeyValue太大導致。KeyValue太大會導致HLog文件寫入頻繁切換、flush以及compaction頻繁觸發,寫入性能急劇下降。
目前針對這種較大KeyValue寫入性能較差的問題還沒有直接的解決方案,好在社區已經意識到這個問題,在接下來即將發布的下一個大版本HBase 2.0.0版本會針對該問題進行深入優化,詳見HBase MOB,優化後用戶使用HBase存儲文檔、圖片等二進位數據都會有極佳的性能體驗。
案件二:大欄位scan導致RegionServer宕機
案件現場:有段時間有個0.98集群的RegionServer經常頻繁宕機,查看日誌是由於」java.lang.OutOfMemoryError: Requested array size exceeds VM limit」,如下圖所示:

原因分析:通過查看源碼以及相關文檔,確認該異常發生在scan結果數據回傳給客戶端時由於數據量太大導致申請的array大小超過JVM規定的最大值( Interge.Max_Value-2)。造成該異常的兩種最常見原因分別是:
-
表列太寬(幾十萬列或者上百萬列),並且scan返回沒有對列數量做任何限制,導致一行數據就可能因為包含大量列而數據超過array大小閾值
-
KeyValue太大,並且scan返回沒有對返回結果大小做任何限制,導致返回數據結果大小超過array大小閾值
有的童鞋就要提問啦,說如果已經對返回結果大小做了限制,在表列太寬的情況下是不是就可以不對列數量做限制呢。這裡需要澄清一下,如果不對列數據做限制,數據總是一行一行返回的,即使一行數據大小大於設置的返回結果限制大小,也會返回完整的一行數據。在這種情況下,如果這一行數據已經超過array大小閾值,也會觸發OOM異常。
解決方案:目前針對該異常有兩種解決方案,其一是升級集群到1.0,問題都解決了。其二是要求客戶端訪問的時候對返回結果大小做限制(scan.setMaxResultSize(210241024))、並且對列數量做限制(scan.setBatch(100)),當然,0.98.13版本以後也可以對返回結果大小在伺服器端進行限制,設置參數hbase.server.scanner.max.result.size即可
2. 寫異常問題檢查點
上述幾點主要針對寫性能優化進行了介紹,除此之外,在一些情況下還會出現寫異常,一旦發生需要考慮下面兩種情況(GC引起的不做介紹):
Memstore設置是否會觸發Region級別或者RegionServer級別flush操作?
問題解析:以RegionServer級別flush進行解析,HBase設定一旦整個RegionServer上所有Memstore佔用記憶體大小總和大於配置文件中upperlimit時,系統就會執行RegionServer級別flush,flush演算法會首先按照Region大小進行排序,再按照該順序依次進行flush,直至總Memstore大小低至lowerlimit。這種flush通常會block較長時間,在日誌中會發現「Memstore is above high water mark and block 7452 ms」,表示這次flush將會阻塞7s左右。
問題檢查點:
-
Region規模與Memstore總大小設置是否合理?如果RegionServer上Region較多,而Memstore總大小設置的很小(JVM設置較小或者upper.limit設置較小),就會觸發RegionServer級別flush。集群規劃相關內容可以參考文章《HBase最佳實踐-集群規劃》
-
列族是否設置過多,通常情況下表列族建議設置在1~3個之間,最好一個。如果設置過多,會導致一個Region中包含很多Memstore,導致更容易觸到高水位upperlimit
Store中HFile數量是否大於配置參數blockingStoreFile?
問題解析:對於數據寫入很快的集群,還需要特別關注一個參數:hbase.hstore.blockingStoreFiles,此參數表示如果當前hstore中文件數大於該值,系統將會強制執行compaction操作進行文件合併,合併的過程會阻塞整個hstore的寫入。通常情況下該場景發生在數據寫入很快的情況下,在日誌中可以發現」Waited 3722ms on a compaction to clean up 『too many store files「
問題檢查點:
-
參數設置是否合理?hbase.hstore.compactionThreshold表示啟動compaction的最低閾值,該值不能太大,否則會積累太多文件,一般建議設置為5~8左右。hbase.hstore.blockingStoreFiles默認設置為7,可以適當調大一些。


