hadoop集群搭建
幾年前搞過一段時間hadoop,現在又要開始搞了,發現環境都不會搭建了。寫個部落格記錄下搭建過程。
1、創建虛擬機及規劃
下面是我本地的環境資訊
| 機器名 | IP | 作業系統 |
|---|---|---|
| hadoop1 | 192.168.68.120 | CentOS7 |
| hadoop2 | 192.168.68.121 | CentOS7 |
| hadoop3 | 192.168.68.122 | CentOS7 |
- 修改機器名:
hostnamectl set-hostname [機器名] # hostnamectl set-hostname hadoop1
修改IP資訊:
在
/etc/sysconfig/network-scripts/ifcfg-ens33文件中配置IP資訊。主要修改如下幾項。IPADDR="192.168.68.120" # IP地址 PREFIX="24" # 子網掩碼位數,也可以設置為 NETMASK=255.255.255.0 GATEWAY="192.168.68.1" # 網關
規劃
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | NodeManager | ResourceManager、NodeManager |
| other | JobHistoryServer |
我們首先創建個名的
hadoop用戶,後續所有操作如無特別說明,均是在hadoop用戶下執行.adduser hadoop # 創建hadoop用戶 passwd hadoop # 設置hadoop用戶密碼,回車後輸入hadoop用戶密碼
2、設置各主機之間免密登錄
1、在每台主機hosts文件中添加IP與主機名的映射關係
-
在每台主機
/etc/hosts文件中添加如下內容。/etc/hosts文件hadoop用戶沒有許可權,所以修改這個文件要用root用戶操作。192.168.68.120 hadoop1 192.168.68.121 hadoop2 192.168.68.122 hadoop3
2、設置互信(每台主機都執行)
-
在每台主機生成ssh公鑰私鑰,將公鑰拷貝到所有主機(包括自己)。
ssh-keygen -t rsa #這裡需要連續4個回車 ssh-copy-id hadoop1 ssh-copy-id hadoop2 ssh-copy-id hadoop3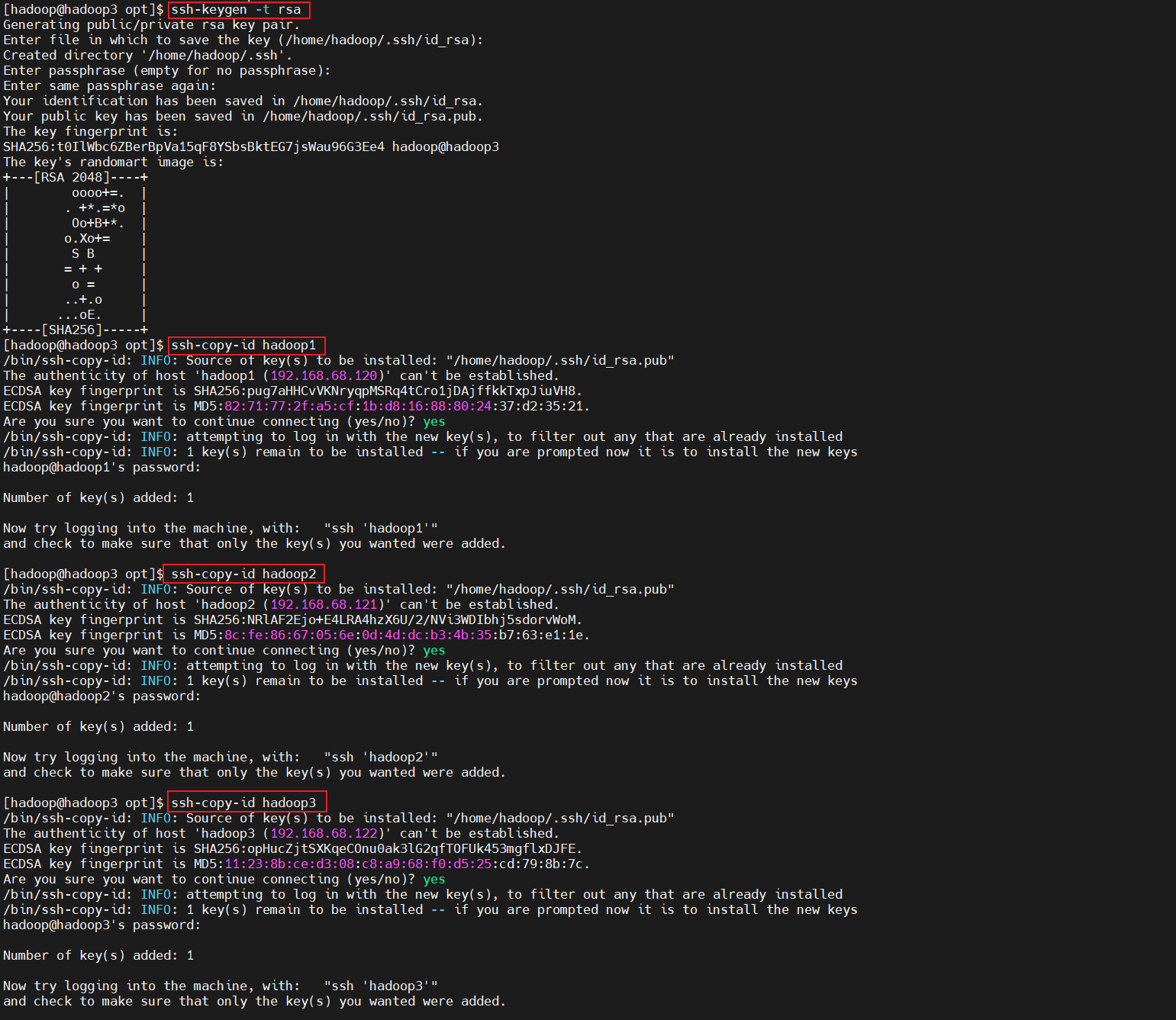

3、安裝JDK和hadoop
需要的軟體是jdk和hadoop,我本次使用的是
jdk-11.0.10_linux-x64_bin.tar.gz、hadoop-3.2.3.tar.gz。我本地軟體安裝位置在
/home/hadoop/software這裡的操作都是在hadoop1上執行,最後會拷貝到hadoop2、hadoop3上
1、上傳軟體包
-
創建安裝目錄
software目錄mkdir /home/hadoop/software -
上傳軟體包
將
jdk-11.0.10_linux-x64_bin.tar.gz、hadoop-3.2.3.tar.gz上傳到/home/hadoop/software目錄中

2、安裝Java,設置環境變數
- 解壓java、hadoop
#在/home/hadoop/software目錄中執行
tar -zxvf jdk-11.0.10_linux-x64_bin.tar.gz # 解壓jdk
tar -zxvf hadoop-3.2.3.tar.gz # 解壓hadoop
-
設置java環境變數
在
~/.bashrc文件中添加如下內容JAVA_HOME=/home/hadoop/software/jdk-11.0.10 CLASSPATH=.:$JAVA_HOME/lib PATH=$PATH:$JAVA_HOME/bin export JAVA_HOME CLASSPATH PATH export HADOOP_HOME=/home/hadoop/software/hadoop-3.2.3 export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin執行如下命令使環境變數生效
source ~/.bashrc
3、配置文件修改
3.1 修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/core-site.xml
<!-- 指定HDFS中NameNode的地址,這裡也就是指定了NameNode在hadoop1這個節點上-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- 指定Hadoop運行時產生文件的存儲目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadoop-3.2.3/data/tmp</value>
</property>
3.修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/hdfs-site.xml
<!-- 指定HDFS中NameNode的web端訪問地址,這裡的節點要和core-site的節點對應起來-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 指定secondary節點主機配置 ,這裡也就是指定了secondary節點在hadoop3-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:50090</value>
</property>
3.修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址,也就是指定resourcemanager所在的節點 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED _HOME</value>
</property>
<!-- 日誌聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日誌保留時間設置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>//hadoop1:19888/jobhistory/logs</value>
</property>
修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 歷史伺服器端地址,也就是指定了歷史伺服器節點 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 歷史伺服器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/workers
hadoop1
hadoop2
hadoop3
4、將上述內容分別拷貝至hadoop2、hadoop3
scp -r /home/hadoop/software/jdk-11.0.10 hadoop2:/home/hadoop/software/
scp -r /home/hadoop/software/jdk-11.0.10 hadoop3:/home/hadoop/software/
scp -r /home/hadoop/software/hadoop-3.2.3 hadoop2:/home/hadoop/software/
scp -r /home/hadoop/software/hadoop-3.2.3 hadoop3:/home/hadoop/software/
scp ~/.bashrc hadoop2:~/
scp ~/.bashrc hadoop3:~/
如果在執行這一步之前已經使用hdoop用戶登錄了hadoop2或者hadoop3,為了使上面拷貝的環境變數生效,需要在
hadoop2,hadoop3上分別執行
source ~/.bashrc命令
4、啟動服務
1、執行初始化命令
在hadoop1節點上執行
hdfs namenode -format #只在namenode節點執行

看到上面這句就表示執行成功。
2、啟動hadoop集群
在hadoop1節點上執行如下命令
start-dfs.sh # 需要在namenode節點上執行

分別在每台主機執行jps命令檢查進程是否啟動正常

同時也可以通過web介面進行訪問//192.168.68.120:9870/dfshealth.html#tab-overview

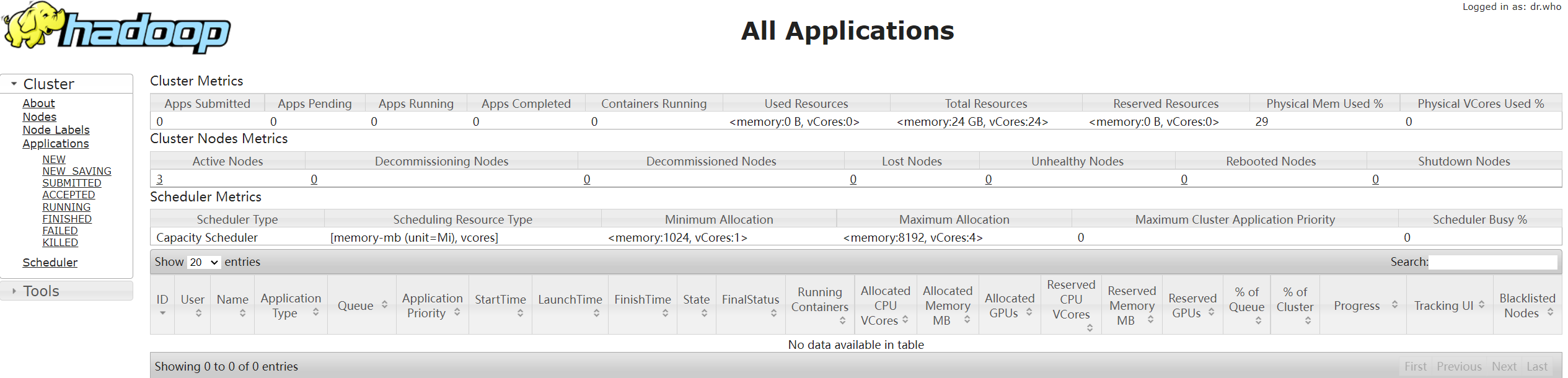
3、啟動yarn。
在hadoop3 節點上實行如下命令
start-yarn.sh #注意這個需要在yarn所在節點啟動(`yarn-site.xml`中`yarn.resourcemanager.hostname`屬性指定)。
再次通過檢查每台主機進程是否啟動正常

也可以通過web介面進行訪問//192.168.68.122:8088/cluster
4、啟動歷史伺服器.
在hadoop1節點上執行如下命令。(通過mapred-site.xml配置文件中指定)
mapred --daemon start historyserver

到這裡,整個hadoop集群就已經搭建完成了。
各個服務組件逐一啟動/停止
(1)分別啟動/停止 HDFS 組件
hdfs --daemon start/stop namenode/datanode/secondarynamenode(2)啟動/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager


