【Python數據分析案例】python數據分析老番茄B站數據(pandas常用基礎數據分析程式碼)
- 2022 年 5 月 7 日
- 筆記
- pandas, pandas數據分析, python可視化, Python數據分析, 數據分析, 統計分析
一、爬取老番茄B站數據
前幾天開發了一個python爬蟲腳本,成功爬取了B站李子柒的影片數據,共142個影片,17個欄位,含:
影片標題,影片地址,影片上傳時間,影片時長,是否合作影片,影片分區,彈幕數,播放量,點贊數,投幣量,收藏量,評論數,轉發量,實時爬取時間
基於這個Python爬蟲程式,我更換了up主的UID,把李子柒的uid換成了老番茄的uid,便成功爬取了老番茄的B站數據。共393個影片,17個欄位,欄位同上。
這裡展示下爬取到的前20個影片數據:
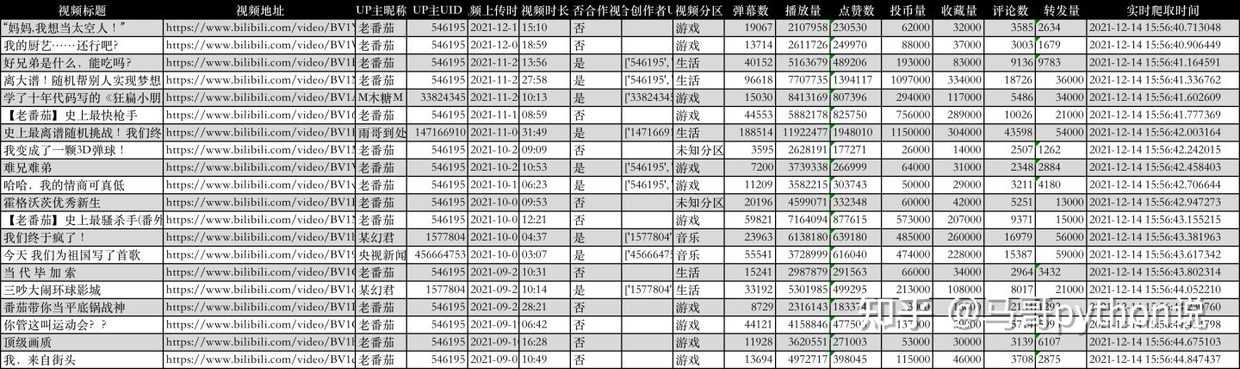
基於爬取的老番茄B站數據,用python做了以下基礎數據分析的開發。
二、python數據分析
1、讀取數據源
import pandas as pd
df = pd.read_excel('B站影片數據_老番茄.xlsx', parse_dates=['影片上傳時間', '實時爬取時間']) # 讀取excel數據
2、查看數據概況
df.head(3) # 查看前三行數據
df.shape # 查看形狀,幾行幾列
df.info() # 查看列資訊
df.describe() # 數據分析
df['是否合作影片'].value_counts() # 統計:是否合作影片
df['影片分區'].value_counts() # 統計:影片分區
3、查看異常值
df2 = df[['影片標題', '影片地址', '彈幕數', '播放量',
'點贊數', '投幣量', '收藏量', '評論數', '轉發量', '影片上傳時間']] # 去掉不關心的列
df2.loc[df.評論數 == 0] # 評論數是0的數據
df2.isnull().any() # 空值
df2.duplicated().any() # 重複值
4.1、查看最大值(max函數)
df2.loc[df.播放量 == df['播放量'].max()] # 播放量最高的影片
df2.loc[df.彈幕數 == df['彈幕數'].max()] # 彈幕數最高的影片
4.2、查看最小值(min函數)
df2.loc[df.投幣量 == df['投幣量'].min()] # 投幣量最小的影片
df2.loc[df.收藏量 == df['收藏量'].min()] # 收藏量最小的影片
5.1、查看TOP3的影片(nlargest函數)
df2.nlargest(n=3, columns='播放量') # 播放量TOP3的影片
df2.nlargest(n=3, columns='投幣量') # 投幣量TOP3的影片
5.2、查看倒數3的影片(nsmallest函數)
df2.nsmallest(n=3, columns='評論數') # 評論數倒數3的影片
df2.nsmallest(n=3, columns='轉發量') # 轉發量倒數3的影片
6、查看相關性
# 查看spearman相關性(得出結論:收藏量&投幣量,相關性最大,0.98)
df2.corr(method='spearman')

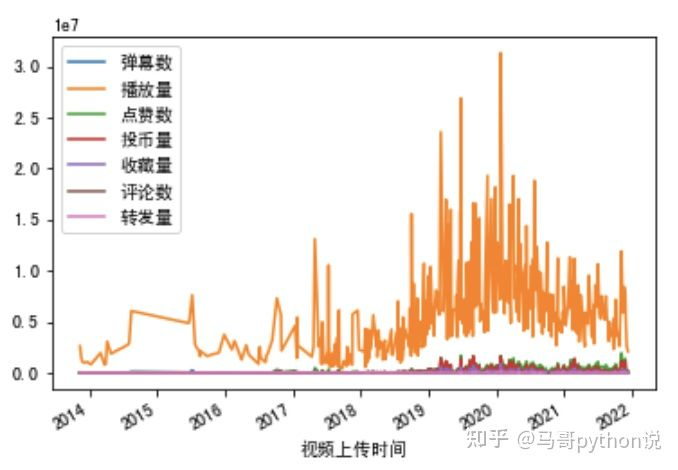
7.1、可視化分析-plot
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文標籤 # 指定默認字體
plt.rcParams['axes.unicode_minus'] = False # 解決保存影像是負號'-'顯示為方塊的問題
# 可視化效果不好
df2.plot(x='影片上傳時間', y=['彈幕數', '播放量', '點贊數', '投幣量', '收藏量', '評論數', '轉發量'])
7.2、可視化分析-pyecharts
from pyecharts.charts import Line # 折線圖所導入的包
from pyecharts import options as opts # 全局設置所導入的包
time_list = df2['影片上傳時間'].astype(str).values.tolist()
line = (
Line() # 實例化Line
# 加入X軸數據
.add_xaxis(time_list)
# 加入Y軸數據
.add_yaxis("彈幕數", df2['彈幕數'].values.tolist())
.add_yaxis("播放量", df2['播放量'].values.tolist())
.add_yaxis("點贊數", df2['點贊數'].values.tolist())
.add_yaxis("投幣量", df2['投幣量'].values.tolist())
.add_yaxis("收藏量", df2['收藏量'].values.tolist())
.add_yaxis("評論數", df2['評論數'].values.tolist())
.add_yaxis("轉發量", df2['轉發量'].values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="老番茄B站數據分析"),
legend_opts=opts.LegendOpts(is_show=True),
)
# 全局設置項
)

至此,基礎數據分析工作完成了。
三、同步講解影片
逐行程式碼影片講解:
//www.zhihu.com/zvideo/1455460990275567616
by 馬哥python說

