微服務9:服務治理來保證高可用
★微服務系列
微服務1:微服務及其演進史
微服務2:微服務全景架構
微服務3:微服務拆分策略
微服務4:服務註冊與發現
微服務5:服務註冊與發現(實踐篇)
微服務6:通訊之網關
微服務7:通訊之RPC
微服務8:通訊之RPC實踐篇(附源碼)
微服務9:服務治理來保證高可用
1 微服務帶來的挑戰
在第2篇《微服務2:微服務全景架構 》中,我們曾經分析過微服務化後所面臨的挑戰,有過如下的結論:
1.1 分散式固有複雜性
微服務架構是基於分散式的系統,而構建分散式系統必然會帶來額外的開銷。
性能: 分散式系統是跨進程、跨網路的調用,受網路延遲和頻寬的影響。
可靠性: 由於高度依賴於網路狀況,任何一次的遠程調用都有可能失敗,隨著服務的增多還會出現更多的潛在故障點。因此,如何提高系統的可靠性、降低因網路引起的故障率,是系統構建的一大挑戰。
分散式通訊: 分散式通訊大大增加了功能實現的複雜度,並且伴隨著定位難、調試難等問題。
數據一致性: 需要保證分散式系統的數據強一致性,即在 C(一致性)A(可用性)P(分區容錯性) 三者之間做出權衡。這塊可以參考我的這篇《分散式事務》。
1.2 服務的依賴管理和測試
在單體應用中,通常使用集成測試來驗證依賴是否正常。而在微服務架構中,服務數量眾多,每個服務都是獨立的業務單元,服務主要通過介面進行交互,如何保證它的正常,是測試面臨的主要挑戰。所以單元測試和單個服務鏈路的可用性非常重要。
1.3 有效的配置版本管理
在單體系統中,配置可以寫在yaml文件,分散式系統中需要統一進行配置管理,同一個服務在不同的場景下對配置的值要求還可能不一樣,所以需要引入配置的版本管理、環境管理。
1.4 自動化的部署流程
在微服務架構中,每個服務都獨立部署,交付周期短且頻率高,人工部署已經無法適應業務的快速變化。有效地構建自動化部署體系,配合服務網格、容器技術,是微服務面臨的另一個挑戰。
1.5 對於DevOps更高的要求
在微服務架構的實施過程中,開發人員和運維人員的角色發生了變化,開發者也將承擔起整個服務的生命周期的責任,包括部署、鏈路追蹤、監控;因此,按需調整組織架構、構建全功能的團隊,也是一個不小的挑戰。
1.6 更高運維成本
運維主要包括配置、部署、監控與告警和日誌收集四大方面。微服務架構中,每個服務都需要獨立地配置、部署、監控和收集日誌,成本呈指數級增長。服務化粒度越細,運維成本越高。
2 迫切的治理需求
正是因為有這些弊端,所以對微服務來說,有了更迫切的服務治理需求,以彌補弊端產生的問題。
可以看看下面的這張圖,這是一個典型的微服架構,他包含4層的Load Balance,7層的GateWay,計算服務,存儲服務,及其他的一些中間件系統。
實際上,但凡有需要微服務化的系統,都是具備一定規模了。一般會有很多模組構成,相應的部署節點也會非常多,這樣故障的概率就會大幅增加,比如磁碟故障、網路故障,機器宕機,觸發一些內核bug或者是運行環境漂移等。
本質上也是微服務細粒度拆分後提升了出問題的概率,正如上面說的,分散式系統有它固有的複雜性,相比於單體服務錯誤會顯著的增多,需要高可用方案來保證複雜通訊鏈路的健壯性。

3 如何進行服務可用性治理
我們有很多種方法對服務進行治理來保障服務的高可用。但總的來說有4類:
- 流量調控:方法主要是金絲雀發布(灰度發布)、ABTesting、流量染色。
- 請求高可用:方法主要有超時重試、快速重試以及負載均衡。
- 服務的自我保護:主要包括限流、熔斷和降級。
- 應對故障實例:主要分為異常點驅逐和主動健康檢查。
3.1 流量調控
3.1.1 金絲雀發布、ABTesting

流量調度中典型的金絲雀場景,你可以先放行一部分流量到一個新的服務實例中,這個新的服務實例只有你的研發和測試團隊可以接入。可以在上面試用或者測試,直到你確認你的服務是健康的,沒有bug的,再把流量逐漸的遷移過去。
這個的好處是減少發布新功能存在的風險,而且全程是無停服發布,對用戶是透明無感知的,大大提高了可用性。
3.1.2 流量染色

流量染色也是一種典型的場景。如果你想讓不同的用戶群體(比如這邊的Group A、Group B、Group C)使用的功能也是不同的,那流量染色是一個不可缺少的功能。
它可以把符合某些特徵的用戶流量調控到對應的服務版本中。比如GroupA是學生群體,對應到V1版本,GroupB是老人群體,對應到V2版本。需要注意的是,如果是一條完整的鏈路,那鏈路上的各個服務包括數據存儲層都應該有不同的版本,這樣才能一一對應。
3.2 請求高可用
3.2.1 超時
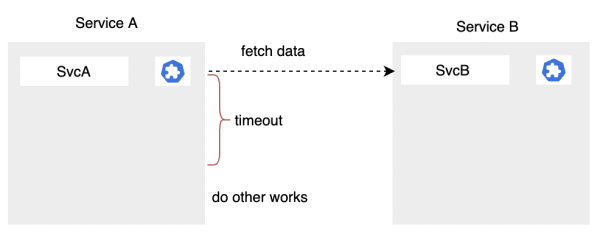
假設你有兩個服務,服務A和服務B,服務A向服務B請求數據。但是B服務由於非常繁忙,在給定的時間周期內(紅色時間線)都無法響應。而這個紅色時間線是A服務固定的超時時間,如果這個時間之後還沒有等到B服務的響應,A服務就不等了,去執行其他的任務。
這個其實就是一個超時的基本概念。它的意義在於可以避免一些長時間的無意義的等待,因為這個時候下游可能是處於故障或者有請求堆積,短時間內可能是無法返回正常的結果的。
因此,服務A在超時之後,可以及時釋放自己的一些資源,比如執行緒或者是請求相關的其他資源。
在實踐中,超時時間的設置通常要比正常的請求時間稍微大一些(正常的返回時間可以根據平響進行分析),這樣可以避免請求還沒有來得及返回就觸發超時。當然這個超時時間也不能設置太大。如果太大的話,在服務B出現異常的時候,服務A不能夠及時的釋放資源,會導致請求堆積,降低自身服務的吞吐能力。
3.2.2 重試
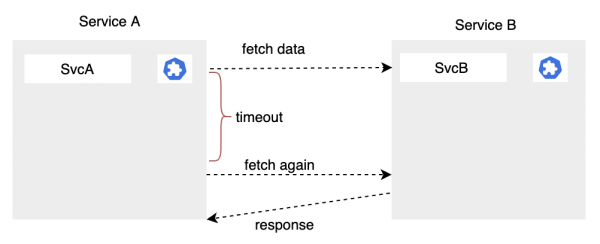
跟上面一樣,A服務向B服務獲取數據,由於B服務非常繁忙,在給定的超時時間內無法獲得響應數據。於是A設置了重試機制,在超時時間結束之後,重新獲取一下B服務的數據,這時候B服務已經不忙碌了,很快就把正常數據響應給A服務。
可以看到,重試的意義在於可以提升一次請求的成功率。通常重試不僅可以配合超時,也可以配合一些其他種類的失敗。
比如B服務5xx錯誤了,但可能是有概率的錯誤,所以重試一次就可能獲取到想要的結果。當然重試也有一些注意事項,避免重試帶來其他災難。
- 重試盡量避開之前已經選擇過的失敗實例,因為這個時候再重試,大概率還是錯誤的,意義不是特別大。
- 其次重試的次數也不能太多,否則很容易對服務B造成數倍的壓力,導致服務B發生一些雪崩。
- 對於多次重試,我們通常可以配合一些類似於退避重試的策略來減緩對服務B的壓力。退避策略說明,演算法
3.2.3 快速重試(backup request)
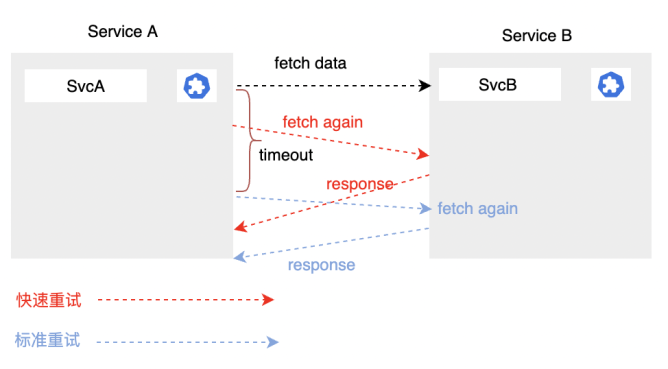
同上面一樣,服務A向服務B發起一個正常的請求,服務B工作繁忙,A服務在給定的超時時間之前都無法獲得響應。按照之前的做法就是等超時時間達到的時候,再發起一次請求。
但是可以在超時時間到達之前做一次更智慧的處理,比如超時時間線的中間點,再請求一次服務B。可以看到,重試其實就是一次backup request。正是由於它在正常的超時之前就觸發了,所以我們叫它快速重試。
這次快速重試,剛好服務B可能已經緩過來。他就收到了這個請求,給服務A返回了這個結果。
服務A在正常的超時觸發之後,就是紅色這條線,他也會發起一次正常的標準重試,這個時候服務B也有可能會再給他返回一次資訊,快速重試的返回和正常返回,他們的時序是有可能不一定的。通常我們的處理方法是服務A先收到哪一個回復,就以哪個為準。後面收到了就會被拋棄掉。
這邊需要注意的是,多一次重試會有一定的額外資源開銷,所以在使用的時候,需要注意快速重試和正常重試合理設置,避免總的重試次數過多導致服務可用性反受影響。
3.2.4 負載均衡
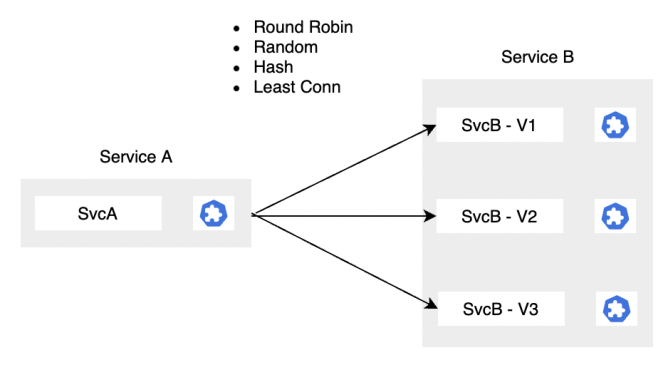
假設服務B有多個實例,對於服務A的請求,我們希望它是比較均勻的流向B服務的各個實例,這樣才能真正做到負載均衡,提供更穩定的服務。比較常用的一些策略比如隨機輪詢、RR順序輪詢等。
我們在實際的生產實踐中會有一些比較高級的負載均衡策略,比如說Least Conn、Least Request,他會觀測你後端集群中連接數、請求數最少的實例進行分配。
還有如LA負載均衡策略,它可以動態計算後端的壓力,比如說,可以根據qps和延遲來算一個權重。那些qps很高,延遲又很低的後端實力,我們可以認為它是一個比較優秀的後端實例,處理能力比較強,我們會給它比較高的權重,反之就給一個稍微低一些的權重。
另外一個比較常用的負載均衡策略就是一致性哈希。一致性哈希指的是說保證相同來源的請求能夠落入相同的後端實例。這在一些後端實例有快取,或者是有一些類似的場景的話,可以大幅提升請求的性能。
3.3 服務的自我保護
3.3.1 限流
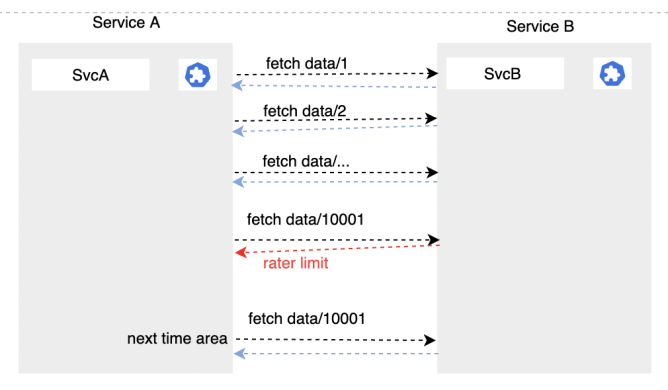
正常一個長期穩定運行的服務,他們的請求是正常波形狀且符合預期的,你可以觀察他的流量峰值、平均值來判斷服務真正的吞吐。
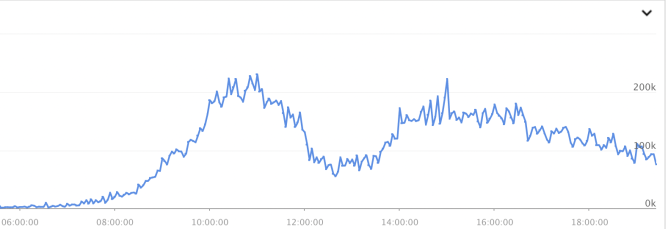
如果你的服務突然遇到持續性的、高頻率的、不符合預期的突發流量。你需要檢查一下服務是否有被錯誤調用、惡意攻擊,或者下遊程式邏輯問題。參考我的這一篇,就是典型的下游瘋狂調用。
這種超出預期的調用經常會造成你的服務響應延遲,請求堆積,甚至服務雪崩。而雪崩會隨著調用鏈向上傳遞,導致整個服務鏈的崩潰,對我們的系統造成很大的隱患。
限流通常指的是上游服務(服務B)這一側,任何服務處理能力總是有限的,所以在超過他的處理能力之後,我們需要一些保護行為來避免服務過載。通常的做法就是讓服務B快速返回失敗來進行自我保護,否則大量請求在服務B堆積,在請求隊列里阻塞,會造成大量資源損耗,也導致正常的請求無法被有效處理。
一些常見的限流方法,比如QPS限流、連接數限流,並發請求數限流等,都可以有效的對服務進行保護,下面列舉幾種常見的限流演算法。
-
時間窗:簡單易用

時間窗實現非常簡單,大概原理是我們有一個統計的時間窗,比1分鐘之內,我們只允許通過1000個請求。但是這種方法有一個比較大的缺陷,就是不太穩定。比如剛好在前10秒,就來了1000個請求,而後面50秒就不能夠再接受任何請求了,非常的不均勻。所以在要求嚴謹的生產環境中比較少使用。 -
漏桶演算法:定速流出

對於漏桶來說,由於它的出水口的速度是恆定的,也就是消化處理請求的速度是恆定的,所以它可以保證組件以恆定的速率來處理請求,這對一些對處理速度或者資源有嚴格要求的系統是非常實用的。 -
令牌桶:定速流入

令牌桶配了一個蓄水池,這個蓄水池通常如果請求比較少的話,那麼它一直往蓄水池裡面放水,就會導致這個蓄水池的容量會稍微多一些。那這樣的話,在接下來的一個瞬時的流量高峰,它可以允許系統經過比這個平均速率更高一些的請求高峰。所以它有一定的彈性,在實踐中也得到了非常廣泛的使用。



3.3.2 熔斷和降級

假設服務B非常繁忙,對於服務A正常的請求未能及時的返回結果,一直在Pending。而服務A在觸發超時時間之後,按照重試策略又發了一次請求,服務B依然沒有給返回。服務A經過多次重試,覺察到服務B有一些異常,他就自己做決策,認為服務B可能已經無法提供服務了,這個時候繼續發出重試請求,可能意義不太大。所以它主動發起熔斷(注意,是服務A發起的,因為B服務可能已經死了),就是一段時間內不再請求服務B。
A既然發起了熔斷,那他總得返回對應的資訊給用戶,不能讓用戶或者更下游的服務一直等待。
這時候的處理方式就是fall back 到默認的處理資訊,比如跳到一個預設的函數,指定返回默認設置的靜態資訊。或者對返回值進行降級,比如說是之前請求成功的一些資訊,或者一些快取的舊值,這樣比什麼都不返回好很多。
筆者這邊的做法是制定一個特定的返回結構(包含狀態碼、錯誤資訊、flag),帶有特定資訊標誌,讓前端可以識別出是正常的返回還是熔斷自動返回。
3.4 實例故障後的離群檢測
3.4.1 異常點驅逐
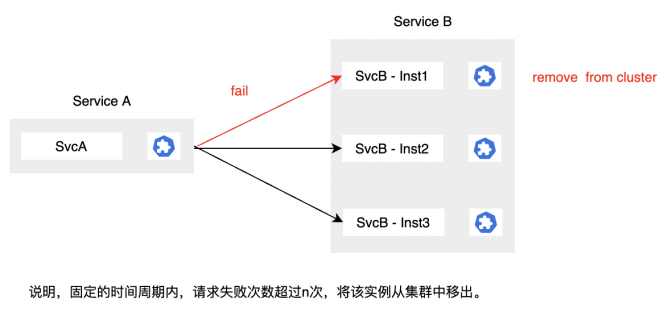
當集群中的某個服務實例發生故障的時候,其實我們最優先的做法是先進行驅逐,然後再檢查問題,處理問題並恢復故障。所以,能否快速的對異常實例進行驅逐,對提高系統的可用性很重要。
下面的是ServiceMesh中Istio的異常驅逐配置,表示每秒鐘掃描一次上游主機,連續失敗 2 次返回 5xx 錯誤碼的所有主機會被移出負載均衡連接池 3 分鐘,並且上游被離群的主機在集群中佔比不應該超過10%。
outlierDetection:
consecutiveErrors: 2
interval: 1s
baseEjectionTime: 3m
maxEjectionPercent: 10
說明:
驅逐: 一段時間內出現多次失敗,屏蔽該實例一段時間
恢復: 屏蔽時間之後,再嘗試請求該實例

