彌平模擬與現實的鴻溝:李飛飛、吳佳俊團隊發布用於 Sim2Real 遷移的多感官物體數據集
- 2022 年 5 月 5 日
- AI

編譯|OGAI
近年來,以物體為中心的多感測器學習顯示出了巨大的潛力。然而,以往的物體建模工作與現實的差距還很大。為此,李飛飛團隊曾發布 OBJECTFOLDER 1.0 據集,包含 100 個具有視覺、聽覺和觸覺數據的虛擬物體。然而,該數據集的規模較小,多感測器數據的品質較低,讓利用該數據集訓練的模型不能很好地泛化到現實場景中。
在本文中,李飛飛、吳佳俊團隊重磅發布了大規模的多感官家居物品數據集 OBJECTFOLDER 2.0,這些數據以一種隱式神經表徵的形式存在。相較於 OBJECTFOLDER 1.0,該數據集有三大提升:(1)數據集的規模為前者的 10 倍,渲染時間也快了幾個數量級(2)顯著提升了所有三種模態的多感官渲染品質(3)作者說明了,利用該數據集中的虛擬物體學習的模型可以成功地在三個具有挑戰性的任務(物體尺寸估計、觸點定位、形狀重建)。OBJECTFOLDER 2.0 為電腦視覺和機器人技術領域的多感官學習提供了新的研究途徑和測試平台。

程式碼地址://github.com/rhgao/ObjectFolder
在日常生活中,我們會感知和操作各種各樣的物體。這些物品的三維形狀、外觀、材料類型等物理屬性各異,具有獨特的感覺模式,都有非常不同的物理屬性——3d形狀、外觀和材料類型,這導致它們具有獨特的感覺模式:鬧鐘看起來是圓的、光滑的,用叉子敲擊盤子時會發出「叮噹聲」,觸摸刀片時會感到刀的鋒利。
然而,以往建模真實世界物體的工作較為局限,與真實世界的差距較大。在電腦視覺領域中,我們往往在二維空間中建模物體,重點關注在靜態影像中識別、定位它們。早先的形狀建模工作則構建物體的 3D CAD 模型,但是往往只關注其幾何特性,物體的視覺紋理品質也較低。此外,大多數工作都沒有關注完整的物理物體屬性,只關注單一模態(通常是視覺)。

圖 1:OBJECTFOLDER 2.0 數據集。
我們旨在構建一個大型的逼真、多感官器的 3D 物體模型數據集,使利用該數據集中的虛擬物體學習的模型可以被泛化到真實世界的對應物體上。如圖 1 所示,我們利用真實世界物體的現有的高品質掃描,提取其物理特徵(例如,視覺紋理、材料類型,3D 形狀)。接著,我們根據物體的固有物理屬性,對其視覺、聽覺、觸覺數據進行模擬,並使用了一個隱式神經表徵網路「Object File」對模擬的多感官數據進行編碼。如果感知到的數據足夠逼真,利用這些虛擬物體學習到的模型就可以被遷移到包含這些物體的真實世界任務中。

圖 2:OBJECTFOLDER 2.0 數據集中的物體示例。
為此,OBJECTFOLDER 2.0 數據集應運而生。該數據集包含從網路資源中收集到的 1,000 個高品質的 3D 物體。其中,100 個物體來自 OBJECTFOLDER 1.0 數據集,855 個物體來自 ABO 數據集,45 個物體來自 Google Scanned Objects 數據集。相較之下,OBJECTFOLDER 2.0 相較於 1.0 版的渲染速度更快、多感官模擬品質更高。我們改進了聽覺和觸覺模擬架構,從而渲染出更逼真的多感官數據。此外,我們提出了一種新的隱式神經表徵網路,可以實時地基於任意的外部參數渲染視覺、聽覺、觸覺感官數據,這些數據具有目前最佳的品質。我們成功地將利用我們的虛擬物體學習到的模型遷移到了三項具有挑戰性的現實世界任務(物體尺寸估計、觸點定位、形狀重建)上。
具體而言,我們為每個物體構建的「元數據」包含從真實產品的公開網頁上獲取的物體的類型、材料、顏色、尺寸等資訊。我們根據物體的材料類型清洗了數據集,只保留下材料類型為「陶瓷、玻璃、木材、塑料、鐵、聚碳酸酯、鋼」的物體,並對數據的正確性進行了人工驗證。
本文的主要貢獻如下:
(1)發布了一個新的大型 3D 物體多感官數據集,物體以隱式神經保證的形式存在,該數據集的規模是現有的 OBJECTFOLDER 1.0 的十倍。我們顯著提升了視覺、聽覺、觸覺的多感官渲染品質,渲染速度快了數個數量級。
(2)我們說明了,使用本數據集學習的模型可以被成功遷移到一系列真實世界任務上,為電腦視覺和機器人學的多感官學習提供了新的研究路徑和測試平台。
如圖 1 所示,相較於離散的傳統訊號表徵,隱式表徵具有許多優勢。我們可以將每個感官模態參數化表示為一個連續函數,該函數將外部參數(例如,視覺上的相機視角、光照條件,聽覺上的衝擊強度,觸覺上的凝膠變形)映射為特定位置或條件下相應的感官訊號。隱式神經表徵是我們通過神經網路得到的對該連續函數的近似,這使得存儲原始感觀數據的記憶體與外部參數相互獨立,用戶可以輕鬆地獲取隱式表徵。此外,由於隱式神經表徵是連續的,我們可以以任意解析度對感觀數據進行取樣。

圖 3:用於生成隱式表徵的「Object File」網路包含三個子網路:VisionNet、AudioNet、TouchNet。
與 OBJECTFOLDER 1.0 相比,我們通過用數千個獨立的多層感知機(MLP)表徵每個物體加速了 VisionNet 的推理;就 AudioNet 而言,我們只預測訊號中與位置相關的部分,而不是直接預測聲波頻譜圖,大大提高了渲染品質,同時加快了推理速度;新的 TouchNet 可以渲染具有各種旋轉角度和凝膠變形的觸覺讀數,而 OBJECTFOLDER 1.0 的每個頂點只能渲染單個觸覺影像。

圖 4:OBJECTFOLDER 2.0 中的視覺、聽覺、觸覺數據渲染結果相較於 OBJECTFOLDER 1.0 有顯著提升(以 YCB 數據集中的杯子為例)。
視覺——VisionNet
我們在 KiloNeRF 的基礎上構建了 KiloOSF 作為 VisionNet。KiloNeRF 使用了多個獨立的小 MLP 表徵靜態場景,而不是使用單個 MLP 表徵整個場景。每個獨立的 MLP 處理場景的一小部分,足以進行逼真的影像渲染。
類似地,我們將每個物體細分為均勻解析度的網格 ,每個網格單元的 3D 索引為
,每個網格單元的 3D 索引為 。從位置 x 到索引 i 的映射 m 可以表示為:
。從位置 x 到索引 i 的映射 m 可以表示為:
其中, 和
和 分別為軸對齊邊界框(AABB)的最小和最大界。對於每個網格單元,我們利用帶有參數
分別為軸對齊邊界框(AABB)的最小和最大界。對於每個網格單元,我們利用帶有參數 的 MLP 網路表徵相應的物體部分。接著,我們首先確定包含點 x 的網格單元的索引
的 MLP 網路表徵相應的物體部分。接著,我們首先確定包含點 x 的網格單元的索引 ,然後查詢相應的小 MLP,就可以得該點的 r 方向上的顏色和密度值:
,然後查詢相應的小 MLP,就可以得該點的 r 方向上的顏色和密度值:

參考 KiloNeRF,我們使用了「基於蒸餾的學習」策略避免在渲染時產生偽影。我們首先針對每個物體訓練了一個普通的「以物體為中心的神經散射函數」(OSF),然後將每個教師模型的知識蒸餾到 KiloOSF 模型中。我們還使用了空的空間跳轉和早期光線終止提升渲染的效率。
聽覺——AudioNet
我們使用為自然環境下的物體網格設計的序貫法將每個對象的表面網格轉換為一個體積二階四面體網格。接著,我們使用有限元方法(FEM)對生成的四面體網格和有限元分析軟體「Abaqus」中的二階元素執行上述模態分析過程。我們對在各軸向上以單位力觸碰四面體網格各頂點的振動模式進行了模擬。接著,我們訓練了一個以四面體網格頂點坐標作為輸入的多層感知機,並預測該頂點在各軸向上被單位力觸碰時每個模式下的增益向量。
在推理時,我們可以首先利用網路預測每個模態下的的增益 ,然後對利用網路預測出的增益
,然後對利用網路預測出的增益 和通過模態分析得到的頻率
和通過模態分析得到的頻率 、阻尼
、阻尼 參數化的指數衰減正弦曲線求和,從而預測出物體的脈衝響應。我們進一步將每個頂點上的外部力 f 分解為沿著三個正交軸方向上的單位力的線性組合。最終的聲波可以被表示為:
參數化的指數衰減正弦曲線求和,從而預測出物體的脈衝響應。我們進一步將每個頂點上的外部力 f 分解為沿著三個正交軸方向上的單位力的線性組合。最終的聲波可以被表示為:

在 OBJECTFOLDER 1.0 中,我們使用了體積六面體網格記性模態分析,而 2.0 中使用的更高階的四面體網格,從而在表徵大小相同的情況下,捕獲到更精細的特徵和表面曲率,也得到了更精確的彈性形變。因此,AudioNet 2.0 可以對物體的聲學屬性進行更加精確的建模。此外,AudioNet 1.0 直接預測複雜的聲波頻譜,其維度過高,局限於固定的解析度和時長。AudioNet 2.0 則只預測與位置相關的部分訊號,然後通過解析獲得其它的模式訊號。
觸覺——TouchNet
我們使用「GelSight」觸覺感測器的幾何測量值作為觸覺讀數。為此,我們需要同時對接觸的形變和對於形變的光學相應進行模擬。我們的觸覺模擬需要實現以下三個目標:(1)針對接觸的位置、方向、按壓深度靈活地渲染觸覺讀數(2)為訓練 TouchNet 高效地渲染數據(3)使模擬儘可能與現實情況相近,從而泛化到真實世界的觸覺感測器中。
為此,我們採用了下面的雙階段方法來渲染逼真的觸覺訊號:首先,我們模擬接觸區域內的物體形狀和非接觸區域內的凝膠墊的形狀的接觸形變圖,從而表示接觸點的局部形狀。我們使用 Pyrender 對感測器和物體的交互進行模擬,使用 GPU 加速的 OpenGL 渲染形變圖,實現了 700 幀/秒的數據生成。
我們使用 TouchNet 對接觸物體各頂點的形變圖編碼,將每個物體的觸覺讀數表徵為一個 8 維函數。該函數的輸入為物體坐標系中的 3D 位置 ,3D 單元接觸方向通過
,3D 單元接觸方向通過 參數化,物體陷入凝膠的深度為 p,形變圖中的空間位置為
參數化,物體陷入凝膠的深度為 p,形變圖中的空間位置為 。該網路的輸出為接觸的形變圖的像素值。在渲染形變圖之後,我們利用目前最先進的 GelSight 模擬框架 Taxim 根據形變圖渲染觸覺 RGB 影像。
。該網路的輸出為接觸的形變圖的像素值。在渲染形變圖之後,我們利用目前最先進的 GelSight 模擬框架 Taxim 根據形變圖渲染觸覺 RGB 影像。
相較之下,OBJECTFOLDER 1.0 中的 TouchNet 智慧沿著每個頂點的法線方向渲染單張觸覺影像,新設計的 TouchNet 可以生成旋轉角度在 15° 以內、按壓深度在 0.5-2mm 之間的觸覺輸出。此外,在 Taxim 的幫助下,形變圖到觸覺光學輸出的映射可以很容易地校準到不同的基於視覺的觸覺感測器,產生逼真的觸覺光學輸出,從而實現 Sim2Real 的遷移。
我們希望利用 OBJECTFOLDER 2.0 中的虛擬物體學習的模型可以泛化到真實世界的物體上。為此,我們測評了模型在物體尺寸估計、觸點定位、形狀重建這三個任務上的遷移性能,說明了數據集的有效性。
物體尺寸估計
物體的所有感官模態都與尺寸緊密相關。我們利用 OBJECTFOLDER 2.0 數據集中渲染的多感官數據訓練模型,用 8 個具有視覺、聽覺、觸覺真實感官數據的物體進行測試。針對視覺和聽覺,我們訓練了一個 ResNet-18 預測物體尺寸,其輸入為物體的 RGB 影像或撞擊聲的幅度頻譜。針對觸覺,我們使用循環神經網路融合 10 次連續觸摸的讀數,實現了基於觸覺的尺寸預測。

表 1:物體尺寸預測結果。
「Random」表示在與我們的模型相同的範圍內隨機預測尺寸的對比基準線。使用 OBJECTFOLDER 2.0 中的多感官數據訓練的模型可以更好地泛化到真實世界物體上,證明了模擬的真實性和隱式表徵網路編碼的準確性。
「觸覺-聽覺」觸點定位
在與形狀已知的物體交互時,準確識別交互的位置是十分重要的。碰撞提供了關於接觸位置的局部資訊,而在不同表面位置的碰撞會產生不同的模態增益。我們研究了使用碰撞聲和/或與接觸相關的觸覺讀數進行觸點定位的可能性。
我們通過粒子濾波(particle filtering)定位接觸位置的序列,收集這些位置的觸覺讀數或碰撞聲音。對於觸覺,我們使用一個預訓練的 FCRN 網路中提取特徵,用於根據觸覺影像進行深度預測。對於聽覺,我們從每 3 秒的碰撞聲中提取 MFCC 特徵。我們將這些特徵與代表候選接觸位置的物體表面取樣的粒子進行比較。與實際的觸覺感測器讀數或碰撞聲音特徵相似度得分高的粒子被認為更有可能是真正的接觸位置。
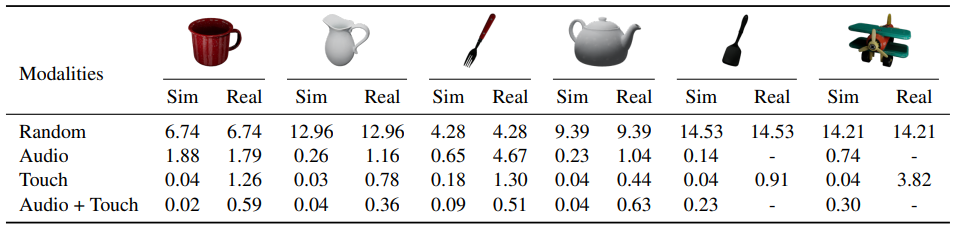
表 2:「聽覺-觸覺」觸點定位。
我們使用與真實標註觸點位置的平均歐氏距離作為評估度量。實驗結果表明,基於觸覺的觸點定位相較於基於聽覺的定位更加準確。

圖 5:基於觸覺和聽覺的觸點定位的可視化結果。
「視覺-觸覺」形狀重建
單影像形狀重建在視覺領域被廣泛研究。然而,在有遮擋的情況下,觸覺訊號對於感知物體形狀則極具價值。視覺可以提供粗略的全局上下文,而觸覺提供精確的局部幾何特性。在這裡,我們訓練模型根據包含物體和/或物體表面的一系列觸覺讀數的單張 RGB 影像重建三維對象的形狀。
我們使用 PCN 網路作為該任務的測試平台。對於觸覺,我們使用 32 個觸覺讀數,並根據相應的觸摸姿勢將相關的變形映射到稀疏的點雲上。將稀疏的點雲作為 PCN 網路的輸入,生成密集完整的點雲。在視覺方面,我們沒有使用一系列局部觸點圖作為物體的部分觀測數據,而是使用 ResNet-18 網路根據包含物體的單張影像中提取的全局特徵來監督形狀補全過程。對於基於視覺和觸覺的形狀重建,我們使用雙流網路,使用全連接層將根據兩種模態預測的點雲合併,以預測最終的密集點雲。
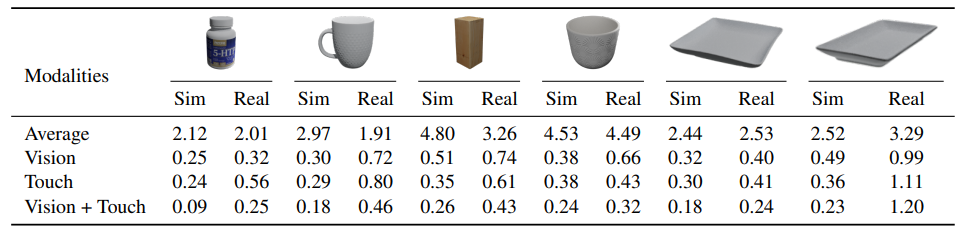
表 3:基於視覺和觸覺的形狀重建。
與使用 6 個物體的平均真實網格作為預測的平均對比基準線相比,使用單張影像的形狀重建和使用觸摸讀數序列的重建效果要好得多。結合來自兩種模式的幾何線索通常可以獲得最佳的 Sim2Real 遷移性能。

圖 6:基於視覺和觸覺的形狀重建可視化結果。

雷峰網雷峰網


