初學者系列:Attentional Factorization Machines(AFM)詳解
- 2019 年 10 月 4 日
- 筆記
導讀
本文通過學習論文《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》介紹一種可以區分特徵交互的重要性的模型——Attentional Factorization Machines(AFM)。下文主要分為兩個部分來講解,包括AFM原理以及源碼解析。
論文地址:
http://staff.ustc.edu.cn/~hexn/papers/ijcai17-afm.pdf
No.0
核心思想
因子分解機(FM)是一種監督學習方法,通過結合二階特徵交互來增強線性回歸模型,通過學習每個特徵的嵌入向量(embedding vector),FM可以估計任何交叉特徵的權重。但是FM缺乏區分特徵交互重要性的能力(並非所有特徵都包含用於估計目標的有用的)。
注意力因子分解機AFM是對FM的改進,解決了FM對於所有的特徵權重都是一樣的,不能區分特徵交互重要性的問題。注意因子分解機(AFM)通過神經注意網路(neural attention network)從數據中自動地學習每個特徵交互的重要性,從而實現特徵交互對預測的貢獻不同。
No.1
AFM
下圖為AFM的框架(省略了線性回歸部分),主要由輸入層、嵌入層、成對交互層( pair-wise interaction layer)與基於注意力的池化層。其中輸入層與嵌入層與FM是一致的,都是將輸入特徵的稀疏表示的非零特徵嵌入到密集矢量中。下面主要介紹成對交互層( pair-wise interaction layer)和基於注意力的池化層。

Pair-wise Interaction 層
成對交互層是將FM中的二階交叉特徵使用神經網路層來實現,FM中的交叉項計算為:

成對交互層是將m個向量擴展為 m(m – 1)/ 2個相互作用(interacted vector)的向量。成對交互層的輸出可以表示為一組向量:

其中:
- R_x = { (i,j) } i ∈ X, j ∈ X, j>i
- 嵌入層的輸出為E = { vixi } i∈X
- X為x中的非零特徵集合
若在交互層後使用全連接層進行預測,則得到的預測得分為:

其中:
- p∈R_k和b∈R分別表示預測層的權重和偏差。
- 在p=1,b=0時,變為FM
pair-wise interaction layer與NFM中的BI-Interaction層的操作是相似的的,都是實現FM 中的二階特徵交互。
Attention-based PoolingLayer
為了解決FM不能區分特徵交互重要性的問題,論文中在二階交互特徵計算完成後加入了注意力網路(Attention Net),使用多層感知器(MLP)參數化注意力得分。注意力網路的輸入是兩個特徵的交互向量,經過注意力網路可以在將特徵交互壓縮到同一表示式時,不同的特徵交互有不同的貢獻。注意力網路定義為:

注意力得分需要通過softmax函數(一個元素的softmax值,就是該元素的指數與所有元素指數和的比值)歸一化,結果如下:

其中:
- W∈ R_{t×k},b∈R_t,h∈R_t是模型參數,t表示注意網路的隱藏層大小(注意因子)
- a_{ij}是特徵交互wij的注意力得分
在此,沒有使用通過最小化預測損失來學習注意力得分(a_{ij}),是因為對於在訓練數據中從未共同出現的特徵,無法估計其交互的注意力得分。
因此,AFM模型的可以表示為:

學習
AFM可以應用於包括回歸,分類和排名在內的各種預測任務。文中以回歸任務為例,選擇平方損失作為目標函數,使用梯度下降法(SGD)進行優化:

為了防止過擬合,文中使用了Dropout與L2正則化。
- dropout:僅在成對交互層上使用,隨機丟棄成對交互層上的神經元。
- L2正則化:在注意力網路的權重矩陣W上加入。

No.2
程式碼詳解
程式碼鏈接:
https://github.com/hexiangnan/attentional_factorization_machine
程式碼框架如下,主要包括數據處理(LoadData.py)與AFM模型構建(AFM.py)

環境
- Python 2.7
- Tensorflow 1.0.1
數據
源碼中提供了 MovieLens 1 Million (ml-1m) 和 frappe兩個數據集, 原始數據格式與LibFM工具包格式一致。原始數據形式如下(以MovieLens數據為例)

其中紅色框內為標籤,黃色框內為特徵(包括用戶id,項目id)。在經過LoadData.py(與NFM中的數據處理源碼相同,請點擊NFM查看)處理之後,得到訓練數據集、驗證數據集、測試數據集。經過處理後的數據示例如下:

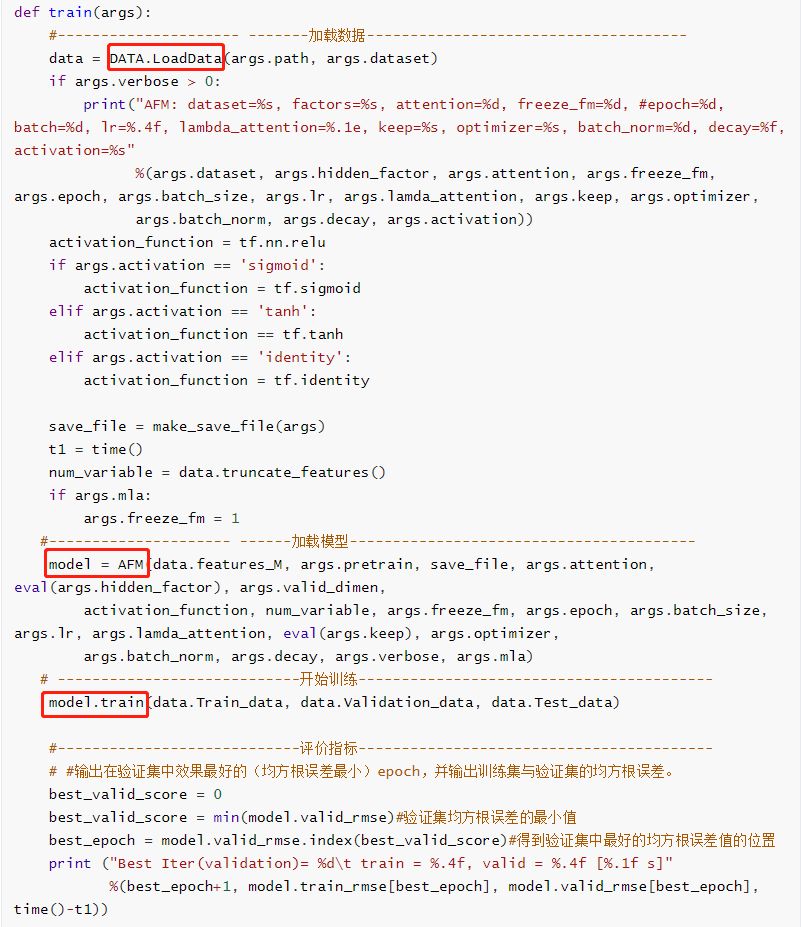
訓練
AFM模型的訓練主要通過調用函數 train()實現,在函數 train()中主要包括載入數據、載入模型、訓練這三部分,並且在訓練結束後輸出驗證集中均方根誤差(RMSE)最小的的epoch值。
模型
AFM模型的實現主要通過AFM類中的 _init_graph函數。模型主要包括Embedding層、成對交互層( pair-wise interaction layer)、基於注意力的池化層、輸出層這四部分。並且在 _init_graph()中定義了損失函數與優化器。
- Embedding層:跟之前的其它模型中Embedding層的實現是一樣的,通過函數tf.nn.embedding_lookup()根據輸入特徵的索引號找到對應權重中的一行。

- 成對交互層:相當於FM中二階交叉項特徵交互的計算。

- 基於注意力的池化層:主要是通過注意力網路計算得到注意力得分 a_{ij},來學習每個特徵交互的重要性。

- 輸出層

訓練
在載入完模型之後,訓練部分主要是通過調用AFM類中的 train ()函數實現。在訓練過程中除了計算損失之外,還輸出了訓練集以及驗證集數據的預測值與真實值之間的均方根誤差(RMSE)。

評價
評價函數evaluate主要是計算數據集中預測值與真實值之間的均方根誤差。


測試
測試部分主要是通過調用函數evaluate()來實現,計算了測試集數據的均方根誤差,並且進行了AFM與FM的對比,分別輸出了兩個模型的總輸出,並計算了二者的差值。


-END-
