[論文] FRCRN:利用頻率遞歸提升特徵表徵的單通道語音增強
本文介紹了ICASSP2022 DNS Challenge第二名阿里和新加坡南陽理工大學的技術方案,該方案針對卷積循環網路對頻率特徵的提取高度受限於卷積編解碼器(Convolutional Encoder-Decoder, CED)中卷積層有限的感受野的問題,將阿里達摩院之前的FSMN與發展自DCCRN/DCCRN的CRN with CCBAM結合。本文提出了一種頻率遞歸卷積循環網路(frequency recurrence Convolutional Recurrent Network, FRCRN)框架在卷積循環編碼器結構的基礎上利用前饋順序記憶網路(feedforward sequential memory network, FSMN)以提高沿頻率特徵的表徵能力。具體而言,在CRED的每個卷積層之後利用FSMN沿頻率維度對三維特徵圖(feature map)進行頻率遞歸以建模範圍更廣的頻率相關性並加強語音輸入的特徵表示;在編碼器和解碼器之間也插入了兩個堆疊的FSMN層以進行時序建模。FRCRN在複數域預測復值理想比掩模(cIRM),並利用時頻域和時域損失優化,在ICASSP2022 DNS Challenge中取得第二名。
論文題目:FRCRN: Boosting feature representation using frequency recurrence for monaural speech enhancement
作者:Shengkui Zhao, Bin Ma (阿里巴巴), Karn N. Watcharasupat, Woon-Seng Gan (新加坡南洋理工大學)
背景動機
CRN結構尤其是DCCRN在語音增強領域取得了優異的性能,但是卷積核有限的感受野限制了對頻率維度的長範圍建模。本文受DCCRN+中頻率相關性建模研究的啟發,提出了FRCRN以提高沿頻率軸的特徵表示。FRCRN在每個卷積之後加入一個用於頻率遞歸的且相比LSTM參數量更小的FSMN層對特徵圖的沿頻率軸建模,卷積層和頻率遞歸層構成卷積遞歸(convolutional recurrent, CR)塊。通過在編碼器和解碼器中疊加多個CR塊來形成CRED,從而不僅能捕捉局地的時間譜結構,還能捕捉長範圍的頻率相關性。不像之DCCRN+只專註於建模時序關係,本工作專註於改進編碼器-解碼器結構的整體特徵表徵。整個模組如DCCRN+一樣採用復值網路並估計復值理想比值掩碼(cIRM),利用時頻域和時域損失函數進行聯合優化。
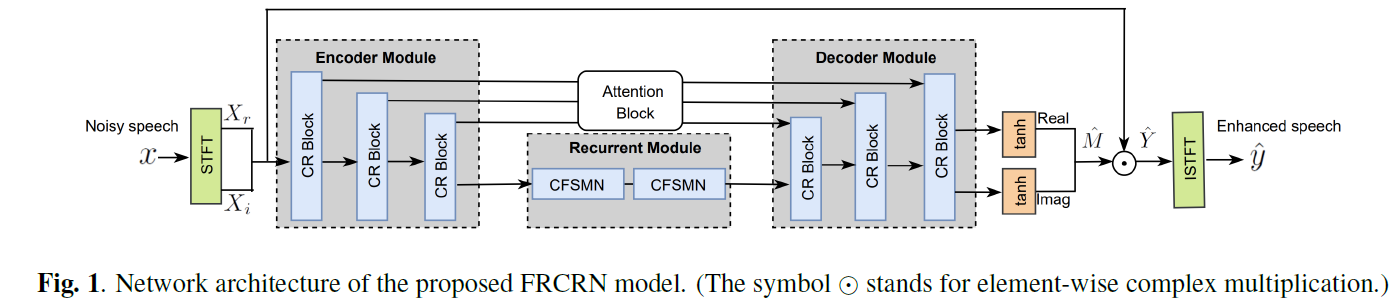
模型架構
模型處理的整體流程如下圖,帶噪訊號經過STFT後送入網路,估計得到的cIRM與帶噪復譜按複數規則相乘得到增強復譜,反變換得到增強語音。FRCRN主要由CRED和時序建模模組組成,其中CRED包括對稱的編碼器模組和解碼器模組,兩個模組都包含多個CR模組。時序建模模組由兩個堆疊的復值FSMN (CFSMN)層組成,帶CCBAM的跳躍連接(skip connection)連接編碼器和解碼器以促進資訊流動。
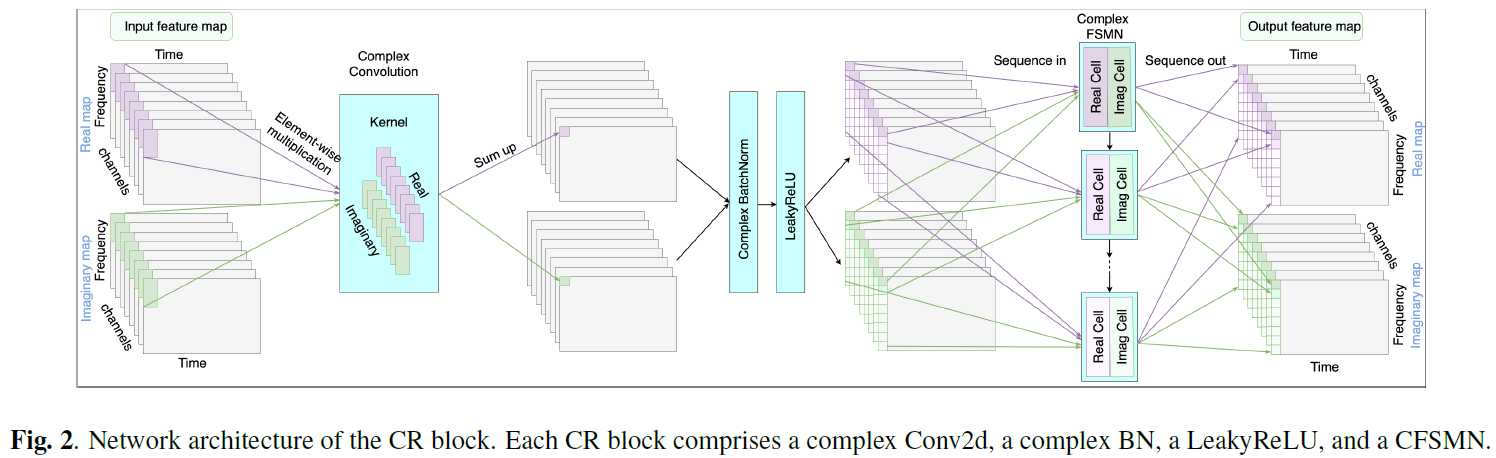
CR模組:由復值二維卷積層、復值BN、LeakyReLU和CFSMN層構成。復值二維卷積和復值BN操作可參看DCUNet或DCCRN論文。其中卷積層的kernel size在時間維和頻率維上分別為(2,7),stide為(1,2),時間維通過補零保證因果性,頻率維不補零,輸出通道數均為128。
CFSMN可以暫且當成LSTM理解,CR中的CFSMN就是將頻率特徵維當作torch中的seq_len維度,通道維度當成torch中的input_size維度。其操作如下(和原文略有不同是因為已將文中參數帶入公式):
Step1(置換操作,對每幀並行處理): \(U_{r/i} \in \mathcal{R}^{C \times T \times F} -> U_{r/i} \in \mathcal{R}^{T \times F \times C}\)
Step2(對當前幀): \(S_{r/i} = U_{r/i}[t,:,:] \in \mathcal{R}^{F \times C} =\{s_{f_1}, \cdots, s_{F}\}\)
Step3(FSMN層,共有兩組,分別為\(FSMN_r\)和\(FSMN_i\)):
\(h_{f_i} = ReLU(W_{f_i} s_{f_i} + b_{f_i})\)
\(p_{f_i} = V_{f_i} h_{f_i} + v_{f_i}\)
\(s_{f_i} = s_{f_i} + p_{f_i} + \sum_{\tau=0}^{20}{a_{\tau} \cdot p_{f_i-\tau}}\)
Step4(復值操作):\(S = (FSMN_r(S_r)-FSMN_i(S_i)) + j(FSMN_r(S_i)+FSMN_i(S_r))\)
時序建模:將編碼器輸出的實(虛)部特徵圖頻率特徵維度和通道特徵維度拉直成一維,而後對時間維進行CFSMN
CCBAM(個人補充):該模組參考了影像中的SENet並拓展到複製網路,即分別對通道維和語譜維做attention。通道維注意力機制是對特徵做均值池化和最大值池化後經過兩個線性層通過Sigmoid函數得到注意力得分;空間維注意力機制是對特徵做完以上兩種池化後通過Sigmoid得到注意力得分。示意圖如下:
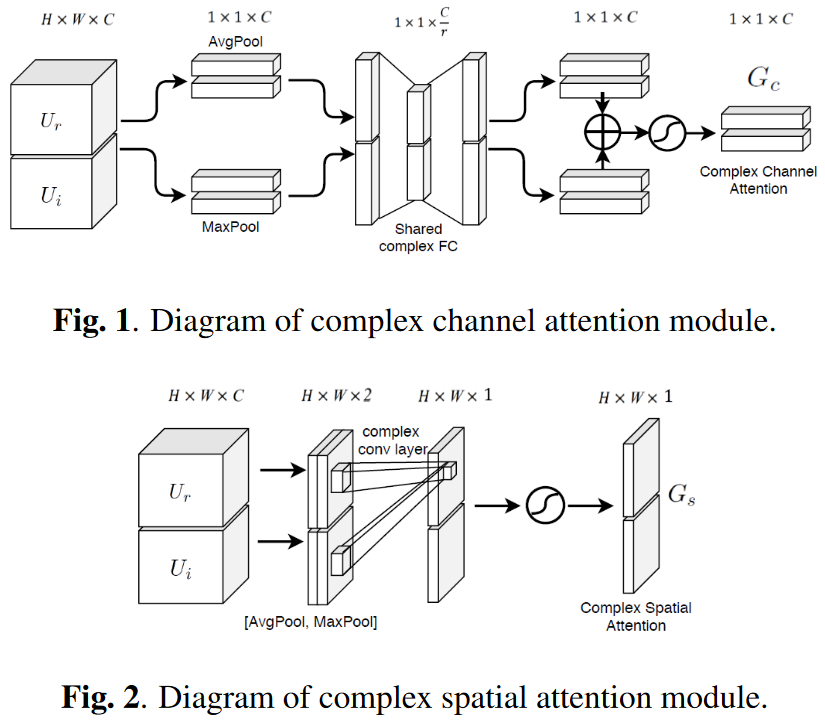
But,這裡有個疑問是,如果只是這樣簡單地使用池化操作,在通道維注意力機制時是怎麼保證模型因果的
損失函數:
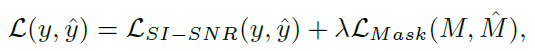
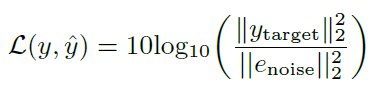
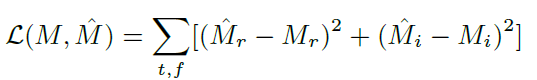
模型參數:編解碼器中各有6個CR模組,時序建模中有兩個CFSMN。幀長20ms幀移10ms,STFT點數為1920,按1-641,641-1282,1282-1921的頻點索引將整個STFT譜分為三組並沿通道為拼接,即網路輸入通道數為3。網路輸出的cIRM為對於為1921。
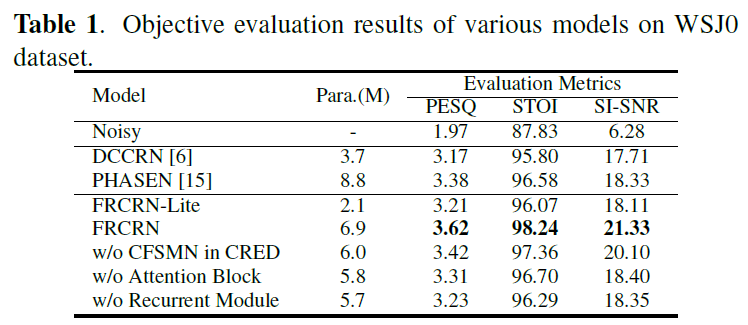
數據與結果
共生成3000小時的數據用於訓練和開發,其中30%帶混響。信噪比在0~15dB之間隨機選取
參數量10.27M,計算量12.30GMACS每秒
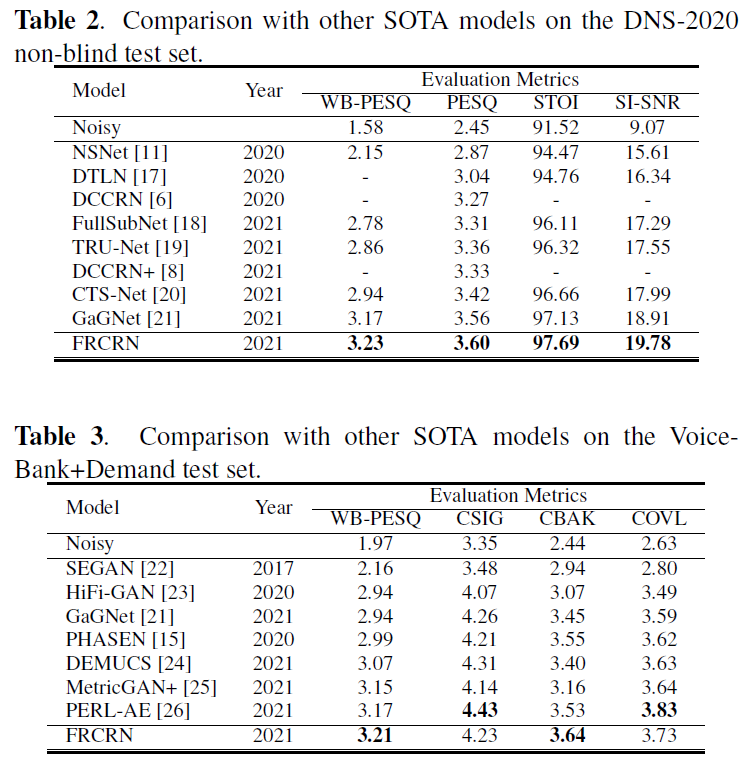
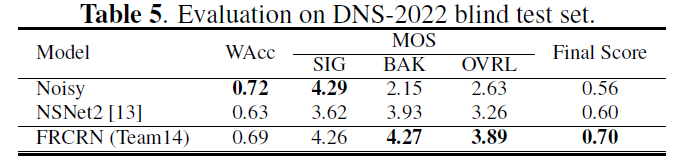
在DNS2020和VB-Demand中表現優異,DNS排名第二
消融實驗說明了CFSMN頻率遞歸、CCBAM和時序建模的有效性