爬蟲系列:爬蟲驗證碼識別
讀取驗證碼與訓練 Tesseract
在上一篇文章中我們介紹了使用 Tesseract 如何識別格式規範的文字,在這篇文章中我們將詳細介紹使用 Tesseract 如何識別影像驗證碼。
雖然大多數人對單詞「CAPTCHA」都很熟悉,但是很少人知道它的具體含義:全自動區分電腦和人類的圖靈測試(Completely Automated Public Turing test to tell Computers and Humans Apart)。它的奇怪縮寫似乎表示,它一直在扮演著十分奇怪的角色。其目的是為了阻止網站訪問,而不是讓訪問更通暢,它經常讓人類和非人類的網路機器人深陷驗證碼識別的泥潭不能自拔。
圖靈測試首次出現在阿蘭·圖靈(Alan Turing)1950 年發表的論文「計算裝置與智慧」(Computing Machinery and Intelligence)中。他在論文中描述了這樣一種場景:一個人可以和其他人交流,也可以通過電腦終端和人工智慧程式交流。如果一番對話之後這個人不能區分人和人工智慧程式,那麼就認為這個人工智慧程式通過了圖靈測試,圖靈認為這個人工智慧程式就可以真正地「思考」所有的事情。
令人啼笑皆非的是,60多年以後,我們開始用這些原本測試程式的題目來測試我們自己。Google 的 reCAPTCHA 難得令人髮指,作為目前最具有安全意識的流行網站,Google 攔截了多達 25% 的準備訪問網站的正常人類用戶。
大多數其他的驗證碼都是比較簡單的。例如,流行的 PHP 內容管理系統 Drupal 有一個名的驗證碼模組,可以生成不同難度的驗證碼。默認圖片如圖下圖所示:
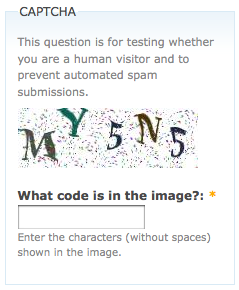
那麼與其他驗證碼相比,究竟是什麼讓這個驗證碼更容易被人類和機器(爬蟲)讀懂呢?
-
母外面畫一個方框,而不會重疊在一起。
-
圖片沒有背景色、線條或其他對 OCR 程式產生干擾的噪點。
-
雖然不能因一個圖片下定論,但是這個驗證碼用的字體種類很少,而且用的是 sans-serif(無襯線字體) 字體(像「4」和「M」)和一種手寫形式的字體(像「m」「C」和「3」)。
-
白色背景色與深色字母之間的對比度很高。
上面驗證碼只做了一點點改變,就讓 OCR 程式很難識別。
-
字母和數據都使用了,這會增加待搜索字元的數量。
-
字母隨機的傾斜程度會迷惑 OCR 軟體,但是人類還是很容易識別的。
-
那個比較陌生的手寫字體很有挑戰性,背景加了一些噪點,同時「M」和」Y「都進行了變換,電腦需要進行額外的訓練才能識別。
用下面的程式碼運行 Tesseract 識別圖片:
E:\Tesseract-OCR>tesseract.exe "E:\我的文檔\My Pictures\Saved Pictures\image_captcha_example.max_239x290.png" "E:\我的文檔\My Pictures\Saved Pictures\1.txt"
我們得到的結果是一個空文本文件,有換行符。
訓練 Tesseract
要訓練 Tesseract 識別一種文字,無論是晦澀難懂的字體還是驗證碼,你都需要向 Tesseract 提供每個字元不同形式的樣本。
做這個枯燥的工作可能要花好幾個小時的時間,你可能更想用這點兒時間找個好看的影片或電影看看。首先要把大量的驗證碼樣本下載到一個文件夾里。下載的樣本數量由驗證碼的複雜程度決定,我在訓練集里一共放了100個樣本(一共 500 個字元,平均每個字元 8 個樣本;a~z 大小寫字母加 0~9 數字,一共 62 個字元),應該足夠訓練的了。
提示:建議使用驗證碼的真實結果給每個樣本文件命名(即 4MmC3.jpg)。這樣可以幫你一次性對大量的文件進行快速檢查——你可以先把圖片調成縮略圖模式,然後通過文件名對比不同的圖片。這樣在後面的步驟中進行訓練效果的檢查也會很方便。
第二步是準確地告訴 Tesseract 一張圖片中的每個字元是什麼,以及每個字元的具體位置。這裡需要創建一些矩形定位文件(box file),個驗證碼圖片生成一個矩形定位文件。一個驗證碼圖片的矩形定位文件如下所示:
A 11 5 46 36 0
c 47 9 69 32 0
r 75 10 94 32 0
E 105 8 131 43 0
第一列符號是圖片中的每個字元,後面的4個數字分別是包圍這個字元的最小矩形的坐標(圖片左下角是原點(0,0),4個數字分別對應每個字元的左下角 x 坐標、左下角 y 坐標、右上角 x 坐標和右上角 y 坐標),最後一個數字「0」表示圖片樣本的編號。
顯然,手工創建這些圖片矩形定位文件很無聊,不過有一些工具可以幫你完成。
矩形定位文件必須保存在一個 .box 後綴的文本文件中。和圖片文件一樣,文本文件也是用驗證碼的實際結果命名(例如:4MmC3.box)。另外,這樣便於檢查 .box 文件的內容和文件的名稱,而且按文件名對目錄中的文件排序之後,就可以讓 .box 文件與對應的圖片文件的實際結果進行對比。
你還需要創建大約 100 個 .box 文件來保證你有足夠的訓練數據。因為 Tesseract 會忽略那些不能讀取的文件,所以建議你盡量多做一些矩形定位文件,以保證訓練足夠充分。如果你覺得訓練的 OCR 結果沒有達到你的目標,或者 Tesseract 識別某些字元時總是出錯,多創建一些訓練數據然後重新訓練將是一個不錯的改進方法。
創建完滿載 .box 文件和圖片文件的數據文件夾之後,在做進一步分析之前最好備份一下這個文件夾。雖然在數據上運行訓練程式不太可能刪除任何數據,但是創建.box 文件用了你好幾個小時的時間,來之不易,穩妥一點兒總沒錯。此外,能夠抓取一個滿是編譯數據的混亂目錄,然後再嘗試一次,總是好的。
完成所有的數據分析工作和創建 Tesseract 所需的訓練文件,一共有六個步驟。有一些工具可以幫你處理圖片和 .box 文件,不過目前 Tesseract 3.02 還不支援。
我再 github 上找到了一個 Python 版的解決方案來處理同時包含圖片文件和 .box 文件的數據文件夾,然後自動創建所有必需的訓練文件。
這個解決方案的主要配置方式和步驟都在 main 方法(目前,作者已經在 GitHub 中將示例程式碼修改為 __init__ 方法,符合 Python 的類定義原則)和 runAll 方法里:
from PIL import Image
import subprocess
import os
# Steps to take before running:
# Set TESSDATA_PREFIX to correct directory
# Put image and box files together in the same directory
# Label each corresponding file with the same filenames
class TesseractTrainer:
def __init__(self):
new_path = os.path.join(os.getcwd(), 'a_z\\')
self.languageName = "eng"
self.fontName = "captchaFont"
self.directory = new_path
self.trainingList = None
self.boxList = None
def runAll(self):
self.createFontFile()
# self.cleanImages()
self.renameFiles()
self.extractUnicode()
self.runShapeClustering()
self.runMfTraining()
self.runCnTraining()
self.createTessData()
def cleanImages(self):
print("CLEANING IMAGES...")
files = os.listdir(self.directory)
for fileName in files:
if fileName.endswith("tif") or fileName.endswith("jpeg") or fileName.endswith("png"):
image = Image.open(self.directory + "/" + fileName)
# # Set a threshold value for the image, and save
# image = image.point(lambda x: 0 if x < 250 else 255)
(root, ext) = os.path.splitext(fileName)
newFilePath = root + ".tiff"
image.save(self.directory + "/" + newFilePath)
# Looks for box files, uses the box filename to find the corresponding
# .tiff file. Renames all files with the appropriate "<language>.<font>.exp<N>" filename
def renameFiles(self):
files = os.listdir(self.directory)
boxString = ""
i = 0
for fileName in files:
if fileName.endswith(".box"):
(root, ext) = os.path.splitext(fileName)
tiffFile = self.languageName + "." + self.fontName + ".exp" + str(i) + ".tiff"
boxFile = self.languageName + "." + self.fontName + ".exp" + str(i) + ".box"
os.rename(self.directory + "/" + root + ".tiff", self.directory + "/" + tiffFile)
os.rename(self.directory + "/" + root + ".box", self.directory + "/" + boxFile)
boxString += " " + boxFile
self.createTrainingFile(self.languageName + "." + self.fontName + ".exp" + str(i))
i += 1
return boxString
# Creates a training file for a single tiff/box pair
# Called by renameFiles
def createTrainingFile(self, prefix):
print("CREATING TRAINING DATA...")
currentDir = os.getcwd()
os.chdir(self.directory)
p = subprocess.Popen(["tesseract", prefix + ".tiff", prefix, "nobatch", "box.train"], stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
returnValue = p.communicate()[1]
returnValue = returnValue.decode("utf-8", errors='ignore')
if "Empty page!!" in returnValue:
os.chdir(self.directory)
subprocess.call(["tesseract", "-psm", "7", prefix + ".tiff", prefix, "nobatch", "box.train"])
os.chdir(currentDir)
def extractUnicode(self):
currentDir = os.getcwd()
print("EXTRACTING UNICODE...")
boxList = self.getBoxFileList()
boxArr = boxList.split(" ")
boxArr.insert(0, "unicharset_extractor")
boxArr = [i for i in boxArr if i != '']
os.chdir(self.directory)
p = subprocess.Popen(boxArr)
p.wait()
os.chdir(currentDir)
def createFontFile(self):
currentDir = os.getcwd()
os.chdir(self.directory)
fname = self.directory + "/font_properties"
with open(fname, 'w') as fout:
fout.write(self.fontName + " 0 0 0 0 0")
os.chdir(currentDir)
def runShapeClustering(self):
print("RUNNING SHAPE CLUSTERING...")
# shapeclustering -F font_properties -U unicharset eng.captchaFont.exp0.tr...
self.getTrainingFileList()
shapeCommand = self.trainingList.split(" ")
shapeCommand.insert(0, "shapeclustering")
shapeCommand.insert(1, "-F")
shapeCommand.insert(2, "font_properties")
shapeCommand.insert(3, "-U")
shapeCommand.insert(4, "unicharset")
shapeCommand = [i for i in shapeCommand if i != '']
currentDir = os.getcwd()
os.chdir(self.directory)
p = subprocess.Popen(shapeCommand)
p.wait()
os.chdir(currentDir)
def runMfTraining(self):
# mftraining -F font_properties -U unicharset eng.captchaFont.exp0.tr...
print("RUNNING MF CLUSTERING...")
self.getTrainingFileList()
mfCommand = self.trainingList.split(" ")
mfCommand.insert(0, "mftraining")
mfCommand.insert(1, "-F")
mfCommand.insert(2, "font_properties")
mfCommand.insert(3, "-U")
mfCommand.insert(4, "unicharset")
mfCommand = [i for i in mfCommand if i != '']
currentDir = os.getcwd()
os.chdir(self.directory)
p = subprocess.Popen(mfCommand)
p.wait()
os.chdir(currentDir)
def runCnTraining(self):
# cntraining -F font_properties -U unicharset eng.captchaFont.exp0.tr...
print("RUNNING MF CLUSTERING...")
self.getTrainingFileList()
cnCommand = self.trainingList.split(" ")
cnCommand.insert(0, "cntraining")
cnCommand.insert(1, "-F")
cnCommand.insert(2, "font_properties")
cnCommand.insert(3, "-U")
cnCommand.insert(4, "unicharset")
cnCommand = [i for i in cnCommand if i != '']
currentDir = os.getcwd()
os.chdir(self.directory)
p = subprocess.Popen(cnCommand)
p.wait()
os.chdir(currentDir)
def createTessData(self):
print("CREATING TESS DATA...")
# Rename all files and run combine_tessdata <language>.
currentDir = os.getcwd()
os.chdir(self.directory)
os.rename("unicharset", self.languageName + ".unicharset")
os.rename("shapetable", self.languageName + ".shapetable")
os.rename("inttemp", self.languageName + ".inttemp")
os.rename("normproto", self.languageName + ".normproto")
os.rename("pffmtable", self.languageName + ".pffmtable")
p = subprocess.Popen(["combine_tessdata", self.languageName + "."])
p.wait()
os.chdir(currentDir)
def getBoxFileList(self):
if self.boxList is not None:
return self.boxList
self.boxList = ""
files = os.listdir(self.directory)
commandString = "unicharset_extractor"
filesFound = False
for fileName in files:
if fileName.endswith(".box"):
filesFound = True
self.boxList += " " + fileName
if not filesFound:
self.boxList = None
return self.boxList
# Retrieve a list of created training files, caches
# the list, so this only needs to be done once.
def getTrainingFileList(self):
if self.trainingList is not None:
return self.trainingList
self.trainingList = ""
files = os.listdir(self.directory)
commandString = "unicharset_extractor"
filesFound = False
for fileName in files:
if fileName.endswith(".tr"):
filesFound = True
self.trainingList += " " + fileName
if not filesFound:
self.trainingList = None
return self.trainingList
if __name__ == '__main__':
trainer = TesseractTrainer()
trainer.runAll()
你需要動手設置的只有三個變數。
- LanguageName
Tesseract 用三個字母的語言縮寫程式碼表示識別的語言種類。可能大多數情況下,你都會用」eng「表示英語(English)。
- fontName
表示你選擇的字體名稱,可以是任意名稱,但必須是一個不包含空格的單詞。
- directory
表示包含所有圖片和 .box 文件的目錄。建議你使用文件夾的絕對路徑,但是如果你使用相對路徑,可能需要以Python 程式碼運行的目錄位置為原點。如果你使用絕對路徑,就可以在電腦的任意位置運行程式碼了。 讓我們再看看runAll 里每個函數的用法。
createFontFile 創建了一個 font_properties 文件,讓 Tesseract 知道我們要創建的新字體:
captchaFont 0 0 0 0 0
這個文件包括字體的名稱,後面跟著若干 1 和 0,分別表示應該使用斜體、加粗或其他版本的字體(用這些屬性訓練字體是一個很好玩兒的練習)。
cleanImages 首先創建所有樣本圖片的高對比度版本,然後轉換成灰度圖,並進行一些清理,讓 Tesseract 更容易讀取圖片文件。如果你要處理的驗證碼圖片上面有一些很容易過濾掉的噪點,那麼你可以在這裡增加一些步驟來處理它們。
renameFiles 把所有的圖片文件和 .box 文件的文件名改變成 Tesseract 需要的形式(fileNumber 是文件序號,用來區別每個文件):
<languageName>.<fontName>.exp<fileNumber>.box
<languageName>,<fontName>.exp<fileNumber>.tiff
extractUnicode 函數會檢查所有已創建的 .box 文件,確定要訓練的字符集範圍。抽取出的 Unicode 會告訴你一共找到了多少個不重複的字元,這也是一個查詢字元的好方法,如果你漏了字元可以用這個結果快速排查。
之後的三個函數,runShapeClustering、runMfTraining 和 runCtTraining 分別用來創建文件 shapetable、pfftable 和 normproto。它們會生成每個字元的幾何和形狀資訊,也為 Tesseract 提供計算字元若干可能結果的概率統計資訊。
最後,Tesseract 會用之前設置的語言名稱對數據文件夾編譯出的每個文件進行重命名(例如:shapetable 被重命名為 eng.shapetable),然後把所有的文件編譯到最終的訓練文件 eng.traineddata 中。
你需要動手完成的唯一步驟,就是用下面的 Linux 和 Mac 命令行把剛剛創建的 eng-traineddata 文件複製到 tessdata 文件夾里,Windows 系統類似:
$cp /path/to/data/eng.traineddata $TESSDATA_PREFIX/tessdata
經過這些步驟之後,你就可以用這些 Tesseract 訓練過的驗證碼來識別新圖片了。

