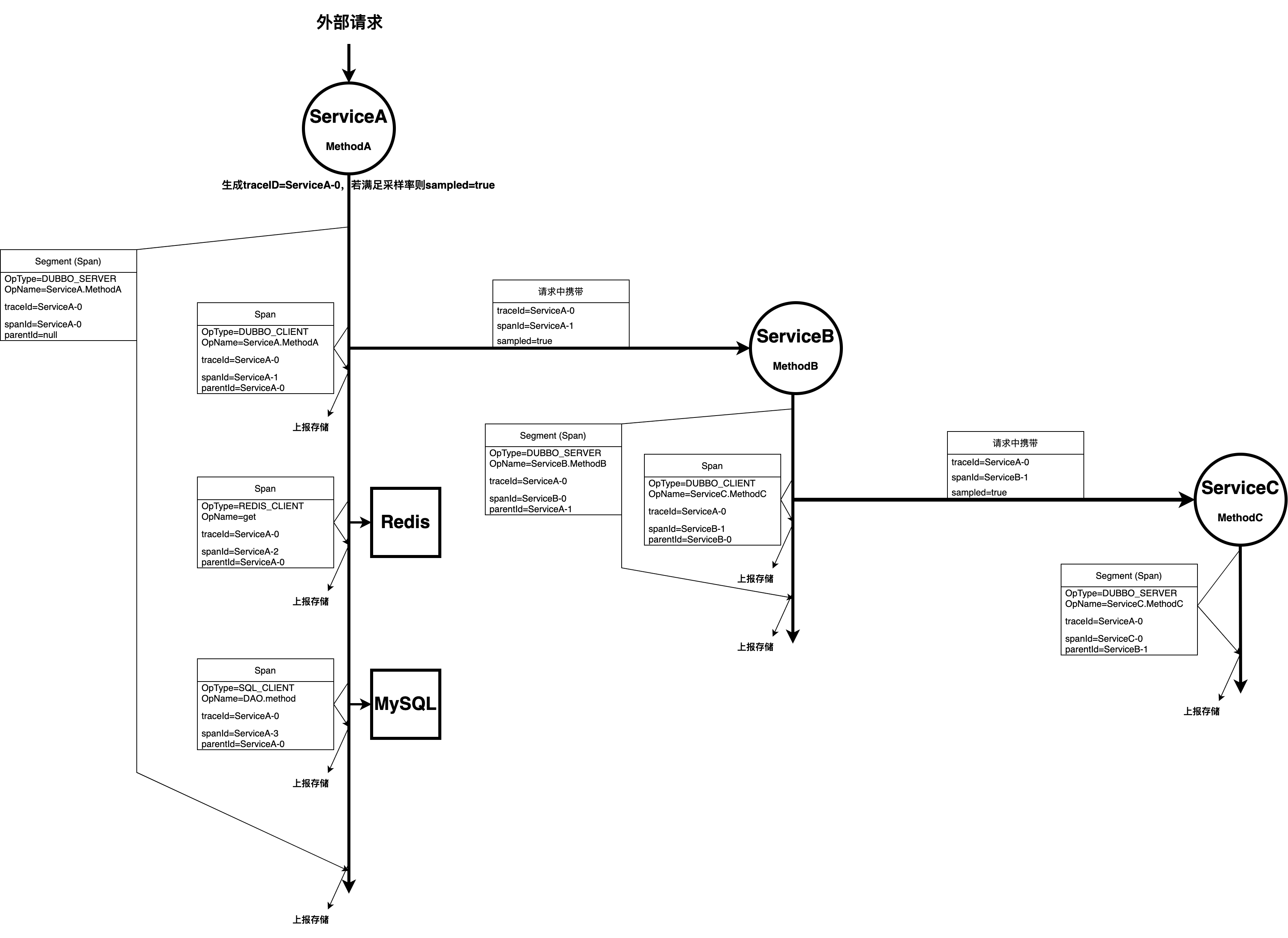
Hadoop3.x 三大組件詳解
Hadoop
Hadoop適合海量數據分散式存儲和分散式計算
運行用戶使用簡單的編程模型實現跨機器集群對海量數據進行分散式計算處理
1. 概述
1.1 簡介
Hadoop核心組件
- HDFS (分散式文件存儲系統):解決海量數據存儲
- YARN(集群資源管理和任務調度框架):解決資源任務調度
- MapReduce(分散式計算框架):解決海量數據計算
Hadoop發展簡史
-
Hadoop起源於Apache Lucen子項目:Nutch
Nutch的設計目標是構建一個大型的全網搜索引擎
問題:如何解決數十億網頁的存儲和索引問題
-
三篇論文Google
- The Google file system Google分散式文件系統 GFS
- MapReduce: Simplified Data Processing on Large Clusters Google分散式計算框架
- Bigtable: A Distributed Storage System for Structured Data Google結構化數據存儲系統
Hadoop現狀
- HDFS處在生態圈底層與核心地位
- YARN支撐各種計算引擎運行
- MapReduce企業一線幾乎不再直接使用,很多軟體的底層依舊使用MapReduce引擎
Hadoop特性優點
- 擴容能力(scalability):節點數量靈活變化
- 成本低(Economical):允許通過部署普通廉價的機器組成集群
- 效率高(efficiency):並發數據,可以在節點之間動態並行的移動數據
- 可靠性(reliability):自動維護數據的多份複製,並且在任務失敗後能自動重新部署計算任務
發行版本
- 開源社區版:Apache開源社區髮型
- 更新快
- 兼容穩定性不好
- 商業發行版
- 基於Apache開源協議
- 穩定兼容好
- 收費,版本更新慢
架構變遷
-
Hadoop 1.0
-
HDFS
-
MapReduce

-
-
Hadoop 2.0
-
HDFS
-
MapReduce
-
YARN

-
-
Hadoop 3.0
著重於性能優化
- 精簡內核,類路徑隔離、shell腳本重構
- EC糾刪碼,多NameNode支援
- 任務本地化優化、記憶體參數自動推斷






1.2 安裝部署
Hadoop集群整體概述
- Hadoop集群包括兩個:HDFS集群、YARN集群
- 兩個集群邏輯上分離、通常物理在一起
- 集群互相之間沒有依賴、互不影響
- 進程部署在同一機器上
- 兩個集群都是標準的主從架構集群
HDFS集群
- NameNode
- DataNode
- SecondaryNameNode
Yarn集群
- ResourceManager
- NodeManager

安裝Hadoop
Hadoop安裝包結構

集群安裝部署


1.3 啟動&關閉
-
要啟動hadoop集群,首先要格式化HDFS
$HADOOP_HOME/bin/hdfs namenode -format -
啟動hdfs
方法一:在主節點上啟動namenode,在每一個從節點上啟動datanode
# node1 $HADOOP_HOME/bin/hdfs --daemon start namenode # node2 node3... $HADOOP_HOME/bin/hdfs --daemon start datanode # 關閉 $HADOOP_HOME/bin/hdfs --daemon stop namenode $HADOOP_HOME/bin/hdfs --daemon stop datanode方法二:如果配置了
etc/hadoop/workers且所有的節點都配置了ssh免密登陸,在任意一個節點上都可以啟動,運行一次即可$HADOOP_HOME/sbin/start-dfs.sh # 關閉 $HADOOP_HOME/sbin/stop-dfs.sh -
啟動YARN
方法一:啟動ResourceManager,在主角色的節點上運行,啟動NodeManager,在每一個從角色上運行
# node1 $HADOOP_HOME/bin/yarn --daemon start resourcemanager # node2 ... $HADOOP_HOME/bin/yarn --daemon start nodemanager #關閉 $HADOOP_HOME/bin/yarn --daemon stop resourcemanager $HADOOP_HOME/bin/yarn --daemon stop nodemanager方法二:如果配置了
etc/hadoop/workers且所有的節點都配置了ssh免密登陸,在任意一個節點上運行都可以啟動$HADOOP_HOME/sbin/start-yarn.sh #關閉 $HADOOP_HOME/sbin/stop-yarn.sh -
也可以使用一鍵運行的腳本開啟yarn和hdfs
$HADOOP_HOME/sbin/start-all.sh $HADOOP_HOME/sbin/stop-all.sh -
開啟日誌伺服器(可選)
開啟之前需要開啟日誌聚合功能,需要修改
bin/yarn-site.xml,添加如下內容要根據自己的配置,修改伺服器地址
<!-- 開啟日誌聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 設置yarn歷史伺服器地址 --> <property> <name>yarn.log.server.url</name> <value>//node1:19888/jobhistory/logs</value> </property> <!-- 保存的時間7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>啟動日誌伺服器
$HADOOP_HOME/bin/mapred --daemon start historyserver #關閉 $HADOOP_HOME/bin/mapred --daemon stop historyserver
2. HDFS
Hadoop Distributed File System, Hadoop的分散式文件系統

2.1 概述
-
HDFS主要是解決大數據如何存儲問題的。分散式意味著是HDFS是橫跨在多台電腦上的存儲系統。
-
HDFS是一種能夠在普通硬體上運行的分散式文件系統,它是高度容錯的,適應於具有大數據集的應用程式,它非 常適於存儲大型數據 (比如 TB 和 PB)。
-
HDFS使用多台電腦存儲文件, 並且提供統一的訪問介面, 像是訪問一個普通文件系統一樣使用分散式文件系統

特點
- 分散式存儲
- 元數據記錄
- 分塊存儲
- 副本備份
設計目標
- 硬體故障(Hardware Failure)是常態, HDFS可能有成百上千的伺服器組成,每一個組件都有可能出現故障。因此故障檢測和自動快速恢復是HDFS的核心架構目標。
- HDFS上的應用主要是以流式讀取數據(Streaming Data Access)。HDFS被設計成用於批處理,而不是用戶互動式的。相較於數據訪問的反應時間,更注重數據訪問的高吞吐量。
- 典型的HDFS文件大小是GB到TB的級別。所以,HDFS被調整成支援大文件(Large Data Sets)。它應該提供很 高的聚合數據頻寬,一個集群中支援數百個節點,一個集群中還應該支援千萬級別的文件。
- 大部分HDFS應用對文件要求的是write-one-read-many訪問模型。一個文件一旦創建、寫入、關閉之後就不需要修改了。這一假設簡化了數據一致性問題,使高吞吐量的數據訪問成為可能。
- 移動計算的代價比之移動數據的代價低。一個應用請求的計算,離它操作的數據越近就越高效。將計算移動到數據 附近,比之將數據移動到應用所在顯然更好。
- HDFS被設計為可從一個平台輕鬆移植到另一個平台。這有助於將HDFS廣泛用作大量應用程式的首選平台
應用場景

主要特性
-
主從架構
- HDFS集群是標準的master/slave主從架構集群。
- 一般一個HDFS集群是有一個Namenode和一定數目的Datanode組成。
- Namenode是HDFS主節點,Datanode是HDFS從節點,兩種角色各司其職,共同協調完成分散式的文件存儲服 務。
- 官方架構圖中是一主五從模式,其中五個從角色位於兩個機架(Rack)的不同伺服器上。
-
分塊存儲
- HDFS中的文件在物理上是分塊存儲(block)的,默認大小是128M(134217728),不足128M則本身就是一塊 。
- 塊的大小可以通過配置參數來規定,參數位於
hdfs-default.xml中:dfs.blocksize
-
副本機制
- 文件的所有block都會有副本。副本係數可以在文件創建的時候指定,也可以在之後通過命令改變。
- 副本數由參數
dfs.replication控制,默認值是3,也就是會額外再複製2份,連同本身總共3份副本。
-
元數據記錄
在HDFS中,Namenode管理的元數據具有兩種類型:
-
文件自身屬性資訊 文件名稱、許可權,修改時間,文件大小,複製因子,數據塊大小。
-
文件塊位置映射資訊 記錄文件塊和DataNode之間的映射資訊,即哪個塊位於哪個節點上。

-
-
抽象統一的目錄樹結構(namespace)
-
HDFS支援傳統的層次型文件組織結構。用戶可以創建目錄,然後將文件保存在這些目錄里。文件系統名字空間的 層次結構和大多數現有的文件系統類似:用戶可以創建、刪除、移動或重命名文件。
-
Namenode負責維護文件系統的namespace名稱空間,任何對文件系統名稱空間或屬性的修改都將被Namenode 記錄下來。
-
HDFS會給客戶端提供一個統一的抽象目錄樹,客戶端通過路徑來訪問文件,形如:
hdfs://namenode:port/dira/dir-b/dir-c/file.data
-
-
資料庫存儲
- 文件的各個block的具體存儲管理由DataNode節點承擔。
- 每一個block都可以在多個DataNode上存儲。



2.2 HDFS Shell操作
簡介
- 命令行介面(英語:
command-line interface,縮寫:CLI),是指用戶通過鍵盤輸入指令,電腦接收到指令後 ,予以執行一種人際交互方式。 - Hadoop提供了文件系統的shell命令行客戶端:
hadoop fs [generic options]

文件系統協議
HDFS Shell CLI支援操作多種文件系統,包括本地文件系統(file:///)、分散式文件系統(hdfs://nn:8020)等- 具體操作的是什麼文件系統取決於命令中文件路徑URL中的前綴協議。
- 如果沒有指定前綴,則將會讀取環境變數中的
fs.defaultFS屬性,以該屬性值作為默認文件系統。

區別
hadoop dfs只能操作HDFS文件系統(包括與Local FS間的操作),不過已經Deprecatedhdfs dfs只能操作HDFS文件系統相關(包括與Local FS間的操作),常用hadoop fs可操作任意文件系統,不僅僅是hdfs文件系統,使用範圍更廣
目前版本來看,官方最終推薦使用的是hadoop fs。當然hdfs dfs在市面上的使用也比較多。
參數說明
- HDFS文件系統的操作命令很多和Linux類似,因此學習成本相對較低。
- 可以通過hadoop fs -help命令來查看每個命令的詳細用法。

操作命令
hadoop fs -xxx [x] <path> ...
-
ls:查詢指定路徑資訊hadoop fs -ls [-h] [-R] [<path> ...][-h]:人性化顯示文件size[-R]:遞歸查看指定目錄及其子目錄
-
put:從本地上傳文件hadoop fs -put [-f] [-p] <localsrc> ... <dst>[-f]覆蓋目標文件(已存在下)[-p]保留訪問和修改時間,所有權和許可權localsrc本地文件系統(客戶端所在機器)dst目標文件系統(HDFS)
-
get:下載文件到本地hadoop fs -get [-f] [-p] <src> ... <localdst>- 下載文件到本地文件系統指定目錄,
localdst必須是目錄 -f覆蓋目標文件(已存在下)-p保留訪問和修改時間,所有權和許可權
- 下載文件到本地文件系統指定目錄,
-
cat:查看HDFS文件內容
hadoop fs -cat <src> ... -
cphadoop fs -cp [-f] <src> ... <dst> -
mkdir:創建文件夾[-p]:遞歸創建文件夾
-
rm [-r]:刪除文件/文件夾 -
apped:追加文件hadoop fs -appendToFile <localsrc> ... <dst>- 將所有給定本地文件的內容追加到給定dst文件
- dst如果文件不存在,將創建該文件
- 如果
<localSrc>為-,則輸入為從標準輸入中讀取 - 適合小文件合併
#追加內容到文件尾部 appendToFile [root@node3 ~]# echo 1 >> 1.txt [root@node3 ~]# echo 2 >> 2.txt [root@node3 ~]# echo 3 >> 3.txt [root@node3 ~]# hadoop fs -put 1.txt / [root@node3 ~]# hadoop fs -cat /1.txt 1 [root@node3 ~]# hadoop fs -appendToFile 2.txt 3.txt /1.txt [root@node3 ~]# hadoop fs -cat /1.txt 1 2 3
示例
# 完整命令
bin/hadoop fs -xxx scheme://authority/path
# 顯示文件
hadoop fs -ls /
# 上傳文件
hadoop fs -put readme.txt /
# 顯示文件
hadoop fs -ls /
# Found 1 items
# -rw-r--r-- 1 root supergroup 0 2022-04-18 21:37 /readme.txt
# 查看文件內容
hadoop fs -cat /readme.txt
# 下載文件到本地
hadoop fs -get /readme.txt read.txt
# 創建文件夾(-p遞歸創建目錄)
hadoop fs -mkdir /test
hadoop fs -mkdir -p /test2/cur/
統計文件數量
hadoop fs -ls / | grep / | wc -l
統計文件大小
hadoop fs -ls / | grep / | awk '{print $8,$5}'
/readme.txt 0
/test 0
2.3 節點概述
架構圖

NameNode
主角色
- NameNode是Hadoop分散式文件系統的核心,架構中的主角色。
- NameNode維護和管理文件系統元數據,包括名稱空間目錄樹結構、文件和塊的位置資訊、訪問許可權等資訊。
- 基於此,NameNode成為了訪問HDFS的唯一入口
- NameNode內部通過記憶體和磁碟文件兩種方式管理元數據。
- 其中磁碟上的元數據文件包括
Fsimage記憶體元數據鏡像文件edits log(Journal)編輯日誌,記錄用戶的操作

DataNode
從角色
- DataNode是Hadoop HDFS中的從角色,負責具體的數據塊存儲。
- DataNode的數量決定了HDFS集群的整體數據存儲能力。通過和NameNode配合維護著數據塊。
- 多副本機制:默認為3

SecondaryNameNode
- Secondary NameNode充當NameNode的輔助節點,但不能替代NameNode。
- 主要是幫助主角色進行元數據文件的合併動作。可以通俗的理解為主角色的「秘書
- 負責定期的把edits文件中的內容合併到fsimage中,合併操作稱為checkpoint,在合併的時候會對edits中的內容進行轉換,生成新的內容保存到fsimage文件中
- SecondaryNameNode進程並不是必須的。

NameNode職責
- NameNode僅存儲HDFS的元數據:文件系統中所有文件的目錄樹,並跟蹤整個集群中的文件,不存儲實際數據。
- NameNode知道HDFS中任何給定文件的塊列表及其位置。使用此資訊NameNode知道如何從塊中構建文件。
- NameNode不持久化存儲每個文件中各個塊所在的datanode的位置資訊,這些資訊會在系統啟動時從DataNode重建。
- NameNode是Hadoop集群中的單點故障
- NameNode所在機器通常會配置有大量記憶體(RAM)
DataNode職責
- DataNode負責最終數據塊block的存儲。是集群的從角色,也稱為Slave。
- DataNode啟動時,會將自己註冊到NameNode並彙報自己負責持有的塊列表。
- 當某個DataNode關閉時,不會影響數據的可用性。 NameNode將安排由其他DataNode管理的塊進行副本複製 。
- DataNode所在機器通常配置有大量的硬碟空間,因為實際數據存儲在DataNode中。

2.4 HDFS寫數據流程
寫數據完整流程

pipeline管道
- Pipeline,中文翻譯為管道。這是HDFS在上傳文件寫數據過程中採用的一種數據傳輸方式。
- 客戶端將數據塊寫入第一個數據節點,第一個數據節點保存數據之後再將塊複製到第二個數據節點,後者保存後將 其複製到第三個數據節點。

- 為什麼DataNode之間採用pipeline線性傳輸,而不是一次給三個DataNode拓撲式傳輸呢?
- 因為數據以管道的方式,順序的沿著一個方向傳輸,這樣能夠充分利用每個機器的頻寬,避免網路瓶頸和高延遲時 的連接,最小化推送所有數據的延時
- 在線性推送模式下,每台機器所有的出口寬頻都用於以最快的速度傳輸數據,而不是在多個接受者之間分配寬頻。
ACK應答響應
- ACK (Acknowledge character)即是確認字元,在數據通訊中,接收方發給發送方的一種傳輸類控制字元。表示 發來的數據已確認接收無誤。
- 在HDFS pipeline管道傳輸數據的過程中,傳輸的反方向會進行ACK校驗,確保數據傳輸安全。

默認3副本存儲策略
- 默認副本存儲策略是由
BlockPlacementPolicyDefault指定。

- 第一塊副本:優先客戶端本地,否則隨機
- 第二塊副本:不同於第一塊副本的不同機架。
- 第三塊副本:第二塊副本相同機架不同機器。

實際流程
-
HDFS客戶端創建對象實例
DistributedFileSystem, 該對象中封裝了與HDFS文件系統操作的相關方法。 -
調用
DistributedFileSystem對象的create()方法,通過RPC請求NameNode創建文件。- NameNode執行各種檢查判斷:目標文件是否存在、父目錄是否存在、客戶端是否具有創建該文件的許可權。檢查通過 ,NameNode就會為本次請求記下一條記錄,返回
FSDataOutputStream輸出流對象給客戶端用於寫數據。
- NameNode執行各種檢查判斷:目標文件是否存在、父目錄是否存在、客戶端是否具有創建該文件的許可權。檢查通過 ,NameNode就會為本次請求記下一條記錄,返回
-
客戶端通過FSDataOutputStream輸出流開始寫入數據。
-
客戶端寫入數據時,將數據分成一個個數據包(packet 默認64k), 內部組件DataStreamer請求NameNode挑 選出適合存儲數據副本的一組DataNode地址,默認是3副本存儲
- DataStreamer將數據包流式傳輸到pipeline的第一個DataNode,該DataNode存儲數據包並將它發送到pipeline的第二個DataNode。同樣,第二個DataNode存儲數據包並且發送給第三個(也是最後一個)DataNode
-
傳輸的反方向上,會通過ACK機制校驗數據包傳輸是否成功
-
客戶端完成數據寫入後,在
FSDataOutputStream輸出流上調用close()方法關閉 -
DistributedFileSystem聯繫NameNode告知其文件寫入完成,等待NameNode確認因為NameNode已經知道文件由哪些塊組成(DataStream請求分配數據塊),因此僅需等待最小複製塊即可成功返回 。 最小複製是由參數
dfs.namenode.replication.min指定,默認是1.

2.5 HDFS讀數據流程
流程圖

-
HDFS客戶端創建對象實例DistributedFileSystem, 調用該對象的open()方法來打開希望讀取的文件
-
DistributedFileSystem使用RPC調用namenode來確定文件中前幾個塊的塊位置(分批次讀取)資訊。 對於每個塊,namenode返回具有該塊所有副本的datanode位置地址列表,並且該地址列表是排序好的,與客戶端的網路拓撲距離近的排序靠前
-
DistributedFileSystem將FSDataInputStream輸入流返回到客戶端以供其讀取數據
-
客戶端在FSDataInputStream輸入流上調用read()方法。
然後,已存儲DataNode地址的InputStream連接到文件 中第一個塊的最近的DataNode。數據從DataNode流回客戶端,結果客戶端可以在流上重複調用read()
-
當該塊結束時,FSDataInputStream將關閉與DataNode的連接,然後尋找下一個block塊的最佳datanode位置。 這些操作對用戶來說是透明的。所以用戶感覺起來它一直在讀取一個連續的流。
客戶端從流中讀取數據時,也會根據需要詢問NameNode來檢索下一批數據塊的DataNode位置資訊。
-
一旦客戶端完成讀取,就對FSDataInputStream調用close()方法
2.6 HDFS的高可用和高擴展
High Available
Federation
高可用(High Available)

HDFS的HA,指的是在一個集群中存在多個NameNode,分別運行在獨立的物理節點上。在任何時間點,只有一個NameNode是處於Active狀態,其它的是處於Standby狀態。 Active NameNode(簡寫為Active NN)負責所有的客戶端的操作,而Standby NameNode(簡寫為Standby NN)用來同步Active NameNode的狀態資訊,以提供快速的故障恢復能力。
為了保證Active NN與Standby NN節點狀態同步,即元數據保持一致。除了DataNode需要向這些NameNode發送block位置資訊外,還構建了一組獨立的守護進程」JournalNodes」(簡寫為JN),用來同步Edits資訊。當Active NN執行任何有關命名空間的修改,它需要持久化到一半以上的JNs上。而Standby NN負責觀察JNs的變化,讀取從Active NN發送過來的Edits資訊,並更新自己內部的命名空間。一旦Active NN遇到錯誤,Standby NN需要保證從JNs中讀出了全部的Edits,然後切換成Active狀態,如果有多個Standby NN,還會涉及到選主的操作,選擇一個切換為Active 狀態。
需要注意一點,為了保證Active NN與Standby NN節點狀態同步,即元數據保持一致
這裡的元數據包含兩塊,一個是靜態的,一個是動態的
靜態的是fsimage和edits,其實fsimage是由edits文件合併生成的,所以只需要保證edits文件內容的一致性。這個就是需要保證多個NameNode中edits文件內容的事務性同步。這塊的工作是由JournalNodes集群進行同步的
動態數據是指block和DataNode節點的資訊,這個如何保證呢? 當DataNode啟動的時候,上報數據資訊的時候需要向每個NameNode都上報一份。 這樣就可以保證多個NameNode的元數據資訊都一樣了,當一個NameNode down掉以後,立刻從Standby NN中選擇一個進行接管,沒有影響,因為每個NameNode 的元數據時刻都是同步的。
注意:使用HA的時候,不能啟動SecondaryNameNode,會出錯。 之前是SecondaryNameNode負責合併edits到fsimage文件 那麼現在這個工作被standby NN負責了。
NameNode 切換可以自動切換,也可以手工切換,如果想要實現自動切換,需要使用到zookeeper集群。
使用zookeeper集群自動切換的原理是這樣的
當多個NameNode 啟動的時候會向zookeeper中註冊一個臨時節點,當NameNode掛掉的時候,這個臨時節點也就消失了,這屬於zookeeper的特性,這個時候,zookeeper就會有一個watcher監視器監視到,就知道這個節點down掉了,然後會選擇一個節點轉為Active,把down掉的節點轉為Standby
高擴展(Federation)
HDFS Federation可以解決單一命名空間存在的問題,使用多個NameNode,每個NameNode負責一個命令空間
這種設計可提供以下特性:
- HDFS集群擴展性:多個NameNode分管一部分目錄,使得一個集群可以擴展到更多節點,不再因記憶體的限制制約文件存儲數目。
- 性能更高效:多個NameNode管理不同的數據,且同時對外提供服務,將為用戶提供更高的讀寫吞吐率。
- 良好的隔離性:用戶可根據需要將不同業務數據交由不同NameNode管理,這樣不同業務之間影響很小。
如果真用到了Federation,一般也會和前面我們講的HA結合起來使用,來看這個圖

3. MapReduce

3.1 分治思想
- MapReduce的思想核心是「先分再合,分而治之」。
- 所謂「分而治之」就是把一個複雜的問題,按照一定的「分解」方法分為等價的規模較小的若干部分,然後逐個解 決,分別找出各部分的結果,然後把各部分的結果組成整個問題的最終結果
- Map表示第一階段,負責「拆分」:即把複雜的任務分解為若干個「簡單的子任務」來並行處理。可以進行拆分的 前提是這些小任務可以並行計算,彼此間幾乎沒有依賴關係。
- Reduce表示第二階段,負責「合併」:即對map階段的結果進行全局匯總。
- 這兩個階段合起來正是MapReduce思想的體現。

3.2 設計構思
1. 如何對付大數據處理場景
- 對相互間不具有計算依賴關係的大數據計算任務,實現並行最自然的辦法就是採取MapReduce分而治之的策略。
- 首先Map階段進行拆分,把大數據拆分成若干份小數據,多個程式同時並行計算產生中間結果;然後是Reduce聚 合階段,通過程式對並行的結果進行最終的匯總計算,得出最終的結果。
- 不可拆分的計算任務或相互間有依賴關係的數據無法進行並行計算!

2. 構建抽象編程模型
-
MapReduce借鑒了函數式語言中的思想,用Map和Reduce兩個函數提供了高層的並行編程抽象模型。
-
map: 對一組數據元素進行某種重複式的處理

- reduce: 對Map的中間結果進行某種進一步的結果整理

-
MapReduce中定義了如下的Map和Reduce兩個抽象的編程介面,由用戶去編程實現:
map: (k1; v1) → (k2; v2) reduce: (k2; [v2]) → (k3; v3)通過以上兩個編程介面,大家可以看出MapReduce處理的數據類型是鍵值對。
3. 統一架構、隱藏底層細節
- 如何提供統一的計算框架,如果沒有統一封裝底層細節,那麼程式設計師則需要考慮諸如數據存儲、劃分、分發、結果 收集、錯誤恢復等諸多細節;為此,MapReduce設計並提供了統一的計算框架,為程式設計師隱藏了絕大多數系統層 面的處理細節。
- MapReduce最大的亮點在於通過抽象模型和計算框架把需要做什麼(what need to do)與具體怎麼做(how to do)分開了,為程式設計師提供一個抽象和高層的編程介面和框架。 (業務和底層技術分開)
- 程式設計師僅需要關心其應用層的具體計算問題,僅需編寫少量的處理應用本身計算問題的業務程式程式碼。
- 至於如何具體完成這個並行計算任務所相關的諸多系統層細節被隱藏起來,交給計算框架去處理:從分布程式碼的執行,到大到數千小到單個節點集群的自動調度使用。
3.3 介紹
分散式計算概念
- 分散式計算是一種計算方法,和集中式計算是相對的。
- 隨著計算技術的發展,有些應用需要非常巨大的計算能力才能完成,如果採用集中式計算,需要耗費相當長的時間 來完成。
- 分散式計算將該應用分解成許多小的部分,分配給多台電腦進行處理。這樣可以節約整體計算時間,大大提高計算效率。

MapReduce
- Hadoop MapReduce是一個分散式計算框架,用於輕鬆編寫分散式應用程式,這些應用程式以可靠,容錯的方式 並行處理大型硬體集群(數千個節點)上的大量數據(多TB數據集)。
- MapReduce是一種面向海量數據處理的一種指導思想,也是一種用於對大規模數據進行分散式計算的編程模型。
產生背景
- MapReduce最早由Google於2004年在一篇名為《MapReduce:Simplified Data Processingon Large Clusters 》的論文中提出。
- 論文中Google把分散式數據處理的過程拆分為Map和Reduce兩個操作函數(受到函數式程式語言的啟發),隨後被 Apache Hadoop參考並作為開源版本提供支援,叫做Hadoop MapReduce。
- 它的出現解決了人們在最初面臨海量數據束手無策的問題,同時它還是易於使用和高度可擴展的,使得開發者無需 關係分散式系統底層的複雜性即可很容易的編寫分散式數據處理程式,並在成千上萬台普通的商用伺服器中運行。
特點
-
易於編程
MapReduce框架提供了用於二次開發的介面;簡單地實現一些介面,就可以完成一個分散式程式。任務計算交給計算 框架去處理,將分散式程式部署到hadoop集群上運行,集群節點可以擴展到成百上千個等。
-
良好的擴展性
當電腦資源不能得到滿足的時候,可以通過增加機器來擴展它的計算能力。基於MapReduce的分散式計算得特點可 以隨節點數目增長保持近似於線性的增長,這個特點是MapReduce處理海量數據的關鍵,通過將計算節點增至幾百或 者幾千可以很容易地處理數百TB甚至PB級別的離線數據。
-
高容錯性
Hadoop集群是分散式搭建和部署得,任何單一機器節點宕機了,它可以把上面的計算任務轉移到另一個節點上運行, 不影響整個作業任務得完成,過程完全是由Hadoop內部完成的。
-
適合海量數據的離線處理
可以處理GB、TB和PB級別得數據量
局限性
MapReduce雖然有很多的優勢,也有相對得局限性,局限性不代表不能做,而是在有些場景下實現的效果比較差,並 不適合用MapReduce來處理,主要表現在以下結果方面:
-
實時計算性能差
MapReduce主要應用於離線作業,無法作到秒級或者是亞秒級得數據響應。
-
不能進行流式計算
流式計算特點是數據是源源不斷得計算,並且數據是動態的;而MapReduce作為一個離線計算框架,主要是針對靜態 數據集得,數據是不能動態變化得。
實例進程
一個完整的MapReduce程式在分散式運行時有三類
- MRAppMaster:負責整個MR程式的過程調度及狀態協調
- MapTask:負責map階段的整個數據處理流程
- ReduceTask:負責reduce階段的整個數據處理流程

階段組成
- 一個MapReduce編程模型中只能包含一個Map階段和一個Reduce階段,或者只有Map階段
- 不能有諸如多個map階段、多個reduce階段的情景出現
- 如果用戶的業務邏輯非常複雜,那就只能多個MapReduce程式串列運行

數據類型
- 注意:整個MapReduce程式中,數據都是以kv鍵值對的形式流轉
- 在實際編程解決各種業務問題中,需要考慮每個階段的輸入輸出kv分別是什麼
- MapReduce內置了很多默認屬性,比如排序、分組等,都和數據的k有關,所以說kv的類型數據確定及其重要的
3.3 官方示例
- 一個最終完整版本的MR程式需要用戶編寫的程式碼和Hadoop自己實現的程式碼整合在一起才可以
- 其中用戶負責map、reduce兩個階段的業務問題,Hadoop負責底層所有的技術問題
- 由於MapReduce計算引擎天生的弊端(慢),所以在企業中工作很少涉及到MapReduce直接編程,但是某些軟體的背後還依賴MapReduce引擎
- 可以通過官方提供的示例來感受MapReduce及其內部執行流程,因為後續的新的計算引擎比如Spark,當中就有 MapReduce深深的影子存在。
示例說明
- 示常式序路徑:
/XXX/hadoop-XXX/share/hadoop/mapreduce/ - 示常式序:
hadoop-mapreduce-examples-3.3.0.jar - MapReduce程式提交命令:
[hadoop jar|yarn jar] hadoop-mapreduce-examples-XXX.jar args… - 提交到哪裡去?提交到YARN集群上分散式執行。
1. 評估圓周率的值
蒙特卡洛方法

- 運行MapReduce程式評估一下圓周率的值,執行中可以去YARN頁面上觀察程式的執行的情況。
- 第一個參數:pi表示MapReduce程式執行圓周率計算任務
- 第二個參數:用於指定map階段運行的任務task次數,並發度,這裡是10
- 第三個參數:用於指定每個map任務取樣的個數,這裡是50。
/opt/hadoop-3.3.0/share/hadoop/mapreduce# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 10 50
2. WordCount單詞詞頻統計
WordCount中文叫做單詞統計、詞頻統計,指的是統計指定文件中,每個單詞出現的總次數

實現思路
-
map階段的核心:把輸入的數據經過切割,全部標記1,因此輸出就是<單詞,1>
-
shuffle階段核心:經過MR程式內部自帶默認的排序分組等功能,把key相同的單詞會作為一組數據構成新的kv對
-
reduce階段核心:處理shuffle完的一組數據,該組數據就是該單詞所有的鍵值對。對所有的1進行累加求和,就是 單詞的總次數

程式提交
- 自己隨便寫個文本文件
1.txt到HDFS文件系統的/input目錄下,如果沒有這個目錄,使用shell創建hadoop fs -mkdir /inputhadoop fs -put 1.txt /input
- 準備好之後,執行官方MapReduce實例,對上述文件進行單詞次數統計
- 第一個參數:wordcount表示執行單詞統計任務
- 第二個參數:指定輸入文件的路徑
- 第三個參數:指定輸出結果的路徑(該路徑不能已存在)
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
3.4 MapReduce執行流程
流程圖

Map執行過程
-
第一階段:把輸入目錄下文件按照一定的標準逐個進行邏輯切片,形成切片規劃。
默認
Split size = Block size(128M),每一個切片由一個MapTask處理。(getSplits) -
第二階段:對切片中的數據按照一定的規則讀取解析返回鍵值對
默認是按行讀取數據。key是每一行的起始位置偏移量,value是本行的文本內容。
(TextInputFormat) -
第三階段:調用Mapper類中的map方法處理數據。
每讀取解析出來的一個
<key, value>,調用一次map方法 -
第四階段:按照一定的規則對Map輸出的鍵值對進行分區partition。默認不分區,因為只有一個reducetask。 分區的數量就是reducetask運行的數量。 (分區方法默認是hash求余法)
-
第五階段:Map輸出數據寫入記憶體緩衝區,達到比例溢出到磁碟上。溢出spill的時候根據key進行排序sort。 默認根據key字典序排序。
-
第六階段:對所有溢出文件進行最終的merge合併,成為一個文件。

Reduce執行過程
- 第一階段:ReduceTask會主動從MapTask複製拉取屬於需要自己處理的數據。
- 第二階段:把拉取來數據,全部進行合併merge,即把分散的數據合併成一個大的數據。再對合併後的數據排序 。
- 第三階段:對排序後的鍵值對調用reduce方法。鍵相等的鍵值對調用一次reduce方法。最後把這些輸出的鍵值對寫入到HDFS文件中。

shuffle
- Shuffle的本意是洗牌、混洗的意思,把一組有規則的數據盡量打亂成無規則的數據。
- 而在MapReduce中,Shuffle更像是洗牌的逆過程,指的是將map端的無規則輸出按指定的規則「打亂」成具有一 定規則的數據,以便reduce端接收處理。
- 一般把從Map產生輸出開始到Reduce取得數據作為輸入之前的過程稱作shuffle。

Map端Shuffle
一個map最後只會產生一個文件
- Collect階段:將MapTask的結果收集輸出到默認大小為100M的環形緩衝區,保存之前會對key進行分區的計算, 默認Hash分區(分區數量為reducetask的數量,對每個key的hash值對reducetask數求餘映射到某個reducetask,key值相同的會映射到相同的reducetask)。
- Spill階段:當記憶體中的數據量達到一定的閥值(默認80%)的時候,就會將數據寫入本地磁碟,在將數據寫入磁碟之前需要對數據進行一次排序的操作,如果配置了combiner,還會將有相同分區號和key的數據進行排序。 (示例圖上顯示有三個分區,即三個reducetask)
- Merge階段:把所有溢出的臨時文件進行一次合併操作,以確保一個MapTask最終只產生一個中間數據文件。(三個分區會分別給三個reducetask,不同map中的相同分區會到同一個reducetask上合併)

Reducer端Shuffle
- Copy階段: ReduceTask啟動Fetcher執行緒到已經完成MapTask的節點上複製一份屬於自己的數據。
- Merge階段:在ReduceTask遠程複製數據的同時,會在後台開啟兩個執行緒對記憶體到本地的數據文件進行合併操作 。
- Sort階段:在對數據進行合併的同時,會進行排序操作,由於MapTask階段已經對數據進行了局部的排序, ReduceTask只需保證Copy的數據的最終整體有效性即可。

Shuffle機制弊端
- Shuffle是MapReduce程式的核心與精髓,是MapReduce的靈魂所在。
- Shuffle也是MapReduce被詬病最多的地方所在。MapReduce相比較於Spark、Flink計算引擎慢的原因,跟 Shuffle機制有很大的關係。
- Shuffle中頻繁涉及到數據在記憶體、磁碟之間的多次往複。
3.5 任務日誌查看
需要開啟YARN的日誌聚合功能,把散落在NodeManager節點上的日誌統一收集管理,方便查看日誌
- 啟動:
bin\mapred --daemion start historyserver yarn logs -applicationId <ID>
3.6 中止任務
在命令行中ctrl+c無法停止程式,因為程式已經提交到Hadoop集群運行 了
yarn application -kill <ID>
4. YARN
4.1 介紹
- Apache Hadoop YARN (Yet Another Resource Negotiator,另一種資源協調者)是一種新的Hadoop資源管 理器。
- YARN是一個通用資源管理系統和調度平台,可為上層應用提供統一的資源管理和調度。
- 它的引入為集群在利用率、資源統一管理和數據共享等方面帶來了巨大好處。

功能
- 資源管理系統:集群的硬體資源,和程式運行相關,比如記憶體、CPU等。
- 調度平台:多個程式同時申請計算資源如何分配,調度的規則(演算法)。
- 通用:不僅僅支援MapReduce程式,理論上支援各種計算程式。YARN不關心你幹什麼,只關心你要資源,在有的情況下給你,用完之後還我。
概述
- 可以把Hadoop YARN理解為相當於一個分散式的作業系統平台,而MapReduce等計算程式則相當於運行於操作 系統之上的應用程式,YARN為這些程式提供運算所需的資源(記憶體、CPU等)。
- Hadoop能有今天這個地位,YARN可以說是功不可沒。因為有了YARN ,更多計算框架可以接入到 HDFS中,而 不單單是 MapReduce,正是因為YARN的包容,使得其他計算框架能專註於計算性能的提升。
- HDFS可能不是最優秀的大數據存儲系統,但卻是應用最廣泛的大數據存儲系統, YARN功不可沒。
yarn.nodemanager.resource.memory-mb:單節點可分配的物理記憶體總量,默認是8MB*1024,即8Gyarn.nodemanager.resource.cpu-vcores:單節點可分配的虛擬CPU個數默認是8
4.2 架構組件
架構圖

client
container 容器(資源的抽象):容器之間邏輯上隔離的
YARN三大組件
- ResourceManager(RM)
- YARN集群中的主角色,決定系統中所有應用程式之間資源分配的最終許可權,即最終仲裁者。
- 接收用戶的作業提交,並通過NM分配、管理各個機器上的計算資源。
- NodeManager(NM)
- YARN中的從角色,一台機器上一個,負責管理本機器上的計算資源。
- 根據RM命令,啟動Container容器、監視容器的資源使用情況。並且向RM主角色彙報資源使用情況
- ApplicationMaster (App Mstr) (AM)
- 用戶提交的每個應用程式均包含一個AM。
- 應用程式內的「老大」,負責程式內部各階段的資源申請,監督程式的執行情況。
- 管理程式的進行
4.3 程式提交交互流程
核心交互流程
- MR作業提交 Client–>RM
- 資源的申請 MrAppMaster–>RM
- MR作業狀態彙報 Container(Map|Reduce Task)–>Container(MrAppMaster)
- 節點的狀態彙報 NM–>RM
整體概述
當用戶向 YARN 中提交一個應用程式後, YARN將分兩個階段運行該應用程式 。
- 第一個階段是客戶端申請資源啟動運行本次程式的ApplicationMaster
- 第二個階段是由ApplicationMaster根據本次程式內部具體情況,為它申請資源,並監控它的整個運行過程,直 到運行完成。

MR提交YARN交互流程
- 第1步:用戶通過客戶端向YARN中ResourceManager提交應用程式(比如hadoop jar提交MR程式)
- 第2步:ResourceManager為該應用程式分配第一個Container(容器),並與對應的NodeManager通訊,要求它在這個Container中啟動這個應用程式的ApplicationMaster
- 第3步:ApplicationMaster啟動成功之後,首先向ResourceManager註冊並保持通訊,這樣用戶可以直接通過 ResourceManager查看應用程式的運行狀態(處理了百分之幾)
- 第4步:AM為本次程式內部的各個Task任務向RM申請資源,並監控它的運行狀態
- 第5步:一旦 ApplicationMaster 申請到資源後,便與對應的 NodeManager 通訊,要求它啟動任務。
- 第6步:NodeManager 為任務設置好運行環境後,將任務啟動命令寫到一個腳本中,並通過運行該腳本啟動任務
- 第7步:各個任務通過某個 RPC 協議向 ApplicationMaster 彙報自己的狀態和進度,以讓 ApplicationMaster 隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務。在應用程式運行過程中,用戶可隨時通過 RPC 向 ApplicationMaster 查詢應用程式的當前運行狀態
- 第8步:應用程式運行完成後,ApplicationMaster 向 ResourceManager 註銷並關閉自己
4.4 調度器Scheduler
-
在理想情況下,應用程式提出的請求將立即得到YARN批准。但是實際中,資源是有限的,並且在繁忙的群集上, 應用程式通常將需要等待其某些請求得到滿足。YARN調度程式的工作是根據一些定義的策略為應用程式分配資源
-
在YARN中,負責給應用分配資源的就是Scheduler,它是ResourceManager的核心組件之一。
Scheduler完全專用於調度作業,它無法跟蹤應用程式的狀態。
-
一般而言,調度是一個難題,並且沒有一個「最佳」策略,為此,YARN提供了多種調度器和可配置的策略供選擇
調度器策略
- FIFO Scheduler(先進先出調度器)
- Capacity Scheduler(容量調度器)(Apache版本YARN默認使用Capacity Scheduler)
- Fair Scheduler(公平調度器)
FIFO
- FIFO Scheduler是Hadoop1.x中JobTracker原有的調度器實現,此調度器在YARN中保留了下來。
- FIFO Scheduler是一個先進先出的思想,即先提交的應用先運行。調度工作不考慮優先順序和範圍,適用於負載較低的小規模集群。當使用大型共享集群時,它的效率較低且會導致一些問題。
- FIFO Scheduler擁有一個控制全局的隊列queue,默認queue名稱為default,該調度器會獲取當前集群上所有的 資源資訊作用於這個全局的queue

優勢
- 無需配置、先到先得、易於執行
劣勢
- 任務的優先順序不會變高,因此高優先順序的作業需要等待
- 不適合共享集群
Capacity
FIFO Schedule的多隊列版本
- Capacity Scheduler容量調度是Apache Hadoop3.x默認調度策略。該策略允許多個組織共享整個集群資源,每個 組織可以獲得集群的一部分計算能力。通過為每個組織分配專門的隊列,然後再為每個隊列分配一定的集群資源, 這樣整個集群就可以通過設置多個隊列的方式給多個組織提供服務了。
- Capacity可以理解成一個個的資源隊列,這個資源隊列是用戶自己去分配的。隊列內部又可以垂直劃分,這樣一個 組織內部的多個成員就可以共享這個隊列資源了,在一個隊列內部,資源的調度是採用的是先進先出(FIFO)策略

資源隊列劃分
- Capacity Scheduler調度器以隊列為單位劃分資源。簡單通俗點來說,就是一個個隊列有獨立的資源,隊列的結構 和資源是可以進行配置的

優勢
- 層次化的隊列設計(Hierarchical Queues)
- 層次化的管理,可以更容易、更合理分配和限制資源的使用
- 容量保證(Capacity Guarantees)
- 每個隊列上都可以設置一個資源的佔比,保證每個隊列都不會佔用整個集群的資源
- 安全(Security)
- 每個隊列有嚴格的訪問控制。用戶只能向自己的隊列裡面提交任務,而且不能修改或者訪問其他隊列的任務
- 彈性分配(Elasticity)
- 空閑的資源可以被分配給任何隊列。 當多個隊列出現爭用的時候,則會按照權重比例進行平衡
Fair
- Fair Scheduler叫做公平調度,提供了YARN應用程式公平地共享大型集群中資源的另一種方式。使所有應用在平均情況下隨著時間的流逝可以獲得相等的資源份額。
- Fair Scheduler設計目標是為所有的應用分配公平的資源(對公平的定義通過參數來設置)。
- 公平調度可以在多個隊列間工作,允許資源共享和搶佔

如何理解公平共享
- 有兩個用戶A和B,每個用戶都有自己的隊列。
- A啟動一個作業,由於沒有B的需求,它分配了集群所有可用的資源。
- 然後B在A的作業仍在運行時啟動了一個作業,經過一段時間,A,B各自作業都使用了一半的資源。
- 現在,如果B用戶在其他作業仍在運行時開始第二個作業,它將與B的另一個作業共享其資源,因此B的每個作業將擁有資源的四分之一,而A的繼續將擁有一半的資源。結果是資源在用戶之間公平地共享。
優勢
- 分層隊列:隊列可以按層次結構排列以劃分資源,並可以配置權重以按特定比例共享集群。
- 基於用戶或組的隊列映射:可以根據提交任務的用戶名或組來分配隊列。如果任務指定了一個隊列,則在該隊列中提交任務。
- 資源搶佔:根據應用的配置,搶佔和分配資源可以是友好的或是強制的。默認不啟用資源搶佔。
- 保證最小配額:可以設置隊列最小資源,允許將保證的最小份額分配給隊列,保證用戶可以啟動任務。當隊列不能滿足最小資源時,可以從其它隊列搶佔。當隊列資源使用不完時,可以給其它隊列使用。這對於確保某些用戶、組或生產應用始終獲得足夠的資源。
- 允許資源共享:即當一個應用運行時,如果其它隊列沒有任務執行,則可以使用其它隊列,當其它隊列有應用需要資源 時再將佔用的隊列釋放出來。所有的應用都從資源隊列中分配資源。
- 默認不限制每個隊列和用戶可以同時運行應用的數量。可以配置來限制隊列和用戶並行執行的應用數量。限制並行 執行應用數量不會導致任務提交失敗,超出的應用會在隊列中等待。
4.5 多資源隊列使用
修改hadoop文件中 etc/hadoop/capacity-scheduler.xml
下面增加了兩個隊列online和offline,將以下內容添加進去,而不是覆蓋。
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,online,offline</value>
<description>隊列列表,多個隊列之間使用逗號分割</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>default隊列70%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.capacity</name>
<value>10</value>
<description>online隊列10%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.capacity</name>
<value>20</value>
<description>offline隊列20%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>70</value>
<description>Default隊列可使用的資源上限.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.maximum-capacity</name>
<value>10</value>
<description>online隊列可使用的資源上限.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.maximum-capacity</name>
<value>20</value>
<description>offline隊列可使用的資源上限.</description>
</property>
5. 序列化機制

為了提高磁碟IO性能,Hadoop棄用了java中的序列化,自己編寫了writable實現類

注意:
- Text等價於java.lang.String的writable,針對utf-8序列
- NullWritable是單例,獲取實例使用NullWritable.get()
Hadoop序列化機制的特點
- 緊湊:高效使用存儲空間
- 快速:讀寫數據的額外開銷小
- 可擴展:可透明地讀取老格式的數據
- 互操作:支援多語言的交互
Java序列化的不足
- 不精簡,附加資訊多,不太適合隨機訪問
- 存儲空間大,遞歸地輸出類的超類描述知道不再有超類
6. InputFormat

源碼
getSplits: 對文件進行分區createRecordReader: 將InputSplit中的數據解析成Record,即<k1, v1>
public abstract class InputFormat<K, V> {
/**
* Logically split the set of input files for the job.
*
* <p>Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.</p>
*
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple. The InputFormat
* also creates the {@link RecordReader} to read the {@link InputSplit}.
*
* @param context job configuration.
* @return an array of {@link InputSplit}s for the job.
*/
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
/**
* Create a record reader for a given split. The framework will call
* {@link RecordReader#initialize(InputSplit, TaskAttemptContext)} before
* the split is used.
* @param split the split to be read
* @param context the information about the task
* @return a new record reader
* @throws IOException
* @throws InterruptedException
*/
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
僅對FileInputFormat源碼進行分析
6.1 InputSplit
源碼註解(Hadoop3.3.0)
/**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
/*
getFormatMinSplitSize() = 1
getMinSplitSize(job) = 0
minSize = 1
*/
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
/*
沒有默認值
getMaxSplitSize(job) = Long.MAX_VALUE
所以maxSize等於Long的最大值
*/
long maxSize = getMaxSplitSize(job);
// generate splits
// 創建List,總部內保存生成的InputSplit
List<InputSplit> splits = new ArrayList<InputSplit>();
// 獲取輸入文件列表
List<FileStatus> files = listStatus(job);
// ignoreDirs = false
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
// 迭代輸入文件列表
for (FileStatus file: files) {
// 是否忽略子目錄,默認不忽略
if (ignoreDirs && file.isDirectory()) {
continue;
}
// 獲取 文件/目錄 路徑
Path path = file.getPath();
// 獲取 文件/目錄 長度
long length = file.getLen();
if (length != 0) {
// 保存文件的Block塊所在的位置
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判斷文件是否支援切割,默認為true
if (isSplitable(job, path)) {
// 獲取文件的Block大小,默認128M
long blockSize = file.getBlockSize();
// 計算split的大小
/*
內部使用的公式是: Math.max(minSize, Math.min(maxSize, blockSize))
Math.max(1, Math.min(Long.MAX_VALUE, 128))
默認情況下split的大小和Block size相等
*/
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 還需要處理的文件剩餘位元組大小,其實就是這個文件的原始大小
long bytesRemaining = length;
/*
SPLIT_SLOP = 1.1
只要剩餘文件大於1.1倍的分區size就繼續切割
*/
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
// 獲取block的索引
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
/*
組裝InputSplit
path: 路徑
length-bytesRemaining 起始位置
splitSize 大小
blkLocations[blkIndex].getHosts() 和 blkLocations[blkIndex].getCachedHosts() 所在的主機
*/
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
// 不支援切割
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
// 整個作為一個InputSplit
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
6.2 RecordReader
- 每一個
InputSplit都有一個RecordReader,作用是把InputSplit中的數據解析成Record,即<k1, v1>
行閱讀器的初始化方法源碼
// 初始化方法
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
// 獲取傳過來的InputSplit,將InputSplit轉換成子類FileSplit
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
// MAX_LINE_LENGTH對應的參數默認沒有配置,所以會取Integer.MAX_VALUE
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
// 獲取InputSplit的起始位置
start = split.getStart();
// 獲取InputSplit的結束位置
end = start + split.getLength();
// 獲取InputSplit的路徑
final Path file = split.getPath();
// open the file and seek to the start of the split
// 打開文件,並跳到InputSplit的起始位置
final FutureDataInputStreamBuilder builder =
file.getFileSystem(job).openFile(file);
FutureIOSupport.propagateOptions(builder, job,
MRJobConfig.INPUT_FILE_OPTION_PREFIX,
MRJobConfig.INPUT_FILE_MANDATORY_PREFIX);
fileIn = FutureIOSupport.awaitFuture(builder.build());
// 獲取文件的壓縮資訊
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
// 如果文件是壓縮文件,則執行if中的語句
if (null!=codec) {
//... 省略程式碼
} else {
// 跳轉到文件的起始位置
fileIn.seek(start);
// 針對未壓縮文件,創建一個閱讀器讀取一行行的數據
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
/*
注意:如果這個InputSplit不是第一個InputSplit,我們將會丟棄讀取出來的第一行
因為我們總是通過next方法多讀取一行
因此,如果一行數據被拆分到了兩個InputSplit中,不會產生問題。
*/
// 如果start不等於0,表示不是第一個inputsplit,所以把start的值重置為第二行的起始位置
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
7. MR性能優化
7.1 小文件問題
- Hadoop的HDFS和MR框架是針對大數據文件來設計的,在小文件的處理上不但效率低下,而且十分消耗記憶體資源
- HDFS提供了兩種類型的容器,SequenceFile和MapFile
SequenceFile
- 二進位文件,直接將
<key, value>對序列化到文件中 - 一般對小文件可以使用這種文件合併,即將文件名作為key,文件內容作為value序列化到大文件中
- 注意:SequenceFile需要一個合併的過程,文件較大,且合併後的文件將不方便查看,必須通過遍歷查看每一個小文件
程式碼實現
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
/*
small files
*/
public class SmallFileSeq {
public static void main(String[] args) throws Exception {
write("/root/smallfiles", "/seqFile");
read("/seqFile");
}
/**
* 生成SequenceFile文件
* @param inputDir 本地文件
* @param outputFile hdfs文件
* @throws Exception
*/
private static void write(String inputDir,String outputFile) throws Exception {
// 創建一個配置對象
Configuration conf = new Configuration();
// 指定hdfs路徑
conf.set("fs.defaultFS", "hdfs://node1:8020");
// 刪除輸出文件
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.delete(new Path(outputFile), true);
// 三個元素:輸出路徑、key的類型、value的類型
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
SequenceFile.Writer.file(new Path(outputFile)),
SequenceFile.Writer.keyClass(Text.class),
SequenceFile.Writer.valueClass(Text.class)
};
// 創建一個writer實例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);
// 指定需要壓縮的文件的目錄
File inputDirPath = new File(inputDir);
if (inputDirPath.isDirectory()) {
// 獲取目錄中的文件
File[] files = inputDirPath.listFiles();
assert files != null;
for (File file : files) {
// 獲取文件的全部記憶體
String content = FileUtils.readFileToString(file, "UTF-8");
// 獲取文件名
String fileName = file.getName();
Text key = new Text(fileName);
Text value = new Text(content);
// 寫入數據
writer.append(key, value);
}
}
writer.close();
}
/**
* 讀取SequenceFile文件
* @param inputFile
* @throws Exception
*/
private static void read(String inputFile) throws Exception {
// 創建一個配置對象
Configuration conf = new Configuration();
// 指定hdfs路徑
conf.set("fs.defaultFS", "hdfs://node1:8020");
// 創建閱讀器
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(new Path(inputFile)));
Text key = new Text();
Text value = new Text();
while (reader.next(key, value)) {
System.out.println("文件名:" + key.toString() + ",");
System.out.println("文件內容:\n" + value.toString() + ".");
}
reader.close();
}
}
MapFile
- MapFile是排序後的SequenceFile,MapFile由兩部分組成,分別是index和data
- index作為文件的數據索引,主要記錄了每個Record的key值,以及該Record在文件中的偏移位置
- 在MapFile被訪問的時候,索引文件會被載入到記憶體,通過索引映射關係可迅速定位到指定Record所在文件位置
SequenceFile文件是用來存儲key-value數據的,但它並不保證這些存儲的key-value是有序的,而MapFile文件則可以看做是存儲有序key-value的SequenceFile文件。MapFile文件保證key-value的有序(基於key)是通過每一次寫入key-value時的檢查機制,這種檢查機制其實很簡單,就是保證當前正要寫入的key-value與上一個剛寫入的key-value符合設定的順序,但是,這種有序是由用戶來保證的,一旦寫入的key-value不符合key的非遞減順序,則會直接報錯而不是自動的去對輸入的key-value排序
程式碼實例
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
/*
small files
*/
public class SmallFilemap {
public static void main(String[] args) throws Exception {
write("/root/smallfiles", "/mapFile");
read("/mapFile");
}
/**
* 生成MapFile文件
* @param inputDir 本地目錄
* @param outputDir hdfs目錄
* @throws Exception
*/
private static void write(String inputDir,String outputDir) throws Exception {
// 創建一個配置對象
Configuration conf = new Configuration();
// 指定hdfs路徑
conf.set("fs.defaultFS", "hdfs://node1:8020");
// 刪除輸出文件
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.delete(new Path(outputDir), true);
// 兩個元素:key的類型、value的類型
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
MapFile.Writer.keyClass(Text.class),
MapFile.Writer.valueClass(Text.class)
};
// 創建一個writer實例
MapFile.Writer writer = new MapFile.Writer(conf, new Path(outputDir), opts);
// 指定需要壓縮的文件的目錄
File inputDirPath = new File(inputDir);
if (inputDirPath.isDirectory()) {
// 獲取目錄中的文件
File[] files = inputDirPath.listFiles();
for (File file : files) {
// 獲取文件的全部記憶體
String content = FileUtils.readFileToString(file, "UTF-8");
// 獲取文件名
String fileName = file.getName();
Text key = new Text(fileName);
Text value = new Text(content);
// 寫入數據
writer.append(key, value);
}
}
writer.close();
}
/**
* 讀取MapFile文件
* @param inputDir MapFile文件路徑
* @throws Exception
*/
private static void read(String inputDir)throws Exception{
// 創建一個配置對象
Configuration conf = new Configuration();
// 指定hdfs路徑
conf.set("fs.defaultFS", "hdfs://node1:8020");
//創建閱讀器
MapFile.Reader reader = new MapFile.Reader(new Path(inputDir),conf);
Text key = new Text();
Text value = new Text();
//循環讀取數據
while(reader.next(key,value)){
//輸出文件名稱
System.out.print("文件名:"+key.toString()+",");
//輸出文件內容
System.out.println("文件內容:"+value.toString()+"");
}
reader.close();
}
}
7.2 數據傾斜問題
- MapReduce程式執行時,Reduce節點大部分執行完畢,但是有一個或者幾個Reduce節點運行很慢,導致整個程式處理時間變得很長,具體表現為:Reduce階段卡著不動
- 示例:利用hash分區方法,如果某個key值特別多,那麼會導致這個key值對應的Reducetask運行量很大,而其他的task則很快執行完畢。
解決方法
- 增加reduce個數(但不一定有用)
- 將傾斜數據打散
8. 參考資料
//www.bilibili.com/video/BV1CU4y1N7Sh?p=1
//wiki.xuwei.tech/