CUDA02 – 訪存優化和Unified Memory
CUDA02 – 的記憶體調度與優化
前面一篇(傳送門)簡單介紹了CUDA的底層架構和一些執行緒調度方面的問題,但這只是整個CUDA的第一步,下一個問題在於數據的訪存:包括數據以何種形式在CPU/GPU之間進行通訊、遷移,以及在GPU內部進行存儲、訪問。
1 global 、shared 、constant、local
通常來講,待計算的數據都存放在記憶體或者硬碟(外部存儲設備)中,由CPU來進行調度。想要在device上計算、處理數據,就首先需要將數據轉移至CUDA,這樣的轉移操作通常需要經過數據匯流排實現。這跟叫做PCI-E的匯流排連接在cpu和gpu之間,負責訊號傳輸,在早期的CUDA版本中程式設計師必須清楚的知道數據儲存在了這根匯流排的哪一端。當然相比起CUDA的計算速度,匯流排的訪存速度是很慢的。
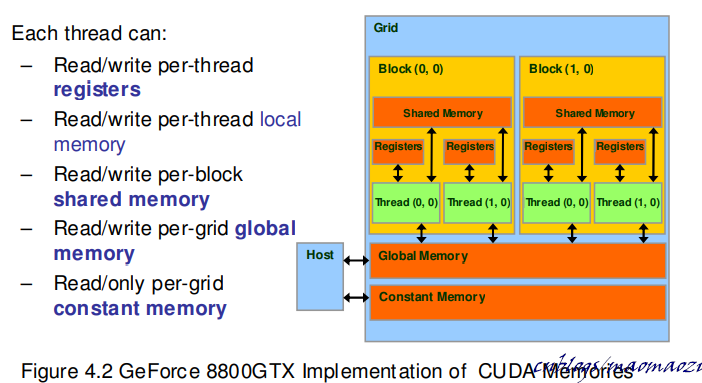
上一章介紹了CUDA的底層存儲結構。在G80中,一個核心計算單元通過訪問不同等級的存儲設備,來獲取計算資源。這些資源有些是屬於執行緒的,有些是屬於SM的,還有一些是全局的。下面寫一些這些物理結構對應的軟體結構,分成了以下幾種:
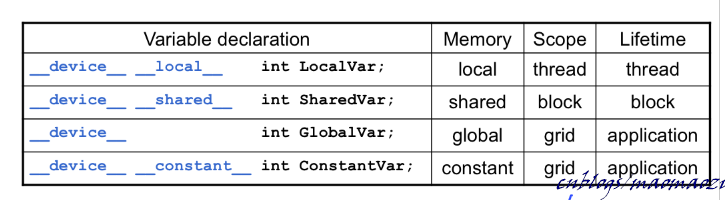
device shared
以__device__ __shared__為關鍵詞聲明的變數會被分配至SM上的shared memory, 可以由block內的全部執行緒所共享,生命周期也隨著block的結束而結束。(下圖位置),為了編程方便,可以直接寫為__shared__
device
以__device__ 為關鍵詞聲明的變數會被分配至GPU上的global memory, 可以由整個GPU上同一grid內的全部執行緒所共享,生命周期也隨著grid的結束而結束。(在G80上,就是這一塊)。global memory是整個GPU上與CPU進行數據交互的主要區域。
constant
以__device__ __constant__為關鍵詞聲明的變數也會在global memory內分配空間,但是同時會在SM上的 const-cache上進行快取。因此使用這部分變數的時候,執行緒會優先在當前sm的cache上進行查找, 如果沒有命中再考慮查找global memory。這類數據是只讀的,因此不會出現不同cache之間的衝突問題。可以縮寫為__constant__。
registers
除此之外,也可以選擇不加任何關鍵字,直接像C中那樣聲明(比如,int num;),這類變數稱作Automatic variables(scalar variables) 。這樣聲明的變數會使用片上的暫存器進行存儲,暫存器是由每一個執行緒所私有的。訪存速度最快,同時可用空間也最小。如果用戶自己定義的變數大小超過了CUDA提供的物理容量,CUDA會自動將一部分變數分配至global memory 中進行存儲,意味著訪存速度會降低很多(早期機器中,約等於200個時鐘周期)。
CUDA的設計思路是基於SIMT的,一行聲明了scalar variable的程式碼會在每一個執行緒的私有暫存器上都聲明一個對應變數,當執行緒生命周期結束,對應的變數也會被銷毀。當然,如果Automatic variables的對象為一個數組的話,數組會被分配到localmemory之中。注意在這種情況下,即便數據被分配到了local memory,這一變數的生命周期依舊與non-array 一樣,並且也只能被當前執行緒訪問。執行緒結束後,數據的空間也會被回收。這意味著使用 Automatic array variables其實是一種費力不討好的策略,應盡量避免使用。
暫存器不僅在硬體上有著更快的訪存速度,更重要的一點在於訪問私有暫存器是可以並行執行的,不會發生訪存衝突。

local
以__device__ __local__為關鍵字聲明的變數也在global memory之中存取。儘管其適用範圍僅限於thread內部,但是訪存速度和使用global 關鍵字聲明的變數速度是基本一樣的。之前說到Automatic variables 中有一部分變數有可能會被分配至全局變數;local memory相當於主動將一部分變數分配至 global內。不推薦使用。
2 訪存速度優化
上文記錄了device內多種等級的存儲器結構。下面介紹一些優化CUDA內訪存效率的方案,使得用戶可以更好的利用這些記憶體,達到最大的性能。
2.1 latency hide
考慮下面的情景:指令在CUDA上運行,由warp scheduler每次調度一個warp的執行緒來到片上執行。假設這次計算任務全部都是訪存指令;
對於暫存器的訪存是沒有延遲的在來到片上的1個時鐘周期內就能夠完成;而如果訪存指令的目標是global mem,情況就會不太一樣。發出訪存指令後,CUDA這一個warp會需要等待很長時間才能得到訪存的結果。在前已經寫了warp調度的原理:在這個warp等待數據就緒,被掛起的這段時間中,warp scheduler不會將這個warp分配至片上。
問題在於,隨著所有warp都執行到了這條指令(假設沒有分支),很有可能出現片上所有的warp都在stall狀態,等待數據從global mem返回的情況。為了減少這種不必要的阻塞,一個非常直觀的思路是:增加warps數量。執行緒束的數量越多,每個warp的掛起時間佔比也就越長,這樣就給予了warp更長的時間等候自己請求的數據準備就緒,相當於用執行thread來填補數據的等候時間,保證總有warp在取指。
這裡以G80為例子,簡單的做一個計算:
- 假設目標程式碼是一段IO密集操作,涉及很高密度的global memory存取,共n條訪存指令。
- 每一條針對global memory的訪存指令,在cache失效的情況下需要大約400-600個時鐘周期。
- 一個warp內含32個thread,每4個時鐘周期切換一個warp
因此,想使用warp片上的執行時間來掩蓋訪存過程中的阻塞,用戶需要至少設計400/4n個warp,才能實現latency hide。
當然上面的情況下一個SM上只有一個Block。為了達到最大的執行效率,一塊sm上可能會分得更多的block。
在早期的一些顯示卡中,latency hide 所起到的作用是巨大的。在使用之前很有必要計算出一個確定的比例,保證cuda可以以最大速度運轉。但是隨著後續的顯示卡優化了global memory 的訪存時間,這個優勢越來約不明顯了。
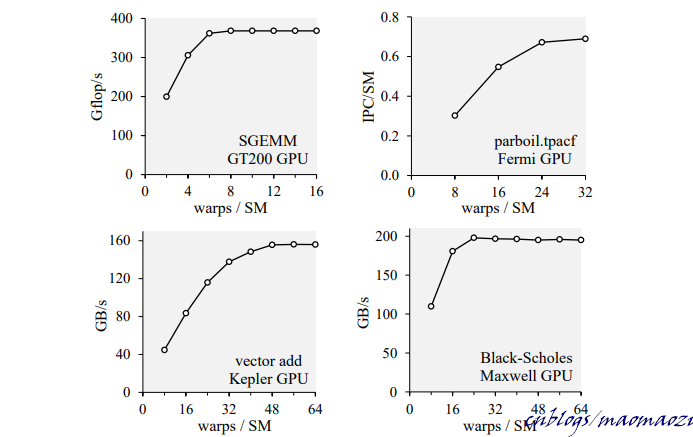
上圖:增加 waps數量可以有效的提高計算速度,但是這種提升會達到一個極限。除了memory latency 之外,這個極限值與其他很多屬性也有關係,例如運算指令的執行周期及其強度。為了達到相同的運算性能,warps數量會隨著計算強度的增長而先增加,後減少。
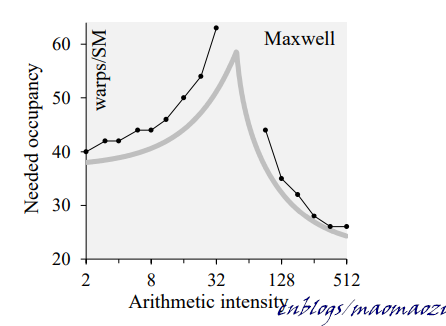
2.2 register
既然暫存器訪存最快,另一個簡單的思路是,多使用暫存器。但問題在於暫存器數量是有限的。儘管在程式碼邏輯上用戶可以定義無限多的暫存器,但是實際上能夠在暫存器上進行存儲的變數並不多。無限制地將變數設為暫存器類型反而會拉低訪存效率,因為編譯器會自動將多餘出來的那部分變數放進global mem。
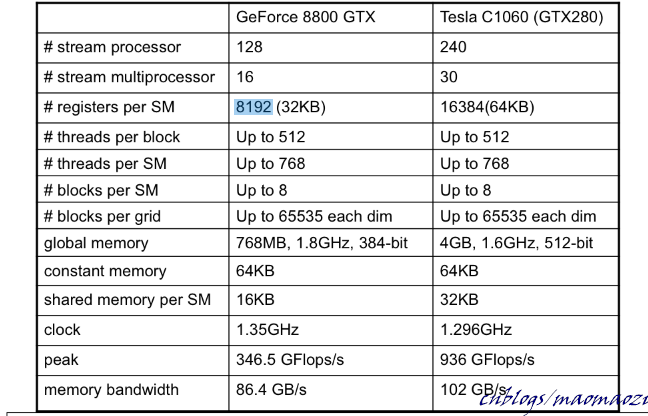
以GeForce 8800GT為例,每塊SM上一共設計了8192個暫存器,每個暫存器都是執行緒私有的執行緒之間不能互相訪問,意味著用戶設計的執行緒數量 * 每個執行緒內暫存器的數量應該小於等於這個值。
Nvidia設計8192(共32KB)這個值有著自己的用意。 假設每個Block內設計了16 * 16個thread, 每個thread又佔用了10個暫存器。這樣算下來每個block內都需要10 * 256 = 2560個暫存器。同時注意,一個SM上不是只會有一個BLOCK,有可能有多個Block同時運行在一塊SM上。假設這個數值為3, 得到的暫存器消耗數量為7680個。
在以上條件下, 假設每個thread內暫存器消耗加1, 總共就會產生2816*3 = 8448 個暫存器,不再能夠滿足G80的標準。這樣一來調度器就不得不減少每塊SM上的block數量為2,相當於整體的執行效率降低了1/3。
每個執行緒分配10個暫存器,這個數量在正常情況下是滿足需求的。據說Nvidia做過調查,去查看不同程式所需的暫存器數量,大部分程式都能夠滿足這個條件。總的來說暫存器就是用來存放臨時變數和頻繁存期的數據的。
順帶提一下,CUDA中一般對每個block內的執行緒數量也有著限制,這個限制個人理解和暫存器數量也有很大關係。考慮到一般的程式段,無論如何都需要使用到數個暫存器(如循環變數i等等),如果執行緒數量太多,反而也會導致計算速度變慢。
2.3 Coalescing
Coalescing 這個說法很形象,直譯為聚合,意思就是將一整塊數據整體存放。在說明coalescing前,有必要說明下CUDA從global memory中取數的方式。
已經說過,global memory很大,運行速度較慢,每次取數都要花費很長時間。同時,連接到 global memory的頻寬很大(64Byte),意味著每次遇到訪存指令取數時,同時可以返回64B的數據。假設取數指令為一條簡單的load int,餘下的60B並不會浪費,而是將這條int數據所在的一整塊兒數據同時返回。
利用這個特性來優化訪存時間的方法叫Coalescing。具體來講,這種方法需要數據的使用者操控多個進程,由0號執行緒訪問的首地址單元格必須為64byte的整數倍,後續地址也必須按序訪問,不能交叉,不能錯位。使用coalescing不需要額外的編寫程式碼,只要滿足了條件,編譯器會自動進行優化。

如上圖所示,thread1 可以選擇不使用address 132 處的數據,但不能夠錯位。由於數據是整個取出的,錯位意味著需要再花費相同的時鐘周期取下一塊記憶體,不再滿足Coalescing的思想。
當然,需要訪存的數據並不能保證總是int形。例如,需要執行緒訪問一個結構體,結構體記憶體儲了長方形兩條邊的長度資訊:
struct matrix
{
float a;
float b;
}
儘管這次結構體中包含兩個float變數,每個執行緒都需要讀取8B的數據,但CUDA仍然可以使用coalescing,只不過同一個warp完成訪存需要花費更長的時間。每次的訪存大小控制在4Byte、 8Byte、16Byte都可以實現Coalescing。
即便是當訪存的需求大小也不滿足以上條件時,也有辦法可以優化訪存。(例如結構體中含有長、寬、高共12Byte的數據) 這時有以下兩個思路:
- 第一個思路是想辦法湊齊到4、8、16B。在上述例子中只需要再填補一個空的Byte就可以滿足16Byte的coalescing,使用
__align(n)__實現記憶體對齊。
struct __align__(16) cube {
float a, b, c;
};
這樣一來,編譯器會自動的在訪問的時候填補上後面一位,實現coalescing。當然,這樣做會帶來一些空間上的浪費。
- 第二個思路是使用數組結構體,來代替結構體數組:
仍舊使用上面的情景。假設待計算的正方體數量只有1024個,那麼使用補齊的方法就產生了1024*4B的額外記憶體開銷。如果不想白白浪費掉這些空間,可以嘗試改變一下編程思路,不再將一個正方體的長、寬、高連續存放,而是把長單獨放在一起、寬單獨放在一起:
struct cube{
float a[256];
float b[256];
float c[256];
};
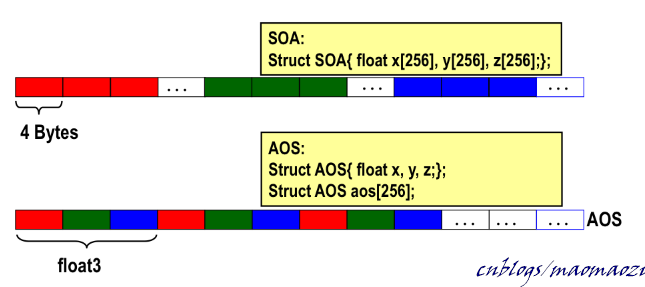
這樣一來,每個執行緒分別訪存長、寬、高,三者都滿足4KB的coalescing(只不過這種程式碼寫起來多少有點彆扭)。
2.4 減少 bank confilct
Coalescing針對global memory的訪存進行了優化,而bank conflict 是一個針對shared memory使用的概念。
shared memory 被主動分成了32塊,每一塊被稱作一個bank。例如,地址0x0000 ~ 0x001F 正好分配在 32 個bank上,意味著0x0000、0x0020位於相同的bank內,相同的bank內地址後四位是相同的。
這樣的設計主要是為了方便記憶體的連續讀寫。shared memory並沒有global memory那樣大的頻寬,但是每個bank的獨立性很強,可以做到同時存取。一個warp內有32個執行緒,一塊shared memory內正好有32塊bank,這樣設計是有用意的。如果程式碼設計得當,對於一條load指令,同一時刻片上的32個執行緒可以同時向shared memory內32個bank並行的進行存取,只要一輪即可完成。
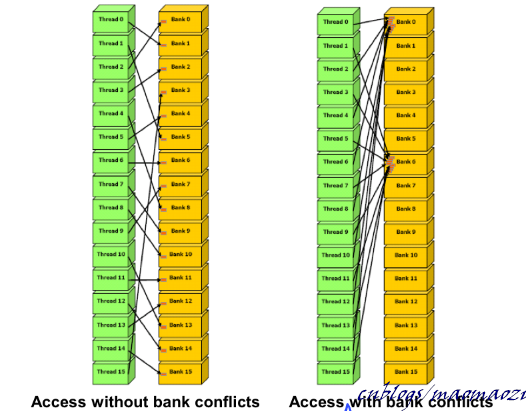
可以看到規避bank conflict的觸發條件沒有那麼嚴格,執行緒可以錯位訪問,只要保證不同時訪問相同的bank即可。被兩個執行緒同時訪問的bank只能串列的處理訪存請求,導致等待時間變長。
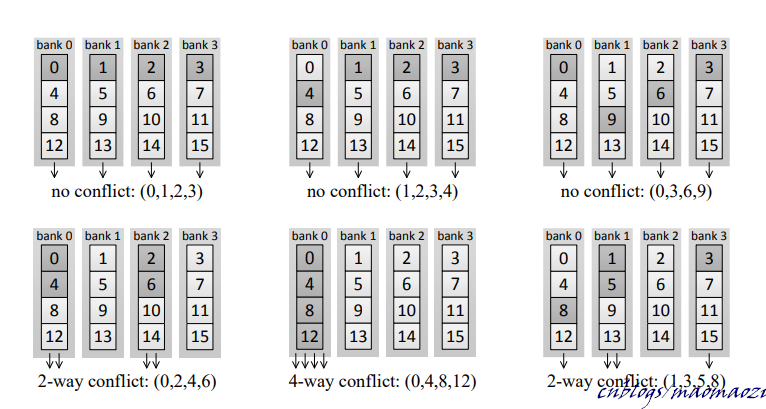
同一個bank上出現的衝突數量越多,整體的訪存速度會越慢。所以bank conflict並不像coalescing 那樣all or nothing,每次優化都有效果。
3 數據遷移
上面主要介紹了GPU內部的數據訪存和優化,下面的部分主要寫一下在GPU和CPU之間,數據是如何交互的。
GPU和CPU都有著自己獨立的記憶體和快取,由於馮諾依曼結構的限制,數據一般會首先由CPU讀入記憶體,當輪到CUDA完成計算任務的時候,再由CUDA讀入device memory;對於分散式系統來說,CUDA device之間也存在著不少的數據交互,這都給數據遷移帶來了很高的要求。這種遷移有很多種模式,程式設計師可能需要主動的控制轉移時機,也可以交給系統自動完成遷移,可以非同步預取數據,也可以在需要數據的時候阻塞,等待數據遷移;數據甚至可以不進行遷移,每次需要的時候都直接通過匯流排訪問… 總之,在這一部分也存在不少優化空間。
3.1 pcie & nvlink
之前說到,在早期的GPU之中,只有PCIe匯流排用來連接各個設備。PCIe比起CPU的DRAM間的速度要慢很多;而當系統中存在一台GPU和多台CPU時,這種瓶頸問題會變得更加嚴重。這部分首先講一下PCI-e和NVLINK這兩條在設備之間進行連接的匯流排。
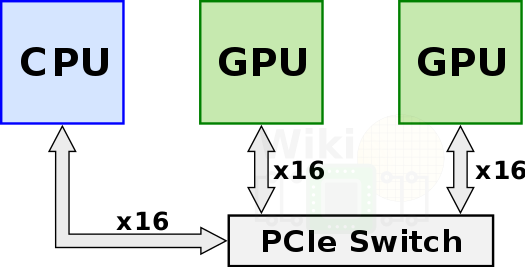
上圖:兩個GPU必須通過PCIe Switch交換數據。
NVLINK在這種情況下誕生了。NVLINK可以理解成一條兩端都是插口的匯流排。只要對應的設備上擁有NVLINK slot,就可以用NVLINK進行連接。相比起使用PCI-e Switch 交換轉發數據,NVLINK能夠在設備之間直接連接,大大提高了分散式系統的拓撲程度和計算速度。大部分情況下,這種連接設置在gpu之間(甚至可以在兩個GPU之間連接多個NVLINK以加強頻寬)。當然,只要應的CPU硬體條件允許,在CPU和GPU之間也可以使用(比如IBM power9)。一條NVLINK內提供了好幾條全雙工的子鏈路(相比之下,PCI為半雙工;PCIe才做到了全雙工),根據一些文章的測試結果,NVlink的效率比PCIe要高出兩倍以上,這是相當強大的改進了。(詳見參考文獻)

上圖:在峰值頻寬和有效頻寬上,兩者也有著不小的差別。
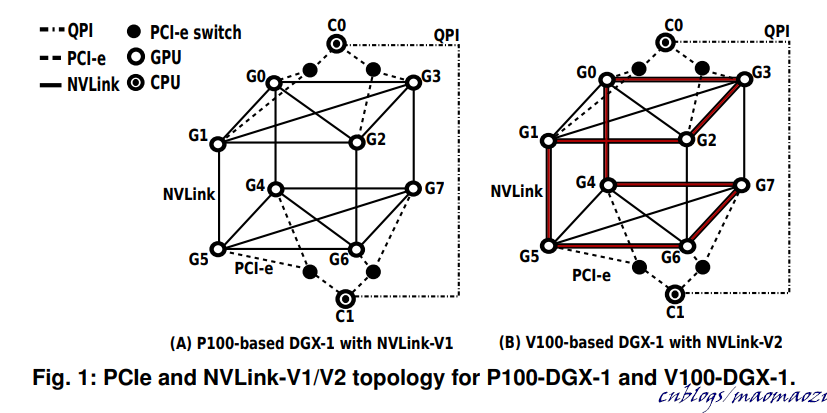
上圖:DGX-1中的拓撲結構。如果沒有NVlink,GPU間的數據交互就必須通過pcie Switch。(另:這篇文章中還提到了不同的通訊模式在當前一些主流人工智慧和大數據模型下的表現,感興趣的同學可以去看看。
3.2 相關函數介面
下面先給出各個函數的介面定義,具體的解釋在後文展開。
- cudaMalloc( void** devPtr, size_t size )
CUDA版的melloc函數,用於在設備上開闢一段空間,存放數組等變數。同C類似的,開闢完空間後需要使用cudaFree函數對空間進行釋放。
- cudaMallocManaged ( void** devPtr, size_t size, unsigned int flags = cudaMemAttachGlobal )
使用效果與cudaMalloc 類似,區別在於cudaMallocManaged 分配的空間會使用UM系統自動調度,一般搭配cudaMemPrefetchAsync使用。
cudaMallocManaged 分配旨在供主機或設備程式碼使用的記憶體,並且現在仍在享受這種方法的便利之處,即在實現自動記憶體遷移且簡化編程的同時,而無需深入了解 cudaMallocManaged 所分配統一記憶體 (UM) 實際工作原理的詳細資訊。nsys profile 提供有關加速應用程式中 UM 管理的詳細資訊,並在利用這些資訊的同時結合對 UM 工作原理的更深入理解,進而為優化加速應用程式創造更多機會。
- cudamemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
用於在主機和設備之間同步數據。程式運行到這一步之後會進入阻塞狀態,直到同步完成。
主機到設備:cudaMemcpy(d_A,h_A,nBytes,cudaMemcpyHostToDevice);設備到主機:cudaMemcpy(h_A,d_A,nBytes,cudaMemcpyDeviceToHost)
- cudaMemcpyAsync ( void* ds。t, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream = 0 )
cudamemcpy 的非同步版本,參數列表和cudamemcopy也相似。
- cudaMemPrefetchAsync ( const void* devPtr, size_t count, int dstDevice, cudaStream_t stream = 0 ):
cudaMemPrefetchAsyn是一個實現數據非同步存取的函數介面。將devPtr指針對應的數據複製到dstDevice對應的設備下。與memcopy不同的是,首先這個函數是非阻塞式的,用於非同步存取;其次cudaMemPrefetchAsyn只針對使用cudaMallocManaged分配的記憶體空間,和managed memory。
3.3 cudaMemCopy & cudaMelloc
cudaError_t cudaMalloc (void **devPtr, size_t size );
cudaMalloc 可以簡單的理解為cuda中的melloc函數,調用後開闢的空間位於GPU內,第一個參數填入空間首地址,第二個參數填入對應空間的大小。和CPU對應的,在調用cudaMalloc 開闢空間後,還需要調用cudaFree()將對應的空間回收。cuda melloc 還可以為更高維度的數據分配空間。使用cudaMallocPitch,cudaMalloc3D 可以為二維、三維的數據分配空間。
-
cudaError_t cudaFree ( void * devPtr )
-
cudaError_t cudaMemcpy (void * dst, const void * src, size_t count, enum kind)
從src向dst拷貝count 數量的記憶體。kind為一個枚舉形,表達數據拷貝的形式,一共有cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, or cudaMemcpyDeviceToDevice四種。
cudaMemCopy 其實可以看成是c語言中memcopy的cuda版本,重點是可以實現不同設備、主機之間的數據交互,是當前最常使用的數據傳輸方法。
同理,對於更高維度的矩陣,可以使用cudaMemcpy2D/cudaMemcpy3D來拷貝數據。
cudaMemcpyAsync 功能類似,是cudaMemcpy的非同步版本。根據傳輸數據類型的不同,同步和非同步函數在表現上有如下差別:
(涉及到一些pinned mem 和 Um的概念會在下文展開)

3.4 UM與記憶體的頁式管理
melloc函數
先看以下一段官方程式碼:(刪掉了一些不太重要的函數聲明和異常處理)
#include <stdio.h>
__global__ void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
}
int main()
{
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
initWith(3, a, N); //實現程式碼不再贅述。就是在CPU下位數組賦初值。
initWith(4, b, N);
initWith(0, c, N);
addVectorsInto<<<1, 1>>>(c, a, b, N);
cudaDeviceSynchronize();
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
可以看到,數據遷移的大體的流程很簡單: melloc—> init —> kernel —> cudaFree
在這短短的幾行程式碼中有很大的優化空間,我們從Melloc寫起。
我們首先考察C語言中Malloc這一函數的表現。使用malloc函數可以為一個佔用空間較大的數組其他數據結構分配空間,這樣做的好處是可以動態的控制分配空間的大小。在C中已經學過:malloc調用之後,系統只是開闢一段空間,並沒有對數據進行賦值,現在需要將這個概念進行一點拓展。
物理上的記憶體大小是有限的。在一塊大小有限的記憶體上需要運行多個不同的進程,這就導致了用戶進程的地址空間很混亂,且充滿隨機性,不方便程式的編寫。這時候作業系統出現了,作業系統為每一個用戶進程創建出了一個虛擬的記憶體空間,這樣在編譯、取指的時候用戶空間可以很好的處理地址問題,不再需要考慮其他進程的影響。這麼做的前提是需要作業系統將虛擬空間向真實空間做一個地址映射,這種映射由頁表實現,可以簡單的理解為一張map,除了映射到的目標地址之外,還需要一些標記位來表示空間的狀態資訊,等等。
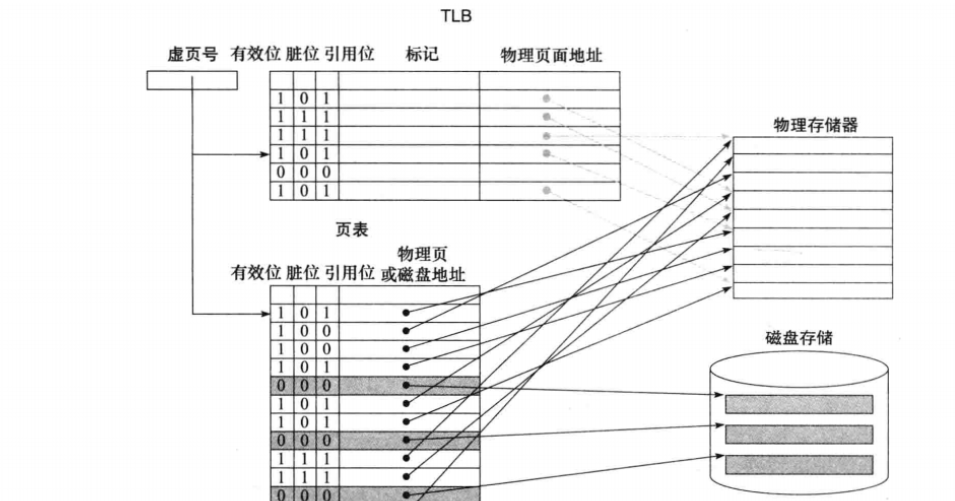
上圖:TLB可以簡單的理解為頁表的一個快取(但維持一致性的方式與cache不同),設計在cpu中。
當程式請求的數據在物理記憶體中不存在時,就會發生page fault。之後作業系統會轉而向磁碟中查找資訊,來替換當前物理頁。
說回melloc這一函數。再C語言程式端執行到這一行指令的時候,作業系統會將數據段的最高地址指針向上移動,但這部分地址空間只存在於虛擬空間下,並不存在於物理記憶體中,頁表中更沒有對應的頁。在第一次訪問這一段虛擬空間時(例如melloc後,需要對該區域進行寫操作),作業系統會引發缺頁中斷,這這段時間中建立起相應的映射關係。(順帶一提:引發缺頁中斷的同時,TLB也會出現相應的 TLB refill 和TLB invalid例外)
在CUDA與CPU的交互過程中,一個很重要的問題就是頁錯誤。
頁表在CPU中存放,而物理記憶體卻包括CPU上的記憶體空間和GPU上的記憶體空間(甚至有可能是多太GPU設備)。因此,不論是CPU還是GPU的程式碼段,都有可能面臨所需要的數據在頁表中缺頁的情況。一旦發生了頁錯誤,意味著程式需要進入阻塞狀態,等待物理頁從一台設備到另一台設備的遷移完成才能繼續執行。隨著數據量的增加,這一等待過程逐漸成為了程式運行的瓶頸,值得投入精力進行優化。
UVA & UM
首先需要介紹一下最古早的UVA,Unified Virtual Addressing。UVA提供了一個單一定址系統,出現也比UM早得多。
在UVA中,nvidia統一了不同設備記憶體設備,將他們全部映射到一個虛擬地址空間下,使得GPU程式碼空間下的指針可以直接訪問記憶體,不管記憶體駐留在哪塊GPU的device mem、hostmem、還是onchicp shared mem上。也正是在UVA中,使用cudamemcopy可以不需要再聲明輸入輸出參數到底駐留在哪個設備上,很大程度上簡化了編程的難度。
同時,UVA也提出了「zero copy memory」的概念。zero copy mem是一種特殊的記憶體,被pin在了host 的物理記憶體頁上,當device 需要的時候,可以通過PCI-e遠程訪問,不再需要使用memcopy。「zero copy mem」也可以看作一種在編程效率上的優化,但是可惜並不能對程式性能起到太大的幫助,因為零拷貝並不是無需拷貝,而是一種隱式非同步即時拷貝策略,每次訪問的時候還是需要走PCIe匯流排。如果需要頻繁的對CPU數據進行讀寫,可能會收到很大的性能影響。在此之前,從device訪問hostmem需要使用cudaHostAlloc(CUDA2.0), cudaHostGetDevicePointer(CUDA4.0)
總的來說,UVA解決了一部分GPU向CPU訪存的問題,但是這條通路是單向的,且效率不高。host無法通過UVA確定駐留在device上的記憶體地址,因為考慮到數據一致性和結構設計等問題,CUDA VA上由CUDA 映射來的記憶體是不允許主機訪問的。反過來,從host訪問device需要等到CUDA 6.0, UM的出現。
UM:Unified Memory是這一部分的重點, 在CUDA6.0 之時提出。某種程度上講,UM統一記憶體融合了前面兩種數據複製方式的優點(零拷貝和顯式的數據轉移):GPU可以自由訪問整個系統的記憶體頁,並且同時根據需求自由地以更高的頻寬進行數據遷移。
UM是一個很優秀的設計,大大簡化了編程的複雜度。但是也因為其不可控性,可能會引發頁錯誤,拖慢程式的運行效率。當數據如何在不同計算部件之間進行遷移不重要、很難隔離工作集合時,UM是一個很好的選擇.例如,當需要快速寫出能夠運行的簡單程式碼、擁有大量數據重用、debug或者數據見關聯性很強,等等。除了這些情景外,使用UM雖然不會影響程式的正確性,但常常不是問題的最優解。最主要的原因就是UM分配是由程式自動完成的。而假如在需要數據的時候數據並不在對應的設備上(GPU/CPU),往往引發頁錯誤,造成延遲。這一部分在下文cudaMallocManaged 里展開。
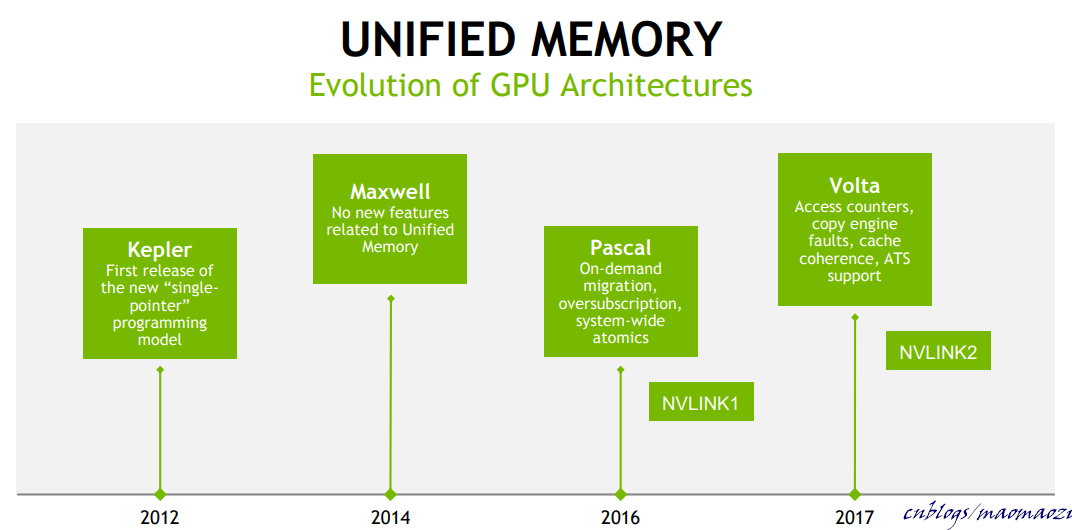
UM的進化史。Pascal為另一個比較重要的一個時間節點(CUDA8),為UM的很多設計提供了硬體層面的支援。
cudaMallocManaged for UM
下面說回cudaMallocManaged()這一函數。相比cudaMelloc,cudaMallocManaged 面向的是統一記憶體。
cudaMallocManaged調用後,程式會自動的分配由主機、設備都可以訪問的程式空間。這一空間的真實物理位置由演算法決定,對程式設計師不可見。在早期的K80等設備上(Pascal 之前),調用 cudaMallocManaged() 會在GPU上分配指定數量的空間大小(除非在多GPU環境下(multi-GPU systems with pre-Pascal GPUs),有些GPU不允許peer-to-peer access,這部分記憶體會被分配至CPU上)。記憶體分配的同時也在頁表上會為相應的虛擬地址段做出標記,初始化相應的頁表項,使得作業系統能夠得知那部分空間駐留在GPU上。
在這些架構中,記憶體分配是在調用核函數時完成的。所有需要訪問的物理頁面都會在進入核函數後預取至運算部件對應的記憶體中。這些GPU可以面臨更少的page fault,但缺點是需要預取大量的物理頁(儘管很大一部分可能是沒有必要的)。當然,用戶可以通過 cudaStreamAttachMemAsync()來使得物理頁只遷移至對應的流或核函數中(默認情況下,會將物理頁遷移至所有的流/核函數)。
儘管page不會在GPU運行態下出現,但是在CPU運行態下還是會出現pagefault。每當CPU面臨對數據的讀寫操作時,GPU驅動都需要將駐留在GPU上的物理頁面遷移至CPU。
在Pascal等後期GPU架構中, cudaMallocManaged() 不會再分配對應的物理空間,只有通過訪問或者預取操作(後續會講到)才會進行填充。這種情況下,除非被CPU/GPU運算單元訪問,在記憶體中是沒有對應頁表項的。頁表中找不到對應的項會引起頁錯誤。此時,程式需要等待物理頁在不同的記憶體之間進行遷移。物理頁可以在不同的處理器記憶體之間進行遷移,程式也會使用一些演算法,使得常用的物理頁儘可能多的駐留在對應的記憶體中,減少頁錯誤的頻率。但儘管如此,使用這種方法進行記憶體分配還是會不可避免地拖慢程式運行效率(尤其是當演算法存在大量頁面遷移時)。
這樣,UM的遷移方法就從Bulk migration 變成了On-demand migration。
在後續發布的架構中,陸續為UM加入了一些新功能,使得其可以更好的避免page fault;在VOLTA中CUDA加入了Access Counters;類似與體系結構中的轉移預測;GPU driver設計了一個計數器,用來記錄最頻繁訪問到的物理頁號,並使其駐留在CUDA內部,減少交換; 而NVLINK2 使得CPU可以直接訪問甚至快取一部分GPU記憶體,把GPUcache保存在自己的L1之中,增加cache命中率。
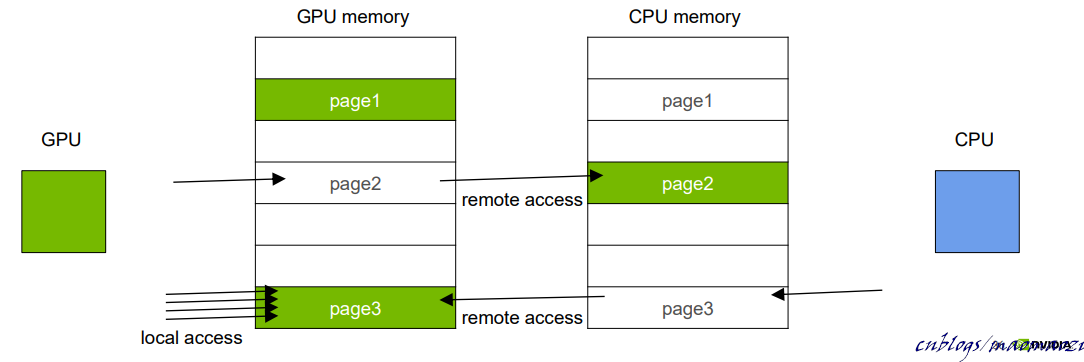
例如,下方的例子:
#include <iostream>
#include <math.h>
// CUDA kernel to add elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory -- accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Launch kernel on 1M elements on the GPU
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
程式內容其實很簡單,就是y[i] += x[i]。注意x和y都是在利用UM進行分配的,在CPU中初始化並在GPU中計算。分別衡量這段程式碼在K80與P100上的表現:

其中,右圖使用了更新的P100,可以看到kernal運行時間明顯的增加了。這是因為數據遷移所花費的時間被計算進了核函數的執行時間(在缺頁時stall,等待物理頁遷移)。在這個測試程式碼中,數據在CPU中進行初始化,這意味著CUDA需要面對大量的page fault,stall會花費大量的時間。
總的來講,使用stall – page fault這種方式來代替預取的模式其實節省了更多時間,減少了不必要的記憶體遷移。但page fault 本身仍是一個程式執行的瓶頸。
page fault及其 一些解決方案
- Initialize the Data in a Kernel
//之前的程式碼中數據全部在cpu中進行初始化,而cudamelloc將其空間分配在了GPU上。所以一個簡單的辦法是乾脆在GPU中進行初始化。
想法很簡單,但是實際使用起來這一方案可能並不適用。一方面,初始化操作可能不適合併行處理,如果在kernel上執行卻只有一個執行緒工作的話,其效率可能還不如CPU;更大的問題在於很多數據是沒辦法在GPU上初始化的,例如存儲設備大多數情況下只能由CPU訪問。誰讓人家是核心呢(攤手
- Run It Many Times
增加數據的重用次數也可以有效的改善page fault。每次出現頁錯誤意味著物理頁的遷移(從cpu到gpu????還是反方向??)。將核函數運行多次,全部物理頁遷移已經在第一次的時候完成了,這樣可以有效的拉低平均執行速度。
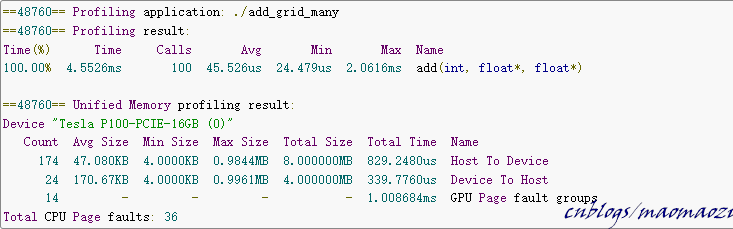
- Prefetching:使用非同步訪存的函數cudaMemPrefetchAsync來實現。
cudaMemPrefetchAsync()
數據改成 on-demand 轉移後,很大一部分頁錯誤會在數據的使用過程中產生。一個很直觀的解決方案誕生了:在數據需要被使用之前,由程式設計師主動將數據遷移至對應的device。這種預取必須是非阻塞式的,否則優化就沒有意義。實現這一功能對應的函數就是cudaMemPrefetchAsync。至於預取的時機只能由程式設計師自己控制。
CUDA 可通過 `cudaMemPrefetchAsync` 函數,輕鬆將託管記憶體非同步預取到 GPU 設備或 CPU。以下所示為如何使用該函數將數據預取到當前處於活動狀態的 GPU 設備,然後再預取到 CPU:
int deviceId;
cudaGetDevice(&deviceId); // The ID of the currently active GPU device.
cudaMemPrefetchAsync(pointerToSomeUMData, size, deviceId); // Prefetch to GPU device.
cudaMemPrefetchAsync(pointerToSomeUMData, size, cudaCpuDeviceId); // Prefetch to host. `cudaCpuDeviceId` is a
// built-in CUDA variable.
在Nvidia的公開課中舉了一個使用Prefetch做記憶體遷移的例子。感興趣的同學可以看看其他人整理的運行結果。
仍舊使用我之前做加法的例子,只不過這裡還包含了一個check函數。由於check函數在CPU上運行,因此數據涉及到 HostToDevice 和 DeviceToHost 兩部分,兩部分都可以使用數據預取來進行加速。
鏈接://blog.csdn.net/Felaim/article/details/104339103
參考文獻
//www.greatlakesconsortium.org/events/GPUMulticore/Chapter4-CudaMemoryModel.pdf
//www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-143.pdf
《深入淺出談CUDA》
//developer.nvidia.com/blog/unified-memory-cuda-beginners/
//docs.nvidia.com/cuda/cuda-memcheck/index.html
//developer.nvidia.com/blog/maximizing-unified-memory-performance-cuda/
//www.nextplatform.com/micro-site-content/achieving-maximum-compute-throughput-pcie-vs-sxm2/
//docs.nvidia.com/cuda/cuda-runtime-api/
//docs.nvidia.com/cuda/cuda-runtime-api/api-sync-behavior.html#api-sync-behavior__memcpy-sync
//blog.csdn.net/weixin_44501699/article/details/118047724
