mongodb 數據塊的遷移流程介紹
1. 基本概念
1.1 Chunk(數據塊)
表示特定伺服器上面,連續範圍的分片鍵值所包含的一組數據,是一個邏輯概念。
例如,某數據塊記錄如下:
{ "_id" : "chunk-a", // 數據塊Id "ns" : "user.address", // 該數據塊對應的資料庫名和表名 "min" : { // 該數據塊對應的分片鍵值的起始值(包含),是「Shi Jiazhuang」 "city" : "Shi Jiazhuang" }, "max" : { // 該數據塊對應的分片鍵值的結束值(不包含),是「Nanjjing」 "city" : "Nan Jing" }, "shard" : "repa" // 該數據塊存儲在repa分片伺服器 }
// 即該數據塊記錄表示,資料庫user中的表address中的「city」欄位中,其值從「Shi Jiazhuang」(包含)到「Nan Jing」(不包含)這段連續區間的數據,都存儲在名為repa的分片伺服器。
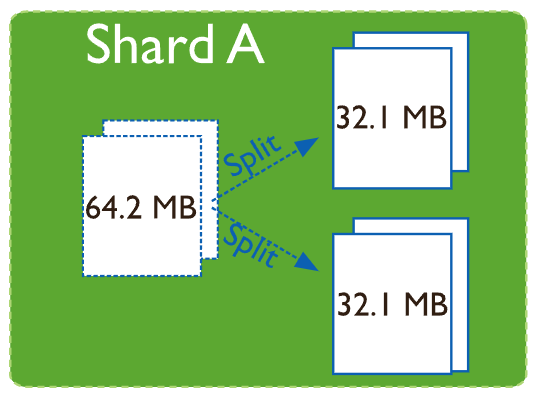
1.2 Chunk Size(數據塊大小)
數據塊所對應的數據,如果超過64M(默認值),則會被系統自動切分為兩個數據,即數據塊會從1塊切分為2塊,圖示如下:
1.3 Migration(數據塊遷移)
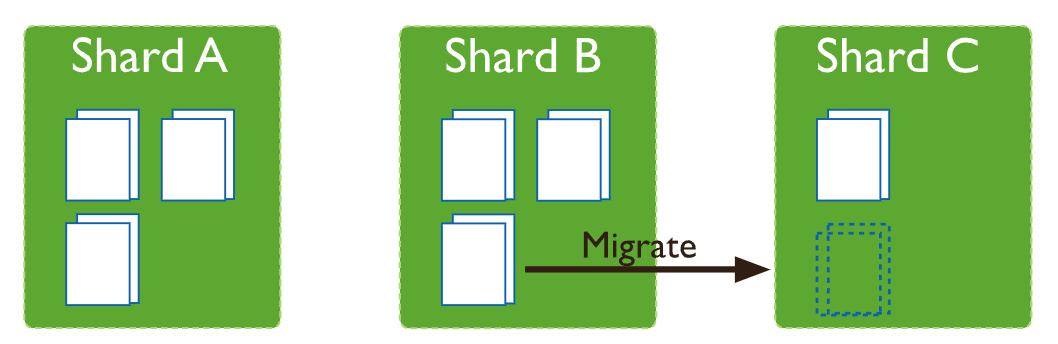
mongodb有一個後台的平衡器進程,它會監控各個分片伺服器上面的數據塊的數量,如果發現不同的分片伺服器上面數據塊的數量差異,超過閾值,則會啟動數據塊遷移任務,
直至不同的分片伺服器之間的數據塊的數量差異落在閾值之內,圖示如下:
1.4 Migration Thresholds(遷移閾值)
數據塊的遷移閾值,是和該表的數據塊總數相關的,具體如下:
| 數據塊總數量 | 閾值 |
| 小於20 | 2 |
| 20-79 | 4 |
| 大於等於80 | 8 |
2. 遷移流程
數據塊的遷移對於用戶和應用層來說是透明的,當然可能會有些性能的損失,整個遷移流程有7個步驟,圖示如下

各個步驟的內容如下:
1. 平衡器發送遷移命令給源節點。
2. 源節點啟動了一個內部的數據塊遷移命令給目標節點,同時在數據塊遷移期間,對於該數據塊的請求依然路由到源節點。
3. 目標節點首先創建該數據塊上缺失的索引(如果需要的話)。
4. 目標節點到源節點拉取數據。
5. 目標節點需要到源節點再請求在步驟4執行期間的增量變更數據(新增、更新和刪掉),如果有則跳轉到步驟4,直到沒有增量數據。
6. 數據全部遷移成功後,源節點會向配置伺服器(config server)發送請求,更新該數據塊的元數據中的”分片伺服器(shard)”的值為目標節點。
7. 源節點刪除本地的該數據塊對應的數據。
3. 最佳實踐
以上分享了數據塊和數據塊遷移的一些基本概念和流程,下面是一些最佳實踐。
3.1 關於數據塊大小的選擇
數據塊的大小,默認是64M,通常情況下是不需要修改它的,但是有時候該值的大小根據不同的業務場景會帶來不同的影響,需要綜合多方面的因素來設置該值。
數據塊大小太小:通常情況下,較小的數據塊大小,會帶來更頻繁的數據塊遷移,數據在集群間的分布會更加均衡,但是如果分片鍵設置的不夠合理,則會產生很多無法切分(split)的大數據塊,太大的數據塊無法在分片之間遷移,從而導致數據分布的不均衡性,此時需要把數據塊大小調大。
數據塊大小太大:較大的數據塊,意味著更少的數據塊遷移,數據在集群間的分布容易出現不平衡,同時也容易產生讀寫熱點(可手動切分),此時需要把數據塊大小調小。
3.2 關於數據塊遷移對集群性能的影響
數據塊遷移除了佔用目標節點和源節點的頻寬和磁碟讀寫資源外,在遷移流程中的步驟6會短暫阻塞對該數據塊的訪問,影響應用的訪問,因此建議設置平衡器的活躍時間窗口,設置為業務低估時進行,步驟如下:
1. 連接到mongos。
2. 切換到config資料庫
use config
3. 啟動平衡器
如果平衡器是關閉狀態,則設置活躍時間窗口也是不會做數據遷移的,命令如下:
sh.startBalancer()
4. 修改活躍時間窗口
db.settings.updateOne( { _id: "balancer" }, { $set: { activeWindow : { start : "01:00", stop : "06:00" } } }, // start和stop的格式為"HH:MM",其中HH的取值範圍是0到23,MM的取值範圍是00到59 { upsert: true } )


