從壓測碰到的詭異斷連問題聊聊Nginx的連接管理
本文主要分享一個在壓測Nginx反向代理服務過程中碰到的連接異常斷開問題,包括問題的定位與復現,最後由這個實際問題引申聊一下Nginx的連接管理。
本部落格已遷移至CatBro’s Blog,那是我自己搭建的個人部落格,歡迎關注。
問題描述
問題是這樣的,我們的Nginx服務是作為HTTP反向代理,前端是HTTPS,後端是HTTP。在一次壓測過程中碰到了連接異常斷開的問題,但是Nginx這邊沒有發現任何的錯誤日誌(已經開了Info級別也沒有)。因為是在客戶那邊進行的測試,而且是同事在對接的項目,我並不了解第一手的情況,包括測試方法、Nginx的配置等,唯一給到我這邊的就是一個抓包,只有這個是確鑿的資訊,其餘的就是一些零星的口頭轉述。同事多次嘗試在公司復現這個問題但沒有成功。
抓包的情況是這樣的:
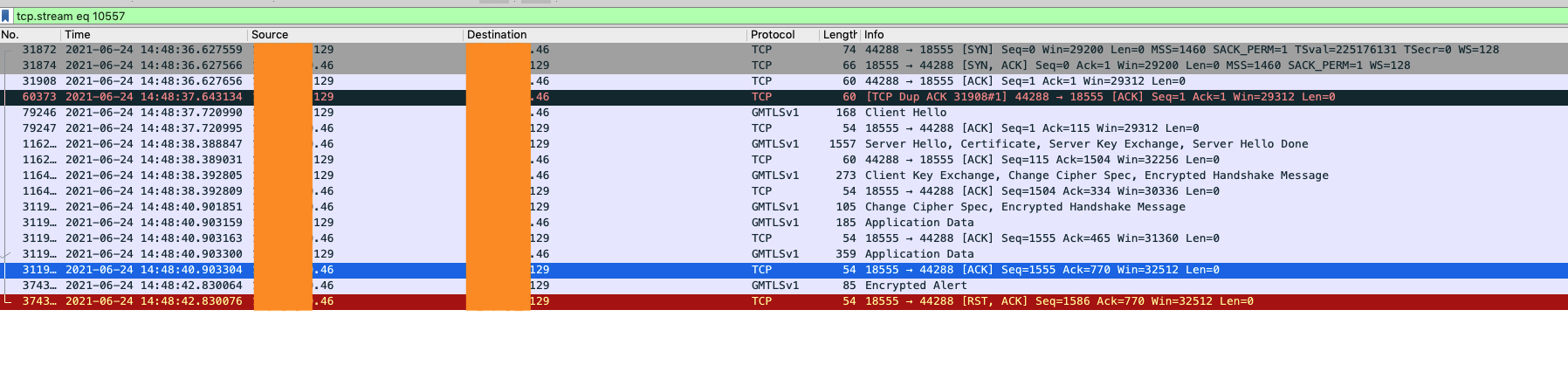
抓包文件很大,在一段很短的時間內出現很多連續的這種錯誤。上面的截圖中是跟前端的交互,因為是壓測的關係,短時間有大量的包,所以從抓包中無法確定對應的後端連接,不清楚後端連接是否已經建立,是否是後端出錯了。
問題定位
我們首先分析下上圖中抓包的情況,前面是一個GMVPN的握手,因為壓測的關係,服務端回復ServerHello消息以及後面的ChangeCipherSpec消息都隔了一兩秒的時間。握完手之後客戶端發了兩個應用數據包(對應HTTP請求頭和請求體)。大概兩秒之後,服務端發送了一個alert消息,然後緊接著發送了一個reset。
同事還觀察到,抓包中從收到應用數據到連接斷開的時間都是2s左右,所以猜測可能跟超時有關。reset的發送原因也是一個關鍵的線索,另外還有前面提到的Nginx日誌(Info級別)中沒有任何錯誤。我們就根據這幾個線索來進行問題的定位,首先來分析reset的情況。
reset原因
有很多情況都會觸發TCP的reset,其中大部分都是內核自身的行為。
-
埠沒有監聽
顯然可以排除這種情況,我們的連接都已經開始處理了。
-
防火牆攔截
伺服器並沒有配置類似的防火牆策略,這種情況也排除。
-
向已經關閉的socket發送消息
socket可能是進程主動關閉,也可能是被動關閉,也就是進程崩了的情況。顯然從抓包可以看出我們的進程並沒有崩,況且進程崩了也會有內核日誌。那如果是進程主動關閉socket的情況呢,我們從抓包中可以看到服務端是在發送了一個Encrypted Alert消息之後緊接著就發送了reset,其間並沒有收到客戶端的消息,所以也可以排除這種情況。
-
接收緩衝區還有數據未接收時關閉該socket
因為我們並不清楚後端連接的情況,所以抓包中的兩個應用數據包是否已經被應用層接收是無法確定的。因此,這種情況是有可能的。
-
SO_LINGER
前面幾種都是內核自發的行為,不需要用戶參與。SO_LINGER是一個TCP選項,可以修改close()系統調用的行為。
- 默認不開的情況下,close調用會立即返回,發送隊列一直保持到發送完成,連接通過正常的四次揮手進行關閉。
- 打開且時間設為0的情況下,直接丟棄發送緩衝區的數據,並發送RST給對方(不走4次揮手流程)。
- 打開且時間不為0的情況下,進程將阻塞直到1)所有數據發送完畢且收到對方確認,2)超時時間到。對於前者會正常關閉;對於後者,close將返回EWOULDBLOCK,然後跟第二種情況相同處理,即且丟棄發送緩衝區數據然後發送RST。這種情況socket必須是阻塞的,否則close會立即返回。
了解了SO_LINGER的情況,一看Nginx程式碼,確實是用到了這個選項,不過只有當連接超時並且打開了reset_timeout_connection配置項時才會去設置。而這個選項默認是關閉的,且我們也沒有顯式地設置過,所以這種情況也排除了。
if (r->connection->timedout) { clcf = ngx_http_get_module_loc_conf(r, ngx_http_core_module); if (clcf->reset_timedout_connection) { linger.l_onoff = 1; linger.l_linger = 0; if (setsockopt(r->connection->fd, SOL_SOCKET, SO_LINGER, (const void *) &linger, sizeof(struct linger)) == -1) { ngx_log_error(NGX_LOG_ALERT, log, ngx_socket_errno, "setsockopt(SO_LINGER) failed"); } } }
至此可以得出結論,reset的原因大概率就是因為接收緩衝區還有數據的時候關閉了連接。至於連接為什麼被關閉,則還需要進一步定位。
連接關閉原因
接著前面的結論我們進一步排查,SSL握手顯然是完成了,因為客戶端已經發送了應用數據消息,所以在接收緩衝區中數據應該就是Application Data。至於請求頭是否已經被讀取目前還不好判斷。不過從抓包可以看出,服務端是直接關閉的連接,並沒有給客戶端發送響應,所以可以確認服務端還沒有走到應用層處理的環節,要麼是還沒有接收請求頭、要麼是還沒處理完畢,否則肯定會有應用層的響應。於是問題的範圍就縮小到了SSL握手完成之後、請求頭處理完畢之前。
是不是之前提到的超時原因呢?不過同事又指出超時時間已經設置了很大(分鐘級別),那會不會遺漏了某些超時呢。但是好像沒有兩秒這麼短的超時時間,Nginx默認的超時基本都是60s級別的。於是開始尋找可能存在的超時,發現SSL階段並沒有單獨的超時,在請求頭讀完之前就只有一個超時時間就是client_header_timeout,但是顯然這個超時不是2s。我們合理假設是現場配置錯了,但我在確認程式碼後發現如果是超時也是會有INFO級別日誌,接收到請求前和接收到請求後都是如此。
所以超時這條路走不通了,大概率不是由於超時導致的連接關閉。沒有辦法只能繼續看源碼分析,看看從SSL握手完成到HTTP請求頭處理完成之前,Nginx到底幹了些什麼。在詳細看了這部分程式碼之後,一個在不同handler中多次出現的函數ngx_reusable_connection引起了我的注意。這個函數用於修改連接的reusable標記,並且ngx_cycle維護了一個resuable連接的隊列,那麼這個隊列是幹啥的呢?進一步探究發現,ngx_get_connection在獲取新連接的時候,如果空閑的連接不足,會嘗試重用部分reusable的連接(一次最多32個)。而nginx連接在完成SSL握手之後、接收到HTTP請求之前就是處於reusable狀態的。我們再次打開抓包文件一數,發現連續關閉的連接正好是31/32個左右,於是我們已經有八九成的把握就是因為這個原因導致的連接斷開,而且正好這種情況下我們使用版本的Nginx是沒有日誌的(高版本加了WARN級別日誌)。
復現問題
為了進一步證明就是這個原因導致的連接斷開,我嘗試構造場景復現問題,這個問題的關鍵在於worker進程的總連接數不足,但是只建立前端連接又是夠的,有很多連接停留在SSL握手完成又沒有開始處理HTTP請求頭的階段。當其他連接的請求嘗試建立後端連接時,就會把這些reusable連接踢掉。所以worker最大連接數需要大於前端連接數、小於前端連接數的兩倍。
因為我是用自己虛擬機簡單測試,客戶端用wrk設置了100個連接,nginx只配了1個worker,最大連接數是120(具體數值可能有點出入,因為已經過去有段時間了記得不太清楚了)。一測試成功復現了這個問題,抓包截圖如下:
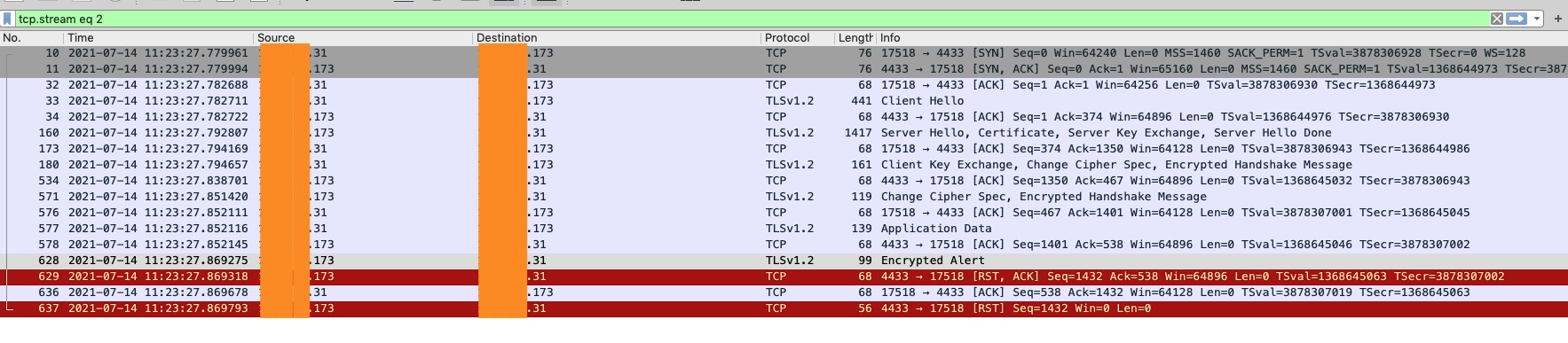
這是跟蹤的其中一個流,可以看到也是在SSL握手完成之後,收到了客戶端發送的應用數據,然後發送了Alert以及RST。順帶提一下,這裡後面還多了一個RST,這是因為連接關閉之後收到了客戶端的一個ACK。
再看下一個截圖,可以觀察到,在這兩個reusable連接被踢掉之後,立馬就往後端新建了兩個連接。

至此,問題的原因基本已經確認。直接原因就是因為worker連接數不足。
總結回顧
問題原因已經定位到,再回過頭看現場的測試配置。其實按照所有worker的連接總數來算,連接是夠的,而單個worker則是不夠的。但是因為其他幾個配置的間接作用導致了連接集中在了單個worker中。首先,因為系統版本較低不支援reuseport,只能依賴nginx自身進行進程間的連接分配。其次又配置了multi_accept,所以只要有已經就緒的TCP連接,worker進程就一直進行accept,造成單個worker進程的接收了大部分連接。這幾個因素結合在一起造成了最終的問題。歸根結底,還是因為測試人員對Nginx配置理解不夠深入導致的。
連接生命周期
在討論前面的問題時我們也看到了,Nginx中的連接是有幾個不同的狀態的,我們分成連接建立時和連接關閉時兩部分來看連接的生命周期。
連接建立
下面是連接建立時一個大致的調用關係圖,實際情況要比著複雜的多。任何一處都可能超時或出錯提前終止連接,碰到NGX_EAGAIN則可能多次調用同一個handler。
ngx_event_accept
|-- accept
|-- ngx_get_connection
+-- ngx_http_init_connection
|-- ngx_reusable_connection(1)
+-- ngx_http_ssl_handshake
|-- NGX_EAGAIN: ngx_reusable_connection(1)
|-- ngx_ssl_create_connection
|-- ngx_reusable_connection(0)
|-- ngx_ssl_handshake
+-- ngx_http_ssl_handshake_handler
|-- ngx_reusable_connection(1)
+-- ngx_http_wait_request_handler
|-- ngx_reusable_connection(0)
|-- ngx_http_create_request
+-- ngx_http_process_request_line
|-- ngx_http_read_request_header
|-- ngx_http_parse_request_line
+-- ngx_http_process_request_headers
|-- ngx_http_read_request_header
|-- ngx_http_parse_header_line
|-- ngx_http_process_request_header
+-- ngx_http_process_request
|-- Switch stat from reading to writing
+-- ngx_http_handler
|-- HTTP to HTTPS? certificate verify fail?
+-- ngx_http_core_run_phases
+-- ngx_http_proxy_handler
+-- ngx_http_read_client_request_body
首先,nginx是從accept才開始接手連接的處理,在此之前則完全是內核的行為。不過在初始化階段可以通過設置一些socket選項來改變其行為,大家比較熟知的有比如SO_REUSEPORT,TCP_DEFER_ACCEPT。前者允許多個socket綁定到在相同的地址埠對上,由內核在多個進程的socket間進行連接接收的負載均衡,後者則可以推遲連接就緒的時間,只有當收到客戶端發來的應用數據時才可以accept。
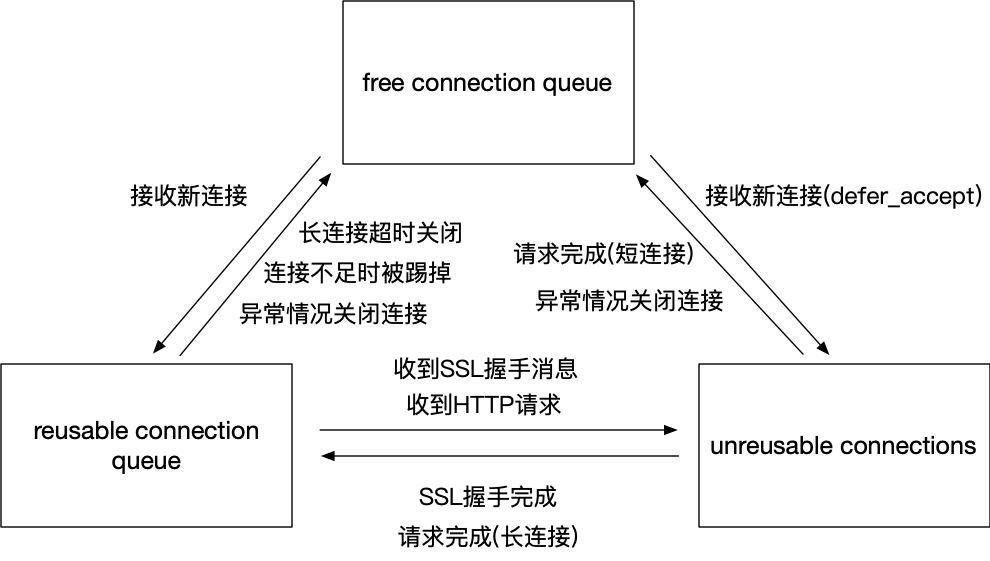
accept之後nginx會從空閑的連接中獲取一個,這個動作在ngx_get_connection中完成,然後進入HTTP初始化流程。我們這裡主要關注連接狀態的變化情況,它是通過ngx_resuable_connection函數進行修改。最初連接是處於free狀態的,進入ngx_http_ssl_handshake完成一些基本的初始化之後,連接設置定時器開始準備接收消息,此時的超時時間是post_accept_timeout,也就是配置項中的client_header_timeout,同步地連接進入reusable狀態。等到接收到SSL握手消息之後,會創建SSL連接,同步地nginx連接進入unreusable狀態。後續會進入握手流程,等到握手完成之後,連接又變成了reusable狀態,開始等待接收HTTP請求,此時的超時時間仍然是post_accept_timeout。直到接收到HTTP請求,連接就此進入unreusable狀態。一直到請求結束為止,狀態都不再變化。
連接關閉
接下來再來看下請求結束時的情況,如果是短連接的情況會進入ngx_http_close_request流程,釋放請求之後會關閉連接,連接變為free狀態被放入空閑隊列中。如果是長連接的情況則會進入ngx_http_set_keepalive流程,此時請求被釋放,但是連接進入reusable狀態,此時定時器的超時時間就是keepalive_timeout了。如果在超時時間內收到了新的請求,那麼連接又變為unreusable狀態,進入請求的處理流程;如果直到超時都沒有收到新請求,則會調用ngx_http_close_connection關閉連接,連接變為free狀態被放入空閑隊列中。
值得注意的是,連接變成reusable狀態時,肯定是處於等待什麼消息的狀態,同步地會有一個定時器存在。
ngx_http_finalize_request
+-- ngx_http_finalize_connection
|-- ngx_http_set_keepalive
| |-- ngx_http_free_request
| |-- ngx_reusable_connection(1)
| +-- ngx_http_keepalive_handler
| |-- ngx_http_close_connection
| |-- ngx_reusable_connection(0)
| |-- ngx_http_create_request
| +-- ngx_http_process_request_line
+-- ngx_http_close_request
|-- ngx_http_free_request
+-- ngx_http_close_connection
|-- ngx_ssl_shutdown
+-- ngx_close_connection
|-- ngx_reusable_connection(0)
|-- ngx_free_connection
+-- ngx_close_socket
為了更清晰地表示連接狀態的轉移情況,我們用一張圖來描述:
連接超時
在連接的各個階段都會伴隨著超時的存在,只要不是進程正在處理當前連接,總會有某個定時器管著當前連接。以HTTP階段為例,主要有以下這些超時:
- client_header_timeout (60s): 在這個時間內,這個請求頭必須接收完。
- client_body_timeout (60s):讀請求頭的超時時間,只是限制兩次連續操作之間的間隔
- send_timeout (60s):發送響應給客戶端的超時時間,同樣只是限制兩次連續操作之間的間隔
- proxy_connect_timeout (60s):與後端伺服器建立連接的超時
- proxy_send_timeout (60s):發送請求給代理伺服器的超時,只是限制兩次連續操作之間的間隔
- proxy_read_timeout (60s):從代理伺服器讀響應的超時,只是限制兩次連續操作之間的間隔
- keepalive_timeout (75s):長連接保持打開的時間。
- resolver_timeout (5s): 域名解析的超時時間
連接的超時控制,當然是為了防止「壞」的連接一直佔用系統資源。但是我們注意到,並不是所有超時都是限制總體的時間,很多超時都只是限制兩次連續操作之間的間隔。所以一個惡意的連接,其實還是可以做到長時間佔用一個連接的。比如客戶端發送請求體時,每次只發一個位元組,但是趕在服務端超時之前發送第二個位元組。對於這種情況,貌似沒有太好的避免辦法。不過我們可以通過限速等其他手段,限制惡意方佔用的連接個數,一定程度緩解了這個問題。

