從容器化到資源池化,數棧雲原生技術實踐探索之路
導讀:
近些年隨著雲計算和雲原生應用的興起,容器技術可以很好地解決許多問題,所以將大數據平台容器化是一種理想的方案。本文將結合袋鼠雲數棧在Flink on Kubernetes的實踐讓您對大數據平台容器化的操作和價值有初步的了解。
你可以看到👇👇👇
▫ Kubernetes如何解決Hadoop痛點
▫ 數棧在Flink on K8S的實踐
▫ 容器化之後的未來設想:資源池化
作者 / 雅澤、狗煥
編輯 / 向山
引言
在過去的很長一段時間,大數據領域中構建可擴展的分散式應用框架中,Apache Hadoop佔據的是絕對的統治地位。
目前絕大多數大數據平台都是基於Hadoop生態構建,使用YARN作為核心組件進行資源管理與資源調度,但是這些大數據平台普遍都會存在資源隔離性差、資源利用率低等問題,與此同時近些年隨著雲計算和雲原生應用的興起,容器技術可以很好地解決這些問題。
所以將大數據平台容器化是一種理想的方案,本文將結合袋鼠雲數棧在Flink on Kubernetes的實踐讓您對大數據平台容器化的操作和價值有初步的了解。
Hadoop痛點頻現,亟待解決
大數據平台顧名思義就是處理急速增長的實時、離線數據的大規模應用程式,所以設計大數據平台的解決方案的需要考慮的首要問題就是如何確定生產環境中大數據平台的部署架構,使得平台具有緊密聯繫數據、應用程式與基礎設施之間的能力。
Hadoop主要提供了三個關鍵功能:資源管理器(YARN)、數據存儲層(HDFS)、計算範式(MapReduce),市面上大多數大數據平台都是基於Hadoop生態構建的,但是這類型的平台會存在下列問題:
資源彈性不足
大數據系統的資源使用高峰是具有周期性的,不同業務線在一天中的高峰期是不一樣的,當業務壓力增大時,當前的大數據系統普遍缺乏資源彈性伸縮的能力,無法按需進行快速擴容,為了應對業務高峰只能預留出足夠的資源保證任務正常運行;
資源利用率低
存儲密集型的業務存儲資源使用較高而CPU使用率長期處於較低的水平,計算密集型的業務雖然CPU使用率相對較高但是存儲的使用率非常低,大量資源閑置;
資源隔離性差
從Hadoop2.2.0開始,YARN開始使用cgroup實現了CPU資源隔離,通過JVM提供的記憶體隔離機制來實現記憶體資源隔離,整體上來看YARN的資源隔離做的並不完善,會造成多個任務運行到同一個工作節點上時,不同任務會出現資源搶佔的情況。
Kubernetes風頭正勁,完美解決Hadoop痛點
Kubernetes是Google開源的生產級的容器編排系統,是建立在Google大規模運行生產工作負載方面的十幾年的經驗基礎上的,而且擁有一個龐大且快速增長的生態系統,伴隨著微服務、DevOps、持續交付等概念的興起和持續發酵,並依託與雲原生計算基金會(CNCF),Kubernetes保持著高速發展。
如下圖所示,Google過去五年對於Kubernetes和Apache Hadoop熱度統計結果展示表明市面上對Kubernetes的熱情逐漸高漲而對Hadoop熱度逐漸減退。
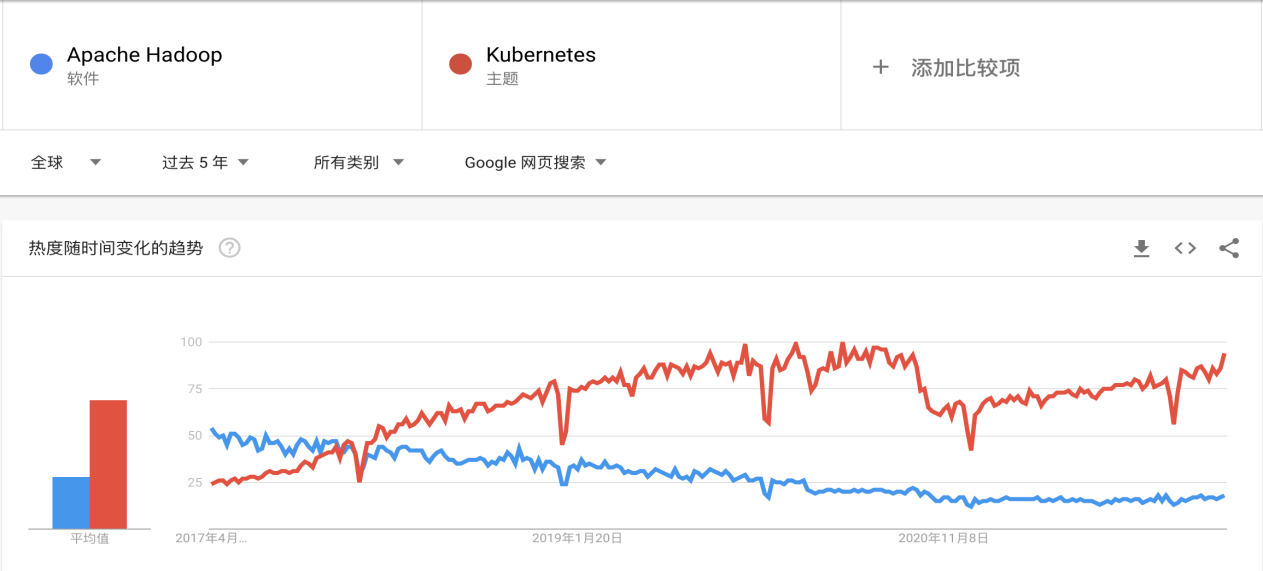
那麼,Kubernetes是如何解決Hadoop存在的痛點的呢,我們一一分析一下。
解決資源彈性不足
對於資源彈性不足的問題,Kubernetes本身就是設計為一個利用模組化架構來進行擴展的系統,對用戶來說,服務進行擴容只需要修改配置文件中容器的副本數或者是使用Pod水平自動擴縮(HPA),將應用擴縮容的複雜度交給Kubernetes控制可以極大減少人為介入的成本。HPA是基於CPU使用率、記憶體使用率或其他實時採集的性能指標自動擴縮ReplicationController、Deployment和ReplicaSet中的Pod數量。
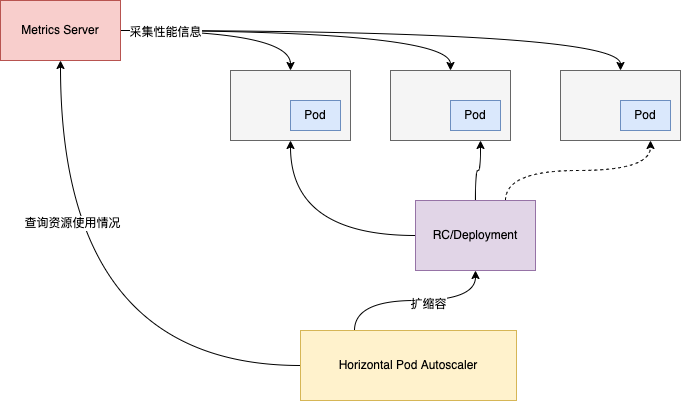
Kubernetes中的Metrics Server會持續採集所有Pod副本的性能指標資訊,HPA控制器通過Metrics Server的API獲取這些數據,並根據用戶設置的自動擴縮容規則計算目標Pod副本數量,當目標Pod數量與當前Pod數量不一致時,HPA控制器就向Pod的副本控制器發起擴縮容操作,調整Pod數量,完成擴縮容操作。
解決資源使用率低
對於資源使用率低的問題,一方面Kubernetes支援更加細粒度的資源劃分,這樣可以盡量做到資源能用盡用,最大限度的按需使用。另外一方面支援更加靈活的調度,並根據業務SLA的不同,業務高峰的不同,通過資源的混合部署來進一步提升資源使用率。
解決資源隔離性差
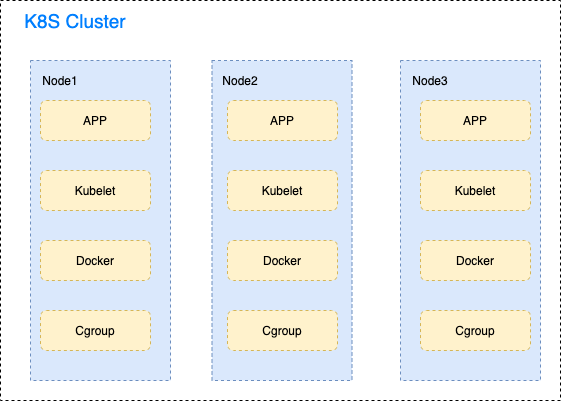
對於資源隔離性差的問題,容器技術本身是具有資源隔離的能力的,底層使用Linux namespace進行資源隔離,它將全局系統的資源包裹在一個抽象層中,使得在每個 namespace 內部的進程看起來自己都擁有一個獨立的全局資源。
同一個 namespace 下的資源變化對於同一 namespace 的進程是可見的,但是對於不同namespace下的進程是不可見的。為了能夠讓容器不佔用其它容器的資源(或者說確定每個容器的「硬體」配置),採用cgroups來限制單個進程或者多個進程所使用資源的機制,可以對 cpu,記憶體等資源實現精細化的控制。
Flink on K8S實踐,數棧研究小成
正因為大數據組件容器化優勢明顯,數棧使用的大數據計算和存儲組件均預期往容器化方向排布。
在數棧目前使用的眾多組件中,我們首先選擇在k8s上嘗試實踐的是數棧流計算引擎——Flink 。經過研究布設,現在數棧的流計算容器化轉換已經基本實現。接下來是一些Flink on K8S的經驗分享:
Flink on K8S概述
目前在K8S中執行Flink任務的方式有兩種,一種是Standalone,一種是原生模式:Flink native session 模式、Flink native per-job 模式,它們各自對應的優缺點如下:
Flink Standalone模式:
● 優點:優點是無需修改 Flink 源碼,僅僅只需預先定義一些 yaml 文件,集群就可以啟動,互相之間的通訊完全不經過 K8s Master;
● 缺點:缺點是資源需要預先申請無法動態調整。
Flink native session 模式:
● 優點:taskManager 的資源是實時的、按需進行的創建,對資源的利用率更高,所需資源更精準。
● 缺點:taskManager 是實時創建的,用戶的作業真正運行前, 與 Per Job集群一樣, 仍需要先等待 taskManager 的創建, 因此對任務啟動時間比較敏感的用戶,需要進行一定的權衡。
Flink native per-job 模式:
● 優點:資源按需申請,適合一次性任務,任務執行後立即釋放資源,保證了資源的利用率;
● 缺點:資源是在任務提交後開始創建,同樣意味著對於提交任務後對延時比較敏感的場景,需要一定的權衡;
數棧Flink Standalone on K8S實踐
接下來我們以standalone模式容器化為切入點介紹下我們的一些實踐。

我們通過自定義的資源對象來定義我們應用的相關部署屬性,然後將這個yaml文件和所需的配置文件以及鏡像打包上傳到easymanager平台(後續會將其開源)進行一鍵部署。這裡對於應用整體狀態的處理大致如下:
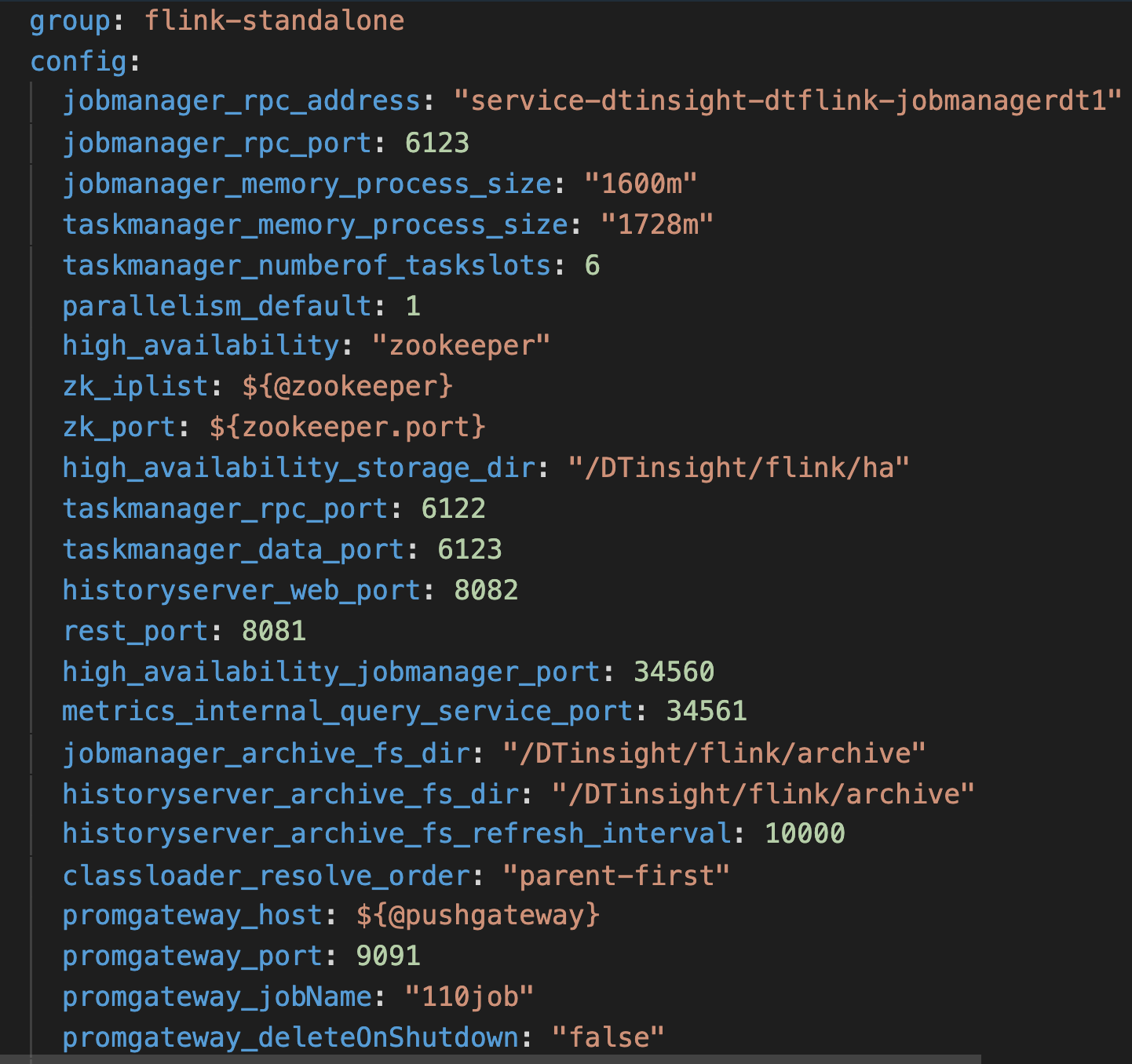
● 對於配置:這裡我們把應用的涉及到的狀態數據都提煉到應用的配置變成k8s中的configmap,通過該配置作為統一的修改入口。同時分離出jobmanager和taskmanager的配置使兩者對各自狀態進行維護互不干擾。
● 對於存儲:分離存儲狀態,可採用pvc來聲明我們所需要的存儲類型(storageclass),或者我們可以在鏡像中內置一個hdfs的client或者s3插件來直接對接客戶現場的環境,這裡我們是將hdfs client和s3的插件包封裝到了flink的鏡像中,然後通過上面提取出的配置來進行控制對應的存儲對接。
● 對於集群狀態資訊:我們在部署flink的時候我們會部署好基礎組件包,如zookeeper、redis、mysql等,同樣也能通過上面提取的配置參數進行修改對接外部基礎組件。
實踐如下:
1) 定義我們自定義資源描述:
flink社區擁有大量的插件供我們使用,通過這些插件我們能擴展一些需要的能力,但是將這些插件都打包到鏡像中,那麼這個鏡像體積勢必會變得非常大,這裡我們將這些插件單獨抽離出來做成一個單獨的基礎服務組件,然後通過我們的業務鏡像去引用這些基礎組件,在引用這些基礎組件後會以sidecar形式注入到我們的業務容器中完成目錄綁定,從而實現按需索取也減小了鏡像體積的大小。
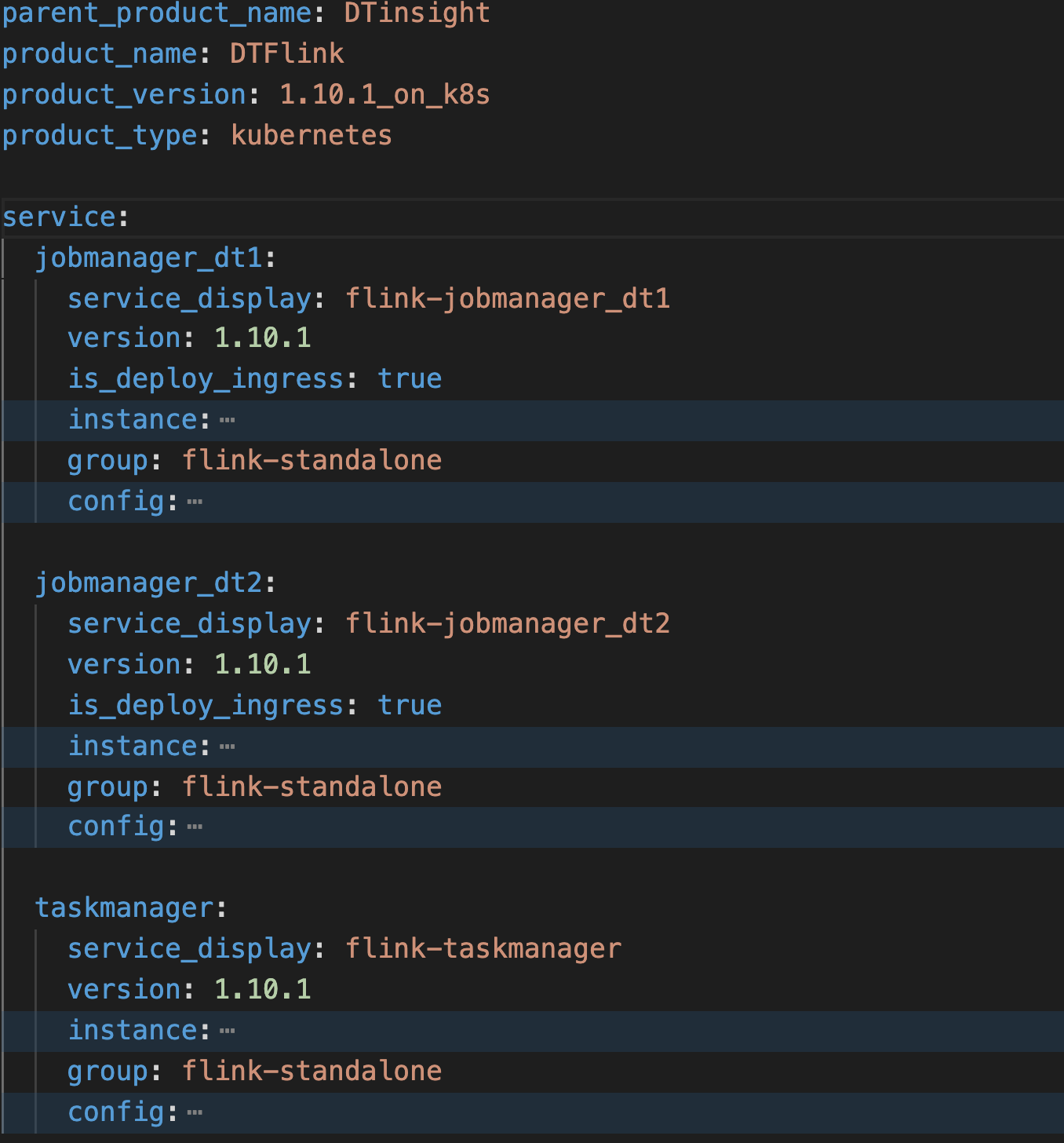
上面對應資源描述了在k8s上應用最基本的部署能力,這裡我們還需要將公共配置進行映射,然後將這些配置暴露到前端。通過這個統一的配置修改入口簡化了交付人員對配置文件的篩查和修改。
2) 自動化出包:
我們在定義好資源對象的描述後,根據定義的資源描述文件將需要的配置提取以及編寫應用需要的相關屬性,將這些內容放到一個yaml文件中,同時編寫dockerfile、啟動腳本、編寫jenkinsfile接入自動化出包流程,最後出包驗證。通過分工合作這樣一來就能將內部原先大量人工的操作全部自動流程化,提高效率。
3) 部署:
完成部署後的結果如下:
通過點擊「服務擴縮容」,我們可以一鍵擴縮taskmanager的計算資源:

然後我們可以通過k8s的ingress資源對象暴露的地址來訪問flink的ui進行後續flink集群的運維操作。

通過以上flink standalone容器化我們簡化了主機模式下flink的部署、資源管理劃分等問題。那麼對於應用日誌收集和監控,我們採用的是loki和prometheus的動態服務發現。
容器之後,數棧走向何方
儘管Kubernetes能夠解決傳統Hadoop生態存在的一些痛點問題,但是距離它能真正成為一個部署大數據應用切實可行的平台還是有很長的一段路要走的:比如為短生命周期與無狀態應用設計的容器技術、不同job之間缺少共享的持久化存儲以及大數據平台關心的調度、安全以及網路相關問題還需要更好的解決方案。現在,數棧正積极參与開源社區,幫助 Kubernetes 能成為部署大數據應用程式的實用選擇。
對於數棧而言,基於存算分離的設計理念,使用Kubernetes解決了計算資源彈性擴展的問題後,由於計算資源與存儲資源的分離,可能會出現計算性能降低、存儲的彈性無法保證等問題。未來我們會考慮在存儲層使用對象存儲,整體架構在計算和底層存儲之間加上一層快取(比如JuiceFS和Alluxio),存儲層選型在OpenStack Swift、Ceph、MinIO等成熟的開源方案中。
容器之後,我們並未停下腳步,關於未來我們有很多在考慮的設想,比如利用雲化或者雲原生技術統一管理資源池,實現大數系統產品、計算、存儲資源池化,實現全局化、集約化的調度資源等等,技術在迭代,我們的自我革新也從未停止。
開源項目技術交流
ChunJun
//github.com/DTStack/chunjun
//gitee.com/dtstack_dev_0/chunjun
Taier
//github.com/DTStack/Taier
//gitee.com/dtstack_dev_0/taier
MoleCule
//github.com/DTStack/molecule
//gitee.com/dtstack_dev_0/molecule
歡迎加入開源框架技術交流群
(釘釘群:30537511)


