深入理解Kafka核心設計及原理(五):消息存儲
轉載請註明出處://www.cnblogs.com/zjdxr-up/p/16127749.html
目錄:
5.1文件目錄布局
5.2消息壓縮
5.3日誌索引
5.4日誌文件及索引文件分段觸發條件
5.5日誌清理
5.6 磁碟存儲–頁快取/零拷貝技術
5.1文件目錄布局
如果分區規則設置得合理, 那麼所有的消息可以均勻地分布到不同的分區中, 這樣就可以實現水平擴展。 不考慮多副本的情況, 一個分區對應一個日誌(Log)。 為了防止Log過大,Kafka又引入了日誌分段(LogSegment)的概念,將Log切分為多個LogS egment, 相當於一個巨型文件被平均分配為多個相對較小的文件, 這樣也便於消息的維護和清理。 事實上, Log 和LogSegnient也不是純粹物理意義上的概念, Log在物理上只以文件夾的形式存儲, 而每個LogSegment對應於磁碟上的 一個日誌文件 和兩個索引文件, 以及可能的其他文件(比如以 ” . txnindex”為後綴的事務索引文件)。
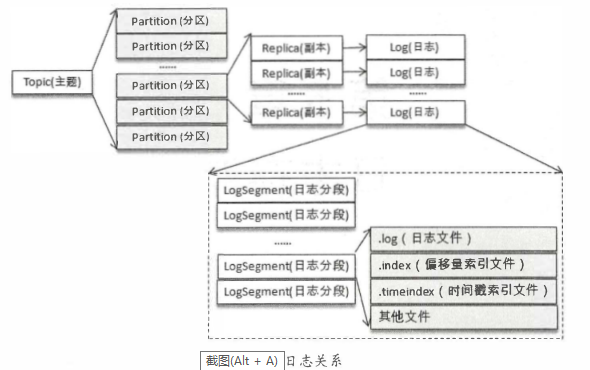
向Log中追加 消息時是順序寫入的, 只有最後 一 個LogSegment才能執行寫入操作,在此之 前所有的LogSegment都 不能寫入數據。
為了便於消息的檢索, 每個LogSegment中的日誌文件 (以 ” . log”為文件後綴)都有對應的兩個索引文件:偏移量 索引文件(以”.index”為文件後綴)和時間戳索引文件(以”. timeindex”為文件後綴) 。 每個ogSegment都有 一 個基準偏移量baseOffset, 用來表示當前LogSegment中第一 條消息的offset。 偏移量是一 個6 4位的長整型數, 日誌文件和兩個索引文件都是根據 基準偏移量(baseOffset)命名 的,名稱固定為20 位數字, 沒有達到的位數則用0填充。 比如第一 個LogSegment的基準偏移量為O, 對應的日誌文件為00000000000000000000.log。
5.2消息壓縮
常見的壓縮演算法是數據量越大壓縮效果越好, 一 條消息通常不會太大,這就導致壓縮效果並不是太好。 而Kafka實現的壓縮方式是將多條消息 一起進行壓縮,這樣可以保證較好的壓縮效果。 在 一般情況下,生產者發送 的壓縮數據在broker中也是保待壓縮狀態進行存儲的,消費者從服 務端獲取的也是壓縮的消息,消費者在處理消息之前才會解壓消息,這樣保待了端到端的壓縮。
Kafka日誌中使用哪種壓縮方式是通過參數compression.type來配置的, 默認值為”producer”, 表示保留生產者使用的壓縮方式。這個參數還可以配置為”gz ip” “snappy” “lz4″,分別對應GZ IP、 SNAPPY、 LZ 4這3種壓縮演算法。如果參數compression.type配置為”uncompressed” , 則表示不壓縮。壓縮率越小,壓縮效果越好。
5.3日誌索引
每個日誌分段文件對應了兩個索引文件,主要用來提高查找消息的效率。偏移量索引文件用來建立消息偏移量( offset )到物理地址之間的映射關係,方便快速定位消息所在的物理文件位置;時間戳索引文件則根據指定的時間戳( timestamp )來查找對應的偏移量小資訊。
Kafka 中的索引文件以稀疏索引( sparse index )的方式構造消息的索引,它並不保證每個消息在索引文件中都有對應的索引 I頁 。 每當寫入一定量(由broker 端參數log.index.interval.bytes 指定,默認值為 4096 ,即 4KB )的消息時,偏移量索引文件和時間戳索引文件分別增加一個偏移量索引項和時間戳索引項,增大或減小 log.index.interval.bytes的值,對應地可以增加或縮小索引項的密度。
Kafka 中的索引文件以稀疏索引( sparse index )的方式構造消息的索引,它並不保證每個消息在索引文件中都有對應的索引 I頁 。 每當寫入一定量(由broker 端參數log.index.interval.bytes 指定,默認值為 4096 ,即 4KB )的消息時,偏移量索引文件和時間戳索引文件分別增加一個偏移量索引項和時間戳索引項,增大或減小 log.index.interval.bytes的值,對應地可以增加或縮小索引項的密度。
5.4日誌文件及索引文件分段觸發條件
日誌分段文件達到一定的條件時需要進行切分,那麼其對應的索引文件也需要進行切分。日誌分段文件切分包含以下幾個條件,滿足其一 即可 。 (1) 當前日誌分段文件的大小超過了broker 端參數 log.segment.bytes 配置的值。log.segment.bytes 參數的默認值為 1073741824 ,即 lGB 。 (2)當前日誌分段中消息的最大時間戳與當前系統的時間戳的差值大於log.roll .ms或 log.roll.hours 參數配置的值。如果同時配置了 log.roll.ms 和 log.roll.hours 參數,那麼 log.roll.ms 的優先順序高 。 默認情況下,只配置了 log.ro ll.h ours 參數,其值為 168,即 7 天。 (3)偏移量索引文件或時間戳索引文件的大小達到 broker 端參數 log. index.size .max.bytes 配置的值。 log.index. size .max. bytes 的默認值為 10485760 ,即 l0MB 。 (4)追加的消息的偏移量與當前日誌分段的偏移量之間的差值大於 Integer.MAX_VALUE,即要追加的消息的偏移量不能轉變為相對偏移量( offset – baseOffset > Integer.MAX_VALUE )。
5.5日誌清理
Kafka 將 消息存儲在磁碟中,為了 控制磁碟佔用空間的不斷增加就需要對消息做一 定的清理操作。 Kafka 中 每 一個分區副本都對應 一個 Log, 而Log又可以分為多個日誌分段,這樣也便於日誌的清理操作。 Kafka提供了兩種日誌清理策略。 (1)日誌刪除(LogRetention) : 按照一 定的保留策略直接刪除不符合條件的日誌分段。 (2)日誌壓縮 (LogCompaction) : 針對每個消息的key進行整合, 對千有相同 key的不同value 值, 只保留 最後 一個版本。 我們可以通過broker端參數log.cleanup.policy來設置 日誌清理策略,此參數的默認值為”delete ” , 即採用日誌刪除的清理策略。 如果要採用日誌壓縮的清理策略, 就需要將log.cleanup.po且cy設置為”compact”, 並且還需要將log.cleaner. enable (默認值為true )設定為true。 通過將log.cleanup.policy參數 設置為”delete,compact” , 還可以同時支援日誌刪除和日誌壓縮兩種策略。日誌清理的粒度可以控制到主題級別, 比如log.cleanup.policy 對應的主題級別的參數為cleanup.policy
5.6 磁碟存儲–頁快取/零拷貝技術
頁快取
頁快取是作業系統實現的一種主要的磁碟快取, 以此用來減少對磁碟I/0 的操作。 具體來說, 就是把磁碟中的數據快取到記憶體中, 把對磁碟的訪間變為對記憶體的訪問。 為了彌補性能上的差異, 現代作業系統越來越「 激進地」 將記憶體作為磁碟快取, 甚至會非常樂意將所有可用的記憶體用作磁碟快取, 這樣當記憶體回收時也幾乎沒有性能損失, 所有對於磁碟的讀寫也將經由統一的快取。 當一個進程準備讀取磁碟上的文件內容時, 作業系統會先查看待讀取的數據所在的頁(page)是否在頁快取(pagecache)中, 如果存在(命中)則直接返回數據, 從而避免了對物理磁碟的I/0操作;如果沒有命中, 則作業系統會向磁碟發起讀取請求並將讀取的數據頁存入頁快取, 之後再將數據返回給進程。 同樣,如果 一個進程需要將數據寫入磁碟, 那麼作業系統也會檢測數據對應的頁是否在頁快取中, 如果不存在, 則會先在頁快取中添加相應的頁, 最後將數據寫入對應的頁。 被修改過後的頁也就變成了臟頁, 作業系統會在合適的時間把臟頁中的 數據寫入磁碟, 以保持數據的一致性。
零拷貝
除了消息順序追加、頁快取等技術,Kafka 還使用 零拷 貝( Zero-Copy )技術來進一步提升性能 。所謂的零拷貝是指將數據直接從磁碟文件複製到網卡設備中,而不需要經由應用程式之手 。零拷貝大大提高了應用程式的性能,減少了內核和用戶模式之間的上下文切換 。對 Linux作業系統而言,零拷貝技術依賴於底層的sendfile() 方法實現 。對應於Java 語言,Fi leChannal.transferTo()方法的底層實現就是 sendfile()方法 。
零拷貝技術通過 DMA (Direct Memory Access) 技術將文件內容複製到內核模式下的 Read Buffer 中。零拷貝是針對內核模式而言的, 數據在內核模式下實現了零拷貝。

