Docker 核心知識回顧
Docker 核心知識回顧
最近公司為了提高項目治理能力、提升開發效率,將之前的CICD項目擴展成devops進行項目管理。開發人員需要對自己的負責的項目進行流水線的部署,包括寫Dockerfile 對自己的服務製作服務鏡像。之前看過的東西,一段時間不用現在突然用起來還有些生疏。此篇對之前的Docker知識進行回顧加深。
對於docker 基本使用命令不再提及,遇到命令忘記或者不知道含義的時候可以使用 help 來進行查看。
基本架構
Docker 採用的是經典的C/S架構,包括客戶端 和 服務端兩大 核心組件。

Containers-shim:是containerd的子進程,為runc容器提供支援,也是容器內進程的 根進程
Dockerfiel
這裡主要說一下Dockerfile 的編寫注意的事項:
-
EXPOSE:只是申明鏡像內監聽埠,並不會完成自動映射。
-
ENV:當一條EVN指令 中同時為多個環境變數賦值 並且 值也是從環境變數中讀取,會為變數都賦值後才更新
ENV key1 = valu1
ENV key1= valu2
ENV key2 = ${key1}
此時key1=valu2,key2=valu1
-
Context: 因為Docker是 C/S 架構的,在編寫完Dockerfile 使用build 命令創建鏡像的時候會將Dockerfile 所在路徑下的數據作為上下文,傳輸給 服務端來創建鏡像。所以如果我們Dockerfile同級目錄下有多個文件,最好使用.dockerignore 來進行忽略,防止過多的數據發送到 docker服務端。
-
ADD\COPY : 都支援 go 語言格式的正則表達式。還有要注意路徑的問題。
因為dockerfile 可以多步驟創建,所以最好 進行單一職責的劃分,製作的鏡像省略掉中間的環境,這樣可以精簡最終鏡像的大小。
命名空間(重要)
命名空間是(namespace)是linux 內核的一個強大 特性。
作業系統中,包括內核,文件系統、網路、進程號、用戶號、進程間通訊 等資源都是進程間 直接共享的。想要虛擬化,那麼除對 記憶體、cpu、網路IO等進行限制分割外,還需要實現文件系統、網路、PID、UID、IPC 等相互隔離。前面的好做限制,關鍵是後面的 文件系統、網路之類的如何隔離,這就需要系統的支援,也就是命名空間的引入了。
-
進程命名空間(較為重要):
每個進程命名空間有一套自己的進程號管理方法,
我們從 前面 基本架構 可以看到,他們的進程是進行繼承的。
子空間對於父親空間是可見,父空間對子空間不可見
linux 通過進程命名空間管理進程號,對於同一進程,在不同命名空間中,看到的進程號不一樣。
$ ps -ef|grep docker root 3393 1 0 Jan18 ? 0:43:02 /usr/bin/dcokerd .. root 3398 3393 0 Jan18 ? 0:34:32 docker-containerd ...我們在創建一個新的容器,執行 sleep 命令,然後在看看容器的 進程號(注意查看 父進程號)
$ docker run --name test -d linux sleep 9999 $ ps -ef|grep docker root 21535 3398 0 0:57 ? docker-containerd-shim....然後我們在 宿主機 查看新建容器的進程,也是 docker-containerd-shim 進程
$ ps -ef|grep sleep 9999 root 21569 21535 0 06:57 ? sleep 9999重點:我們在容器內 查看進程
$ docker exec -it 3a bash -c 'ps -ef' UID PID PPID C STME TTY TIME CMD root 1 0 0 06:57 ? 00:00:00 sleep 9999可以使用 pstree 命令,查看到完整的進程樹
-
IPC命名空間:
容器中 進程交互 還是使用linux 進程間的交互方法,包括訊號量、消息隊列。同一個IPC命名空間,進程可以彼此可見,不同的則無法訪問。
-
網路命名空間(重點)
有了進程間的命名空間,不用命名空間的進程訊號可以相互隔離,但是,網路埠還是公用的,所以可以使用網路命名空間。
docker 採用虛擬網路設備,將不用命名空間的網路設備連接到一起。(默認網橋)
docker 可以使用四種網路模式:
-
Host :和主機公用一個網路,容器沒有虛擬的網卡,沒有獨立的ip,和主機的網路是一樣的。(但是文件之類的還是隔離的)
-
Container模式:和其他已存在的容器共享一個 Network Namespace, 不是和主機共享。
-
None模式:放在自己容器的網路內部中,外部訪問不到,內部也訪問不到外部。容器內部只能使用loopback網路設備不會再有其他網路資源。只能使用127.0.0.1的本機網路
-
Bridge模式:容器獨立的使用 network Namespace,並鏈接到docker0虛擬網卡,通過docker0網橋以及Iptables nat表配置與宿主機通訊;bridge模式是Docker默認的網路設置
當Docker server啟動時,會在主機上創建一個名為docker0的虛擬網橋,
此主機上啟動的Docker容器會連接到這個虛擬網橋上。
虛擬網橋的工作方式和物理交換機類似,這樣主機上的所有容器就通過交換機連在了一個二層網路中。
接下來就要為容器分配IP了,
Docker會從RFC1918所定義的私有IP網段中,選擇一個和宿主機不同的IP地址和子網分配給docker0,
連接到docker0的容器就從這個子網中選擇一個未佔用的IP使用。
如一般Docker會使用172.17.0.0/16這個網段,並將172.17.0.1/16分配給docker0網橋(在主機上使用ifconfig命令是可以看到docker0的,可以認為它是網橋的管理介面,在宿主機上作為一塊虛擬網卡使用)。
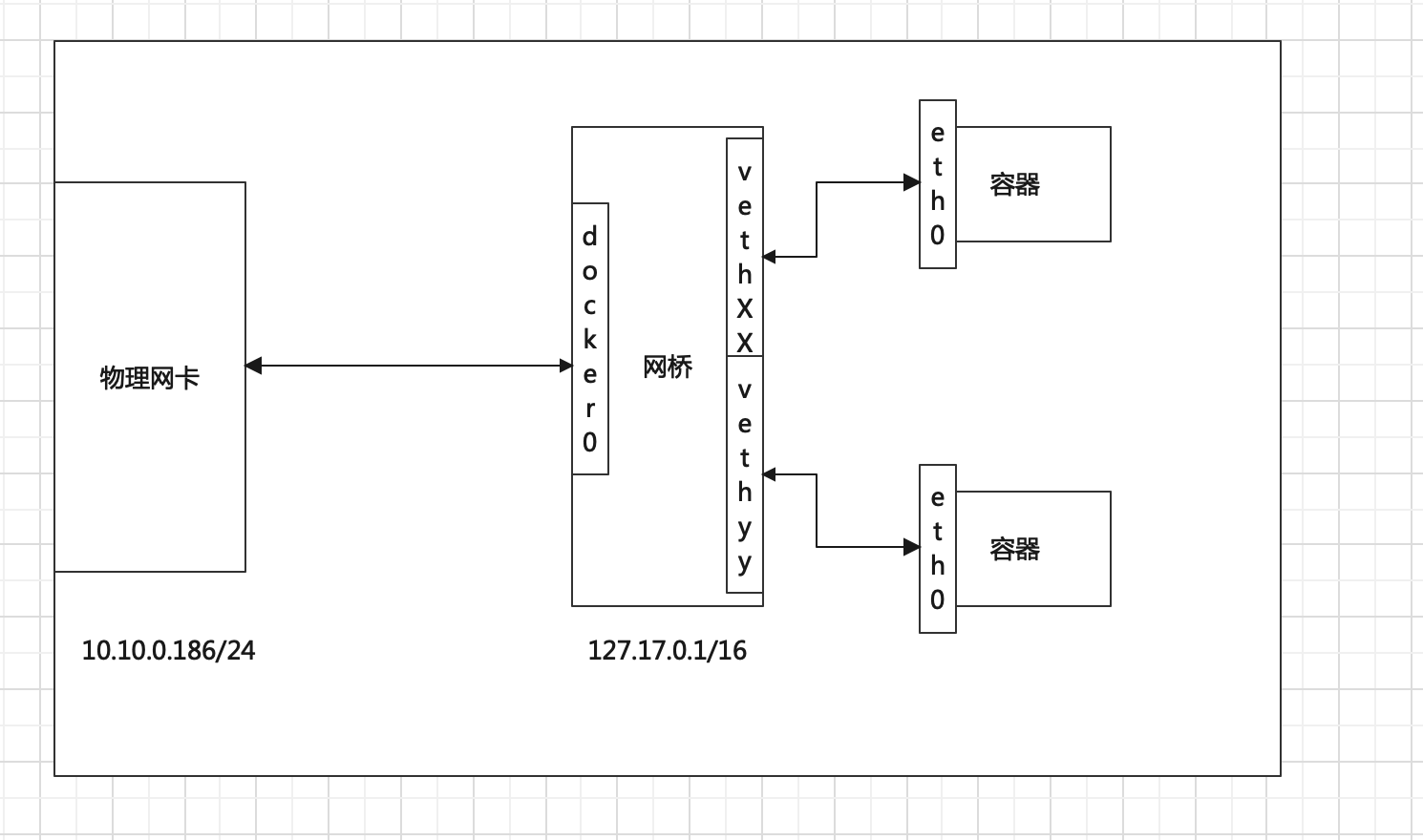
這裡容器的訪問控制 主要通過linux的 iptables 防火牆軟體來控制的,
-
容器間的訪問,這裡是需要兩個方面的支援
-
網路拓撲是否已經聯通(默認都鏈接到docker0上一般都是互通的)
-
本地系統的防火牆軟體iptables 是否允許訪問通過,這取決於防火牆的規則
-
訪問所有埠
當啟動docker ,默認會添加一條『允許』轉發策略到iptables的 forward 鏈上,通過配置 — icc=true|false 參數控制(啟動docker 手動指定 iptables規則,不會影響 宿主機的iptables規則)
-
訪問指定埠
可以通過 –link=container_name:allas 指定。(兩個容器之間通過添加一條 ACCEPT規則)
-
-
-
對於容器訪問外部。
轉發過程:我們可以從上圖看到,容器將請求通過 veth pair 介面給到docker 網橋,然後網橋通過docker0 發送到宿主機物理網卡上(其實dock er0 對應的就是一個網卡的埠) 網橋就是和交換機類似的作用。
- 這裡請求要到外部,需要宿主機進行輔助轉發,在宿主機器內查看是否允許 轉發
sudo sysctl net.ipv4.ip_forward - forward =1 則是轉發,0則是關閉轉發。
轉發IP 變化:外部訪問內部肯定不止直接訪問 容器的IP了,需要進行源地址映射 SNAT(Source NAT),修改為宿主機 IP地址 10.0.2.2
具體操作:內部容器請求到達到主機向外部發送請求前,主機的ipstable 偽裝源地址,ipstable 的 nat 表添加規則,將其源地址改為 主機地址 10.0.2.2(這個規則適用所用從docker 網橋的請求ip)
#iptables -t nat -A POSTROUTING -s 127.17.0.1/16 -o eth1 -j SNAT --to-source 10.10.0.186 ## 解釋規則:就是給nat表中 POSTROUTING 鏈 添加一條規則:從 s 過來的網段 (127.17.0.1/16) 都進行 snat 動作,即轉換ip 為10.10.0.186上邊是針對企業中常應用的,但在家庭當中,很少有固定地址,一般都是動態地址,也就是說,出去的跳板是變動的,這樣剛才所設置的規則就不行了,不過現在可以通過一個叫做 MASQUERADE—- 地址偽裝來解決,即 snat 換成 MASQUERADE。
- 這裡請求要到外部,需要宿主機進行輔助轉發,在宿主機器內查看是否允許 轉發
-
外部訪問內部容器。
我們通過 容器啟動時映射埠命令 -p 來添加容器到本機的埠映射,這其實也是在本地的 ipstable 添加 nat 規則,將外部IP 進行目標地址DNAT,將目標地址修改為容器內部ip 地址。
這裡nat表設計兩條鏈:
- PREROUTING 鏈 負責包到 網路介面時,改寫器目的地址,其中的規則流量都到 docker 鏈,
- Docker 鏈將所有不是從docker0 進來的包(非本機器的產生的包),同時目標 埠為 docker0 映射的物理埠號(或者容器映射的埠號),修改目標地址為 172.2.0.2,目標埠使用 容器映射埠。
-

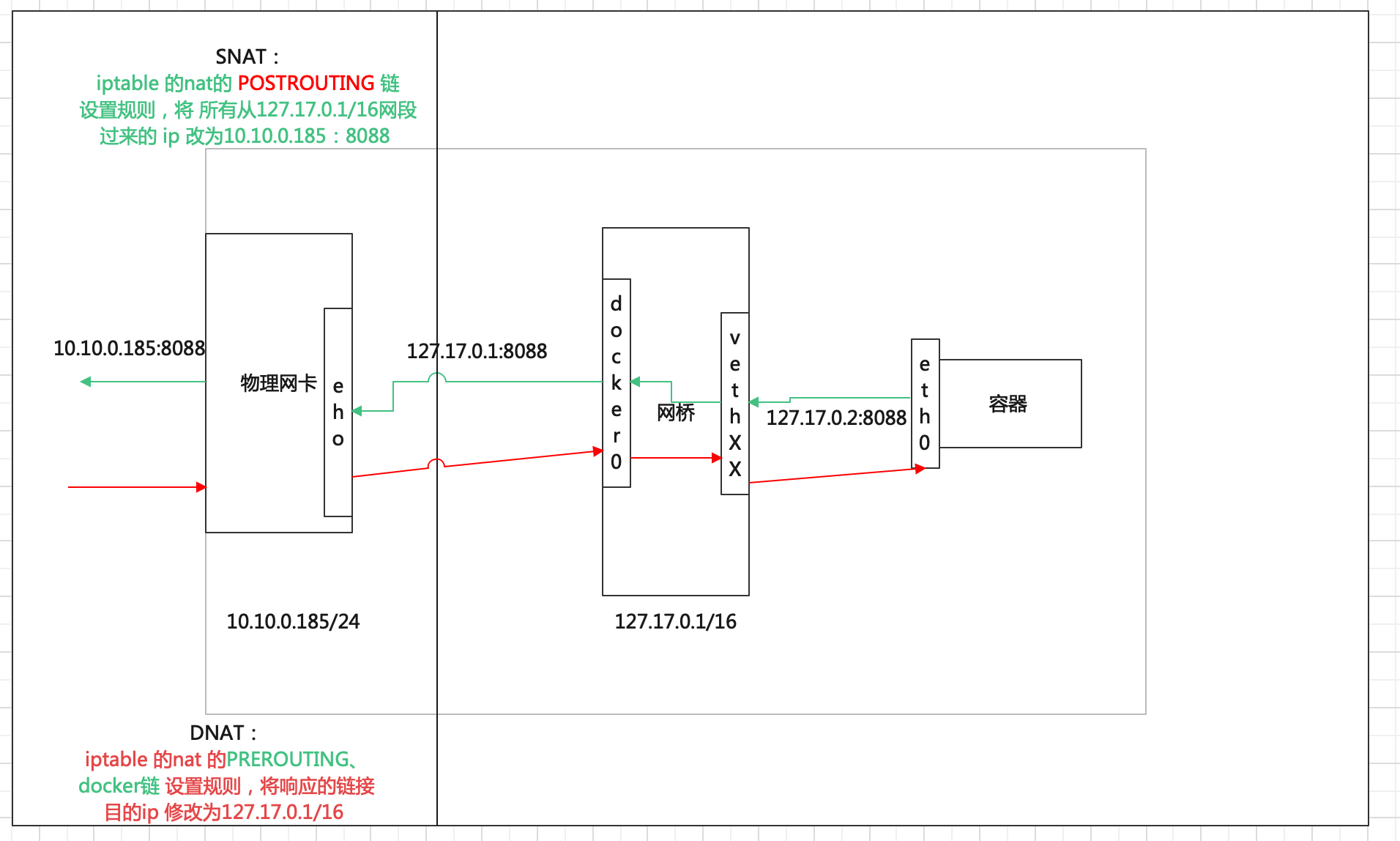
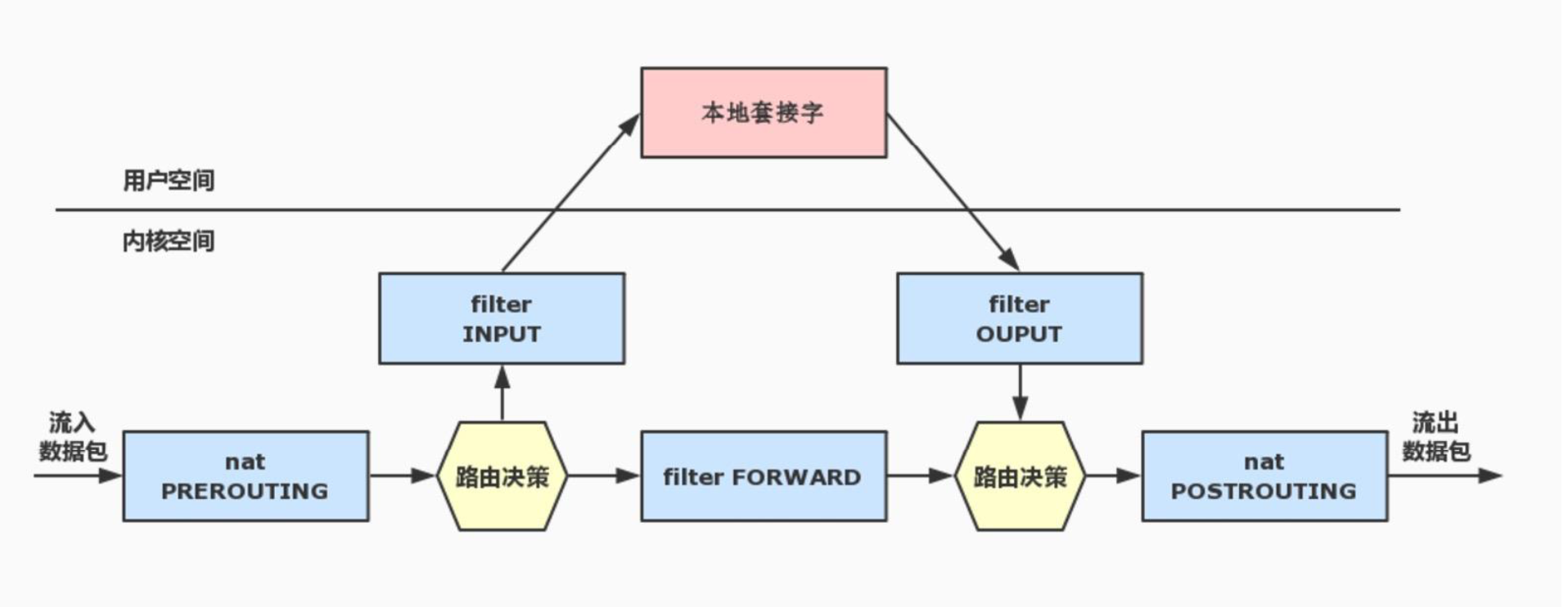
該圖片來源於網路【//blog.csdn.net/beanewself/article/details/78317626】
報文流向:
流入本機:PREROUTING --> INPUT-->用戶空間進程 流出本機:用戶空間進程-->OUTPUT--> POSTROUTING 轉發:PREROUTING --> FORWARD --> POSTROUTING
不過還是建議,自定義一個網橋,這樣方便自己管理容器的網路 。(使用openvswitch)
DNS
-
docker 服務啟動後會默認啟用一個 內嵌的 dns 服務,來自動解析同一個網路中的容器主機名和地址,如果無法解析,則通過容器內的dns 相關配置進行解析。
-
Docker啟動容器時,會從宿主機 複製/etc/resolv.conf 文件,並刪除掉無法鏈接的Dns 伺服器。
-
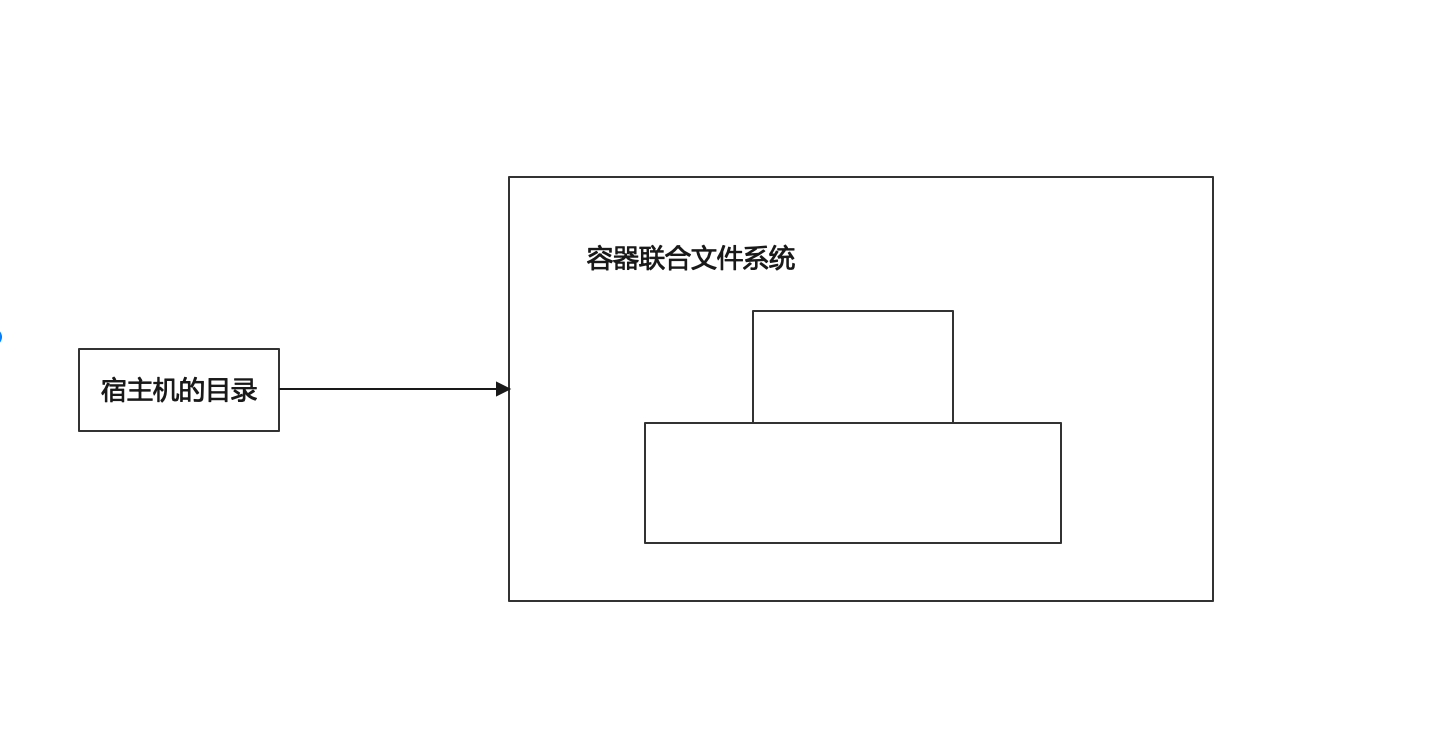
掛載命名空間
掛載命名空間允許 不同命名空間的進程看到的本地文件位於宿主機的不同路徑下,每個命名空間的進程看到的目錄是彼此隔離的。
這裡有 聯合文件系統的知識,網路上很多講解,這裡我自己的理解為:
Docker 容器內部使用 聯合文件系統,我們宿主機上看到的還是一個文件目錄,只不過在docker 容器中相互隔離了。
這裡要注意一點,對於可寫層要讀取下面的對象,如果 較為深層的對象 數據太大,意味著較差的IO性能。所以對於IO敏感型,推薦將容器通過 volume 方式掛載。
-
UTS命名空間
UTS 命名空間 允許每個容器擁有獨立的主機名和域名,從而可以虛擬出一個獨立的主機名 和網路空間的環境
-
用戶命名空間
每個容器可以有不同的用戶 和 組ID,也就是說,可以在容器內使用特定的內部用戶 執行程式,而非本地系統存在的用戶
控制組
這個是linux 內核的一個特性,主要用來對共享資源進行隔離、限制、審計。
-
資源限制:可以將組設置一定對記憶體限制,記憶體子系統可以對對進程組 設定一個記憶體使用上線
-
優先順序:通過優先順序 讓一些組 優先得到更多的cpu 資源
-
資源審計:用來統計系統實際上把多少資源用到合適的目的上。
-
隔離:為組隔離命名空間,使得另一個組不會看到進程、網路等
-
控制:執行掛起、恢復 和重啟
用戶可以 /sys/fs/cgroup/memory/docker/目錄下看到Docker組應用的各種限制項,用戶可以修改這些值,來進行限制docker 應用資源。
compose
作為Docker 三劍客之一,它最主要的功能是服務編排。
這裡只是簡單的介紹 和 說明一些常用的語法
我們通過Dockerfile 可以快速的編寫一個應用的鏡像,但是我們的服務往往是 多個服務協作進行的:
比如前後端分離:前端一個服務、後端一個服務、再有一個資料庫。。。
所以如果一個一個的寫dockerfile 那麼部署的時候也要進行先後配置,這顯然不是Devpos初衷,我們想要的是一鍵部署,所以這就用到compose了。
我們可以使用compose 將各個服務進行依賴編寫,然後同時部署多個容器。(在compose中,這叫做服務棧)
- 任務:一個容器被稱為一個任務,任務有個獨一無二的ID
- 服務:某個相同鏡像的容器副本(一個前端,對應多個後端,多個後端就是副本)
- 服務棧:多個服務組成,相互配合完成特定業務。
使用一個web 應用作為例子:
version: '3' ##使用的compose版本
services: ## 定義一個服務
mall-admin: ## 服務容器配置資訊
image: mall/mall-admin:1.0-SNAPSHOT ##鏡像,也可通過build 構建鏡像,
container_name: mall-admin
ports: ##容器埠
- 8080:8080
volumes: ##任務掛載路徑
- /mydata/app/mall-admin/logs:/var/logs
- /etc/localtime:/etc/localtime
environment: ##啟動入口
- 'TZ="Asia/Shanghai"'
external_links: ## 鏈接,通過這個可以做任務之間的依賴,容器之間可以訪問。
- mysql:db #可以用db這個域名訪問mysql服務
- nacos-registry:nacos-registry #可以用nacos-registry這個域名訪問nacos服務
mysql:
image: mysql:5.7
container_name: mysql
command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
restart: always
environment:
MYSQL_ROOT_PASSWORD: root #設置root帳號密碼
ports:
- 3306:3306
volumes:
- /mydata/mysql/data/db:/var/lib/mysql #數據文件掛載
- /mydata/mysql/data/conf:/etc/mysql/conf.d #配置文件掛載
- /mydata/mysql/log:/var/log/mysql #日誌文件掛載
swarm
我們上面解決了服務棧,也就是服務之間的依賴問題,但是我們現在都是微服務,需要的是一個服務部署多個機器,如果有上百個服務,成千的機器群,那我們部署排查,那不得忙的不可開交了么。所以docker 推出了swarm 來解決這個問題,就是對服務集群部署的解決。
Swarm 集群是一組被統一管理起來的docker 主機,集群是swarm 所管理的 對象,這些主機通過docker引擎的swarm模式相互溝通,
說白了,swarm是定義一個服務 部署多少個節點(部署在多少個主機上),然後對每個節點的容器服務進行監控管理的。這才是docker 真正運用在企業生產的地方。
Kubernetes
和swarm 擁有相同 的能力,只不過它更優秀,是Google公司開源的項目。
用戶可以將配置模版提交之後,kubernetes 會自動管理(包括部署、發布、伸縮、更新)應用容器來維護指定狀態。實現了十分高的可靠性 ,用戶無需關心細節。
他的核心概念:每個對象包括三大屬性:元數據、規範、狀態。通過這三個屬性,用戶可以定義讓某個對象處於給定的狀態。這些對象存儲在 Etcd高可用鍵值存儲對象上(就是key-value形式,這個是分散式的存儲,採用簡潔的Raft共識演算法(這裡可以看之前的文章)),他自己本身也用的Raft共識演算法來保證 一致性。
這裡很重要,但是越來越覺得開發和運維分不開了,這完全是要開發做了運維的工作啊。。。目前用不到,之前嘗試搭建過環境,直接把我雲主機給干崩了(3個4G記憶體的機器),等以後用的時候可以在深入的看用法。
參考源:
- 《Docker技術入門與實戰第三版》:機械工業出版社
- 網路部落格【//blog.csdn.net/beanewself/article/details/78317626】


