數據倉庫(5)數倉Kimball與Inmon架構的對比
數據倉庫主要有四種架構,Kimball的DW/BI架構、獨立數據集市架構、輻射狀企業資訊工廠Inmon架構、混合Inmon與Kimball架構。不過不管是那種架構,基本上都會使用到維度建模。
<b>Kimball的DW/BI架構</b>,可以參考這篇文章 數據倉庫(4)基於維度建模的KimBall架構。
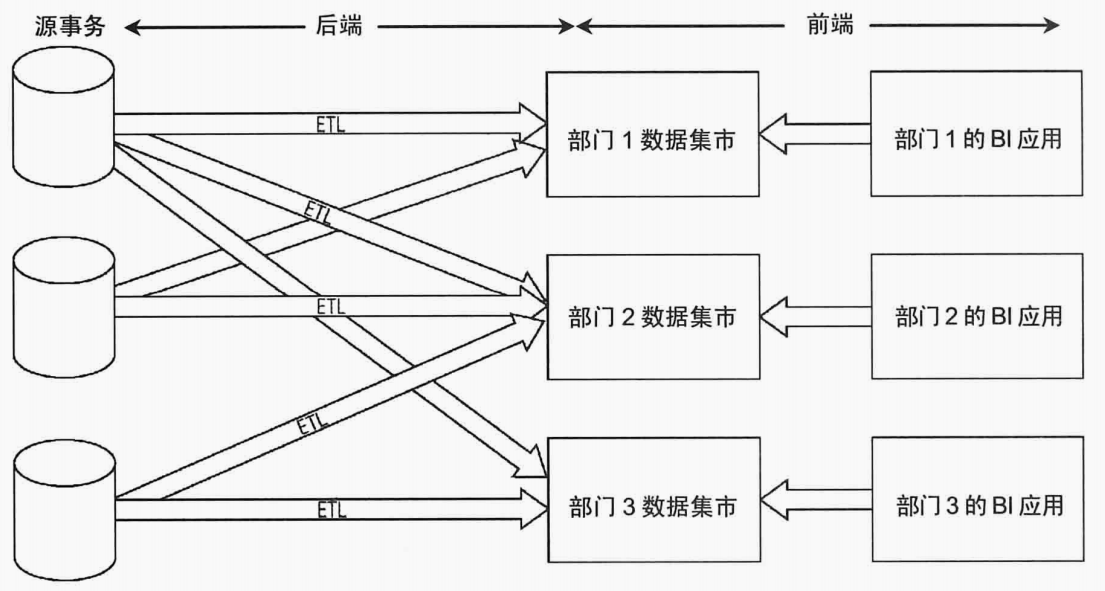
<b>獨立數據集市架構</b>,採用這種架構的數據倉庫,數據以部門為基礎來部署,不考慮企業級別的資訊共享和集成。也就是各個部門各自按照需要,各自在數據源同步數據,按照各自的標準,對數據進行處理。這種實際上就是沒有架構,會造成分析數據的冗餘存儲,計算資源的浪費,會導致每一個統計部門統計口徑的不統一,也就會導致因為數據口徑不一致導致長時間的對數據。
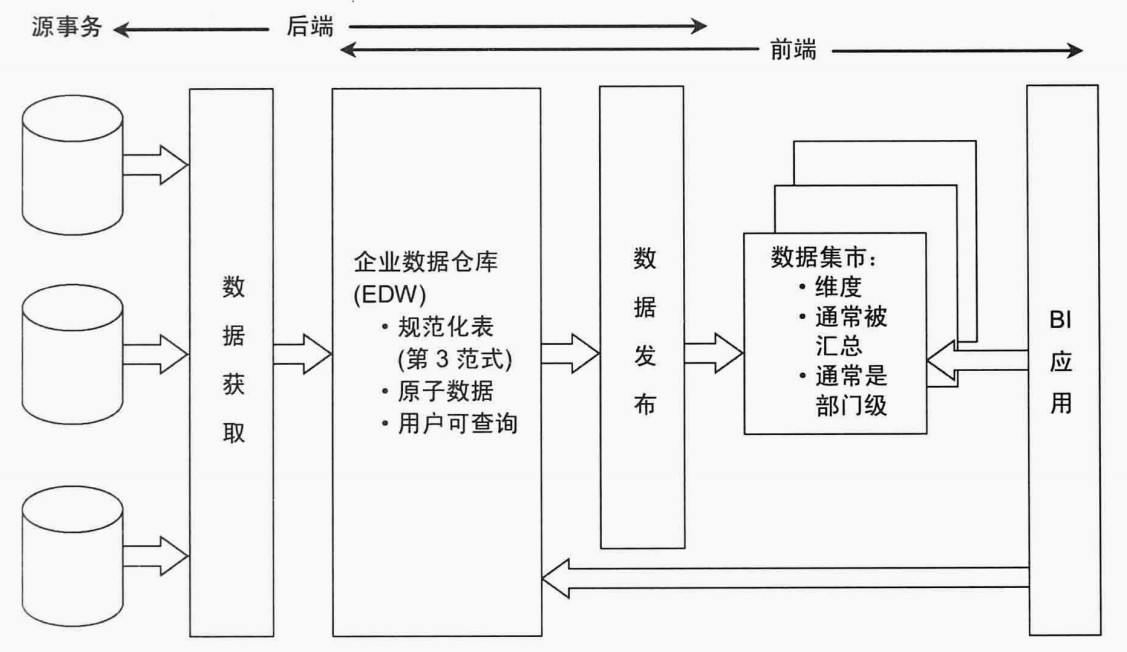
<b>輻射狀企業資訊工廠Inmon架構</b>,數據從操作型數據源中獲取,在ETL中進行處理,獲得的原子數據保存在滿足第三範式的資料庫中,這種規範化,原子數據的倉庫就是企業資訊工廠Inmon架構。Inmon架構與Kimball架構的差別之一就是,Inmon的數據倉庫是規範化的,而Kimball架構是基於維度建模的星型模型。
<b>混合Inmon與Kimball架構</b>,這種就是將Kimball與Inmon兩種架構進行嫁接,抽取過來的數據,存放在規範化的數據倉庫中,然後在這個的基礎之上抽取基於維度建模的數據展現,開發給數據分析人員等。
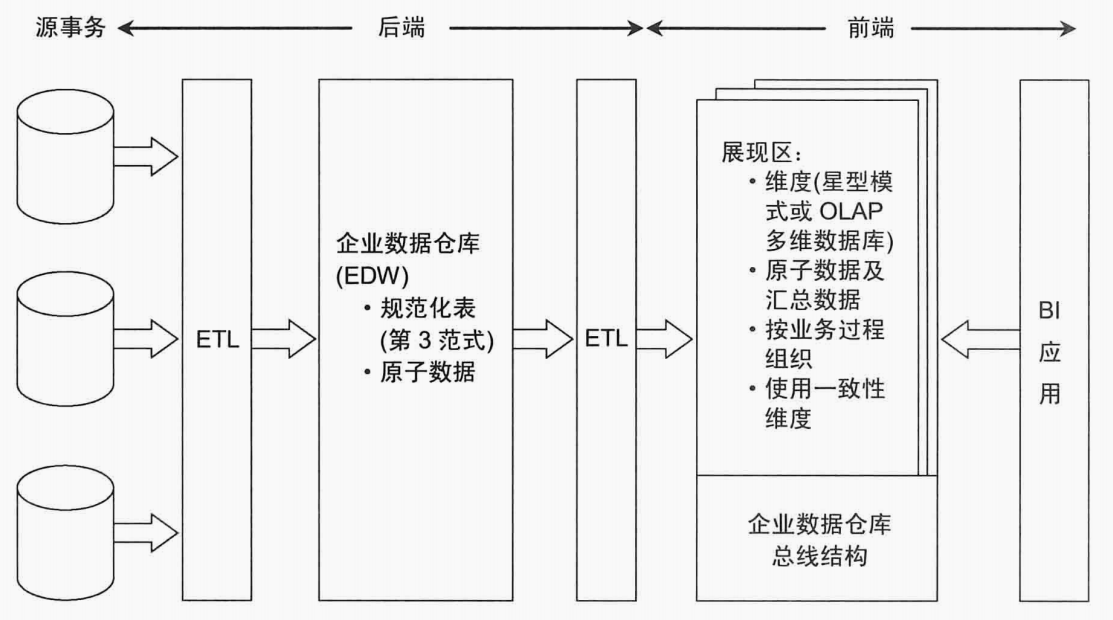
在經典的理論認為,混合Inmon與Kimball架構是最好的方式。這種方法可以將數據規範化,然後通過維度建模,以一種比較簡單的方式開發給分析人員。但是這種方式適合比較傳統的行業,或者政府單位,這種業務發展緩慢的模式,如果是互聯網企業,特別是創業型團隊,業務還在快速的迭代中,使用維度建模需要花費很長的前期準備工作,而且擴展性不好,使用Kimball維度建模是比較合適的。
Kimball 模式從流程上看是是自底向上的,即從數據集市到數據倉庫再到數據源(先有數據集市再有數據倉庫)的一種敏捷開發方法。對於Kimball模式,數據源每每是給定的若干個資料庫表,數據較為穩定可是數據之間的關聯關係比較複雜,須要從這些OLTP中產生的事務型數據結構抽取出分析型數據結構,再放入數據集市中方便下一步的BI與決策支援。所以<b>KimBall是根據需求來確定需要開發ETL哪些數據。</b>
Inmon 模式從流程上看是自頂向下的,即從數據源到數據倉庫再到數據集市的(先有數據倉庫再有數據市場)一種瀑布流開發方法。對於Inmon模式,數據源每每是異構的,好比從自行定義的爬蟲數據就是較為典型的一種,數據源是根據最終目標自行訂製的。這裡主要的數據處理工做集中在對異構數據的清洗,包括數據類型檢驗,數據值範圍檢驗以及其餘一些複雜規則。在這種場景下,數據沒法從stage層直接輸出到dm層,必須先經過ETL將數據的格式清洗後放入dw層,再從dw層選擇須要的數據組合輸出到dm層。在Inmon模式中,並不強調事實表和維度表的概念,由於數據源變化的可能性較大,須要更增強調數據的清洗工做,從中抽取實體-關係。immon是將<b>整個數據倉庫規劃好,統一按照範式建模進行開發</b>。
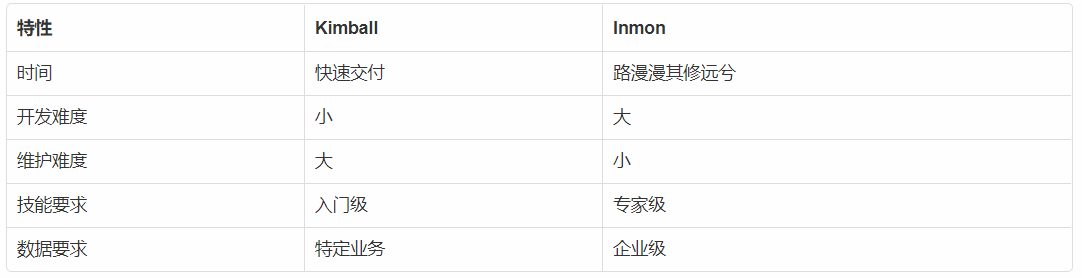
下面是兩種架構的優劣比較。
> 參考文章: 數據倉庫(5)數倉Kimball與Inmon架構的對比


