Citus 分散式 PostgreSQL 集群 – SQL Reference(查詢分散式表 SQL)
- 2022 年 3 月 30 日
- 筆記
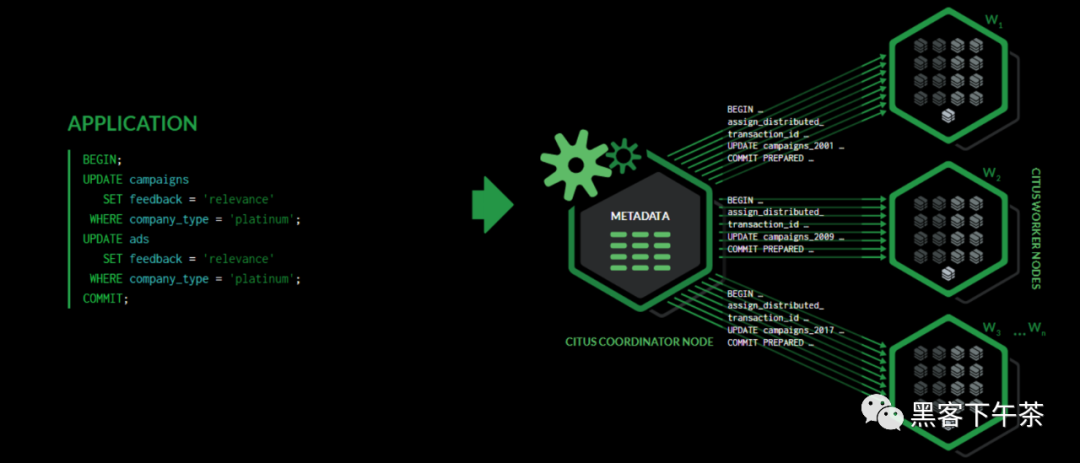
如前幾節所述,Citus 是一個擴展,它擴展了最新的 PostgreSQL 以進行分散式執行。這意味著您可以在 Citus 協調器上使用標準 PostgreSQL SELECT 查詢進行查詢。 Citus 將並行化涉及複雜選擇、分組和排序以及 JOIN 的 SELECT 查詢,以加快查詢性能。在高層次上,Citus 將 SELECT 查詢劃分為更小的查詢片段,將這些查詢片段分配給 worker,監督他們的執行,合併他們的結果(如果需要,對它們進行排序),並將最終結果返回給用戶。
在以下部分中,我們將討論您可以使用 Citus 運行的不同類型的查詢。
聚合函數
Citus 支援和並行化 PostgreSQL 支援的大多數聚合函數,包括自定義用戶定義的聚合。 聚合使用以下三種方法之一執行,優先順序如下:
-
當聚合按表的分布列分組時,
Citus可以將整個查詢的執行下推到每個worker。 在這種情況下支援所有聚合,並在worker上並行執行。(任何正在使用的自定義聚合都必須安裝在worker身上。) -
當聚合沒有按表的分布列分組時,
Citus仍然可以根據具體情況進行優化。Citus對sum()、avg()和count(distinct)等某些聚合有內部規則,允許它重寫查詢以對worker進行部分聚合。例如,為了計算平均值,Citus從每個worker那裡獲得一個總和和一個計數,然後coordinator節點計算最終的平均值。特殊情況聚合的完整列表:avg, min, max, sum, count, array_agg, jsonb_agg, jsonb_object_agg, json_agg, json_object_agg, bit_and, bit_or, bool_and, bool_or, every, hll_add_agg, hll_union_agg, topn_add_agg, topn_union_agg, any_value, var_pop(float4), var_pop(float8), var_samp(float4), var_samp(float8), variance(float4), variance(float8) stddev_pop(float4), stddev_pop(float8), stddev_samp(float4), stddev_samp(float8) stddev(float4), stddev(float8) tdigest(double precision, int), tdigest_percentile(double precision, int, double precision), tdigest_percentile(double precision, int, double precision[]), tdigest_percentile(tdigest, double precision), tdigest_percentile(tdigest, double precision[]), tdigest_percentile_of(double precision, int, double precision), tdigest_percentile_of(double precision, int, double precision[]), tdigest_percentile_of(tdigest, double precision), tdigest_percentile_of(tdigest, double precision[])
-
最後的手段:從
worker中提取所有行並在coordinator節點上執行聚合。 如果聚合未在分布列上分組,並且不是預定義的特殊情況之一,則Citus會退回到這種方法。 它會導致網路開銷,並且如果要聚合的數據集太大,可能會耗盡coordinator的資源。(可以禁用此回退,見下文。)
請注意,查詢中的微小更改可能會改變執行模式,從而導致潛在的令人驚訝的低效率。例如,按非分布列分組的 sum(x) 可以使用分散式執行,而 sum(distinct x) 必須將整個輸入記錄集拉到 coordinator。
SELECT sum(value1), sum(distinct value2) FROM distributed_table;
為避免意外將數據拉到 coordinator,可以設置一個 GUC:
SET citus.coordinator_aggregation_strategy TO 'disabled';
請注意,禁用 coordinator 聚合策略將完全阻止 「類型三」(最後的手段) 聚合查詢工作。
Count (Distinct) 聚合
Citus 以多種方式支援 count(distinct) 聚合。
如果 count(distinct) 聚合在分布列上,Citus 可以直接將查詢下推給 worker。
如果不是,Citus 對每個 worker 運行 select distinct 語句,
並將列表返回給 coordinator,從中獲取最終計數。
請注意,當 worker 擁有更多 distinct 項時,傳輸此數據會變得更慢。
對於包含多個 count(distinct) 聚合的查詢尤其如此,例如:
-- multiple distinct counts in one query tend to be slow
SELECT count(distinct a), count(distinct b), count(distinct c)
FROM table_abc;
對於這類查詢,worker 上產生的 select distinct 語句本質上會產生要傳輸到 coordinator 的行的 cross-product(叉積)。
為了提高性能,您可以選擇進行近似計數。請按照以下步驟操作:
- 在所有
PostgreSQL實例(coordinator和所有worker)上下載並安裝hll擴展。有關獲取擴展的詳細資訊,請訪問 PostgreSQL hll github 存儲庫。 - 只需從
coordinator運行以下命令,即可在所有PostgreSQL實例上創建hll擴展CREATE EXTENSION hll; - 通過設置
Citus.count_distinct_error_rate配置值啟用計數不同的近似值。 此配置設置的較低值預計會提供更準確的結果,但需要更多時間進行計算。我們建議將其設置為0.005。SET citus.count_distinct_error_rate to 0.005;在這一步之後,
count(distinct)聚合會自動切換到使用HLL,而無需對您的查詢進行任何更改。 您應該能夠在表的任何列上運行近似count distinct查詢。
HyperLogLog 列
某些用戶已經將他們的數據存儲為 HLL 列。在這種情況下,他們可以通過調用 hll_union_agg(hll_column) 動態匯總這些數據。
估計 Top N 個項
通過應用 count、sort 和 limit 來計算集合中的前 n 個元素很簡單。 然而,隨著數據大小的增加,這種方法變得緩慢且資源密集。使用近似值更有效。
Postgres 的開源 TopN 擴展可以快速獲得 「top-n」 查詢的近似結果。該擴展將 top 值具體化為 JSON 數據類型。TopN 可以增量更新這些 top 值,或者在不同的時間間隔內按需合併它們。
基本操作
在查看 TopN 的實際示例之前,讓我們看看它的一些原始操作是如何工作的。首先 topn_add 更新一個 JSON 對象,其中包含一個 key 被看到的次數:
select topn_add('{}', 'a');
-- => {"a": 1}
-- record the sighting of another "a"
select topn_add(topn_add('{}', 'a'), 'a');
-- => {"a": 2}
該擴展還提供聚合以掃描多個值:
-- for normal_rand
create extension tablefunc;
-- count values from a normal distribution
SELECT topn_add_agg(floor(abs(i))::text)
FROM normal_rand(1000, 5, 0.7) i;
-- => {"2": 1, "3": 74, "4": 420, "5": 425, "6": 77, "7": 3}
如果 distinct 值的數量超過閾值,則聚合會丟棄那些最不常見的資訊。
這可以控制空間使用。閾值可以由 topn.number_of_counters GUC 控制。它的默認值為 1000。
現實例子
現在來看一個更現實的例子,說明 TopN 在實踐中是如何工作的。讓我們提取 2000 年的亞馬遜產品評論,並使用 TopN 快速查詢。首先下載數據集:
curl -L //examples.citusdata.com/customer_reviews_2000.csv.gz | \
gunzip > reviews.csv
接下來,將其攝取到分散式表中:
CREATE TABLE customer_reviews
(
customer_id TEXT,
review_date DATE,
review_rating INTEGER,
review_votes INTEGER,
review_helpful_votes INTEGER,
product_id CHAR(10),
product_title TEXT,
product_sales_rank BIGINT,
product_group TEXT,
product_category TEXT,
product_subcategory TEXT,
similar_product_ids CHAR(10)[]
);
SELECT create_distributed_table('customer_reviews', 'product_id');
\COPY customer_reviews FROM 'reviews.csv' WITH CSV
接下來我們將添加擴展,創建一個目標表來存儲 TopN 生成的 json 數據,並應用我們之前看到的 topn_add_agg 函數。
-- run below command from coordinator, it will be propagated to the worker nodes as well
CREATE EXTENSION topn;
-- a table to materialize the daily aggregate
CREATE TABLE reviews_by_day
(
review_date date unique,
agg_data jsonb
);
SELECT create_reference_table('reviews_by_day');
-- materialize how many reviews each product got per day per customer
INSERT INTO reviews_by_day
SELECT review_date, topn_add_agg(product_id)
FROM customer_reviews
GROUP BY review_date;
現在,我們無需在 customer_reviews 上編寫複雜的窗口函數,只需將 TopN 應用於 reviews_by_day。 例如,以下查詢查找前五天中每一天最常被評論的產品:
SELECT review_date, (topn(agg_data, 1)).*
FROM reviews_by_day
ORDER BY review_date
LIMIT 5;
┌─────────────┬────────────┬───────────┐
│ review_date │ item │ frequency │
├─────────────┼────────────┼───────────┤
│ 2000-01-01 │ 0939173344 │ 12 │
│ 2000-01-02 │ B000050XY8 │ 11 │
│ 2000-01-03 │ 0375404368 │ 12 │
│ 2000-01-04 │ 0375408738 │ 14 │
│ 2000-01-05 │ B00000J7J4 │ 17 │
└─────────────┴────────────┴───────────┘
TopN 創建的 json 欄位可以與 topn_union 和 topn_union_agg 合併。 我們可以使用後者來合併整個第一個月的數據,並列出該期間最受好評的五個產品。
SELECT (topn(topn_union_agg(agg_data), 5)).*
FROM reviews_by_day
WHERE review_date >= '2000-01-01' AND review_date < '2000-02-01'
ORDER BY 2 DESC;
┌────────────┬───────────┐
│ item │ frequency │
├────────────┼───────────┤
│ 0375404368 │ 217 │
│ 0345417623 │ 217 │
│ 0375404376 │ 217 │
│ 0375408738 │ 217 │
│ 043936213X │ 204 │
└────────────┴───────────┘
有關更多詳細資訊和示例,請參閱 TopN readme。
百分位計算
在大量行上找到精確的百分位數可能會非常昂貴,
因為所有行都必須轉移到 coordinator 以進行最終排序和處理。
另一方面,找到近似值可以使用所謂的 sketch 演算法在 worker 節點上並行完成。 coordinator 節點然後將壓縮摘要組合到最終結果中,而不是讀取完整的行。
一種流行的百分位數 sketch 演算法使用稱為 t-digest 的壓縮數據結構,可在 tdigest 擴展中用於 PostgreSQL。Citus 集成了對此擴展的支援。
以下是在 Citus 中使用 t-digest 的方法:
- 在所有
PostgreSQL節點(coordinator和所有worker)上下載並安裝tdigest擴展。tdigest 擴展 github 存儲庫有安裝說明。 - 在資料庫中創建
tdigest擴展。在coordinator上運行以下命令:CREATE EXTENSION tdigest;coordinator也會將命令傳播給worker。
當在查詢中使用擴展中定義的任何聚合時,Citus 將重寫查詢以將部分 tdigest 計算下推到適用的 worker。
T-digest 精度可以通過傳遞給聚合的 compression 參數來控制。
權衡是準確性與 worker 和 coordinator 之間共享的數據量。
有關如何在 tdigest 擴展中使用聚合的完整說明,請查看官方 tdigest github 存儲庫中的文檔。
限制下推
Citus 還儘可能將限制條款下推到 worker 的分片,以最大限度地減少跨網路傳輸的數據量。
但是,在某些情況下,帶有 LIMIT 子句的 SELECT 查詢可能需要從每個分片中獲取所有行以生成準確的結果。 例如,如果查詢需要按聚合列排序,則需要所有分片中該列的結果來確定最終聚合值。 由於大量的網路數據傳輸,這會降低 LIMIT 子句的性能。 在這種情況下,如果近似值會產生有意義的結果,Citus 提供了一種用於網路高效近似 LIMIT 子句的選項。
LIMIT 近似值默認禁用,可以通過設置配置參數 citus.limit_clause_row_fetch_count 來啟用。
在這個配置值的基礎上,Citus 會限制每個任務返回的行數,用於在 coordinator 上進行聚合。 由於這個 limit,最終結果可能是近似的。增加此 limit 將提高最終結果的準確性,同時仍提供從 worker 中提取的行數的上限。
SET citus.limit_clause_row_fetch_count to 10000;
分散式表的視圖
Citus 支援分散式表的所有視圖。有關視圖的語法和功能的概述,請參閱 CREATE VIEW 的 PostgreSQL 文檔。
請注意,某些視圖導致查詢計劃的效率低於其他視圖。
有關檢測和改進不良視圖性能的更多資訊,請參閱子查詢/CTE 網路開銷。
(視圖在內部被視為子查詢。)
Citus 也支援物化視圖,並將它們作為本地表存儲在 coordinator 節點上。
連接(Join)
Citus 支援任意數量的表之間的 equi-JOIN,無論它們的大小和分布方法如何。
查詢計劃器根據表的分布方式選擇最佳連接方法和 join 順序。
它評估幾個可能的 join 順序並創建一個 join 計劃,該計劃需要通過網路傳輸最少的數據。
共置連接
當兩個表共置時,它們可以在它們的公共分布列上有效地 join。co-located join(共置連接) 是 join 兩個大型分散式表的最有效方式。
注意
確保表分布到相同數量的分片中,並且每個表的分布列具有完全匹配的類型。嘗試加入類型略有不同的列(例如 `int` 和 `bigint`)可能會導致問題。
引用表連接
引用表可以用作「維度」表,
以有效地與大型「事實」表連接。因為引用表在所有 worker 上完全複製,
所以 reference join 可以分解為每個 worker 上的本地連接並並行執行。
reference join 就像一個更靈活的 co-located join 版本,
因為引用表沒有分布在任何特定的列上,並且可以自由地 join 到它們的任何列上。
引用表也可以與 coordinator 節點本地的表連接。
重新分區連接
在某些情況下,您可能需要在除分布列之外的列上連接兩個表。
對於這種情況,Citus 還允許通過動態重新分區查詢的表來連接非分布 key 列。
在這種情況下,要分區的表由查詢優化器根據分布列、連接鍵和表的大小來確定。
使用重新分區的表,可以確保只有相關的分片對相互連接,從而大大減少了通過網路傳輸的數據量。
通常,co-located join 比 repartition join 更有效,因為 repartition join 需要對數據進行混洗。
因此,您應該儘可能通過 common join 鍵來分布表。
更多
- Citus 分散式 PostgreSQL 集群 – SQL Reference(創建和修改分散式表 DDL)
- Citus 分散式 PostgreSQL 集群 – SQL Reference(攝取、修改數據 DML)

