python數據分析與挖掘實戰————銀行分控模型(幾種演算法模型的比較)
- 2022 年 3 月 29 日
- 筆記
- python數據挖掘與分析實戰
一、神經網路演算法:
1 import pandas as pd 2 from keras.models import Sequential 3 from keras.layers.core import Dense, Activation 4 import numpy as np 5 # 參數初始化 6 inputfile = 'C:/Users/76319/Desktop/bankloan.xls' 7 data = pd.read_excel(inputfile) 8 x_test = data.iloc[:,:8].values 9 y_test = data.iloc[:,8].values 10 inputfile = 'C:/Users/76319/Desktop/bankloan.xls' 11 data = pd.read_excel(inputfile) 12 x_test = data.iloc[:,:8].values 13 y_test = data.iloc[:,8].values 14 15 model = Sequential() # 建立模型 16 model.add(Dense(input_dim = 8, units = 8)) 17 model.add(Activation('relu')) # 用relu函數作為激活函數,能夠大幅提供準確度 18 model.add(Dense(input_dim = 8, units = 1)) 19 model.add(Activation('sigmoid')) # 由於是0-1輸出,用sigmoid函數作為激活函數 20 model.compile(loss = 'mean_squared_error', optimizer = 'adam') 21 # 編譯模型。由於我們做的是二元分類,所以我們指定損失函數為binary_crossentropy,以及模式為binary 22 # 另外常見的損失函數還有mean_squared_error、categorical_crossentropy等,請閱讀幫助文件。 23 # 求解方法我們指定用adam,還有sgd、rmsprop等可選 24 model.fit(x_test, y_test, epochs = 1000, batch_size = 10) 25 predict_x=model.predict(x_test) 26 classes_x=np.argmax(predict_x,axis=1) 27 yp = classes_x.reshape(len(y_test)) 28 29 def cm_plot(y, yp): 30 from sklearn.metrics import confusion_matrix 31 cm = confusion_matrix(y, yp) 32 import matplotlib.pyplot as plt 33 plt.matshow(cm, cmap=plt.cm.Greens) 34 plt.colorbar() 35 for x in range(len(cm)): 36 for y in range(len(cm)): 37 plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') 38 plt.ylabel('True label') 39 plt.xlabel('Predicted label') 40 return plt 41 cm_plot(y_test,yp).show()# 顯示混淆矩陣可視化結果 42 score = model.evaluate(x_test,y_test,batch_size=128) # 模型評估 43 print(score)
結果以及混淆矩陣可視化如下:
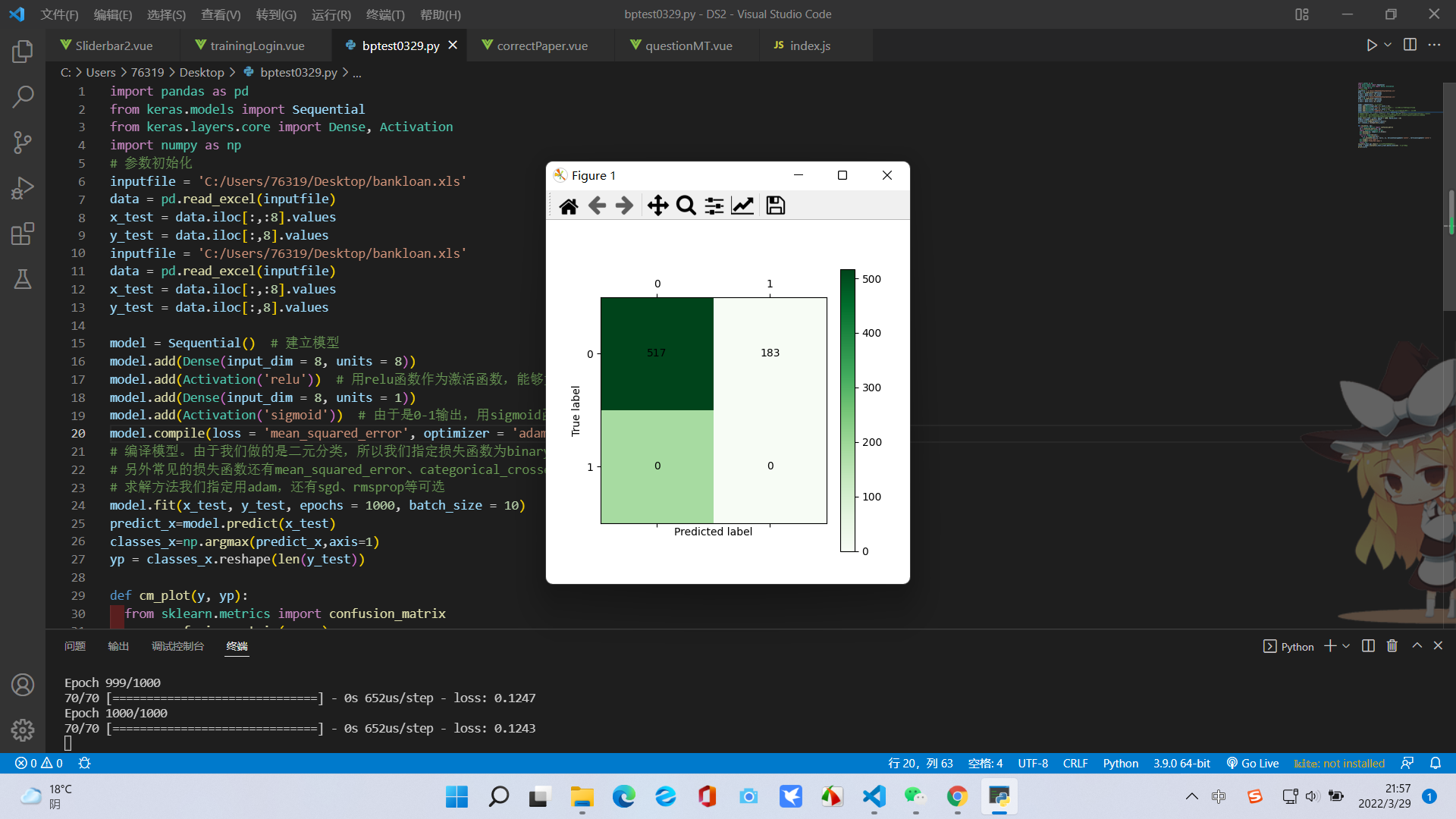
二、然後我們使用邏輯回歸模型進行分析和預測:
import pandas as pd inputfile = 'C:/Users/76319/Desktop/bankloan.xls' data = pd.read_excel(inputfile) print (data.head()) X = data.drop(columns='違約') y = data['違約'] from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) model = LogisticRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test) print(y_pred) from sklearn.metrics import accuracy_score score = accuracy_score(y_pred, y_test) print(score) def cm_plot(y, y_pred): from sklearn.metrics import confusion_matrix #導入混淆矩陣函數 cm = confusion_matrix(y, y_pred) #混淆矩陣 import matplotlib.pyplot as plt #導入作圖庫 plt.matshow(cm, cmap=plt.cm.Greens) #畫混淆矩陣圖,配色風格使用cm.Greens,更多風格請參考官網。 plt.colorbar() #顏色標籤 for x in range(len(cm)): #數據標籤 for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐標軸標籤 plt.xlabel('Predicted label') #坐標軸標籤 return plt cm_plot(y_test, y_pred).show()
結果如下:
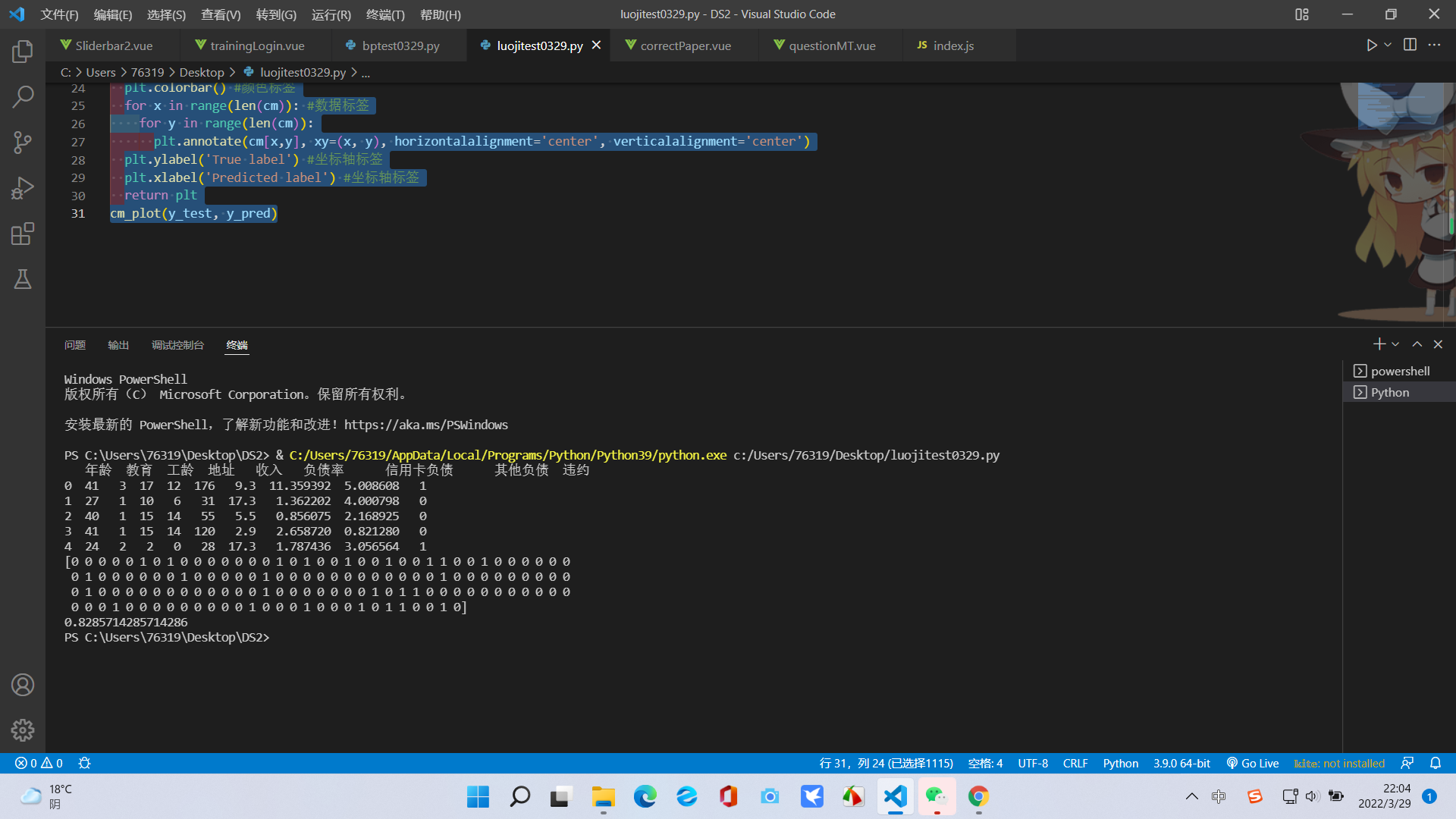

綜上所述得出,兩種演算法模型總體上跑出來的準確率還是不錯的,但是神經網路準確性更高一點。


