Apache HBase MTTR 優化實踐
- 2022 年 3 月 26 日
- 筆記
HBase介紹
HBase是Hadoop Database的簡稱,是建立在Hadoop文件系統之上的分散式面向列的資料庫,它具有高可靠、高性能、面向列和可伸縮的特性,提供快速隨機訪問海量數據能力。
HBase採用Master/Slave架構,由HMaster節點、RegionServer節點、ZooKeeper集群組成,底層數據存儲在HDFS上。
整體架構如圖所示:
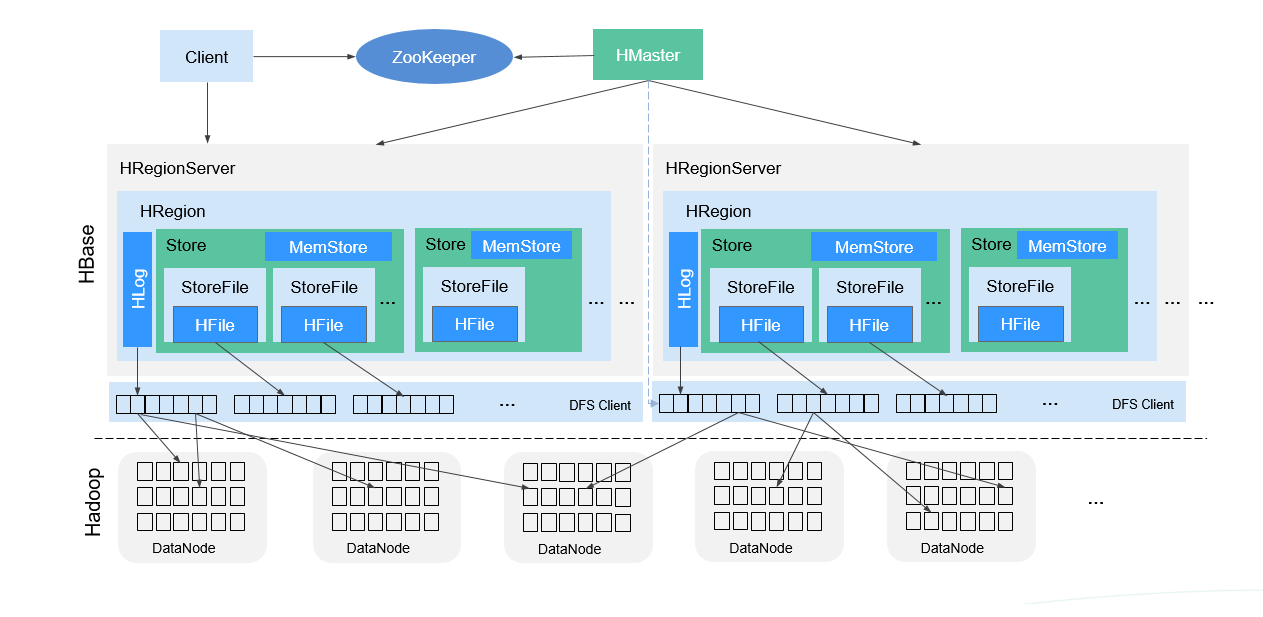
HMaster主要負責:
- 在HA模式下,包含主用Master和備用Master。
- 主用Master:負責HBase中RegionServer的管理,包括表的增刪改查;RegionServer的負載均衡,Region分布調整;Region分裂以及分裂後的Region分配;RegionServer失效後的Region遷移等。
- 備用Master:當主用Master故障時,備用Master將取代主用Master對外提供服務。故障恢復後,原主用Master降為備用。
RegionServer主要負責:
- 存放和管理本地HRegion。
- RegionServer負責提供表數據讀寫等服務,是HBase的數據處理和計算單元,直接與Client交互。
- RegionServer一般與HDFS集群的DataNode部署在一起,實現數據的存儲功能。讀寫HDFS,管理Table中的數據。
ZooKeeper集群主要負責:
- 存放整個 HBase集群的元數據以及集群的狀態資訊。
- 實現HMaster主從節點的Failover。
HDFS集群主要負責:
- HDFS為HBase提供高可靠的文件存儲服務,HBase的數據全部存儲在HDFS中。
結構說明:
Store
- 一個Region由一個或多個Store組成,每個Store對應圖中的一個Column Family。
MemStore
- 一個Store包含一個MemStore,MemStore快取客戶端向Region插入的數據,當RegionServer中的MemStore大小達到配置的容量上限時,RegionServer會將MemStore中的數據「flush」到HDFS中。
StoreFile
- MemStore的數據flush到HDFS後成為StoreFile,隨著數據的插入,一個Store會產生多個StoreFile,當StoreFile的個數達到配置的閾值時,RegionServer會將多個StoreFile合併為一個大的StoreFile。
HFile
- HFile定義了StoreFile在文件系統中的存儲格式,它是當前HBase系統中StoreFile的具體實現。
HLog(WAL)
- HLog日誌保證了當RegionServer故障的情況下用戶寫入的數據不丟失,RegionServer的多個Region共享一個相同的HLog。
HBase提供兩種API來寫入數據。
- Put:數據直接發送給RegionServer。
- BulkLoad:直接將HFile載入到表存儲路徑。
HBase為了保證數據可靠性,使用WAL(Write Ahead Log)來保證數據可靠性。它是HDFS上的一個文件,記錄HBase中數據的所有更改。所有的寫操作都會先保證將數據寫入這個文件後,才會真正更新MemStore,最後寫入HFile中。如果寫WAL文件失敗,則操作會失敗。在正常情況下,不需要讀取WAL文件,因為數據會從MemStore中持久化為HFile文件。但是如果RegionServer在持久化MemStore之前崩潰或者不可用,系統仍然可以從WAL文件中讀取數據,回放所有操作,從而保證數據不丟失。
寫入流程如圖所示:
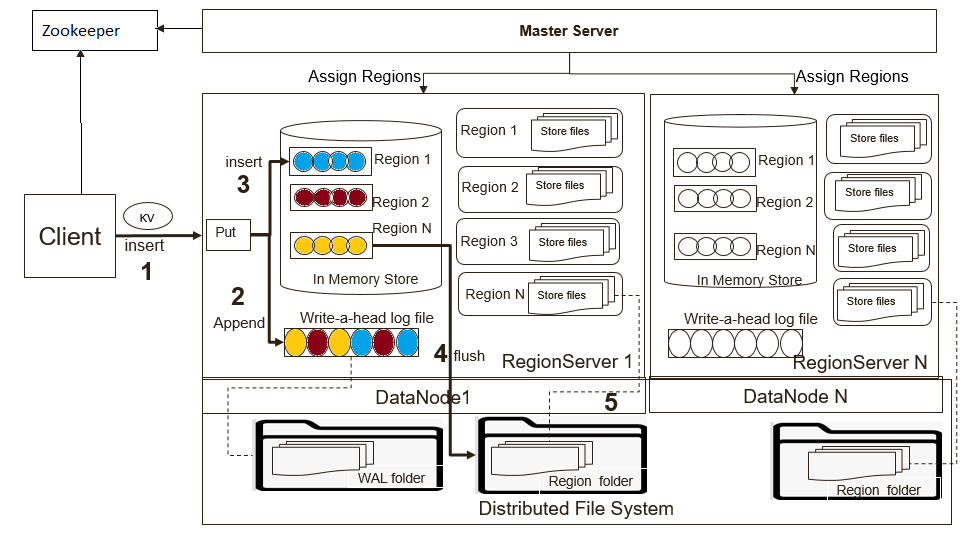
默認情況下RegionServer上管理的所有HRegion共享同一個WAL文件。WAL文件中每個記錄都包括相關Region的資訊。當打開Region時,需要回放WAL文件中屬於該Region的記錄資訊。因此,WAL文件中的記錄資訊必須按Region進行分組,以便可以回放特定Region的記錄。按Region分組WAL的過程稱為WAL Split。
WAL Split由HMaster在集群啟動時完成或者在RegionServer關閉時由ServershutdownHandler完成。在給定的Region再次可用之前,需要恢復和回放所有的WAL文件。因此在數據恢復之前,對應的Region無法對外服務。
HBase啟動時,Region分配簡要分配流程如下:
- HMaster啟動時初始化AssignmentManager。
- AssignmentManager通過hbase:meta表查看當前Region分配資訊。
- 如果Region分配依然有效(Region所在RegionServer依然在線),則保留分配資訊。
- 如果Region分配無效,調用LoadBalancer來進行重分配。
- 分配完成後更新hbase:meta表。
本文主要關注集群重新啟動和恢復相關內容,著重描述相關優化,減少HBase恢復時長。
RegionServer故障恢複流程
當HMaster檢測到故障時,會觸發SCP(Server Crash Procedure)流程。SCP流程包括以下主要步驟:
- HMaster創建WAL Split任務,用於對屬於崩潰RegionServer上Region進行記錄分組。
- 將原屬於崩潰RegionServer上Region進行重分配,分配給正常RegionServer。
- 正常RegionServer執行Region上線操作,對需要恢複數據進行回放。
故障恢復常見問題
HMaster等待Namespace表超時終止
當集群進行重啟時,HMaster進行初始化會找到所有的異常RegionServer(Dead RegionServer)並開始SCP流程,並繼續初始化Namespace表。
如果SCP列表中存在大量的RegionServer,那麼Namespace表的分配將可能被延遲並超過配置的超時時間(默認5分鐘),而這種情況在大集群場景下是最常見的。為臨時解決該問題,常常將默認值改大,但是必不能保證一定會成功。

另外一種方式是在HMaster上啟用表來避免此問題(hbase.balancer.tablesOnMaster=hbase:namespace),HMaster會優先將這些表進行分配。但是如果配置了其它表也可以分配到HMaster或者由於HMaster性能問題,這將無法做到100%解決此問題。此外在HBase 2.X版本中也不推薦使用HMaster來啟用表。解決這個問題的最佳方法是支援優先表和優先節點,當HMaster觸發SCP流程時,優先將這些表分配到優先節點上,確保分配的優先順序,從而完全消除此問題。
批量分配時RPC超時
HBase專門線性可擴展性而設計。如果集群中的數據隨著表增加而增多,集群可以很容易擴展添加RegionServer來管理表和數據。例如:如果一個集群從10個RegionServer擴展到20個RegionServer,它在存儲和處理能力方面將會增加。
隨著RegionServer上Region數量的增加,批量分配RPC調用將會出現超時(默認60秒)。這將導致重新進行分配並最終對分配上線時間產生嚴重影響。
在10個RegionServer節點和20個RegionServer節點的測試中,RPC調用分別花費了約60秒和116秒。對於更大的集群來說,批量分配無法一次成功。主要原因在於對ZooKeeper進行大量的讀寫操作和RPC調用,用來創建OFFLINE ZNode節點,創建正在恢復的Region ZNode節點資訊等。
恢復可擴展性測試
在10到100個節點的集群測試中,我們觀察到恢復時間隨著集群規模的增大而線性增加。這意味著集群越大,恢復所需的時間就越多。特別是當要恢復WAL文件時,恢復時間將會非常大。在100個節點的集群中,通過Put請求寫入數據的情況下,恢復需要進行WAL Split操作,發現需要100分鐘才能從集群崩潰中完全恢復。而在相同規模的集群中,如果不寫入任何數據大約需要15分鐘。這意味著85%以上的時間用於WAL Split操作和回放用於恢復。
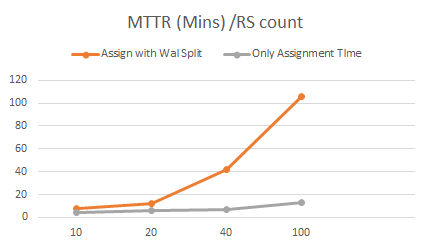
| Cluster Size | Recovered edit files count | Total No. Of regions [2k per RS] | Region Assignment (with WAL split) | Empty Region Assignment |
|---|---|---|---|---|
| 10 Node | 4,00,000 | 20,000 | 7.5 Mins | 4 Min |
| 20 Node | 8,00,000 | 40,000 | 12 Mins | 6 Mins |
| 40 Node | 1.6 Million | 80,000 | 42 Mins | 7 Mins |
| 100 Nodes | 4 Million | 0.2 Million | 106 Mins | 15 Mins |
下面我們將分析測試過程中發現的瓶頸在哪裡?
恢復耗時分析
HDFS負載
在10個節點的HBase集群上,通過JMX來獲取HDFS的RPC請求監控資訊,發現在啟動階段有1200萬讀取RPC調用。
其中GetBlockLocationNumOps:380萬、GetListingNumOps:13萬、GetFileInfoNumOps:840萬。
當集群規模達到100個時,RPC調用和文件操作將會非常大,從而對HDFS負載造成很大壓力,成為瓶頸。可能由於以下原因導致HDFS寫入失敗、WAL Split和Region上線緩慢超時重試。
- 巨大的預留磁碟空間。
- 並發訪問達到DataNode的xceiver的限制。
HMaster負載
HMaster使用基於ZooKeeper的分配機制時,在Region上線過程中HMaster會創建一個OFFLINE ZNode節點,RegionServer會將該ZNode更新為OPENING和OPENED狀態。對於每個狀態變化,HMaster都會進行監聽並處理。
對於100個節點的HBase集群,大概將會有6,000,000個ZNode創建和更新操作和4,000,000個監聽事件要進行處理。
ZooKeeper的監聽事件通知處理是順序的,旨在保證事件的順序。這種設計在Region鎖獲取階段將會導致延遲。在10個節點的集群中發現等待時間為64秒,而20節點的集群中等待時間為111秒。
.png)
GeneralBulkAssigner 在批量發送OPEN RPC請求到RegionServer之前會獲取相關Region的鎖,再收到RegionServer的OPEN RPC請求響應時才會釋放該鎖。如果RegionServer再處理批量OPEN RPC請求時需要時間,那麼在收到確認響應之前GeneralBulkAssigner將不會釋放鎖,其實部分Region已經上線,也不會單獨處理這些Region。
HMaster按照順序創建OFFLINE ZNode節點。觀察發現在執行批量分配Region到RegionServer之前將會有35秒的延遲來創建ZNode。
.png)
採用不依賴ZooKeeper的分配機制將會減少ZooKeeper的操作,可以有50%左右的優化。HMaster依然會協調和處理Region的分配。
提升WAL Split性能
持久化FlushedSequenceId來加速集群重啟WAL Split性能(HBASE-20727)
ServerManager有每個Region的flushedSequenceId資訊,這些資訊被保存在一個Map結構中。我們可以利用這些資訊來過濾不需要進行回放的記錄。但是這個Map結構並沒有被持久化,當集群重啟或者HMaster重啟後,每個Region的flushedSequenceId資訊將會丟失。
如果這些資訊被持久化那麼即使HMaster重啟,這些依然存在可用於過濾WAL記錄,加快恢復記錄和回放。hbase.master.persist.flushedsequenceid.enabled 可用於配置是否開啟此功能。flushedSequenceId資訊將會定時持久化到如下目錄 < habse root dir >/.lastflushedseqids。可以通過參數 hbase.master.flushedsequenceid.flusher.interval 來配置持久化間隔,默認為3小時。
注意:此特性在HBase 1.X版本不可用。
改善WAL Split在故障切換時穩定性(HBASE-19358)
在WAL記錄恢復期間,WAL Split任務將會將RegionServer上的所有待恢復記錄輸出文件打開。當RegionServer上管理的Region數量較多時將會影響HDFS,需要大量的磁碟保留空間但是磁碟寫入非常小。
當集群中所有RegionServer節點都重啟進行恢復時,情況將變得非常糟糕。如果一個RegionServer上有2000個Region,每個HDFS文件為3副本,那麼將會導致每個WAL Splitter打開6000個文件。
通過啟用hbase.split.writer.creation.bounded可以限制每個WAL Splitter打開的文件。當設置為true時,不會打開任何recovered.edits的寫入直到在記憶體積累的記錄已經達到 hbase.regionserver.hlog.splitlog.buffersize(默認128M),然後一次性寫入並關閉文件,而不是一直處於打開狀態。這樣會減少打開文件流數量,從hbase.regionserver.wal.max.splitters * the number of region the hlog contains減少為hbase.regionserver.wal.max.splitters * hbase.regionserver.hlog.splitlog.writer.threads。
通過測試發現在3節點集群中,擁有15GB WAL文件和20K Region的情況下,集群整體重啟時間從23分鐘縮短為11分鐘,減少50%。
hbase.regionserver.wal.max.splitters = 5
hbase.regionserver.hlog.splitlog.writer.threads= 50
WAL Split為HFile(HBASE-23286)
WAL恢復時使用HFile文件替換Edits文件這樣可以避免在Region上線過程中寫入。Region上線過程中需要完成HFile文件校驗、執行bulkload載入並觸發Compaction來合併小文件。此優化可以避免讀取Edits文件和持久化記憶體帶來的IO開銷。當集群中的Region數量較少時(例如50個Region)觀察發現性能有顯著提升。
當集群中有更多的Region時,測試發現由於大量的HFile寫入和合併將會導致CPU和IO的增加。可以通過如下額外的措施來減少IO。
- 將故障RegionServer作為首選WAL Splitter,減少遠程讀取。
- 將Compaction延遲後台執行,加快region上線處理。
Observer NameNode(HDFS-12943)
當HBase集群規模變大時,重啟會觸發大量的RPC請求,使得HDFS可能成為瓶頸,可以通過使用Observer NameNode負擔讀請求來降低HDFS的負載。
總結
通過上述分析,可以配置如下參數來提升HBase MTTR,尤其是在集群整體從崩潰中恢復的情況。
| Configuration | Recommendation | Remarks |
|---|---|---|
| HMaster hbase.master.executor.openregion.thread | 2 * no. of cores | Opened region thread to process OPENED ZK events. Can increase based on the cores in large cluster. |
| HMaster hbase.assignment.zkevent.workers | 2 * no. of cores | ZK event worker thread to process RIT ZK notification, can be tuned based on cores |
| HMaster hbase.master.skip.log.split.task | true | Master participate in WAL split as namespace region is assigned to Hmaster. Hmaster may be overloaded during MTTR |
| HMaster hbase.balancer.tablesOnMaster | hbase:namespace | Assign namespace region to Hmaster, so that HM WAL will be split first to recover namespace region and there wont be any Hmaster abort due to Namespace init timeout Note: Later this will be replaced with Assign system tables to specified RS Group |
| RegionServer hbase.regionserver.executor.openregion.threads | 2 * no. of cores | Handlers to process Open region requests |
| RegionServer hbase.regionserver.metahandler.count | 5 * no. of cores | Meta operation handlers. During full cluster restart, all RSs are opening the region concurrently, so we need more handlers. We observed better perf upto 400 handlers. |
| RegionServer hbase.regionserver.wal.max.splitters | Same as hbase.regionserver.maxlogs | To perform WAL split concurrently and avoid overlap with assignment region cycle. If SCP is blocked for assignment which takes more time, WAL split would be delayed. |
| RegionServer hbase.regionserver.hlog.splitlog.writer.threads | 50 | Works in combination with hbase.split.writer.creation.bounded Writer thread to flush the recovered edits region wise. , can be reduced when active regions are less |
| RegionServer hbase.split.writer.creation.bounded | true | To control the number of open files in HDFS for writing recovered edits. If true, edits are cached and flushed once the buffer is full. |
| RegionServer hbase.wal.split.to.hfile | true | When the active regions are less per RS, can use this configurations to reduce IO. But if the active regions are high, this feature may not have impact. |
| RegionServer hbase.regionserver.maxlogs | 20 | Lesser the logs, lesser the time for wal split & recovering edits |
| HMaster hbase.master.persist.flushedsequenceid.enabled | true | Skip WAL edits which are already flushed into Hfile |
| HMaster hbase.rpc.timeout | 120000 | Bulk assignment RPC gets timed out due to slow processing by RS if there are many regions in RS |
本文由華為雲發布。

