Python 細聊從暴力(BF)字元串匹配演算法到 KMP 演算法之間的精妙變化
1. 字元串匹配演算法
所謂字元串匹配演算法,簡單地說就是在一個目標字元串中查找是否存在另一個模式字元串。如在字元串 “ABCDEFG” 中查找是否存在 「EF」 字元串。
可以把字元串 “ABCDEFG” 稱為原始(目標)字元串,「EF」 稱為子字元串或模式字元串。
本文試圖通過幾種字元串匹配演算法的演算法差異性來探究字元串匹配演算法的本質。
常見的字元串匹配演算法:
- BF(Brute Force,暴力檢索演算法)
- RK (Robin-Karp 演算法)
- KMP (D.E.Knuth、J.H.Morris、V.R.Pratt 演算法)
2. BF(Brute Force,暴力檢索)
BF 演算法是一種原始、低級的窮舉演算法。
2.1 演算法思想
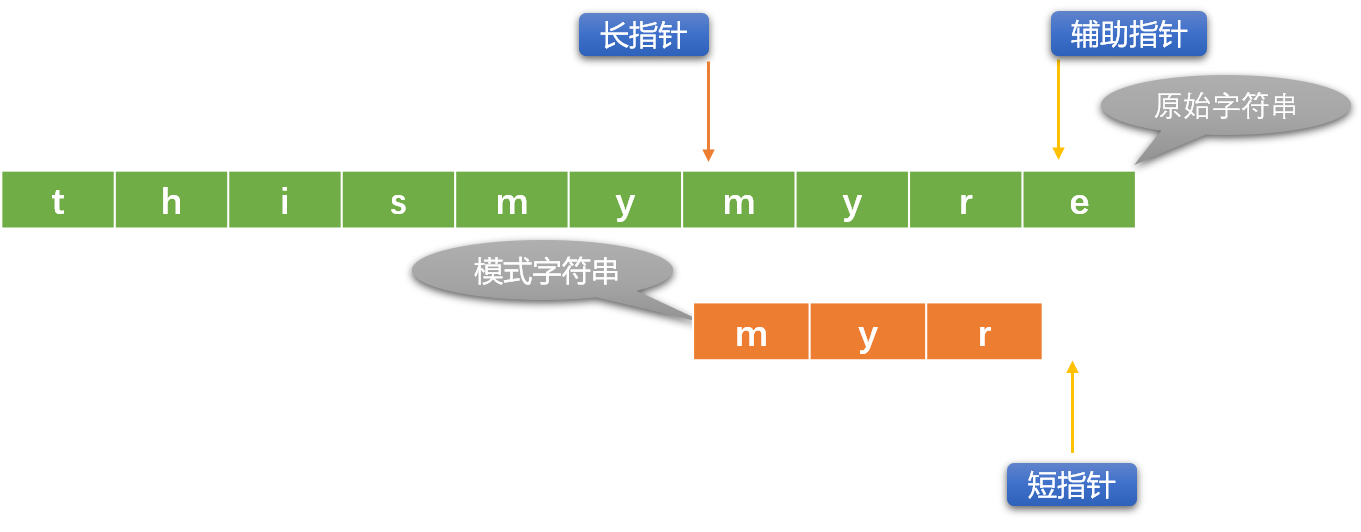
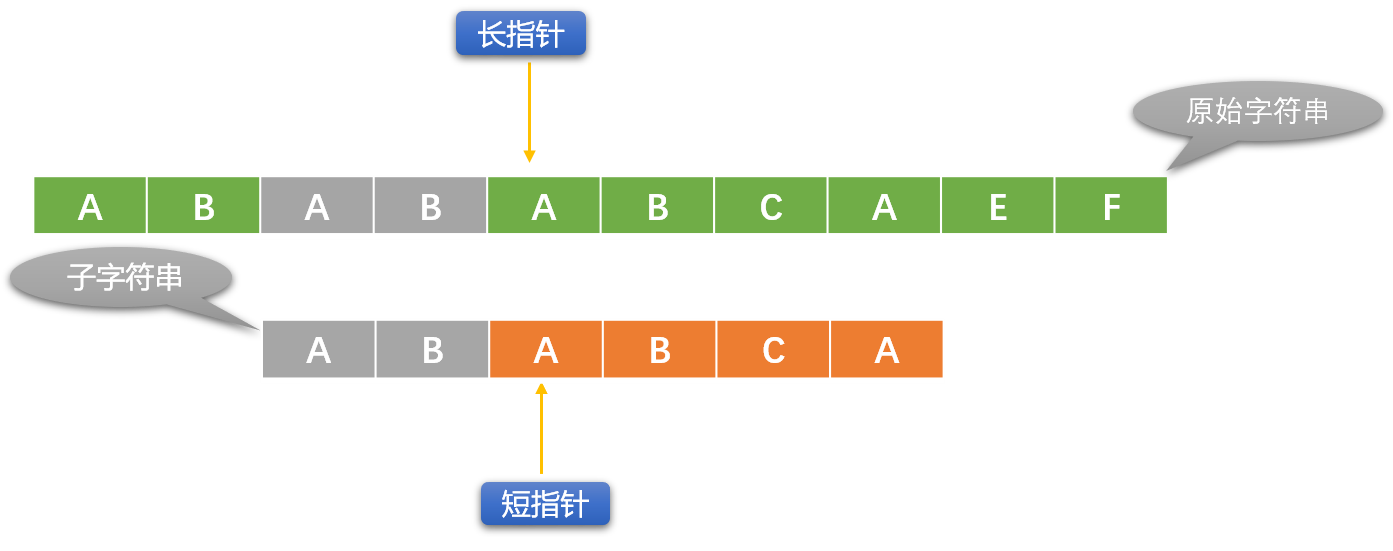
下面使用長、短指針方案描述 BF 演算法:
-
初始指針位置: 長指針指向原始字元串的第一個字元位置、短指針指向模式字元串的第一個字元位置。這裡引入一個輔助指針概念,其實可以不用。
輔助指針是長指針的替身,替長指針和短指針所在位置的字元比較。
每次初始化長指針位置時,讓輔助指針和長指針指向同一個位置。

- 如果長、短指針位置的字元不相同,則長指針向右移動(短指針不動)。如果長、短指針所指位置的字元相同,則用輔助指針替代長指針(長指針位置暫不動)和短指針位置的字元比較,如果比較相同,則同時向右移動輔助指針和短指針。
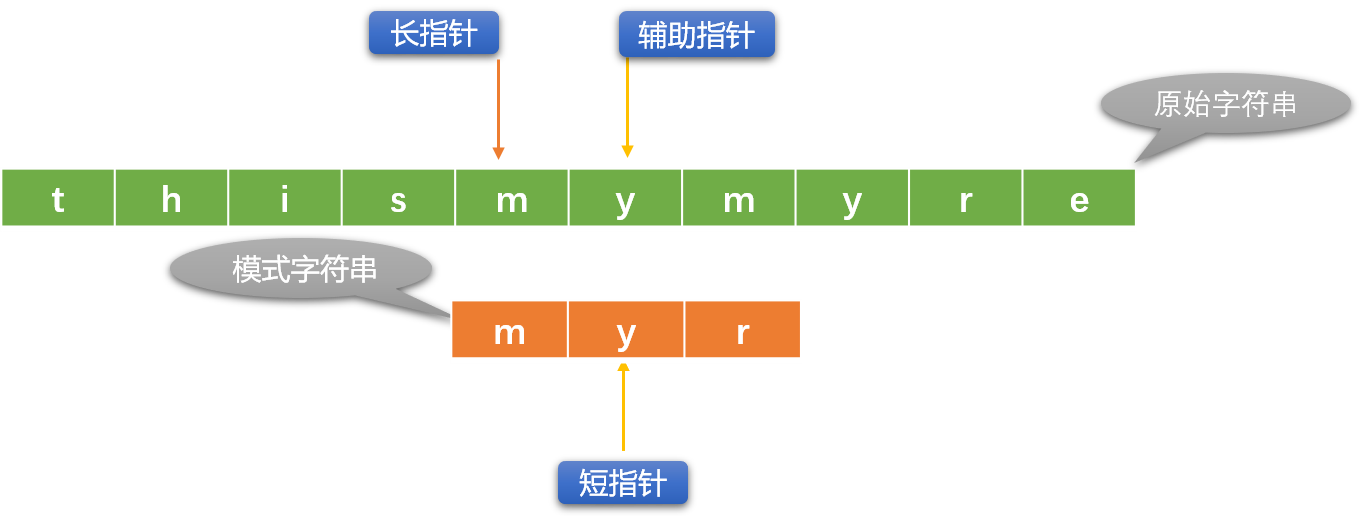
- 如果輔助指針和短指針位置的字元不相同,則重新初始化長指針位置(向右移動),短指針恢復到最原始狀態。
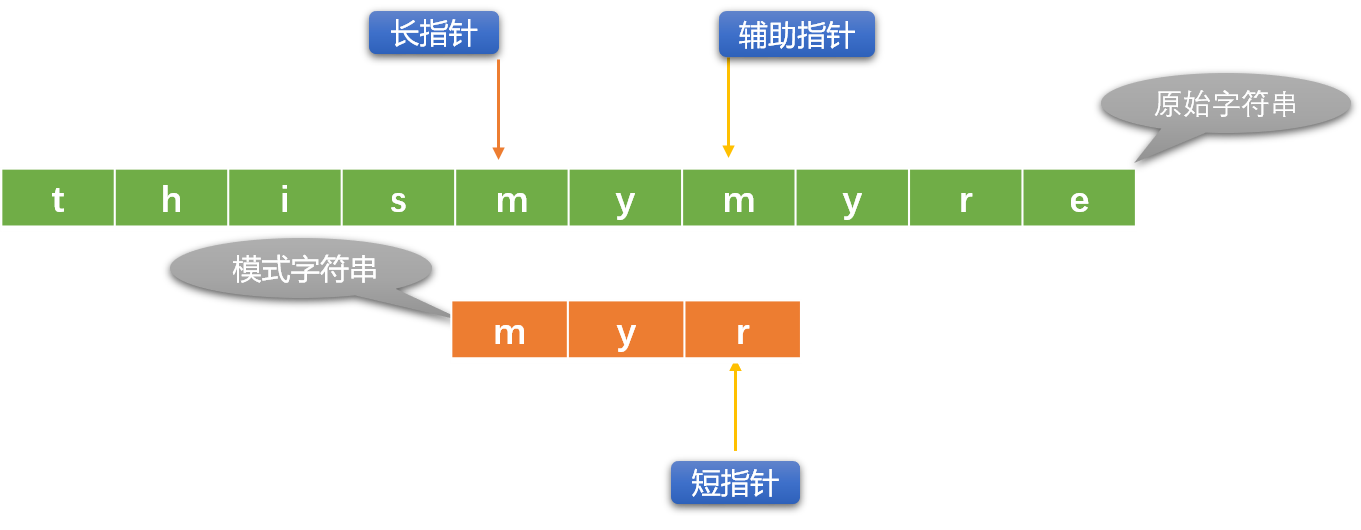
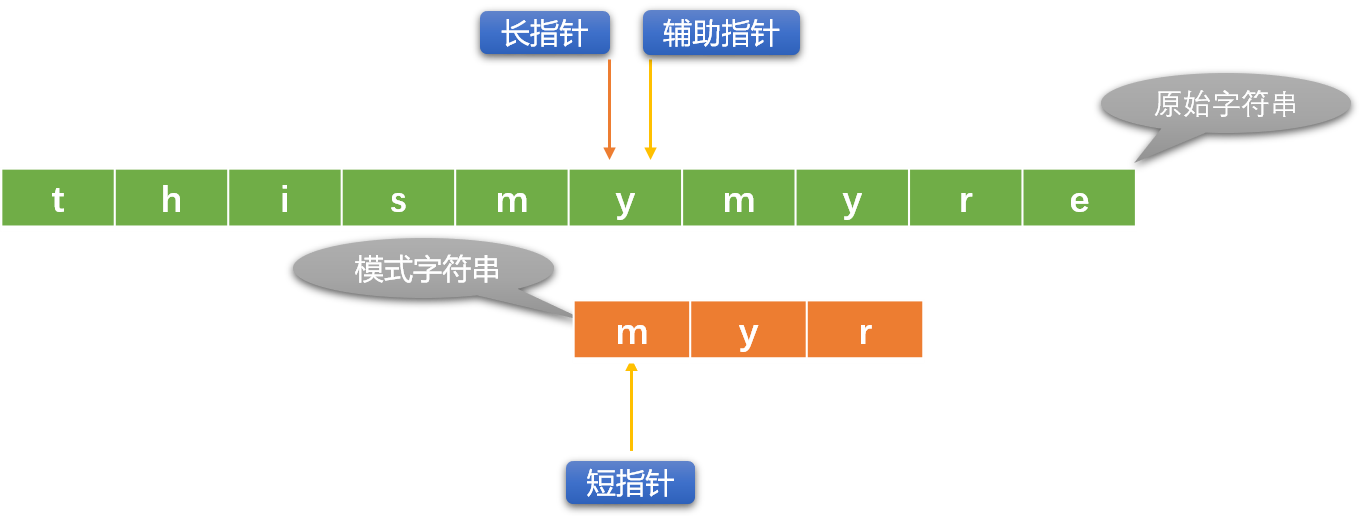
-
使用重複或者遞歸的方式重複上述流程,直到出口條件成立。
- 查找失敗:長指針到達了原始字元串的尾部。當 長指針位置=原始字元串長度 – 模式字元串長度+1 時就可以認定查找失敗。
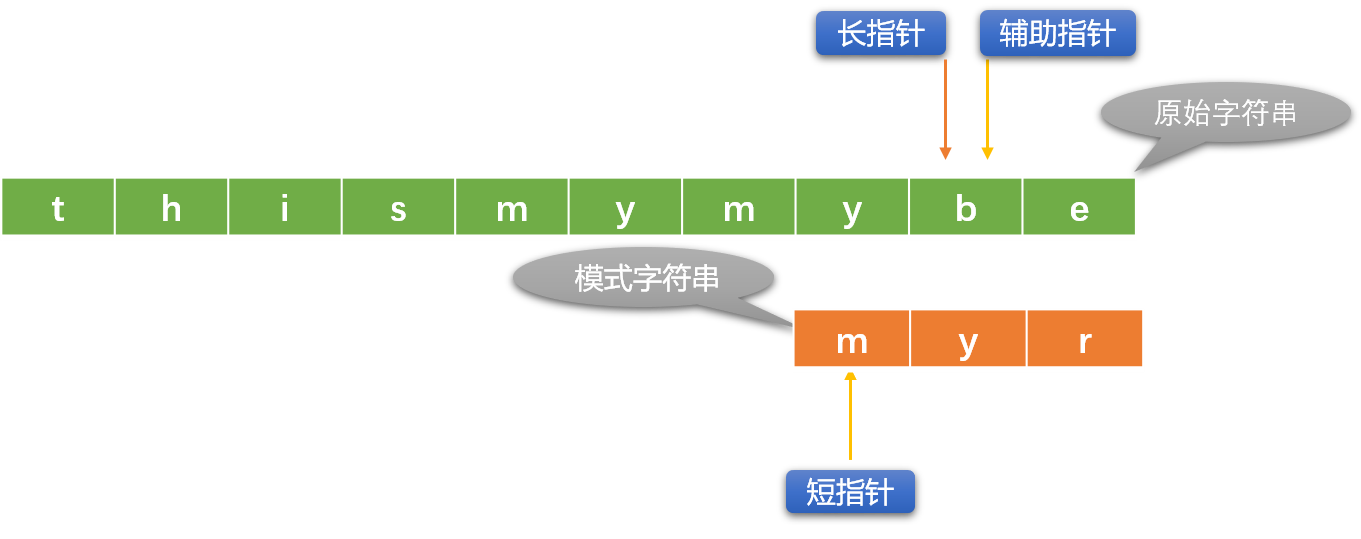
- 查找成功: 短指針到達模式字元串尾部。
2.2 編碼實現
使用輔助指針:
# 原始字元串
src_str = "thismymyre"
# 長指針
sub_str = "myr"
# 長指針 :在原始字元串上移動
long_index = 0
# 短指針:在模式字元串上移動
short_index = 0
# 輔助指針
fu_index = long_index
# 原始字元串長度
str_len = len(src_str)
# 模式字元串的長度
sub_len = len(sub_str)
# 是否存在
is_exist = False
while long_index < str_len-sub_len+1:
# 把長指針的位值賦給輔助指針
fu_index = long_index
# 短指針初始為原始位置
short_index = 0
while short_index < sub_len and src_str[fu_index] == sub_str[short_index]:
# 輔助指針向右
fu_index += 1
# 短指針向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
# 比較不成功,則長指針向右移動
long_index += 1
if not is_exist:
print("{0} 不存在於 {1} 字元串中".format(sub_str, src_str))
else:
print("{0} 存在於 {1} 的 {2} 位置".format(sub_str, src_str, long_index))
使用一個增量:
# 原始字元串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 長指針
long_index = 0
# 短指針
short_index = 0
# 原始字元串長度
str_len = len(src_str)
# 模式字元串的長度
sub_len = len(sub_str)
is_exist = False
while long_index < str_len:
i = 0
short_index = 0
while short_index < sub_len and src_str[long_index + i] == sub_str[short_index]:
i += 1
# 短指針向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
long_index += 1
if not is_exist:
print("{0} 不存在於 {1} 字元串中".format(sub_str, src_str))
else:
print("{0} 存在於 {1} 的 {2} 位置".format(sub_str, src_str, long_index))
使用或不使用輔助指針的程式碼邏輯是一樣。
在原始字元串和模式字元串齊頭並進逐一比較時,最好不要修改長指針的位置,否則,在比較不成功的情況下,則修正長指針的邏輯就沒有單純的直接向右移動那麼好理解。
如下直接使用長指針和短指針進行比較:
# 原始字元串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 長指針
long_index = 0
# 短指針
short_index = 0
# 原始字元串長度
str_len = len(src_str)
# 模式字元串的長度
sub_len = len(sub_str)
is_exist = False
while long_index < str_len:
short_index = 0
# 直接使用長指針和短指針位置相比較
while short_index < sub_len and src_str[long_index] == sub_str[short_index]:
long_index+=1
# 短指針向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
# 修正長指針的位置
long_index = long_index-short_index+1
if not is_exist:
print("{0} 不存在於 {1} 字元串中".format(sub_str, src_str))
else:
print("{0} 存在於 {1} 的 {2} 位置".format(sub_str, src_str, long_index-short_index))
使用字元串切片實現: 使用 Python 的切片實現起來更簡單。但不利於初學者理解 BF 演算法的細節。
# 原始字元串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 原始字元串長度
str_len = len(src_str)
# 模式字元串的長度
sub_len = len(sub_str)
is_exist = False
for index in range(str_len - sub_len + 1):
if src_str[index:index + sub_len] == sub_str:
is_exist = True
break
if not is_exist:
print("{0} 不存在於 {1} 字元串中".format(sub_str, src_str))
else:
print("{0} 存在於 {1} 的 {2} 位置".format(sub_str, src_str, index))
BF 演算法的時間複雜度:
BF 演算法直觀,易於實現。但程式碼中有循環中嵌套循環的結構,這是典型的窮舉結構。如果原始字元串的長度為 m ,模式字元串的長度為 n。時間複雜度則是 O(m*n),時間複雜度較高。
3. RK(Robin-Karp 演算法)
RK演算法 ( 指紋字元串查找) 在 BF 演算法的基礎上做了些改進,基本思路:
在模式字元串和原始字元串的字元準備開始逐一比較時,能不能通過一種演算法,快速判斷出本次比較是沒有必要。

3.1 RK 的演算法思想
-
選定一個哈希函數(可自定義)。
-
使用哈希函數計算模式字元串的哈希值。
如上計算 thia 的哈希值
-
再從原始字元串的開始比較位置起,截取一段和模式字元串長度一樣的子串,也使用哈希函數計算哈希值。
如上計算 this 的哈希值
-
如果兩次計算出來的哈希值不相同,則可判斷兩段模式字元串不相同,沒有比較的必要。
-
如果兩次計算的哈希值相同,因存在哈希衝突,還是需要使用 BF 演算法進行逐一比較。
RK 演算法使用哈希函數演算法減少了比較次數。
3.2 編碼實現:
# 原始字元串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 長指針
long_index = 0
# 短指針
short_index = 0
# 輔助指針
fu_index = 0
# 原始字元串長度
str_len = len(src_str)
# 模式字元串的長度
sub_len = len(sub_str)
is_exist = False
for long_index in range(str_len - sub_len + 1):
# 這裡使用 python 內置的 hash 函數
if hash(sub_str) != hash(src_str[long_index:long_index + sub_len]):
# 哈希值一樣就沒有必要比較了
continue
# 把長指針的位置賦給輔助指針
fu_index = long_index
short_index = 0
while short_index < sub_len and src_str[fu_index] == sub_str[short_index]:
# 輔助指針向右
fu_index += 1
# 短指針向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
if not is_exist:
print("{0} 不存在於 {1} 字元串中".format(sub_str, src_str))
else:
print("{0} 存在於 {1} 的 {2} 位置".format(sub_str, src_str, long_index))
RK 的時間複雜度:
RK 的程式碼結構和 BF 看起來一樣,使用了循環嵌套。但內置循環只有當哈希值一樣時才會執行,執行次數是模式字元串的長度。如果原始子符串長度為 m,模式字元串的長度為 n。則時間複雜度為 O(m+n),如果不考慮哈希衝突問題,時間複雜度為 O(m)。
很顯然 RK 演算法比 BF 演算法要快很多。
4. KMP演算法
演算法的本質都是窮舉,這是由電腦的思維方式決定的。我們在談論”好”和「壞」 演算法時,所謂好就是想辦法讓窮舉的次數少一些。比如前面的 RK 演算法,通過一些特性提前判斷是否值得比較,這樣可以省掉很多不必要的內循環。
KMP 也是一樣,也是儘可能減少比較的次數。
4.1 KMP 演算法思路:
KMP 的基本思路和 BF 是一樣的(字元串逐一比較),BF 演算法中,如果比較不成功,長指針每次只會向右移動一位。如下圖:輔助指針和短指針對應位置字元不相同,說明比較失敗。
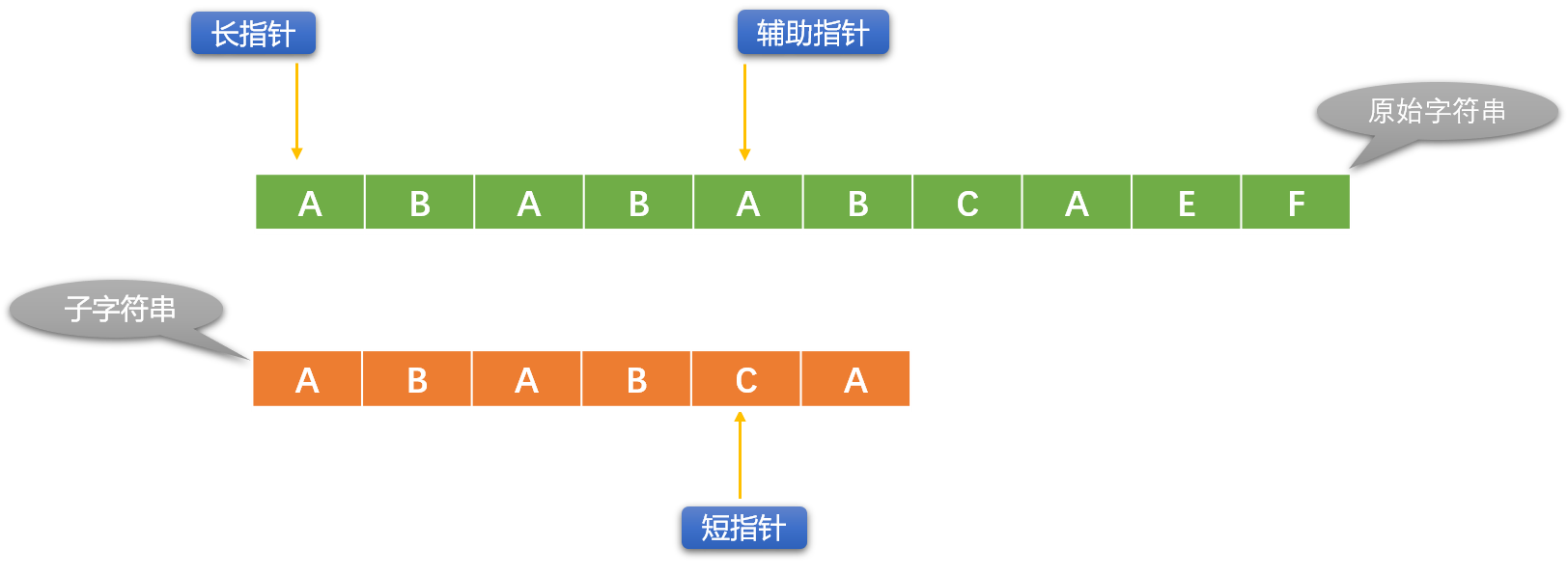
長指針向右移一位,短指針恢復原始狀態。重新逐一比較。
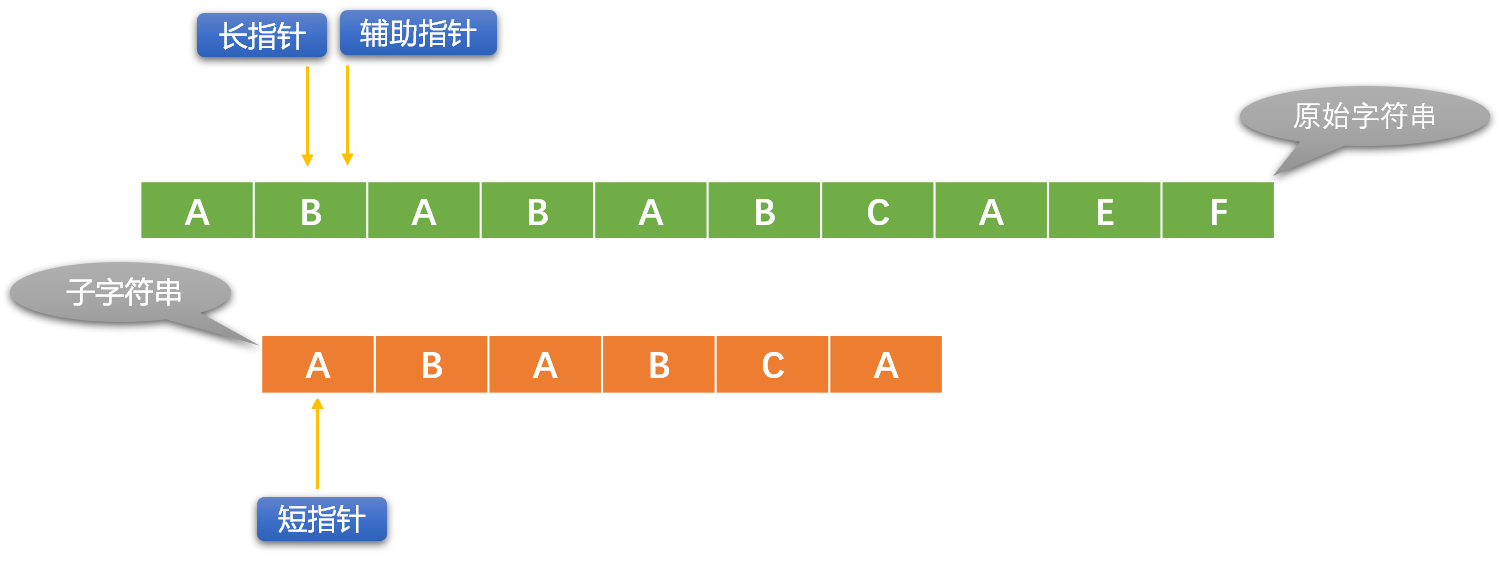
KMP 演算法對長、短指針的移位做了優化。
- 沒有必要再使用輔助指針。
- 直接把長指針和短指針所在位置的字元逐一比較。
- 比較失敗後,長指針位置不動。根據 KMP 演算法中事先計算好的 「部分匹配表(PMT:Partial Match Table)」 修改短指針的位置。
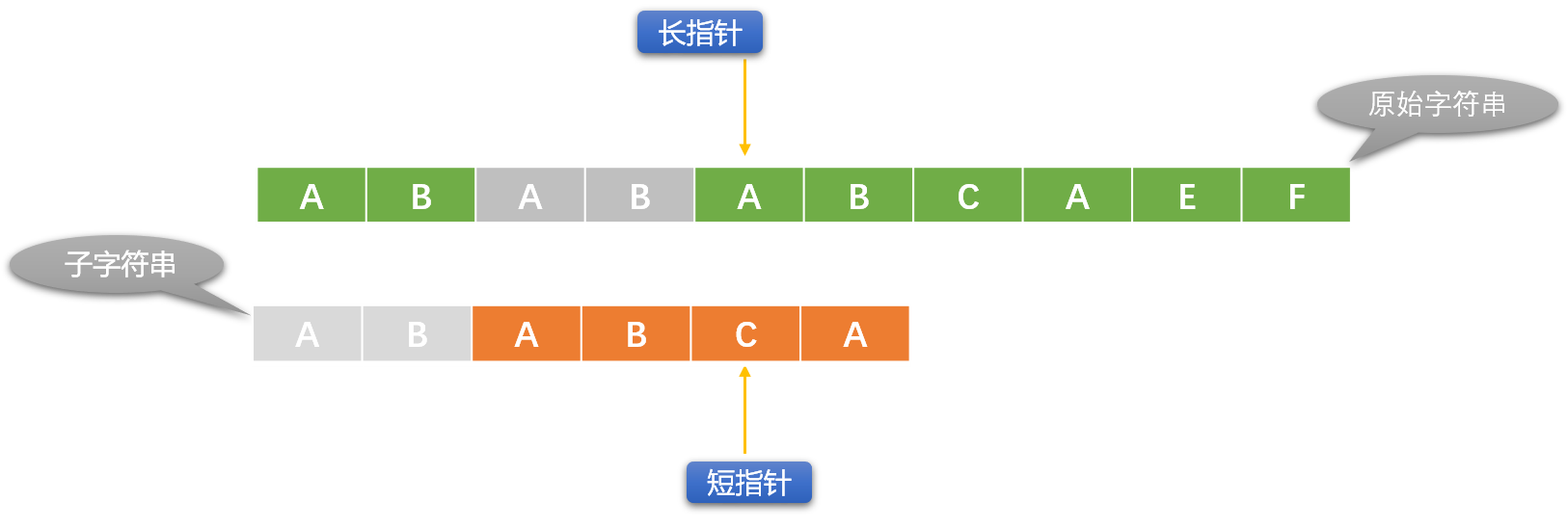
如上圖比較失敗後,長指針位置保持不變,只需要移動短指針。短指針具體移動哪裡,由 PMT 表決定。上圖灰色區域就是根據 PMT 表計算出來的可以不用再比較的字元。
在移動短指針之前,先要理解 KMP 演算法中 的 “部分匹配表(PMT)” 是怎麼計算出來的。
先理解與 PMT 表有關係的 3 個概念:
-
前綴集合:
如: ABAB 的前綴(不包含字元串本身)集合 {A,AB,ABA}
-
後綴集合:
如:ABAB 中後綴(不包含字元串本身)集合 { BAB,AB,B }
-
PMT值: 前綴、後綴兩個集合的交集元素中最長元素的長度。
如:先求 {A,AB,ABA} 和 { BAB,AB,B } 的交集,得到集合 {AB} ,再得到集合中最長元素的長度, 所以 ABAB 字元串的 PMT 值是 2 。
如前面圖示,原始字元串和模式字元串逐一比較時,前 4 位即 ABAB 是相同的,而 ABAB 存在最大長度的前綴和後綴 『AB』 子串。意味著下一次比較時,可以直接讓模式字元串的前綴和原始字元串中已經比較的字元串的後綴對齊,公共部分不用再比較。
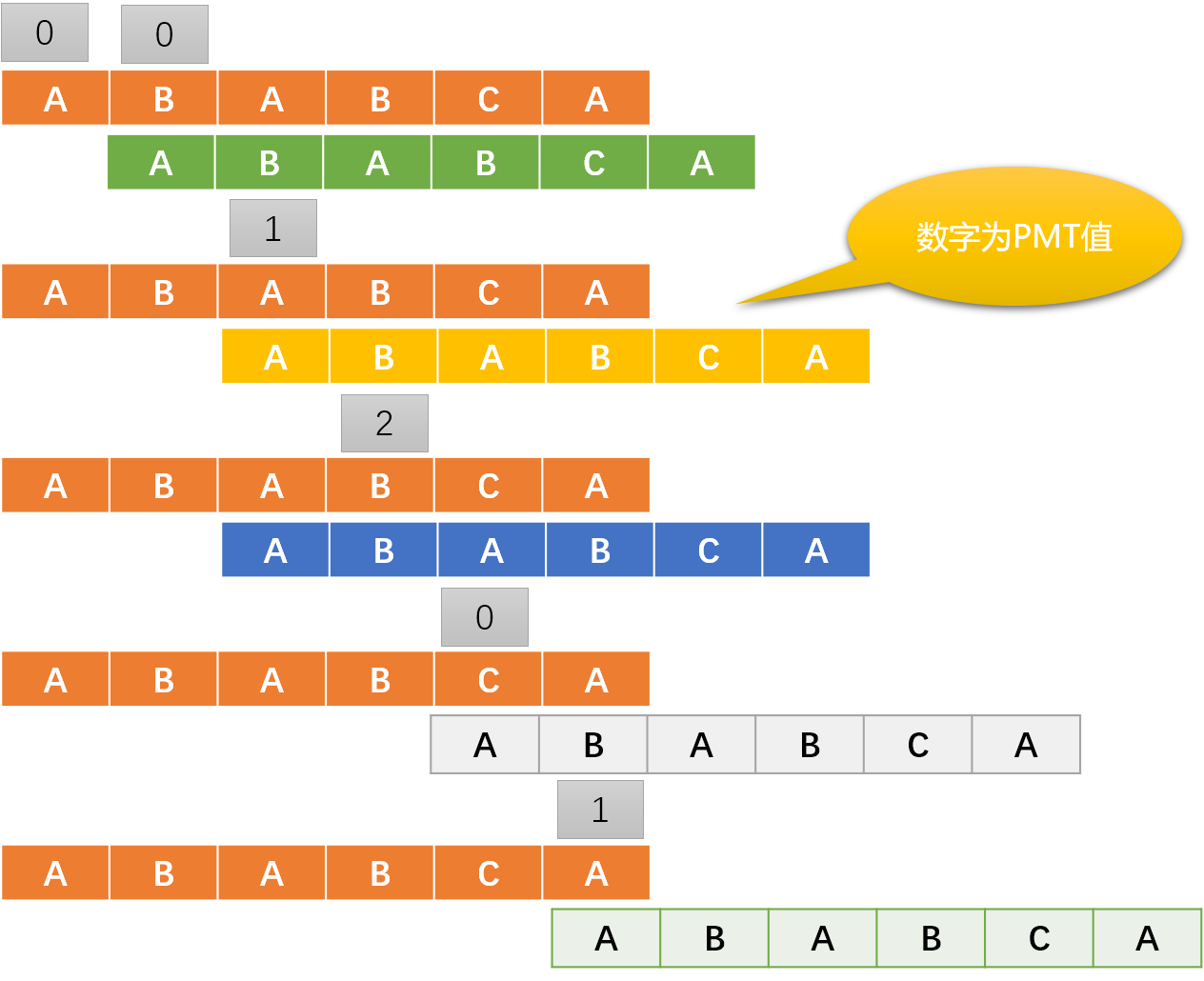
所以,KMP 演算法的核心是得到 PMT 表,現使用手工方式計算 ABABCA 的 PMT 值:
-
當僅匹配第一個字元 A 時,A 沒有前綴集合也沒有後綴集合,所以 PMT[0]=0,短指針要移到模式字元串的 0 位置。
-
當僅匹配前二個字元 AB 時,AB的前綴集合{A},後綴集合是{B},沒有交集,所以 PMT[1]=0,短指針要移到模式字元串的 0 位置。
-
當僅匹配前三個字元 ABA 時,ABA 的前綴集合{A,AB} ,後綴集合{BA,A},交集{A},所以 PMT[2]=1,短指針要移到模式字元串 1 的位置。
-
當僅匹配前四個字元 ABAB 時,ABAB 的前綴集合 {A ,AB,ABA },後綴集合{BAB,AB,B},交集{AB},所以 PMT[3]=2,短指針要移到模式字元串 2 的位置。
-
當僅匹配前五個字元 ABABC 時,ABABC 的前綴集合{ A,AB,ABA,ABAB },後綴集合{ C,BC,ABC,BABC },沒有交集,所以PMT[4]=0,短指針要移到模式字元串的 0 位置。
-
當全部匹配後,ABABCA 的前綴是{A,AB,ABA,ABABC,ABABCA},後綴是{A,CA,BCA,ABCA,BABCA} 交集是{A},PMT[5]=1。

其實在 KMP 演算法中,本沒有直接使用 PMT 表,而是引入了next 數組的概念,next 數組中的值是 PMT 的值向右移動一位。

KMP演算法實現: 先不考慮 next 數組的演算法,先以上面的手工計算值作為 KMP 演算法的已知數據。
src_str = 'ABABABCAEF'
sub_str = 'ABABCA'
# next 數組,現在不著急討論 next 數組如何編碼實現,先用上面手工推演出來的結果
p_next = [-1, 0, 0, 1, 2, 0]
# long_index 指向原始字元的第一個位置
long_index = 0
# short_index 指向模式字元串的第一個
short_index = 0
# 原始字元串的長度
src_str_len = len(src_str)
# 模式字元串的長度
sub_str_len = len(sub_str)
# 保存長指針、短指針位置有效 當長指針越界時,說明查找失敗,當短指針越界,說明查找成功
while long_index < src_str_len and short_index < sub_str_len:
# 理論上 當長指針和短指針所在位置的字元相同時,長、短指針向右移動
# 如果長指針和短指針所在位置的字元不相同時,這裡 -1 就起到神奇的作用,長指針可以前進,短指針會變成 0 。
# 下次比較時,如果還是不相同 short_index 又變回 -1, 長指針又可以前進,短指針還是指向 0 位置
if short_index == -1 or src_str[long_index] == sub_str[short_index]:
long_index += 1
short_index += 1
else:
short_index = p_next[short_index]
if short_index == sub_str_len:
print(long_index - short_index)
上面的程式碼是沒有通用性的,因為 next 數組的值是固定的,現在實現求解 netxt 數組的演算法:
求 next 也可以認為是一個字元串匹配過程,只是原始字元串和模式字元串都是同一個字元串,因第一個字元沒有前綴也沒有後綴,所以從第二個字元開始。
# 求解 next 的演算法
def getNext(p):
i, j = 0, -1
m = len(p)
pnext = [-1] * m
while i < m - 1:
if j == -1 or p[i] == p[j]:
i += 1
j += 1
pnext[i] = j
else:
j = pnext[j]
return pnext
KMP演算法的時間複雜度為 O(m+n)
5. 總結
字元串匹配演算法除了上述幾種外,還有 Sunday演算法、Sunday演算法。從暴力演算法開始,其它演算法可以儘可能減少比較的次數。加快演算法的速度。


