除了增刪改查你對MySQL還了解多少?
除了增刪改查你對MySQL還了解多少?

MySQL授權遠程連接
👉遠程連接
👉授權
相關庫:mysql
相關表:user
相關欄位:select host,user from user;
創建用戶、授權
-
創建用戶格式:
create user 用戶名@ip地址 identified by '密碼'; -
授權:
grant all on *.* To 用戶名@'ip地址';`grant select,create on 資料庫名.表名 To 用戶名@ip地址;`
# 創建用戶
create user root@'192.168.11.%' identified by '123456';
# 這樣[email protected].% 這個網段的用戶可以登錄
create user hans@'192.168.11.161' identified by '123456';
# 這樣只允許hans用戶登錄
create user li@'%' identified by '123456';
# 所有li用戶都可登錄
# 刪除用戶
drop user root@'192.168.11.%';
# 授權
grant all on *.* To hans@'192.168.11.161';
grant select,create on oldboy_test.* To hans@'192.168.11.161';
# 查看授權
show grants for hans@'192.168.11.161';
# 刷新許可權表
flush privileges;
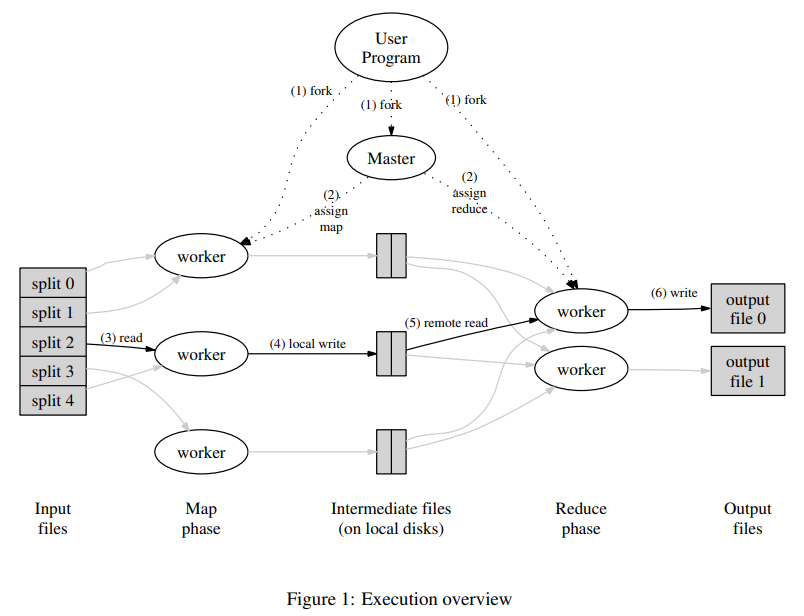
客戶端與伺服器連接的過程
我們知道MySQL在配置好環境變數後,直接mysql -p xx -u xx -h xx就登錄了,不需要先啟動服務端,再啟動客戶端這麼繁瑣,但凡涉及到服務端和客戶端就會涉及到通訊問題,客戶端進程向伺服器進程發送請求並得到回復的過程本質上是一個進程間通訊的過程!那麼MySQL的通訊方式??是什麼???
TCP/IP
在我們實際使用資料庫的過程中,大概率伺服器和客戶端不會在一台機器上,那麼他們之間就得通過網路來通訊,MySQL採用TCP作為伺服器和客戶端之間的網路通訊協議。我們知道MySQL登錄的命令可以攜帶多個參數,在我們有許可權遠程登錄的情況下,通過-P和-h來指定埠和域名;
ps:協議不清楚可以百度或者看一下俺的部落格哈哈哈
👉網路編程理論 – HammerZe – 部落格園 (cnblogs.com)
我們都知道MySQL伺服器的默認埠為3306,之後就在這個埠號上等待客戶端進程進行連接(MySQL伺服器會默認監聽3306埠)
如果埠被佔用了,可以在啟動伺服器的時候通過-P指定參數:
mysqld -P3307
禁止各客戶端使用TCP/IP網路進行通訊:
mysqld --skip-networking
mysql -h127.0.0.1 -uroot -p
Enter password:
ERROR 2003 (HY000): Can't connect to MySQL server on '127.0.0.1' (61)
命名管道和共享記憶體
如果是Windows用戶,客戶端和服務端連接可以使用:
- 命名管道
- 共享記憶體
使用這兩種方式連接需要添加參數:
-
使用
命名管道來進行進程間通訊:需要在啟動伺服器程式的命令中加上
--enable-named-pipe參數,然後在啟動客戶端程式的命令中加入--pipe或者--protocol=pipe參數; -
使用
共享記憶體來進行進程間通訊:需要在啟動伺服器程式的命令中加上
--shared-memory參數,在成功啟動伺服器後,共享記憶體便成為本地客戶端程式的默認連接方式,不過我們也可以在啟動客戶端程式的命令中加入--protocol=memory參數來顯式的指定使用共享記憶體進行通訊;
注意
- 不過需要注意的是,使用
共享記憶體的方式進行通訊的伺服器進程和客戶端進程必須在同一台Windows主機中 - 命名管道和共享記憶體是Windows作業系統中的兩種進程間通訊方式
Unix域套接字文件
使用此連接方式的前提是伺服器和客戶端進程都在同一類Unix的機器上,我們才可以使用Unix域套接字文件來進行通訊;
啟動客戶端程式的時候指定的主機名為localhost,或者指定了--protocol=socket的啟動參數,那伺服器程式和客戶端程式之間就可以通過Unix域套接字文件來進行通訊了;
MySQL伺服器程式默認監聽的Unix域套接字文件路徑為/tmp/mysql.sock,客戶端程式也默認連接到這個Unix域套接字文件;
# 修改默認路徑,啟動時指定路徑
mysqld --socket=/tmp/a.txt
然後登錄的時候伺服器監聽的就是tmp下的a.txt文件,如何登錄?
mysql -hlocalhost -uroot --socket=/tmp/a.txt -p1234
查詢優化
因為我們寫的MySQL語句執行起來效率可能並不是很高,MySQL的優化程式會對我們的語句做一些優化,如外連接轉換為內連接、表達式簡化、子查詢等,最後優化的結果就是生成一個執行計劃,這個執行計劃表明了應該使用哪些索引進行查詢,表之間的連接順序是啥樣的,我們可以通過EXPLAIN語句來設置執行計劃;
MySQL中走與不走索引的情況匯總
轉自://cloud.tencent.com/developer/article/1666887
在MySQL中,並不是你建立了索引,並且你在SQL中使用到了該列,MySQL就肯定會使用到那些索引的,有一些情況很可能在你不知不覺中,你就「成功的避開了」MySQL的所有索引;
多種情況說明如下:
索引列參與計算
如果where條件中age列中使用了計算,則不會使用該索引。如果需要計算,千萬不要計算到索引列,想方設法讓其計算到表達式的另一邊去;
SELECT `sname` FROM `t_stu` WHERE `age`=20; -- 會使用索引
SELECT `sname` FROM `t_stu` WHERE `age`+10=30; -- 不會使用索引!!因為所有索引列參與了計算
SELECT `sname` FROM `t_stu` WHERE `age`=30-10; -- 會使用索引
索引列使用了函數
同樣的道理,索引列使用了函數,一樣會導致相同的後果
SELECT `sname` FROM `stu` WHERE concat(`sname`,'abc') ='Jaskeyabc'; -- 不會使用索引,因為使用了函數運算,原理與上面相同
SELECT `sname` FROM `stu` WHERE `sname`=concat('Jaskey','abc'); -- 會使用索引
索引列使用了Like %XXX
SELECT * FROM `houdunwang` WHERE `uname` LIKE '前綴%' -- 走索引
SELECT * FROM `houdunwang` WHERE `uname` LIKE '%後綴' -- 掃描全表,不走索引
所以當需要搜索email列中.com結尾的字元串而email上希望走索引時候,可以考慮資料庫存儲一個反向的內容reverse_email
SELECT * FROM `table` WHERE `reverse_email` LIKE REVERSE('%.com'); -- 走索引
註:以上如果你使用REVERSE(email) = REVERSE(』%.com』),一樣得不到你想要的結果,因為你在索引列email列上使用了函數,MySQL不會使用該列索引 同樣的,索引列上使用正則表達式也不會走索引。
字元串列與數字直接比較
這是一個坑,假設有一張表,裡面的a列是一個字元char類型,且a上建立了索引,你用它與數字類型做比較判斷的話:
CREATE TABLE `t1` (`a` char(10));
SELECT * FROM `t1` WHERE `a`='1' -- 走索引
SELECT * FROM `t2` WHERE `a`=1 -- 字元串和數字比較,不走索引!
但是如果那個表那個列是一個數字類型,拿來和字元類型的做比較,則不會影響到使用索引
CREATE TABLE `t2` (`b` int);
SELECT * FROM `t2` WHERE `b`='1' -- 雖然b是數字類型,和'1'比較依然走索引
但是,無論如何,這種額外的隱式類型轉換都是開銷,而且由於有字元和數字比就不走索引的情況,故建議避免一切隱式類型轉換
盡量避免 OR 操作
select * from dept where dname='jaskey' or loc='bj' or deptno=45
--如果條件中有or,即使其中有條件帶索引也不會使用。換言之,就是要求使用的所有欄位,都必須建立索引
所以除非每個列都建立了索引,否則不建議使用OR,在多列OR中,可以考慮用UNION 替換
select * from dept where dname='jaskey' union
select * from dept where loc='bj' union
select * from dept where deptno=45
ORDER BY 操作
在ORDER BY操作中,排序的列同時也在WHERE中時,MYSQL將無法使用索引;
MySQL索引通常是被用於提高WHERE條件的數據行匹配或者執行聯結操作時匹配其它表的數據行的搜索速度。
MySQL也能利用索引來快速地執行ORDER BY和GROUP BY語句的排序和分組操作。
通過索引優化來實現MySQL的ORDER BY語句優化:
1、ORDER BY的索引優化。如果一個SQL語句形如:
SELECT [column1],[column2],…. FROM [TABLE] ORDER BY [sort]; 在[sort]這個欄位上建立索引就可以實現利用索引進行order by 優化。
2、WHERE + ORDER BY的索引優化,形如:
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] = [value] ORDER BY [sort]; 建立一個聯合索引(columnX,sort)來實現order by 優化。
注意:如果columnX對應多個值,如下面語句就無法利用索引來實現order by的優化 SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] IN ([value1],[value2],…) ORDER BY[sort];
3、WHERE+ 多個欄位ORDER BY
SELECT * FROM [table] WHERE uid=1 ORDER x,y LIMIT 0,10; 建立索引(uid,x,y)實現order by的優化,比建立(x,y,uid)索引效果要好得多。
MySQL Order By不能使用索引來優化排序的情況 * 對不同的索引鍵做 ORDER BY :(key1,key2分別建立索引) SELECT * FROM t1 ORDER BY key1, key2;
* 在非連續的索引鍵部分上做 ORDER BY:(key_part1,key_part2建立聯合索引;key2建立索引) SELECT * FROM t1 WHERE key2=constant ORDER BY key_part2;
* 同時使用了 ASC 和 DESC:(key_part1,key_part2建立聯合索引) SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
* 用於搜索記錄的索引鍵和做 ORDER BY 的不是同一個:(key1,key2分別建立索引) SELECT * FROM t1 WHERE key2=constant ORDER BY key1;
* 如果在WHERE和ORDER BY的欄位上應用表達式(函數)時,則無法利用索引來實現order by的優化 SELECT * FROM t1 ORDER BY YEAR(logindate) LIMIT 0,10;
特別提示:
1>mysql一次查詢只能使用一個索引。如果要對多個欄位使用索引,建立複合索引。 2>在ORDER BY操作中,MySQL只有在排序條件不是一個查詢條件表達式的情況下才使用索引。
Offset Limit 操作
存在性能問題的方式
SELECT * FROM myTable ORDER BY `id` LIMIT 1000000, 30
寫出這樣SQL語句的人肯定心裡是這樣想的:MySQL資料庫會直接定位到符合條件的第1000000位,然後再取30條數據。 然而,實際上MySQL不是這樣工作的。
LIMIT 1000000, 30 的意思是:掃描滿足條件的1000030行,扔掉前面的1000000行,然後返回最後的30行。
mysql 的 limit 給分頁帶來了極大的方便,但數據偏移量一大,limit 的性能就急劇下降。
以下是兩條查詢語句,都是取10條數據,但性能就相去甚遠
所以不能簡單的使用 limit 語句實現數據分頁。
探究
為什麼 offset 偏大之後 limit 查找會變慢?這需要了解 limit 操作是如何運作的,以下面這句查詢為例:
select * from table_name limit 10000,10
這句 SQL 的執行邏輯是 1.從數據表中讀取第N條數據添加到數據集中 2.重複第一步直到 N = 10000 + 10 3.根據 offset 拋棄前面 10000 條數 4.返回剩餘的 10 條數據
顯然,導致這句 SQL 速度慢的問題出現在第二步!這前面的 10000 條數據完全對本次查詢沒有意義,但是卻佔據了絕大部分的查詢時間!如何解決?首先我們得了解為什麼資料庫為什麼會這樣查詢。
首先,資料庫的數據存儲並不是像我們想像中那樣,按表按順序存儲數據,一方面是因為電腦存儲本身就是隨機讀寫,另一方面是因為數據的操作有很大的隨機性,即使一開始數據的存儲是有序的,經過一系列的增刪查改之後也會變得凌亂不堪。所以資料庫的數據存儲是隨機的,使用 B+Tree, Hash 等方式組織索引。所以當你讓資料庫讀取第 10001 條數據的時候,資料庫就只能一條一條的去查去數。
第一次優化
根據資料庫這種查找的特性,就有了一種想當然的方法,利用自增索引(假設為id):
select * from table_name where (id >= 10000) limit 10
由於普通搜索是全表搜索,適當的添加 WHERE 條件就能把搜索從全表搜索轉化為範圍搜索,大大縮小搜索的範圍,從而提高搜索效率。
這個優化思路就是告訴資料庫:「你別數了,我告訴你,第10001條數據是這樣的,你直接去拿吧。」
但是!!!你可能已經注意到了,這個查詢太簡單了,沒有任何的附加查詢條件,如果我需要一些額外的查詢條件,比如我只要某個用戶的數據 ,這種方法就行不通了。
可以見到這種思路是有局限性的,首先必須要有自增索引列,而且數據在邏輯上必須是連續的,其次,你還必須知道特徵值。
如此苛刻的要求,在實際應用中是不可能滿足的。
第二次優化
說起資料庫查詢優化,第一時間想到的就是索引,所以便有了第二次優化:先查找出需要數據的索引列(假設為 id),再通過索引列查找出需要的數據。
Select * From table_name Where id in (Select id From table_name where ( user = xxx )) limit 10000, 10;
select * from table_name where( user = xxx ) limit 10000,10
相比較結果是(500w條數據):第一條花費平均耗時約為第二條的 1/3 左右。
同樣是較大的 offset,第一條的查詢更為複雜,為什麼性能反而得到了提升?
這涉及到 mysql 主索引的數據結構 b+Tree ,這裡不展開,基本原理就是:
- 子查詢只用到了索引列,沒有取實際的數據,所以不涉及到磁碟IO,所以即使是比較大的 offset 查詢速度也不會太差。
- 利用子查詢的方式,把原來的基於 user 的搜索轉化為基於主鍵(id)的搜索,主查詢因為已經獲得了準確的索引值,所以查詢過程也相對較快。
第三次優化
在數據量大的時候 in 操作的效率就不怎麼樣了,我們需要把 in 操作替換掉,使用 join 就是一個不錯的選擇
select \* from table_name inner join ( select id from table_name where (user = xxx) limit 10000,10) b using (id)
至此 limit 在查詢上的優化就告一段落了。如果還有更好的優化方式,歡迎留言告知
最終優化
技術上的優化始終是有天花板的,業務的優化效果往往更為顯著。
比如在本例中,因為數據的時效性,我們最終決定,只提供最近15天內的操作日誌,在這個前提下,偏移值 offset 基本不會超過一萬,這樣一來,即使是沒有經過任何優化的 sql,其執行效率也變得可以接受了,所以優化不能局限於技術層面,有時候對需求進行一下調整,可能會達到意想不到的效果