字節跳動流式數據集成基於Flink Checkpoint兩階段提交的實踐和優化
背景
字節跳動開發套件數據集成團隊(DTS ,Data Transmission Service)在字節跳動內基於 Flink 實現了流批一體的數據集成服務。其中一個典型場景是 Kafka/ByteMQ/RocketMQ -> HDFS/Hive 。Kafka/ByteMQ/RocketMQ -> HDFS/Hive(下面均稱之為 MQ dump,具體介紹可見 字節跳動基於Flink的MQ-Hive實時數據集成 ) 在數倉建設第一層,對數據的準確性和實時性要求比較高。
目前字節跳動中國區 MQ dump 例行任務數巨大,日均處理流量在 PB 量級。巨大的任務量和數據量對 MQ dump 的穩定性以及準確性帶來了極大的挑戰。
本文主要介紹 DTS MQ dump 在極端場景中遇到的數據丟失問題的排查與優化,最後介紹了上線效果。
線上問題
HDFS 集群某個元數據節點由於硬體故障宕機。在該元數據節點終止半小時後,HDFS 手動運維操作將 HDFS 切主到 backup 節點後,HDFS 恢復服務。故障恢復後用戶回饋 MQ dump 在故障期間有數據丟失,產出的數據與 MQ 中的數據不一致。
收到回饋後我們立即進行故障的排查。下面先簡要介紹一下 Flink Checkpoint 以及 MQ dump 寫入流程,然後再介紹一下故障的排查過程以及解決方案,最後是上線效果以及總結。
Flink Checkpoint 簡介
Flink 基於 Chandy-Lamport 分散式快照演算法實現了 Checkpoint 機制,能夠提供 Exactly Once 或者 At Least Once 語義。
Flink 通過在數據流中注入 barriers 將數據拆分為一段一段的數據,在不終止數據流處理的前提下,讓每個節點可以獨立創建 Checkpoint 保存自己的快照。每個 barrier 都有一個快照 ID ,在該快照 ID 之前的數據都會進入這個快照,而之後的數據會進入下一個快照。
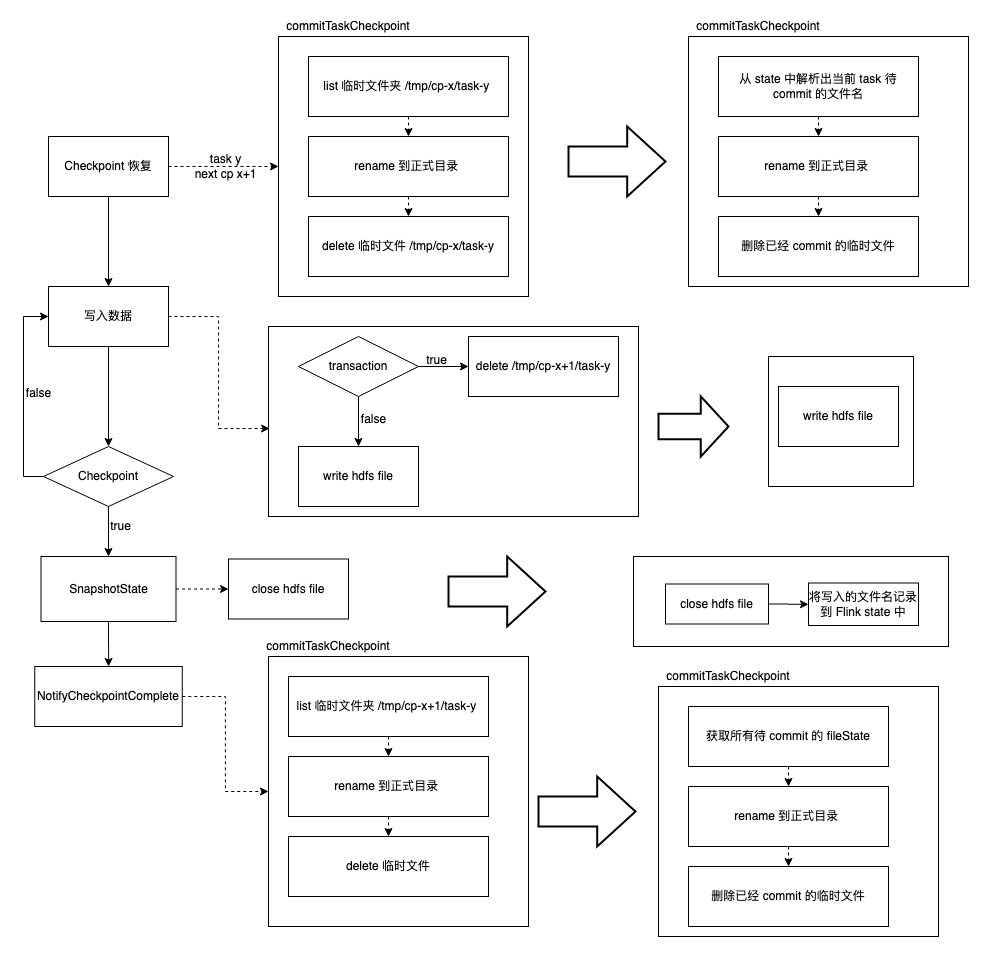
Checkpoint 對 Operator state 進行快照的流程可分為兩個階段:
- Snapshot state 階段:對應 2PC 準備階段。Checkpoint Coordinator 將 barries 注入到 Source Operator 中。Operator 接收到輸入 Operator 所有並發的 barries 後將當前的狀態寫入到 state 中,並將 barries 傳遞到下一個 Operator。
- Notify Checkpoint 完成階段:對應 2PC 的 commit 階段。Checkpoint Coordinator 收到 Sink Operator 的所有 Checkpoint 的完成訊號後,會給 Operator 發送 Notify 訊號。Operator 收到訊號以後會調用相應的函數進行 Notify 的操作。
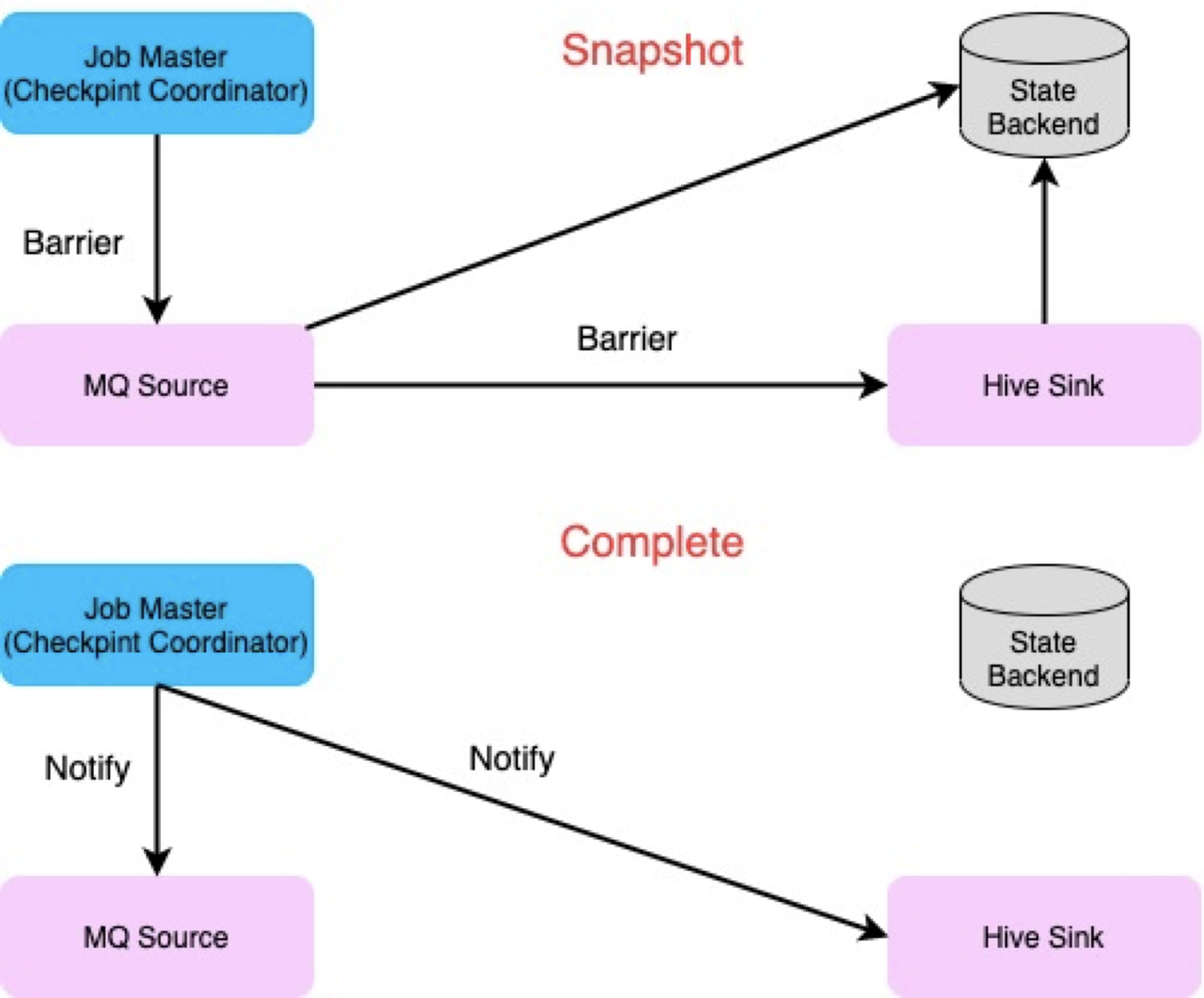
而在任務失敗後,任務會從上一個 Checkpoint state 中進行恢復,進而實現 Exactly Once 或者 At Least Once 語義。

MQ dump 寫入流程梳理
MQ dump 利用 Flink Checkpoint 機制和 2PC(Two-phase Commit) 機制實現了 Exactly Once 語義,數據可以做到不重不丟。
根據 Flink Checkpoint 的流程,MQ dump 整個寫入過程可以分為四個不同的流程:
- 數據寫入階段
- SnapshotState 階段
- Notify Checkpoint 完成階段
- Checkpoint 恢復階段
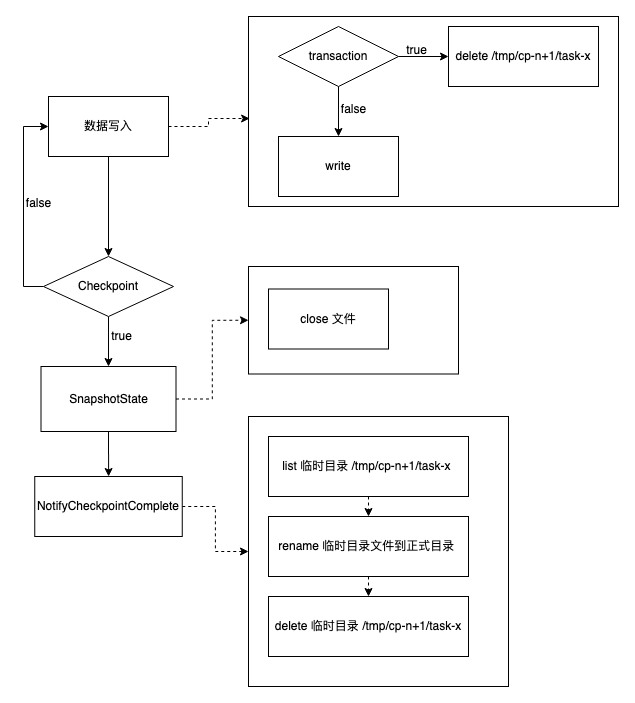
整個流程可以用下面的流程圖表示:
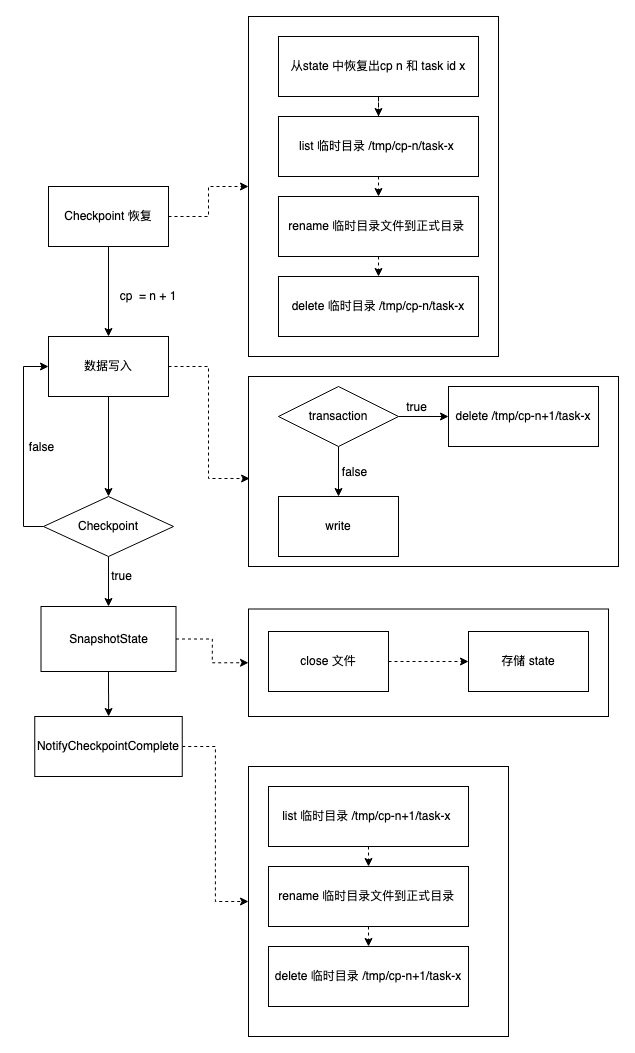
下面詳細介紹上面各個階段的主要操作。假設 Flink 任務當前 Checkpoint id 為 n,當前任務的 task id 為x。
數據寫入階段
寫入階段就主要有以下兩個操作:
- 如果是當前 Checkpoint 第一次寫入(transaction),先清理要寫入臨時文件夾 /tmp/cp-n/task-x
- 在臨時文件夾中建立文件並寫入數據
注意在寫入數據之前我們會先清理臨時目錄。執行這個操作的原因是我們需要保證最終數據的準確性:
假設任務 x 在 Checkpoint n 寫入階段失敗了(將部分數據寫入到臨時文件夾 /tmp/cp-n/task-x),那麼任務會從上一個 Checkpoint n-1 恢復,下一個寫入的 Checkpoint id 仍然為 n。如果寫入前不清理臨時目錄,失敗前遺留的部分臟文件就會保留,在 Checkpoint 階段就會將臟文件移到正式目錄中。
SnapshotState 階段
SnapshotState 階段對應 2PC 的兩個階段中的第一個階段。主要操作是關閉正在寫入的文件,並將任務的 state (主要是當前的 Checkpoint id 和 task id)存儲起來。
Notify Checkpoint 完成階段
該階段對應 2PC 兩個階段中的第二個階段。主要操作如下:
- List 臨時目錄文件夾 /tmp/cp-n/task-x
- 將臨時目錄文件夾下的所有文件 rename 到正式目錄
- 刪除臨時目錄文件夾 /tmp/cp-n/task-x
Checkpoint 恢復階段
Checkpoint 恢復階段是任務在異常場景下,從輕量級的分散式快照恢復階段。主要操作如下:
- 從 Flink state 中恢復出任務的 Checkpoint id n 和 任務的 task id x
- 根據 Checkpoint id 和 任務的 task id x 獲取到臨時目錄文件夾 /tmp/cp-n/task-x
- 將臨時目錄文件夾下的所有文件 rename 到正式目錄
- 刪除臨時目錄文件夾 /tmp/cp-n/task-x
故障排查過程
了解完相關寫入流程後,我們回到故障的排查。用戶任務配置的並發為 8,也就是說執行過程中有 8 個task在同時執行。
Flink 日誌查看
排查過程中,我們首先查看 Flink Job manager 和 Task manager 在 HDFS 故障期間的日誌,發現在 Checkpoint id 為 4608 時, task 2/3/6/7 都產出了若干個文件。而 task 0/1/4/5 在 Checkpoint id 為 4608 時,都由於某個文件被刪除造成寫入數據或者關閉文件時失敗,如 task 0 失敗是由於文件 /xx/_DUMP_TEMPORARY/cp-4608/task-0/date=20211031/18_xx_0_4608.1635674819911.zstd 被刪除而失敗。
但是查看正式目錄下相關文件的資訊,我們發現 task 2、3 兩個 task 並沒有 Checkpoint 4608 的文件(文件名含有 task id 和 Checkpoint id 資訊,所以可以根據正式目錄下的文件名知道其是哪個 task 在哪個 Checkpoint 期間創建的)。故初步確定的原因是某些文件被誤刪造成數據丟失。 Task 2/3/6/7 在文件刪除後由於沒有文件的寫入和關閉操作,task 正常運行;而 task 0/1/4/5 在文件刪除後還有文件的寫入和關閉操作,造成 task 失敗。
HDFS 元數據查看
下一步就要去排查文件丟失的原因。我們通過 HDFS trace 記錄表( HDFS trace記錄表記錄著用戶和系統調用行為,以達到分析和運維的目的)查看 task 2 Checkpoint 4608 臨時目錄操作記錄,對應的路徑為 /xx/_DUMP_TEMPORARY/cp-4608/task-2。
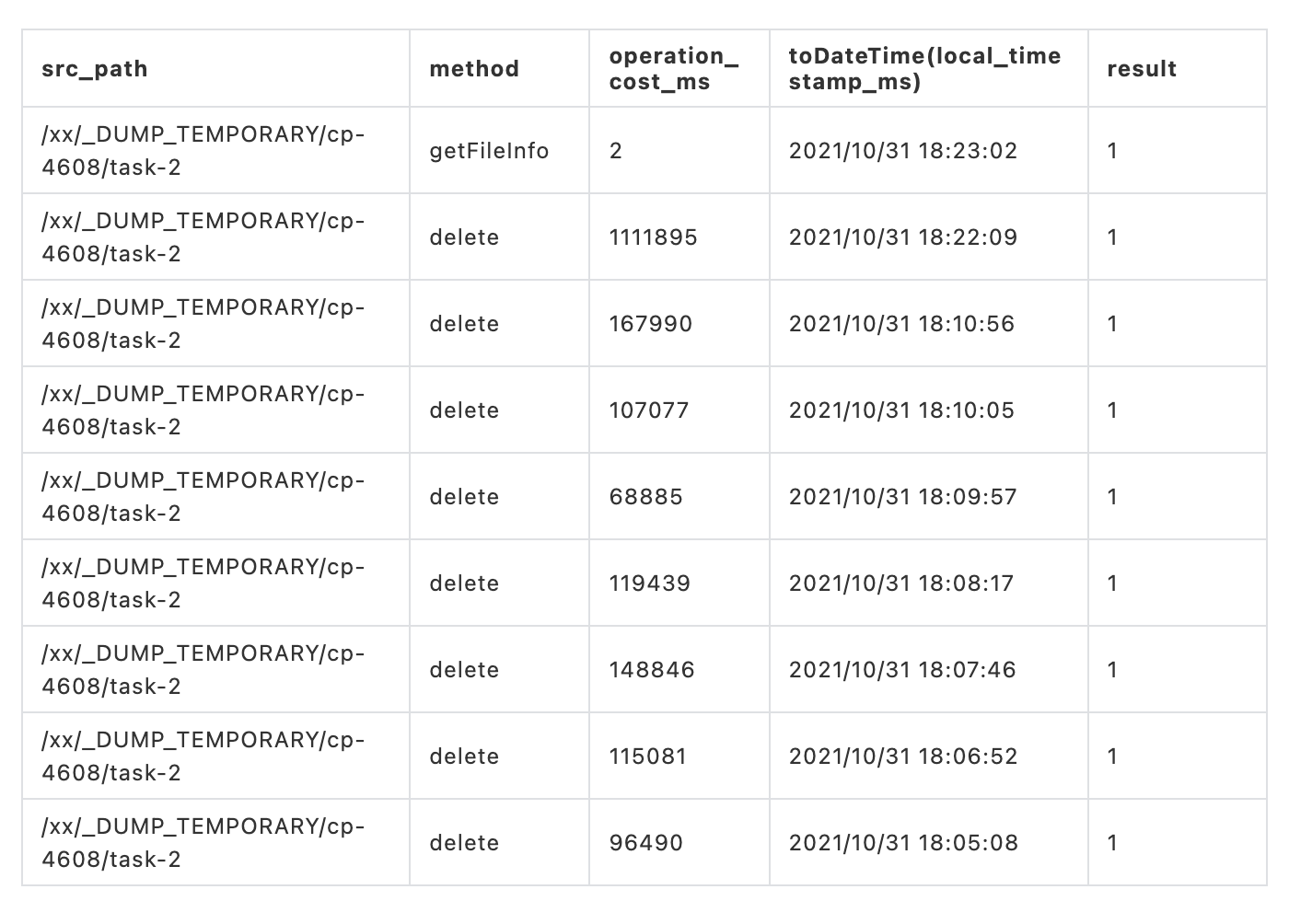
從 HDFS trace 操作記錄中可以發現文件夾的刪除操作執行了很多次。
然後再查詢 task 2 Checkpoint 4608 臨時目錄下的文件操作記錄。可以看出在 2021-10-31 18:08:58 左右實際有創建兩個文件,但是由於刪除操作的重複執行造成創建的兩個文件被刪除。
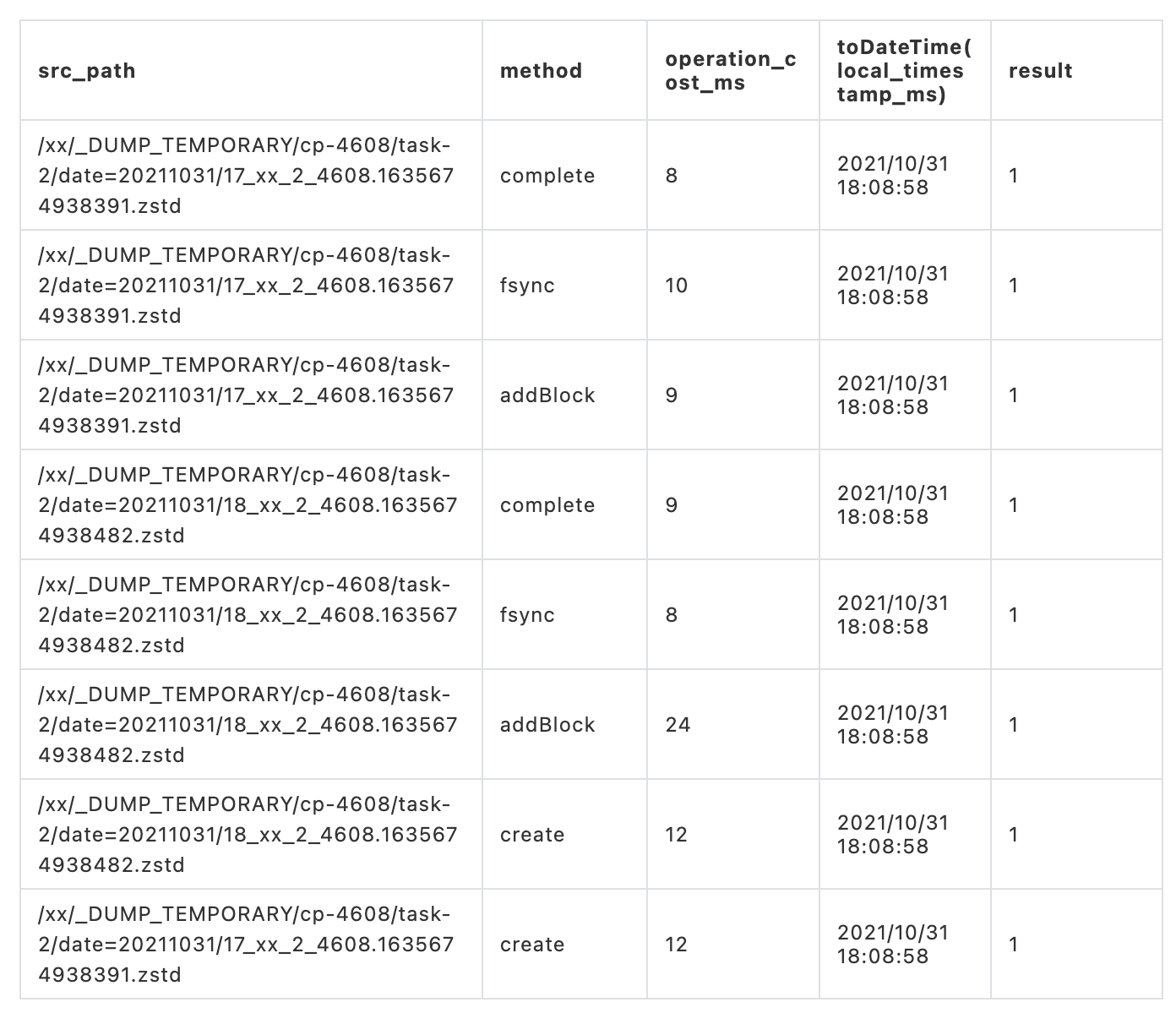
問題的初步原因已經找到:刪除操作的重複執行造成數據丟失。
根本原因
我們對以下兩點感覺比較困惑:一是為啥刪除操作會重複執行;二是在寫入流程中,刪除操作要不是發生在數據寫入之前,要不發生在數據已經移動到正式目錄之後,怎麼會造成數據丟失。帶著疑惑,我們進一步分析。
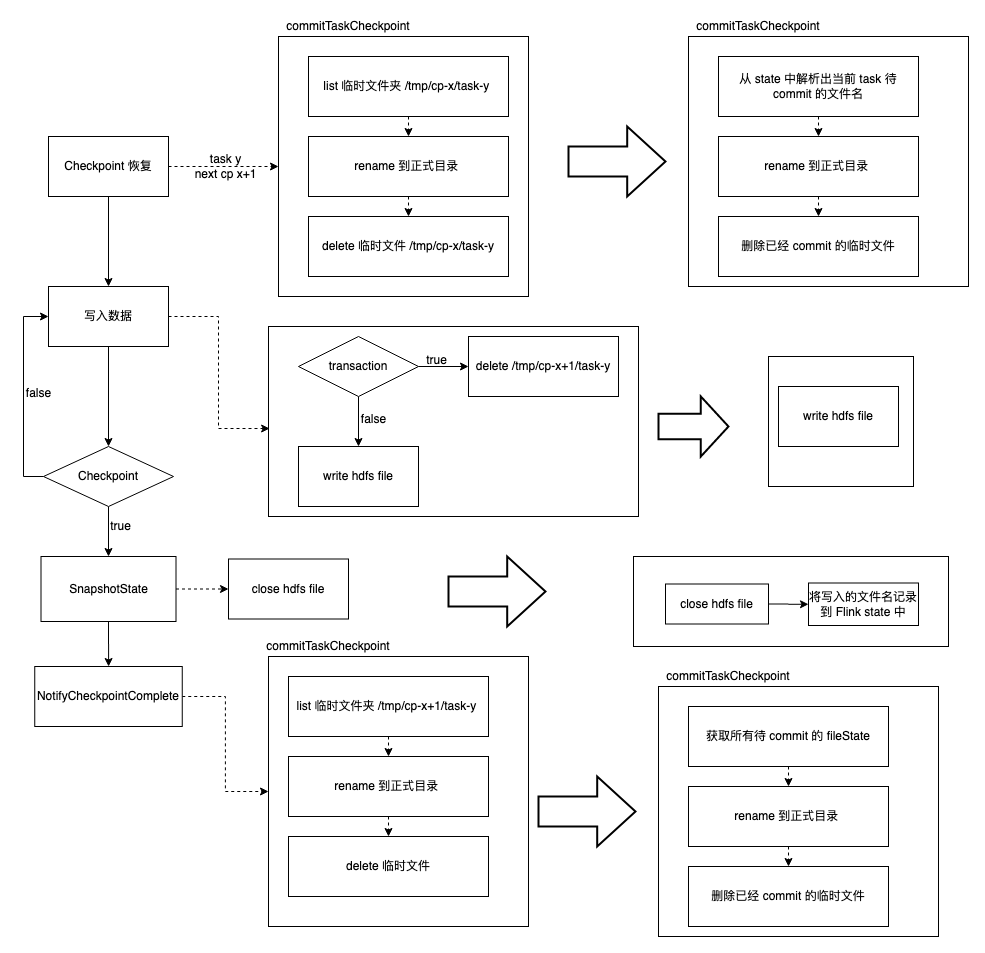
忽略 Flink Checkpoint 的恢複流程以及 Flink 狀態的操作流程,只保留與 HDFS 交互的相關步驟,DTS MQ dump 與 HDFS 的操作流程可以簡化為如下流程圖:
在整個寫入流程中涉及到 delete 的操作有兩個地方:一個是在寫入文件之前;一個是在將臨時文件重命名到正式目錄之後。在第二個刪除操作中,即使刪除操作重複執行,也不影響最終數據的準確性。因為在之前的重命名過程中已經將所有數據從臨時文件夾移動到正式目錄。
所以我們可以確定是在寫入文件之前的刪除操作的重複執行造成最終的數據丟失。
在 task-2 的日誌中我們發現 HDFS client 在 18:03:37-18:08:58 一直在嘗試調用 HDFS 刪除介面刪除臨時目錄,但是由於java.net.SocketTimeoutException 一直刪除失敗。在時間點18:08:58 刪除操作執行成功。而這個時間點也基本與我們在 HDFS trace 數據中發現刪除操作的執行記錄時間是對應的。通過日誌我們發現建立文件以及關閉文件操作基本都是在 18:08:58 這個時間點完成的,這個時間點與 HDFS trace 中的記錄也是對應上的。
諮詢 HDFS 後,HDFS 表示 HDFS 刪除操作不會保證冪等性。進而我們判斷問題發生的根源為:在故障期間,寫入數據前的刪除操作的多次重試在 HDFS NameNode 上重複執行,將我們寫入的數據刪除造成最終數據的丟失。如果重複執行的刪除操作發生在文件關閉之前,那麼 task 會由於寫入的文件不存在而失敗;如果重複刪除命令是在關閉文件之後,那麼就會造成數據的丟失。
解決方案
MQ dump 在異常場景中丟失數據的本質原因是我們依賴刪除操作和寫入操作的順序性。但是 HDFS NameNode 在異常場景下是無法保證兩個操作的順序性。
方案一:HDFS 保證操作的冪等性
為了解決這個問題,我們首先想到的是 HDFS 保證刪除操作的冪等性,這樣即使刪除操作重複執行也不會影響後續寫入的問題,進而可以保證數據的準確性。但是諮詢 HDFS 後,HDFS 表示 HDFS在現有架構下無法保證刪除的冪等性。
參考 DDIA (Designing Data-Intensive Applications) 第 9 章中關於因果關係的定義:因果關係對事件施加了一種順序——因在果之前。對應於MQ dump 流程中刪除操作是因,發生在寫入數據之前。我們需要保證這兩個關係的因果關係。而根據其解決因果問題的方法,一種解決思路是 HDFS 在每個client 請求中都帶上序列號順序,進而在HDFS NameNode 上可以保證單個client的請求因果性。跟HDFS 討論後發現這個方案的實現成本會比較大。
方案二:使用文件 state
了解 HDFS 難以保證操作的冪等性後,我們想是否可以將寫入前的刪除操作去除,也就是說在寫入 HDFS 之前不清理文件夾而是直接寫入數據到文件,這樣就不需要有因果性的保證。
如果我們知道臨時文件夾中哪些文件是我們需要的,在重命名階段就可以直接將需要的文件重命名到正式目錄而忽略臨時文件夾中的臟文件,這樣在寫入之前就不需要刪除文件夾。故我們的解決方案是將寫入的文件路徑存儲到 Flink state 中,從而確保在 commit 階段以及恢復階段可以將需要的文件移動到正式目錄。
最終,我們選擇了方案二解決該問題,使用文件 state 前後處理流程對比如下圖所示:
目前文件 state 已經在線上使用了,下面先介紹一下實現中碰到的相關問題,然後再描述一下上線後效果。
文件 state 實現細節
文件移動冪等性
通過文件 state 我們可以解析出當前文件所在的臨時目錄以及將要寫入的正式目錄。通過以下流程我們保證了移動的冪等性。
通過以上的流程即使文件移動失敗,再次重試時也能夠保證文件移動的冪等性。
可觀測性
實現文件 state 後,我們增加了 metric 記錄創建的文件數量以及成功移動到正式目錄的文件數量,提高了系統可觀測性。如果文件在臨時目錄和正式目錄都不存在時,我們增加了移動失敗的 metric ,並增加了報警,在文件移動失敗後可以及時感知到,而不是等用戶報告數據丟失後再排查。
上線後線上 metric 效果如下:

總共有四個指標,分別為創建文件的數量、重命名成功文件的數量、忽略重命名文件的數量、重命名失敗的文件數量,分別代表的意義如下:
- 創建文件的數量:state 中所有文件的數量,也就是當前 Checkpoint 處理數據階段創建的所有文件數量。
- 重命名成功文件的數量:NotifyCheckpointComplete 階段將臨時文件成功移動到正式目錄下的文件數量。
- 忽略重命名文件的數量:NotifyCheckpointComplete 階段忽略移動到正式目錄下下的文件數量。也就是臨時文件夾中不存在但是正式目錄存在的文件。這種情況通常發生在任務有 Failover 的情況。 Failover 後任務從 Checkpoint 中恢復,失敗前已經重命名成功的文件在當前階段會忽略重命名。
- 重命名失敗的文件數量:臨時目錄以及正式目錄下都不存在文件的數量。這種情況通常是由於任務發生了異常造成數據的丟失。目前線上比較常見的一個 case 是任務在關閉一段時間後再開啟。由於 HDFS TTL 的設置小於任務關閉的時長,臨時目錄中寫入的文件被 HDFS TTL 策略清除。這個結果實際是符合預期的。
前向兼容性
預期中上線文件 state 後寫入數據前不需要刪除要寫入的臨時文件,但是為了保證升級後的前向兼容性,我們分兩期上線了文件 state :
- 第一期寫入數據前保留了刪除操作
- 第二期刪除了寫入數據前的刪除操作
第一期保留刪除操作的原因如果文件 state 上線後有異常的話,回滾到之前的版本需要保證數據的準確性。而只有保留刪除操作才能保證回滾後數據的準確性。否則如果之前的 Checkpoint 文件夾中有臟文件存在,回滾到文件 state 之前的版本的話,由於沒有文件 state 存在,會將臟文件也移動到正式目錄中,影響最終數據的準確性。
上線效果
切主演練
上線後與 HDFS 進行了 HDFS 集群切主演練。演練了以下兩個場景:
- HDFS 集群正常切主
- HDFS 集群主節點失敗超過10分鐘
而測試過程是建立兩組不同的任務消費相同的 Kafka topic,寫入不同的 Hive 表。然後建立數據校驗任務校驗兩組任務數據的一致性。一組任務使用 HDFS 測試集群,另一組任務使用正常集群。
將測試集群進行多次 HDFS 正常切主和異常切主,校驗任務顯示演練結束前後兩組任務寫入數據的一致性。結果驗證了該方案可有效解決 HDFS 操作非冪等的丟數問題。
性能效果
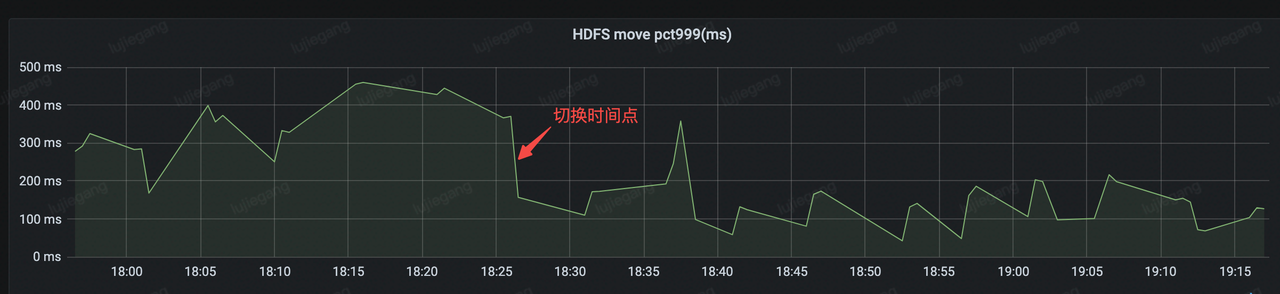
使用文件 state 後,在 Notify Checkpoint 完成階段不需要調用 HDFS list 介面,可以減少一次 HDFS 調用,理論上可以減少 Notify Checkpoint 階段與 HDFS 交互時間。下圖展示了上線(18:26 左右)前後 Notify 階段與 HDFS 交互的 metrics。可以看出上線前的平均處理時間在 300ms 左右,而上線後平均處理時間在 150 ms 左右,減少了一半的處理時間。
總結
隨著字節跳動產品業務的快速發展,字節跳動一站式大數據開發平台功能也越來越豐富了,提供了離線、實時、增量等場景下全域數據集成解決方案。而業務數據量的增大以及業務的多樣化給數據集成帶來了很大的挑戰。比如我們擴展了添加 Hive 分區的策略,以支援實時數倉近實時 append 場景,使數據的使用延遲下降了 75% 。
字節跳動流式數據集成仍在不斷發展中,未來主要關注以下幾方面:
- 功能增強,增加簡單的數據轉換邏輯,縮短流式數據處理鏈路,進而減少處理時延
- 架構升級,離線集成和實時數據集成架構統一
- 支援 auto scaling 功能,在業務高峰和低峰自動擴縮容,提高資源利用率,減少資源浪費
本文中介紹的《字節跳動流式數據集成基於Flink Checkpoint兩階段提交的實踐和優化》,目前已通過火山引擎數據產品大數據研發治理套件 DataLeap 向外部企業輸出。
大數據研發治理套件 DataLeap 作為一站式大數據中台解決方案,可以實現全場景數據整合、全鏈路數據研發、全周期數據治理、全方位數據安全。
參考文獻
- 字節跳動基於Flink的MQ-Hive實時數據集成
- 字節跳動單點恢復功能及 Regional CheckPoint 優化實踐
- Designing Data-Intensive Applications
- Stateful Stream Processing
歡迎關注字節跳動數據平台同名公眾號


