Redis(一):基本數據類型與底層存儲結構
最近在整理有關redis的相關知識,對於redis的基本數據類型以及其底層的存儲結構簡要的進行匯總和備註(主要為面試用 )
)
Redis對外提供的基本數據類型主要為五類,分別是
- STRING:可以存儲字元串、數字
- LIST:列表,鏈表的每個節點存儲一個字元串對象
- HASH:包含鍵值對的無需散列表
- SET:無序集合,集合中包含的是不重複的集合對象
- ZSET:有序集合,是有一對一對字元串成員-浮點數分值所構成的有序映射,排序規則由分值大小所決定
以上是我們在使用Redis的時候經常見到的五種數數據結構,這五種數據結構在底層存儲上又有著千絲萬縷的聯繫;例如字元串對象作為一個最基本的存儲對象,其在上午五種數據結構中均有應用,那麼具體在Redis底層數據結構中是如何構造這五種數據結構的,本文將對底層存儲做深入解析。
文章中所描述的數據結構大都基於2.9版本,如有描述不對還請留言指正,萬分感謝
一、STRING
字元串對象根據保存值的類型、長度不同,可以分為三種存儲結構
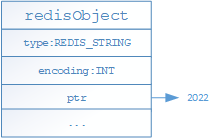
- 如果存儲的是整數值(可以用long表示),則底層通過如下結構進行存儲,其中type代表當前對象為STRING對象,encoding表示當前對象的編碼格式,ptr的屬性保存是真實的值;
舉例: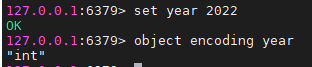
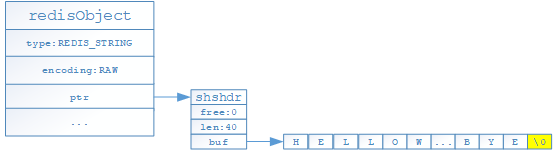
- 如果存儲的是字元串且字元串長度超過39位元組,則底層通過如下結構進行存儲,其中type代表當前對象為STRING對象,encoding表示當前對象的編碼格式,ptr為指針指向一個SDS(shshdr:簡單動態字元串對象)來保存具體的值;
舉例:
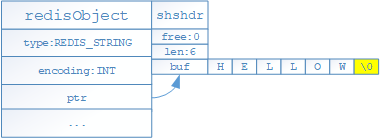
- 如果存儲的是字元串且字元串長度未超過39位元組,則底層通過如下結構進行存儲(需要一塊連續的記憶體空間),其中type代表當前對象為STRING對象,encoding表示當前對象的編碼格式,ptr為指針指向一個SDS(shshdr:簡單動態字元串對象)來保存具體的值;
舉例: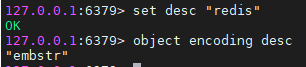
- 存儲結構差異
- embstr需要一塊連續的記憶體空間,因此其效率上比raw方式要高
- emstr在記憶體分配以及記憶體釋放時只需要一次介面,而raw方式需要兩次(因為存在redisObject和shshdr兩個對象)
- embstr為只讀對象,任何對embstr編碼對象的修改都會導致對象的編碼格式變為raw
- int/embstr編碼格式的字元串對象在滿足一定條件後會自動轉為raw編碼格式
- 字元串對象常用的命令
| 命令 | 作用 | 備註 |
| set | 設置key的值 | 根據值不同底層會採用三種不同的編碼進行存儲 |
| get | 獲取字元串對象值 | 對於int編碼格式有個值拷貝-轉換的過程 |
| append | 在現有字元串值後面追加新的值 | int/embstr編碼格式對象會先轉換為raw後在執行追加操作 |
| incrbyfloat | 對浮點型數值進行加法操作 | |
| incrby | 對整數型數值進行加法操作 | embstr/raw不能執行此命令 |
| decrby | 對整數型數值進行減法操作 | embstr/raw不能執行此命令 |
| strlen | 返回字元串長度 | int編碼格式需要拷貝對象並轉換為raw格式後在執行操作 |
| setrange | 在字元串指定索引上的值設置為給定值 | int/embstr需要轉換為raw後在執行操作 |
| getrange | 返回字元串指定索引的值 | int編碼格式需要拷貝對象並轉換為raw格式後在執行操作 |
二、LIST
列表對象根據存儲數據的長度以及存儲數據元素個數的不同,可以分為兩種存儲結構:
- 如果列表對象保存的所有字元串對象值的長度均未超過64位元組且列表對象保存元素數量小於512個的時候,就採用ziplist(壓縮列表)格式存儲
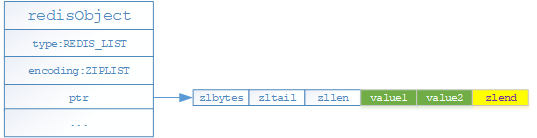
- 如果列表對象保存的所有字元串對象值的長度有超過64位元組或者列表對象保存元素數量大於等於512個的時候,就採用linkedlist(雙端鏈表)格式存儲
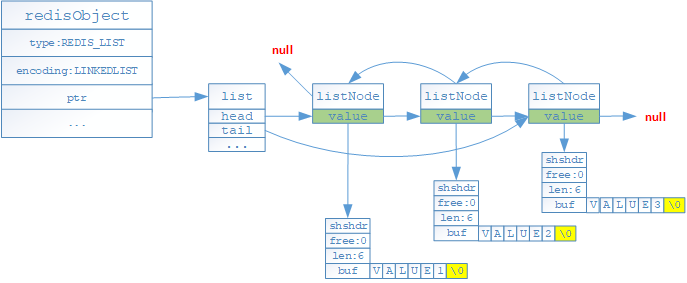
- 存儲結構差異
- 壓縮列表是有一系列特殊編碼的連續記憶體塊組成的順序型數據結構,而雙端鏈表則不需要連續的記憶體塊
- 壓縮列表的每個節點是由三部分組成(previous_entry_length/encoding/content),其中previous_entry_length是記錄前一個節點的長度,以便程式可以通過任意節點的指針計算出前一個節點的起始位置;而雙端鏈表則必須通過頭尾節點進行遍歷獲取
- 由於previous_entry_length屬性會隨著前一個節點的位元組長度不同而存儲1或者5位元組,如果新增的頭結點長度大於254位元組,會導致當前頭結點的previous_entry_length(假設當前節點的previous_entry_length為1)的長度無法保存新節點的長度,此時程式會對原頭節點進行記憶體空間重新分配,最壞的情況是新增的頭結點導致原列表中的所有元素全部重新分配;而雙端鏈表則不會存在該問題;因此在使用列表對象時要考慮連鎖更新的問題;
三、HASH
哈希對象根據存儲鍵值對數據長度以及鍵值對數量,可以分為兩種存儲結構:
- 如果hash對象保存的所有鍵值對的字元串長度小於64直接且鍵值對數量小於512個,採用ziplist(壓縮列表)編碼存儲

key-value總是以成對的方式存在,存儲順序類似於棧,先添加的鍵值對會存在列表的前面,後添加的會在列表的尾部;
- 如果hash對象保存的鍵值對的字元串長度有超過64位元組或者鍵值對數量大於等於512個,將採用hashtable編碼存儲
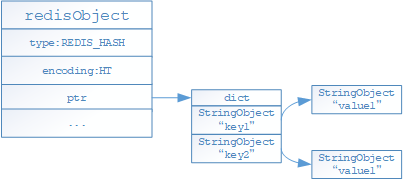
- 上述存儲格式會隨著存儲的內容變化進行編碼格式轉變,轉變只能從ziplist轉換為hashtable
四、SET
集合對象根據存儲數據的長度以及存儲數據元素類型的不同,可以分為兩種存儲結構:
- 如果列表對象保存的所有元素均是整數型且保存元素數量不超過512個的時候,就採用intset編碼存儲
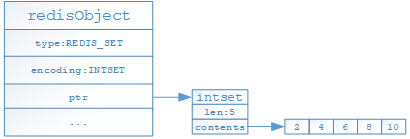
- 如果列表對象保存的元素有不是整數型或者保存元素數量超過512個的時候,就採用hashtable編碼存儲
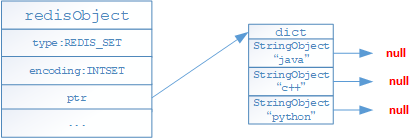
- 上述存儲格式會隨著存儲的內容變化進行編碼格式轉變,轉變只能從intset轉換為hashtable
- 在實際使用過程中,需要提前規劃好存儲數據內容,盡量不要出現編碼格式轉換
五、ZSET
有序集合對象根據數據元素數量以元素成員長度,可以分為兩種存儲結構:
- 如果有序集合對象保存的元素數量小於128個且有序結合對象保存的元素成員的長度都小於64位元組,就採用ziplist(壓縮列表)編碼存儲
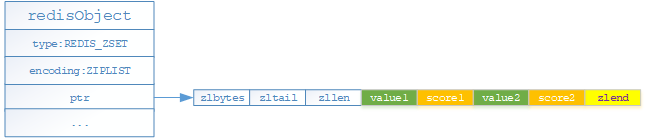
使用壓縮列表的有序結合中每個對象由兩個節點構成,第一個節點保存元素的具體值,第二個節點保存元素的分值;默認情況元素是按照分值從小到大排序;
- 如果有序集合對象保存的元素數量>=128個或有序結合對象保存的元素成員的長度存在>=64位元組,就採用skplist(跳躍表【詳細請參見:演算法-跳躍表原理與實現】)和dict編碼存儲
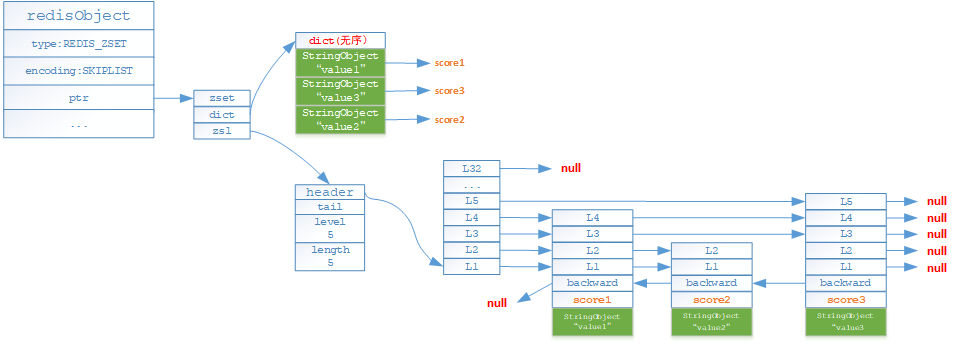
為了兼顧查找與範圍查找,有序集合需要同時使用跳躍表與字典
- 字典可以保證O(1)複雜度直接根據指定key查找成員值
- 跳躍表可以在O(logN)的複雜度下完成範圍查找,遠遠優於字典的O(NlogN)
在底層存儲上,針對相同的數據對象以及分值,跳躍表與字典會通過指針進行共享,因此不會產生較多的記憶體浪費
六、總結
Redis對外提供的是上述五種數據類型,但是在底層構造這五種數據類型時,底層實際上使用了包括「簡單動態字元串」、「鏈表」、「字典」、「跳躍表」、「整數集合」、「壓縮列表」來構造
根據存儲數據的類型、長度以及數量,不同存儲格式之間可以進行動態轉換,有的存儲結構體現是查詢速度,有的存儲介面體現的空間佔用
STRING |
INT |
| embstr | |
| raw | |
| LIST | ziplist |
| linkedlist | |
| HASH | ziplist |
| ht | |
| SET | intset |
| ht | |
| ZSET | ziplist |
| skiplist |


