從讀寫角度,帶你了解數倉的IO基本框架
摘要:本文從讀取和寫入的角度分別描述了行存和列存的IO模型,並對文件結構做了簡單介紹。
本文分享自華為雲社區《GaussDB(DWS)基本IO框架》,作者: Naibaoofficial。
行存IO管理框架
存儲結構
- OID(Object identifiers):對象的唯一標識。
- 每個表存在對應資料庫的文件夾中,用relfilenode標識。
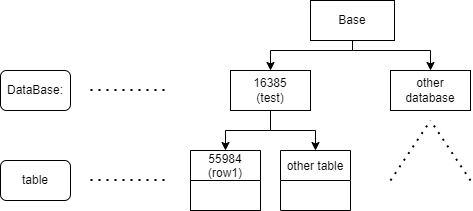
例如表row1,可以直接查詢對應的文件
test=# select pg_relation_filepath('row1'); pg_relation_filepath ---------------------- base/16385/55984 (1 row)
- 每個表的讀取寫入以頁(文件塊)為基本單位,頁的大小是一個BLCKSZ,默認8KB,其結構如下:
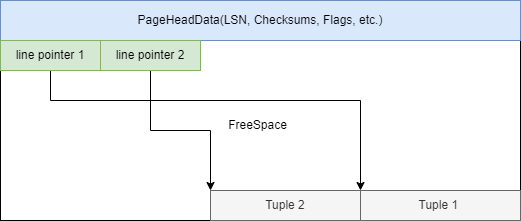
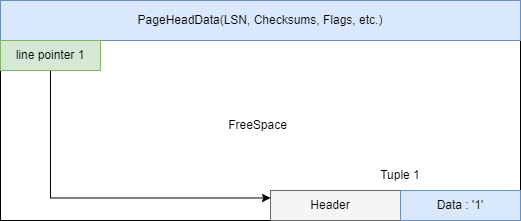
- Tuple保存了當前一行的數據,分為Header和Data兩塊,頭部保存元組的相關資訊(列數,事務資訊,是否有Toast表等)。
- 每個Tuple最大為2kb,若Data過大無法壓縮至2KB,則採用額外的Toast表存儲,此時Tuple內的Data保存Toast表的相關資訊。
GaussDB 行存框架:
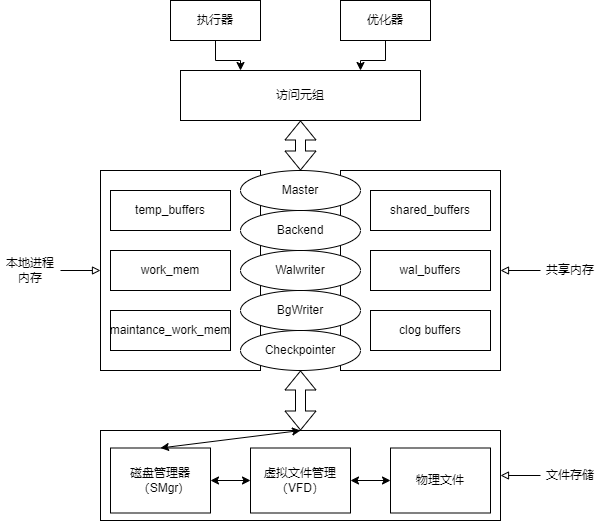
這裡面涉及到幾個比較大的內核機制:
- 本地快取:
這裡面的本地快取介紹了三個比較常用的快取結構,這裡直接引用了官方的英文解釋。
temp_buffers: Sets the maximum number of temporary buffers used by each database session. These are session-local buffers used only for access to temporary tables.
work_mem: Specifies the amount of memory to be used by internal sort operations and hash tables before writing to temporary disk files.
maintenance_work_mem: Specifies the maximum amount of memory to be used by maintenance operations, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY.
- 共享記憶體:可由整個Gaussdb共享
包括shared_buffer和wal_buffer, 分別用來存放Page和Clog,Wal Segment。
- WalWriter,BgWriter:
主要是將共享記憶體的內容落盤,WalWriter一般是在事務提交時就需要落盤,但是有時候可以放棄一定的事務一致性原則,從而讓WalWriter非同步落盤加快速度。BgWriter負責將shared_buffer中的內容落盤。
- 外存管理:
負責上層與外存之間的文件交互。
IO管理框架:讀取
讀取的過程相對簡單,就是從物理文件先裝到shared_buffer中,然後從shared_buffers返回相關的結果。
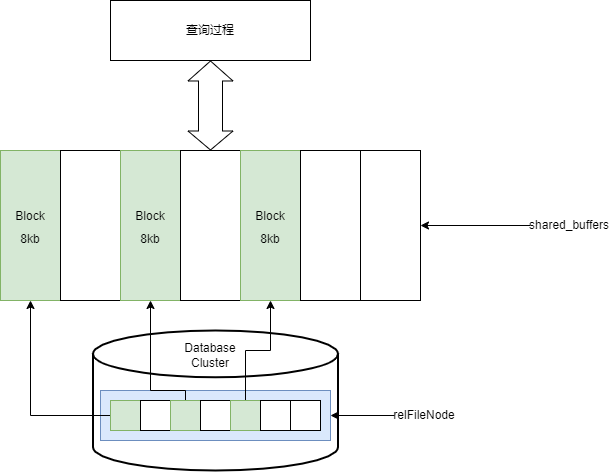
shared_buffers中就是以Page為單位進行存儲的,因為每個Page的大小是固定的,所以shared_buffers能存放的page個數也就是確定的。這裡面就需要考慮一個問題,因為這個資源是共享的,如果一個執行緒讀取了大量的文件,這樣勢必會使得其他執行緒的快取命中率下降。
GaussDB在這裡引入了Ringbuffer的機制,可以限制一個執行緒所使用的shared_buffers的大小,從而解決掉這個問題。
IO管理框架:寫入
- 寫入操作是增加的新的元組,Update操作相當於先Delete,再Insert。
- INSERT
- UPDATE
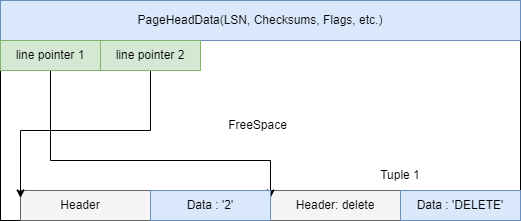
將舊元組標記為Dead,然後插入新的元組,由Vacuum負責清理。當然,這裡面Data變為DELETE只是用來描述刪除的是此Tuple,實際上Data當中的值是不變的。
- 寫入的整體邏輯:
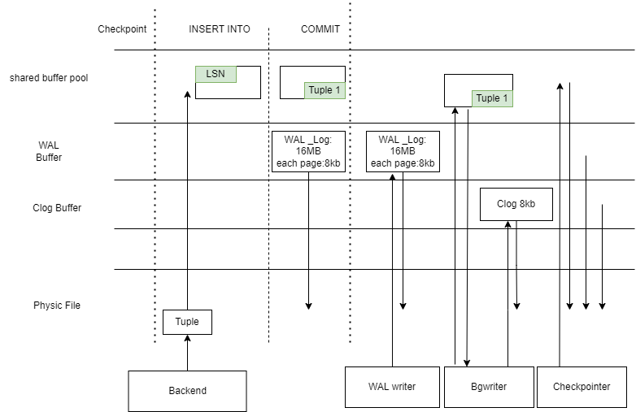
GaussDB行存在寫入時,將元組資訊先寫入到shared_buffers,然後用bgwriter刷入磁碟,這樣在事務提交時就可以避免磁碟的IO開銷,提升性能,為了保證一致性和恢復,使用wal日誌和checkpoints可以實現日誌先落盤(也可以非同步)和redo等操作。
列存的IO管理框架
列存的存儲單元
- 列存的存儲單元為CU(CStore Unit)
- CU的大小為8k對齊
- 適合大批量導入的場景
- 同一列的CU存在一個新文件中,大於1GB時,切換到新文件中。
- 列存用一個CUDesc的行存表描述CU的相關資訊,可以理解成為一個Toast表。
- CUDesc:行存表,記錄CU的相關資訊, 主要屬性如下:
- col_id,cu_id: 第col_id列,第cu_id個CU
- min, max, row_count, size
- cu_mode: information mask(RLE,LZ4,Delta表等)
- cu_pointer:指向每一個CU,記錄delete bitmap
- magic:和CU頭部的magic相同,校驗使用
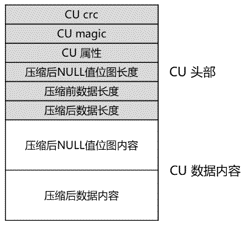
CU結構
列存索引
這裡介紹兩個索引,C-Btree和Psort,這裡不做過多介紹。
主要涉及的是IO相關的內容。
C-Btree
- 索引結構和行存無差別,同樣以行存形式存儲
- C-Btree可以提升點查效率
- 存儲key->ctid(cu_id, offset)
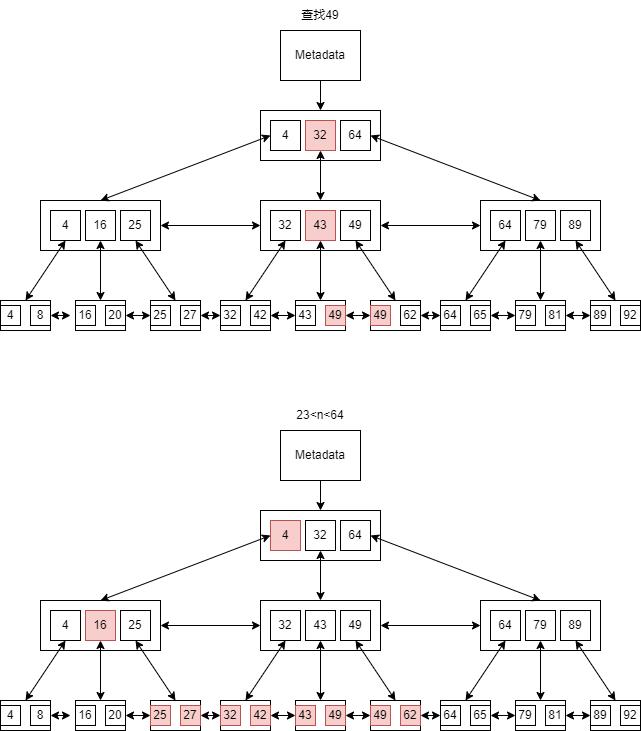
- 過程:
- 根據B-tree索引找到ctid集合
- 對集合進行批量排序(減少IO開銷)
- 在CUDesc找到對應的cu_id,根據offset找到數據
- 舉例,等值查詢 n=49, 範圍查詢 23<n<64。
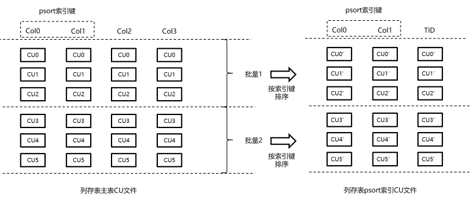
PSort
PSort是一個聚簇索引,對索引進行排序,然後將排序後的索引和行號存入一個新的表,用單獨的列存表存儲。
簡單示意如下,圖片來源://www.modb.pro/db/108155
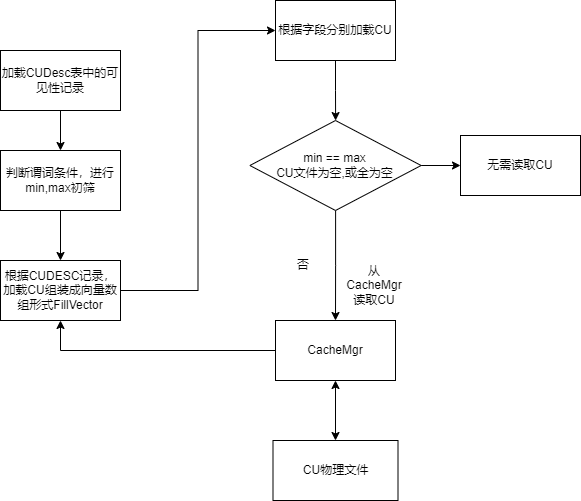
IO管理框架:讀取
- 讀取過程:
- 根據where條件,做MIN/MAX過濾的謂詞條件
- 載入CUDesc
- MIN/MAX過濾
- 讀取CU到CU Cache中
- 解析並填充
- CacheMgr: 用來快取CU到記憶體中,可以提高重複查詢的性能。
- CU的物理文件:
1. CStore_1.0: 當前基本不怎麼實用
2. CStore_2.0: 重整了CU的文件結構,避免列數過多導致文件結構複雜。
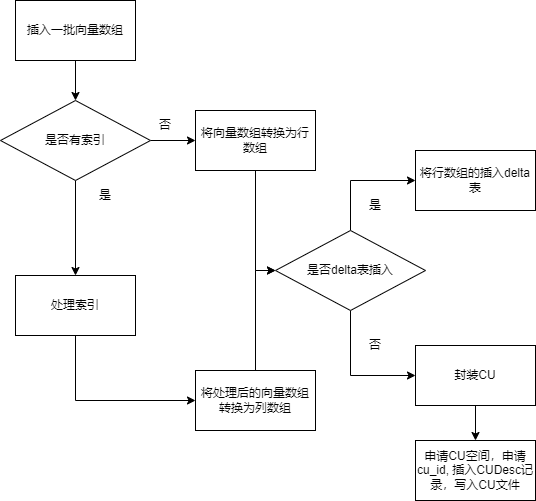
IO管理框架:寫入
列存的插入要分兩種情況,少量的插入和大量的插入,列存主要是對大批量數據設計的,因此為了彌補小量插入的打包CU性能開銷,設計了一個delta行存表,用來記錄插入結果,可以減少膨脹和提升性能,最後定期的整理。
- 寫入框架如下
列存的刪除比較簡單,如果是delta表,先從delta表中刪除滿足謂詞條件的記錄,然後在CUDesc表中更新待刪除CU的delete_bitmap。


