Nebula Graph 在企查查的應用

背景
企查查是企查查科技有限公司旗下的一款企業信用查詢工具,旨在為用戶提供快速查詢企業工商資訊、法院判決資訊、關聯企業資訊、法律訴訟、失信資訊、被執行人資訊、知識產權資訊、公司新聞、企業年報等服務。
為更好地展現企業之間的法律訴訟、風險資訊、股權資訊、董監高法等資訊,我們抽取結構化/非結構化的企業數據構建企業知識圖譜,為用戶提供真實可靠的服務。
圖資料庫選擇
在最初的時候,我們用的是 Neo4j HA cluster 作為存儲端。隨著數據和業務規模的不斷擴展,要求我們需要一個讀寫性能良好,分散式的圖資料庫作支撐。經過幾番調研,在 Dgraph、Nebula、Galaxybase、HugeGraph 中進行選擇,最終選擇了 Nebula Graph。
關於選型維度,我們相對側重社區活躍度、資料獲取難易程度、和最基本的讀寫、子圖查詢性能等方面。
具體的測評因為沒有社區其他用戶之前分享的文章那麼詳實,這裡就不展開了。這裡附上之前美團的測評鏈接:美團傳送門。
Nebula Graph 簡介
Nebula Graph 是什麼
Nebula Graph 是一款開源的、分散式的、易擴展的原生圖資料庫,能夠承載數千億個點和數萬億條邊的超大規模數據集,並且提供毫秒級查詢。
基於圖資料庫的特性使用 C++ 編寫的 Nebula Graph,可以提供毫秒級查詢。眾多資料庫中,Nebula Graph 在圖數據服務領域展現了卓越的性能,數據規模越大,Nebula Graph 優勢就越大。
Nebula Graph 採用 shared-nothing 架構,支援在不停資料庫服務的情況下擴縮容。
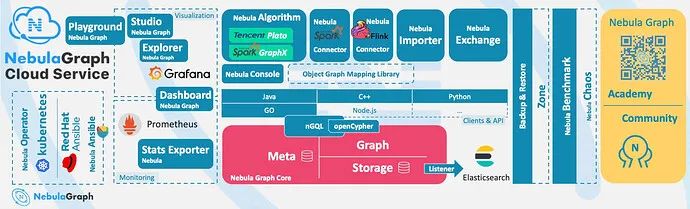
Nebula Graph 開放了越來越多的原生工具,例如 Nebula Studio、Nebula Console、Nebula Exchange 等,更多工具可以查看生態工具概覽。
此外,Nebula Graph 還具備與 Spark、Flink、HBase 等產品整合的能力,在這個充滿挑戰與機遇的時代,大大增強了自身的競爭力。
上面內容來源於 Nebula Graph 文檔站點
Nebula Graph 架構
Nebula Graph 由三種服務構成:Graph 服務、Meta 服務和 Storage 服務,是一種存儲與計算分離的架構。
每個服務都有可執行的二進位文件和對應進程,用戶可以使用這些二進位文件在一個或多個電腦上部署 Nebula Graph 集群。
下圖展示了 Nebula Graph 集群的經典架構。
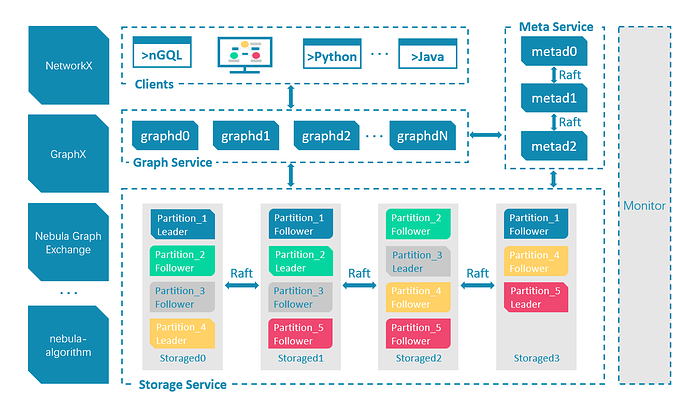
上面內容來源於 Nebula Graph 文檔站點
流程優化
Nebula Graph 的數據導入
在我們接觸 Nebula Graph 初期,當時周邊工具不夠完善。我們對 Nebula Graph 數據的導入不管全量還是增量都是採用 Hive 表推到 Kafka,消費 Kafka 批量寫入 Nebula Graph 的方式。後來隨著越來越多的數據和業務切換到 Nebula Graph,發現當前的方式存在三個較大問題:
- 全量導入的時長增多,到了難以接受的地步
- 增量數據消費由於 Kafka 多個分區,部分時序性無法保證
- 時間較長後如何減少增量數據進入 Nebula Graph 後整體數據的偏差
針對以上問題,我們針對各個 Space 的業務特性,由實時性的需求不同,做不同的優化方案。
- 在嘗試 Nebula Spark Connector 和 Nebula Importer 之後,由便於維護和遷移多方面考慮,採用
hive table -> csv -> nebula server -> importer的方式進行全量的導入,整體耗時時長也有較大的提升。 - 經過拆分,測試把增量由多個分區合併到一個分區中消費。這樣不會影響實時性,實時的誤差可以保證在 1min 內,可以接受
- 對不同欄位設置 TTL 屬性,定期導入全量校正數據,同時補消費導入全量期間的數據,以免數據覆蓋導致的錯誤數據。
服務的故障發現
當前我們已經升級到 v2.6.1,在最初的 v1 和 v2.0.1 存在部分 bug,經常容易出現的就是 OOM 導致 graph down。當時為了儘可能減少 graph down 的影響,做了相關腳本監控進程,出現宕機會立刻重啟。
此外,為了提高整體服務的可用性,對集群節點的CPU,記憶體,硬碟,TCP等做了相應監控與告警。Nebula Graph 服務層的部分指標也接入了 Grafana,比較重要的幾個告警指標如下:
nebula_metad_heartbeat_latency_us_avg_60 > 200000
nebula_graphd_num_slow_queries_rate_60 > 60
nebula_graphd_slow_query_latency_us_avg_60 >400000
nebula_graphd_slow_query_latency_us_p95_60 > 900000
nebula_graphd_num_query_errors_rate_60 > 10
nebula_storaged_add_edges_latency_us_avg_60 > 90000
nebula_storaged_add_vertices_latency_us_avg_60 > 90000
nebula_storaged_delete_edges_latency_us_avg_60 > 90000
nebula_storaged_delete_vertices_latency_us_avg_60 > 90000
nebula_storaged_get_neighbors_latency_us_avg_60 > 200000
同時應用層的介面做了慢查詢和流量監控告警:
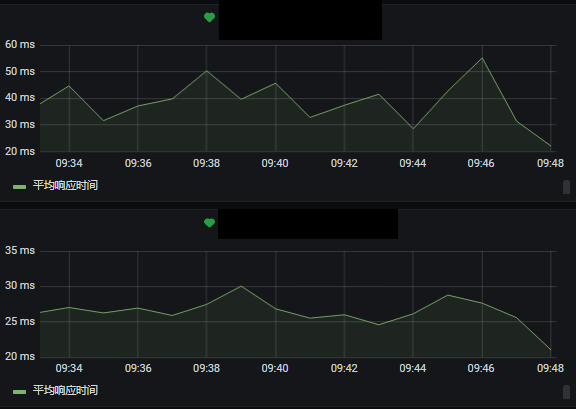
後來 Nebula 官方自己推出了 Nebula Dashboard 用於各個方面指標的監控, 不過貌似暫時沒有告警(企業版有告警功能)。
經過前面的介紹,我們這邊 Nebula Graph 的基本框架流程如下圖:
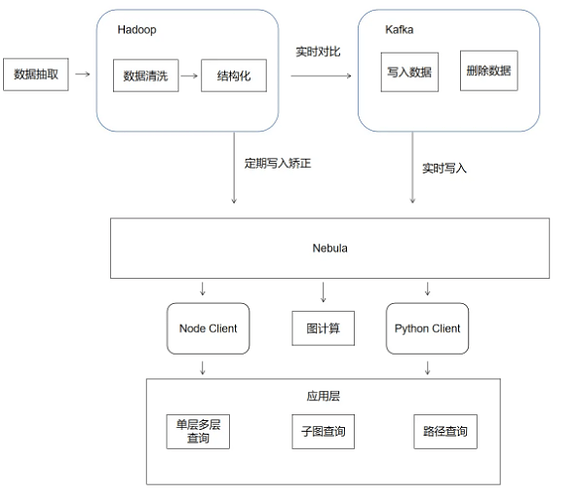
Nebula Graph 在企查查的經典業務
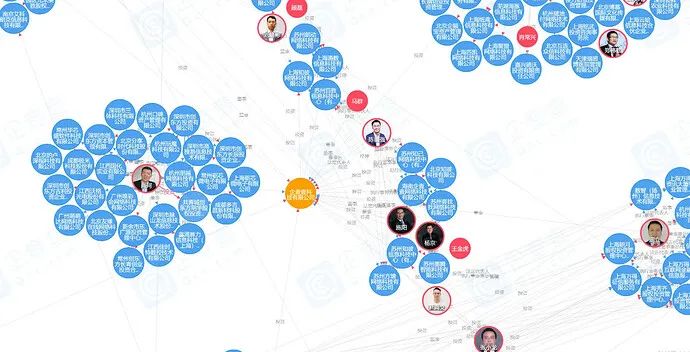
- 子圖查詢
業務需求:展示某公司/個人兩跳以內的企業關係(例如:董監高法),以圖的形式直觀展示。
更多、更詳細的資訊可以訪問企查查官網查看,有更多、更全面的企業 / 個人關係圖譜、風險圖譜、股東關係穿透等。傳送門
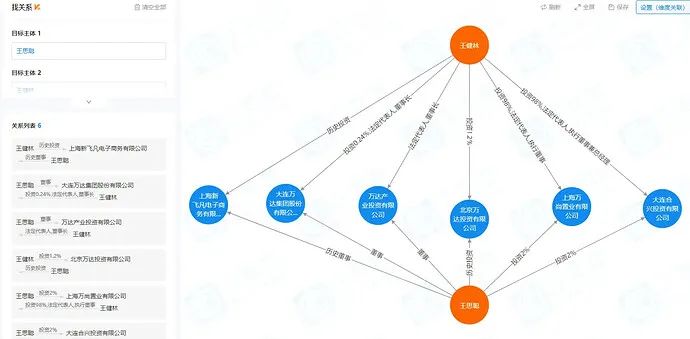
- 找關係
業務需求: 尋找任意兩個或者多個實體(公司或者人)之間的關係,關係包括不限於董監高法,控股,歷史董監高法,歷史控股。
遺憾的是 Nebula Graph 目前官方的路徑查詢,經過多輪交叉對比測試,發現切過來後性能損失較大,暫時無法滿足業務需求。我們目前還沒有從 Neo4j 切到 Nebula Graph,經過多次溝通提了issue。目前在enhancement list中期待官方的優化,我們會持續跟進。
展望
Nebula 目前提供了超強的讀寫能力和豐富的生態,以及優秀的社區活躍度、官方支援等。但是在複雜的查詢表達能力和路徑查找及其節點過濾上還有待加強,期望社區越做越強,儘快完善相關功能,我們也方便都切到 Nebula Graph,不必維護兩套資料庫。
交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebula 名片,Nebula 小助手會拉你進群~~

