MySQL優化之索引解析
索引的本質
MySQL索引或者說其他關係型資料庫的索引的本質就只有一句話,以空間換時間。
索引的作用
索引關係型資料庫為了加速對表中行數據檢索的(磁碟存儲的)數據結構
索引的分類
數據結構上面的分類
-
HASH 索引
- 等值匹配效率高
- 不支援範圍查找
-
樹形索引
-
二叉樹,遞歸二分查找法,左小右大
-
平衡二叉樹,二叉樹到平衡二叉樹,主要原因是左旋右旋
- 缺點1,IO次數過多
- 缺點2,IO利用率不高,IO飽和度
-
多路平衡查找樹(B-Tree)
- 特點,大大的減少了樹的高度
-
B+樹
-
特點,採用左閉合的比較方式
-
根節點支節點沒有數據區,只有葉子結點才包含數據區(說白了就是即便在根節點和子節點已經定位到,因為沒有數據區的原因也不會停留,會一直找到葉子結點為止。)
- 當我們搜索13這條數據時,在根節點和子節點 都能定位,但是一直會找到葉子結點。

-
二叉樹平衡二叉樹,B樹對比
如圖顯示如果是自增主鍵情況下:
二叉樹顯然不適合做關係型資料庫索引(和全表掃描沒什麼區別)。
平衡二叉樹呢,雖然解決了這種情況,但是同樣會導致這棵樹,又瘦又高,這同樣會造成上文所提到查詢IO次數過多以及IO利用率不高。
B樹呢,顯然已經解決了這兩個問題,所以下文來解釋,為什麼在這種情況下MySQL還用了B+樹,又做了那些增強。
-


B樹和B+樹比較
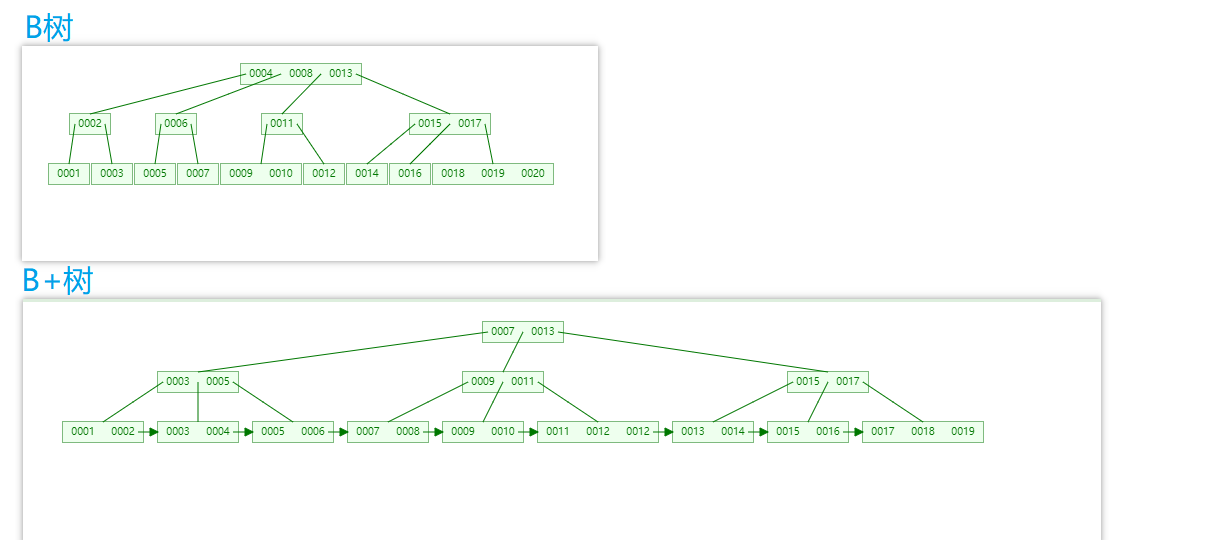
-
B+樹在B樹上面的優化
-
IO效率更高(B樹每個節點都會保留數據區,而B+樹則不會,假設我們查詢一條數據要遍歷三層,那麼顯然B+樹查詢中IO消耗更小)
-
範圍查找效率更高(如圖,B+樹已經形成了一個天然鏈表形式,只需要根據最結尾的鏈式結構查找)

-
基於索引的數據掃描效率更高。
-

索引類型的分類
-
索引類型可分為兩類:
- 主鍵索引
- 輔佐索引(二級索引)
- 唯一性索引
- 複合索引
- 普通索引
- 覆蓋索引
主鍵索引相對來說性能是最好的,但是對於SQL優化,其實大多時候我們都在輔佐索引上面做一些改進和補充。
B+樹在儲存引擎層面落地
-
我們創建兩個表分別為test_innodb(採用InnoDB作為儲存引擎)test_myisam(採用MyISAM作為儲存引擎)下圖是兩張表磁碟落地的相關文件,這兩個儲存引擎在B+樹磁碟落地式截然不同的。


B+樹在MyISAM落地
- *.frm文件是表格骨架文件比如這個表中的id欄位name欄位是什麼類型的存儲在這裡
- *.MYD(D=data)則儲存數據
- *.MYI (I=index)則儲存索引

-
比如現在執行如下sql語句 ,那麼在MyISAM中他就是先在test_myisam.MYI中查找到103然後拿到0x194281這個地址然後再去test_myisam.MYD中找到這個數據返回。
SELECT id,name from test_myisam where id =103
-
如果test_myisam表中,id為主鍵索引,name也是一個索引,那麼在test_myisam.MYI中則會有兩個平級的B+樹,這也導致MyISAM引擎中主鍵索引和二級索引是沒有主次之分的,是平級關係。因為這種機制在MyISAM引擎中,有可能使用多個索引,在InnoDB中則不會出現這種情況。

B+樹在InnoDB落地


-
InnoDB不像MyISAM來獨立一個MYD 文件來存儲數據,它的數據直接存儲在葉子結點關鍵字對應的數據區在這保存這一個id列所有行的詳細記錄。
-
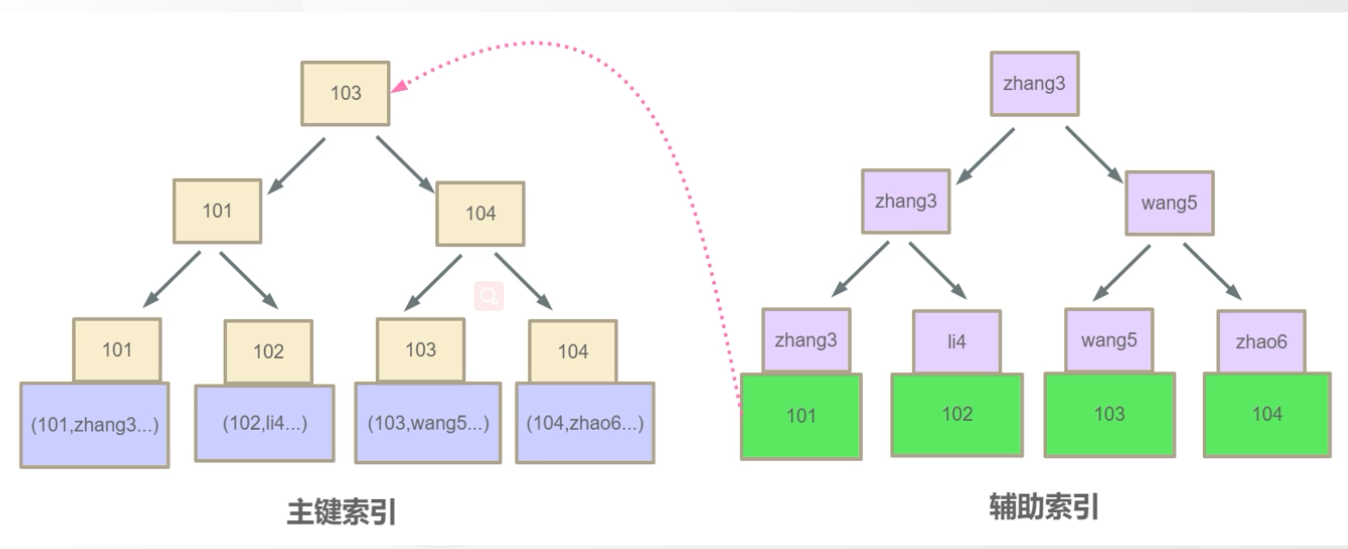
InnoDB 主鍵索引和輔助索引關係
我們現在執行如下SQL語句,他會先去找輔助索引,然後找到輔助索引下101的主鍵,再去回表(二次掃描)根據主鍵索引查詢103這條數據將其返回。
SELECT id,name from test_myisam where name ='zhangsan'這裡就有一個問題了,為什麼不像MyISAM在輔助索引下直接記錄磁碟地址,而是要多此一舉再去回表掃描主鍵索引,這個問題在下面相關面試題中回答,記一下這個問題是這裡來的。
相關面試題
-
為什麼MySQL選擇B+樹作為索引結構
這個就不說了,上文應該講清楚了。
-
B+樹在MyISAM和InnoDB落地區別。
這個可以總結一下,MyISAM落地數據儲存會有三個類型文件 ,.frm文件是表骨架文件,.MYD(D=data)則儲存數據 ,.MYI (I=index)則儲存索引,MyISAM引擎中主鍵索引和二級索引平級關係,在MyISAM引擎中,有可能使用多個索引,InnoDB則相反,主鍵索引和二級索有嚴格的主次之分在InnoDB一條語句只能用一個索引要麼不用。
-
如何判斷一條sql語句是否使用了索引。
可以通過執行計劃來判斷 可以在sql語句前explain/ desc
set global optimizer_trace=’enabled=on’ 打開執行計劃開關他將會把每一條查詢sql執行計劃記錄在information_schema 庫中OPTIMIZER_TRACE表中
-
為什麼主鍵索引最好選擇自增列?
自增列,數據插入時整個索引樹是只有右邊在增加的,相對來說索引樹的變動更小。
-
為什麼經常變動的列不建議使用索引?
和上一個問題原因一樣,當一個索引經常發生變化,那麼就意味這,這個縮印樹也要經常發生變化。4
-
為什麼說重複度高的列,不建議建立索引?
這個原因是因為離散性,比如說,一張一百萬數據的表,其中一個欄位代表性別,0代表男1代表女,把這欄位加了索引,那麼在索引樹上,將會有大量的重複數據。而我們常見的索引建立一般都是驅動型的。其目的是,儘可能的刪減數據的查詢範圍,這個顯然是不匹配的。
-
什麼是聯合索引
聯合索引是一個包含了多個功效的索引,他只是一個索引而不是多個,
其次,單列索引是一種特殊的聯合索引
聯合索引的創立要遵循最左前置原則(最常用列>離散度>佔用空間小)
-
什麼是覆蓋索引
通過索引項資訊可直接返回所需要查詢的索引列,該索引被稱之為覆蓋索引,說白了就是不需要做回表操作,可以從二級索引中直接取到所需數據。
-
什麼是ICP機制
索引下推,簡單點來說就是,在sql執行過程中,面對where多條件過濾時,通過一個索引,完成數據搜索和過濾條件其,特點能減少io操作。
-
在InnoDB表中不可能沒有主鍵對還是不對原因是什麼?
- 首先這句話是對的,但是情況有三種:
- 就是在你手動顯式指定這一個欄位為主鍵時候,會以這一個欄位為聚集索引。
- 在沒有顯式指定主鍵時候有兩種情況:
- 他會尋找第一個UK(unique key)作為主鍵索引組織索引編排。
- 如果既沒有指定主鍵也沒有UK的情況下,此時會以rowId(在InnoDB表中每一個記錄都會有一個隱藏(6byte)的rowId)為聚集索引。
- 首先這句話是對的,但是情況有三種:
-
什麼是回表操作
在InnoDB 中基於輔助索引查詢的內容,從輔助索引中無法直接獲取,需要基於主鍵索引的二次掃描的操作叫做回表操作。
-
為什麼在InnoDB 中輔助索引葉子結點數據區記錄的是主鍵索引的值而不是像MyISAM中去記錄磁碟地址。
- 這個原因其實很簡單,因為主鍵索引的數據結構是會經常發生變化的,如果在輔助索引數據區記錄磁碟地址,那麼假設我們有10個輔助索引,當我們主鍵索引結構發生變化後,還要一個個去通知輔助索引,且主鍵索引結構是經常發生變化的,增刪都有可能影響他的數據結構。
版權歸屬: 淚夢紅塵
本文鏈接: //www.bss2.com/archives/mysql-opt-index
- 這個原因其實很簡單,因為主鍵索引的數據結構是會經常發生變化的,如果在輔助索引數據區記錄磁碟地址,那麼假設我們有10個輔助索引,當我們主鍵索引結構發生變化後,還要一個個去通知輔助索引,且主鍵索引結構是經常發生變化的,增刪都有可能影響他的數據結構。

