NLP論文解讀:無需模板且高效的語言微調模型(下)
- 2022 年 3 月 14 日
- 筆記
©原創作者 | 蘇菲
論文題目:
Prompt-free and Efficient Language Model Fine-Tuning
論文作者:
Rabeeh Karimi Mahabadi
論文地址:
//openreview.net/pdf?id=6o5ZEtqP2g
02 PERFECT:無需Patterns和Verbalizer的微調模型
這個模型主要包含三個部分:
1)無需pattern的任務描述,使用了一個任務相關的適配器來有效告知模型相關的任務,取代了手工製作的patterns;
2)使用多token的標籤向量來有效學習標籤的表示,去掉了原來手工設計的verbalizers;
3)基於原型網路思想的有效預測策略,取代了原來的逐個自回歸解碼方法。如圖3所示,該模型固定了預訓練語言模型的底層,而僅僅優化新加入模組(圖中綠色模組)的參數。這些新加入的模組包括可以適應給定任務的表示的適配器和多token標籤表示等等。
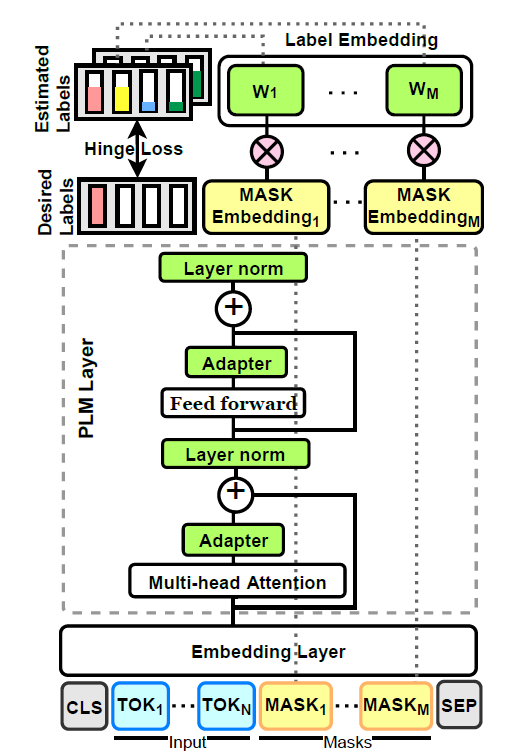
圖3
2.1 無需模板的任務描述
該模型使用了面向具體任務的適配層(Adapter Layers),為模型提供學習到的隱式的任務描述。
適配層的加入還額外帶來了其它好處:
a)微調預訓練語言模型的上百萬或幾十億的所有權重參數是樣本低效的,在低資源環境下是不穩定的,而適配層的引入可以通過保持預訓練語言模型底層參數不變,使得微調是樣本高效的;
b)適配層減少了存儲和記憶體的佔用空間;
c)增加了模型的穩定性和性能,使得這種方法成為少樣本微調的一種好方案。
2.2 多標記標籤向量

使用固定的token數M來表示每一個標籤,而不是經典模型中可變token長度的verbalizers,可以大大簡化模型的實現並提升訓練的速度。
2.3 PERFECT的訓練
如圖3所示,模型通過標籤向量的最優化,使得預訓練語言模型可以預測得到正確的標籤;通過適配器的最優化使得預訓練語言模型可以適應給定的任務。
對於標籤向量來說,PERFECT模型為每一個token都訓練了一個分類器,並使得所有掩碼位置的多類別鉸鏈損失平均值最小。

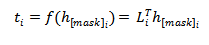

2.4 PERFECT的預測
在預測過程中,PERFECT模型沒有使用之前的遞歸自回歸解碼方案,而是通過尋找最近的掩碼token向量的類別原型來區分一個查詢點,如公式(6)所示。
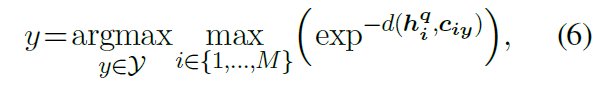

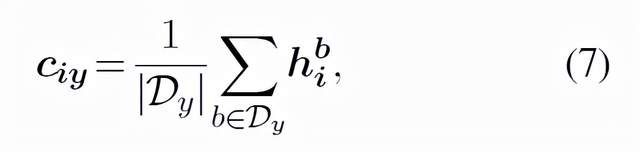

03 實驗
數據集:論文作者選擇了7個任務(共12個數據集):

對於其它數據集,由於測試集數據無法公開獲取,論文作者只是在原始驗證集數據上進行了測試,即從訓練集中按每個類別分別取16個樣本例子,得到16個訓練樣本和16個驗證樣本。
3.1 基準線模型:

是目前最好的少樣本學習系統,採用了手工精心設計的verbalizers和pattern;論文作者給出了使用所有patterns和verbalizers後PET系統的最好結果和平均結果。
微調:採用標準的微調,基於[CLS]加了一個分類器並微調所有參數。
3.2 本文模型:
PERFECT-rand:從標準正態分布隨機初始化標籤向量L,其中(基於驗證集表現),並沒有依賴於任何手工製作的模板(patterns)和語言生成器(verbalizers)。
PERFECT-init:作為消融實驗之一,論文作者使用預訓練語言模型辭彙表手工設計了verbalizers,並利用其中的token向量去初始化標籤(label)向量,以便研究verbalizers對模型的影響。
PERFECT-prompt:作為消融實驗之二,論文作者比較了使用適配層與使用軟提示微調的結果,軟提示微調是去除適配層並在輸入增加可訓練的連續提示向量。微調時論文作者僅僅微調了軟提示以及標籤向量。
3.3 實驗細節
論文作者使用了含355M個參數的RoBERTa大模型作為所有方法的基礎預訓練語言模型(PLM),使用了HuggingFace的PyTorch實現。對基準線模型,使用了手工精心設計的patterns和verbalizers。
對於所有的模型方法,評估時使用了5種不同的隨機取樣去獲得訓練集或者驗證集,並且訓練時用了4個不同的隨機種子數。
因此,對於PET系統的平均結果,是基於20*5(模板數*語言生成器辭彙標籤轉換數)共100次運行的結果;而PET的最好結果以及論文作者模型的各種結果,都是基於20次運行的結果。
在少樣本學習方法中方差通常是很高的,因此論文作者報告了所有運行結果中方差的平均值、最壞情況表現,以及標準差,其中後兩個的值對於風險敏感的應用是十分重要的。
3.4 實驗結果
表1給出了所有模型及方法的實驗結果。其中,論文提出的PERFECT模型得到了最先進的結果,在單句測試中比PET系統的平均得分提高了1.1個百分點,在句子對數據集測試中提高了4.6個百分點。
PERFECT模型的表現甚至超過了PET系統的最好結果(PET-best),這個最好結果是多個手工編製patterns和verbalizers的結果。而且,PERFECT還改善了最低表現,並大幅降低了標準差。
最後,PERFECT也是顯著高效率的,它減少了訓練時間和預測時間,降低了記憶體成本和存儲成本(見表2)。
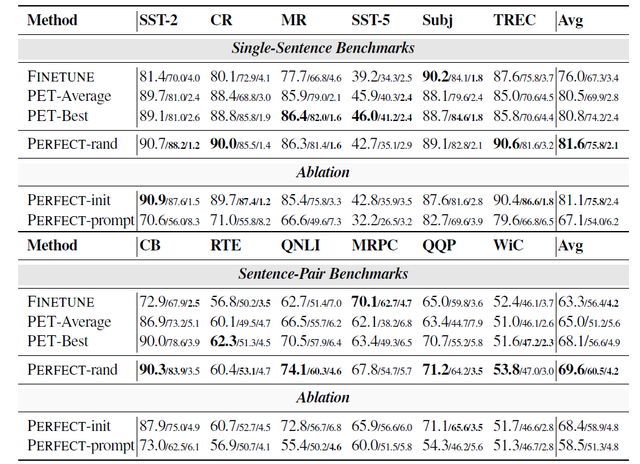
表1
表2給出了PET模型和PERFECT模型的訓練參數、記憶體使用、訓練時間和預測時間的對比。可以看到,PERFECT的參數數量下降了99.08%,因此在存儲的需求上幾乎縮小了100倍。
在記憶體使用峰值上,PERFECT下降了21.93%,對記憶體的需求與PET相比也減少了。在訓練時間上,PEFECT比原始的PET系統減少了97.22%,比論文作者實現的PET系統則減少了30.85%。
而在預測時間上,PERFECT與PET相比也顯著減少了96.76%。
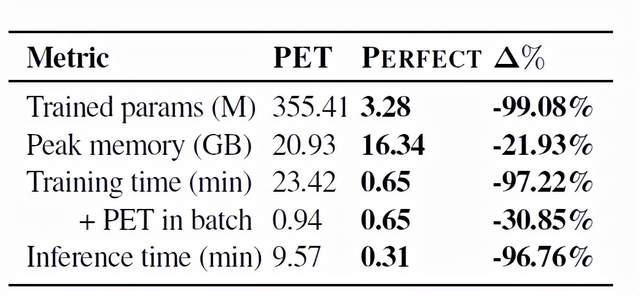
表2
04 結論
這篇論文提出的PERFECT模型及方法,對於預訓練語言模型的小樣本學習是簡單且高效的,該方法並不需要手工的模板和辭彙標籤映射。
PERFECT使用了面向具體任務的適配層來隱式地學習具體任務的描述,取代了以前的手工的模板;並使用一個連續的多標記標籤向量來表示輸出的類別。
通過多達12個NLP數據集的實驗,論文作者證明了PERFECT模型儘管更加簡單,但卻更加高效。與當前先進的預訓練語言模型小樣本學習方法相比,得到了SOTA的結果。
總之,PERFECT的簡單性和有效性使其在預訓練語言模型的少樣本學習方法中前景廣闊。
參考文獻
[1] Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. In NeurIPS.
[2] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In EMNLP.
[3] Bo Pang and Lillian Lee. 2005. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In ACL.
[4] Minqing Hu and Bing Liu. 2004. Mining and summarizing customer reviews. In SIGKDD.
[5] Bo Pang and Lillian Lee. 2004. A sentimental education: sentiment analysis using subjectivity summarization based on minimum cuts. In ACL.
[6] Ellen M Voorhees and Dawn M Tice. 2000. Building a question answering test collection. In SIGIR.
[7] Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. 2019. The commitmentbank: Investigating projection in naturally occurring discourse. In proceedings of Sinn und Bedeutung.
[8] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2019a. Superglue: a stickier benchmark for general-purpose language understanding systems. In NeurIPS.
[9] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In EMNLP.
[10] Mohammad Taher Pilehvar and Jose Camacho-Collados. 2019. Wic: the word-in-context dataset for evaluating context-sensitive meaning representations. In NAACL.
[11] William B Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In IWP.
[12] Timo Schick and Hinrich Schütze. 2021a. Exploiting cloze-questions for few-shot text classification and natural language inference. In EACL.
[13] Timo Schick and Hinrich Schütze. 2021b. It』s not just size that matters: Small language models are also few-shot learners. In NAACL.


