Hadoop原生對象存儲Ozone
Hadoop 社區推出了新一代分散式Key-value對象存儲系統 Ozone,同時提供對象和文件訪問的介面,從構架上解決了長久以來困擾HDFS的小文件問題。本文作為Ozone系列文章的第一篇,拋個磚,介紹Ozone的產生背景,主要架構和功能。
背景
HDFS是業界默認的大數據存儲系統,在業界的大數據集群中有非常廣泛的使用。HDFS集群有著很高的穩定性,得益於它較簡單的構架,集群也很容易擴展。業界包含幾千個數據節點,保存上百PB數據的集群也不鮮見。
HDFS通過把文件系統元數據全部載入到Namenode記憶體中,給客戶端提供了低延遲的元數據訪問。由於元數據需要全部載入到記憶體,所以一個HDFS集群能支援的最大文件數,受JAVA堆記憶體的限制,上限大概是4億左右個文件。所以HDFS適合大量大文件(幾百兆以上)的集群,如果集群中有非常多的小文件,HDFS的元數據訪問性能會受到影響。雖然可以通過各種Federation技術來擴展集群的節點規模, 但單個HDFS集群仍然沒法很好的解決小文件的限制。
基於這些背景,Hadoop 社區推出了新的分散式存儲系統 Ozone,從構架上解決這個問題。

目前,Ozone已經脫離成為Hadoop子項目,逐漸升級為Apache的頂級項目,詳見://ozone.apache.org。
設計原則
Ozone 由一群對大規模Hadoop集群有著豐富運維和管理經驗的工程師和構架師設計和實現。他們對大數據有深刻的洞察力,清楚地了解HDFS的優缺點,這些洞察力自始自終影響了Ozone的設計和實現。Ozone的設計遵循以下原則:
- 弱一致性
- 架構簡潔性,當系統出現問題時,一個簡單的架構更容易定位,也容易調試。Ozone儘可能的保持架構的簡單,即使因此需要可擴展性上做一些妥協。但是在Ozone在擴展性上絕不遜色,目標是支援單集群1000億個對象。
- 架構分層,Ozone採用分層的文件系統。Namespace 元數據的管理,數據塊和節點的管理分開。用戶可以對二者獨立擴展。
- 容易恢復,HDFS一個關鍵優點是,它能經歷大的災難事件,比如集群級別的電力故障,而不丟失數據, 並且能高效的從災難中恢復。對於一些小的故障,比如機架和節點級別的故障,更是不在話下。Ozone將繼承HDFS的這些優點。
- Apache開源,Apache社區開源對於Ozone的成功非常重要。所有Ozone的設計和實現都在社區中進行,接受社區所有人的Review。
- 與Hadoop生態的互操作性,Ozone可以被Hadoop生態中的應用,如 Apache Hive、Apache Spark 和 Mapreduce 無縫對接。Ozone支援Hadoop Compatible FileSystem API (aka OzoneFS)。通過OzoneFS, Hive,Spark等應用不需要做任何修改,就可以運行在Ozone上。Ozone同時支援Data Locality,使得計算能夠儘可能的靠近數據。
語義
Ozone是一個分散式Key-value對象存儲系統。Ozone提供給用戶的語義包含Volume, Bucket 和Key。
- Volume,概念與賬戶類似,類似於用戶的Home目錄,建議每個用戶單獨創建自己的Volume。Volume只有系統管理員才可以創建和刪除,是存儲管理的單位,比如配額管理。Volume用來存儲Bucket,一個Volume下面可以包含任意多個Bucket。
- Bucket,桶的概念類似於目錄,用戶可以在自己所在的卷下創建任意多的桶,Bucket 下存儲任意多的Key 和 Value,但是不包括其他Bucket。Bucket 的概念類似於 S3 的 Bucket,或者 Azure 中的 Container。Bucket 由 ACL 來控制訪問。
- Key,概念和文件類似,每個 Key 在 Bucket 中必須唯一,可以是任意字元串。用戶的數據以 Key-value 的形式存儲在 Bucket 下,用戶通過key來讀寫數據。
- Ozone URL,Ozone URL 採用的格式:
[schema][server:port]/volume/bucket/key。其中schema可選,有兩種協議支援。第一,O3 -通過 RPC 協議訪問 Ozone Manager 和 Datanodes;第二,HTTP/HTTPS-通過 HTTP 協議訪問REST API。Scheme可以省略,這種情況下默認使用RPC協議。Server:Port 是 Ozone Manager 的地址。如果沒有指定,則用定義在 ozone-site.xml 中 “ozone.om.address” 默認值。
架構
Ozone 從結構上分為四個部分:Ozone Manager, 元數據管理;Storage Container Manager, 數據塊和節點管理;Datanodes, 數據最終的存放處;Recon Server 管理和監視控制台。類比 HDFS 的構架, 可以看到原來 Namenode 的功能,現在由 Ozone Manager 和 Storage Container Manage 分別進行管理了。接下來,我們仔細看一下 Ozone 主要模組和概念。


Ozone Manager
管理 Ozone 的 Namespace,提供所有的 Volume, Bucket 和 Key 的新建,更新和刪除操作。存儲了 Ozone 的元數據資訊,這些元數據資訊包括 Volumes、Buckets 和 Keys,底層通過 Ratis(實現了Raft協議) 擴展元數據的副本數來實現 元數據的 HA。Ozone Manager 只和 Ozone Client 和 Storage Container Manager 通訊,並不直接和 Datanode 通訊。
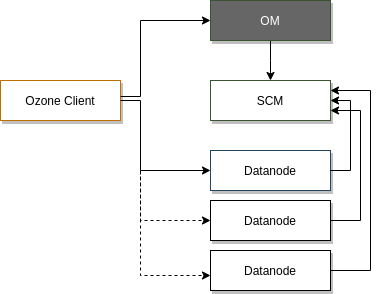
Storage Container Manager(SCM)
類似HDFS中的Block Manager,管理 Container, Pipelines 和 Datanode,為 Ozone Manager 提供Block 和 Container 的操作和資訊。SCM也監聽 Datanode 發來的心跳資訊,作為Datanode manager的角色, 保證和維護集群所需的數據冗餘級別。SCM 和 Ozone Client 之間沒有通訊。

Block、Container 和 Pipeline
Block 是數據塊對象,真實存儲用戶的數據。Container是一個邏輯概念,是由一些相互之間沒有關係的 Block 組成的集合。在 Ozone 中, 數據是以 Container 的粒度進行副本複製的。Pipeline 來保證 Container 實現想要的副本數。SCM 中目前支援2種 Pipeline 方式實現多副本,單副本的 Standalone 模式和三副本的 Ratis 方式。Container 有2種狀態,OPEN 和 CLOSED。當一個Container 是 OPEN 狀態時,可以往裡邊寫入新的 BLOCK。當一個Container 達到它預定的大小時(默認5GB),它從 OPEN 狀態轉換成 CLOSED 狀態。一個 Closed Container 是不可修改的。

Datanodes
Datanode 是 Ozone 的數據節點,以 Container 為基本存儲單元,維護每個 Container 內部的數據映射關係,定時向 SCM 發送心跳節點,彙報節點的資訊,管理的 Container 的資訊,Pipeline 的資訊。當一個 Container Size 超過預定的大小 90% 時 或者寫操作失敗時,Datanode 會發送 Container Close 命令給 SCM,把 Container 的狀態從 Open 轉變成 Closed。或者當Pipeline 出錯時,發送 Pipeline Close 命令給SCM,把Pipeline 從 Open 狀態轉為 Closed 狀態。

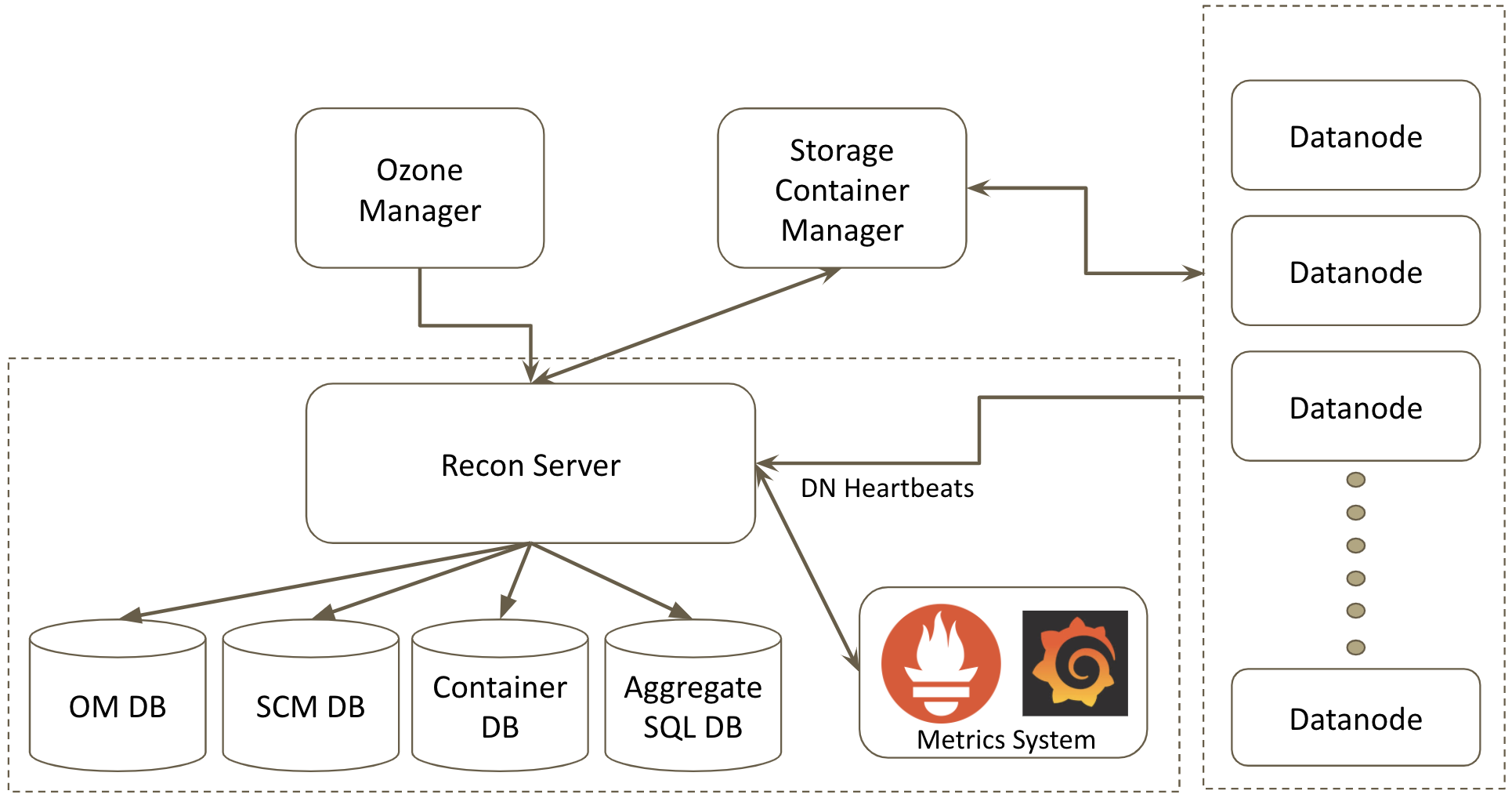
Recon Server
Recon 充當 Ozone 的管理和監視控制台。它提供了 Ozone 的鳥瞰圖,並通過基於 REST 的 API 和豐富的網頁用戶介面(Web UI)展示了集群的當前狀態,從而幫助用戶解決任何問題。
在較高的層次上,Recon 收集和匯總來自 Ozone Manager(OM)、Storage Container Manager(SCM)和數據節點(DN)的元數據,並充當中央管理和監視控制台。Ozone 管理員可以使用 Recon 查詢系統的當前狀態,而不會使 OM 或 SCM 過載。
Recon 維護多個資料庫,以支援批處理,更快的查詢和持久化聚合資訊。它維護 OM DB 和 SCM DB 的本地副本,以及用於持久存儲聚合資訊的 SQL 資料庫。
Recon 還與 Prometheus 集成,提供一個 HTTP 端點來查詢 Prometheus 的 Ozone 指標,並在網頁用戶介面(Web UI)中顯示一些關鍵時間點的指標。
讀寫過程
寫過程
Ozone 客戶端 先和 Ozone Manager 通訊,提供需要創建的Key 的資訊,包括 /volume/bucket/key,數據的大小,備份數,和其他用戶自定義Key的屬性。Ozone Manager 收到 Ozone 客戶端的請求後,調用SCM 的服務,尋找足夠容納數據的Open Container,將Container 對應的Pipeline 的Datanode 列表資訊返回給Ozone Manager。Ozone Manager 返回對應的資訊給客戶端。
客戶端拿到Datanode列表資訊之後,和第一個Datanode(Raft Leader)建立通訊,將數據寫入Datanode 的Container 中,更新Container 的元數據,記錄新增加的這個數據塊。
最後,客戶端再和Ozone Manager 通訊,告知數據已經成功的在 Datanode寫入了。Ozone 修改 Namspace 元數據,記錄一個新生成的Key。之後,其他的客戶端就可以訪問這個Key了。

讀過程
讀的過程相對簡單,類似於HDFS的文件讀。Ozone 客戶端 先和 Ozone Manager 通訊,告知需要讀取的Key 的資訊(/volume/bucket/key)。Ozone Manager 在元資料庫中查找對應的Key,返回 Key 數據所在的 Datanode 列表給Ozone 客戶端。Ozone 支援Data locality。如果Ozone 客戶端運行在集群中的某個節點上,Ozone Manager 會返回按照網路拓撲距離排序的Datanode列表。當 Ozone 客戶端拿到 Key 的資訊之後,可以選擇第一個Datanode 節點(一本地節點),也是離客戶端最近的節點來讀取數據,節省數據讀取的時間。

與Hadoop生態的結合
Ozone 同時支援 Hadoop 2.x 和 Hadoop 3.x 集群,能夠和運行其上的Hive,Spark 等應用無縫集成。
結束
Apache Ozone 是一個開發迭代非常活躍的社區,在 2018 年發布了版本 0.2.1 和 0.3.0,支援 OzoneFS, YARN, HIVE and Spark on OzoneFS, S3 協議介面。2019年發布了版本0.4.0,0.4.1 和0.4.2,支援基於Kerbero的認證,透明數據加密/解密,支援Ranger,實現CNCF CSI 插件支援Kubernetes布署。2020年0.5.0 的發布正在進行中。Ozone 社區提供Docker-Compose腳本,幫助初次使用者很方便的布署單集群,嘗試Ozone的各種功能。目前最新版已到1.2.1,更多文檔的資訊,請參考Apache Ozone官網和對應的Github開源項目。


