RNN原理
- 2020 年 1 月 27 日
- 筆記
現在考慮這樣一個問題,給一句話,如何判斷這句話的情感是積極的(Positive)還是消極的(Negative)
例如下圖中的一句話"I hate this boring movie",我們看一眼就知道這句話肯定是消極的,但是如何構建一個網路模型去識別呢?
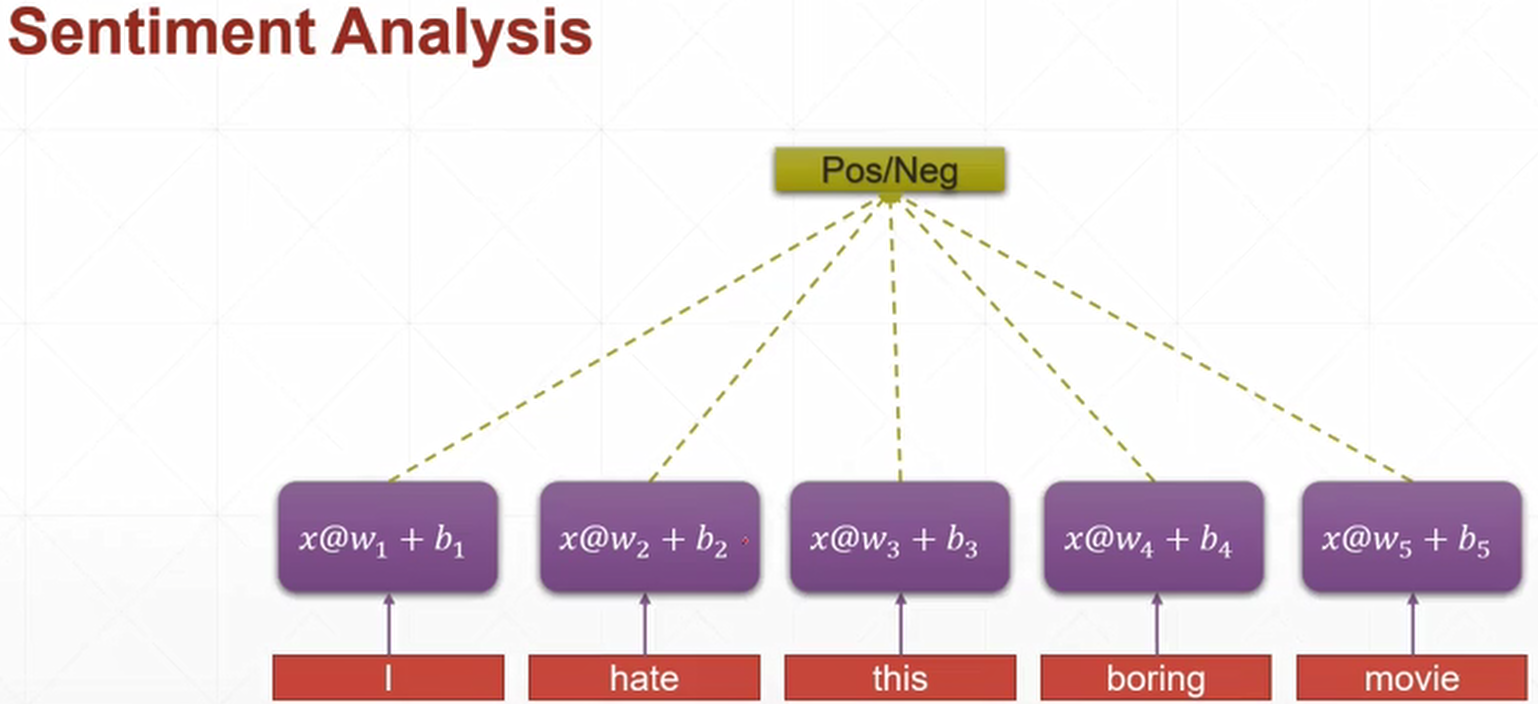
有一種naive的方法,假設我們把這句話變成一個[5, 100]的tensor,5表示這句話里有5個詞,100表示每句話的維度是100。然後對於將每個詞$x_i=[100]$作為輸入,分別帶入5個Linear Layer,假設得到的輸出$y_i=[2]$,把這五個輸出合在一起就是$y=[5, 2]$,最後再接一個Linear Layer,輸出$p=[1]$,這個值表示給出句子是$x$的情況下,這個句子的情感是Positive的概率,即$P(pos|x)$,就變成了一個二分類的問題
這只是一個naive的做法,這樣做會存在很多問題。首先如果輸入是一個很長的句子,那麼這個句子里的單詞就會很多,再加上每個單詞對應還需要一段長度的詞向量,整個參數量就會非常大;其次,這種做法沒有考慮到上下文的資訊,例如"我不喜歡你"這句話,如果你只分析"喜歡",你會以為這是一個積極的句子,但其實沒有考慮到上文中的"不"字。再比如,一個人說:我喜歡旅遊,其中最喜歡的地方是雲南,以後有機會一定要去__。這裡填空,是個正常人都知道填"雲南"。我們是根據上下文內容推斷出來的,這就意味著,一句話不能單獨一個單詞一個單詞來分析,所以我們希望能有一個consistent tensor來存儲語境資訊,並且在訓練的時候能夠將這個語境資訊利用起來
對於第一個問題,如何解決參數量過大,我們可以參考CNN,卷積神經網路中的每個kernel都利用的權重共享的思想,應用到我們這裡就是,每個單詞經過的Linear Layer,其$w$和$b$,都是相同的,而不再是上面那張圖的$w_1$,$w_2$,…$b_1$,$b_2$,…,具體見下圖
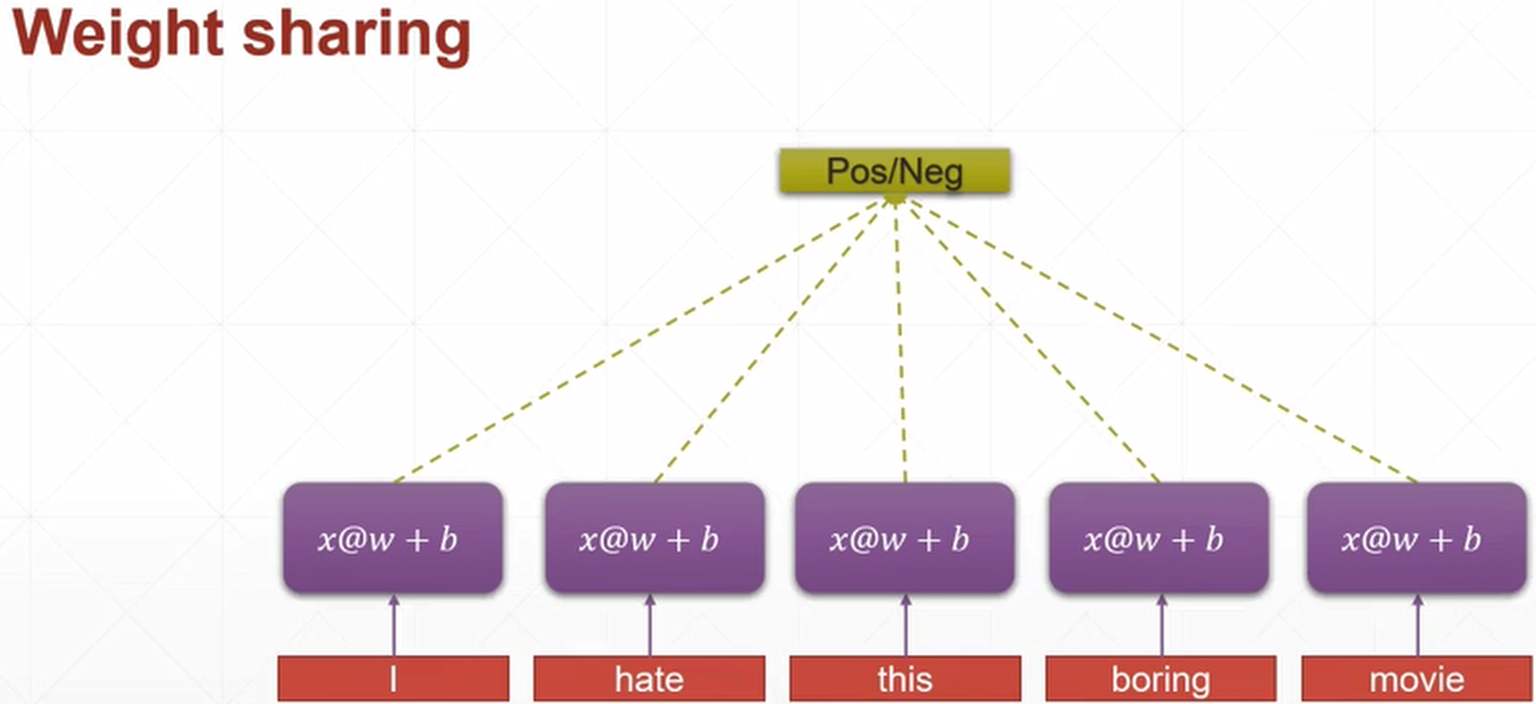
對於第二個問題,如何將語境資訊也貫穿在整個網路訓練的過程中?
看下圖的網路結構,每一層的輸出,都會作為下一層的一部分輸入。例如將"I"的詞向量$x_1$和$h_0$作為輸入,輸出得到$h_1$,就,然後將"hate"這個詞的詞向量$x_2$和$h_1$作為輸入,輸出得到$h_2$,如此循環下去。因此這種網路被稱為循環神經網路(RNN)

下圖是一個典型的RNN網路結構。右邊可以理解為左邊按照時間進行展開

假設$x_{t-1},x_{t}$表示輸入"我"和"是",$x_{t+1}$表示輸入"中國",連起來輸入就是"我是中國",那麼$O_{t-1},O_{t}$就應該對應"是"和"中國",預測下一個詞最有可能是什麼?就是預測$O_{t+1}$最有可能是什麼,應該是"人"的概率比較大
因此,我們可以做這樣的定義:
$$ X_t:表示t時刻的輸入,O_t:表示t時刻的輸出,S_t:表示t時刻的記憶 $$
因為我們當前時刻的輸出是由記憶和當前時刻的輸入共同決定的。就像你現在大四,你的知識是由大四學到的知識(當前輸入)和大三以及大三以前學到的知識(記憶)的結合。RNN在這點上也類似,神經網路最擅長做的就是通過一系列參數把很多內容整合到一起,然後學習這個參數,因此就定義了RNN的基礎:
$$ S_t=f(U*x_t + W*S_{t-1}) $$
這裡的$f()$函數表示激活函數,對於CNN來說,激活函數一般選取的都是$ReLU$,但是RNN一般選用$tanh$
假設你大四快畢業了,要參加考研,請問你參加考研是先記住學過的內容然後去考研,還是直接帶幾本書參加考研呢?答案很顯然。RNN的做法也就是預測的時候帶著當前時刻的記憶$S_t$去預測。假如你要預測"我是中國"的下一個詞,運用SoftMax在合適不過了,但預測不能直接用一個矩陣去預測,要轉為一個向量,所以最終的公式表示為:
$$ O_t = softmax(V*S_t) $$
RNN的結構細節:
- 可以把$S_t$當作隱狀態,捕捉了之前時間點上的資訊。就像你去考研一樣,考的時候記住了你能記住的所有資訊
- 可惜的是$S_t$並不能捕捉之前所有時間點的資訊,或者說在網路傳播的過程中會"忘掉"一部分。就像你考研也記不住所有的英語單詞一樣
- 和卷積神經網路一樣,RNN中的每個節點都共享了一組參數$(U, V, W)$,這樣就能極大降低計算量
