數倉建模—埋點設計與管理
數據倉庫系列文章(部分已出,持續更新)
- 數倉架構發展史
- 數倉建模方法論
- 數倉建模分層理論
- 數倉建模—寬表的設計
- 數倉建模—指標體系
- 數據倉庫之拉鏈表
- 數倉—數據集成
- 數倉—數據集市
- 數倉—商業智慧系統
- 數倉—埋點設計與管理
- 數倉—ID Mapping
- 數倉—OneID
- 數倉—AARRR海盜模型
- 數倉—匯流排矩陣
- 數倉—數據安全
- 數倉—數據品質
- 數倉—數倉建模和業務建模
關注公眾號:
大數據技術派,回復:資料,領取1024G資料。
埋點設計與管理
埋點的作用
開始之前我們先看一下我們為什麼要收集埋點數據,埋點都可以做什麼,埋點主要用於記錄用戶行為,幾乎是應用必不可少的功能.埋點的作用包括但不限於
分析用戶轉化以及存留
例如下載的用戶數量,註冊的用戶數量,一段時間之後的存留用戶數量;
分析用戶偏好
例如通過用戶行為的分析,可以對用戶的偏好做一定的概括,便於投其所好針對特性的用戶推送特定的服務,甚至開發不同的用戶體驗;
收集市場回饋
例如針對新功能的用戶行為進行統計,就可以分析出功能的市場回饋,為是否保留功能或者改良方向提供依據;
保障用戶數據安全
例如用戶的地理位置數據在短時間內突然發生了異常變更,這一秒在南京,下一秒突然就在東京登陸了,那就說明帳號發生了異常,需要對帳號身份進行驗證,以確保用戶數據的安全.
定位異常
例如特定的數據(比如註冊)在某一段時間內數據突然無緣由發生持續性異常,說明該功能可能存在異常,需要及時做排查.
其他作用
例如當某一個較早機型佔比降低到某一個閥值時,就可以在下一個版本中去掉對該設備的支援.
埋點數倉設計
數據進入數倉之前我們就需要設計好數倉表,埋點的表的數據有幾個特點,所以我們在設計的時候需要考慮到
- 數據量非常大,可能是所有數據集成渠道裡面,流量最大的了
- 數據不存在更新,這是埋點表的數據特點
面對這兩個特點,我們需要做一些設計,當然還有一些其他設計方面的點需要注意一下,首先因為量大,而且我們往往關注的是昨天的數據,所以我們的表肯定是分區表,其次因為我們使用的特點,例如關注的是頁面瀏覽或者是按鈕點擊,所以我們在時間分區的基礎上按照事件進行分區。這樣我們可以在數據查詢的時候過濾掉大量的數據從而提高查詢的性能。
其次就是埋點表的作為數據報表的數據來源的時候,可能會大概率遇到計算延遲,或者是一些其他問題,所以在寬表的設計或者是報表展示中,請盡量地將集成進行後延,從而更好的保證穩定性和可用性。關於這一點,請參考數倉建模—寬表的設計
這裡是我們公司小程式端的埋點表

下面是web 端的埋點表

埋點的類型
埋點:在期望的點位,埋設一個記錄的標記。這個點位,一般多是指用戶與產品進行一次次交互的接觸點,從而可以在用戶和產品交互的時候,將用戶的數據進行上報。
通過收集這些標記點的數據,可以幫助產品運營及開發同學了解功能的整體使用、運行情況,並通過數據基礎上做出下一步調整或優化的方向。遇事不拍腦袋,而是用數據說話,這是數據埋點最大的價值。
在AB測試的場景下,數據埋點為實驗組的效果提供數據支援,其本質也是數據決策的基礎。
根據目前常見的數據埋點形式,可以將數據埋點分為全埋點、程式碼埋點(自定義埋點),當然我們也可以按照產品的類型劃分為,APP埋點、web 埋點、小程式埋點
全埋點
全埋點的邏輯,是指數據採集sdk無區別的對待所有事件的,將所有事件(頁面的載入成功事件、控制項的瀏覽和點擊事件)全部獲取後先存下來,到使用的時候,再根據具體的頁面路徑和控制項名稱,去撈取相應的數據。
可視化埋點
基於此,可視化埋點是指,在全埋點部署成功、已經可以獲得全量數據的基礎上,以可視化的方式,然後進行數據選擇。
這種方案的弊端之一是耗流量和存儲空間,全埋點採集的數據一般會根據情況設定一個銷毀時限,比如7天。即:全採集過來的數據,如果7天之內沒有被使用,則會刪除。而一旦對圈選數據做了圈選定義之後,則被定義的頁面數據、控制項數據,則會一直採集,且不會刪除。
全埋點,其優勢和特點是功能上線時,不需要開發做額外的埋點定義工作,用的時候再根據需求去獲取對應的數據,因此也叫無埋點。
全埋點的缺點:
- 耗用戶流量、占存儲空間;
- 一旦版本迭代,對頁面的路徑做修改,或者控制項位置、文案有修改,原來的圈選數據可能就會出錯,需要重新圈選,之前利用圈選指標設定的分析模型都要替換;
- 圈選指標無法區分細部參數,比如:商品詳情頁,無法通過圈選數據來區分是哪一個商品或哪一個類目;
- 對web的頁面數據處理一直不好,尤其是涉及到APP的內嵌H5頁時,非常痛苦。
因此,全埋點適用於業務多變、經常調整,且分析訴求比較輕量的場景。對於通用的功能,形態相對比較固定,且對數據分析顆粒度、下鑽深度、聚合程度要求比較高,那就需要用到程式碼埋點
程式碼埋點
程式碼埋點也叫自定義埋點,從字面上即可理解:是針對想要的點位單獨定義,並可以通過變數豐富埋點的資訊,以支援上下游分析。
程式碼埋點分為前端埋點和後端埋點。
前端埋點,包括但不限於APP客戶端、H5、微信小程式、PC網頁,是指對具體的功能場景(如載入成功、瀏覽、點擊等)進行明確的定義,由前端觸發,採集上來的數據相比於全埋點,更準確、穩定,且通過變數欄位,能夠實現更細顆粒度數據的拆分、聚合和下鑽。
後端埋點,指觸發了服務端介面調用(如:介面回調成功觸發)的事件埋點,如最典型的註冊成功事件、付費成功事件。後端埋點對數據的準確度要求更高,同時也可以通過變數欄位的擴展支援數據拆分、聚合和下鑽。需要強調的是,後端事件一般採集的是已登錄狀態下的用戶行為,如果想使用後端埋點事件作為流程分析的其中一環(如漏斗分析),則可能出現未登錄的用戶會漏掉的情況。
綜合以上,幾種埋點類型的比較
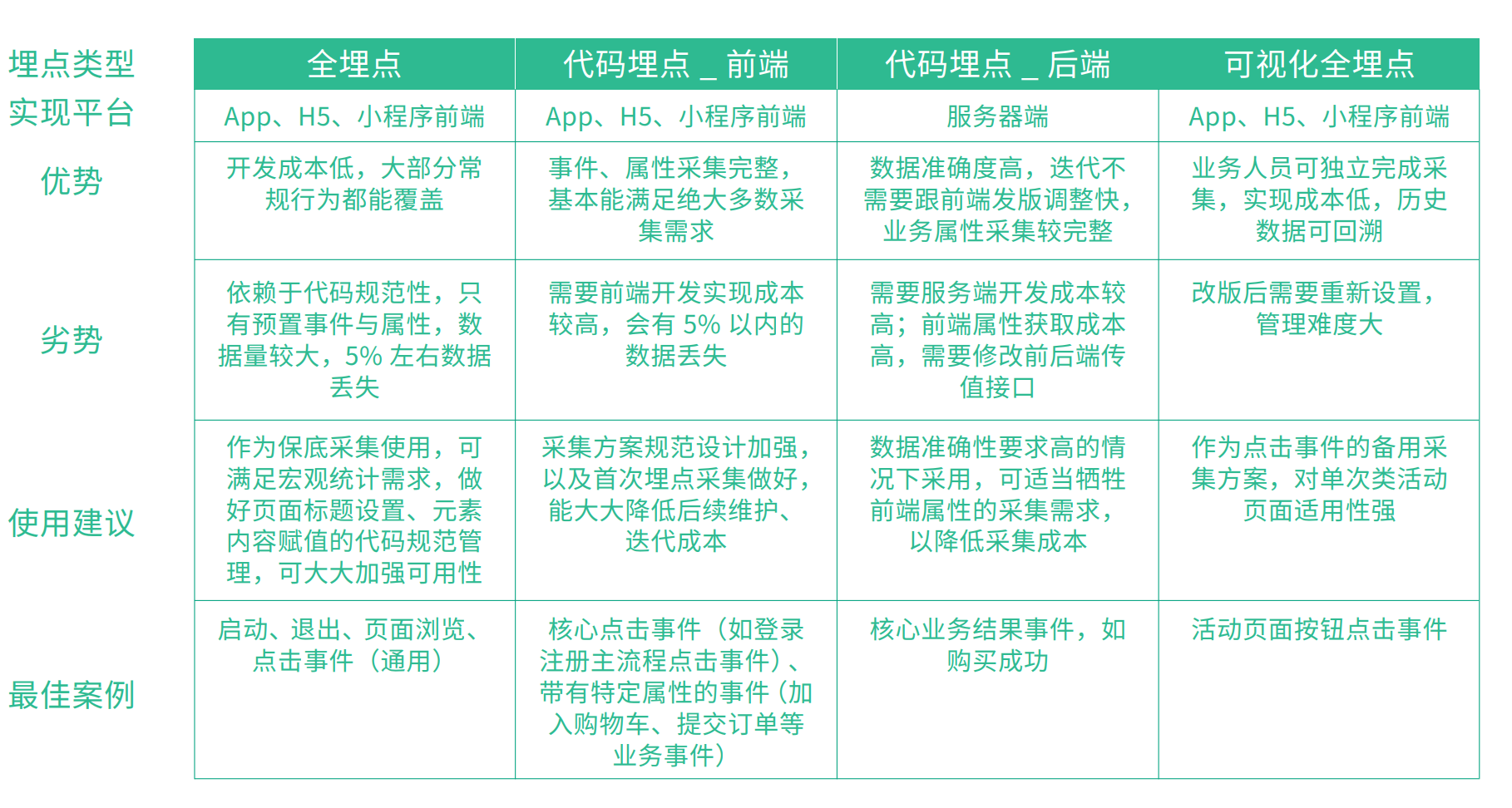
埋點上報方式
對於一個埋點方案來說,數據上報有兩個點需要著重考慮:
- 對跨域做特殊處理。
- 頁面銷毀後,如何還能夠將未上傳的埋點數據成功上報
參考 //juejin.cn/post/6844904153739706375
圖片請求
有下面幾點優勢:
- 沒有跨域問題,一般這種上報數據,程式碼要寫通用的,img 天然支援跨域;(排除 ajax)
- 不會阻塞頁面載入,影響用戶的體驗,只要 new Image 對象就好了, 通過它的onerror和onload事件來檢測發送狀態;(排 除 JS/CSS 文件資源方式上報)
- 在所有圖片中,簡單、安全、相比PNG/JPG體積最小;(比較 PNG/JPG)(tip:最小的BMP文件需要74個位元組,PNG需要67個位元組,而合法的GIF,只需要43個字
這種使用方式也存在缺陷。首先對於src 中的URL內容是有大小限制的,太大的數據量不適用。詳細看這裡。其次,在頁面卸載的時候,若存在數據未發送的情況,會先將對應的數據發送完,再執行頁面卸載。這種情況下,會在體驗上給使用者帶來不方便。
GET 請求
GET把參數包含在URL中,也就是說我們的上報的數據是在一個url 參數中或者是幾個參數中,例如 ?data=XXXX 這裡的data 就是我們上報的數據
GET 請求 最大的特點就是簡單,但是同時也帶來了很多其他的問題,首先是安全問題因為GET 請求參數被暴露在IURL 中,GET請求只能進行url編碼,而POST支援多種編碼方式,其次GET請求在URL中傳送的參數是有長度限制的,也就是如果你上報的數據內容比較多,可能會被截斷。
POST 請求
POST 請求 相比GET 請求首先就是更加安全,其次是支援多種編碼,而且所能發送的數據量也更大,看起來是個不錯的選擇,但是還是不如圖片請求好
埋點管理設計
整個埋點的事件我們可以使用4W1H 進行表示
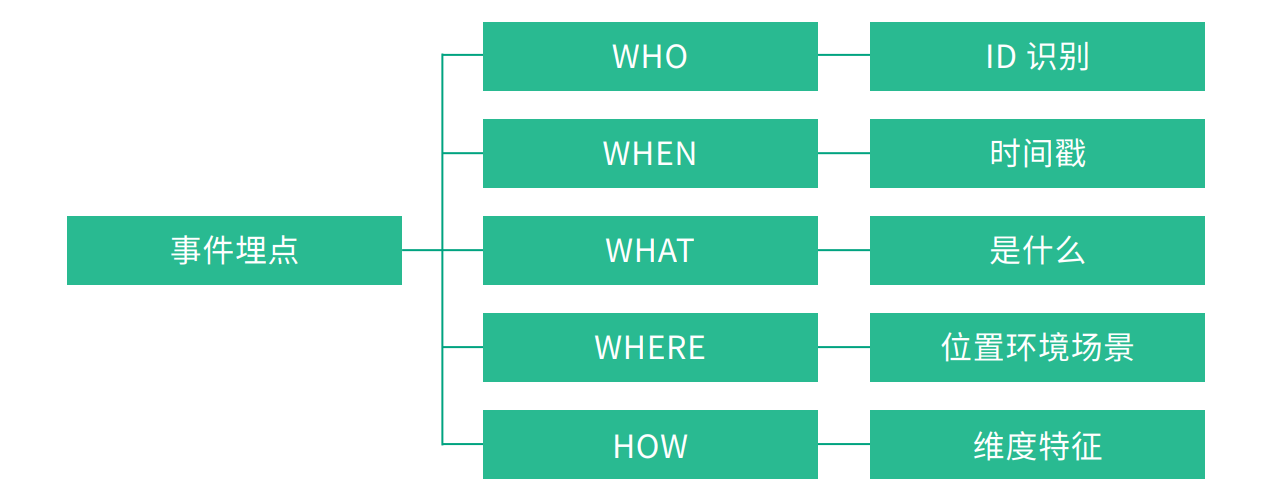
下面是APP 端的一個例子
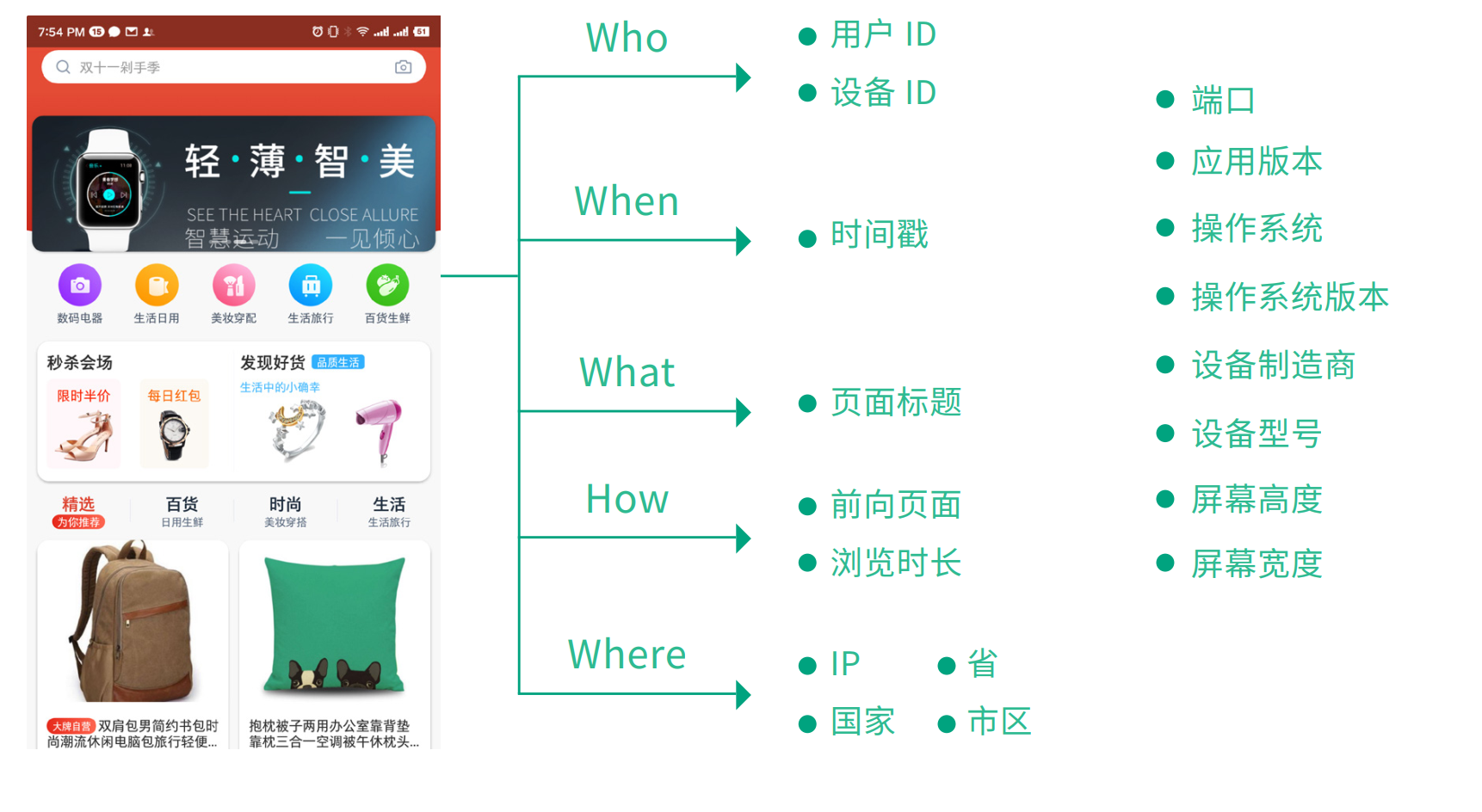
事件模型
我們使用「事件模型( Event 模型)」來描述用戶的各種行為,事件模型包括事件( Event )和用戶( User )兩個核心實體。整個埋點的屬性,我們可以分為兩大類,第一類是事件屬性,第二類是用戶屬性。
為什麼這兩個實體結合在一起就可以清晰地描述清楚用戶行為?實際上,我們在描述用戶行為時,往往只需要描述清楚幾個要點,即可將整個行為描述清楚,要點包括:是誰、什麼時間、什麼地點、以什麼方式、幹了什麼。而事件( Event )和用戶( User )這兩個實體結合在一起就可以達到這一目的。下面分別介紹一下這兩個實體。
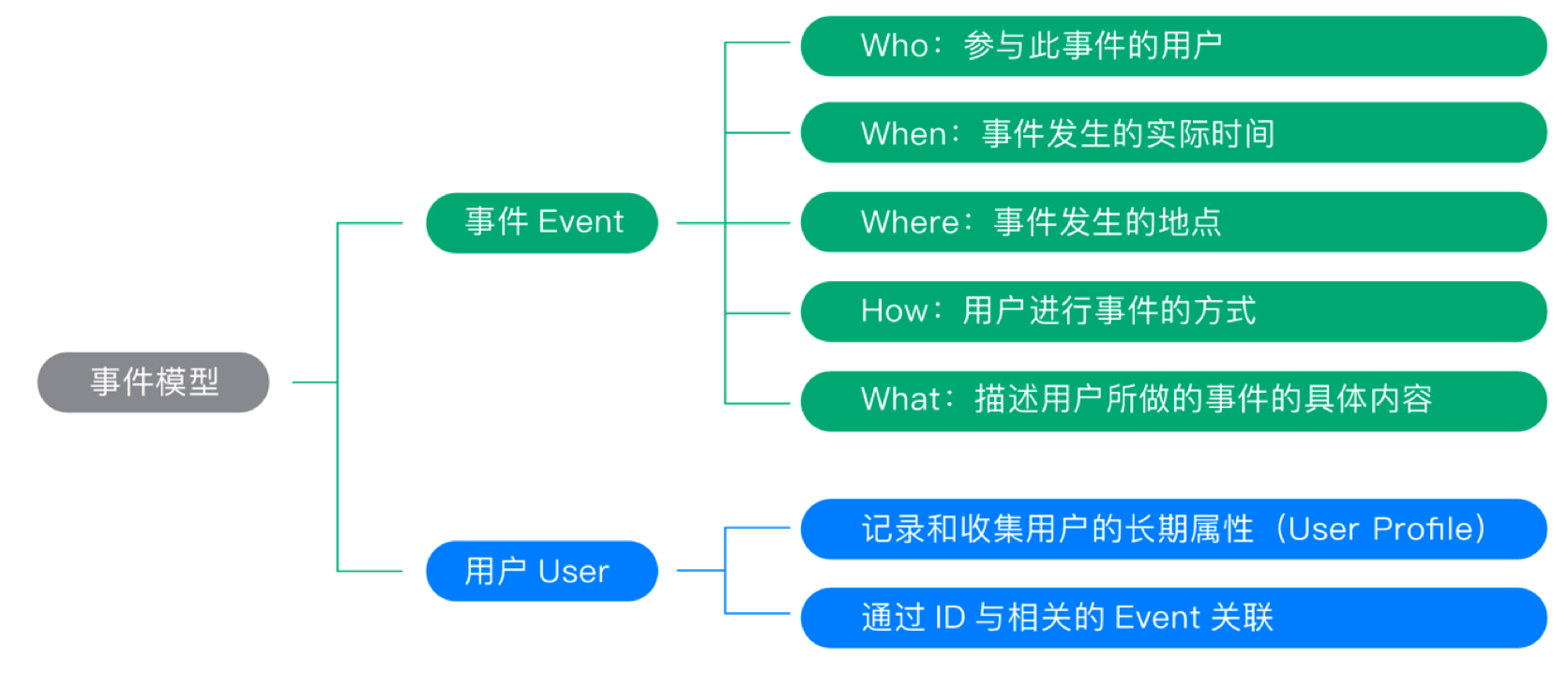
一個完整的事件( Event ),包含如下的幾個關鍵因素:
Who:即參與這個事件的用戶是誰。
When:即這個事件發生的實際時間。
Where:即事件發生的地點。
How:即用戶從事這個事件的方式。這個概念就比較廣了,包括用戶使用的設備、使用的瀏覽器、使用的 App 版本、作業系統版本、進入的渠道、跳轉過來時的 referer 等。
What:以欄位的方式記錄用戶所做的事件的具體內容。不同的事件需要記錄的資訊不同,下面給出一些典型的例子:
對於一個「購買」類型的事件,則可能需要記錄的欄位有:商品名稱、商品類型、購買數量、購買金額、 付款方式等;
對於一個「搜索」類型的事件,則可能需要記錄的欄位有:搜索關鍵詞、搜索類型等;
對於一個「點擊」類型的事件,則可能需要記錄的欄位有:點擊 URL、點擊 title、點擊位置等;
對於一個「用戶註冊」類型的事件,則可能需要記錄的欄位有:註冊渠道、註冊邀請碼等;
對於一個「用戶投訴」類型的事件,則可能需要記錄的欄位有:投訴內容、投訴對象、投訴渠道、投訴方式等;
對於一個「申請退貨」類型的事件,則可能需要記錄的欄位有:退貨金額、退貨原因、退貨方式等。
描述事件的任意一個欄位,都是一個事件屬性。應該採集哪些事件,以及每個事件採集哪些事件屬性,完全取決於產品形態以及分析需求。
事件的設計
下面分別是 H5、APP 、小程式 端埋點的一個設計
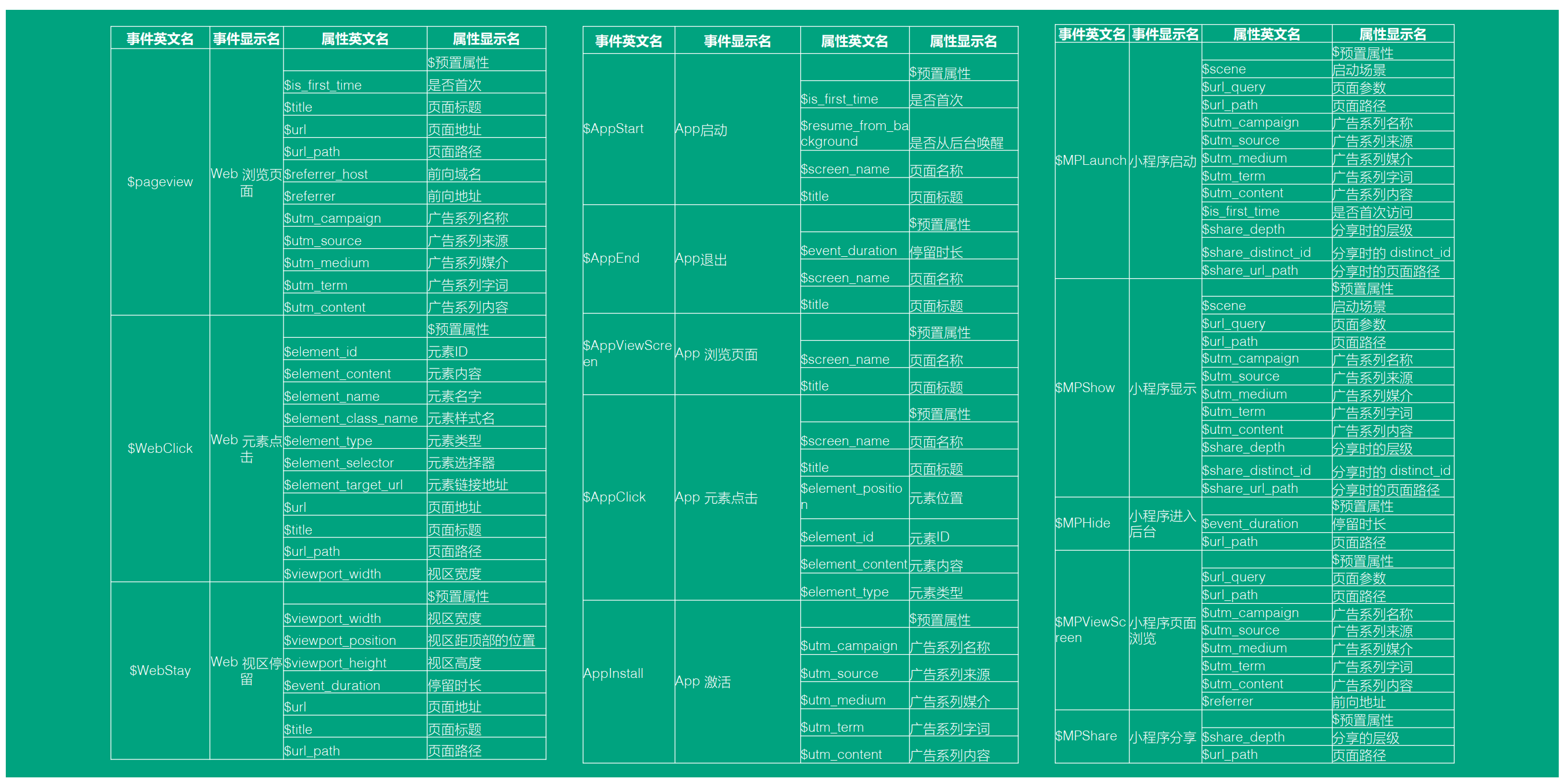
基本規範
我們在設計的時候要注意一些基本的規範,例如我們屬性的命名,這樣才能可以更好的維護
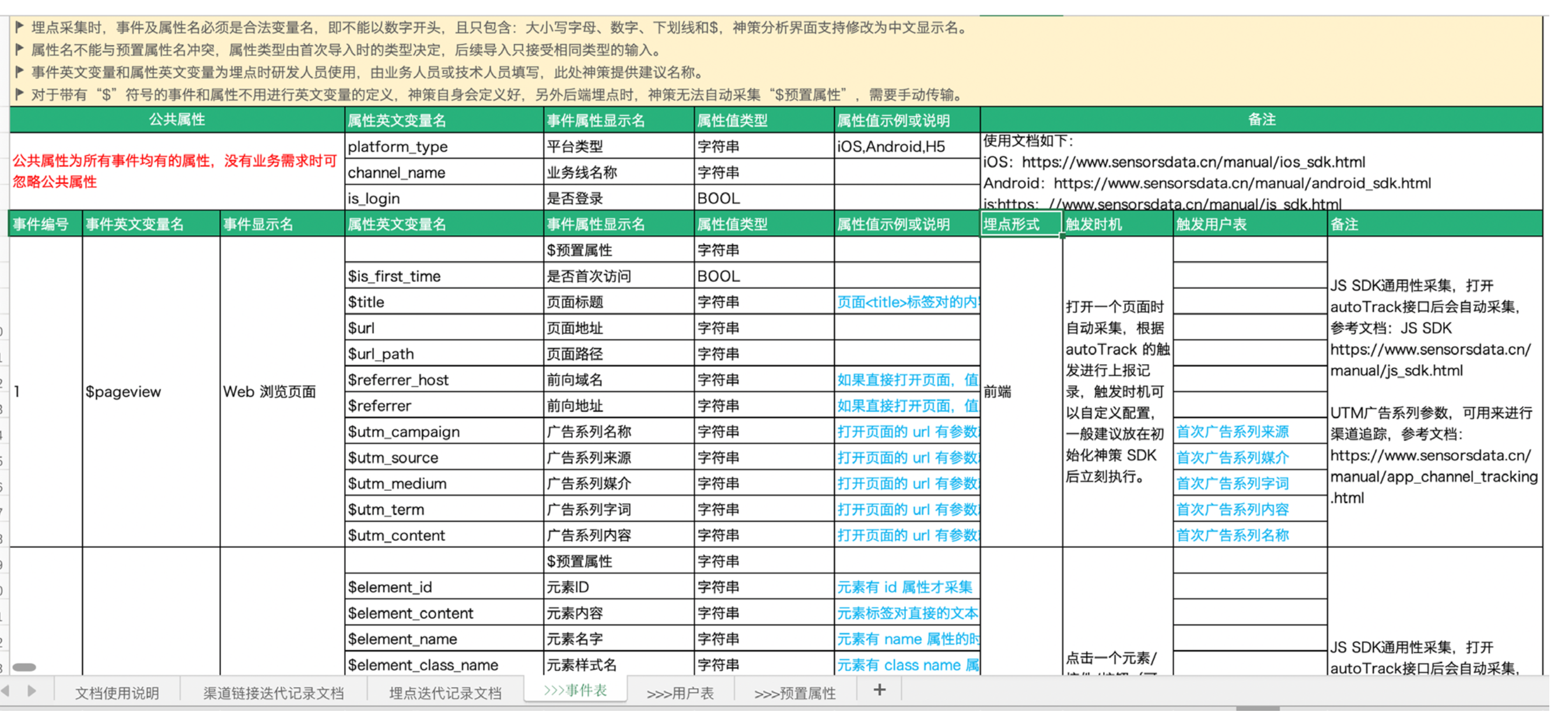
預置屬性
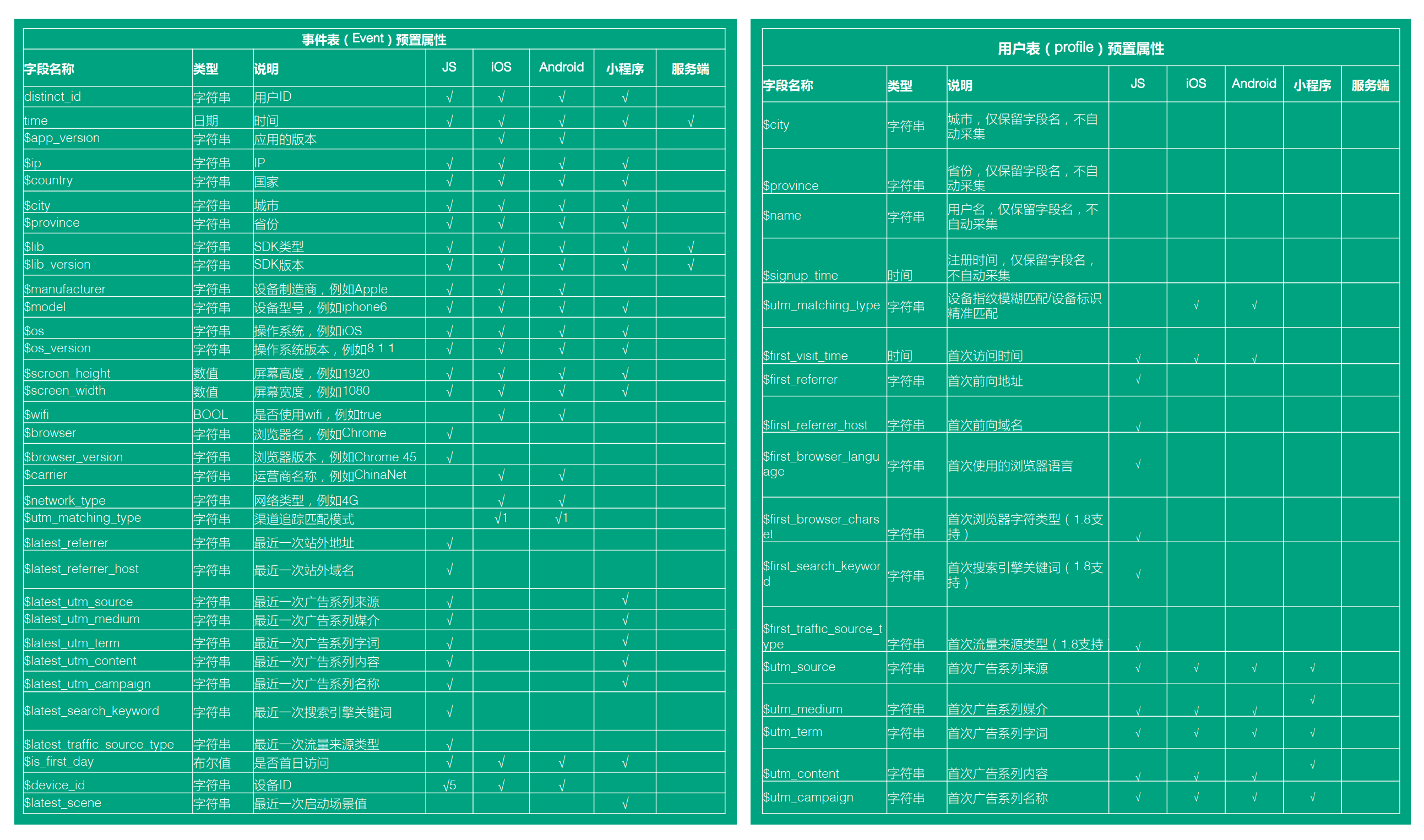
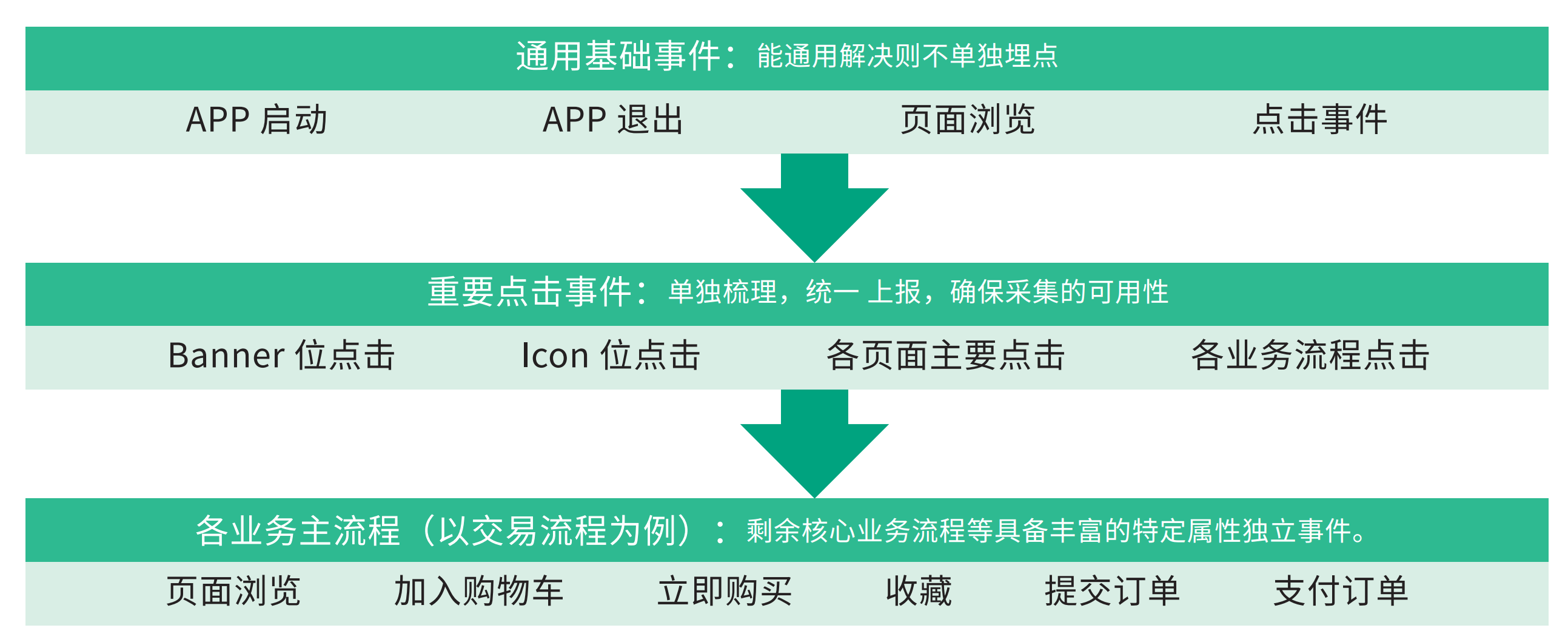
設計原則
整個埋點的設計我們應該遵循一下幾個原則,從而可以更好的維護和管理整個埋點系統
通用基礎事件
埋點時間能通用則不單獨埋點,不是說單獨埋點越多越好,我們應該儘可能的從上層設計比較通用的事件,這樣方便復用。
重要事件
重要事件單獨處理,統一上報,保證採集的可用性
業務主流程
對於主要的業務流程,我們可以設計獨立的事件,從而方便更好的分析
自定義事件
其實所有的事件都是自定義事件,但是我們為什麼還是要區分自定義事件呢?
這是因為我們在一開始定義可很多通用的事件,所以我們的自定義事件是相對我們的通用事件而言的,但是我們怎麼去定義一個自定義事件嗎,其實還要考慮到通用的屬性,因為這樣我們可以復用通用事件的一些屬性的定義,而不是完全重新設計一套東西。
舉例來說,一個電商產品可能包含如下事件:用戶註冊、瀏覽商品、添加購物車、支付訂單等,這裡我們就那用戶註冊事件來說吧,其實它應該是一個點擊事件,但是和點擊事件不一樣的是,我們需要添加一些新的屬性,所以我們可以在點擊事件的基礎上去添加屬性,有點類似程式語言的繼承,但是有的時候我們也可以去組合多個事件的屬性,其實這個是不常見的。
數據從生產到應用的流程
業務流程
確定場景或目標
確定一個場景,或者一個目標。比如,我們發現很多用戶訪問了註冊頁面,但是最終完成註冊的很少。那麼我們的目標就是提高註冊轉化率,了解為什麼用戶沒有完成註冊,是哪一個步驟擋住用戶了。
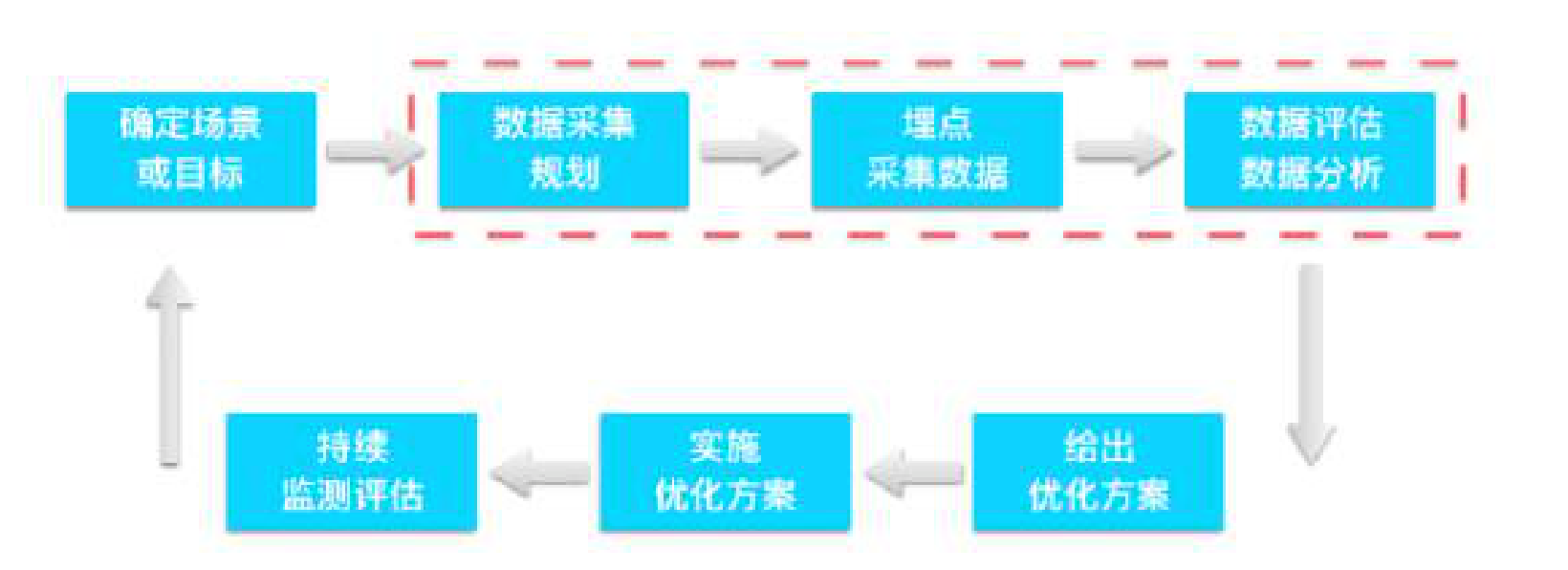
數據採集規劃
思考哪些數據我們需要了解,以幫助我們實現這個目標。比如對於之前的目標,我們需要拆解從進入註冊頁面到完成註冊的每一個步驟的數據,每一次輸入的數據,同時,還有完成或者未完成這些步驟的人的特徵數據。
埋點採集數據
我們需要確定誰來負責收集數據,一般是工程師,有些企業有專門的數據工
程師,負責埋點採集數據。
數據評估和數據分析
給出優化方案
發現問題後,怎麼給出解決方案。比如,是否需要在設計上改進,或者是否是工程上的 bug。
實施優化方案
誰負責實現解決方案,需要確定方案的實施責任人。
評估解決方案的效果
進行下一輪數據採集和分析,回到第一步繼續迭代。
知易行難。這整個流程里,第 2 步到第 4 步是關鍵。目前傳統的服務商
比如 Google Analytics、百度統計、友盟所採用的方式稱作 Capture 模
式。通過在客戶端埋下確定的點,採集相關數據到雲端,最終在雲端做呈
現。
開發流程
首先是基於一定的需求出發,然後產品/業務/分析師 對需求進行評審,主要就是需求同步,資訊對齊,接下來就是埋點的開發與測試,埋點上線之後,數據同學開始進行數據需求開發在此過程中對埋點進行驗收,最後對數據需求進行交付
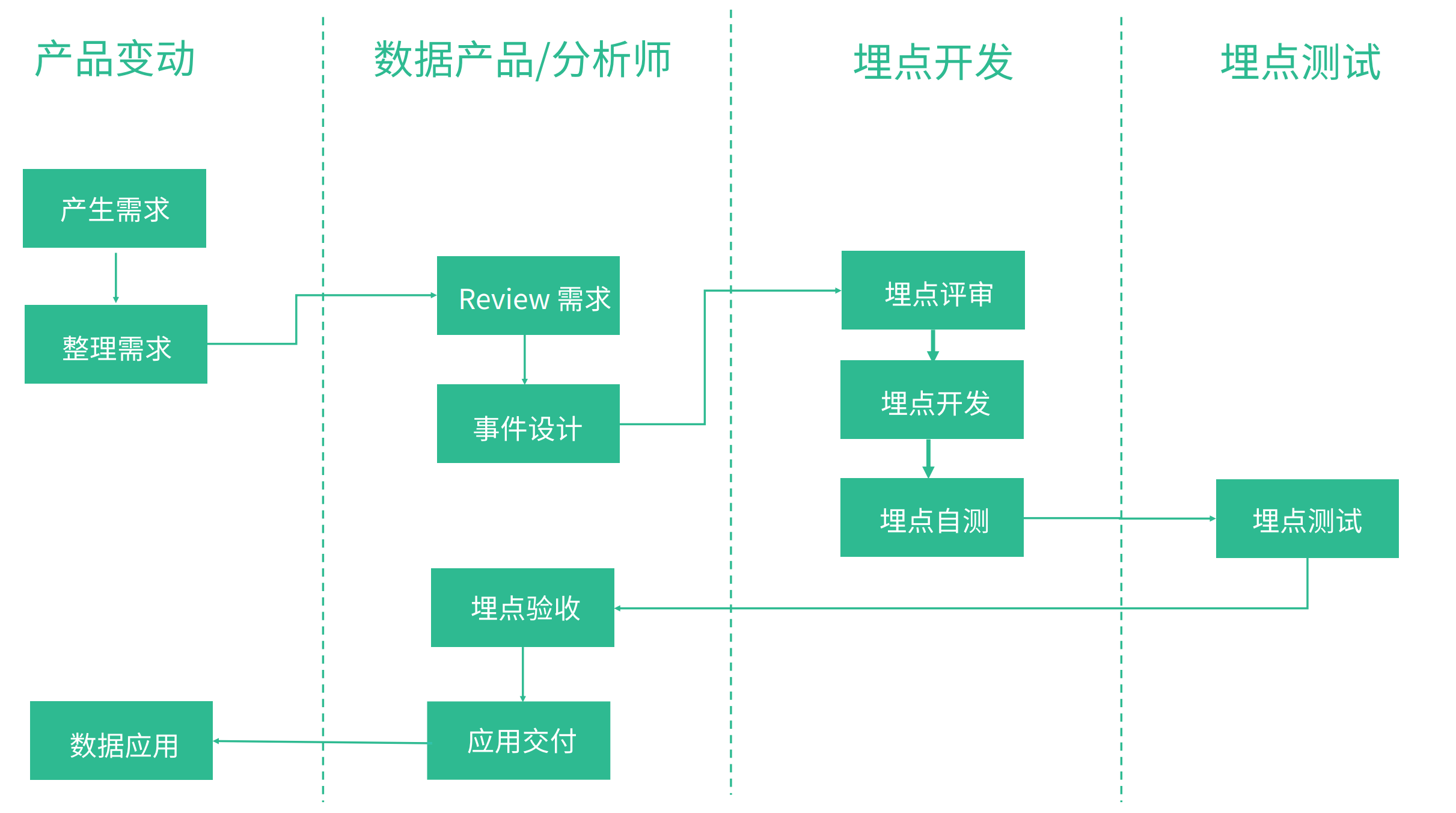
這個過程,需要專門投入專人去做這個事情,企業需要訂製頂層的業務規範,上面的流程中有一個環節是沒有的,那就是埋點的下線。
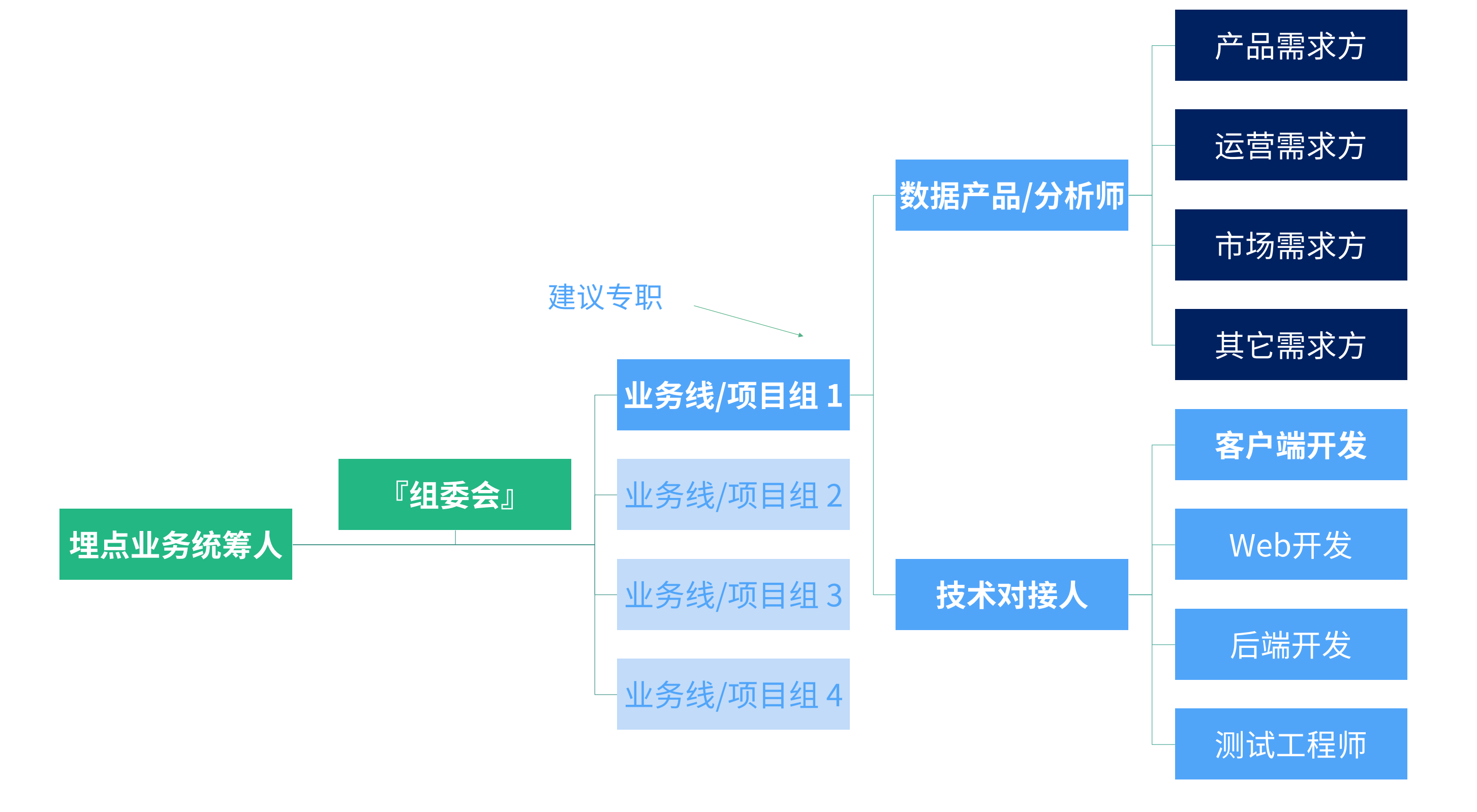
數據產品和數據分析師不僅要考慮到業務需求和數據分析的工作,還要站在業務線數據體系和數據應用負責人的角度,對埋點實施、管理、迭代、文檔、交付、支援進行掌控和維護
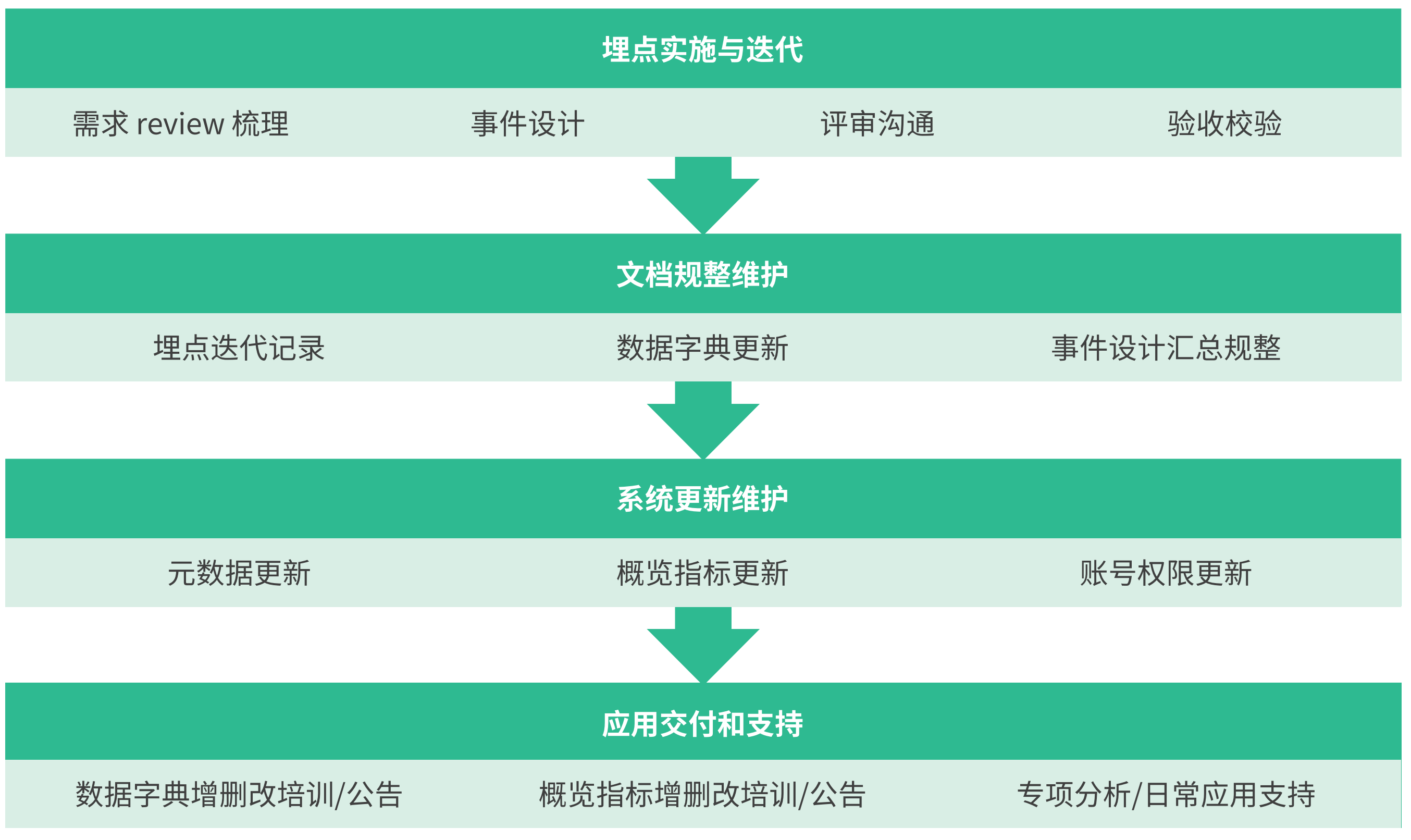
埋點管理系統設計
其實很多公司針對埋點會維護單獨的一個系統,這個系統主要維護了公司的全部埋點,其實你可以將其理解為和jira 類似的一套系統。下面我們看系統的核心
埋點列表
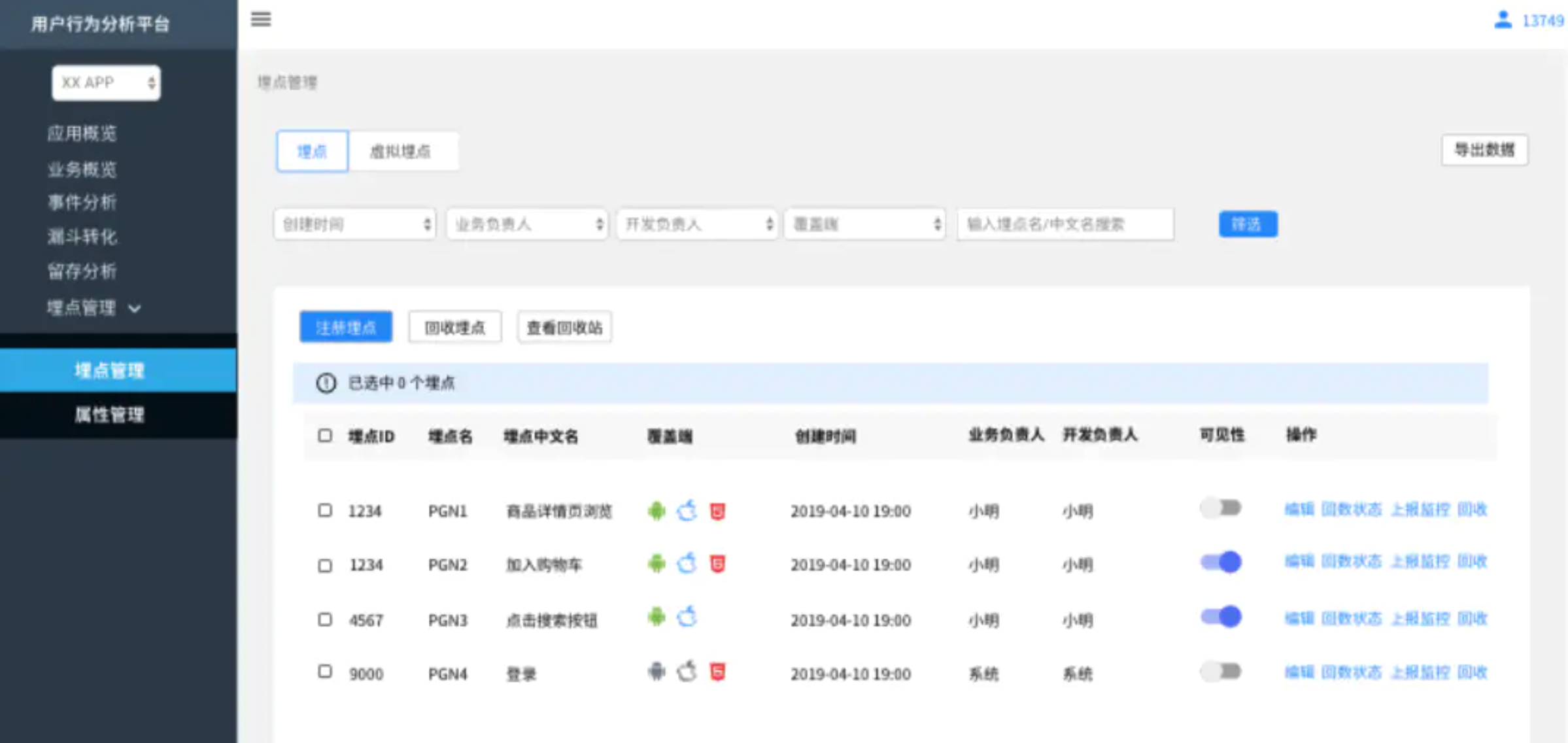
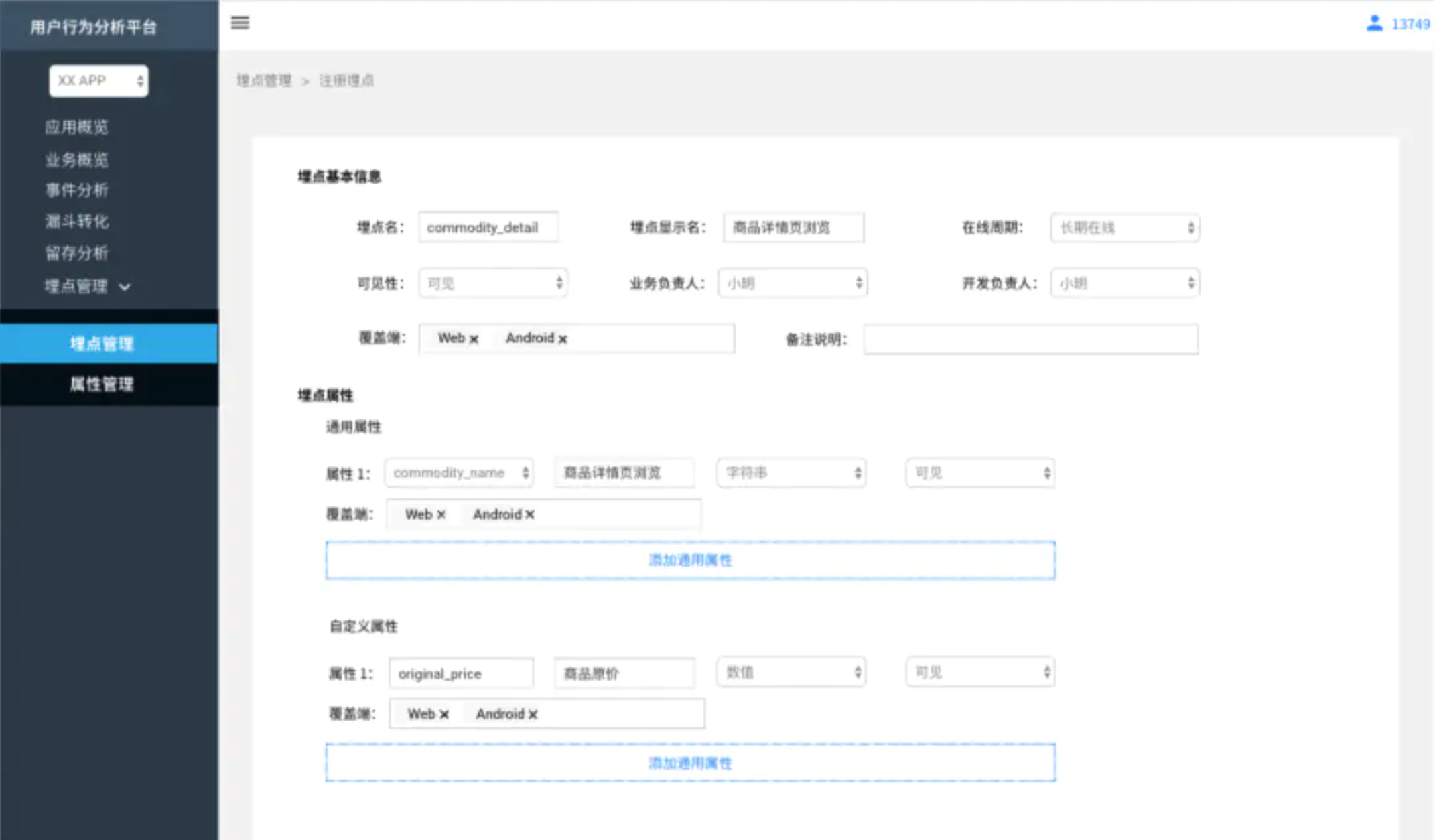
埋點註冊
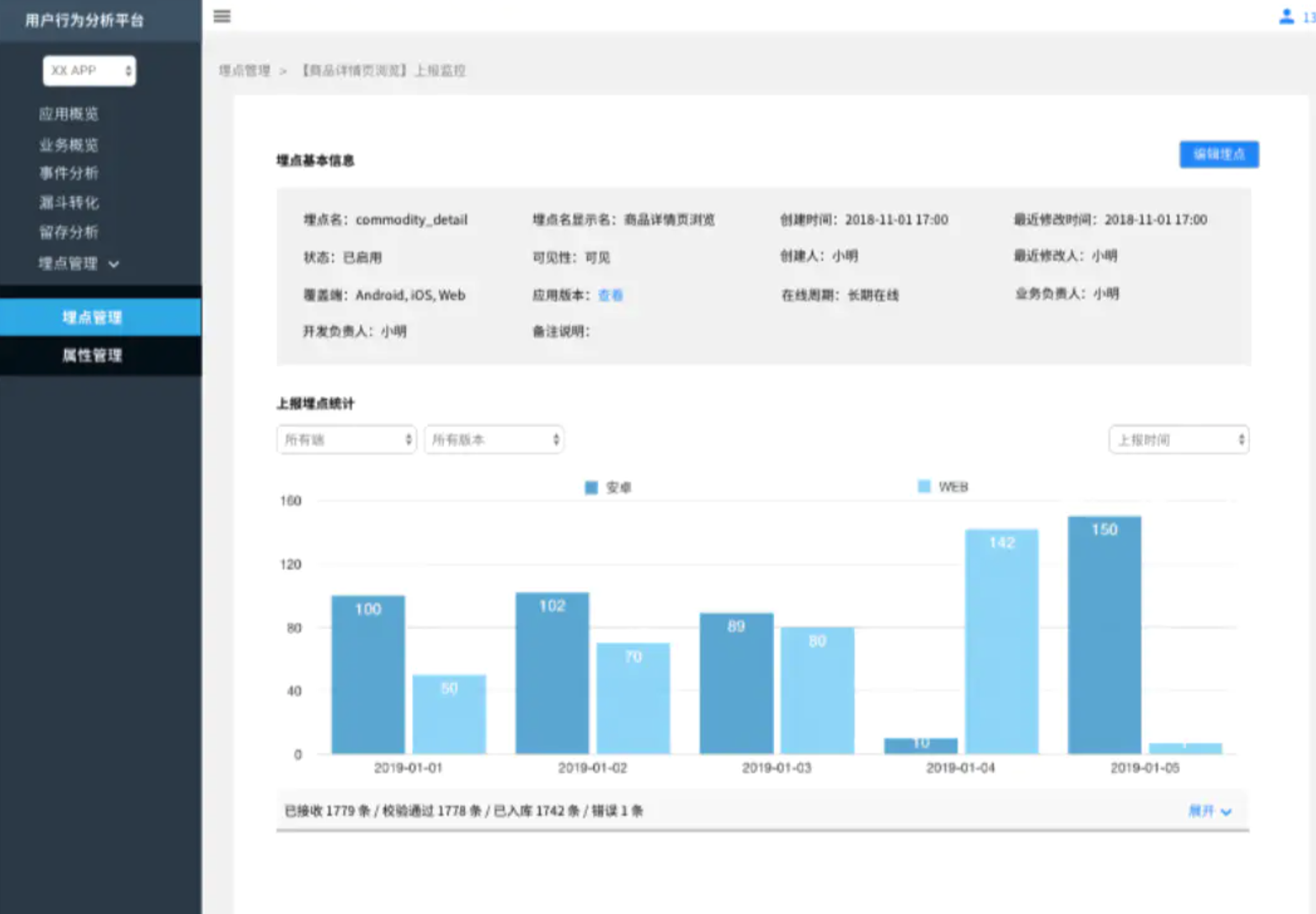
埋點詳情
主要提供關於埋點的基本資訊和統計資訊
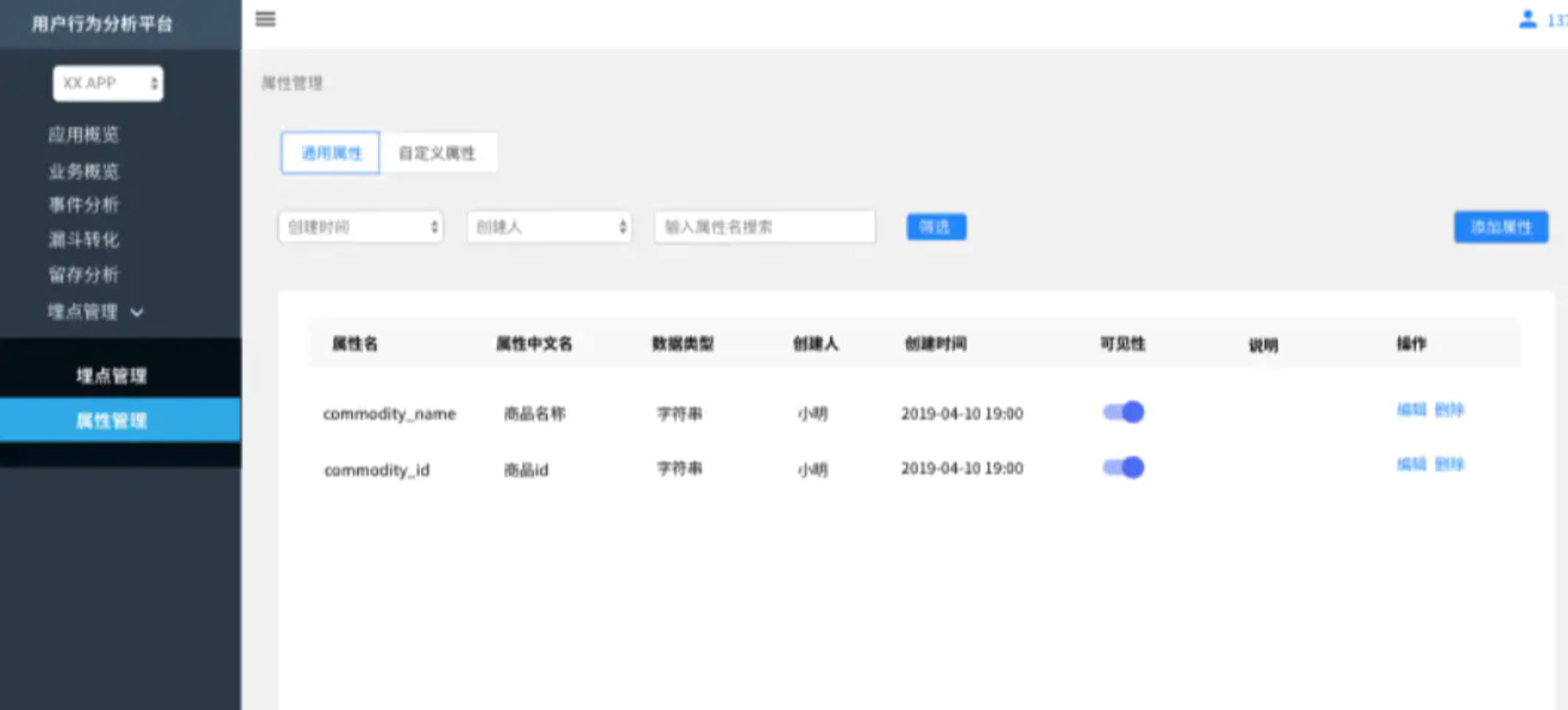
屬性管理
在埋點元數據中維護產品/業務層面的通用屬性,由數據團隊統一維護,所有可見的屬性,都可以在註冊/編輯埋點是添加屬性時搜索到。自定義屬性相對於通用屬性,是某個事件下特有的屬性,由業務方根據埋點方案維護
表設計/展示設計
| 欄位名稱 | 備註 |
|---|---|
| 埋點ID | 表的自增ID 即可 |
| 埋點域 | 是APP 埋點還是web 埋點還是都是 |
| 埋點中文名稱 | |
| 埋點英文名稱 | |
| 埋點位置 | 這個位置我們要求使用圖片進行展示+文字說明 這裡的圖片展示很重要,因為這樣很形象 |
| 埋點開發負責人 | 誰負責開發,很多時候會涉及到APP 和 Web 同時開發 |
| 埋點業務負責人 | 誰提的需求 |
| 埋點數據負責人 | 誰負責該埋點對應數據需求的處理,完成最終埋點的驗收 |
| 埋點業務含義 | 為什麼埋點,關於埋點的具體數據計算邏輯是什麼 |
| 埋點所屬事件 | 埋點所屬的事件,一般情況下我們都可以將一個埋點歸到我們已經定義的埋點事件中去 如果是沒有合適的埋點事件,需要先定義事件,再定義該埋點 |
| 埋點通用屬性 | 一旦歸類到某個埋點事件下面,我們要求上報該事件的全部屬性 |
| 自定義屬性 | 該埋點的自定義屬性 |
| 埋點程式碼git的PR | 是一個url,方便追蹤埋點程式碼 |
| 埋點的Jira | 埋點需求的jira 跟蹤 |
| 埋點的狀態 | 上線、測試、開發、下線、不可見等狀態 這裡下線,指的是如果埋點的功能不要了或者其他的一些原因,我們需要對埋點進行及時下線 |
| 埋點的創建時間 | |
| 埋點的上線時間 | |
| 埋點的更新時間 |
主要的就是上面這些,我們需要做的就是將這些進行前端展示和前端錄入。
數據解析在哪裡做
首先我們還是先看一下一個架構圖,從而理解一下數據流轉,下面就是數據流轉的一個大致方向

最後面的maxcompute 是我們的計算引擎,你可以將其當作是hive/spark ,具體是啥不重要,我們的數據通過前端(APP/web)前端上報,但是我們需要一個後端服務用來接收數據,然後後端獲取到數據之後進入消息隊列,最後我們再通過數據同步工具/數據消工具 把數據同步到大數據平台,從而開始數據計算和建模。
這裡有一個問題就是我們上報上來的數據可能是加密的,或者是我們的消息隊列是支援schema的(kafka 不支援),這種情況下我們的數據要不要解析呢?直接說結論吧,最好不要解析,將解析的工作放在計算引擎中做,原因很多,下面陳述兩點:
- 後端服務在這裡扮演的角色其實和消息隊列差不多,如果這個過程有邏輯越多,耦合就越高,可擴展性就差,例如前端上報的數據格式變了,或者是有其他的一些升級,這個時候後端也要做對應的操作,然後重新發布。
- 後端服務如果在這裡有大量的邏輯的話,對性能也不好,因為埋點的數據量很大,如果這裡出現瓶頸的話,就會出現服務不穩定,從而導致數據丟失
其實我看到有的人可能將IP 解析放在這裡做,其實這也是不合理的,因為做IP 解析之前你需要先做數據解密、JSON 解析,然後數據推送到消息隊列之前還要做數據加密,可以看出這裡的加解密想當於白做了。
但是凡事也有例外,你也可以在後端這裡做一些數據過濾,這樣可以減少後面數據處理的壓力,畢竟相比CPU ,網路才是最慢的。
數據丟失如何處理
這裡我們主要關注前端—>後端—> 消息隊列的這個環節的消息丟失,我們認為消息只要成功投遞就不會發生消息丟失,關於這一點很多消息隊列都可以保證,我們不做過多討論,可以參考: //blog.csdn.net/king14bhhb/article/details/114624437
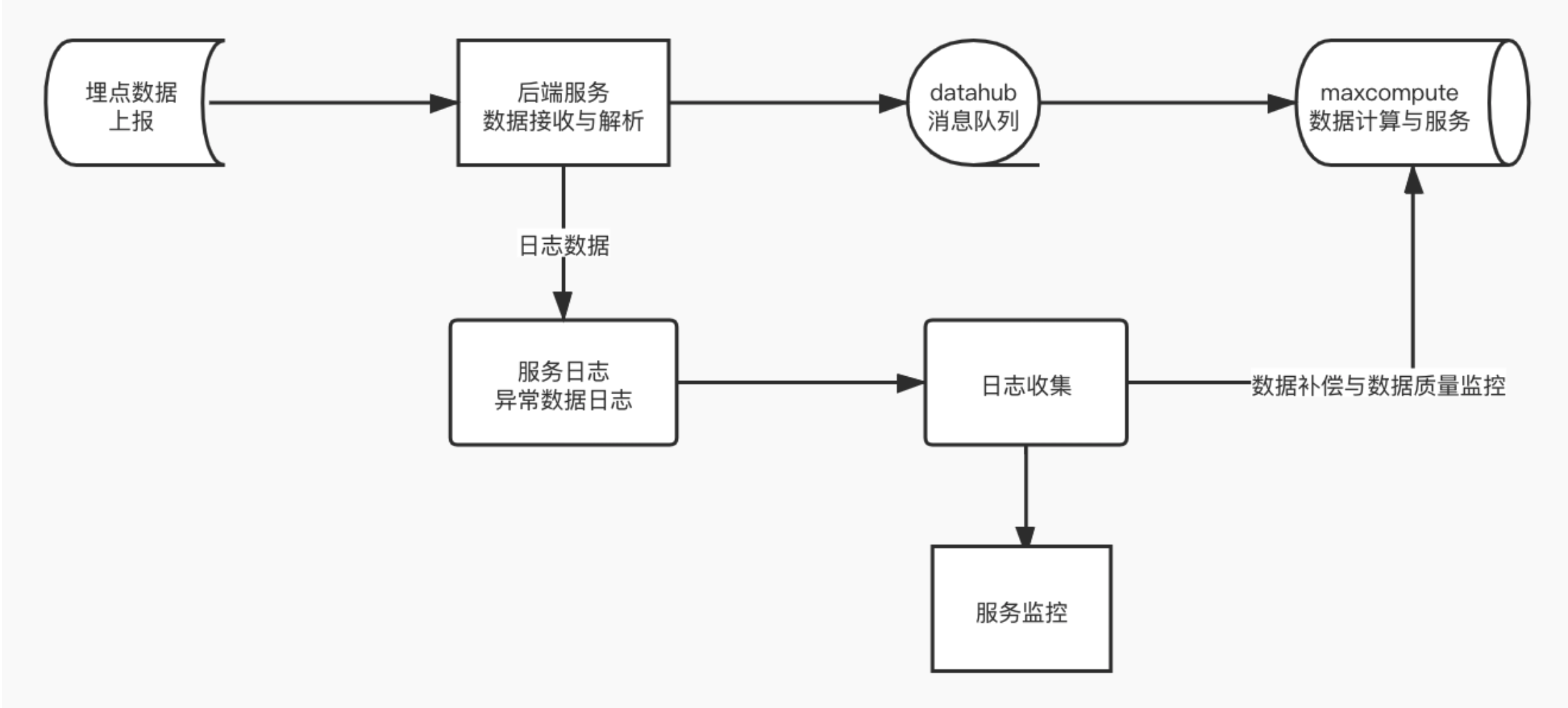
所以我們的消息丟失主要在後端這一塊,當然這裡丟失的原因,我們可以分為兩類
- 後端服務不穩定,前端請求得不到影響,數據丟失,我們可以認為是前端數據丟失
- 消息隊列服務不穩定,後端消息不能成功投遞,導致消息丟失,我們可以認為是後端數據丟失
可以看出來,這裡後端是關鍵,所以我們採取的措施是日誌補償的方式,也就是對於投遞失敗的消息,我們可以將其追加到特定的日誌文件,然後再將抽取到大數據計算平台,這裡有一個問題就是最好監控,如果有大量的消息投遞失敗,我們一定要及時修復,防止日誌文件過大。
對於後端服務的不穩定導致前端數據投遞失敗,我們需要做的就是做好監控和高可用,以及自動擴容,因為很多時候是因為流量急劇增加導致後端服務壓力太大,從而導致不穩定。
總結
-
埋點是數據平台很重要的一部分,如果只有業務數據沒有埋點數據,那麼用戶在我們平台上的一切行為對我們來說都是黑盒,所以我們想要做到精細化運營埋點是必須的。
-
由於埋點的數據從產生到使用鏈路很長,而且很複雜,這就需要我們做好設計和管理工作。
知識星球
其實知識星球我以前就建立了,當時覺得自己沒有那麼多的精力維護,不能很好的幫助有需要的同學們,所以一直沒有開放。最近很多同學私聊我學習路線,個人精力也是有限,並不能及時解答所有同學的問題。
通過調查,大部分同學表示願意加入知識星球,我也覺得這樣讓大家的提問更加有層次和意義,而不是問一些比較膚淺和不太合適的問題,有問題也能自己先查詢一下,這樣更好的交流和解答疑問,提升時間利用率。

猜你喜歡
Hadoop3數據容錯技術(糾刪碼)
Hadoop 數據遷移用法詳解
Flink實時計算topN熱榜
數倉建模分層理論
Hive之同比環比的計算

