別再用 Redis List 實現消息隊列了,Stream 專為隊列而生
上回說到使用 Redis 的 List 實現消息隊列有很多局限性,比如:
- 沒有良好的 ACK 機制;
- 沒有 ConsumerGroup 消費組概念;
- 消息堆積。
- List 是線性結構,想要查詢指定數據需要遍歷整個列表;
Stream 是 Redis 5.0 引入的一種專門為消息隊列設計的數據類型,Stream 是一個包含 0 個或者多個元素的有序隊列,這些元素根據 ID 的大小進行有序排列。
它實現了大部分消息隊列的功能:
- 消息 ID 系列化生成;
- 消息遍歷;
- 消息的阻塞和非阻塞讀;
- Consumer Groups 消費組;
- ACK 確認機制。
- 支援多播。
提供了很多消息隊列操作命令,並且借鑒 Kafka 的 Consumer Groups 的概念,提供了消費組功能。
同時提供了消息的持久化和主從複製機制,客戶端可以訪問任何時刻的數據,並且能記住每一個客戶端的訪問位置,從而保證消息不丟失。
廢話少說,先來看下如何使用,官網文檔詳見://redis.io/topics/streams-intro
XADD:插入消息
「雲嵐宗眾弟子聽命,擊殺蕭炎!」
當雲山最後一字落下,那瀰漫的緊繃氣氛,頓時宣告破碎,懸浮半空的眾多雲嵐宗長老背後雙翼一振,便是咻咻的划過天際,追殺蕭炎。
雲山使用以下指令向隊列中插入「追殺蕭炎」命令,讓長老帶領子弟去執行。
XADD 雲嵐宗 * task kill name 蕭炎
"1645936602161-0"
Stream 中的每個元素由鍵值對的形式組成,不同元素可以包含不同數量的鍵值對。
該命令的語法如下:
XADD streamName id field value [field value ...]
消息隊列名稱後面的 「*」 ,表示讓 Redis 為插入的消息自動生成唯一 ID,當然也可以自己定義。
消息 ID 由兩部分組成:
- 當前毫秒內的時間戳;
- 順序編號。從 0 為起始值,用於區分同一時間內產生的多個命令。
通過將元素ID與時間進行關聯,並強制要求新元素的ID必須大於舊元素的ID, Redis從邏輯上將流變成了一種只執行追加操作(append only)的數據結構。
這種特性對於使用流實現消息隊列和事件系統的用戶來說是非常重要的:
用戶可以確信,新的消息和事件只會出現在已有消息和事件之後,就像現實世界裡新事件總是發生在已有事件之後一樣,一切都是有序進行的。
XREAD:讀取消息
雲凌老狗使用如下指令接收雲山的命令:
XREAD COUNT 1 BLOCK 0 STREAMS 雲嵐宗 0-0
1) 1) "\xe4\xba\x91\xe5\xb2\x9a\xe5\xae\x97"
2) 1) 1) "1645936602161-0"
2) 1) "task"
2) "kill"
3) "name"
4) "蕭炎" # 蕭炎
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
該指令可以同時對多個流進行讀取,每個心法對應含義如下:
- COUNT:表示每個流中最多讀取的元素個數;
- BLOCK:阻塞讀取,當消息隊列沒有消息的時候,則阻塞等待, 0 表示無限等待,單位是毫秒。
- ID:消息 ID,在讀取消息的時候可以指定 ID,並從這個 ID 的下一條消息開始讀取,0-0 則表示從第一個元素開始讀取。
如果想使用 XREAD 進行順序消費,每次讀取後要記住返回的消息 ID,下次調用 XREAD 就將上一次返回的消息 ID 作為參數傳遞到下一次調用就可以繼續消費後續的消息了。
雲韻宗主,我今天剛到雲嵐宗,歷史的消息就不接了,只想接收我使用 XREAD 阻塞等待的那一刻開始通過 XADD 發布的消息要咋整?
運行「$」心法即可,心法的最後 「$」符號表示讀取最新的阻塞消息,讀取不到則一直死等。
等待過程中,其他長老向隊列追加消息,則會立即讀取到。
XREAD COUNT 1 BLOCK 0 STREAMS 雲嵐宗 $
這麼容易就實現消息隊列了么?說好的 ACK 機制呢?
這裡只是開胃菜,通過 XREAD 讀取的數據其實並沒有被刪除,當重新執行XREAD COUNT 2 BLOCK 0 STREAMS 雲嵐宗 0-0指令的時候又會重新讀取到。
所以我們還需要 ACK 機制,
接下來,我們來一個真正的消息隊列。
ConsumerGroup
Redis Stream 的 ConsumerGroup(消費者組)允許用戶將一個流從邏輯上劃分為多個不同的流,並讓 ConsumerGroup 的消費者去處理。
它是一個強大的支援多播的可持久化的消息隊列。 Redis Stream 借鑒了 Kafka 的設計。
Stream 的高可用是建立主從複製基礎上的,它和其它數據結構的複製機制沒有區別,也就是說在 Sentinel 和 Cluster 集群環境下 Stream 是可以支援高可用的。
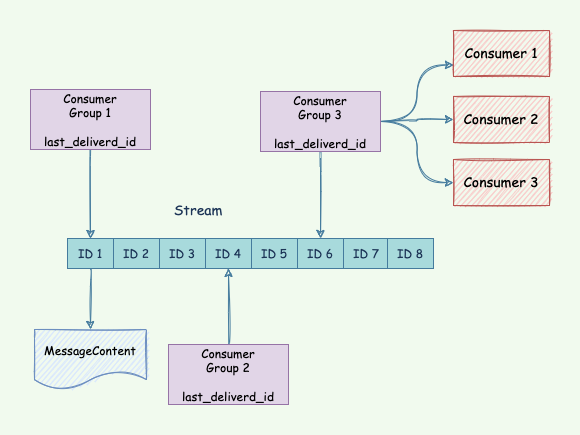
- Redis Stream 的結構如上圖所示。有一個消息鏈表,每個消息都有一個唯一的 ID 和對應的內容;
- 消息持久化;
- 每個消費組的狀態是獨立的,不不影響,同一份的 Stream 消息會被所有的消費組消費;
- 一個消費組可以有多個消費者組成,消費者之間是競爭關係,任意一個消費者讀取了消息都會使 last_deliverd_id 往前移動;
- 每個消費者有一個 pending_ids 變數,用於記錄當前消費者讀取了但是還沒 ack 的消息。它用來保證消息至少被客戶端消費了一次。
消費組實現的消息隊列主要涉及以下三個指令:
- XGROUP用於創建、銷毀和管理消費者組。
- XREADGROUP用於通過消費者組從流中讀取。
- XACK是允許消費者將待處理消息標記為已正確處理的命令。
創建消費組
Stream 通過 XGROUP CREATE 指令創建消費組 (Consumer Group),需要傳遞起始消息 ID 參數用來初始化 last_delivered_id 變數。
我們使用 XADD 往 bossStream 隊列插入一些消息:
XADD bossStream * name zhangsan age 26
XADD bossStream * name lisi age 2
XADD bossStream * name bigold age 40
如下指令,為消息隊列名為 bossStream 創建「青龍門」和「六扇門」兩個消費組。
# 語法如下
# XGROUP CREATE stream group start_id
XGROUP CREATE bossStream 青龍門 0-0 MKSTREAM
XGROUP CREATE bossStream 六扇門 0-0 MKSTREAM
- stream:指定隊列的名字;
- group:指定消費組名字;
- start_id:指定消費組在 Stream 中的起始 ID,它決定了消費者組從哪個 ID 之後開始讀取消息,
0-0從第一條開始讀取,$表示從最後一條向後開始讀取,只接收新消息。 - MKSTREAM:默認情況下,XGROUP CREATE命令在目標流不存在時返回錯誤。可以使用可選
MKSTREAM子命令作為 之後的最後一個參數來自動創建流。
讀取消息
讓「青龍門」消費組的 consumer1 從bossStream 阻塞讀取一條消息:
XREADGROUP GROUP 青龍門 consumer1 COUNT 1 BLOCK 0 STREAMS bossStream >
1) 1) "bossStream"
2) 1) 1) "1645957821396-0"
2) 1) "name"
2) "zhangsan"
3) "age"
4) "26"
語法如下:
XREADGROUP GROUP groupName consumerName [COUNT n] [BLOCK ms] STREAMS streamName [stream ...] id [id ...]
[] 內的表示可選參數,該命令與 XREAD 大同小異,區別在於新增 GROUP groupName consumerName 選項。
該選項的兩個參數分別用於指定被讀取的消費者組以及負責處理消息的消費者。
其中:
>:命令的最後參數>,表示從尚未被消費的消息開始讀取;- BLOCK:阻塞讀取;
敲黑板了
如果消息隊列中的消息被消費組的一個消費者消費了,這條消息就不會再被這個消費組的其他消費者讀取到。
比如 consumer2 執行讀取操作:
XREADGROUP GROUP 青龍門 consumer2 COUNT 1 BLOCK 0 STREAMS bossStream >
1) 1) "bossStream"
2) 1) 1) "1645957838700-0"
2) 1) "name"
2) "lisi"
3) "age"
4) "2"
consumer2 不能再讀取到 zhangsan 了,而是讀取下一條 lisi 因為這條消息已經被 consumer1 讀取了。
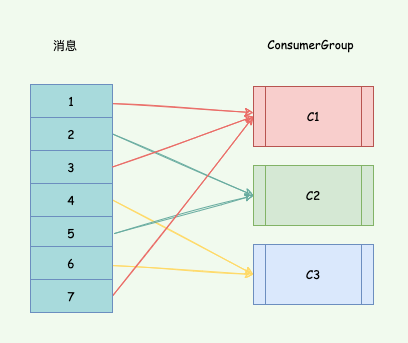
使用消費者的另一個目的可以讓組內的多個消費者分擔讀取消息,也就是每個消費者讀取部分消息,從而實現均衡負載。
比如一個消費組有三個消費者 C1、C2、C3 和一個包含消息 1、2、3、4、5、6、7 的流:
XPENDING 查看已讀未確認消息
為了保證消費者在消費的時候發生故障或者宕機重啟後依然可以讀取消息,Stream 內部有一個隊列(pending List)保存每個消費者讀取但是還沒有執行 ACK 的消息。
如果消費者使用了 XREADGROUP GROUP groupName consumerName 讀取消息,但是沒有給 Stream 發送 XACK 命令,消息依然保留。
比如查看 bossStream 中的 消費組「青龍門」中各個消費者已讀取未確認的消息資訊:
XPENDING bossStream 青龍門
1) (integer) 2
2) "1645957821396-0"
3) "1645957838700-0"
4) 1) 1) "consumer1"
2) "1"
2) 1) "consumer2"
2) "1"
1)未確認消息條數;2) ~ 3)青龍門中所有消費者讀取的消息最小和最大 ID;
查看 consumer1讀取了哪些數據,使用以下命令:
XPENDING bossStream 青龍門 - + 10 consumer1
1) 1) "1645957821396-0"
2) "consumer1"
3) (integer) 3758384
4) (integer) 1
ACK 確認
所以當接收到消息並且消費成功以後,我們需要手動 ACK 通知 Streams,這條消息就會被刪除了。命令如下:
XACK bossStream 青龍門 1645957821396-0 1645957838700-0
(integer) 2
語法如下:
XACK key group-key ID [ID ...]
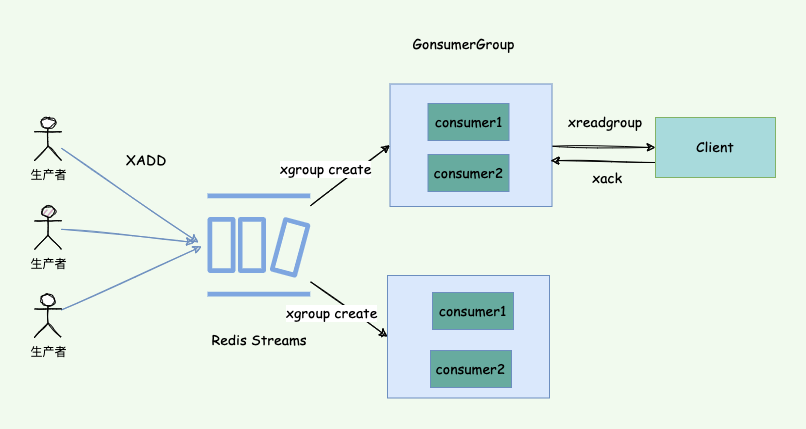
消費確認增加了消息的可靠性,一般在業務處理完成之後,需要執行 ack 確認消息已經被消費完成,整個流程的執行如下圖所示:
使用 Redisson 實戰
使用 maven 添加依賴
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.7</version>
</dependency>
添加 Redis 配置,碼哥的 Redis 沒有配置密碼,大家根據實際情況配置即可。
spring:
application:
name: redission
redis:
host: 127.0.0.1
port: 6379
ssl: false
@Slf4j
@Service
public class QueueService {
@Autowired
private RedissonClient redissonClient;
/**
* 發送消息到隊列
*
* @param message
*/
public void sendMessage(String message) {
RStream<String, String> stream = redissonClient.getStream("sensor#4921");
stream.add("speed", "19");
stream.add("velocity", "39%");
stream.add("temperature", "10C");
}
/**
* 消費者消費消息
*
* @param message
*/
public void consumerMessage(String message) {
RStream<String, String> stream = redissonClient.getStream("sensor#4921");
stream.createGroup("sensors_data", StreamMessageId.ALL);
Map<StreamMessageId, Map<String, String>> messages = stream.readGroup("sensors_data", "consumer_1");
for (Map.Entry<StreamMessageId, Map<String, String>> entry : messages.entrySet()) {
Map<String, String> msg = entry.getValue();
System.out.println(msg);
stream.ack("sensors_data", entry.getKey());
}
}
}
讀者朋友閱讀後有收穫的話點贊、收藏並分享,感謝支援。利他利己利黎明百姓。
參考鏈接:
//blog.51cto.com/u_15239532/2835962
//redis.io/topics/streams-intro
//redisson.org/articles/redis-streams-for-java.html


