PRML 回歸的線性模型
- 2022 年 3 月 1 日
- 筆記
- PRML 模式識別與機器學習
線性模型最簡單的形式就是輸入變數的線性模型,但是,將一組輸入變數的非線性函數進行線性組合,我們可以得到一類更加有用的函數,本章我們的討論重點就是輸入變數的非線性函數的線性組合。
1 線性基函數
回歸問題最簡單的形式就是輸入變數的線性函數,即
\]
這稱為線性回歸(linear regression),更一般地
\]
其中\(\phi_j(\mathbf x)\)稱為基函數(basis function),這是線性模型更一般的形式,具有更廣泛的應用。參數\(w_0\)使數據中可以存在任意的偏置,故這個值通常稱為偏置參數(bias parameter)。通常我們會定義\(\phi_0(\mathbf x)=1\),那麼此時
\]
其中\(\mathbf w=(w_0,\cdots,w_{M-1})^T\),\(\pmb\phi(\mathbf x)=(\phi_0(\mathbf x),\cdots,\phi_{M-1}(\mathbf x))^T\)。
在PRML 基礎知識一節中,我們曾經介紹過Polynomial Curve Fitting問題,那時的基函數即為\(\phi_j(x)=x^j\),這屬於多項式基函數,多項基函數在許多場合很有用,但是它的一個局限性在於:它們是輸入變數的全局函數,因此輸入空間中一個區域的改變會影響到所有其他區域,比如,在順序學習過程中,當我們有一個新得到的數據點,那麼原則上我們只需要修改與之相近的區域,但是在多項式基函數的例子中,新得到一個數據點將會影響到所有區域。另外,如果我們要建立的模型是分段的,那麼多項式基函數就有很大的局限性。對於此處出現的問題,我們可以這樣解決:把輸入空間切分為多個小區域,並對每個小區域用不同的多項式函數擬合。這樣的函數叫做樣條函數(spline function)。
對於基函數還有其他選擇,例如高斯基函數
\]
其中\(\mu_j\)控制了基函數在輸入空間的位置,參數\(s\)控制了基函數的空間大小。注意,雖然此種基函數稱為高斯基函數,但是它未必是一個歸一化的概率表達式,其歸一化係數並不重要,因為它將與一個調節參數\(w_j\)相乘。另一種基函數的例子是sigmoid基函數,即
\]
其中\(\sigma(x)\)是logistic sigmoid函數,在PRML 概率分布中4.1小節中我們已經見過這個函數,定義為\(\sigma(x)=\frac{1}{1+\text{exp}(-x)}\),該函數是S函數(sigmoid function)的一個簡單例子。因為我們已經證明S函數的另一個實例雙曲正切(hyperbolic tangent)函數等價於logistic sigmoid函數的平移和縮放,即\(\tanh(x)=2\sigma(2x)-1\),所以我們也可以選擇雙曲正切函數作為基函數。下圖展示了上述三個基函數的直觀影像,從左至右依次為:多項式基函數、高斯基函數、sigmoid基函數
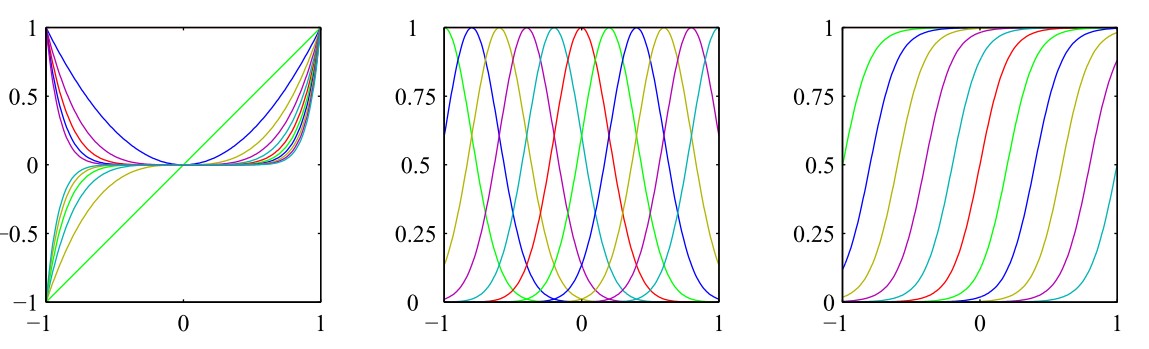
基函數的選擇實際上就是為了描述一個函數空間,根據所學知識,傅里葉(Fourier)函數可以描述任意的函數,因此,傅里葉基函數可以被選為基函數,這在訊號處理領域是尤其重要的,這種研究產生了一類被稱為小波(wavelet)的函數,為了簡化應用,這些基函數被選為正交的。
在本章中,我們通常不會關注基函數的具體形式,除非特別說明。
1.1 極大似然與最小平方
對於一般的問題而言,極大似然方法與最小誤差方法都是可行的思路,特別地,對於Polynomial Curve Fitting問題來說,就是極大似然與最小平方,現在來詳細地討論最小平方的方法與極大似然方法之間的關係。
假設目標變數\(t\)由兩部分組成:模型\(y(\mathbf x,\mathbf w)\)和雜訊\(\epsilon\)組成,其中雜訊\(\epsilon\)符合高斯分布(均值為零,精度為\(\beta\)),即
\]
則有
\]
從PRML 基礎知識5.2小節中知道,當我們新輸入一個\(\mathbf x\)的時候,為使平方損失函數最小,目標變數\(t\)的預測值應為
\]
注意,雜訊的假設說明,給定\(x\)的條件下,\(t\)的條件分布是單峰的,這對於⼀些實際應用來說是不合適的,後面一些章節將擴展到條件高斯分布的混合,那種情況下可以描述多峰的條件分布。
現在考慮一個輸入數據集\(\mathbf X=\{\mathbf x_1\cdots,\mathbf x_N\}\)和對應的目標值\(\mathbf t=\{t_1,\cdots,t_N\}\),於是有如下的似然函數
\]
在有監督學習(例如回歸問題和分類問題)領域內,我們不是在尋找模型來對輸入變數進行概率分布建模,因此\(\mathbf x\)總會出現在條件變數的位置上,因此此後不再在諸如\(p(\mathbf t|\mathbf x,\mathbf w,\beta)\)這類表達式中顯式地寫出\(\mathbf x\)。對上述似然函數取對數,得到
\ln p(\mathbf t|\mathbf w,\beta)&=\sum_{n=1}^N\ln\mathcal N(t_n|\mathbf w^T\pmb\phi(\mathbf x_n),\beta^{-1})\\
&=\sum_{n=1}^N\ln(\frac{1}{(2\pi\beta^{-1})^{1/2}}\text{exp}\{-\frac{(\mathbf x_n-\mathbf w^T\pmb\phi(\mathbf x_n))^2}{2\beta^{-1}}\})\\
&=\frac{N}{2}\ln\beta-\frac{N}{2}\ln(2\pi)-\beta E_D(\mathbf w)
\end{aligned}
\]
其中平方誤差和函數為
\]
這樣,我們就得到了一個重要的結論:當雜訊符合高斯分布時,極大似然方法等價於最小化平方和誤差函數方法,特別地,當我們添加一個懲罰項(以保證不會過擬合)的時候,該結論仍然成立,這在PRML 基礎知識的2.3小節中出現過。下面用極大似然方法確定參數\(\mathbf w\)和\(\beta\),上述對數似然函數對\(\mathbf w\)求偏導得到
\]
解得
\]
這被稱為最小平方問題的規範方程(normal equation),其中\(\mathbf\Phi\)是一個\(N\times M\)的矩陣,被稱為設計矩陣(design matrix)
\left(
\begin{array}
{cccc}
\phi_0(\mathbf x_1) & \phi_1(\mathbf x_1) & \cdots & \phi_{M-1}(\mathbf x_1)\\
\phi_0(\mathbf x_2) & \phi_1(\mathbf x_2) & \cdots & \phi_{M-1}(\mathbf x_2)\\
\vdots & \vdots & & \vdots\\
\phi_0(\mathbf x_N) & \phi_1(\mathbf x_N) & \cdots & \phi_{M-1}(\mathbf x_N)
\end{array}
\right)
\]
現令\(\mathbf\Phi^{\dagger}=(\mathbf\Phi^T\mathbf\Phi)^{-1}\mathbf\Phi^T\),稱為矩陣\(\mathbf\Phi\)的Moore-Penrose偽逆矩陣(pseudo-inverse matrix),可以視為逆矩陣概念對於非方陣的推廣,如果矩陣\(\mathbf\Phi\)是方陣且可逆,那麼有\(\mathbf\Phi^{-1}=\mathbf\Phi^{\dagger}\)。另外,當\(\mathbf\Phi^T\mathbf\Phi\)接近奇異矩陣時,直接求解規範方程會導致數值計算上的困難,此時可以通過奇異值分解(singular value decomposition or SVD)的方法解決。注意, 正則項的添加確保了矩陣是非奇異的。
對於偏置參數\(w_0\),如果我們顯式地寫出它,那麼誤差函數變為
\]
令其關於\(w_0\)的導數為零,解得
\quad\bar{t}=\frac1N\sum_{n=1}^Nt_n,
\quad\bar{\phi_j}=\frac1N\sum_{n=1}^N\phi_j(\mathbf x_n)
\]
因此\(w_0\)的作用就是補償了目標值的平均值與基函數的值的平均值的加權求和之間的差。
類似地,上述對數似然函數對\(\beta\)求偏導得到
\]
解得
\]
因此我們看到雜訊精度的倒數由目標值在回歸函數周圍的殘留方差(residual variance)給出。
3.2 順序學習
順序學習在數據集非常大或者數據點依次到達的情況下非常有用,一個常用的方法是隨機梯度下降(stochastic gradient descent)或者稱為順序梯度下降(sequential gradient descent)
\]
其中\(\tau\)表示迭代次數,\(\eta\)是學習率參數,\(E_n\)表示誤差函數,對於平方和誤差函數而言
\]
這和PRML 概率分布中3.9小節介紹的Robbins-Monro方法有相通的地方,該方法稱為最小均方(least-mean-squares or LMS)演算法,其中\(\eta\)的值需要仔細選取以保證收斂。
3.3 正則化最小平方
向誤差函數中添加正則項,總誤差函數變成了
\]
並給出如下定義
E_D(\mathbf w)&=\frac12\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2\\
E_W(\mathbf w)&=\frac12\mathbf w^T\mathbf w
\end{aligned}
\]
則可記總誤差函數為\(E_D(\mathbf w)+\lambda E_W(\mathbf w)\)。注意,正則化項並不是唯一的,但其中最簡單的形式就是\(\frac\lambda2\mathbf w^T\mathbf w\)。這種對於正則化項的選擇方法在機器學習文獻中稱為權值衰減(weight decay),因為在順序學習中,它傾向於讓權值向零的方向衰減,除非有數據支援;在統計學中,它提供了一個參數收縮(parameter shrinkage)的例子,因為這種方法把參數的值向零的方向收縮。將上述總誤差函數對\(\mathbf w\)求偏導並令其為零,解得
\]
這是\(\mathbf w_{ML}=(\mathbf\Phi^T\mathbf\Phi)^{-1}\mathbf\Phi^T\mathbf t\)的一個擴展。
正則化項可以選取其他形式,更一般地,總誤差函數為
\]
其中\(q=1\)的情形稱為套索(lasso),它的性質是:如果\(\lambda\)合理地大,那麼某些係數\(w_j\)將會等於零,從而產生了一個稀疏(sparse)模型。我們注意到最小化上述的總誤差函數等價於在\(\sum_{j=1}^M|w_j|^q\leq\eta\)(其中\(\eta\)是選取的合適的值)的條件下將\(\frac12\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2\)進行最小化,不妨令\(\sum_{j=1}^M|w_j|^q=\eta\),那麼這通過拉格朗日乘數法很容易求解。下面兩幅圖說明了\(q=1\)時稀疏性的來源

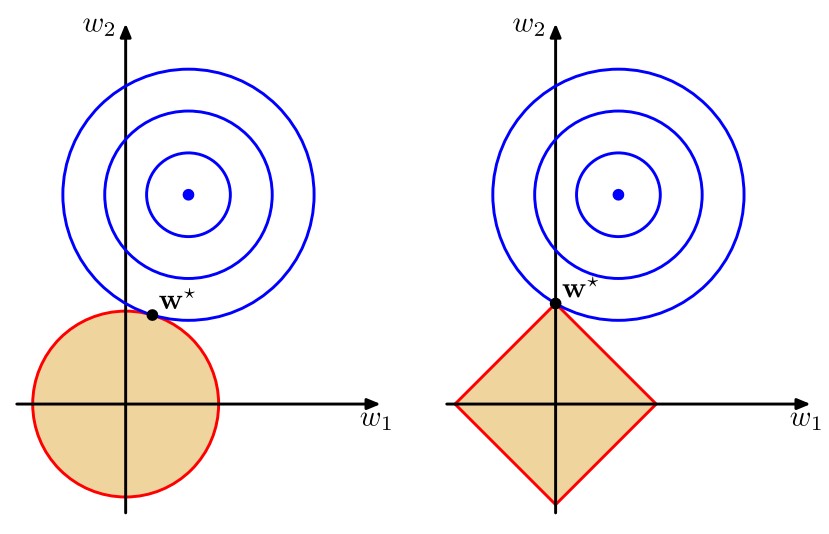
第一幅圖給出了不同的\(q\)值對應的正則項的輪廓線,第二幅圖中藍色同心圓即為\(\frac12\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2\)等於不同值對應的影像,因此該圖明確說明了當\(q=1\)時,解得的\(\mathbf w^*\)將會有某個\(w_j\)的數值為零。
3.4 多個目標變數
在實際應用中,我們可能想要預測\(K>1\)個變數,此時記要預測的目標變數為\(\mathbf t=(t_1,\cdots,t_K)^T\),那麼有兩個思路處理此問題:一是對每個目標變數單獨建模處理,二是引入一個整體的函數進行建模,即
\]
其中\(\mathbf y(\mathbf x,\mathbf w)\)是一個\(K\)維列向量,\(\mathbf W\)是一個\(M\times K\)的參數矩陣,\(\pmb\phi(\mathbf x)\)是一個\(M\)維列向量,每個元素為\(\phi_j(\mathbf x)\),並且\(\phi_0(\mathbf x)=1\)。如果我們令目標向量的條件概率分布是一個各向同性的高斯分布,則
\]
如果我們有觀測數據集\(\mathbf T=(\mathbf t_1^T,\cdots,\mathbf t_N^T)^T\),即該矩陣大小為\(N\times K\),其中第\(n\)行為\(\mathbf t_n^T\),並將輸入向量類似地組合成\(\mathbf X=(\mathbf x_1^T,\cdots,\mathbf x_N^T)^T\),那麼對數似然函數為
\ln p(\mathbf T|\mathbf X,\mathbf W,\beta)&=\sum_{n=1}^N\ln\mathcal N(\mathbf t_n|\mathbf W^T\pmb\phi(\mathbf x_n),\beta^{-1}\mathbf I)\\
&=\frac{NK}{2}\ln(\frac{\beta}{2\pi})-\frac\beta2\sum_{n=1}^N||\mathbf t_n-\mathbf W^T\pmb\phi(\mathbf x_n)||^2
\end{aligned}
\]
類似地可解出
\]
該結果可以分解為
\]
因此不同的目標變數實際上是可以被分解出來的,偽逆矩陣\(\mathbf\Phi^{\dagger}\)是被所有目標變數所共享的,所以,單一目標變數的情形很容易擴展到多變數的情形。
2 偏置-方差分解
頻率主義和貝葉斯主義看待模型複雜度的思路是不同的,本小節介紹頻率主義思路——偏置-方差分解。在PRML 基礎知識中5.2節中我們已經說明了平方損失函數的期望可以寫成(記\(h(\mathbf x)=E_t(t|\mathbf x)\))
\]
其中與\(y(\mathbf x)\)無關的第二項是由數據的雜訊造成的(如果雜訊為零,那麼\(\text{var}(t|\mathbf x)=0\))。顯然,如果我們有足夠多的數據點,那麼就能在很高的精度上建模得到\(h(\mathbf x)\)與\(y(\mathbf x)\)很接近。
如果我們使用由參數向量\(\mathbf w\)控制的函數\(y(\mathbf x,\mathbf w)\)對\(h(\mathbf x)\)建模,那麼從貝葉斯主義的觀點來看,模型的不確定性是通過\(\mathbf w\)的後驗概率分布來表示的。但是,頻率主義方法涉及到根據數據集\(D\)對\(\mathbf w\)進行點估計,然後試著通過下面的思想實驗來表示估計的不確定性。假設我們有許多數據集,每個數據集的大小為\(N\),並且每個數據集都獨立地從分布\(p(t,\mathbf x)\)中抽取。對於任意給定的數據集\(D\),我們可以運行我們的學習演算法,得到⼀個預測函數\(y(\mathbf x;D)\)。不同的數據集會給出不同的函數,從而給出不同的平方損失的值。這樣,特定的學習演算法的表現就可以通過取各個數據集上的表現的平均值來進行評估。
對一個特定的數據集\(D\)而言,\(E(L)\)表達式的第一項為
\{y(\mathbf x;D)-h(\mathbf x)\}^2&=\{y(\mathbf x;D)-E_D(y(\mathbf x;D))+E_D(y(\mathbf x;D))-h(\mathbf x)\}^2\\
&=\{y(\mathbf x;D)-E_D(y(\mathbf x;D))\}^2+\{E_D(y(\mathbf x;D))-h(\mathbf x)\}^2\\
&\quad+2\{y(\mathbf x;D)-E_D(y(\mathbf x;D))\}\cdot\{E_D(y(\mathbf x;D))-h(\mathbf x)\}
\end{aligned}
\]
現在在兩側對\(D\)求期望,得到
E_D(\{y(\mathbf x;D)-h(\mathbf x)\}^2)&=\{E_D(y(\mathbf x;D))-h(\mathbf x)\}^2+E_D(\{y(\mathbf x;D)-E_D(y(\mathbf x;D))\}^2)\\
&=\text{偏置}^2+\text{方差}
\end{aligned}
\]
其中第一項稱為平方偏置(bias),表示所有數據集的平均預測與預期的回歸函數之間的差異;第二項稱為方差(variance),度量了對於單獨的數據集,模型給出的解在平均值附近的波動情況,因此也度量了函數\(y(\mathbf x;D)\)對於特定的數據集的敏感程度。現在,我們的平方損失函數就可以分解為
\]
其中
\text{偏置}^2&=\int\{E_D(y(\mathbf x;D))-h(\mathbf x)\}^2p(\mathbf x)d\mathbf x\\
\text{方差}&=\int E_D(\{y(\mathbf x;D)-E_D(y(\mathbf x;D))\}^2)d\mathbf x\\
\text{雜訊}&=\iint\{h(\mathbf x)-t\}^2p(\mathbf x,t)d\mathbf xdt=\int\text{var}(t|\mathbf x)p(\mathbf x)d\mathbf x
\end{aligned}
\]
現在,偏置和方差是指積分後的量。
我們的目標是最小化期望損失,它可以分解為(平方)偏置、方差和⼀個常數雜訊項的和。對於非常靈活的模型來說, 偏置較小,方差較大。對於相對固定的模型來說,偏置較大,方差較小。有著最優預測能力的模型是在偏置和方差之間取得最優的平衡的模型。下圖以正弦分布為例說明了這一點


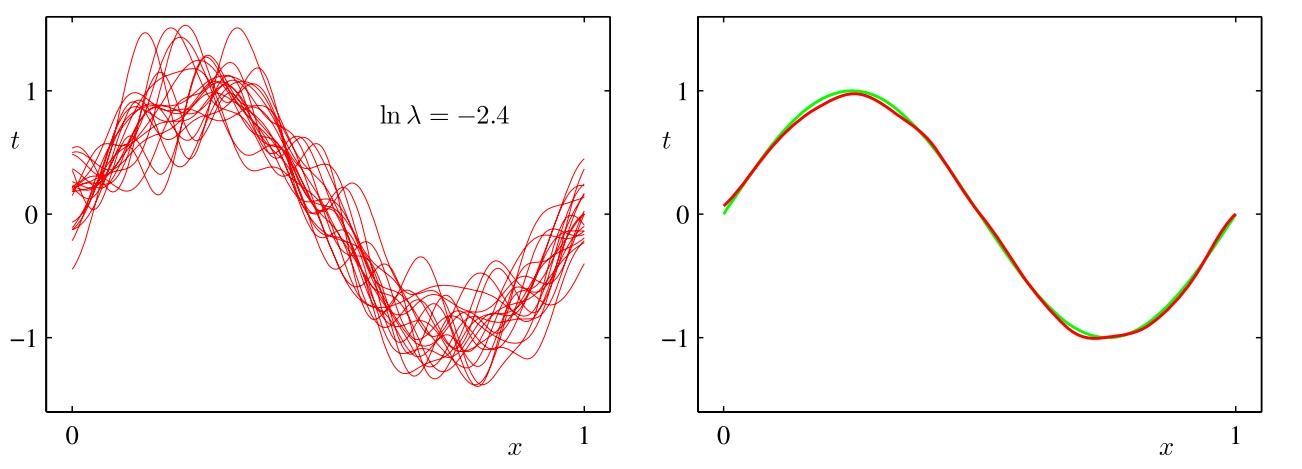
我們預先生成了符合正弦分布的若干組數據點,每個集合都包含\(N\)個數據點,數據集的編號為\(l=1,\cdots,L\),並且對於每個數據集\(D(l)\),通過最小化正則化的誤差函數\(\frac12\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2+\frac\lambda2\mathbf w^T\mathbf w\)擬合了⼀個帶有若干個高斯基函數的模型,然後給出了預測函數\(y^{(l)}(x)\),如上圖所示(左側的紅色曲線表示各數據集的擬合結果,右側的紅色曲線表示左側紅色曲線的平均)。第一行對應著較大的正則化係數\(\lambda\),這樣的模型的方差很小(因為左側圖中的紅色曲線看起來很相似),但是偏置很大(因為右側圖中的兩條曲線看起來相當不同)。相反,在最後一行,正則化係數\(\lambda\)很小,這樣模型的方差較大(因為左側圖中的紅色曲線變化性相當大),但是偏置很小(因為平均擬合的結果與原始正弦曲線十分吻合)。從上面的內容可以直觀看出,求(加權)平均是得到較為準確的模型的重要手法,這不僅在頻率主義方法中起作用(此時將多個數據集得到的擬合函數求(加權)平均),而且在貝葉斯主義方法中仍然起作用(此時將多個後驗概率所支援的參數進行(加權)平均)。
下面我們仍以正弦分布為例定量分析方差-偏置中的合理平衡。平均預測為
\]
並且積分後的平方偏置以及積分後的方差為
\text{偏置}^2&=\frac1N\sum_{n=1}^N\{\bar{y}(x_n)-h(x_n)\}^2\\
\text{方差}&=\frac1N\sum_{n=1}^N\frac1L\sum_{l=1}^L\{y^{(l)}(x_n)-\bar{y}(x_n)\}^2
\end{aligned}
\]
下圖直觀展示了不同的\(\lambda\)對應的偏置和方差以及它們的加和
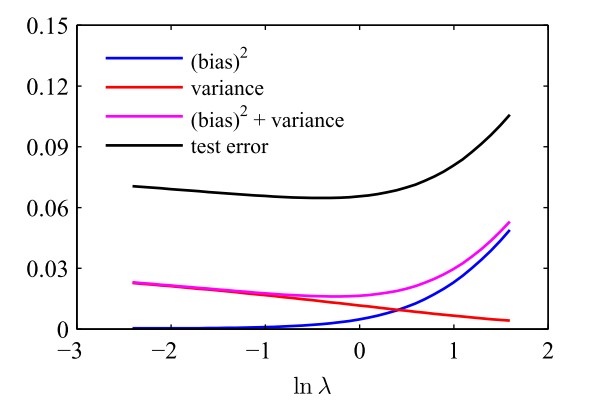
明顯可以看出:當\(\lambda\)較小時,懲罰項的重要程度較低,此時模型傾向於過擬合(即對雜訊過於重視),因此偏置較小但方差較大;當\(\lambda\)較大時,懲罰項的重要程度較高,此時模型容易擬合不足,因此偏置較大但方差較小。只有\(\lambda\)適中時,才能取到\(\text{偏置}^2+\text{方差}\)的最小值。
雖然偏置-方差分解能夠從頻率主義的角度對模型的複雜度提供思路,但是它的實用價值很有限。這是因為偏置-方差分解依賴於對所有的數據集求平均,而在實際應用中我們常常只有⼀個觀測數據集。另外,如果我們有大量的已知規模的獨立的訓練數據集,那麼把它們組合成一個更大的訓練數據集顯然會降低給定複雜度的模型的過擬合程度,這個思路比求平均更加有用。 由於有這麼多局限性,因此我們在下⼀節將討論線性基函數模型的貝葉斯觀點。它不僅提供了對於過擬合現象的深刻認識,還提出了解決模型複雜度問題的實用的方法。
3 貝葉斯線性回歸
線性回歸的貝葉斯方法避免了過擬合問題,並引出了使用數據本身確定模型複雜度的自動化方法。
3.1 參數分布
在PRML 概率分布中的3.7節我們證明了,當有如下形式的邊緣分布(先驗概率)和條件高斯分布(似然函數)
p(\mathbf x)&=\mathcal N(\mathbf x|\pmb\mu,\pmb\Lambda^{-1})\\
p(\mathbf y|\mathbf x)&=\mathcal N(\mathbf y|\mathbf A\mathbf x+\mathbf b,\mathbf L^{-1})
\end{aligned}
\]
的時候,可得
p(\mathbf y)&=\mathcal N(\mathbf y|\mathbf A\pmb\mu+\mathbf b,\mathbf L^{-1}+\mathbf A\mathbf\Lambda^{-1}\mathbf A^T)\\
p(\mathbf x|\mathbf y)&=\mathcal N(\mathbf x|\mathbf\Sigma\{\mathbf A^T\mathbf L(\mathbf y-\mathbf b)+\pmb\Lambda\pmb\mu\},\mathbf\Sigma)
\end{aligned}
\]
其中\(\mathbf\Sigma=(\pmb\Lambda+\mathbf A^T\mathbf L\mathbf A)^{-1}\)。
現在,似然函數\(p(\mathbf t|\mathbf w)\)為
\]
為了保證共軛性,參數\(\mathbf w\)的先驗分布可設為高斯分布
\]
其中\(\mathbf m_0\)為(先驗的)均值,\(\mathbf S_0\)為(先驗的)協方差。那麼根據上面的結論,我們可以得到參數\(\mathbf w\)的後驗分布為
\mathbf S_N^{-1}=\mathbf S_0^{-1}+\beta\mathbf\Phi^T\mathbf\Phi
\]
如果我們令(先驗的)協方差\(\mathbf S_0=\alpha^{-1}\mathbf I\),其中\(\alpha\rightarrow0\),那麼在實際意義上就給定了一個無限寬的先驗分布,相當於沒有先驗分布,此時的均值\(\mathbf m_N=(\mathbf\Phi^T\mathbf\Phi)^{-1}\mathbf\Phi^T\mathbf t=\mathbf w_{ML}\),這就是極大似然方法中的規範方程。在本章的剩餘部分,為簡便起見,我們假設先驗分布\(p(\mathbf w)\)是各向同性的零均值高斯分布,即
\]
那麼此時有
\mathbf m_N&=\beta\mathbf S_N\mathbf\Phi^T\mathbf t\\
\mathbf S_N^{-1}&=\alpha\mathbf I+\beta\mathbf\Phi^T\mathbf\Phi
\end{aligned}
\]
且後驗概率的對數為
\]
這正好對應含正則化項的總誤差函數\(\frac12\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2+\frac\lambda2\mathbf w^T\mathbf w\)中令\(\lambda=\frac\alpha\beta\)。需要注意的是,在貝葉斯線性回歸中,我們沒有引入任何「懲罰項」的概念,這就說明在貝葉斯線性回歸中過擬合問題自動地被避免了。
現在以直線擬合為例說明線性基函數的貝葉斯學習過程,以及後驗概率分布的順序更新過程。考慮單一輸入變數\(x\)和單一目標變數\(t\),以及線性模型\(y(x,\mathbf w)=w_0+w_1x\)。預先生成滿足\(f(x,\mathbf a)=a_0+a_1x\)的一組點,其中\(a_0=−0.3\)且\(a_1=0.5\),並增加⼀個標準差為\(0.2\)的高斯雜訊,得到數據集(目標變數為\(t\))。現在我們想從數據集中恢復出\(a_0\)和\(a_1\)的值,並且想研究模型對於數據集規模的依賴關係。我們假設雜訊方差是已知的,因此我們把精度參數設置為它的真實值\(\beta=(\frac{1}{0.2})^2=25\)。類似地,我們令\(\alpha=2.0\)(稍後會簡短討論從訓練集中確定\(\alpha\)和\(\beta\)的值的策略)。下圖給出了當數據集的規模增加時貝葉斯學習的結果,還直觀展示了貝葉斯學習的順序本質(即當新數據點到達時,後驗分布變成了先驗分布)

真實參數值\(a_0=−0.3\)以及\(a_1=0.5\)在上圖中被標記為白色十字。第一行是開始訓練之前的影像,即先驗分布的影像,我們設參數\(\mathbf w=\left(\begin{array}{c}w_0\\w_1\end{array}\right)\)先驗分布為各向同性的零均值高斯分布\(p(\mathbf w)=\mathcal N(\mathbf w|\mathbf 0,\alpha^{-1}\mathbf I)\),它的影像如第一行中間圖所示,從中隨機抽取六組先驗參數\(\mathbf w\),得到第一行右側圖中所示的六條紅線。第二行中有一個數據點到達(右側圖中的藍色圓圈),左側圖為該數據點的似然函數\(p(t|\mathbf w)\)的影像。如果我們把這個似然函數與第一行的先驗概率相乘,然後歸一化,我們就得到了第二行中間圖給出的後驗概率分布。繼續從這個後驗概率分布中抽取六組參數\(w\),對應的回歸函數\(y(x,\mathbf w)\)如第二行右側圖所示。注意,這些樣本直線全部穿過數據點的附近位置(此處的「附近」由雜訊精度\(\beta\)確定)。上圖第三行展示了第二個數據點到達後的效果。第四行展示了\(20\)個數據點到達後的效果。左側圖展示了第\(20\)個數據點自身的似然函數,中間圖展示了融合了\(20\)次觀測資訊的後驗概率分布。注意與第三行相比,這個後驗概率分布變得更加尖銳。在無窮多個數據點的極限情況下,後驗概率分布會變成一個Delta函數,這個函數的中心就是用白色十字標記出的真實參數值。
當然,除了高斯分布,先驗分布\(p(\mathbf w)\)也可以取其他形式,比如高斯分布的推廣形式
\]
其中\(\alpha=2\)對應高斯分布。
3.2 預測分布
我們的預測值通常由一個分布來描述
p(t|\mathbf t,\alpha,\beta)&=\int p(t|\mathbf w)\cdot p(\mathbf w|\mathbf t,\alpha,\beta)d\mathbf w\\
&=\int p(t|\mathbf x,\mathbf w,\beta)\cdot p(\mathbf w|\mathbf t)d\mathbf w\\
&=\int\mathcal N(t|y(\mathbf x,\mathbf w),\beta^{-1})\cdot
\mathcal N(\mathbf w|\mathbf S_N\{\beta\mathbf\Phi^T\mathbf t+\mathbf S_0^{-1}\mathbf m_0\},\mathbf S_N)d\mathbf w
\end{aligned}
\]
其中\(\mathbf t\)為訓練集(\(\mathbf\Phi\)中暗含訓練集的另一部分,即\(\mathbf X\)),\(\mathbf w\)為參數集,\(\alpha\)和\(\beta\)是模型參數,\(\mathbf x\)是輸入的自變數。上面的式子實際上就是求出聯合分布\(p(t,\mathbf w|\mathbf x,\mathbf t,\alpha,\beta)\)中關於\(t\)的邊緣分布,根據PRML 概率分布中3.7小節的內容可以得到
\sigma_N^2(\mathbf x)=\frac1\beta+\pmb\phi(\mathbf x)^T\mathbf S_N\pmb\phi(\mathbf x)
\]
其中預測分布的方差\(\sigma_N^2(\mathbf x)\)中的第一項表示數據的雜訊,第二項反映了與參數\(\mathbf w\)相關聯的不確定性。由於雜訊和\(\mathbf w\)的分布是相互獨立的高斯分布,因此它們的值是可以直接相加的。當新的數據點到達的時候,方差會縮小,因此可以證明\(\sigma_{N+1}^2(\mathbf x)\leq\sigma_N^2(\mathbf x)\),進而當\(N\rightarrow\infty\)時,第二項會趨於零,從而預測分布的方差只與參數\(\beta\)控制的具有可加性的雜訊有關。
在前一小節我們以直線擬合為例介紹了線性基函數的貝葉斯學習過程,以及後驗概率分布的順序更新過程。現在,我們考慮一個更具體的例子——正弦分布,並以此為例說明貝葉斯線性回歸模型的預測分布,其中基函數選為高斯基函數。在下圖中,綠線表示正弦曲線,生成的數據以此為基礎並附加一定的高斯雜訊

藍色圓圈表示數據點,紅線表示對應的高斯預測分布的均值,紅色陰影區域是均值兩側的一個標準差範圍的區域。注意,預測的不確定性依賴於\(x\),並且在數據點的鄰域內最小。還要注意,不確定性的程度隨著觀測到的數據點的增多而逐漸減小。上圖只給出了每個點處的預測方差與\(x\)的函數關係。為了更加深刻地認識對於不同的\(x\)值的預測之間的協方差,我們可以從\(\mathbf w\)的後驗概率分布中抽取若干樣本,然後畫出對應的函數\(y(x,\mathbf w)\),如下圖

如果我們使用局部的基函數(例如高斯基函數),那麼在距離基函數中心比較遠的區域,\(\sigma_N^2(\mathbf x)\)表達式中的第二項將會趨於零,只剩下第一項(雜訊)\(\beta^{-1}\)。因此,當對基函數所在的區域之外的區域進行外插的時候,模型對於它做出的預測會變得相當確定(因為與訓練數據集無關,僅與\(\beta\)相關的高斯分布有關),這種結果通常是不準確的,使用被稱為高斯過程(Gaussian process)的另一種貝葉斯回歸方法可以避免這個問題。
最後,如果\(w\)和\(\beta\)都被當成未知的,那麼根據PRML 概率分布中3.10小節的討論,共軛先驗分布\(p(\mathbf w,\beta)\)是一個高斯-Gamma分布,此時的預測分布是一個t分布。
3.3 等價核
如果我們將\(\mathbf m_N=\beta\mathbf S_N\mathbf\Phi^T\mathbf t\)視為參數\(\mathbf w\)的估計值並將其代入\(y(\mathbf x,\mathbf w)=\mathbf w^T\pmb\phi(\mathbf x)\),那麼得到
\]
使用PRML 概率分布中3.2小節介紹的Dirac符號,我們可以發現,\(\beta\mathbf S_N\mathbf\Phi^T\mathbf t\)的形式為\(|\cdots\rangle\),因此\((\beta\mathbf S_N\mathbf\Phi^T\mathbf t)^T\)的形式為\(\langle\cdots|\),又因為\(\pmb\phi(\mathbf x)\)的形式為\(|\cdots\rangle\),那麼\((\beta\mathbf S_N\mathbf\Phi^T\mathbf t)^T\pmb\phi(\mathbf x)\)的形式即為\(\langle\cdots\rangle\),即一個數值(而非向量)(因為我們只估計一個目標變數\(t\),這一點亦是顯而易見的),那麼上式可以寫成
\]
其中\(\mathbf S_N^{-1}=\alpha\mathbf I+\beta\mathbf\Phi^T\mathbf\Phi\),函數\(k(\mathbf x,\mathbf x’)=\beta\pmb\phi(\mathbf x)^T\mathbf S_N\pmb\phi(\mathbf x’)\)稱為平滑矩陣(smoother matrix)或者等價核(equivalent kernel)。像這樣的回歸函數,通過對目標值進行線性組合做預測,被稱為線性平滑(linear smoother)。注意,等價核依賴於訓練集(因為\(\mathbf S_N\)的表達式中含有\(\mathbf\Phi\),而\(\mathbf\Phi\)的表達式中含有訓練集的\(\mathbf X\))。
關於等價核,我們可以更加細緻地討論。因為參數\(\mathbf x\)滿足\(p(\mathbf w|\mathbf t)=\mathcal N(\mathbf w|\mathbf m_N,\mathbf S_N)\),則\(y(\mathbf x)\)與\(y(\mathbf x’)\)的協方差為
\text{cov}(y(\mathbf x),y(\mathbf x’))&=\text{cov}(\mathbf w^T\pmb\phi(\mathbf x),\mathbf w^T\pmb\phi(\mathbf x’))\\
&=\text{cov}(\pmb\phi(\mathbf x)^T\mathbf w,\mathbf w^T\pmb\phi(\mathbf x’))\\
&=
E(\pmb\phi(\mathbf x)^T\mathbf w\cdot\mathbf w^T\pmb\phi(\mathbf x’))-E(\pmb\phi(\mathbf x)^T\mathbf w)E(\mathbf w^T\pmb\phi(\mathbf x’))\\
&=\pmb\phi(\mathbf x)^T\cdot E(\mathbf w\mathbf w^T)\cdot\pmb\phi(\mathbf x’)-\pmb\phi(\mathbf x)^T\cdot E(\mathbf w)\cdot E(\mathbf w^T)\cdot\pmb\phi(\mathbf x’)\\
&=\pmb\phi(\mathbf x)^T\cdot(E(\mathbf w\mathbf w^T)-E(\mathbf w)E(\mathbf w^T))\cdot\pmb\phi(\mathbf x’)\\
&=\pmb\phi(\mathbf x)^T\cdot\text{cov}{(\mathbf w,\mathbf w^T)}\cdot\pmb\phi(\mathbf x’)\\
&=\pmb\phi(\mathbf x)^T\mathbf S_N\pmb\phi(\mathbf x’)\\
&=\beta^{-1}k(\mathbf x,\mathbf x’)
\end{aligned}
\]
由此我們知道,在已知數據點\(\mathbf x’\)附近進行預測,得到的\(y(\mathbf x)\)和已知的\(y(\mathbf x’)\)相關性較高,而對於較遠的\(\mathbf x\)而言,相關性就較低,上面的幾幅圖讓我們可以直觀地感受到這一點。
上面的式子\(y(\mathbf x,\mathbf m_N)=\sum_{n=1}^Nk(\mathbf x,\mathbf x_n)t_n\)暗示了解決回歸問題的另一種方法:不顯式地引入一組基函數(它隱式地定義了一個等價的核),而是顯式地定義一個局部的核函數(它隱式地定義了基函數),然後在給定訓練數據集的條件下,用這個核函數對新的輸入變數\(x\)做預測。這就引出了用於回歸問題(以及分類問題)的很實用的框架,被稱為高斯過程(Gaussian process)。這將在後續內容中討論。
我們已經看到,一個等價核定義了模型的權值。通過這個權值,訓練數據集中的目標值被重新(線性)組合,作為新輸入的\(\mathbf x\)的預測值。可以證明這些權值的和等於\(1\),即\(\sum_{n=1}^Nk(\mathbf x,\mathbf x_n)=1\)對所有的\(\mathbf x\)均成立。
對於等價核\(k(\mathbf x,\mathbf x’)=\beta\pmb\phi(\mathbf x)^T\mathbf S_N\pmb\phi(\mathbf x’)\)而言,它是核函數的一個具體例子。核函數可以為正也可以為負,但必須滿足加和為\(1\)的限制,除此之外,任意核函數均可以表示為非線性函數的向量\(\pmb\psi(\mathbf x)\)的內積的形式,即
\]
對於我們的例子而言,其中\(\pmb\psi(\mathbf x)=\beta^{1/2}\mathbf S_N^{1/2}\pmb\phi(\mathbf x)\)。
4 貝葉斯模型比較
4.1 後驗概率與預測分布
在貝葉斯方法中,我們比較不同模型之間的唯一思路就是概率,現假設我們想要比較\(L\)個模型\(\{\mathcal M_i\}\),其中\(i=1,\cdots,L\),「一個模型」指的是訓練數據集\(D\)上的概率分布。在Polynomial Curve Fitting問題中,我們用數據集\(\mathbf X\)和與之相關的\(\mathbf t\)表示出了一個模型,這時「概率分布」指的是關於新的目標變數\(\mathbf t\)的一個概率分布,而輸入變數\(\mathbf x\)是已知的。在一般化的問題中,「概率分布」指的是關於輸入變數\(\mathbf x\)和目標變數\(\mathbf t\)的一個聯合分布\(p(\mathbf x,\mathbf t)\),我們通過積分(連續變數情況下)或者求和(離散變數情況下)得到邊緣分布\(p(\mathbf x)\)和\(p(\mathbf t)\)。對於\(L\)個模型中某個模型\(\mathcal M_i\)而言,其後驗概率為
\]
如果後驗概率較大,則說明數據集\(D\)比較支援這個模型\(\mathcal M_i\),如果後驗概率較小則說明其不支援該模型。如果所有的模型都有相同的先驗概率\(p(\mathcal M_i)\),那麼項\(p(D|\mathcal M_i)\)就表達了數據展現出的不同模型的優先順序,該項稱為模型證據(model evidence)或者邊緣似然(marginal likelihood)(被稱為邊緣似然因為該項可以視為聯合分布\(p(\mathcal M_i,D)\)進行積分或求和得到)。兩個模型的模型證據的比值\(\frac{p(D|\mathcal M_i)}{p(D|\mathcal M_j)}\)稱為貝葉斯因子(Bayes factor)。
如果我們知道了所有的模型的後驗概率\(p(\mathcal M_i|D)\),那麼就掌握了在(訓練)數據集\(D\)下,\(L\)個模型的可能性,故此時預測分布為
\]
這實際上就是對各個模型的預測分布\(p(t|\mathbf x,\mathcal M_i,D)\)進行加權平均,可視作混合分布(mixture distribution)的一個例子。如果有兩個模型的後驗概率分布\(p(\mathcal M_i|D)=p(\mathcal M_j|D)\),且一個模型預測為\(t=a\)附近的一個很窄的分布、一個模型預測為\(t=b\)附近的一個很窄的分布,那麼總體將會是一個雙峰分布(而不是\(t=\frac{a+b}{2}\)附近的單峰分布)。在具體應用中,一個粗略的思路就是從\(L\)個模型中選出後驗概率最大的模型進行預測。
4.2 模型證據
現在來展開說說模型證據這個概念。對於由參數\(\mathbf w\)控制的模型而言,其模型證據(邊緣似然)為
\]
從取樣的角度來說,這個邊緣似然\(p(D|\mathcal M_i)\)可以視作從模型\(\mathcal M_i\)中生成數據集\(D\)的概率,而模型\(\mathcal M_i\)的參數\(\mathbf w\)是從先驗分布\(p(\mathbf w)\)(在預先訓練一定次數的時候,先驗分布就是之前的後驗分布\(p(\mathbf w|D)\))中隨機取樣的。
先來看一個簡化的情況:模型只有一個參數\(w\),那麼\(p(w|D)\varpropto p(D|w)p(w)\)(其中省去了\(\mathcal M_i\))。如果後驗分布在極大似然估計\(w_{MAP}\)附近有一個尖峰,寬度為\(\Delta w_{\text{後驗}}\),並進一步假設先驗分布是平的,且寬度為\(\Delta w_{\text{先驗}}\)(即\(p(w)=\frac{1}{\Delta w_{\text{先驗}}}\)),那麼
\]
取對數可得
\]
其中第一項表示由最可能的參數\(w_{MAP}\)給出的數據,第二項用於根據模型的複雜度來懲罰模型。由於\(\Delta w_{\text{後驗}}<\Delta w_{\text{先驗}}\)(隨著學習過程的進行,不確定度會減小,即會越來越趨於某個尖峰),因此,如果參數精確地調整為後驗分布的數據,那麼\(\ln(\frac{\Delta w_{\text{後驗}}}{\Delta w_{\text{先驗}}})<0\)將會非常小,這非常不利於後驗概率\(p(D|\mathcal M_i)\)最大化。
現在來看一般的情況,如果一個模型具有\(M\)個參數,我們可以對每個參數進行類似的近似,假設所有參數的\(\frac{\Delta w_{\text{後驗}}}{\Delta w_{\text{先驗}}}\)均相同,那麼
\]
因此,在這種非常簡單的近似下,複雜度懲罰項(上式第二項)的大小(負數)隨著可調節參數數量\(M\)的增加而越來越小。另外,隨著\(M\)的增加,模型能夠更加精確地描述數據集,也就是第一項會變大。這就帶來了一個矛盾:更多的參數能夠更好地描述數據集,但是複雜度上升也會招致懲罰,我們需要在這兩方面進行折中。
一般而言,對兩個模型\(\mathcal M_i\)和\(\mathcal M_j\)而言,其中的某一個模型更加貼近真實情況,現在假設\(\mathcal M_i\)即為真實模型,那麼模型\(\mathcal M_j\)和模型\(\mathcal M_i\)的貼近程度可以由PRML 基礎知識中6.4小節中介紹的KL散度來描述,即
\]
如果模型\(\mathcal M_j\)和模型\(\mathcal M_i\)完全一致,那麼上面的KL散度為零,否則恆為正。
我們已經看到,貝葉斯框架避免了過擬合的問題,並且使得模型能夠隨著訓練次數的增加而得到優化。但是貝葉斯方法需要對模型的形式作出假設,並且如果這些假設不合理,那麼結果就會出錯。特別地,我們從上圖可以看出,模型證據對先驗分布的很多方面都很敏感,例如在低概率處的行為等等。如果先驗分布是反常的,那麼模型證據無法定義,因為反常的先驗分布有著任意的縮放因子(換句話說,歸一化係數無法定義,因為分布根本無法被歸一化)。如果我們考慮一個正常的先驗分布,然後取一個適當的極限來獲得一個反常的先驗(例如高斯先驗中,我們令方差為無窮大),那麼模型證據就會趨於零。但是這種情況下也可能通過首先考慮兩個模型的證據比值,然後取極限的方式來得到⼀個有意義的答案。 因此,在實際應用中,一種明智的做法是,保留一個獨立的測試數據集,這個數據集用來評估最終系統的整體表現。
5 證據近似
5.1 基本框架介紹
在經典的貝葉斯方法中,我們預先確定了模型的超參數(現在我們假設有兩個參數\(\alpha\)和\(\beta\)),然後計算後驗概率\(p(\mathbf w|D,\alpha,\beta)\),再確定出預測分布\(p(t|\mathbf w,\mathbf x)\)。如果我們引入的是超參數的先驗分布(而不是具體的值),那麼預測分布需要通過積分方法來求解,即
\]
為了記號簡潔,上述式子省略了預測分布對\(\mathbf x\)的依賴。其中\(p(\mathbf w|\mathbf t,\alpha,\beta)\)為此時參數的後驗分布,\(p(t|\mathbf w,\beta)\)為確定參數\(\mathbf w\)時的預測分布\(\mathcal N(t|y(\mathbf x,\mathbf w),\beta^{-1})\),\(p(\alpha,\beta|\mathbf t)\)為在訓練數據集\(\mathbf t\)條件下模型超參數\(\alpha\)和\(\beta\)的後驗(聯合)分布(且該分布\(p(\alpha,\beta|\mathbf t)\varpropto p(\mathbf t|\alpha,\beta)p(\alpha,\beta)\)),所以,如果我們先對參數\(\mathbf w\)進行積分得到邊緣似然函數(marginal likelihood function),那麼預測分布就是超參數的積分,從統計意義上來說,關於超參數的積分即為超參數條件下預測目標變數\(t\)的條件分布),故只需要考慮將這個邊緣似然函數最大化,便能得到超參數的值,這個框架在統計學文獻中稱為經驗貝葉斯(empirical Bayes)或者第二類極大似然(type 2 maximum likelihood)或者推廣的最大似然(generalized maximum likelihood),在機器學習文獻中,這種方法也被稱為證據近似(evidence approximation)。考慮到\(p(\alpha,\beta|\mathbf t)\varpropto p(\mathbf t|\alpha,\beta)p(\alpha,\beta)\),如果先驗分布\(p(\alpha,\beta)\)比較平,那麼邊緣似然函數最大化就等價於將證據函數\(p(\mathbf t|\alpha,\beta)\)最大化,這樣得到的參數\(\alpha\)和\(\beta\)的極大似然估計不妨記為\(\hat{\alpha}\)和\(\hat{\beta}\)。一個簡單的近似情況是:如果後驗分布\(p(\alpha,\beta|\mathbf t)\)在\(\hat{\alpha}\)和\(\hat{\beta}\)附近有峰值,那麼上述積分可以近似為
\]
在上面介紹的方法中,模型超參數\(\alpha\)和\(\beta\)是通過訓練數據集得到的,這種方法具有很好的實用性。對於證據函數\(p(\mathbf t|\alpha,\beta)\)最大化而言,有兩種常見的方法:一是計算證據函數並令證據函數的導數等於零,這將在接下來進行討論;二是期望最大化(EM)方法,這將在後續章節進行討論。
5.2 計算證據函數
求證據函數的第一步是對權值參數\(\mathbf w\)進行積分,即
p(\mathbf t|\alpha,\beta)&=\int p(\mathbf t|\mathbf w,\alpha,\beta)p(\mathbf w|\alpha)d\mathbf w\\
&=\int\mathcal N(\mathbf t|\mathbf w^T\pmb\phi(\mathbf x_n),\beta^{-1})\cdot\mathcal N(\mathbf w|\mathbf 0,\alpha^{-1}\mathbf I)d\mathbf w\\
&=\int\prod_{n=1}^N\mathcal N(t_n|\mathbf w^T\pmb\phi(\mathbf x_n),\beta^{-1})\cdot\prod_{m=1}^M\mathcal N(w_m|\mathbf 0,\alpha^{-1}\mathbf I)d\mathbf w\\
&=(\frac{\beta}{2\pi})^{N/2}(\frac{\alpha}{2\pi})^{M/2}\int\mathcal N(t_n|\mathbf w^T\pmb\phi(\mathbf x_n),\beta^{-1})\cdot\mathcal N(w_m|\mathbf 0,\alpha^{-1}\mathbf I)d\mathbf w\\
&=(\frac{\beta}{2\pi})^{N/2}(\frac{\alpha}{2\pi})^{M/2}\iint\cdots\int\mathcal N(t_n|\mathbf w^T\pmb\phi(\mathbf x_n),\beta^{-1})\cdot\mathcal N(w_m|\mathbf 0,\alpha^{-1}\mathbf I)dw_1dw_2\cdots dw_M\\
&=\cdots
\end{aligned}
\]
除了上面逐步推導的思路,我們還可以用PRML 概率分布中3.7小節介紹的結論,得到
E(\mathbf w)=\beta E_D(\mathbf w)+\alpha E_W(\mathbf w)=\frac\beta2||\mathbf t-\mathbf\Phi\mathbf w||^2+\frac\alpha2\mathbf w^T\mathbf w
\]
其中\(E(\mathbf w)\)在形式上和正則化的誤差函數\(\frac12\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2+\frac\lambda2\mathbf w^T\mathbf w\)相似。我們現在對參數\(\mathbf w\)配方,過程如下
E(\mathbf w)&=\frac\beta2||\mathbf t-\mathbf\Phi\mathbf w||^2+\frac\alpha2\mathbf w^T\mathbf w\\
&=\frac\beta2(\mathbf t-\mathbf\Phi\mathbf w)^T(\mathbf t-\mathbf\Phi\mathbf w)+\frac\alpha2\mathbf w^T\mathbf w\\
&=\frac\beta2(\mathbf t^T\mathbf t-\mathbf t^T\mathbf\Phi\mathbf w-(\mathbf\Phi\mathbf w)^T\mathbf t+(\mathbf\Phi\mathbf w)^T(\mathbf\Phi\mathbf w))+\frac\alpha2\mathbf w^T\mathbf w\\
&=\frac\beta2(\mathbf t^T\mathbf t-\mathbf t^T\mathbf\Phi\mathbf w-(\mathbf\Phi\mathbf w)^T\mathbf t)+\frac12(\mathbf w^T(\beta\mathbf\Phi^T\mathbf\Phi)\mathbf w+\mathbf w^T(\alpha\mathbf I)\mathbf w)\\
&=\frac\beta2(\mathbf t^T\mathbf t-\mathbf t^T\mathbf\Phi\mathbf w-(\mathbf\Phi\mathbf w)^T\mathbf t)+\frac12\mathbf w^T\mathbf A\mathbf w,\quad\mathbf A=\beta\mathbf\Phi^T\mathbf\Phi+\alpha\mathbf I=\mathbf S_N^{-1}\\
&=\frac12(\beta\mathbf t^T\mathbf t-\beta\mathbf t^T\mathbf\Phi\mathbf w-\beta(\mathbf\Phi\mathbf w)^T\mathbf t+\mathbf w^T\mathbf A\mathbf w)\\
&=\frac12(\beta\mathbf t^T\mathbf t-2\beta\mathbf t^T\mathbf\Phi\mathbf w+\mathbf w^T\mathbf A\mathbf w)\\
&=\frac12((\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)-\mathbf m_N^T\mathbf A\mathbf m_N+\beta\mathbf t^T\mathbf t),\quad\mathbf m_N=\beta\mathbf S_N\mathbf\Phi^T\mathbf t\\
&\qquad+\frac12(\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)-\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N))\\
&=\frac12((\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)-\mathbf m_N^T\mathbf A\mathbf m_N+\beta\mathbf t^T\mathbf t)\\
&\qquad+\frac12(\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)-\beta\mathbf t^T\mathbf t+2\beta\mathbf t^T\mathbf\Phi\mathbf m_N-\beta\mathbf m_N^T(\mathbf\Phi^T\mathbf\Phi)\mathbf m_N)\\
&=\frac12(-\mathbf m_N^T\mathbf A\mathbf m_N+\beta\mathbf t^T\mathbf t-\beta\mathbf t^T\mathbf t+2\beta\mathbf t^T\mathbf\Phi\mathbf m_N-\beta\mathbf m_N^T(\mathbf\Phi^T\mathbf\Phi)\mathbf m_N)\\
&\qquad+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac12\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)\\
&=\frac12(-\mathbf m_N^T\mathbf A\mathbf m_N+2\beta\mathbf t^T\mathbf\Phi\mathbf m_N-\beta\mathbf m_N^T(\mathbf\Phi^T\mathbf\Phi)\mathbf m_N)\\
&\qquad+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac12\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)\\
&=\frac12(-\mathbf m_N^T\mathbf A\mathbf m_N+2\beta(\beta^{-1}\mathbf m_N^T\mathbf A^T)\mathbf m_N-\beta\mathbf m_N^T(\mathbf\Phi^T\mathbf\Phi)\mathbf m_N)\\
&\qquad+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac12\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)\\
&=\frac12(-\mathbf m_N^T\mathbf A\mathbf m_N+2\beta(\beta^{-1}\mathbf m_N^T\mathbf A)\mathbf m_N-\beta\mathbf m_N^T(\mathbf\Phi^T\mathbf\Phi)\mathbf m_N)\\
&\qquad+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac12\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)\\
&=\frac12(-\mathbf m_N^T\mathbf A\mathbf m_N+2\mathbf m_N^T\mathbf A\mathbf m_N-\beta\mathbf m_N^T(\mathbf\Phi^T\mathbf\Phi)\mathbf m_N)\\
&\qquad+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac12\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)\\
&=\frac12(\mathbf m_N^T\mathbf A\mathbf m_N-\mathbf m_N^T(\beta\mathbf\Phi^T\mathbf\Phi)\mathbf m_N)\\
&\qquad+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac12\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)\\
&=\frac12\mathbf m_N^T(\alpha\mathbf I)\mathbf m_N+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac12\beta(\mathbf t-\mathbf\Phi\mathbf m_N)^T(\mathbf t-\mathbf\Phi\mathbf m_N)\\
&=\frac\alpha2\mathbf m_N^T\mathbf m_N+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)+\frac\beta2||\mathbf t-\mathbf\Phi\mathbf m_N||^2\\
&=E(\mathbf m_N)+\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)
\end{aligned}
\]
其中\(E(\mathbf m_N)=\frac\beta2||\mathbf t-\mathbf\Phi\mathbf m_N||^2+\frac\alpha2\mathbf m_N^T\mathbf m_N\),此時矩陣\(\mathbf A\)就是誤差函數\(E(\mathbf w)\)的二階導數\(\nabla\nabla E(\mathbf w)\),稱為Hessian矩陣。上述推導過程還得到一個副產品\(\mathbf A=\mathbf S_N^{-1}\),這給出了方差的數學依據。
現在,關於\(\mathbf w\)的積分\(\int\text{exp}(-E(\mathbf w))d\mathbf w\)可以計算為
\int\text{exp}(-E(\mathbf w))d\mathbf w&=\text{exp}(E(\mathbf m_N))\int\text{exp}\{\frac12(\mathbf w-\mathbf m_N)^T\mathbf A(\mathbf w-\mathbf m_N)\}d\mathbf w\\
&=\text{exp}(E(\mathbf m_N))\cdot(2\pi)^{M/2}|\mathbf A|^{-1/2}
\end{aligned}
\]
則邊緣似然函數\(p(\mathbf t|\alpha,\beta)\)的對數可以寫為
\]
這就是證據函數的表達式。
現在,如果我們將證據函數關於\(\alpha\)(\(\beta\))求偏導,那麼便可以分析得到\(\alpha\)(\(\beta\))取何值時,證據函數有極值,也就是說,此時的參數\(\alpha\)(和參數\(\beta\))是在訓練過程中確定的,而\(\frac12\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2+\frac\lambda2\mathbf w^T\mathbf w\)的懲罰項因子\(\lambda\)卻是預先確定的,當值選取不合適的時候,模型擬合效果就會很差,在訓練過程中不斷修正參數值的思路比預先確定參數的值要更好、所得到的模型擬合得也更好。
5.3 最大化證據函數
先考慮邊緣似然函數\(p(\mathbf t|\alpha,\beta)\)對參數\(\alpha\)的最大化,在\(\ln p(\mathbf t|\alpha,\beta)\)中,\(\frac{M}{2}\ln\alpha-E(\mathbf m_N)\)可以直接地對\(\alpha\)求偏導,\(\frac{N}{2}\ln\beta-\frac{N}{2}\ln(2\pi)\)與\(\alpha\)無關,所以現在只需要考慮如何對\(\ln|\mathbf A|\)求\(\alpha\)的偏導即可。考慮到\(\mathbf A=\beta\mathbf\Phi^T\mathbf\Phi+\alpha\mathbf I\),矩陣\(\beta\mathbf\Phi^T\mathbf\Phi\)的特徵值滿足\((\beta\mathbf\Phi^T\mathbf\Phi)\mathbf u_i=\lambda_i\mathbf u_i\),因此\(\mathbf A\)的特徵值為\(\lambda_i+\alpha\),因此\(|\mathbf A|=\prod_{i=1}(\lambda_i+\alpha)\),故駐點滿足
\frac{\partial}{\partial\alpha}\ln p(\mathbf t|\alpha,\beta)&=\frac{M}{2\alpha}-\frac{\partial}{\partial\alpha}E(\mathbf m_N)-\frac12\frac{\partial}{\partial\alpha}\ln|\mathbf A|\\
&=\frac{M}{2\alpha}-\frac12\mathbf m_N^T\mathbf m_N-\frac12\sum_i\frac{1}{\lambda_i+\alpha}=0
\end{aligned}
\]
解得
\]
這是\(\alpha\)的一個隱式解,在實際應用中,我們採用迭代的方法求解:首先選定一個初始的\(\alpha\)的值,使用這個值計算出\(\mathbf m_N=\beta\mathbf S_N\mathbf\Phi^T\mathbf t\)的值,然後計算出此時的\(\gamma\),從而得到新的\(\alpha\)的值。注意,由於矩陣\(\mathbf\Phi^T\mathbf\Phi\)是固定的,因此可以在最開始計算以此特徵值,然後接下來只需要乘以\(\beta\)就可以得到\(\lambda_i\)的值。
此時的參數\(\alpha\)僅通過訓練參數集確定的,最極大似然方法不同,最優化模型複雜度不需要單獨的數據集。
接下來考慮參數\(\beta\),\(\ln p(\mathbf t|\alpha,\beta)\)對\(\beta\)求偏導得到
\frac{\partial}{\partial\beta}\ln p(\mathbf t|\alpha,\beta)&=\frac{N}{2\beta}-\frac{\partial}{\partial\beta}E(\mathbf m_N)-\frac12\frac{\partial}{\partial\beta}\ln|\mathbf A|\\
&=\frac{N}{2\beta}-\frac12\sum_{n=1}^N\{t_n-\mathbf m_N^T\pmb\phi(\mathbf x_n)\}^2-\frac{\gamma}{2\beta}=0
\end{aligned}
\]
需要注意,雖然\(\mathbf m_N\)的表達式中仍含有參數\(\beta\),但在迭代方法中,這個\(\beta\)是預先確定的,因此不需要考慮偏導。解得
\]
這也是\(\beta\)的一個隱式解,使用和\(\alpha\)類似的迭代方法可以求解。
5.4 參數的有效數量
先分析下面的一幅圖從而得到一些有趣的結論
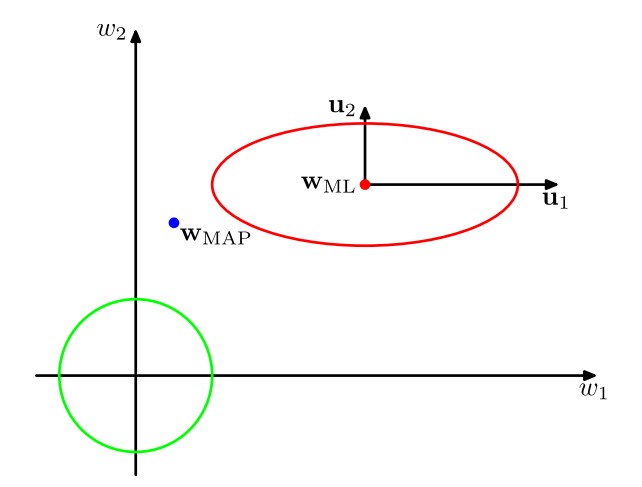
圖中綠線表示似然函數\(p(\mathbf w|\mathbf t)\)的先驗分布\(p(\mathbf w)\)的輪廓線(因為我們認為先驗分布是零均值的各向同性高斯分布,即前面提到過的\(p(\mathbf w)=\mathcal N(\mathbf w|\mathbf 0,\alpha^{-1}\mathbf I)\)),而紅線為似然函數\(p(\mathbf w|\mathbf t)\)的輪廓線,且此時中心\(\mathbf w_{ML}\)是對數似然函數\(\ln p(\mathbf w|\mathbf t)=-\frac\beta2\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2-\frac\alpha2\mathbf w^T\mathbf w+\text{常數}\)在不考慮懲罰項(即\(\alpha=0\))的條件下的極大似然解(一個通俗的理解為:當不考慮懲罰項時,\(\mathbf w\)距離原點的廣義距離\(\mathbf w^T\mathbf w\)不再被考慮,即儘可能符合數據點\(t_n\),即儘可能使\(\sum_{n=1}^N\{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)\}^2\)小)。\(\mathbf w_{MAP}\)是對數似然函數考慮懲罰項(即\(\alpha\neq0\))的條件下的極大似然解,因此會比\(\mathbf w_{ML}\)偏移一些。\(\mathbf w_{MAP}\)是我們訓練的結果。上圖中在引入坐標系時進行了隱式地轉換,使得坐標軸與Hessian矩陣的特徵向量\(\mathbf u_i\)對齊。在PRML 概率分布中3.1小節我們曾經介紹過二次型與橢球面的對應關係,並指出了二次型的特徵向量\(\mathbf u_i\)就是橢球各個軸的方向,當時的特徵值\(\lambda_i\)指的是協方差\(\mathbf\Sigma\)的特徵值,此時的\(\lambda_i\)越大則橢球在對應的方向\(\mathbf u_i\)上越突出(因為在此方向上的不確定性大);而這裡的特徵值\(\lambda_i\)指的是矩陣\(\beta\mathbf\Phi^T\mathbf\Phi\)的特徵值,這個矩陣是從\(\mathbf S_N^{-1}=\alpha\mathbf I+\beta\mathbf\Phi^T\mathbf\Phi\)中得到的、即是從協方差矩陣的逆矩陣得到的,因此此時的\(\lambda_i\)越大則橢球在對應方向\(\mathbf u_i\)上越不突出。另外,由於矩陣\(\beta\mathbf\Phi^T\mathbf\Phi\)是正定的,因此比值\(\frac{\lambda_i}{\lambda_i+\alpha}\)介於\(0\)與\(1\)之間,所以\(\gamma=\sum_i\frac{\lambda_i}{\lambda_i+\alpha}\)介於\(0\)與\(M\)之間,如果某方向上的\(\lambda_i>>\alpha\)(即比值\(\frac{\lambda_i}{\lambda_i+\alpha}\)接近\(1\)),那麼對應的參數\(w_i\)會與它的極大似然解相近,這樣的參數稱為良好確定的(well determined),因為它們的值被數據緊緊地限制著。相反,對於\(\lambda_i<<\alpha\)的方向,對應的參數\(w_i\)會與它的先驗更加相近(在上圖中,即與\(0\)更加相近)。特別地,如果所有的特徵值\(\lambda_i\)都特別小,那麼我們的訓練結果\(\mathbf w_{MAP}\)將會極為接近先驗的零均值,在實際意義上,這就相當於我們白訓練了、訓練基本沒什麼效果。因此,\(\gamma=\sum_i\frac{\lambda_i}{\lambda_i+\alpha}\)度量了良好確定的參數的有效總數。
對於滿足高斯分布的單一變數\(x\)而言,方差的極大似然估計為
\]
但是這個估計是有偏的,因為均值的極大似然解\(\mu_{ML}\)擬合了數據中的一些雜訊。方差的無偏估計為
\]
而對於線性模型的一般結果,目標分布的均值現在由函數\(\mathbf w^T\pmb\phi(\mathbf x)\)給出,這包含了\(M\)個參數,但是由數據良好確定的參數的有效總數僅為\(\gamma\)(而非\(M\))個,剩餘的\(M-\gamma\)個參數應該被先驗地設為較小的值(因為此時對應的參數\(w_i\)會與它的先驗更加相近,即相當於白訓練了,故先驗會較大程度地影響最後的結果,所以需要儘可能減小先驗對最終結果的影響)。對於極限情況\(N>>M\)(即訓練數據集中數據點的數量\(N\)遠大於參數的數量\(M\)),那麼矩陣\(\beta\mathbf\Phi^T\mathbf\Phi\)的模\(|\beta\mathbf\Phi^T\mathbf\Phi|\)將會變得很大(因為模等於特徵值之積),所以現在\(0\leq\gamma\leq M\)中的\(\gamma\)將會大大傾向於\(M\),在極限情況\(\gamma=M\)的情況下,參數估計為
\beta=\frac{N-\gamma}{\sum_{n=1}^N\{t_n-\mathbf m_N^T\pmb\phi(\mathbf x_n)\}^2}\sim\frac{N}{2E_D(\mathbf m_N)}
\]
其中\(E_W\)和\(E_D\)的定義在前面已經提到過,\(\beta\)的分子本來應該近似為\(N-M\),但由於\(N>>M\),因此也可以近似為\(N\)。這些結果可以用作完整的重新估計公式的簡化計算的近似,因為它們不需要計算Hessian矩陣的一系列特徵值。
6 固定基函數的局限性
在本章中,我們已經關注了由固定的非線性基函數的線性組合組成的模型。我們已經看到,對於參數的線性性質的假設產生了一系列有用的性質,包括最小平方問題的解析解,以及容易計算的貝葉斯方法。此外,對於一個合適的基函數的選擇,我們可以建立輸入向量到目標值之間的任意非線性映射。在下一章中,我們會研究類似的用於分類的模型。
因此,似乎這樣的模型建立的解決模式是識別問題的通用框架。不幸的是,線性模型有一些重要的局限性,這使得我們在後續的章節中要轉而關注更加複雜的模型,例如支援向量機和神經網路。
困難的產生主要是因為我們假設了基函數在觀測到任何數據之前就被固定了下來,而這正是維數災難問題的一個表現形式。結果,基函數的數量隨著輸入空間的維度\(D\)迅速增長(通常是指數方式增長)。
幸運的是,真實數據集有兩個性質,可以幫助我們緩解這個問題。第一,數據向量\(\{x_n\}\)通常位於一個非線性流形內部。由於輸入變數之間的相關性,這個流形本身的維度小於輸入空間的維度。我們將在後面討論手寫數字識別時給出一個例子來說明這一點。如果我們使用局部基函數,那麼我們可以讓基函數只分布在輸入空間中包含數據的區域。這種方法被用在徑向基函數網路中,也被用在支援向量機和相關向量機當中。神經網路模型使用可調節的基函數,這些基函數有著sigmoid非線性的性質。神經網路可以通過調節參數,使得在輸入空間的區域中基函數會按照數據流形發生變化。第二,目標變數可能只依賴於數據流形中的少量可能的方向。利用這個性質,神經網路可以通過選擇輸入空間中基函數產生響應的方向。
7 參考資料
- Christopher M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006
- Markus Svensen, Christopher M. Bishop, Pattern Recognition and Machine Learning – Solutions to the Exercises: Tutors』 Edition, Springer, 2009
- 馬春鵬,《模式識別與機器學習》(本文部分名詞翻譯來自此書),PRML的網傳中文版,2014
- S函數
- 雙曲函數
- 偏置-方差分解
- 數據科學導論 Page47
- Delta函數
- PRML 模式識別和機器學習 從零開始的公式推導 3.5 證據近似 3.5.1 計算證據函數
- PRML 模式識別和機器學習 從零開始的公式推導 3.5.3參數的有效數量 3.6固定基函數的局限性




