圖解AI數學基礎 | 線性代數與矩陣論
- 2022 年 2 月 24 日
- 筆記
- 圖解AI數學基礎 | 從入門到精通系列教程, 矩陣, 線性代數


作者:韓信子@ShowMeAI
教程地址://www.showmeai.tech/tutorials/83
本文地址://www.showmeai.tech/article-detail/162
聲明:版權所有,轉載請聯繫平台與作者並註明出處
1.標量(Scalar)
一個標量就是一個單獨的數。只具有數值大小,沒有方向(部分有正負之分),運算遵循一般的代數法則。
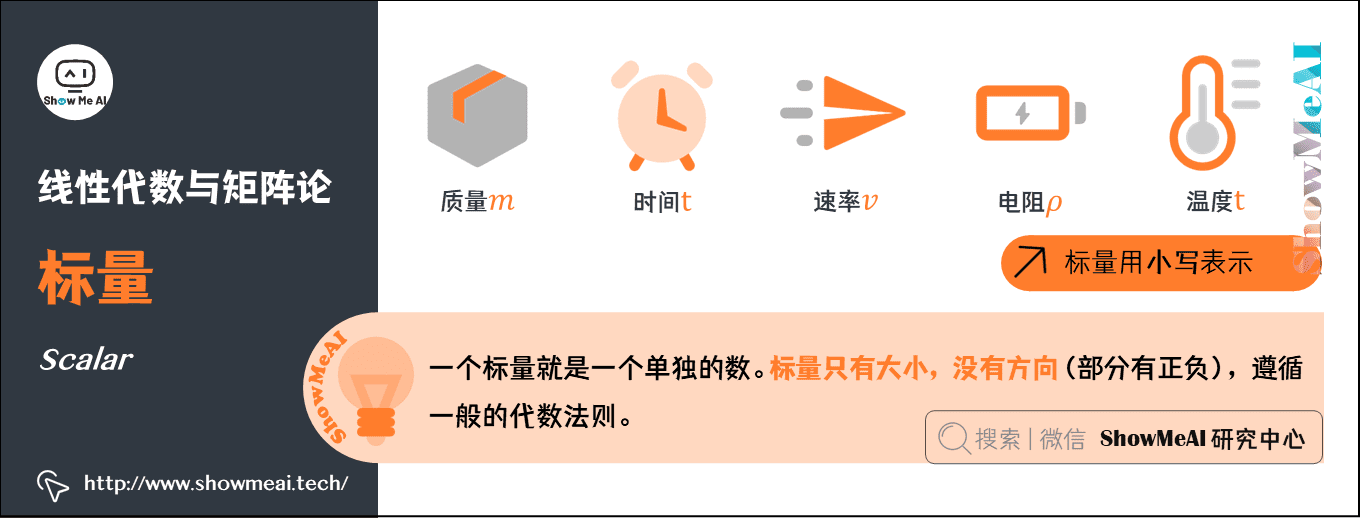

- 一般用小寫的變數名稱表示。
- 品質\(m\)、速率\(v\)、時間\(t\)、電阻\(\rho\) 等物理量,都是數據標量。
2.向量(Vector)
向量指具有大小和方向的量,形態上看就是一列數。
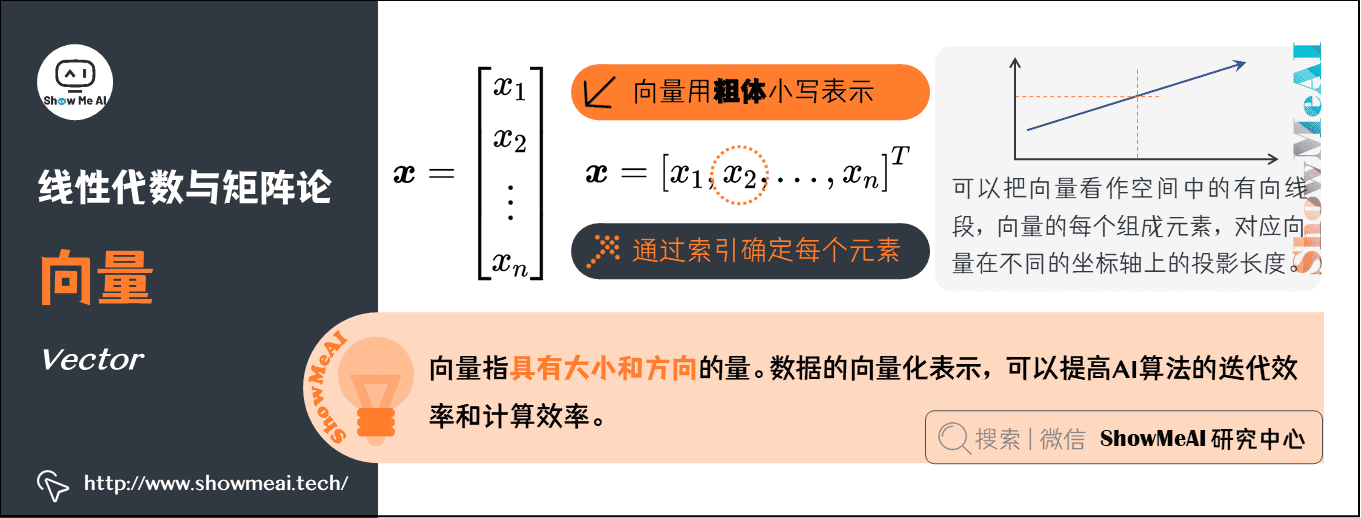
-
通常賦予向量粗體小寫的名稱;手寫體則在字母上加一個向右的箭頭。
-
向量中的元素是有序排列的,通過索引可以確定每個元素。
-
以下兩種方式,可以明確表示向量中的元素時(注意用方括弧)。
-
可以把向量看作空間中的有向線段,向量的每個組成元素,對應向量在不同的坐標軸上的投影長度。
AI中的應用:在機器學習中,單條數據樣本的表徵都是以向量化的形式來完成的。向量化的方式可以幫助AI演算法在迭代與計算過程中,以更高效的方式完成。
3.矩陣(Matrix)
矩陣是二維數組,其中的每一個元素被兩個索引確定。矩陣在機器學習中至關重要,無處不在。
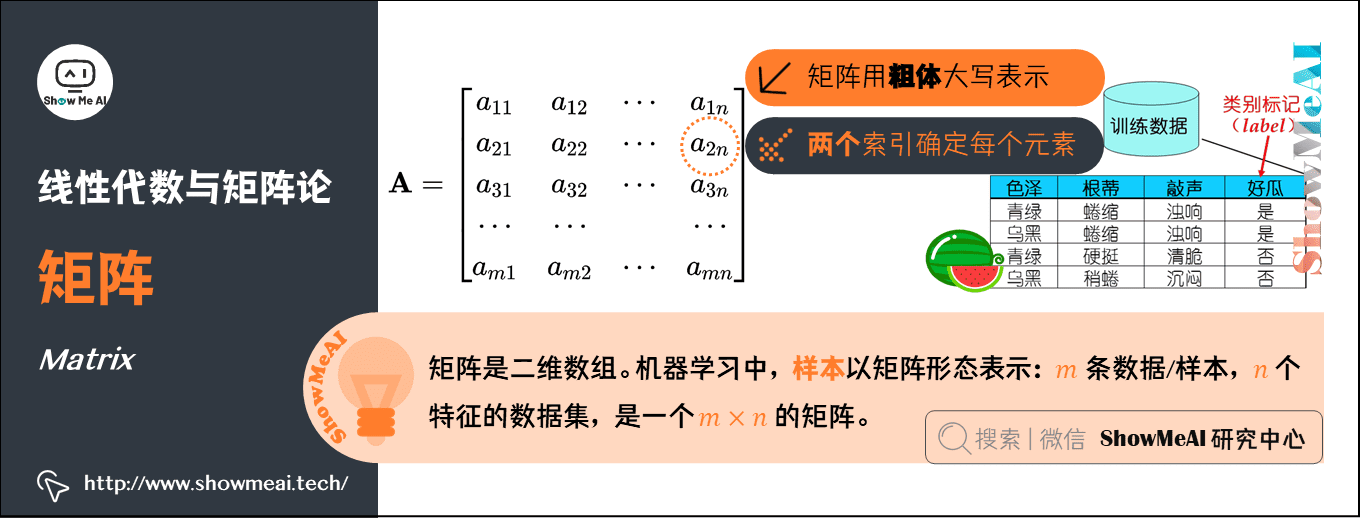
- 通常會賦予矩陣粗體大寫的變數名稱。
AI中的應用:樣本以矩陣形態表示:\(m\)條數據/樣本,\(n\)個特徵的數據集,就是一個\(m \times n\)的矩陣。
4.張量(Tensor)
幾何代數中定義的張量,是基於向量和矩陣的推廣。
- 標量,可以視為零階張量
- 向量,可以視為一階張量
- 矩陣,可以視為二階張量
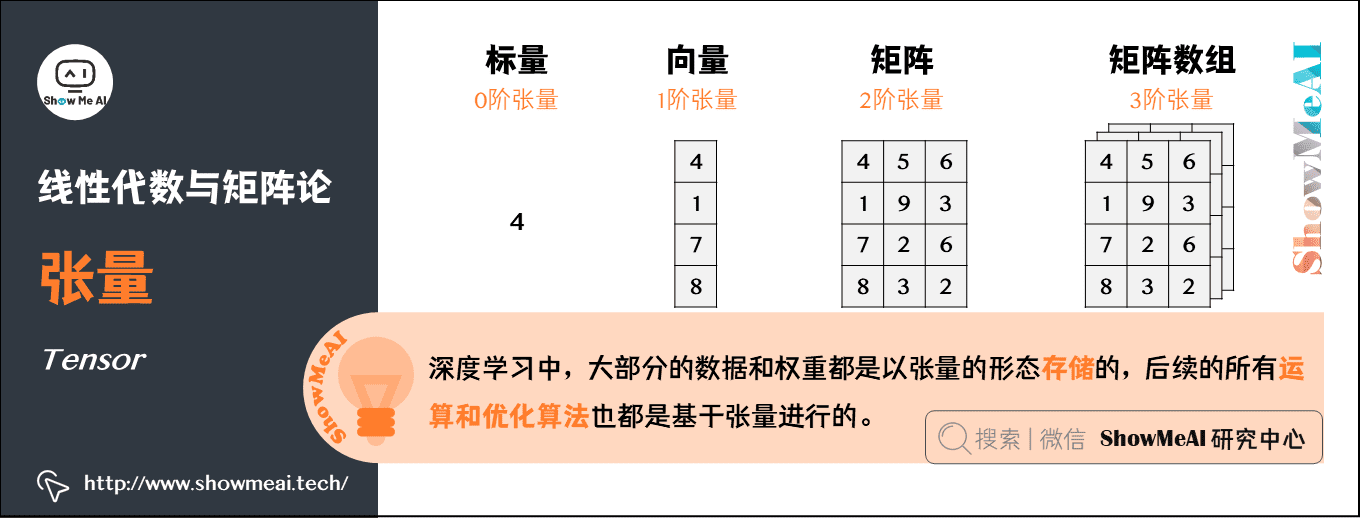

- 圖片以矩陣形態表示:將一張彩色圖片表示成一個\(H \times W \times C\)的三階張量,其中\(H\)是高,\(W\)是寬,\(C\)通常取3,表示彩色圖3個顏色通道。
- 在這個例子的基礎上,將這一定義繼續擴展,即:用四階張量(樣本,高度,寬度,通道)表示一個包含多張圖片的數據集,其中,樣本表示圖片在數據集中的編號。
- 用五階張量(樣本,幀速,高度,寬度,通道)表示影片。
AI中的應用:張量是深度學習中一個非常重要的概念,大部分的數據和權重都是以張量的形態存儲的,後續的所有運算和優化演算法也都是基於張量進行的。
5.範數(Norm)
範數是一種強化了的距離概念;簡單來說,可以把『範數』理解為『距離』。
在數學上,範數包括『向量範數』和『矩陣範數』:
-
向量範數(Vector Norm),表徵向量空間中向量的大小。向量空間中的向量都是有大小的,這個大小就是用範數來度量。不同的範數都可以來度量這個大小,就好比米和尺都可以來度量遠近一樣。
-
矩陣範數(Matrix Norm),表徵矩陣引起變化的大小。比如,通過運算\(\boldsymbol{A}\boldsymbol{X} = \boldsymbol{B}\),可以將向量\(\boldsymbol{X}\)變化為\(\boldsymbol{B}\),矩陣範數就可以度量這個變化的大小。

向量範數的計算:
對於\(\mathrm{p} -\)範數,如果\(\boldsymbol{x}=\left[x_{1}, x_{2}, \cdots, x_{n}\right]^{\mathrm{T}}\),那麼向量\(\boldsymbol{x}\)的\(\mathrm{p} -\)範數就是\(\|\boldsymbol{x}\|_{p}=\left(\left|x_{1}\right|^{p}+\left|x_{2}\right|^{p}+\cdots+\left|x_{n}\right|^{p}\right)^{\frac{1}{p}}\)。
L1範數:\(|| \boldsymbol{x}||_{1}=\left|x_{1}\right|+\left|x_{2}\right|+\left|x_{3}\right|+\cdots+\left|x_{n}\right|\)
-
\(\mathrm{p} =1\)時,就是L1範數,是\(\boldsymbol{x}\)向量各個元素的絕對值之和。
-
L1範數有很多的名字,例如我們熟悉的曼哈頓距離、最小絕對誤差等。
L2範數:\(\|\boldsymbol{x}\|_{2}=\left(\left|x_{1}\right|^{2}+\left|x_{2}\right|^{2}+\left|x_{3}\right|^{2}+\cdots+\left|x_{n}\right|^{2}\right)^{1 / 2}\)
-
\(\mathrm{p} =2\)時,就是L2範數,是\(\boldsymbol{x}\)向量各個元素平方和的開方。
-
L2範數是我們最常用的範數,歐氏距離就是一種L2範數。
AI中的應用:在機器學習中,L1範數和L2範數很常見,比如『評估準則的計算』、『損失函數中用於限制模型複雜度的正則化項』等。
6.特徵分解(Eigen-decomposition)
將數學對象分解成多個組成部分,可以找到他們的一些屬性,或者能更高地理解他們。例如,整數可以分解為質因數,通過\(12=2 \times 3 \times 3\)可以得到『12的倍數可以被3整除,或者12不能被5整除』。
同樣,我們可以將『矩陣』分解為一組『特徵向量』和『特徵值』,來發現矩陣表示為數組元素時不明顯的函數性質。特徵分解(Eigen-decomposition)是廣泛使用的矩陣分解方式之一。
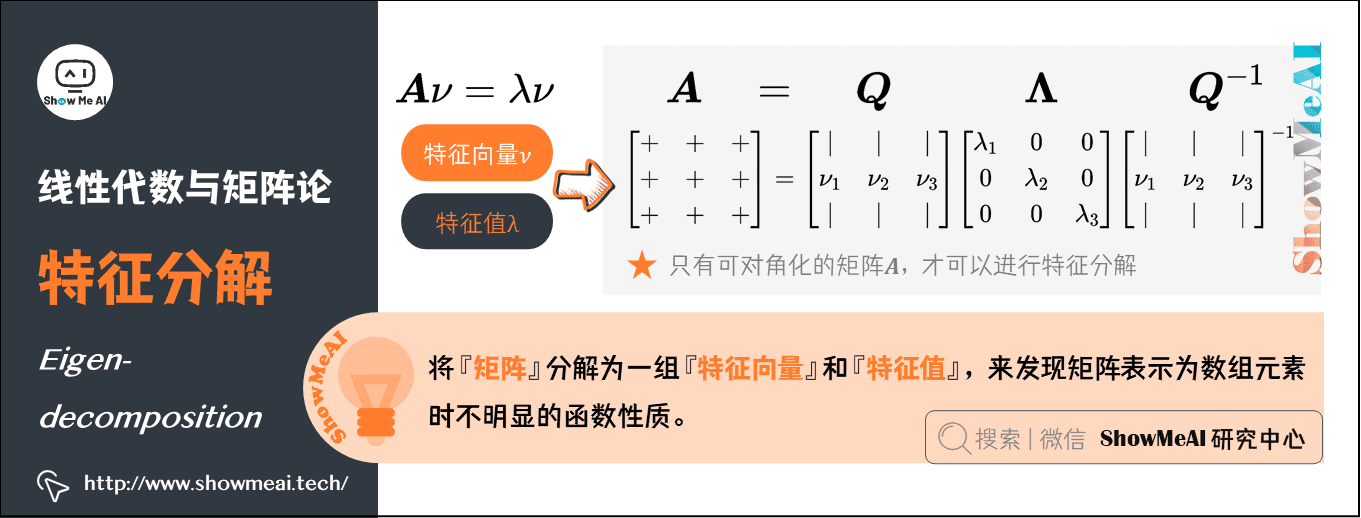
-
特徵向量:方陣\(\boldsymbol{A}\)的特徵向量,是指與\(\boldsymbol{A}\)相乘後相當於對該向量進行縮放的非零向量,即\(\boldsymbol{A}\nu =\lambda \nu\)。
-
特徵值:標量\(\lambda\)被稱為這個特徵向量對應的特徵值。
使用特徵分解去分析矩陣\(\boldsymbol{A}\)時,得到特徵向量\(\nu\)構成的矩陣\(\boldsymbol{Q}\)和特徵值構成的向量\(\boldsymbol{\Lambda }\),我們可以重新將\(\boldsymbol{A}\)寫作:\(\boldsymbol{A} = \boldsymbol{Q} \boldsymbol{\Lambda} \boldsymbol{Q}^{-1}\)
7.奇異值分解(Singular Value Decomposition,SVD)
矩陣的特徵分解是有前提條件的。只有可對角化的矩陣,才可以進行特徵分解。實際很多矩陣不滿足這一條件,這時候怎麼辦呢?
將矩陣的『特徵分解』進行推廣,得到一種被稱為『矩陣的奇異值分解』的方法,即將一個普通矩陣分解為『奇異向量』和『奇異值』。通過奇異值分解,我們會得到一些類似於特徵分解的資訊。
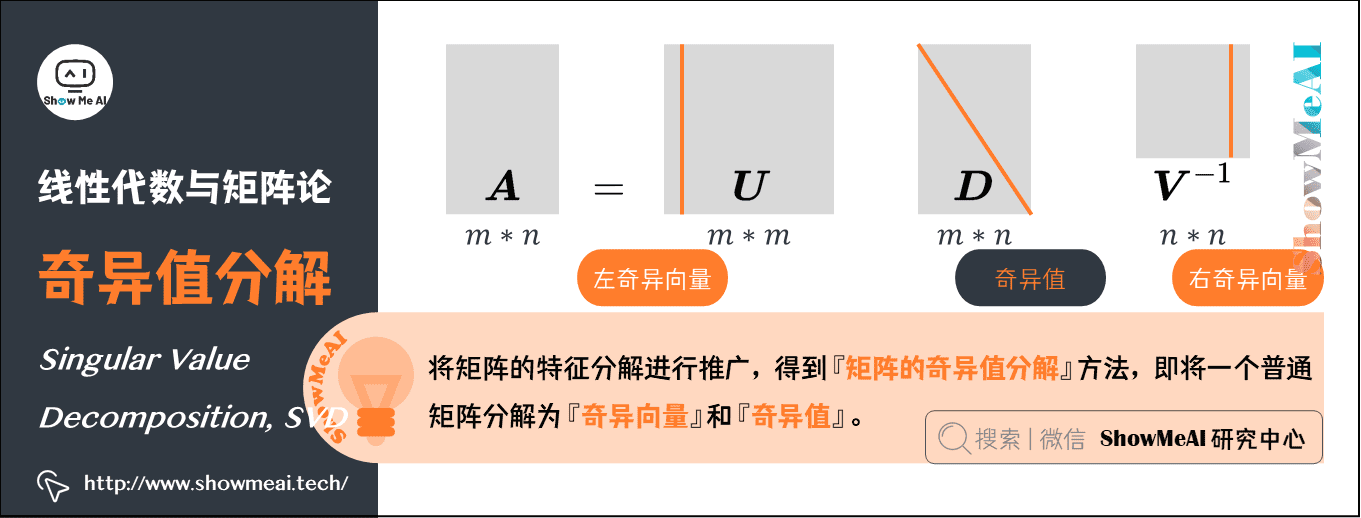
將矩陣\(\boldsymbol{A}\)分解成三個矩陣的乘積\(\boldsymbol{A} = \boldsymbol{U} \boldsymbol{D} \boldsymbol{V}^{-1}\)。
-
假設\(\boldsymbol{A}\)是一個\(m*n\)矩陣,那麼\(\boldsymbol{U}\)是一個\(m*m\)矩陣,\(D\)是一個\(m*n\)矩陣,\(V\)是一個\(n*n\)矩陣。
-
\(\boldsymbol{U} \boldsymbol{V} \boldsymbol{D}\)這幾個矩陣都擁有特殊的結構:
-
\(\boldsymbol{U}\)和\(\boldsymbol{V}\)都是正交矩陣,矩陣\(\boldsymbol{U}\)的列向量被稱為左奇異向量,矩陣\(\boldsymbol{V}\) 的列向量被稱右奇異向量。
-
\(\boldsymbol{D}\)是對角矩陣(注意,\(\boldsymbol{D}\)不一定是方陣)。對角矩陣\(\boldsymbol{D}\)對角線上的元素被稱為矩陣\(\boldsymbol{A}\)的奇異值。
-
AI中的應用:SVD最有用的一個性質可能是拓展矩陣求逆到非方矩陣上。而且大家在推薦系統中也會見到基於SVD的演算法應用。
8.Moore-Penrose廣義逆/偽逆(Moore-Penrose Pseudoinverse)
假設在下面問題中,我們想通過矩陣\(\boldsymbol{A}\)的左逆\(\boldsymbol{B}\)來求解線性方程:\(\boldsymbol{A} x=y\),等式兩邊同時左乘左逆B後,得到:\(x=\boldsymbol{B} y\)。是否存在唯一的映射將\(\boldsymbol{A}\)映射到\(\boldsymbol{B}\),取決於問題的形式:
-
如果矩陣\(\boldsymbol{A}\)的行數大於列數,那麼上述方程可能沒有解;
-
如果矩陣\(\boldsymbol{A}\)的行數小於列數,那麼上述方程可能有多個解。
Moore-Penrose偽逆使我們能夠解決這種情況,矩陣\(\boldsymbol{A}\)的偽逆定義為:
\]
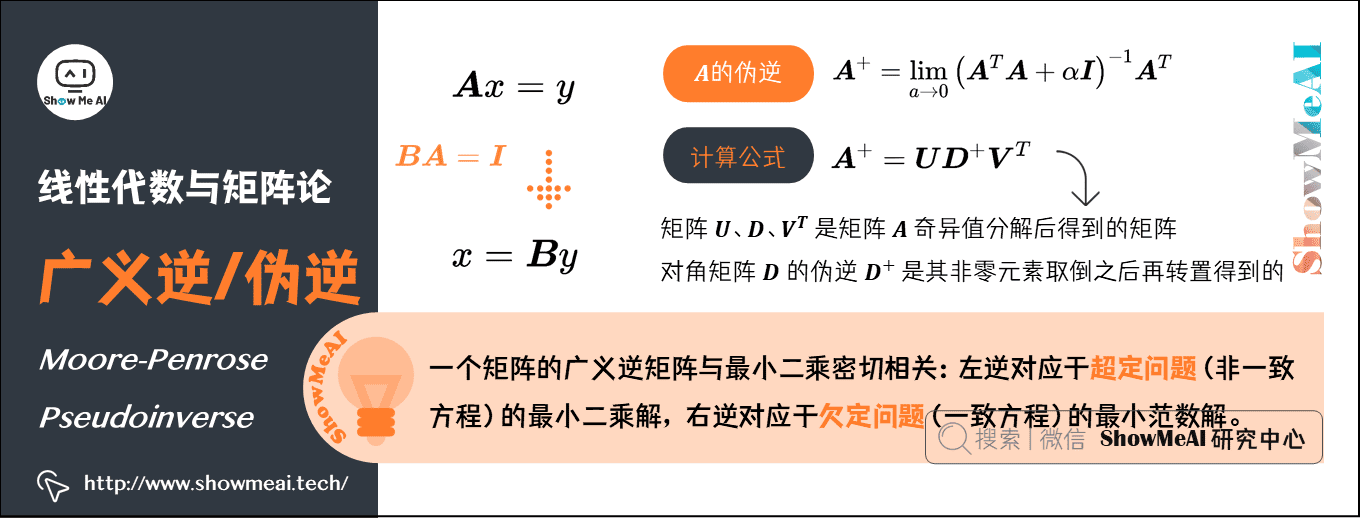
但是計算偽逆的實際演算法沒有基於這個式子,而是使用下面的公式:
\]
-
矩陣\(\boldsymbol{U}\)、\(\boldsymbol{D}\)和\(\boldsymbol{V}^{T}\)是矩陣\(\boldsymbol{A}\)奇異值分解後得到的矩陣;
-
對角矩陣\(\boldsymbol{D}\)的偽逆\(\boldsymbol{D}^{+}\)是其非零元素取倒之後再轉置得到的。
9.常用的距離度量
在機器學習里,大部分運算都是基於向量的,一份數據集包含n個特徵欄位,那每一條樣本就可以表示為n維的向量,通過計算兩個樣本對應向量之間的距離值大小,有些場景下能反映出這兩個樣本的相似程度。還有一些演算法,像KNN和K-means,非常依賴距離度量。
設有兩個\(n\)維變數:
\]
\]
一些常用的距離公式定義如下:

1)曼哈頓距離(Manhattan Distance)

曼哈頓距離也稱為城市街區距離,數學定義如下:
\]
曼哈頓距離的Python實現:
import numpy as np
vector1 = np.array([1,2,3])
vector2 = np.array([4,5,6])
manhaton_dist = np.sum(np.abs(vector1-vector2))
print("曼哈頓距離為", manhaton_dist)
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
2)歐氏距離(Euclidean Distance)

歐氏距離其實就是L2範數,數學定義如下:
\]
歐氏距離的Python實現:
import numpy as np
vector1 = np.array([1,2,3])
vector2 = np.array([4,5,6])
eud_dist = np.sqrt(np.sum((vector1-vector2)**2))
print("歐式距離為", eud_dist)
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
3)閔氏距離(Minkowski Distance)
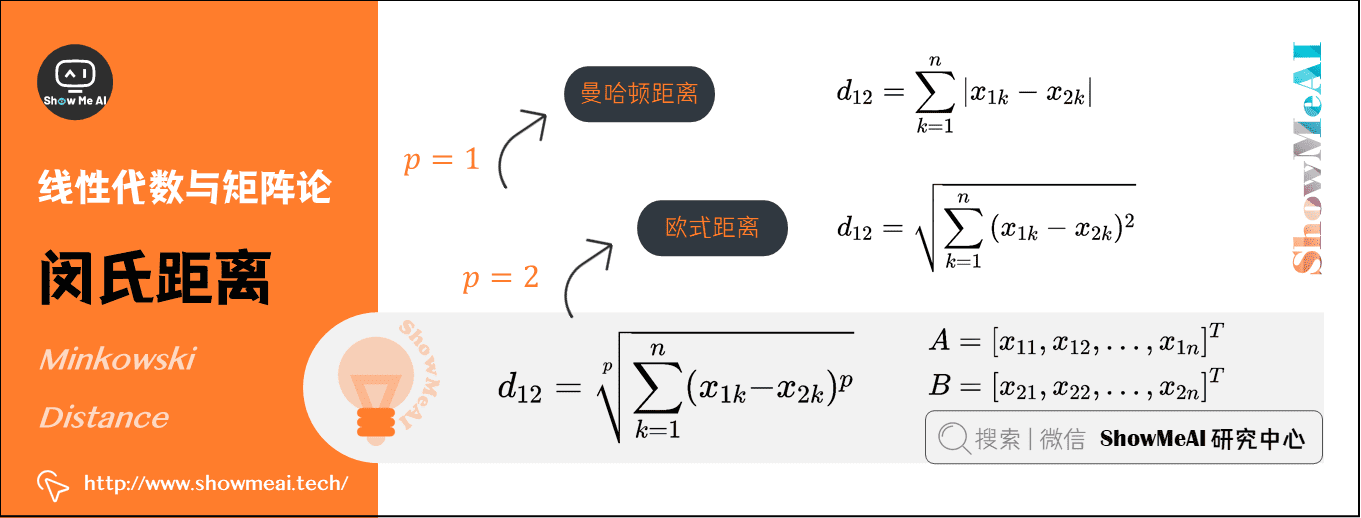
從嚴格意義上講,閔可夫斯基距離不是一種距離,而是一組距離的定義:
\]
實際上,當\(p=1\)時,就是曼哈頓距離;當\(p=2\)時,就是歐式距離。
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
4)切比雪夫距離(Chebyshev Distance)

切比雪夫距離就是無窮範數,數學表達式如下:
\]
切比雪夫距離的Python實現如下:
import numpy as np
vector1 = np.array([1,2,3])
vector2 = np.array([4,5,6])
cb_dist = np.max(np.abs(vector1-vector2))
print("切比雪夫距離為", cb_dist)
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
5)餘弦相似度(Cosine Similarity)
餘弦相似度的取值範圍為[-1,1],可以用來衡量兩個向量方向的差異:
- 夾角餘弦越大,表示兩個向量的夾角越小;
- 當兩個向量的方向重合時,夾角餘弦取最大值1;
- 當兩個向量的方向完全相反時,夾角餘弦取最小值-1。

機器學習中用這一概念來衡量樣本向量之間的差異,其數學表達式如下:
\]
夾角餘弦的Python實現:
import numpy as np
vector1 = np.array([1,2,3])
vector2 = np.array([4,5,6])
cos_sim = np.dot(vector1, vector2)/(np.linalg.norm(vector1)*np.linalg.norm(vector2))
print("餘弦相似度為", cos_sim)
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
6)漢明距離(Hamming Distance)

漢明距離定義的是兩個字元串中不相同位數的數目。例如,字元串『1111』與『1001』之間的漢明距離為2。資訊編碼中一般應使得編碼間的漢明距離儘可能的小。
\]
漢明距離的Python實現:
import numpy as np
a=np.array([1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0])
b=np.array([1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1])
hanm_dis = np.count_nonzero(a!=b)
print("漢明距離為", hanm_dis)
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
7)傑卡德係數(Jaccard Index)
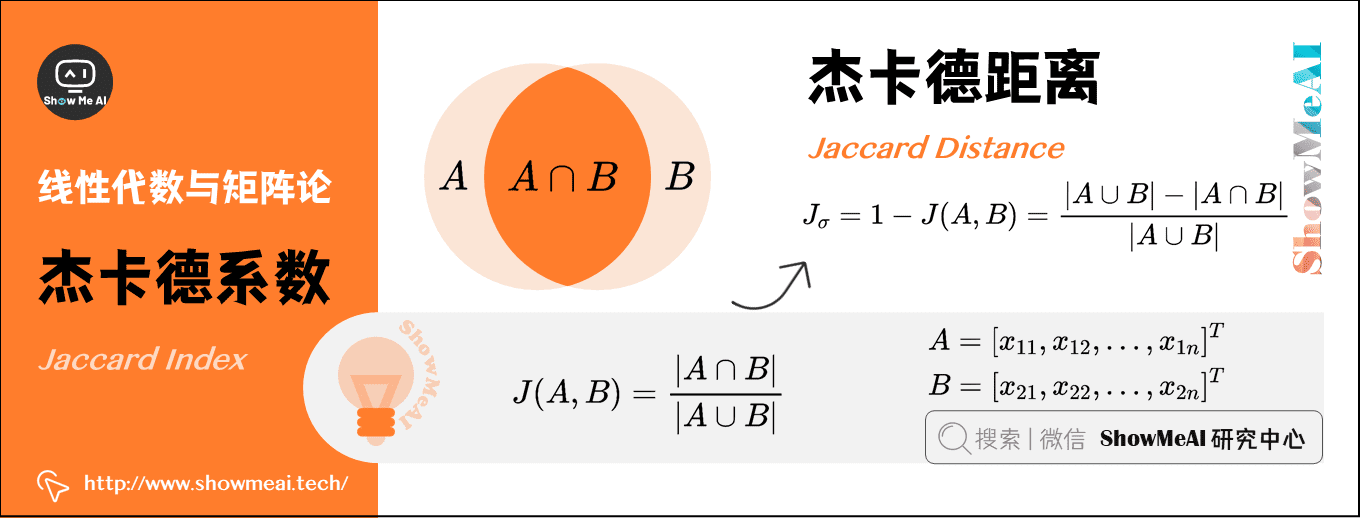
兩個集合\(A\)和\(B\)的交集元素在\(A\)和\(B\)的並集中所佔的比例稱為兩個集合的傑卡德係數,用符號\(J(A,B)\)表示,數學表達式為:
\]
傑卡德相似係數是衡量兩個集合的相似度的一種指標。一般可以將其用在衡量樣本的相似度上。
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
8)傑卡德距離(Jaccard Distance)

與傑卡德係數相反的概念是傑卡德距離,其定義式為:
\]
傑卡德距離的Python實現:
import numpy as np
vec1 = np.random.random(10)>0.5
vec2 = np.random.random(10)>0.5
vec1 = np.asarray(vec1, np.int32)
vec2 = np.asarray(vec2, np.int32)
up=np.double(np.bitwise_and((vec1 != vec2),np.bitwise_or(vec1 != 0, vec2 != 0)).sum())
down=np.double(np.bitwise_or(vec1 != 0, vec2 != 0).sum())
jaccard_dis =1-(up/down)
print("傑卡德距離為", jaccard_dis)
前往我們的在線編程環境運行程式碼://blog.showmeai.tech/python3-compiler/#/
ShowMeAI相關文章推薦
ShowMeAI系列教程推薦







