Spring系列19:SpEL詳解
本文內容
-
SpEL概念
-
快速入門
-
關鍵介面
-
全面用法
-
bean定義中使用
SpEL概念
Spring 表達式語言(簡稱「SpEL」)是一種強大的表達式語言,支援在運行時查詢和操作對象圖。語言語法類似於 Unified EL,但提供了額外的功能,最值得注意的是方法調用和基本的字元串模板功能。
雖然 SpEL 是 Spring 產品組合中表達式評估的基礎,但它不直接與 Spring 綁定,可以獨立使用。
表達式語言支援以下功能:
- 字面表達式
- 布爾和關係運算符
- 正則表達式
- 類表達式
- 訪問屬性、數組、列表和映射
- 方法調用
- 關係運算符
- 調用構造函數
- bean引用
- 數組構造
- 內聯的list
- 內聯的map
- 三元運算符
- 變數
- 用戶自定義函數
- 集合選擇
- 模板化表達式
快速入門
通過幾個案例快速體驗SpEL表達式的使用。
案例1 Hello World
純字面意義的字元串輸出,體驗使用的基本步驟。
@Test
public void test_hello() {
// 1 定義解析器
SpelExpressionParser parser = new SpelExpressionParser();
// 2 使用解析器解析表達式
Expression exp = parser.parseExpression("'Hello World'");
// 3 獲取解析結果
String value = (String) exp.getValue();
System.out.println(value);
}
// 結果
Hello World
案例2 字元串方法的字面調用
在表達式中調用字元串的普通方法和構造方法。
@Test
public void test_String_method() {
// 1 定義解析器
SpelExpressionParser parser = new SpelExpressionParser();
// 2 使用解析器解析表達式
Expression exp = parser.parseExpression("'Hello World'.concat('!')");
// 3 獲取解析結果
String value = (String) exp.getValue();
System.out.println(value);
exp = parser.parseExpression("'Hello World'.bytes");
byte[] bytes = (byte[]) exp.getValue();
exp = parser.parseExpression("'Hello World'.bytes.length");
int length = (Integer) exp.getValue();
System.out.println("length: " + length);
// 調用
exp = parser.parseExpression("new String('hello world').toUpperCase()");
System.out.println("大寫: " + exp.getValue());
}
// 結果
Hello World!
length: 11
大寫: HELLO WORLD
案例3 針對特定對象解析表達式
SpEL 更常見的用法是提供針對特定對象實例(稱為根對象)進行評估的表達式字元串。案例演示如何從 Inventor 類的實例中檢索名稱屬性或創建布爾條件。
Inventor相關類定義如下
public class Inventor {
private String name;
private String nationality;
private String[] inventions;
private Date birthdate;
private PlaceOfBirth placeOfBirth;
// 省略其它方法
}
public class PlaceOfBirth {
private String city;
private String country;
// 省略其它方法
}
表達式解析測試
@Test
public void test_over_root() {
// 創建 Inventor 對象
GregorianCalendar c = new GregorianCalendar();
c.set(1856, 7, 9);
Inventor tesla = new Inventor("Nikola Tesla", c.getTime(), "Serbian");
// 1 定義解析器
ExpressionParser parser = new SpelExpressionParser();
// 指定表達式
Expression exp = parser.parseExpression("name");
// 在 tesla對象上解析
String name = (String) exp.getValue(tesla);
System.out.println(name); // Nikola Tesla
exp = parser.parseExpression("name == 'Nikola Tesla'");
// 在 tesla對象上解析並指定返回結果
boolean result = exp.getValue(tesla, Boolean.class);
System.out.println(result); // true
}
執行過程分析和關鍵介面
執行過程分析
上面的案例中SpEL表達式的使用步驟中涉及了幾個概念和介面:
- 用戶表達式:我們定義的表達式,如
1+1!=2 - 解析器:ExpressionParser 介面,負責將用戶表達式解析成SpEL認識的表達式對象
- 表達式對象:Expression介面,SpEL的核心,表達式語言都是圍繞表達式進行的
- 評估上下文:EvaluationContext 介面,表示當前表達式對象操作的對象,表達式的評估計算是在上下文上進行的。
通過下面的簡單案例debug分析執行過程。
@Test
public void test_debug(){
SpelExpressionParser parser = new SpelExpressionParser();
SimpleEvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
Boolean value = parser.parseExpression("1+1!=2").getValue(context, Boolean.class);
System.out.println(value);
}
源碼debug如下,分2大階段,建議自行debug一次:
解析階段:InternalSpelExpressionParser#doParseExpression() 無關源碼已經刪除
// 用戶提供的表達式1+1!=2
private String expressionString = "";
// 分詞流
private List<Token> tokenStream = Collections.emptyList();
@Override
protected SpelExpression doParseExpression(String expressionString, @Nullable ParserContext context)
throws ParseException {
try {
// 1 讀取到用戶的表達式 1+1!=2
this.expressionString = expressionString;
// 2.1 定義分詞器Tokenizer
Tokenizer tokenizer = new Tokenizer(expressionString);
// 2.2 分詞器將字元串拆分為分詞流
this.tokenStream = tokenizer.process();
this.tokenStreamLength = this.tokenStream.size();
this.tokenStreamPointer = 0;
this.constructedNodes.clear();
// 3 將分詞流解析成抽象語法樹 表示為SpelNode介面
SpelNodeImpl ast = eatExpression();
Assert.state(ast != null, "No node");
// 4、將抽象語法樹包裝成 Expression 表達式對象
return new SpelExpression(expressionString, ast, this.configuration);
}
catch (InternalParseException ex) {
throw ex.getCause();
}
}
評估求值階段:SpelExpression#getValue(),無關源碼已經刪除
// 解析階段生成的抽象語法樹對象 SpelNodeImpl
private final SpelNodeImpl ast;
public <T> T getValue(EvaluationContext context, @Nullable Class<T> expectedResultType) throws EvaluationException {
Assert.notNull(context, "EvaluationContext is required");
// ...
// 6.1 應用活動上下文和解析器的配置
ExpressionState expressionState = new ExpressionState(context, this.configuration);
// 6.2 在上下中抽象語法樹進行評估求值
TypedValue typedResultValue = this.ast.getTypedValue(expressionState);
checkCompile(expressionState);
// 6.3 將結果進行類型轉換
return ExpressionUtils.convertTypedValue(context, typedResultValue, expectedResultType);
}
方便理解,流程圖如下圖:
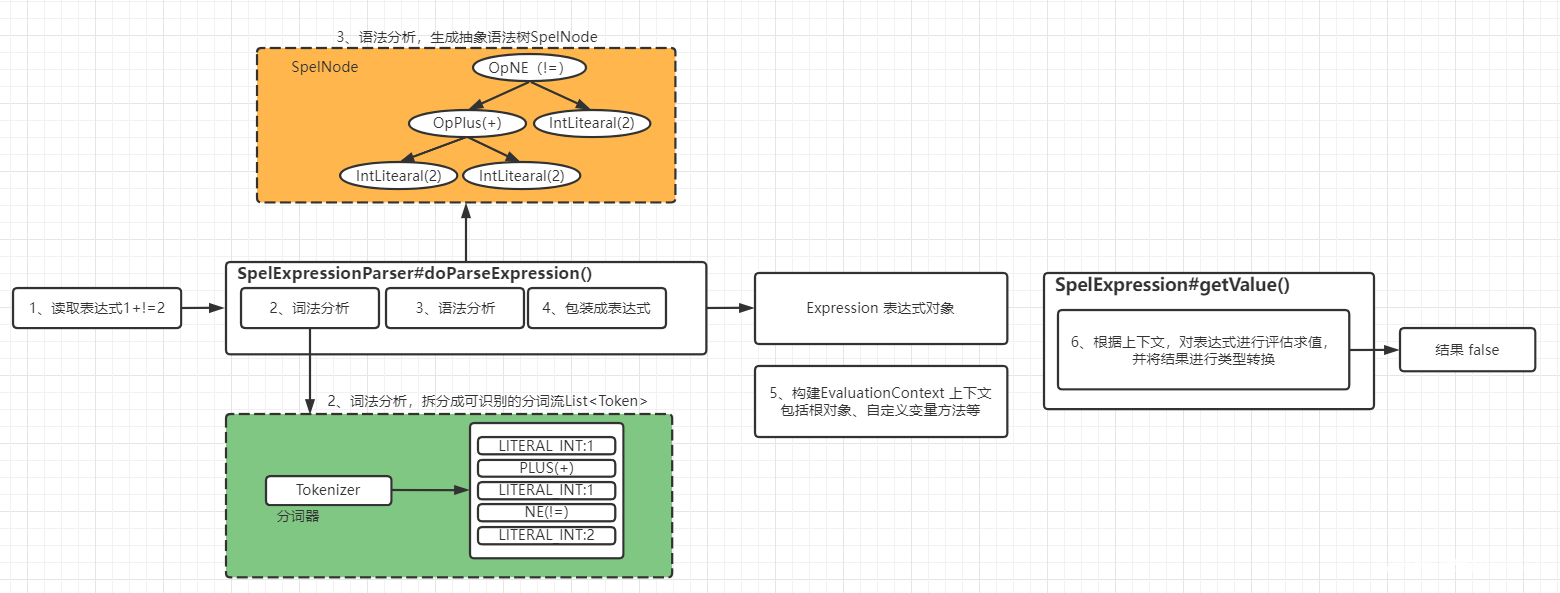
匯總下執行過程:
- 解析器 SpelExpressionParser 讀取用戶提供的表達式
1+1!=2 - 詞法分析:解析器 SpelExpressionParser 使用分詞器拆分用戶字元串表達式成分詞流
- 語法分析:解析器 SpelExpressionParser 將分詞流生成內部的抽象語法樹
- 包裝表達式:對外提供Expression介面來簡化表示抽象語法樹,從而隱藏內部實現細節,並提供getValue簡單方法用於獲取表達式
- 用戶提供表達式上下文對象(非必須),SpEL使用EvaluationContext介面表示上下文對象,用於設置根對象、自定義變數、自定義函數、類型轉換器等
- 在表達式上下文中調用內部抽象語法樹進行評估求值並轉換結果類型到目標類型。
ExpressionParser 介面
ExpressionParser 介面將表達式字元串解析為可以計算的編譯表達式。支援解析模板以及標準表達式字元串。
關鍵方法parseExpressio(),在解析失敗時拋出 ParseException 異常。
public interface ExpressionParser {
// 解析表達式字元串並返回一個可用於重複評估的表達式對象。
Expression parseExpression(String expressionString) throws ParseException;
// 解析表達式字元串並返回一個可用於重複評估的表達式對象。 指定解析評估上下文
Expression parseExpression(String expressionString, ParserContext context) throws ParseException;
}
實現類 TemplateAwareExpressionParser 增加了對模板的解析支援。
常用的實現類 SpelExpressionParser 增加了 SpelParserConfiguration 解析器配置,實例是可重用和執行緒安全的。

Expression 介面
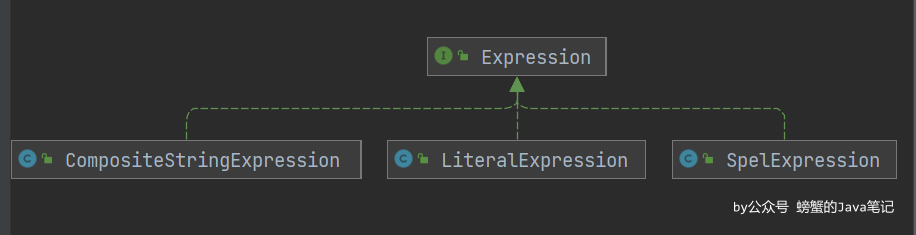
Expression 指能夠根據上下文對象評估自身的表達式。封裝先前解析的表達式字元串的詳細資訊。為表達式求值提供通用抽象。
關鍵方法如下:
getValue()在解析計算失敗會拋出 EvaluationException 異常
public interface Expression {
// 獲取原始表達式
String getExpressionString();
// 獲取表達式計算值 默認上下文 默認類型
Object getValue() throws EvaluationException;
// 獲取表達式計算值 指定上下文、根對象、期望返回值類型
<T> T getValue(EvaluationContext context, @Nullable Object rootObject, @Nullable Class<T> desiredResultType)
throws EvaluationException;
// 在提供的上下文中將此表達式設置為提供的值。
void setValue(@Nullable Object rootObject, @Nullable Object value) throws EvaluationException;
}
SpelExpression 介面表示已準備好在指定上下文中評估的已解析(有效)表達式。表達式可以獨立評估,也可以在指定的上下文中評估。在表達式評估期間,可能會要求上下文解析對類型、bean、屬性和方法的引用。
ParserContext 介面
ParserContext介面代表提供給表達式解析器的輸入,可以影響表達式解析和編譯。
源碼如下:
public interface ParserContext {
// 是否是模板
boolean isTemplate();
// 模板表達式的前綴
String getExpressionPrefix();
// 模板表達式的後綴
String getExpressionSuffix();
// 啟用模板表達式解析模式的默認 ParserContext 實現。表達式前綴是「#{」,表達式後綴是「}」。
ParserContext TEMPLATE_EXPRESSION = new ParserContext() {
@Override
public boolean isTemplate() {
return true;
}
@Override
public String getExpressionPrefix() {
return "#{";
}
@Override
public String getExpressionSuffix() {
return "}";
}
};
}
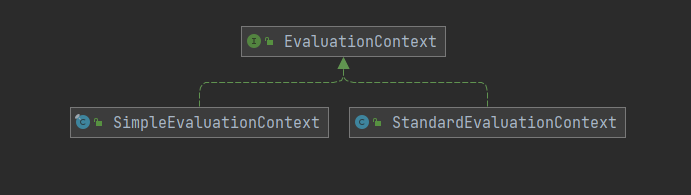
EvaluationContext 介面
EvaluationContext 介面評估表達式以解析屬性、方法或欄位並幫助執行類型轉換。表達式是在在評估上下文中執行的,遇到引用時使用上下文來解析。
源碼及關鍵方法如下:
public interface EvaluationContext {
// 返回默認的根上下文對象,可以在評估表達式時被覆
TypedValue getRootObject();
// 返回訪問器列表用於屬性的讀寫訪問
List<PropertyAccessor> getPropertyAccessors();
// 返回解析器列表用於定位構造函數。
List<ConstructorResolver> getConstructorResolvers();
// 返回方法解析器以查找方法
List<MethodResolver> getMethodResolvers();
// 返回 bean解析器以通過名稱查找bean
@Nullable
BeanResolver getBeanResolver();
// 返回類型定位器用於查找類型,支援簡單類型名稱和全程
TypeLocator getTypeLocator();
// 返回類型轉換器用於類型轉換
TypeConverter getTypeConverter();
// 返回一個類型比較器,用於比較對象對是否相等
TypeComparator getTypeComparator();
// 返回一個操作符重載器,該操作符重載器可能支援多個標準類型集之間的數學操作。
OperatorOverloader getOperatorOverloader();
// 將此評估上下文中的命名變數設置為指定值。
void setVariable(String name, @Nullable Object value);
// 在此求值上下文中查找指定變數。
@Nullable
Object lookupVariable(String name);
}
Spring 中提供了2個實現類:
-
StandardEvaluationContext
公開全套 SpEL 語言功能和配置選項。可以使用它來指定默認根對象並配置每個可用的評估相關策略。功能強大且高度可配置,此上下文使用所有適用策略的標準實現,基於反射來解析屬性、方法和欄位。
-
SimpleEvaluationContext
側重於基本 SpEL 功能和自定義選項的子集,針對簡單的條件評估和特定的數據綁定場景。
SimpleEvaluationContext 旨在僅支援 SpEL 語言語法的子集。它不包括 Java 類型引用、構造函數和 bean 引用。要求明確選擇對表達式中的屬性和方法的支援級別,默認情況下,create() 靜態工廠方法只允許對屬性進行讀取訪問。獲取構建器以配置所需的確切支援級別,針對以下一項或某種組合:
- 僅自定義 PropertyAccessor(無反射)
- 只讀訪問的數據綁定屬性
- 用於讀取和寫入的數據綁定屬性
SpEl用法一網打盡
基本字面表達式
支援的文字表達式類型是字元串、數值(int、real、hex)、boolean 和 null。字元串由單引號分隔。要將單引號本身放在字元串中,使用兩個單引號字元。數字支援使用負號、指數表示法和小數點。默認情況下,使用 Double.parseDouble() 解析實數。
@Test
public void test_literal() {
ExpressionParser parser = new SpelExpressionParser();
// 字元串 "Hello World"
String helloWorld = (String) parser.parseExpression("'Hello World'").getValue();
System.out.println(helloWorld);
double num = (Double) parser.parseExpression("6.0221415E+23").getValue();
System.out.println(num);
// int 2147483647
int maxValue = (Integer) parser.parseExpression("0x7FFFFFFF").getValue();
System.out.println(maxValue);
// 負數
System.out.println((Integer) parser.parseExpression("-100").getValue());
// boolean
boolean trueValue = (Boolean) parser.parseExpression("true").getValue();
System.out.println(trueValue);
// null
Object nullValue = parser.parseExpression("null").getValue();
System.out.println(nullValue);
}
// 結果
Hello World
6.0221415E23
2147483647
-100
true
null
屬性、數組、列表、Map
屬性: 指定屬性名,通過”.”支援多級嵌套。
數組:[index] 方式
列表:[index] 方式
Map:[‘key’] 方式
直接看案例。
通用的對象,後面案例通用
public class SpELTest2 {
// 解析器
SpelExpressionParser parser;
// 評估上下文
SimpleEvaluationContext context;
@Before
public void before() {
parser = new SpelExpressionParser();
context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
}
}
/**
* 屬性 數組 列表 map 索引
*/
@Test
public void test2(){
Inventor inventor = new Inventor("發明家1", "中國");
// 發明作品數組
inventor.setInventions(new String[] {"發明1","發明2","發明3","發明4"});
// 1 屬性
String name = parser.parseExpression("name").getValue(context, inventor, String.class);
System.out.println("屬性: " + name);
// 屬性: 發明家1
// 2 數組表達式
String invention = parser.parseExpression("inventions[3]").getValue(context, inventor, String.class);
System.out.println("數組表達式: " + invention);
// 數組表達式: 發明4
// 3 List
List strList = Arrays.asList("str1", "str2", "str3");
String str = parser.parseExpression("[0]").getValue(context, strList, String.class);
System.out.println(str);
// str1
// 4 map
Map map = new HashMap<String, String>();
map.put("xxx", "ooo");
map.put("xoo", "oxx");
String value = parser.parseExpression("['xoo']").getValue(context, map, String.class);
System.out.println(value);
// oxx
}
內聯List
使用 {} 表示法直接在表達式中表示列表
// 內聯List
@Test
public void test3() {
List numbers = (List) parser.parseExpression("{1,3,5,7}").getValue(context);
System.out.println(numbers);
//[1, 3, 5, 7]
List listOfList = (List) parser.parseExpression("{{1,3,5,7},{0,2,4,6}}").getValue(context);
System.out.println(listOfList);
// [[1, 3, 5, 7], [0, 2, 4, 6]]
}
內聯Map
使用 {key:value} 表示法直接在表達式中表示映射
/**
* 4 內聯Map
*/
@Test
public void test4(){
Map<String, Object> infoMap =
(Map<String, Object>) parser.parseExpression("{'name':'name', password:'111'}").getValue();
System.out.println(infoMap);
//{name=name, password=111}
Map mapOfMap =
(Map) parser.parseExpression("{name:{first:'xxx', last:'ooo'}, password:'111'}").getValue(context);
System.out.println(mapOfMap);
// {name={first=xxx, last=ooo}, password=111}
}
集合選擇
選擇是一種強大的表達式語言功能,通過從其元素中進行選擇將源集合轉換為另一個集合。
Map 篩選的元素是 Map.Entry,可以使用 key 和 value 來篩選。
3種用法:
- 從集合按條件篩選生成新集合:
.?[selectionExpression] - 從集合按條件篩選後取第一個元素:
.?[selectionExpression] - 從集合按條件篩選後取最後一個元素:
.?[selectionExpression]
/**
* 集合選擇
*/
@Test
public void test15(){
Society society = new Society();
// 發明者列表
for (int i = 0; i < 5; i++) {
Inventor inventor = new Inventor("發明家" + i, i % 2 == 0 ? "中國" : "外國");
society.getMembers().add(inventor);
}
// 1、 List 篩選 .?[selectionExpression]
List<Inventor> list = (List<Inventor>) parser.parseExpression("members.?[nationality == '中國']").getValue(society);
list.forEach(item -> {
System.out.println(item.getName() + " : " + item.getNationality());
});
// 發明家0 : 中國
// 發明家2 : 中國
// 發明家4 : 中國
// 2、 List 取第一個.^[selectionExpression] 取最後一個.$[selectionExpression]
Inventor first = parser.parseExpression("members.^[nationality == '中國']").getValue(society, Inventor.class);
Inventor last = parser.parseExpression("members.$[nationality == '中國']").getValue(society, Inventor.class);
System.out.println(first.getName() + " : " + first.getNationality());// 發明家0 : 中國
System.out.println(last.getName() + " : " + last.getNationality()); // 發明家4 : 中國
// 3 Map 篩選維度是 Map.Entry,其鍵和值可作為用於選擇的屬性訪問
society.getOfficers().put("1", 100);
society.getOfficers().put("2", 200);
society.getOfficers().put("3", 300);
Map mapNew = (Map) parser.parseExpression("officers.?[value>100]").getValue(society);
System.out.println(mapNew); // {2=200, 3=300}
}
集合映射
一個集合通過映射的方式轉換成新的集合,如從 Map 映射成 List,語法是: .![projectionExpression]
/**
* 集合映射
*/
@Test
public void test16(){
Society society = new Society();
// 發明者列表
for (int i = 0; i < 5; i++) {
Inventor inventor = new Inventor("發明家" + i, i % 2 == 0 ? "中國" : "外國");
society.getMembers().add(inventor);
}
// 1、 List<Inventor> 映射到 List<String> 只要name
List<String> nameList = (List<String>) parser.parseExpression("members.![name]").getValue(society);
System.out.println(nameList); // [發明家0, 發明家1, 發明家2, 發明家3, 發明家4]
// 2 Map映射到List
society.getOfficers().put("1", 100);
society.getOfficers().put("2", 200);
society.getOfficers().put("3", 300);
List<String> kvList= (List<String>) parser.parseExpression("officers.![key + '-' + value]").getValue(society);
System.out.println(kvList); // [1-100, 2-200, 3-300]
}
數組定義
直接使用 new 方式 ,注意: 多維數組不可以初始化。
/**
* 數組生成
*/
@Test
public void test5(){
int[] numbers1 = (int[]) parser.parseExpression("new int[4]").getValue(context);
// 一維數組可以初始化
int[] numbers2 = (int[]) parser.parseExpression("new int[]{1,2,3}").getValue(context);
// 多維數組不可以初始化
int[][] numbers3 = (int[][]) parser.parseExpression("new int[4][5]").getValue(context);
}
關係運算符
-
使用標準運算符表示法支援關係運算符(等於、不等於、小於、小於或等於、大於和大於或等於)和等價的英文字元縮寫表示。
標準符號 等價英文縮寫 <lt>gt<=le>=ge==eq!=ne/div%mod!not注意特殊的
null比任何比較都小,所以-1 < null為false,0 > null為false,如果數字比較使用0代替null更好。 -
支援 instanceof
小心原始類型,因為它們會立即裝箱到包裝器類型,因此
1 instanceof T(int)的計算結果為false,而1 instanceof T(Integer)的計算結果為true。 -
通過
matches支援正則表達式
/**
* 關係運算符
*/
@Test
public void test() {
// true
boolean trueValue = parser.parseExpression("2 == 2").getValue(Boolean.class);
// false
boolean falseValue = parser.parseExpression("2 < -5.0").getValue(Boolean.class);
// false
boolean falseValue2 = parser.parseExpression("2 gt -5.0").getValue(Boolean.class);
// true
boolean trueValue2 = parser.parseExpression("'black' < 'block'").getValue(Boolean.class);
// null 比任何比較數小
// true
Boolean value = parser.parseExpression("100 > null").getValue(boolean.class);
// false
Boolean value2 = parser.parseExpression("-1 < null").getValue(boolean.class);
System.out.println(value);
System.out.println(value2);
// instanceof 支援
// false
Boolean aBoolean = parser.parseExpression("'xxx' instanceof T(Integer)").getValue(Boolean.class);
System.out.println(aBoolean);
// 支援正則表達式 matches
// true
Boolean match = parser.parseExpression(
"'5.00' matches '^-?\\d+(\\.\\d{2})?$'").getValue(Boolean.class);
// false
Boolean notMatch = parser.parseExpression(
"'5.0067' matches '^-?\\d+(\\.\\d{2})?$'").getValue(Boolean.class);
System.out.println(match);
System.out.println(notMatch);
}
邏輯運算符
支援標準符號和英文字元縮寫:
and(&&)or(||)not(!)
/**
* 邏輯運算符
*/
@Test
public void test8() {
Society societyContext = new Society();
// -- AND --
// false
boolean falseValue = parser.parseExpression("true and false").getValue(Boolean.class);
// true
String expression = "isMember('Nikola Tesla') and isMember('Mihajlo Pupin')";
boolean trueValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- OR --
// true
boolean trueValue2 = parser.parseExpression("true or false").getValue(Boolean.class);
// true
expression = "isMember('Nikola Tesla') or isMember('Albert Einstein')";
boolean trueValue3 = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- NOT --
// false
boolean falseValue2 = parser.parseExpression("!true").getValue(Boolean.class);
// -- AND and NOT --
expression = "isMember('Nikola Tesla') and !isMember('Mihajlo Pupin')";
boolean falseValue3 = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
}
數學運算符
可以對數字和字元串使用加法運算符,字元串只支援”+”。
/**
* 數學運算符
*/
@Test
public void test9(){
// Addition
int two = parser.parseExpression("1 + 1").getValue(Integer.class); // 2
String testString = parser.parseExpression(
"'test' + ' ' + 'string'").getValue(String.class); // 'test string'
// Subtraction
int four = parser.parseExpression("1 - -3").getValue(Integer.class); // 4
double d = parser.parseExpression("1000.00 - 1e4").getValue(Double.class); // -9000
// Multiplication
int six = parser.parseExpression("-2 * -3").getValue(Integer.class); // 6
double twentyFour = parser.parseExpression("2.0 * 3e0 * 4").getValue(Double.class); // 24.0
// Division
int minusTwo = parser.parseExpression("6 / -3").getValue(Integer.class); // -2
double one = parser.parseExpression("8.0 / 4e0 / 2").getValue(Double.class); // 1.0
// Modulus
int three = parser.parseExpression("7 % 4").getValue(Integer.class); // 3
int value = parser.parseExpression("8 / 5 % 2").getValue(Integer.class); // 1
int minusTwentyOne = parser.parseExpression("1+2-3*8").getValue(Integer.class); // -21
}
賦值操作符
賦值運算符 =用於設置屬性。通常在對 setValue 的調用中完成,但也可以在對 getValue 的調用中完成
/**
* 賦值操作
*/
@Test
public void test(){
Inventor inventor = new Inventor();
EvaluationContext context = SimpleEvaluationContext.forReadWriteDataBinding().build();
// setValue 中
parser.parseExpression("Name").setValue(context, inventor, "xxx");
// 等價於在 getValue 賦值
String name = parser.parseExpression(
"Name = 'xxx'").getValue(context, inventor, String.class);
System.out.println(name); // xxx
}
三目運算與 Elvis 操作符
三元運算符表示執行 if-then-else 條件邏輯。
parser.parseExpression("name != null ? name : 'null name'").
使用三目運算符語法,通常必須重複一個變數兩次如上面的name。Elvis 運算符是三元運算符語法的縮寫,借鑒了Groovy 語言的語法。
parser.parseExpression("name?:'null name'")
為什麼
?:叫Elvis操作符 ? 之前挺納悶的,後來發現是與美國搖滾歌星Elvis(貓王)的髮型相似而得名。
案例如下:
/**
* 三目運算和簡化
*/
@Test
public void test17(){
Inventor inventor = new Inventor("not null name", "");
String name = (String) parser.parseExpression("name != null ? name : 'null name'").getValue(inventor);
System.out.println("三目:" + name);
// 使用 Elvis運算符
name = (String) parser.parseExpression("name?:'null name'").getValue(inventor);
System.out.println("Elvis運算符:" + name);
}
嵌套屬性安全訪問?.
多級屬性訪問如國家城市城鎮nation.city.town三級訪問,如果中間的 city是null則會拋出 NullPointerException 異常。為了避免這種情況的異常,SpEL借鑒了Groovy的語法?.,如果中間屬性為null不會拋出異常而是返回null。
/**
* 多級屬性安全訪問
*/
@Test
public void test18(){
Inventor inventor = new Inventor("xx", "oo");
inventor.setPlaceOfBirth(new PlaceOfBirth("北京", "中國"));
// 正常訪問
String city = parser.parseExpression("PlaceOfBirth?.city").getValue(context, inventor, String.class);
System.out.println(city); // 北京
// placeOfBirth為null
inventor.setPlaceOfBirth(null);
String city1 = parser.parseExpression("PlaceOfBirth?.city").getValue(context, inventor, String.class);
System.out.println(city1); // null
// 非安全訪問 異常
String city3 = parser.parseExpression("PlaceOfBirth.city").getValue(context, inventor, String.class);
System.out.println(city3); // 拋出異常
}
方法調用
使用典型的 Java 編程語法來調用方法。可以在字面上調用方法。還支援可變參數。
/**
* 方法調用
*/
@Test
public void test6(){
String bc = parser.parseExpression("'abc'.substring(1, 3)").getValue(String.class);
System.out.println(bc);
// bc
Society societyContext = new Society();
// 傳遞參數
boolean isMember = parser.parseExpression("isMember('Mihajlo Pupin')").getValue(
societyContext, Boolean.class);
System.out.println(isMember);
// false
}
構造方法new
使用 new 運算符調用構造函數。對除原始類型(int、float 等)和 String 之外的所有類型使用完全限定的類名。
/**
* new 調用構造方法
*/
@Test
public void test12(){
Inventor value =
parser.parseExpression("new com.crab.spring.ioc.demo20.Inventor('ooo','xxx')").getValue(Inventor.class);
System.out.println(value.getName() + " " + value.getNationality()); // ooo xxx
String value1 = parser.parseExpression("new String('xxxxoo')").getValue(String.class);
System.out.println(value1); // xxxxoo
}
類類型T
使用特殊的 T 運算符指定 java.lang.Class 的實例(類型)。
類中的靜態變數、靜態方法屬於Class, 可以通過T(xxx).xxx調用。
@Test
public void test11(){
// 1 獲取類的Class java.lang包下的類可以不指定全路徑
Class value = parser.parseExpression("T(String)").getValue(Class.class);
System.out.println(value);
// 2 獲取類的Class 非java.lang包下的類必須指定全路徑
Class dateValue = parser.parseExpression("T(java.util.Date)").getValue(Class.class);
System.out.println(dateValue);
// 3 類中的靜態變數 靜態方法屬於Class 通過T(xxx)調用
boolean trueValue = parser.parseExpression(
"T(java.math.RoundingMode).CEILING < T(java.math.RoundingMode).FLOOR")
.getValue(Boolean.class); // true
System.out.println(trueValue);
Long longValue = parser.parseExpression("T(Long).parseLong('9999')").getValue(Long.class);
System.out.println(longValue);// 9999
}
表達式模板 #{}
表達式模板允許將文字文本與一個或多個評估塊混合。每個評估塊都由前綴和後綴字元分隔,默認是#{ }。支援實現介面ParserContext自定義前後綴。
調用parseExpression()時指定 ParserContext參數如new TemplateParserContext()
/**
* 表達式模板 #{}
*/
@Test
public void test19() {
String randomStr = parser.parseExpression("隨機數字是: #{T(java.lang.Math).random()}", new TemplateParserContext())
.getValue(String.class);
System.out.println(randomStr);
}
定義和使用變數
可以使用#variableName 語法來引用表達式中的變數。通過在 EvaluationContext 實現上使用 setVariable 方法設置變數。
/**
* 變數 #
*/
@Test
public void test13() {
Inventor inventor = new Inventor("xxx", "xxx");
SimpleEvaluationContext context = SimpleEvaluationContext.forReadWriteDataBinding().build();
context.setVariable("newName", "new ooo");
// 使用預先的變數賦值 Name 屬性
parser.parseExpression("Name = #newName").getValue(context, inventor);
System.out.println(inventor.getName()); // new ooo
}
#this 和 #root 變數
#this 變數始終被定義並引用當前評估對象(針對那些非限定引用被解析)。
#root 變數始終被定義並引用根上下文對象。
註冊和使用自定義方法
函數可以當做一種變數來註冊和使用的。2種方式註冊:
- 按變數設置方式
EvaluationContext#setVariable(String name, @Nullable Object value) - 按明確的方法設置方式
StandardEvaluationContext#public void registerFunction(String name, Method method),其實底下也是按照變數處理。
/**
* 方法註冊和使用
*/
@Test
public void test20() throws NoSuchMethodException {
// 註冊 org.springframework.util.StringUtils.startsWithIgnoreCase(String str,String prefix)
Method method = StringUtils.class.getDeclaredMethod("startsWithIgnoreCase",String.class,String.class);
// 方式1 變數方式
SimpleEvaluationContext simpleEvaluationContext = SimpleEvaluationContext.forReadOnlyDataBinding().build();
simpleEvaluationContext.setVariable("startsWithIgnoreCase" ,method);
Boolean startWith = parser.parseExpression("#startsWithIgnoreCase('123', '111')").getValue(simpleEvaluationContext,
Boolean.class);
System.out.println("方式1: " + startWith);
// 方式2 明確方法方式
StandardEvaluationContext standardEvaluationContext = new StandardEvaluationContext();
standardEvaluationContext.registerFunction("startsWithIgnoreCase" ,method);
Boolean startWit2 =
parser.parseExpression("#startsWithIgnoreCase('123', '111')").getValue(simpleEvaluationContext,
Boolean.class);
System.out.println("方式2: " + startWit2);
}
bean引用
如果評估上下文已經配置了 bean 解析器,可以使用 @ 符號從表達式中查找 bean。直接看案例。
@Configuration
@ComponentScan
public class BeanReferencesTest {
// 注入一個bean
@Component("myService")
static class MyService{
}
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext =
new AnnotationConfigApplicationContext(BeanReferencesTest.class);
SpelExpressionParser parser = new SpelExpressionParser();
// 使用 StandardEvaluationContext
StandardEvaluationContext standardEvaluationContext = new StandardEvaluationContext();
// 需要注入一個BeanResolver來解析bean引用,此處注入 BeanFactoryResolver
standardEvaluationContext.setBeanResolver(new BeanFactoryResolver(applicationContext));
// 使用 @ 來引用bean
MyService myService = parser.parseExpression("@myService").getValue(standardEvaluationContext, MyService.class);
System.out.println(myService);
}
}
思考下 FactoryBean 如何引用?
Spring bean定義中使用
基於 XML 或基於注釋的配置元數據的 SpEL 表達式來定義 BeanDefinition 實例的語法都是 #{ <expression string> }。
應用程式上下文中的所有 bean 都可以作為具有公共 bean 名稱的預定義變數使用。常用的包括但限於:
- 標準上下文環境
environment,類型為org.springframework.core.env.Environment - JVM系統屬性
systemProperties,類型為Map<String, Object> - 系統環境變數
systemEnvironment,類型為Map<String, Object>
注意: 作為預定義變數的不需要使用 #前綴。
xml 方式
可以使用表達式設置屬性或構造函數參數值,直接上案例。
配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="//www.springframework.org/schema/beans"
xmlns:xsi="//www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="//www.springframework.org/schema/beans //www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="com.crab.spring.ioc.demo20.MyBean" id="myBean">
<!--SpeL調用類靜態方法-->
<property name="randomNumber" value="#{ T(java.lang.Math).random() * 100.0 }"/>
<!--SpeL讀取系統屬性中的用戶名-->
<property name="name" value="#{ systemProperties['user.name']}"/>
</bean>
<!-- 引用別的bean的屬性-->
<bean class="com.crab.spring.ioc.demo20.MyBean" id="myBean2">
<!--@引用bean實例 其實所有注入容器的bean都是預定義變數,不需要@也行-->
<property name="name" value="#{@myBean.randomNumber}"/>
<property name="randomNumber" value="#{myBean.randomNumber}"/>
</bean>
</beans>
測試程式和結果
/**
* xml方式在bean定義中使用SpEL
*/
@Test
public void test() {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("demo20/spring.xml");
Map<String, MyBean> beansOfType = context.getBeansOfType(MyBean.class);
beansOfType.entrySet().forEach(entry -> System.out.println(entry.getKey() + " : " + entry.getValue()));
context.close();
// myBean : MyBean{randomNumber=72.45707551702549, name='dell'}
// myBean2 : MyBean{randomNumber='dell', name='72.45707551702549'}
}
註解方式
要指定默認值,可以將 @Value 注釋放在欄位、方法以及方法或構造函數參數上。直接看案例。
@Component
@ComponentScan
public class MyComponent {
private String language;
@Value("#{ systemProperties['user.language']}")
private String locale;
private String name;
@Value("#{ systemProperties['user.name']}")
public void setName(String name) {
this.name = name;
}
@Autowired
public MyComponent(@Value("#{ systemProperties['user.language']}") String language) {
this.language = language;
}
// ...
}
測試,觀察輸出結果。
@Test
public void test(){
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(MyComponent.class);
MyComponent bean = context.getBean(MyComponent.class);
System.out.println(bean);
// MyComponent{language='zh', locale='zh', name='dell'}
}
總結
本文從原理到實戰案例詳解介紹了SpEL表達式。紙上得來終覺淺,絕知此事要躬行,案例比較多,好好消化。本文也可以作為SpEL使用手冊來使用。
知識分享,轉載請註明出處。學無先後,達者為先!