【讀書筆記】貝葉斯學習
原理
與直接應用貝葉斯公式不同,貝葉斯學習指在當前訓練樣本的基礎上,根據新樣本更新每個模型的後驗概率。貝葉斯深度學習[1]則結合了神經網路的模型表示能力,將神經網路的權重視作服從某分布的隨機變數,而不是固定值;網路的前向傳播,就是從權值分布中抽樣然後計算。
我們將當前所有樣本記為\(\pmb e\),新樣本記為\(X = x\),待估計的參數或目標標籤為\(Y\),那麼學習的目標就是計算後驗概率\(P(Y|X=x,\pmb e)\)。在貝葉斯學習中,模型參數具有分布,因此每個標籤的輸出概率是參數概率(\(P(m|\pmb e)\),給定新舊樣本的後驗概率)與對應輸出概率\(P(Y|m,x)\)的加權和(其實也是條件概率),具體寫為
P(Y|X=x,\pmb e) &= \sum_{m\in M}P(Y,m|x,\pmb e)\\
&=\sum_{m\in M}P(Y|m,x,\pmb e)P(m|x,\pmb e)\\
&=\sum_{m\in M}P(Y|m,x)P(m|\pmb e)
\end{align}
\]
其中最後一步假設了模型已經包含了所有當前樣本的資訊。由於\(P(Y|m,x)\)是一個已知值,只需用貝葉斯公式計算\(P(m|\pmb e)\)
\]
然而,直接求數據分布\(P(\pmb e)\)是不可能的。處理這個有兩種解決思路:
- 擬合後驗分布:用MCMC家族、變分擬合(VI)家族,通過KL散度建立擬合分布與\(P(m|\pmb e)\)後驗概率的差異,根據訓練樣本不斷優化得到擬合結果[1]。
- 省略數據分布:由於分母\(P(\pmb e)\)保證後驗概率求和後為1,因此在獲得分子的表達式後,可以用一個常數代替其概率值。
例題
考慮單個布爾型隨機變數,輸出為True的概率為\(\phi\),為False的概率為\(1-\phi\),根據不同的樣本情況求解\(\phi\)的後驗概率。
根據貝葉斯分布,有\(P(\phi|\pmb e) = P(\pmb e|\phi)P(\phi)/P(\pmb e)\)
考慮i.i.d.獲取\(n_1\)個True樣本,\(n_0\)個False樣本,因此其似然函數為
\]
將未知的先驗分布\(P(\phi)\)設為\([0,1]\)上的均勻分布,歸一化後可得後驗概率如下圖

這個先驗分布為均勻分布的後驗分布又叫做Beta分布,其參數\(\alpha_i=n_i+1\)比樣本個數多一,記為
\]
同樣\(K\)是一個保證積分後為1的歸一化係數。有趣的是最大後驗概率對應的點在\(\frac{n_1}{n_1+n_0}\)處,而這個分布的期望是\(\frac{n_1+1}{n_1+n_0+2}\)(雖然我覺得期望好像沒什麼意義)
進一步的,當參數超過2個時,為Dirichlet分布,記為
\]
其每一維上是一個Beta分布。
優勢
-
當某一類沒有樣本的時候,直接說\(P(Y=False)=0\)是不正確的,只能說此時為0的後驗概率最大,邏輯上是合理的。
-
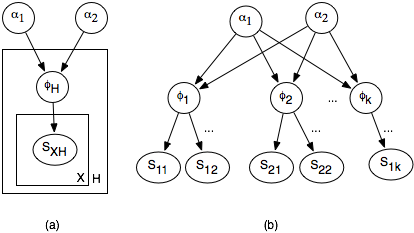
對於複雜的相關關係,可以利用貝葉斯網路表明隱變數之間的關係,進行推斷。

參考鏈接
[1] C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra, 「Weight Uncertainty in Neural Networks,」 arXiv:1505.05424 [cs, stat], May 2015. [Online]. Available: //arxiv.org/abs/1505.05424
【讀書筆記】貝葉斯原理 – 木坑 – 部落格園 (cnblogs.com)


