圖計算 on nLive:Nebula 的圖計算實踐

在 #圖計算 on nLive# 直播活動中,來自 Nebula 研發團隊的 nebula-plato 維護者郝彤和 nebula-algorithm 維護者 Nicole 分別同大家分享了他她眼中的圖計算。
嘉賓們
- 王昌圓:論壇 ID:Nicole,nebula-algorithm 維護者;
- 郝彤:論壇 ID:caton-hpg,nebula-plato 維護者;
先開場的是 nebula-plato 的維護者郝彤。
圖計算之 nebula-plato

nebula-plato 的分享主要由圖計算系統概述、Gemini 圖計算系統介紹、Plato 圖計算系統介紹以及 Nebula 如何同 Plato 集成構成。
圖計算系統
圖的劃分
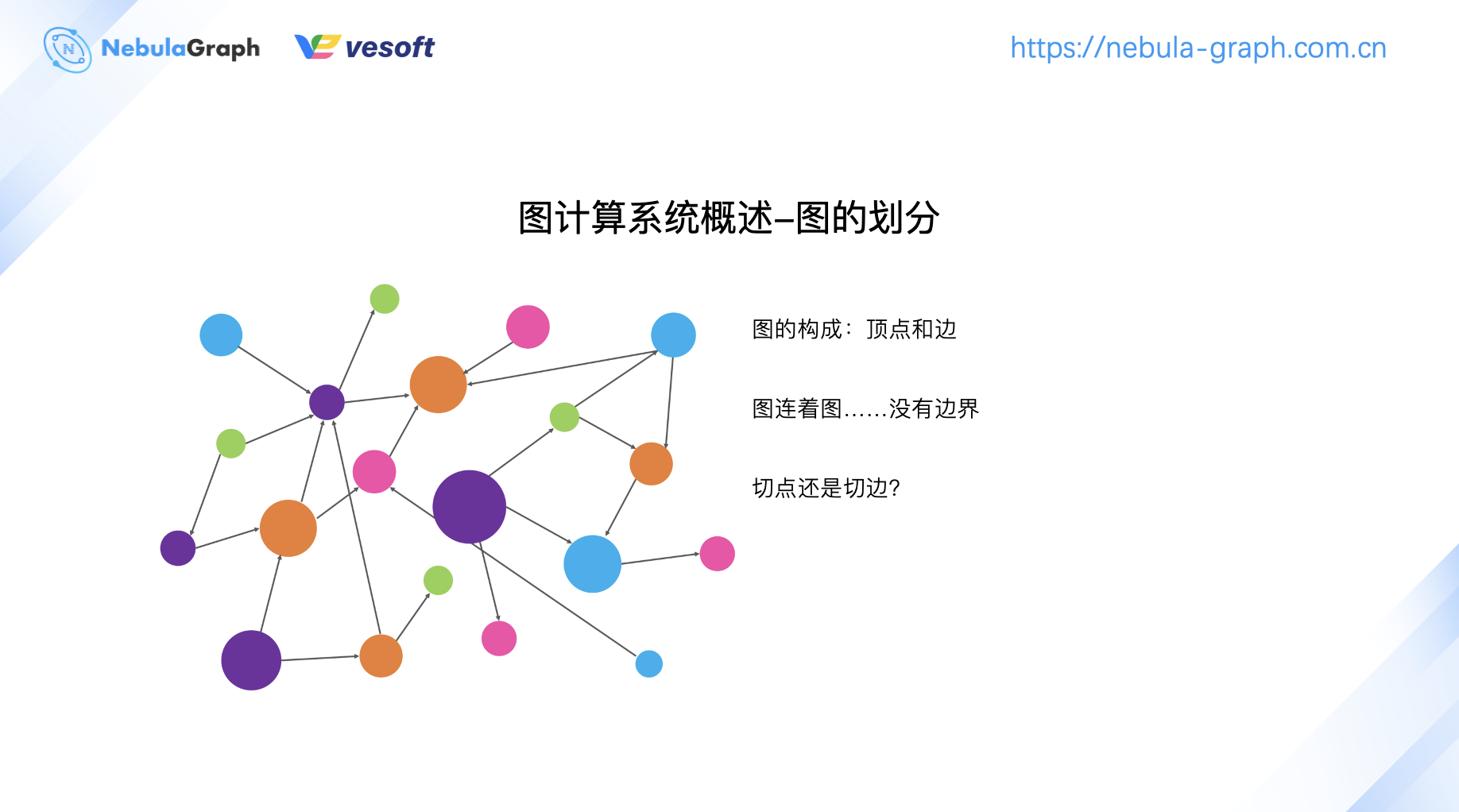
圖計算系統概述部分,著重講解下圖的劃分、分片、存儲方式等內容。
圖自身由頂點和邊構成,而圖結構本身是個發散性結構沒有邊界。要對圖進行切分,必然是切頂點或者是切邊二選一。
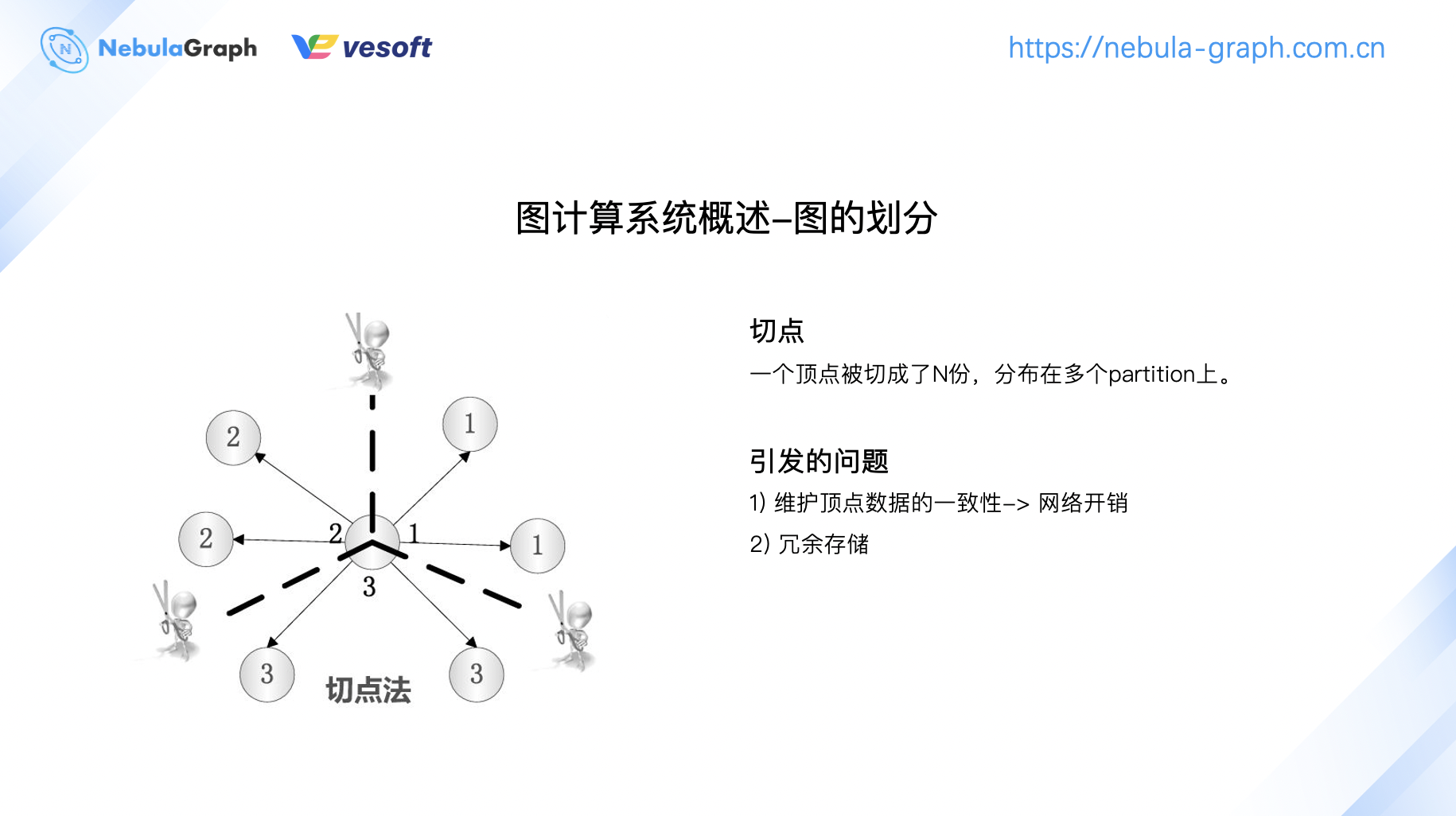
切頂點意味著一個頂點切成多份,每個 partition 上會存儲部分頂點,這樣會引發兩個問題:頂點數據的一致性和網路開銷的問題。此外,切點也存在一個頂點存儲多份帶來的數據冗餘。
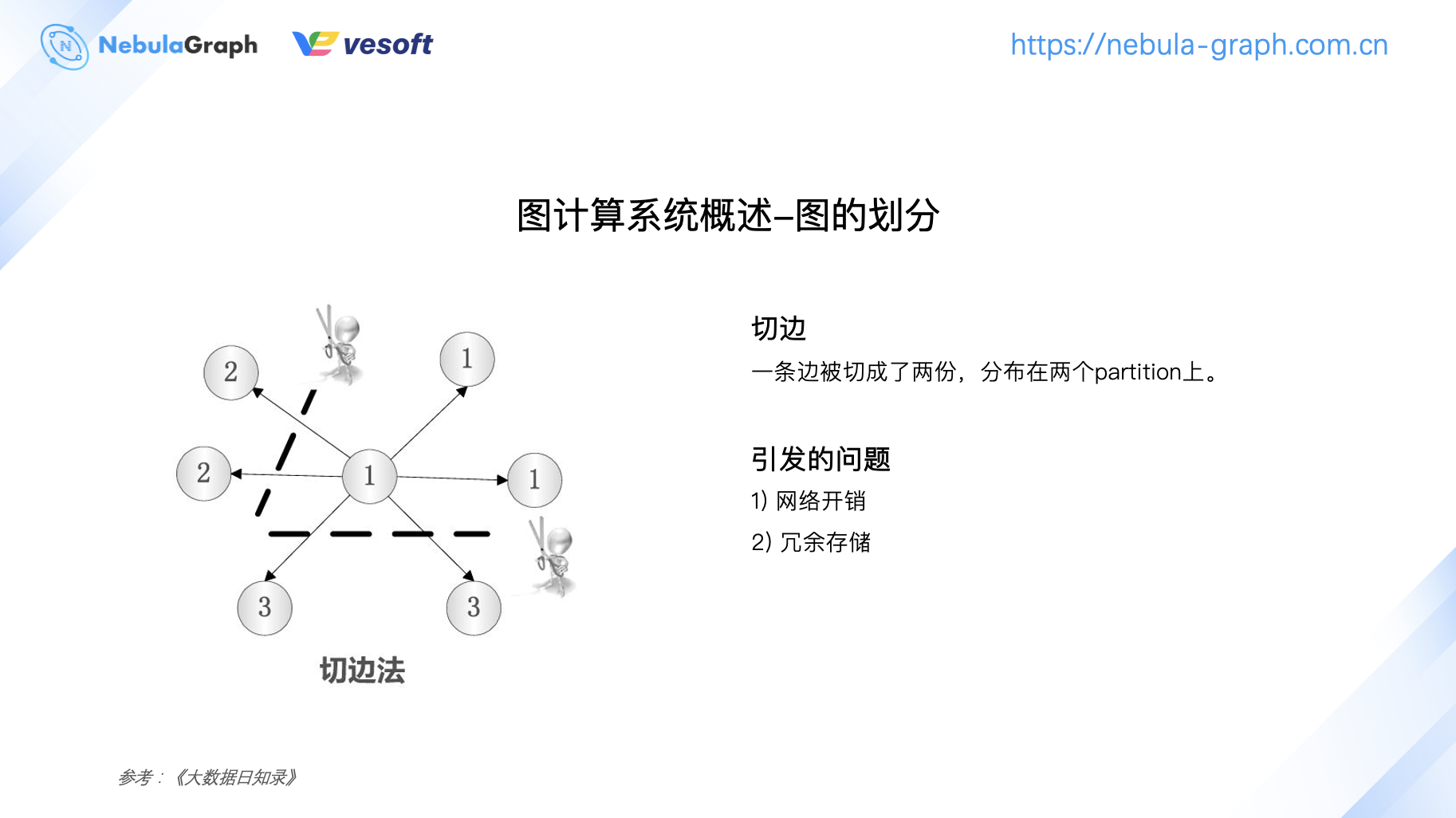
而切邊則一條邊會切成兩份,分別存儲在兩個 partition 上。在計算(迭代計算)過程中就會存在網路開銷。同樣,切邊也會引發數據冗餘帶來的存儲危機。
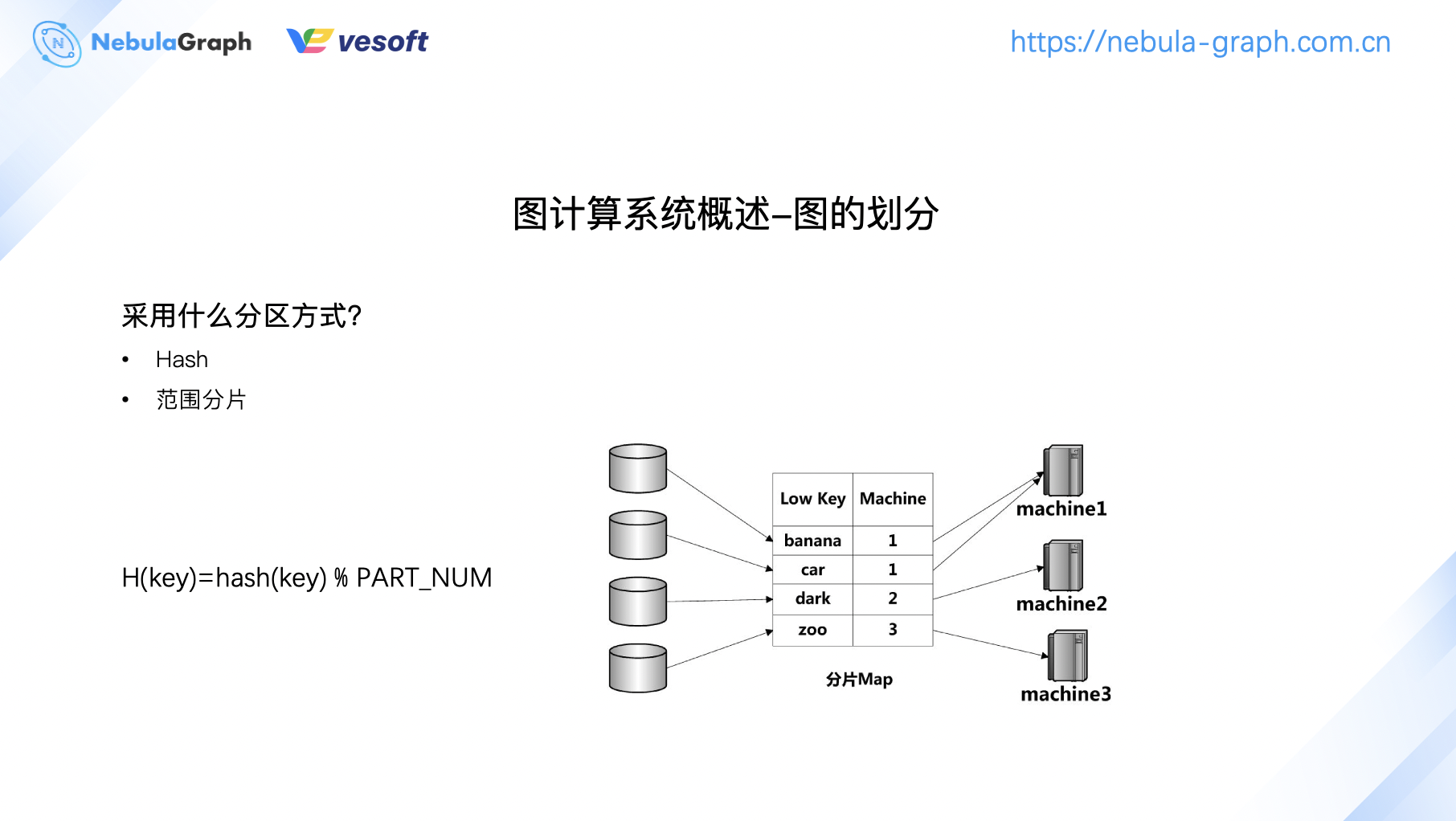
圖的劃分除了有圖數據結構自身的切割問題,還有數據存儲的分區問題。圖數據分區通常有兩種方式,一種是 Hash,還有一種是範圍分片。範圍分片指的是數據劃分為由片鍵值確定的連續範圍,比如說 machine 1 有 bannana、car 等 key,machine 2 有 dark 範圍的 key,按照類似規定分片。
圖存儲的方式
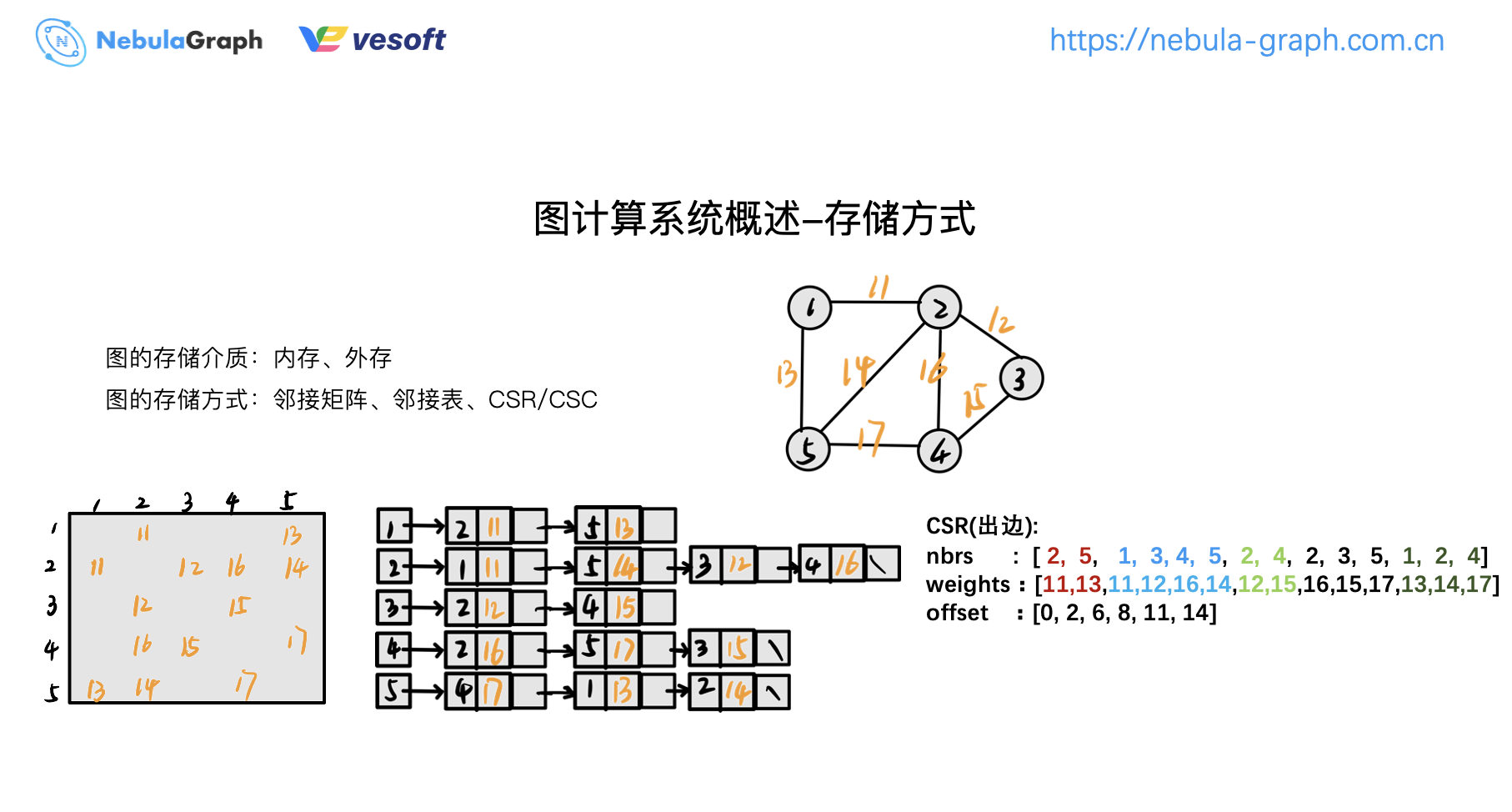
圖計算系統的存儲介質分為記憶體和外存,記憶體方式會把所有數據放記憶體中進行迭代計算;而外存存儲則要不停地去讀寫磁碟,這種效率非常低。目前,主流圖計算系統都是基於記憶體存儲,但記憶體有個缺點,如果記憶體放不下數據會非常麻煩。
圖計算的存儲方式主要有:鄰接矩陣、鄰接表、CSR/CSC,前兩者大家比較熟悉,這裡簡單講下 CSR/CSC。CSR 是壓縮稀疏行,存儲頂點的出邊資訊。舉個例子:
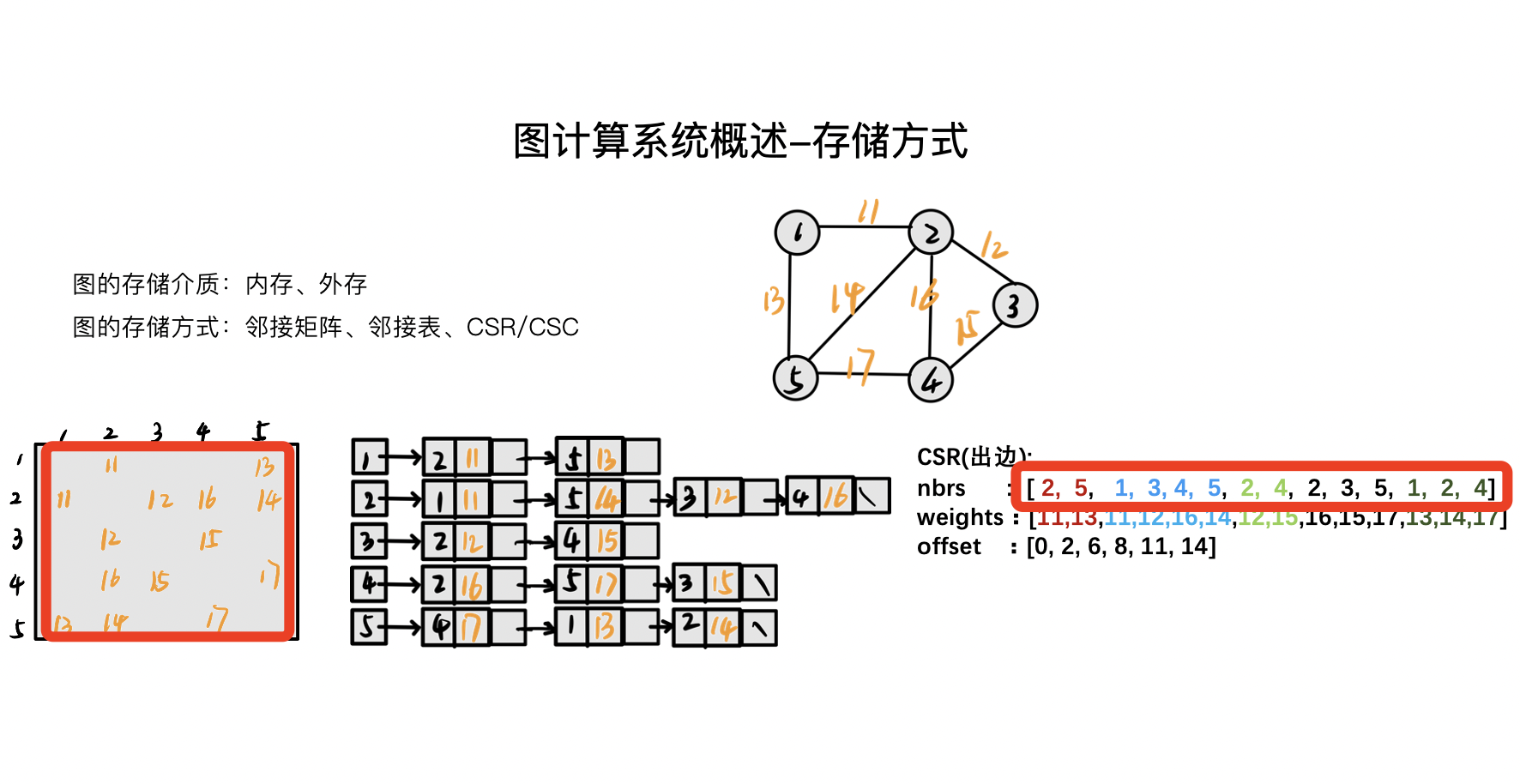
現在我們對這個矩陣(上圖)進行壓縮,只壓存儲中有數據的內容,剔除矩陣中沒有數據的內容,這樣會得到最右邊的這張圖。但是這種情況如何去判斷 2 和 5 是哪個頂點的出邊呢?這裡引入一個欄位 offset。
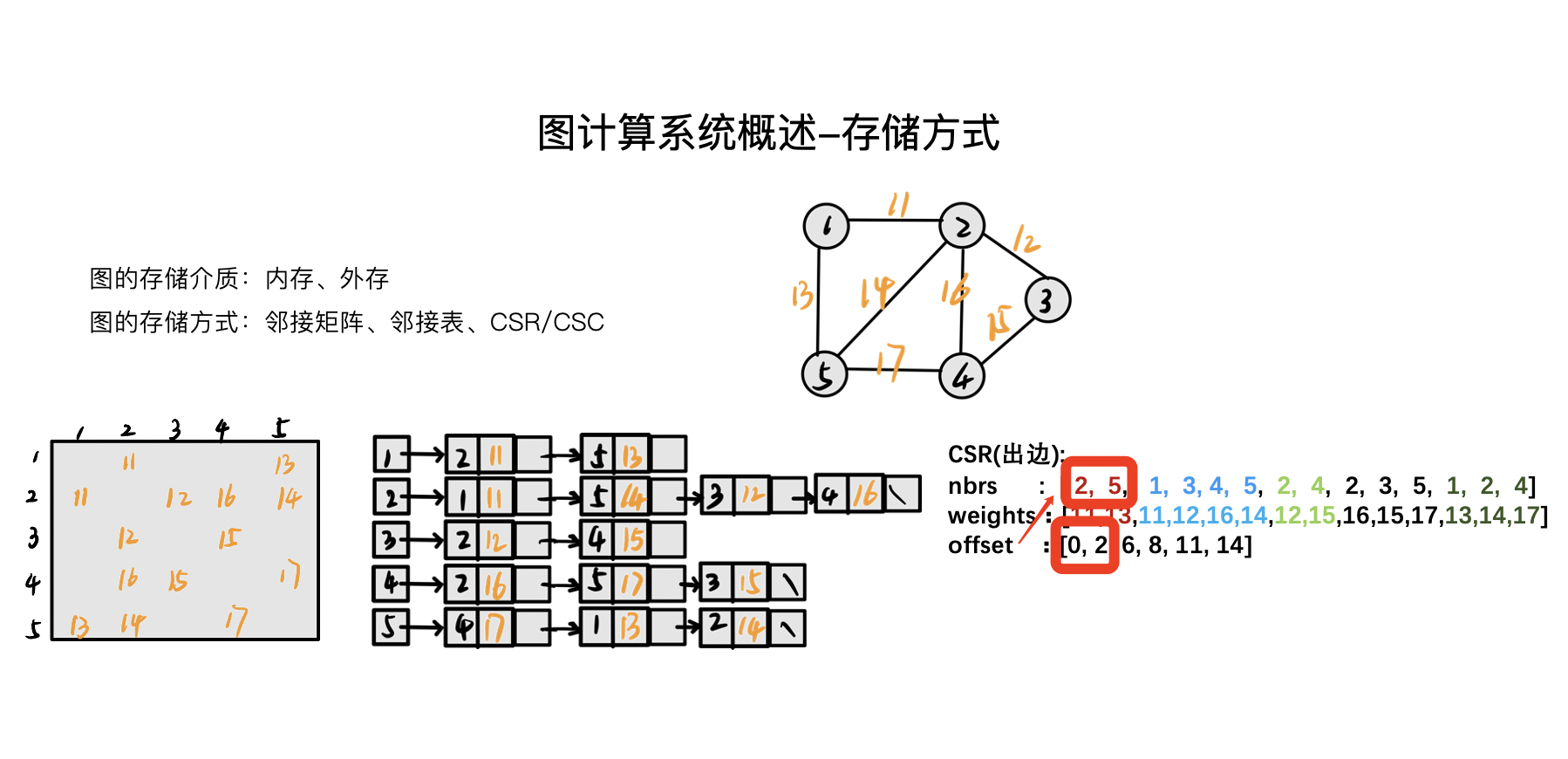
比如說,現在要取頂點 1 的鄰居,頂點 1 在 offset 第一個,那它的鄰居是什麼區段?如上圖,紅色框所示:1 的 offset 是 0~2,但不包括 2,對應的鄰居就是 2 和 5。
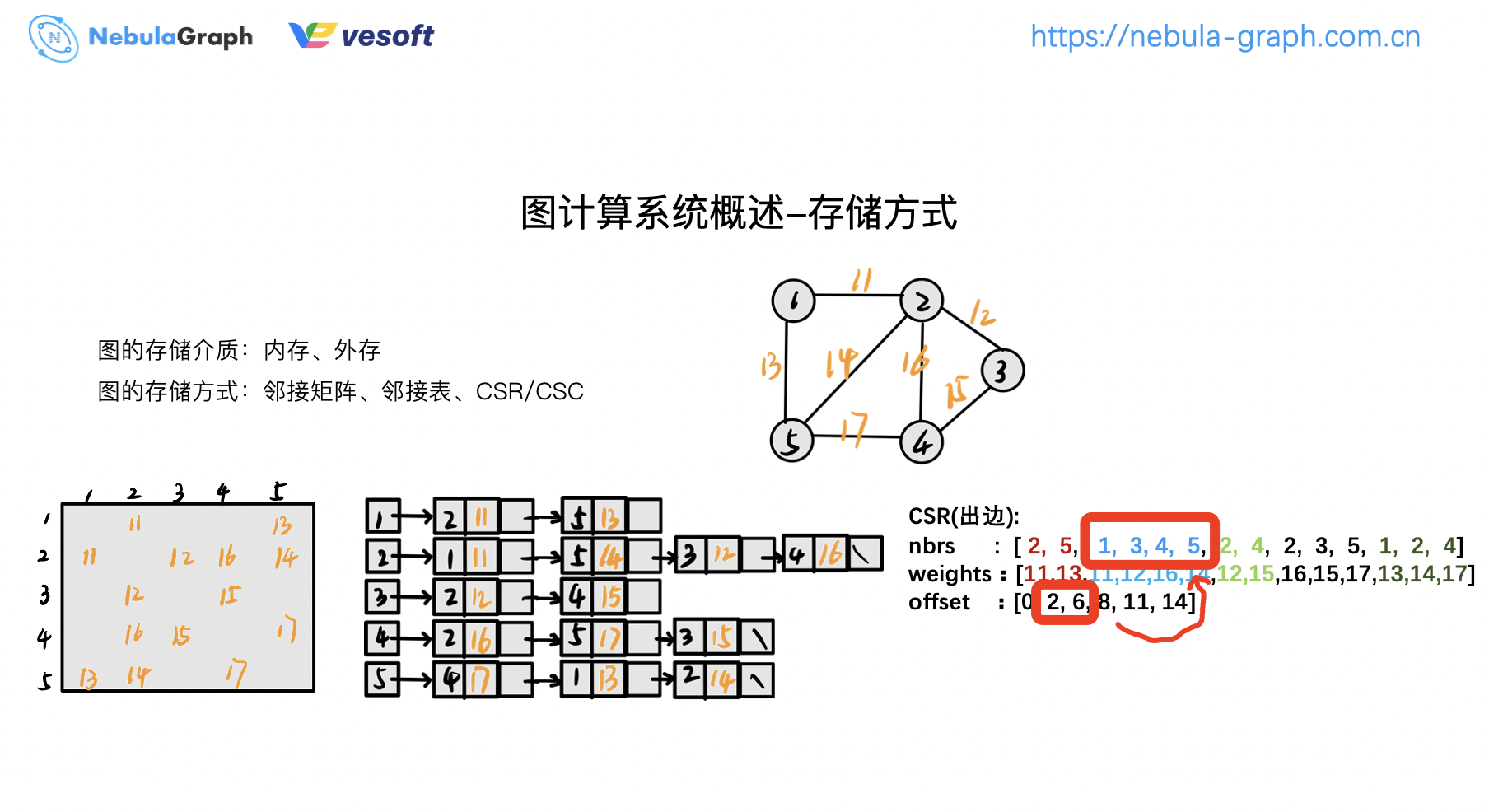
取節點 2 的鄰居,節點 2 的鄰居是範圍是 2~6,這樣對應的鄰居就是 1、3、4、5,這就是 CSR。同理,CSC 為壓縮稀疏列,同 CSR 類似,不過是按照列的方式進行壓縮,它存的是入邊資訊。
圖計算模式
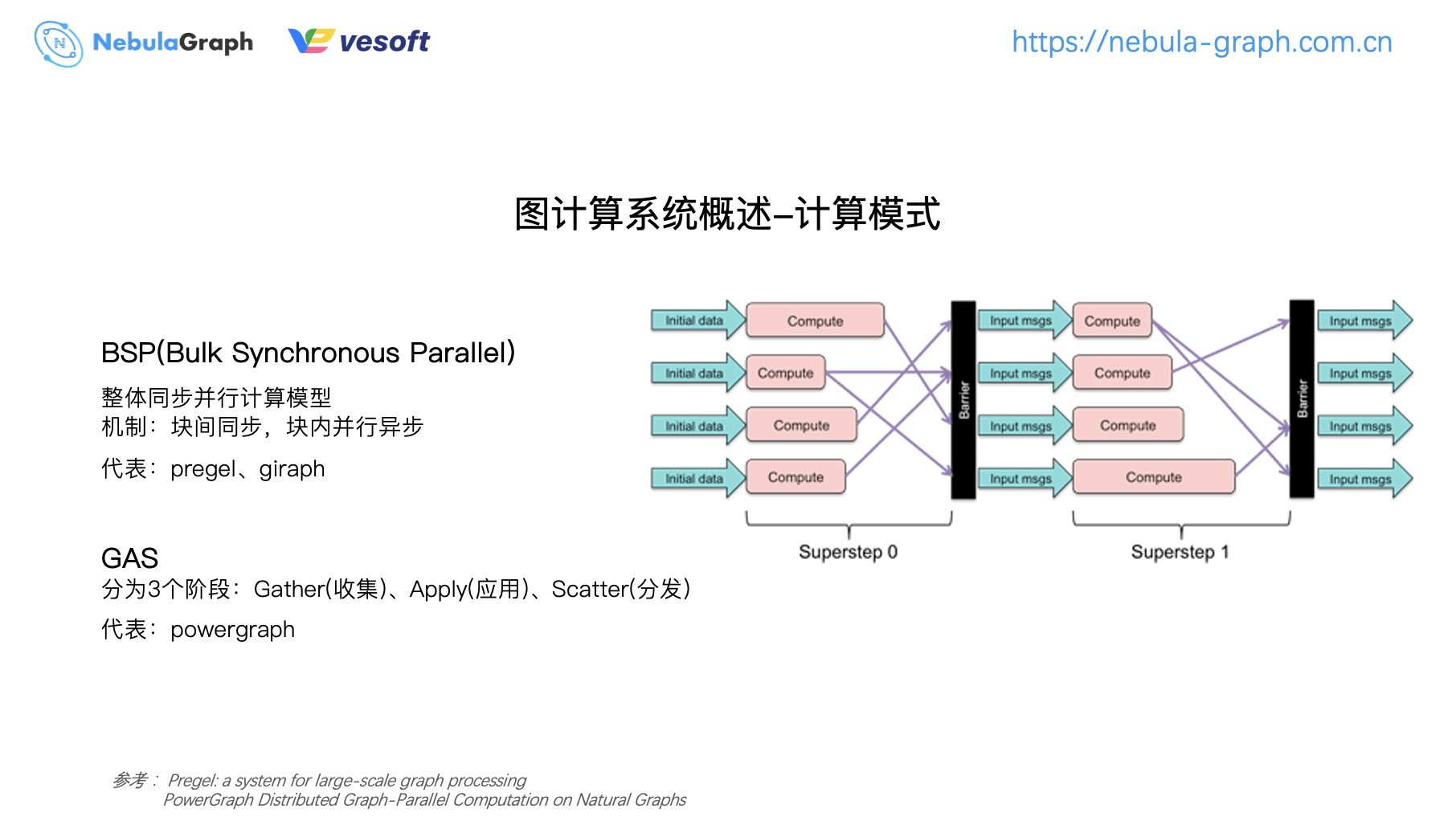
圖計算模式通常有兩種,一種是 BSP(Bulk Synchronous Parallel),一種是 GAS(Gather、Apply、Scatter)。 BSP 是一個整體同步的計算模式,塊內部會進行並行計算,塊與塊之間會進行同步計算。像常見的圖計算框架 Pregel、Giraph 都是採用的 BSP 編程模式。
再來說下 PowerGraph 它才用了 GAS 編程模型,相比 BSP,GAS 則細分成了 Gather 收集、Apply 應用、Scatter 分發等三個階段,每次迭代都會經過這三個階段。在 Gather 階段先收集 1 度鄰居的數據,再在本地進行一次計算(Apply),如果數據有變更將變更的結果 Scatter 分發出去,上面就是 GAS 編程模型的處理過程。
圖計算的同步和非同步
在圖計算系統中,常會見到兩個術語:同步、非同步。同步意味著本輪產生的計算結果,在下一輪迭代生效。而本輪產生的計算結果,在本輪中立即生效則叫做非同步。
非同步方式的好處在於演算法收斂速度特別快,但它有個問題。
因為非同步的計算結果是在當輪立即生效的,所以同節點的不同的執行順序會導致不同的結果。
此外,非同步在並行執行的過程中會存在數據不一致的問題。
圖計算系統的編程模式
圖計算系統編程模型通常也分為兩種,一種是以頂點為中心的編程模型,另外一種是以邊為中心的編程模型。

(圖:以頂點為中心的編程模型)

(圖:以邊為中心的編程模型)
這兩種模式以頂點為中心的編程模型比較常見,以頂點為中心意味著所有的操作對象為頂點,例如上圖的 vertex v 便是一個頂點變數 v,而所有諸如 scatter、gather 之類的操作都是針對這個頂點數據進行。
Gemini 圖計算系統
Gemini 圖計算系統是以計算為中心的分散式圖計算系統,這裡主要說下它的特點:
- CSR/CSC
- 稀疏圖/稠密圖
- push/pull
- master/mirror
- 計算/通訊 協同工作
- 分區方式:chunk-base,並支援 NUMA 結構
Gemini 中文的含義是「雙子座」,在 Gemini 論文中提到的很多技術是成雙成對出現的。不僅在存儲結構上 CSR 和 CSC 成雙成對出現,在圖劃分上也分為了稀疏圖和稠密圖。
稀疏圖採用 push 的方式,可以理解為將自己的數據發送出去,更改他人數據;對於稠密圖,它採用 pull 的方式把 1 度鄰居數據拉過來,更改自己的數據。
此外,Gemini 把頂點分為 master 和 mirror。在計算和通訊方面進行協同工作,以便降低時間提升整體效率。最後是分區方式,採用 chunk-base分區,並支援 NUMA 結構。
下面來舉個例子加速理解:
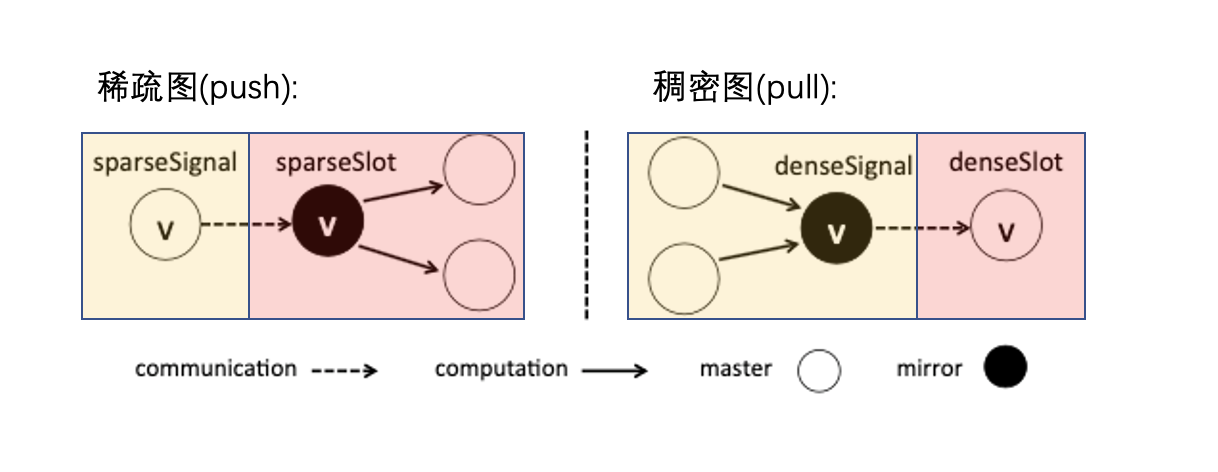
上圖黃色和粉色是 2 個不同的 partition 分區。
- 在稀疏圖的 push 操作時,master 頂點(上圖左圖黃色區域的 v 頂點)會通過網路將數據同步給所有的 mirror 頂點(上圖左圖粉色區域的 v 頂點),mirror 節點執行push,修改它的一度鄰居節點數據。
- 在稠密圖的 pull 操作中, mirror 頂點(上圖右圖黃色區域的 v 節點)會拉取它 一度鄰居的數據,再通過網路同步給它的 master 頂點(上圖右圖粉色區域的 v 節點),修改它自己的數據。
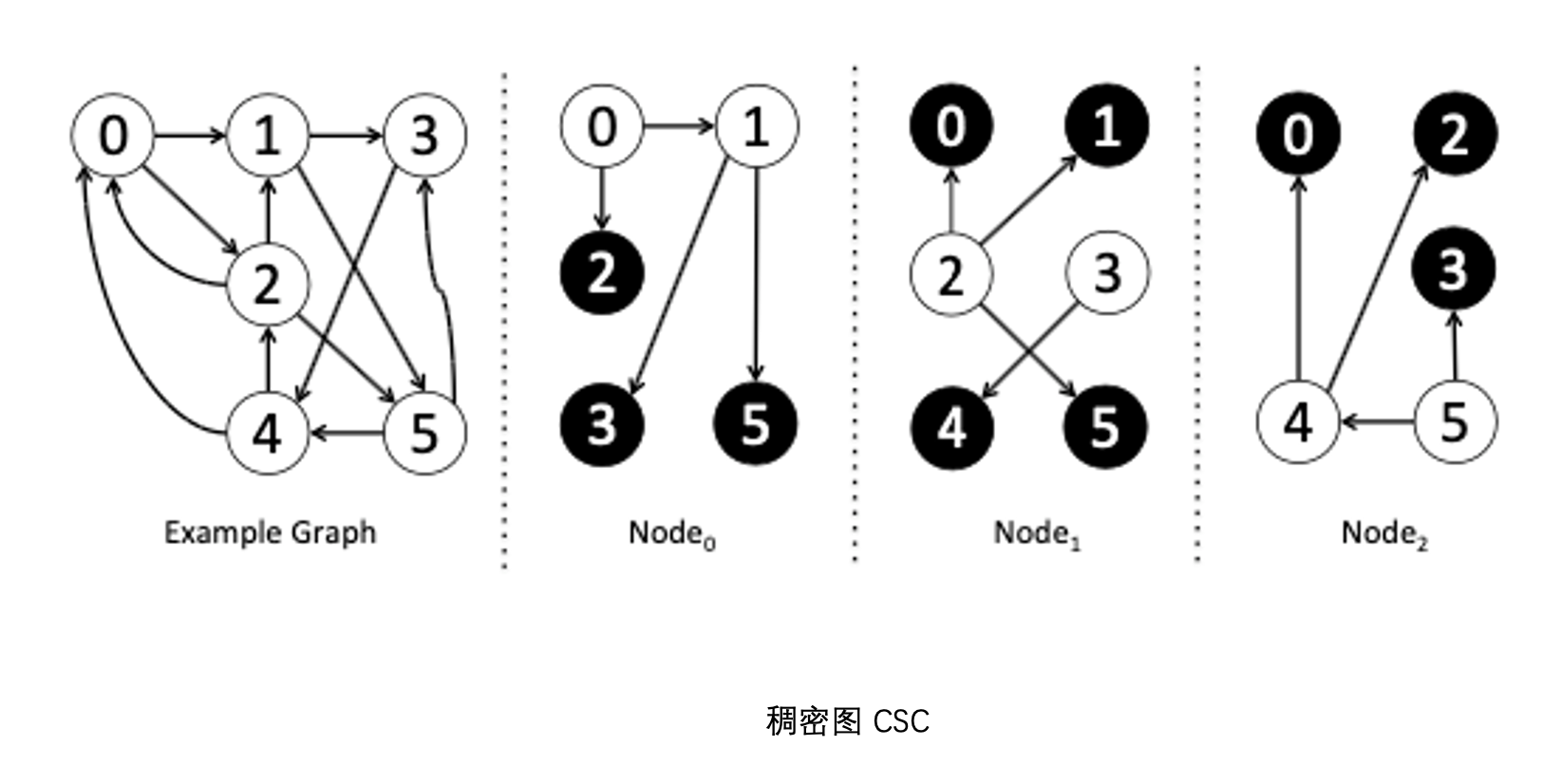
結合上圖例子深入理解下,這是一個稠密圖,採用 CSC 存儲方式。這裡上圖左側 Example Graph 中的頂點 0 要進行 pull 操作,這時候 0 的 mirror 節點(Node1 和 Node2)會拉取它的 一度鄰居數據,然後同步給 master(Node0)更改自己的數據。
上述便是稠密圖 0 對應的 pull 操作。
接著來簡單介紹下 Plato。
圖計算系統 Plato 介紹

Plato 是騰訊開源的圖計算框架,這裡著重講下 Plato 和 Gemini 的不同點。
上面我們科普過 Gemini 的 pull/push 方式:csr: part_by_dst 適用於 push 模式以及csc: part_by_src 適用於 pull 模式。相比較 Gemini,Plato 在它 pull 和 push 方式基礎上新增了適用於 pull 模式的 csr: part_by_src 和適用於 push 模式的 csc: part_by_dst。這是 Plato 在分區上同 Gemini 的不同,當然 Plato 還支援 Hash 的分區方式。
在編碼方面,Gemini 是支援 int 類型的頂點 ID 並不支援 String ID,但 Plato 支援 String ID 的編碼。Plato 通過對String ID進行 Hash 處理計算出對應的機器,將 String ID 發送給對應機器進行編碼再傳回進行編碼數據聚合。在一個大的 map 映射之後,每台機器都能拿到一個全局的 String ID 編碼。在系統計算結束的時候需要將結果輸出,這時候全局編碼就可以在本地將 int ID 轉回 String ID。這便是 Plato String ID 編碼的原理。
Nebula Graph 與 Plato 的集成
首先 Nebula 優化了 String ID 的編碼,上面說到的全局編碼映射是非常消耗記憶體的,尤其是在生產環境上。在 Nebula 這邊每台機器只保存部分的 String ID,在結果輸出時由對應的機器進行 Decode 再寫入磁碟。
此外還支援了 Nebula Graph 的讀取和寫入,可以通過 scan 介面來讀取數據,再通過 nGQL 寫回到 Nebula Graph 中。
在演算法上面,Nebula Graph 也進行了補充,sssp 單源最短路徑、apsp 全對最短路徑、jaccard similary 相似度、triangle count 三角計數、clustering coefficent 聚集係數等演算法。
我們的 Plato 實踐文章也將會在近期發布,會有更詳細的集成介紹。
圖計算之 nebula-algorithm
在開始 nebula-algorithm 介紹之前,先貼一個它的開源地址://github.com/vesoft-inc/nebula-algorithm。
Nebula 圖計算
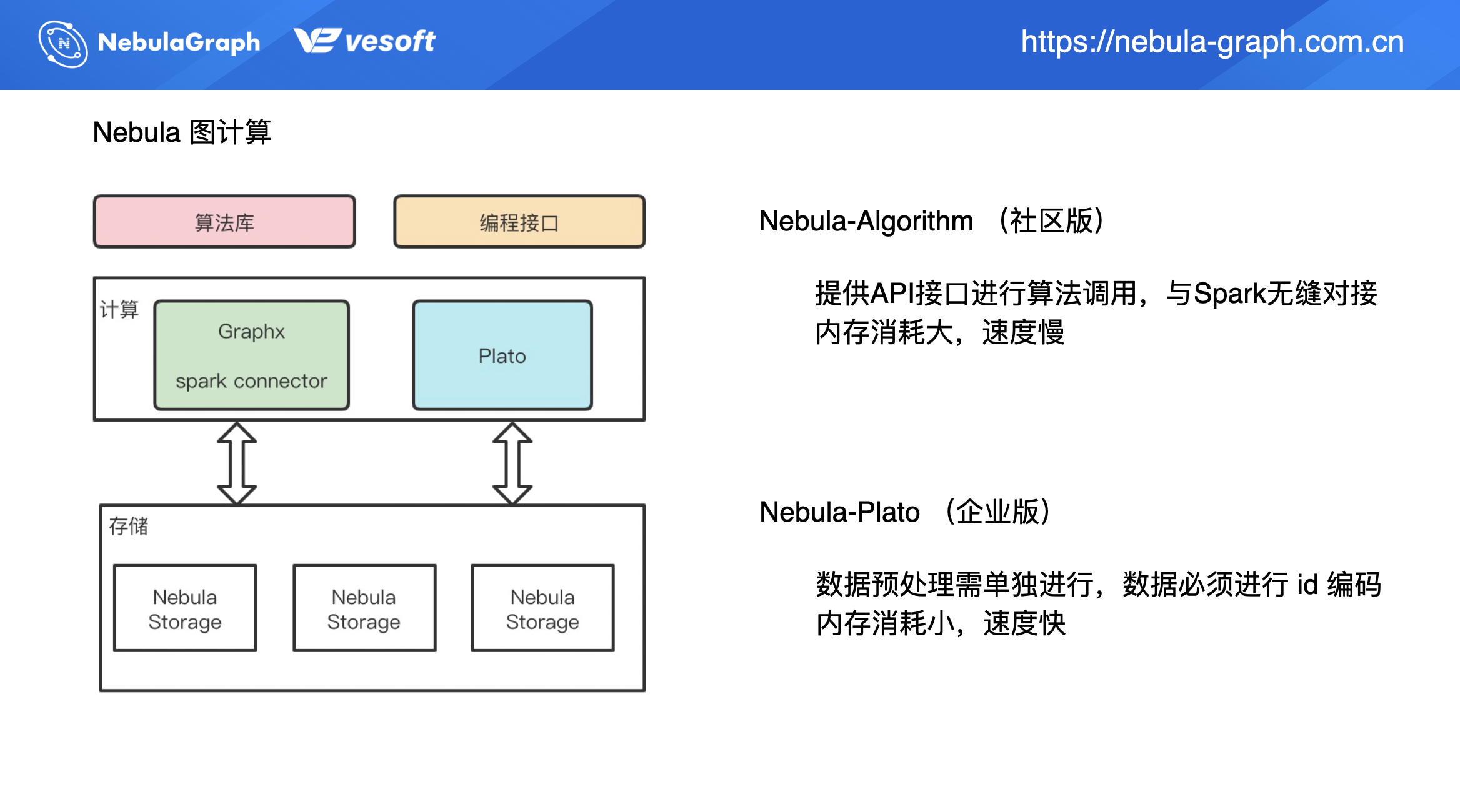
目前 Nebula 圖計算集成了兩種不同圖計算框架,共有 2 款產品:nebula-algorithm 和 nebula-plato。
nebula-algorithm 是社區版本,同 nebula-plato 的不同之處在於,nebula-algorithm 提供了 API 介面來進行演算法調用,最大的優勢在於集成了 [GraphX](//spark.apache.org/docs/latest/graphx-programming-guide.html),可無縫對接 Spark 生態。正是由於 nebula-algorithm 基於 GraphX 實現,所以底層的數據結構是 RDD 抽象,在計算過程中會有很大的記憶體消耗,相對的速度會比較慢。
nebula-plato 上面介紹過,數據內部要進行 ID 編碼映射,即便是 int ID,但如果不是從 0 開始遞增,都需要進行 ID 編碼。nebula-plato 的優勢就是記憶體消耗是比較小,所以它跑演算法時,在相同數據和資源情況下,nebula-plato 速度是相對比較快的。
上圖左側是是 nebula-algorithm 和 nebula-plato 的架構,二者皆從存儲層 Nebula Storage 中拉取數據。GraphX 這邊(nebula-algorithm)主要是通過 Spark Connector 來拉取存儲數據,寫入也是通過 Spark Connector。
nebula-algorithm 使用方式
jar 包提交
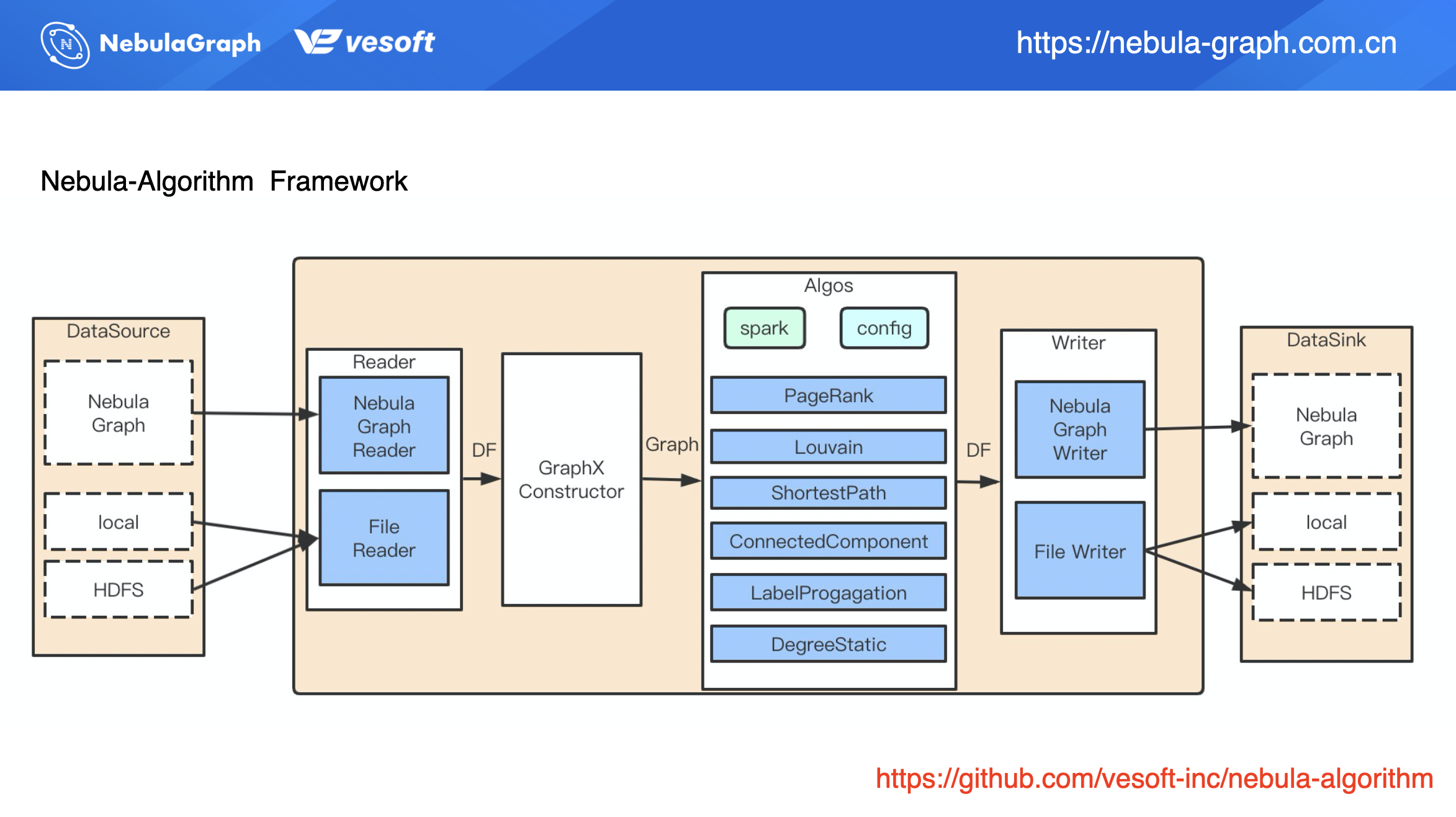
nebula-algorithm 目前是提供了兩種使用方式,一種是通過直接提交 jar 包,另外一種是通過調用 API 方式。
通過 jar 包的方式整個流程如上圖所示:通過配置文件配置數據來源,目前配置文件數據源支援 Nebula Graph、HDFS 上 CSV 文件以及本地文件。數據讀取後被構造成一個 GraphX 的圖,該圖再調用** nebula-algorithm **的演算法庫。演算法執行完成後會得到一個演算法結果的 data frame(DF),其實是一張二維表,基於這張二維表,Spark Connector 再寫入數據。這裡的寫入可以把結果寫回到圖資料庫,也可以寫入到 HDFS 上。
API 調用
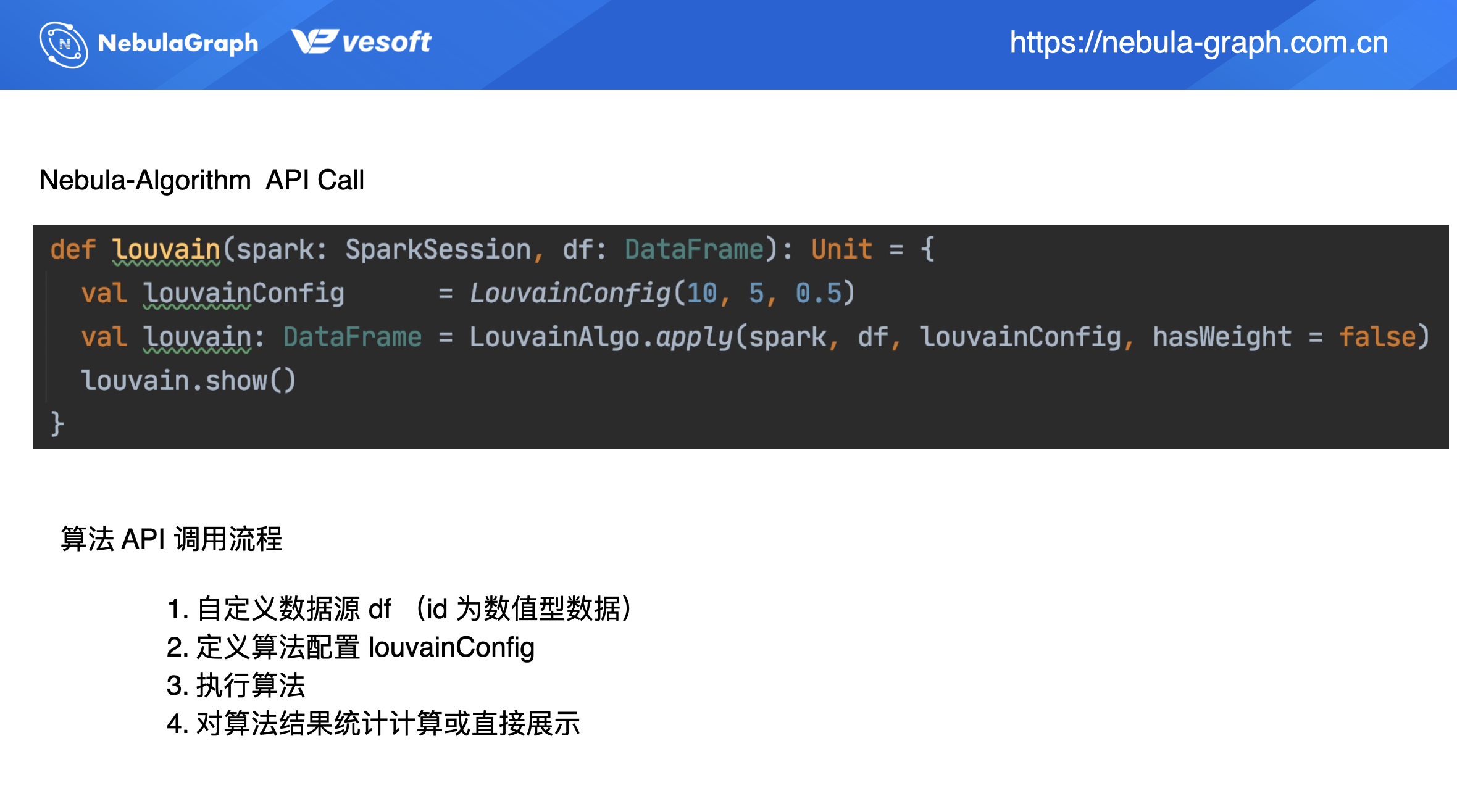
更推薦大家通過 API 調用的方式。像上面通過 jar 包形式在後面的數據寫入部分是不處理數據的。而採用 API 調用方式,在數據寫入部分可進行數據預處理,或是對演算法結果進行統計分析。
API 調用的流程如上圖所示,主要分為 4 步:
- 自定義數據源 df(id 為數值型數據)
- 定義演算法配置 louvainConfig
- 執行演算法
- 對演算法結果統計計算或直接展示
上圖的程式碼部分則為具體的調用示例。先定義個 Spark 入口:SparkSession,再通過 Spark 讀取數據源 df,這種形式豐富了數據源,它不局限於讀取 HDFS 上的 CSV,也支援讀取 HBase 或者 Hive 數據。上述示例適用於頂點 ID 為數值類型的圖數據,String 類型的 ID 在後面介紹。
回到數據讀取之後的操作,數據讀取之後將進行演算法配置。上圖示例調用 Louvain 演算法,需要配置下 LouvainConfig 參數資訊,即 Louvain 演算法所需的參數,比如迭代次數、閾值等等。
演算法執行完之後你可以自定義下一步操作結果統計分析或者是結果展示,上面示例為直接展示結果 louvain.show()。
ID Mapping 映射原理與實現
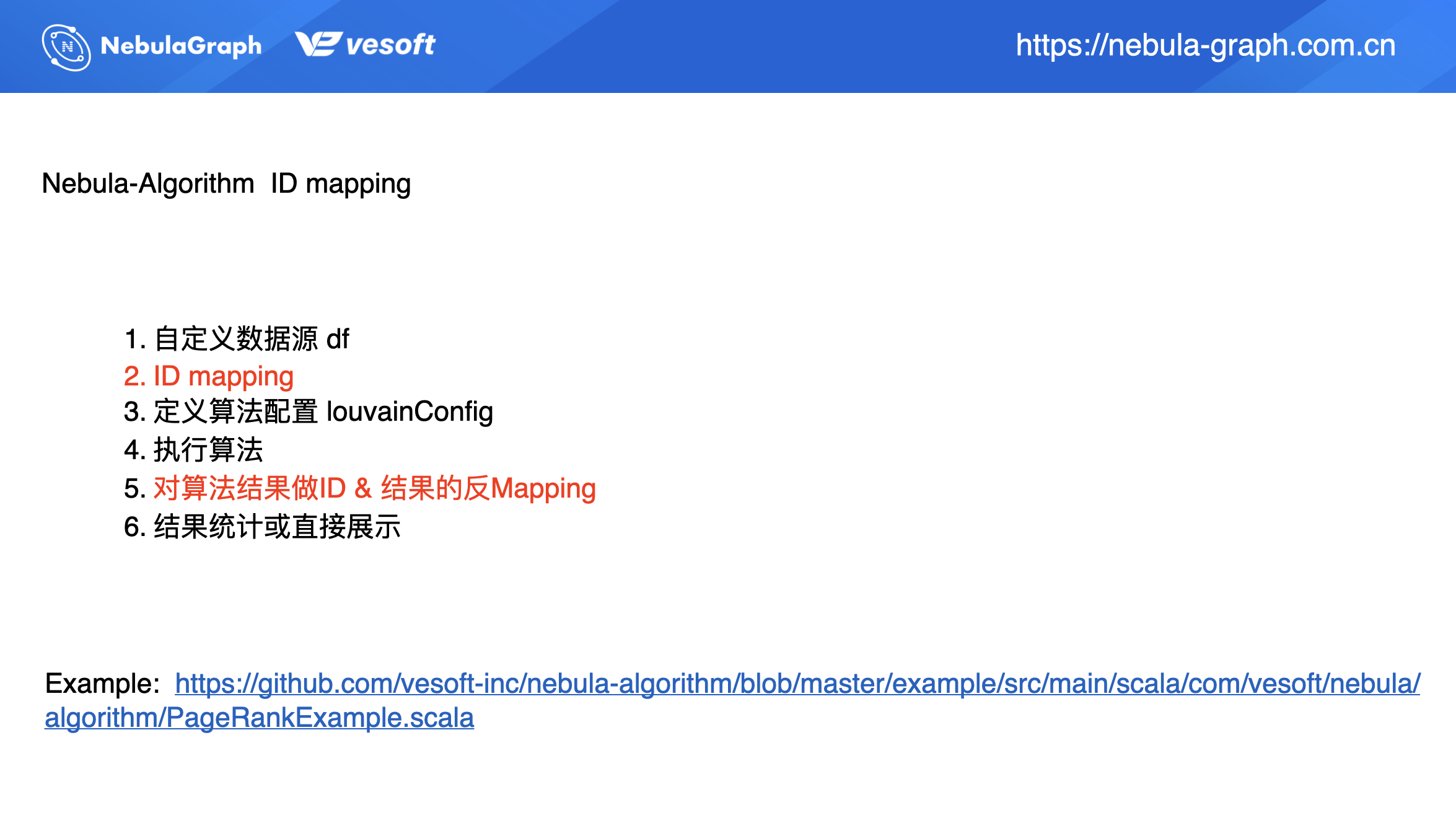
再來介紹下 ID 映射,String ID 的處理。
熟悉 GraphX 的小夥伴可能知道它是不支援 String ID 的,當我們的數據源 ID 是個 String 該如何處理呢?
同社區用戶 GitHub issue 和論壇的日常交流中,許多用戶都提到了這個問題。這裡給出一個程式碼示例://github.com/vesoft-inc/nebula-algorithm/blob/master/example/src/main/scala/com/vesoft/nebula/algorithm/PageRankExample.scala
從上面的流程圖上,我們可以看到其實同之前調用流程相同,只是多兩步:ID Mapping 和 對結算結果做 ID & 結果的反 Mapping。因為演算法運行結果是數值型,所以需要做一步反 Mapping 操作使得結果轉化為 String 類型。
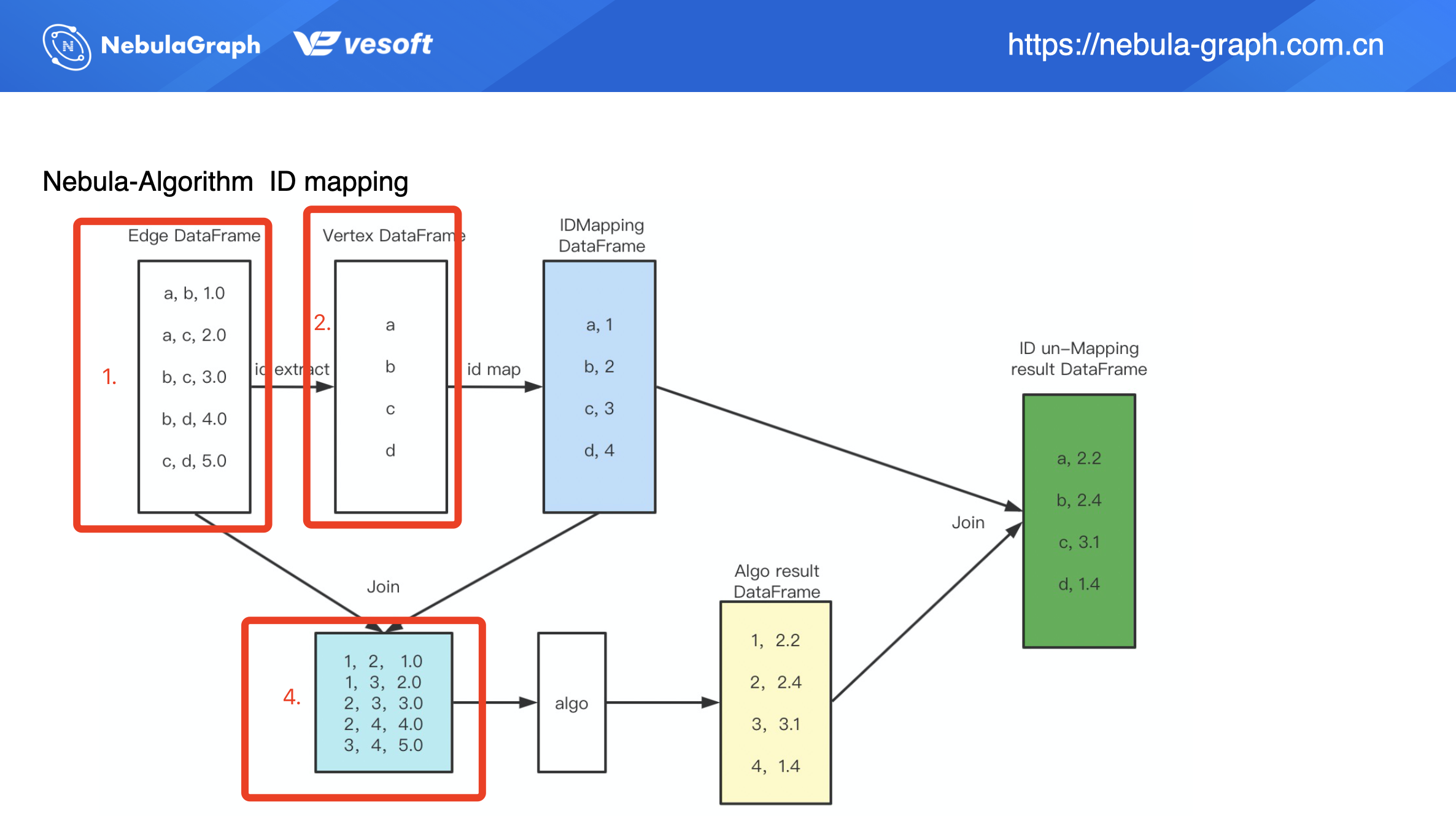
上圖為 ID 映射(Mapping)的過程,在演算法調用的數據源(方框 1)顯示該數據為邊數據,且為 String 類型(a、b、c、d),當中的 1.0、2.0 等等列數據為邊權重。在第 2 步中將會從邊數據中提取點數據,這裡我們提取到了 a、b、c、d,提取到點數據之後通過 ID 映射生成 long 類型的數值 ID(上圖藍色框)。有了數值類型的 ID 之後,我們將映射之後的 ID 數據(藍色框)和原始的邊數據(方框 1)進行 Join 操作,得到一個編碼之後的邊數據(方框 4)。編碼之後的數據集可用來做演算法輸入,演算法執行之後得到數據結果(黃色框),我們可以看到這個結果是一個類似二維表的結構。
為了方便理解,我們假設現在這個是 PageRank 的演算法執行過程,那我們得到的結果數據(黃色框)右列(2.2、2.4、3.1、1.4)則為計算出來的 PR 值。但這裡的結果數據並非是最終結果,別忘了我們的原始數據是 String 類型的點數據,所以我們要再做下流程上的第 5 步:對結算結果做 ID & 結果的反 Mapping,這樣我們可以得到最終的執行結果(綠色框)。
要注意的是,上圖是以 PageRank 為例,因為 PageRank 的演算法執行結果(黃框右列數據)為 double 類型數值,所以不需要做 ID 反映射,但是如果上面的流程執行的演算法為連通分量或是標籤傳播,它的演算法執行結果第二列數據是需要做 ID 反映射的。
節選下 PageRank 的程式碼中的實現
def pagerankWithIdMaping(spark: SparkSession, df: DataFrame): Unit = {
val encodedDF = convertStringId2LongId(df)
val pageRankConfig = PRConfig(3, 0.85)
val pr = PageRankAlgo.apply(spark, encodedDF, pageRankConfig, false)
val decodedPr = reconvertLongId2StringId(spark, pr)
decodedPr.show()
}
我們可以看到演算法調用之前通過執行 val encodedDF = convertStringId2LongId(df) 來進行 String ID 到 Long 類型的映射,語句執行完之後,我們才會調用演算法,演算法執行之後再來進行反映射 val decodedPr = reconvertLongId2StringId(spark, pr)。
在直播影片(B站://www.bilibili.com/video/BV1rR4y1T73V)中,講述了 PageRank 示例程式碼實現,有興趣的小夥伴可以看下影片 24『31 ~ 25’24 的程式碼講解,當中也講述了編碼映射的實現。
nebula-algorithm 支援的演算法
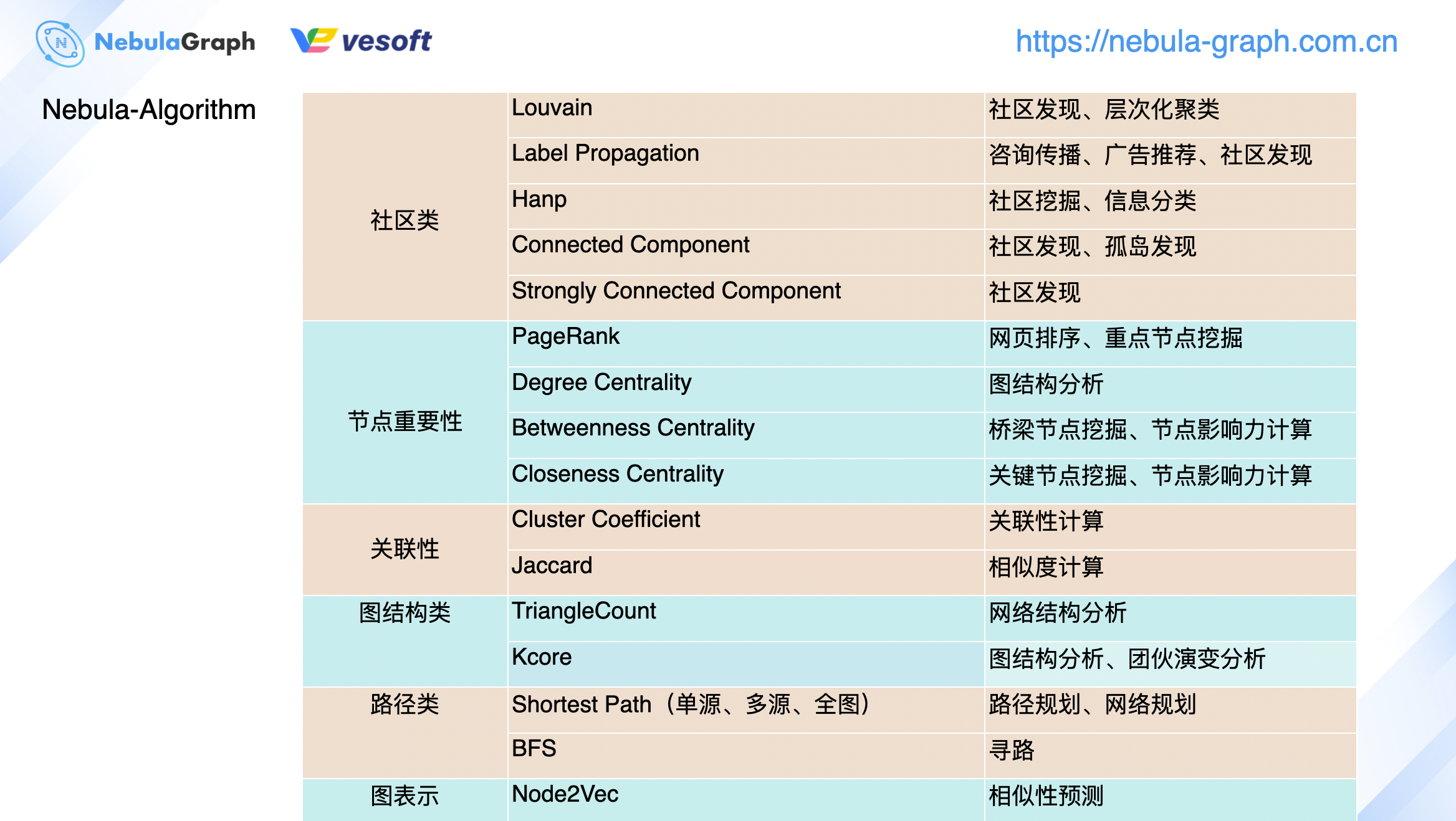
上圖展示的是我們在 v3.0 版本中將會支援的圖演算法,當然當中部分的圖演算法在 v2.0 也是支援的,不過這裡不做贅述具體的可以查看 GitHub 的文檔://github.com/vesoft-inc/nebula-algorithm 。
按照分類,我們將現支援的演算法分為了社區類、節點重要性、關聯性、圖結構類、路徑類和圖表示等 6 大類。雖然這裡只是列舉了 nebula-algorithm 的演算法分類,但是企業版的 nebula-plato 的演算法分類也是類似的,只不過各個大類中的內部演算法會更豐富點。根據目前社區用戶的提問回饋來講,演算法使用方便主要以上圖的社區類和節點重要性兩類為主,可以看到我們也是針對性的更加豐富這 2 大類的演算法。如果你在 nebula-algorithm 使用過程中,開發了新的演算法實現,記得來 GitHub 給 nebula-algorithm 提個 pr 豐富它的演算法庫。
下圖是社區發現比較常見的 Louvain、標籤傳播演算法的一個簡單介紹:

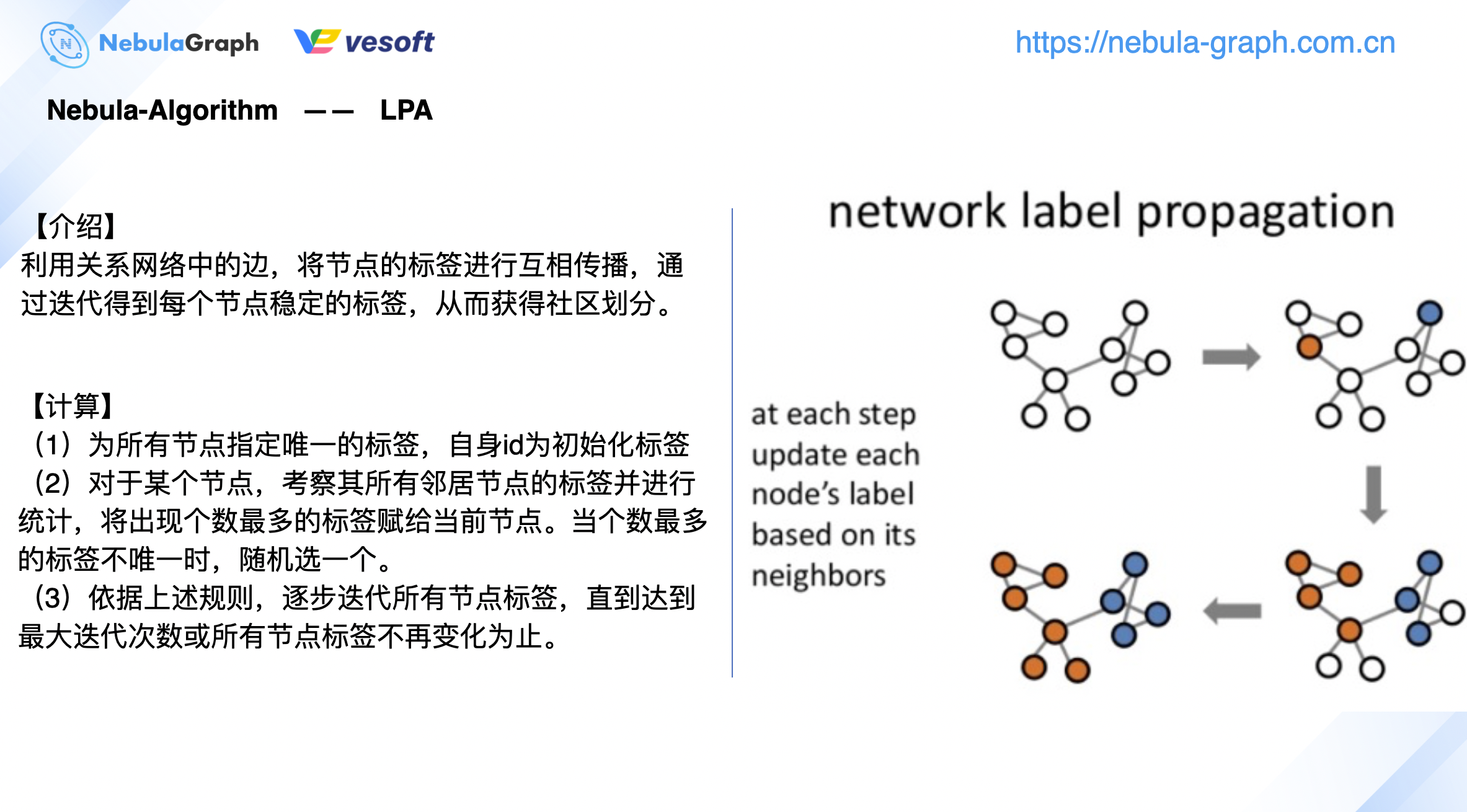
由於之前寫過相關的演算法介紹,這裡不做贅述,可以閱讀《GraphX 在圖資料庫 Nebula Graph 的圖計算實踐》。
這裡簡單介紹下連通分量演算法
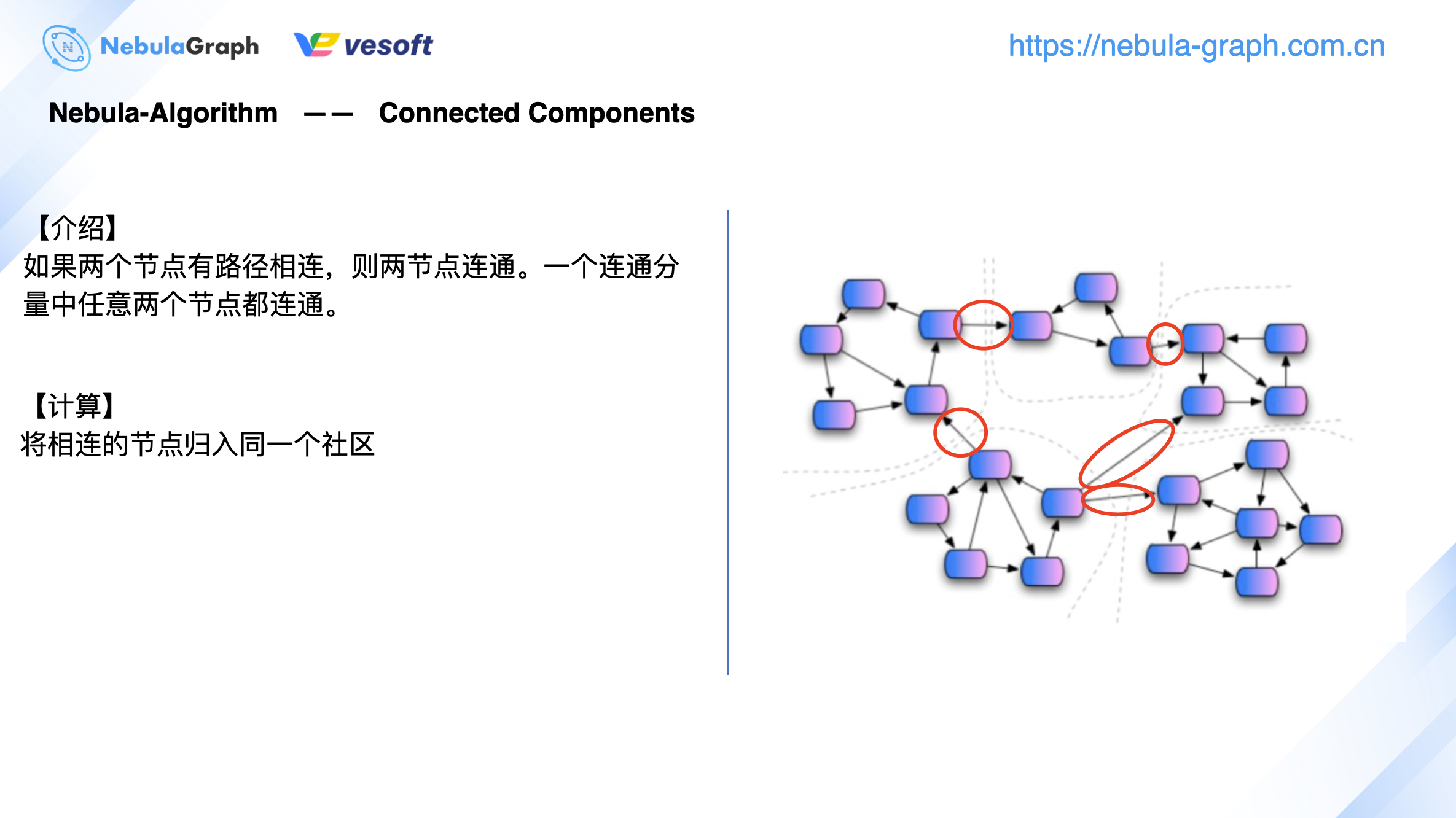
連通分量一般指的是弱連通分量,演算法針對無向圖,它的計算流程相對簡單。如上圖右側所示,以虛線劃分的 5 個小社區,在計算連通分量過程中,每個社區之間的連線(紅色框)是不做計算的。你可理解為從圖資料庫中抽取出 1 個子圖來進行 1 個聯通分量的計算,計算出來有 5 個小連通分量。這時候基於全圖去數據分析,不同的小社區之間又增加了連接邊(紅色框),將它們連接起來。
社區演算法的應用場景
銀行領域

再來看個具體的應用場景,在銀行中存在這種情況,一個身份證號對應多個手機號、多台手機設備、多張借記卡、多張信用卡,還有多個 APP。而這些銀行數據會分散存儲,要做關聯分析時,可以先通過聯通分量來去計算小社區。舉個例子:把同一個人所擁有的不同的設備、手機號等數據資訊歸到同一連通分量,把它們作為一個持卡人實體,再進行下一步計算。簡單來說,將分散數據通過演算法聚合成大節點統一分析。
安防領域
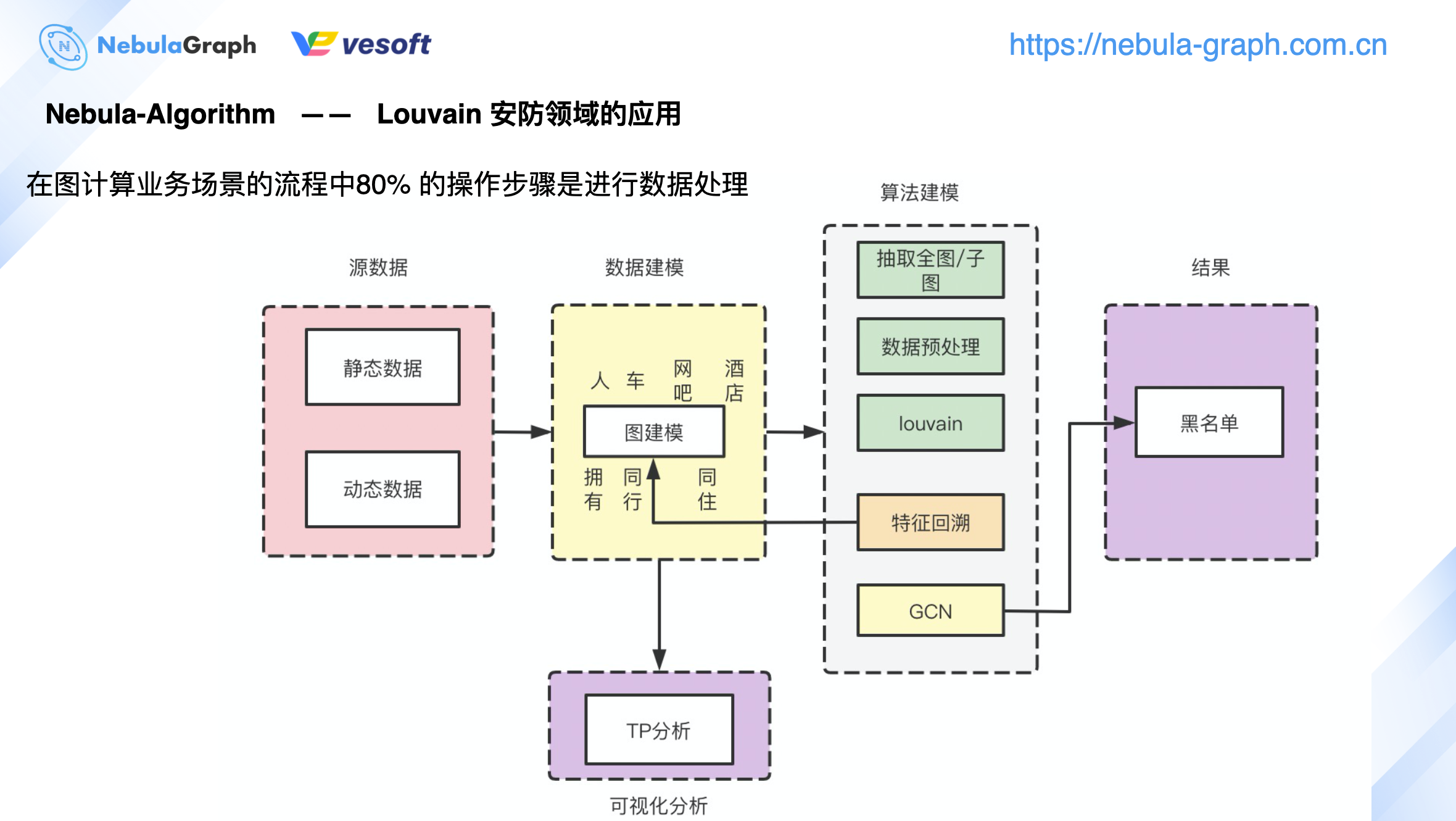
上圖是 Louvain 演算法在安防領域的應用,可以看到其實整個業務處理流程中,演算法本身的比重佔比並不高,整個處理流程 80% 左右是在對數據做預處理和後續結果進行統計分析。不同領域有不同的數據,領域源數據按業務場景進行實際的圖建模。
以公安為例,通過公安數據進行人、車、網吧、酒店等實體抽取,即圖資料庫中可以分成這 4 個 tag(人、車、網吧、酒店),基於用戶的動態數據抽象出擁有關係、同行關係、同住關係,即對應到圖資料庫中的 Edge Type。完成數據建模之後,再進行演算法建模,根據業務場景選擇抽取全圖,還是抽取子圖進行圖計算。數據抽取後,需要進行數據預處理。數據預處理包括很多操作,比如將數據拆分成兩類,一類進行模型訓練,另外一類進行模型驗證;或是對數據進行權重、特徵方面的數值類轉換,這些都稱為數據的一個預處理。
數據預處理完之後,執行諸如 Louvain、節點重要程度之類的演算法。計算完成後,通常會將基於點數據得到的新特徵回溯到圖資料庫中,即圖計算完成後,圖資料庫的 Tag 會新增一類屬性,這個新屬性就是 Tag 的新特徵。計算結果寫回到圖資料庫後,可將圖資料庫的數據讀取到 Studio 畫布進行可視化分析。這裡需要領域專家針對具體業務需求進行可視化分析,或者數據完成計算後進入到 GCN 進行模型訓練,最終得到黑名單。
以上為本次圖計算的概述部分,下面為來自社區的一些相關提問。
社區提問
這裡摘錄了部分的社區用戶提問,所有問題的提問可以觀看直播影片 33『05 開始的問題回復部分。
演算法內部原理
dengchang:想了解下圖計算各類成熟演算法的內部原理,如果有結合實際場景跟數據的講解那就更好了。
Nicole:趙老師可以看下之前的文章,比如:
一些相對比較複雜的演算法,在直播中不便展開講解,後續會發布文章來詳細介紹。
圖計算的規劃
en,coder:目前我看到 Nebula Algorithm 計算要將資料庫數據導出到 Spark,計算完再導入到資料庫。後續是否考慮支援不導出,至少輕量級演算法的計算,結果展示在 Studio。
Nicole:先回復前面的問題,其實用 nebula-algorithm 計算完不一定要將結果導入到圖資料庫,目前 nebula-algorithm 的 API 調用和jar 包提交兩種方式均允許把結果寫入到 HDFS。是否要將結果數據導入圖資料庫取決於你後續要針對圖計算結果進行何種處理。至於「後續是否支援不導出,至少輕量級的計算」,我的理解輕量級的演算法計算是不是先把數據從圖資料庫中查出來,在畫布展示,再針對畫布中所展示出來的一小部分數據進行輕量級計算,計算結果立馬去通過 Studio 展示在畫布中,而不是在寫回到圖資料庫。如果是這樣的話,其實後續 Nebula 有考慮去做個圖計算平台,結合了 AP 和 TP,針對畫布中的數據,也可以考慮進行簡單的輕量級計算,計算結果是否要寫回到圖資料庫由用戶去配置。回到需求本身,是否進行畫布數據的輕量級計算還是取決於你的具體場景,是否需要進行這種操作。
潮與虎:nebula-algorithm 打算支援 Flink 嗎?
Nicole:這裡可能指的是 Flink 的 Gelly 做圖計算,目前暫時沒有相關的打算。
繁凡:有計劃做基於 nGQL 的模式匹配嗎?全圖的 OLAP 計算任務,實際場景有一些模式匹配的任務,一般自己開發程式碼,但是效率太低。
郝彤:模式匹配是個 OLTP 場景,TP 受限於磁碟的速度較慢,所以想用在 OLAP 上,但是 OLAP 通常是處理傳統演算法,不支援模式匹配。其實後續 AP 和 TP 融合之後,圖數據放在記憶體中,速度會提升。
圖計算的最佳實踐案例
戚名鈺:利用圖計算能力做設備風險畫像的問題,業界有哪些最佳實踐?比如在群控識別、黑產團伙挖掘上面,有沒有相關業界的最佳實踐分享?
Nicole:具體業務問題需要依靠運營同學同社區用戶約稿,從實際案例中講解圖計算更有價值。
圖計算記憶體資源配置
劉翊:如何評估圖計算所需的記憶體總量。
郝彤:因為不同的圖計算系統設計不同,記憶體使用量也就不一樣。即便是同一個圖計算系統,不同的演算法對於記憶體的需求也存在些差異,可以先通過 2、3 種不同數據進行測試,以便評估出最佳的資源配置。
以上為圖計算 on nLive 的分享,你可以通過觀看 B站影片://www.bilibili.com/video/BV1rR4y1T73V 查看完整的分享過程。如果你在使用 nebula-algorithm 和 nebula-plato 過程中遇到任何使用問題,歡迎來論壇同我們交流,論壇傳送門://discuss.nebula-graph.com.cn/ 。
交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebula 名片,Nebula 小助手會拉你進群~~

