【論文總結】Zero-Shot Semantic Segmentation
論文地址://arxiv.org/abs/1906.00817
程式碼://github.com/valeoai/ZS3
一、內容
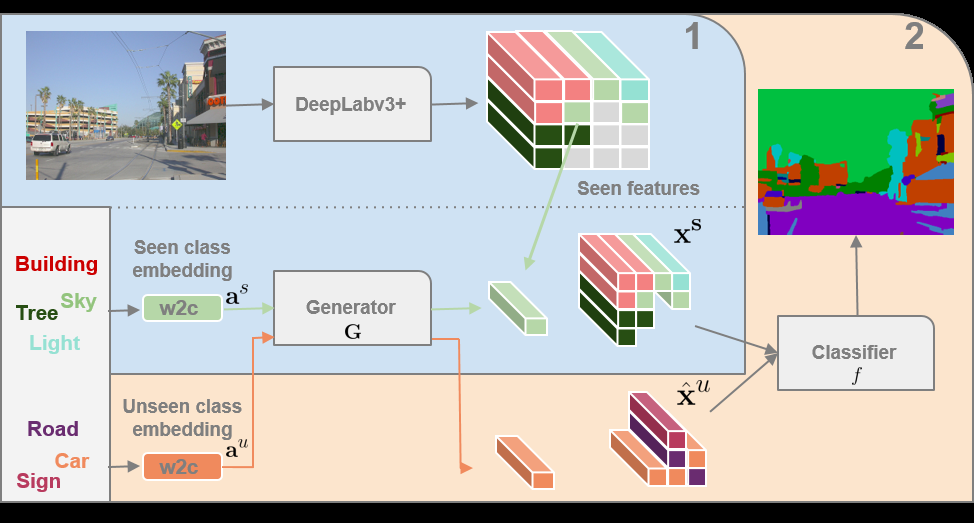
Step 0:首先使用數據集(完全不包含 Unseen Classes 的圖片)訓練 DeepLabv3+ 模型,得到的模型可以對只含有 Seen Classes 的圖片進行分類,去掉訓練好的 DeepLabv3+ 的最後一層分類層,將其變成一個特徵提取器。將所有 Classes 輸入到 w2c 模型,得到每個Class 對應的向量,將此向量連接到 ground-truth 中每個像素上,即每個像素都有其對應的類的向量。
Step 1:使用數據集(完全不包含 Unseen Classes 的圖片)輸入到 DeepLabv3+ 模型,得到特徵圖,根據 ground-truth 上的 Class 篩選出不同類別的特徵,將每個類的特徵作為 Label,對應類的 w2c 輸出的向量作為輸入,訓練 GMMN 模型。
Step 2:使用完整數據集 (包含 Seen 和 Unseen Classes 的圖片)輸入到 DeepLabv3+ 模型,如果不包含 Unseen Classes,那麼直接拿出特徵圖去訓練最終的分類器,如果包含,則根據圖片的 ground-truth 對應的類的向量一一生成特徵,將不同類特徵組合到一起,再去訓練最終的分類器。
二、理解
1. 程式碼中將 Step 1 和 2 和在了一起,為了便於理解,把 Step 1 和 2 分開解釋。
2. Step 2 中使用了兩次包含 Unseen Classes 的影像和其 ground-truth。
- 在逐個對類的詞向量生成特徵時,用到了 ground-truth,根據 ground-truth 知道了類的總數、每個類的位置、以及對應的詞向量。
- 在最終訓練分類器時,也用到了含有 Unseen Class 的影像的 ground-truth。
- 也可以直接忽略 DeepLab 生成的特徵圖,直接根據 Seen 和 Unseen 標籤隨機生成圖片,利用類的詞向量通過 GMMN 生成特徵,結合生成的圖片的 Label 去訓練最終分類器。
3. w2c 和 GMMN 是文章的關鍵,w2c 建立了一個從詞語到向量的聯繫,GMMN 建立了一個從詞向量到特徵圖上的視覺特徵的聯繫,比如,使用 Unseen Class 為子彈,Seen Class 中包括彈匣,其他都是些不相干的類,自然子彈和彈匣在詞向量中的聯繫比較起來相對緊密,從而子彈通過 GMMN 生成的特徵也更與彈匣類似,通過最終分類器的訓練,也就更容易能分辨出子彈。


