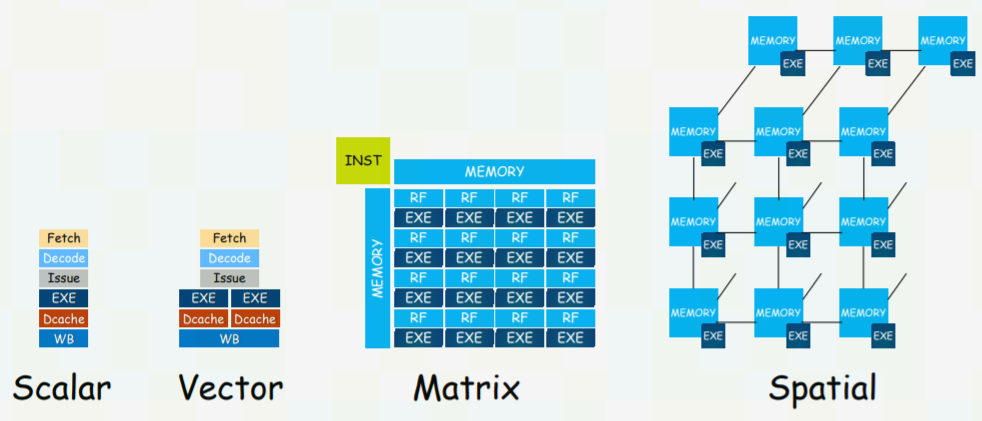
計算架構的演進
- 2022 年 2 月 8 日
- 筆記
姚偉峰
Landmark
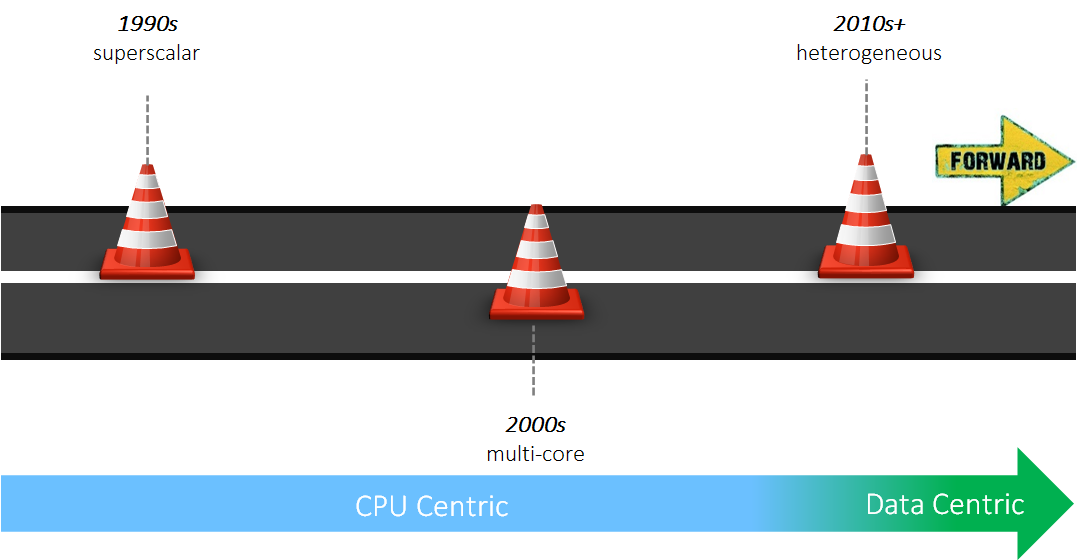
Superscalar時期(1990s)
超標量時期主要關注single core的性能,主要使用的方法有:
ILP(Instruction Level Parallelism)
ILP顧名思義就是挖掘指令性並行的機會,從而增加指令吞吐。指令吞吐的度量是: IPC(Instructions Per Cycle)即每個clock cycle可以執行的指令數。在未做ILP的時候 IPC = 1。
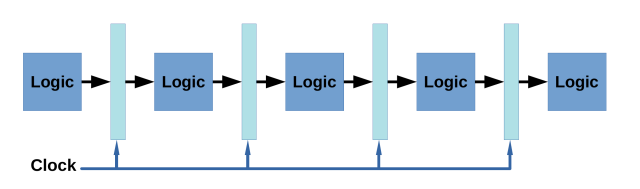
增加IPC主要通過pipeline技術來完成(如下圖)。Pipeine技術把指令的執行過程分成多個階段(stages),然後通過一個同步clock來控制,使得每一拍指令都會往前行進到pipeline的下一個階段,這樣理想情況下可以保證同一個cycle有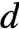 條指令在pileline內,使得pipeline的所有stage都是忙碌的。稱為pipeline的深度(depth)。
條指令在pileline內,使得pipeline的所有stage都是忙碌的。稱為pipeline的深度(depth)。
下圖是RISC-V的標準pipeline,它的 ,分別為:取指(Instruction Fetch, IF),譯指(Instruction Decode, ID),執行(Execute, EX),訪存(Memory Access, Mem),回寫(Write Back, WB)。其中IF和ID稱為前端(Front End)或者Control Unit,執行/訪存/回寫稱為後端(Back End)或者廣義Arithmetic/Logical Unit(ALU)。
,分別為:取指(Instruction Fetch, IF),譯指(Instruction Decode, ID),執行(Execute, EX),訪存(Memory Access, Mem),回寫(Write Back, WB)。其中IF和ID稱為前端(Front End)或者Control Unit,執行/訪存/回寫稱為後端(Back End)或者廣義Arithmetic/Logical Unit(ALU)。
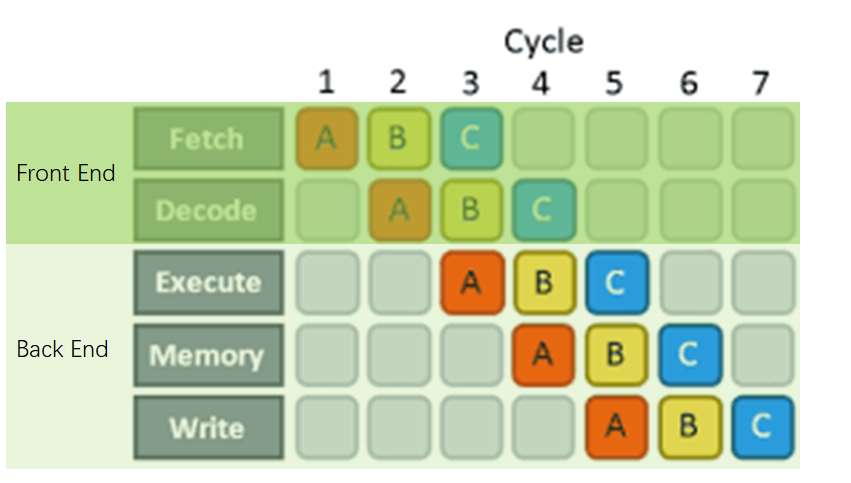

有了pipeline,可以通過增加pipeline width的方式提高指令並行度,即使得pipeline可以在同一個cycle取、譯、發射(issue, 發射到execution engine執行)多個指令的方式來達成ILP。物理上,需要多路ID/IF以及多個execution engines。如果一個core在一個cycle最多可以issue 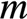 條指令,我們就叫這個架構為m-wide的multi-issue core。Multi-issue core也叫superscalar core。
條指令,我們就叫這個架構為m-wide的multi-issue core。Multi-issue core也叫superscalar core。
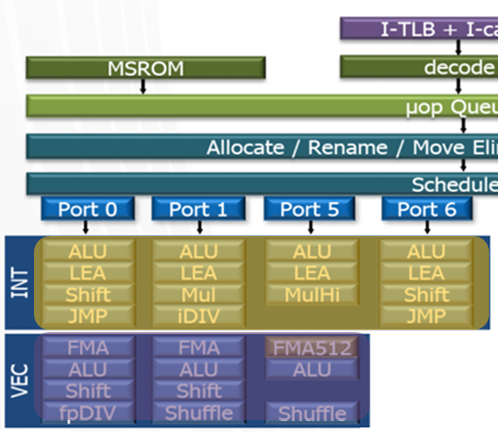
下圖為x86 SunnyCove core(Skylake的core)示意圖,可以看到,它有4個計算ports(即execution engines),我們可以稱它為4-wide multi-issue core,且它的最大可達IPC為4。
DLP(Data Level Parallelism)
提高數據並行度的主要方式是增加每個execution engine單clock cycle能處理的數據數來達成。傳統的CPU一個clock只能處理一個標量的運算,我們叫它scalar core。增加DLP的方式是使得一個clock能處理一個特定長度的vector數據,這就是vector core。目前vector core主要通過SIMD(Single Instruction Multiple Data)技術來實現數據並行,如ARM的NEON,X86的SSE、AVX(Advanced Vector eXtensions)、AVX2、AVX-512,以及GPU的SIMT(Single Instruction Multiple Data)的execution engine都是SIMD。
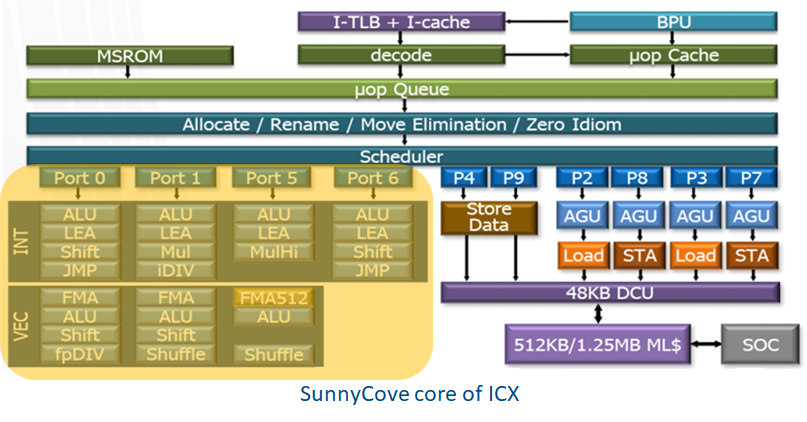
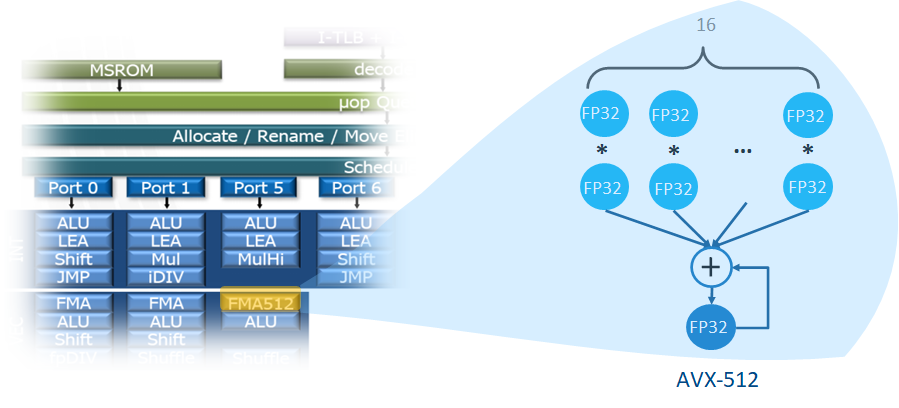
下圖SunnyCove core的port 5有一個AVX-512的FMA512(512-bit Fused MultiplyAdd) 它可以帶來16個FP32乘加運算的DLP。
Heterogeneous Parallelism
這一時期,我們也能依稀看到異構並行的萌芽,體現在標量和向量的異構並行上。下圖就體現出標量和向量的並行。
Multi Core時期(2000s)
多核時期在繼續摳ILP、DLP的同時,慢慢開始重視TLP(Thread Level Parallelism)。主要想法是通過組合多個同構(homogeneous)核,橫向擴展並行計算能力。
TLP(Thread Level Parallelism)
Physical Multi-Core
Physical Multi-Core就很簡單了,就是純氪金,對CPU和GPU而言都是堆核,只不過GPU把核叫作SM(Streaming Multiprocessor, NV),SubSlice(Intel)或Shader Array(AMD)。
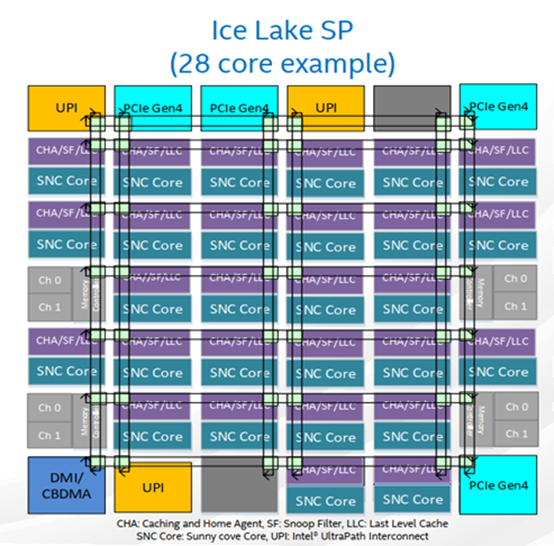
下圖是x86 Icelake socket,它有28個cores。
下圖是NV A100對應的GA100 full chip,它有128個cores(SMs)。

Hardware Threading
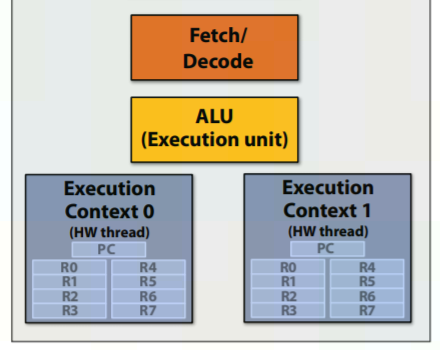
相比Physical Multi-Core,Hardware Threading就是挖掘存量了。它的基本假設是現有單程式pipeline里因為各種依賴會造成各種stall,導致pipeline bubble,且想僅靠從單個程式中來fix從而打滿pipeline利用率比較困難,所以考慮跨程式挖掘並行度。基於這個假設,一個自然的想法就是增加多個程式context,如果一個程式stall了,pipeline就切到另一個,從而增加打滿pipeline的概率。示意圖如下。
CPU:
GPU:
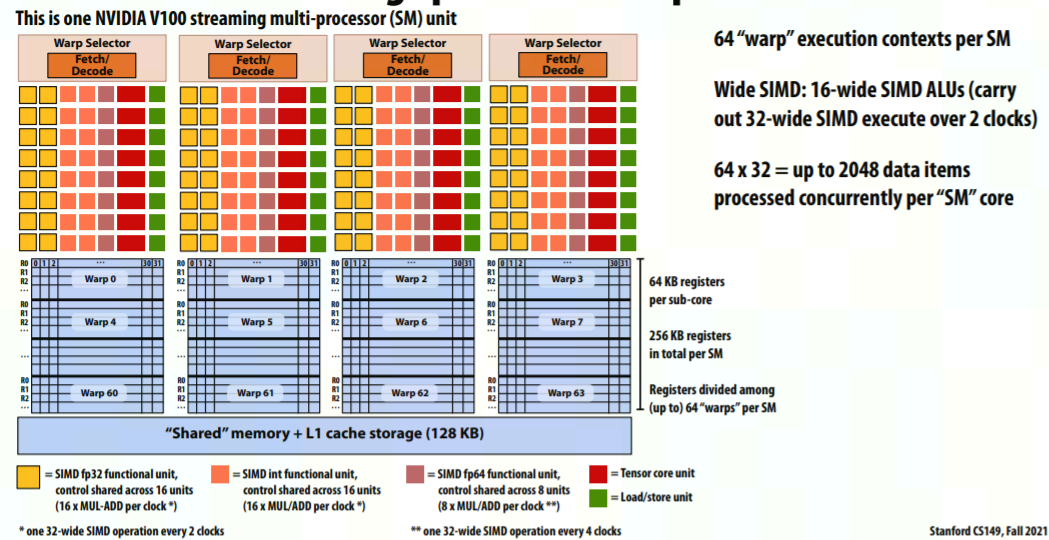
這就可以看出為啥叫threading了,就是不增加實際pipeline,只增加execution context的白嫖,:),這是threading的精髓。跟software threading不一樣的地方是,這個execution context的維護和使用是hardware做的,而不是software做的,因此叫hardware threading。
因為有多個contexts對應於同一個pipeline,因此如何Front End間如何issue指令也有兩種方式:
-
SMT(Simultaneous Multi-Threading)
Each clock, the pipeline chooses instructions from multiple threads to run on ALUs。典型的SMT就是Intel X86 CPU的Hyper Threading Technology(HT or HTT),每個core有2個SMT threads;以及NV GPU的warp。 -
IMT(Interleaved Multi-Threading)
Each clock, the pipeline chooses a thread, and runs an instruction
from the thread on the core』s ALUs. Intel Gen GPU採用的SMT和IMT的混合技術。
Heterogeneous Computing時期(2010s+)
由於application對算力(Higher Computation Capacity)和能效(Better Power Efficiency)的需求越來越高,體系架構為了應對這種需求發生了methodology的shift,從One for All走向Suit is Best。這是需求側。
而在供給側,GPU的成功也側面證明了Domain Specific Computing的逐漸成熟。
對software productivity而言,需要有兩個前提條件:
-
Unified Data Access
這個OpenCL 2.0的SVM (Shared Virtual Memory)和CUDA的UVM(Unified Virtual Memory)有希望。硬體上coherency-aware data access硬體如CXL可以從性能角度support這個。 -
Unified Programming Model
需要類C/C++的且支援異構計算的統一程式語言,這個有CUDA,OpenCL以及DPC++。
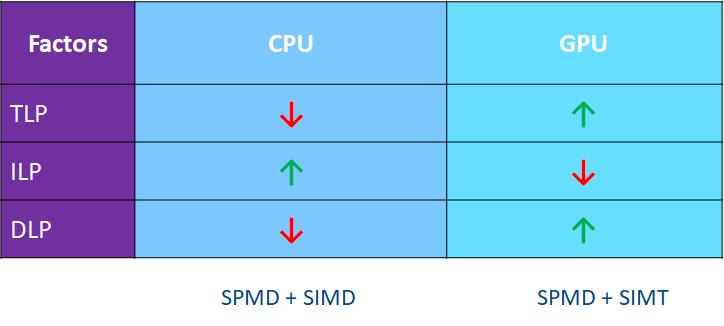
異構計算的題中之意是:Use best compute engine for each workload by re-balancing ILP & DLP & TLP,最終計算能力是3者的組合:

對不同的wokload,我們需要考慮我們是更傾向於A Few Big還是Many Small。

目前最常見的異構計算是CPU和GPU的異構計算,CPU作為latency machine代表, GPU作為throughput machine的代表,二者各有所長。
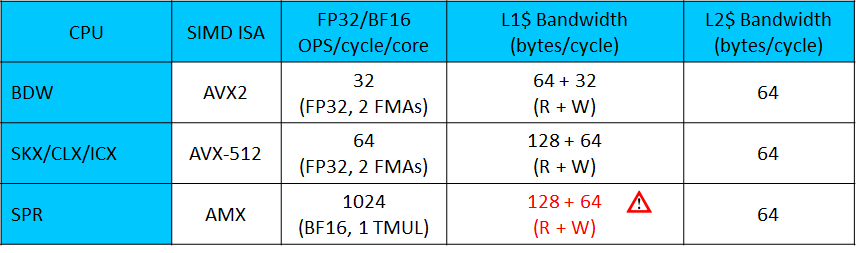
CPU Micro-Architecture Characteristics
-
TLP
tens of cores, each with 2 hardware threads; -
ILP
4 compute ports w/ OoO(Out of Order) issue -
DLP
SIMD width supported by Increased $ bandwidth

GPU Micro-Architecture Characteristics
-
TLP
hundreds of cores, each with many(e.g. 32) hardware threads;
simple and efficient thread generation/dispatching/monitoring -
ILP
2~3 compute ports, mainly in-order issue -
DLP
Wider SIMD width, plus large register files reduce $/memory bandwidth needs and improve compute capability and efficiency
隨著算力和能效的要求越來越高,除了挖掘馮-諾伊曼體系內的異構電腦會外(如CPU+GPU異構, CPU+ASIC異構等)。大家還開始revisit其他體系結構,尋找cross體系結構的異構機會,如最近一段時間大家討論比較多的dataflow architecture或者spatial computing。路是越走越寬了!